一、为什么要进行浏览器缓存?
- 减少 HTTP 请求次数,避免重复建立连接,缩短页面加载时间,提升用户体验。
- 减少服务器压力,降低带宽、CPU、IO 消耗,减少服务端成本。
二、浏览器缓存机制:
明确浏览器请求的不同情况:
第一件事:第一次请求(从来没访问过)
浏览器:
- 本地什么都没有
- 没有资源
- 没有缓存
- 没有任何过期规则
所以: 必须发 1 次请求服务器返回:
- 资源内容
- 缓存规则(Cache-Control / Expires)
- 缓存标识(ETag / Last-Modified)
浏览器把这三样全部存在本地。
第二件事:第二次、第三次、第 N 次请求
浏览器:
- 本地已经有缓存规则了
- 是上一次请求时,服务器给你的
- 存在硬盘 / 内存里,不用再问服务器要
所以:👉 浏览器直接看本地已有的规则自己判断:
- 过期了吗?
- 能用缓存吗?
这个过程,不发任何请求。
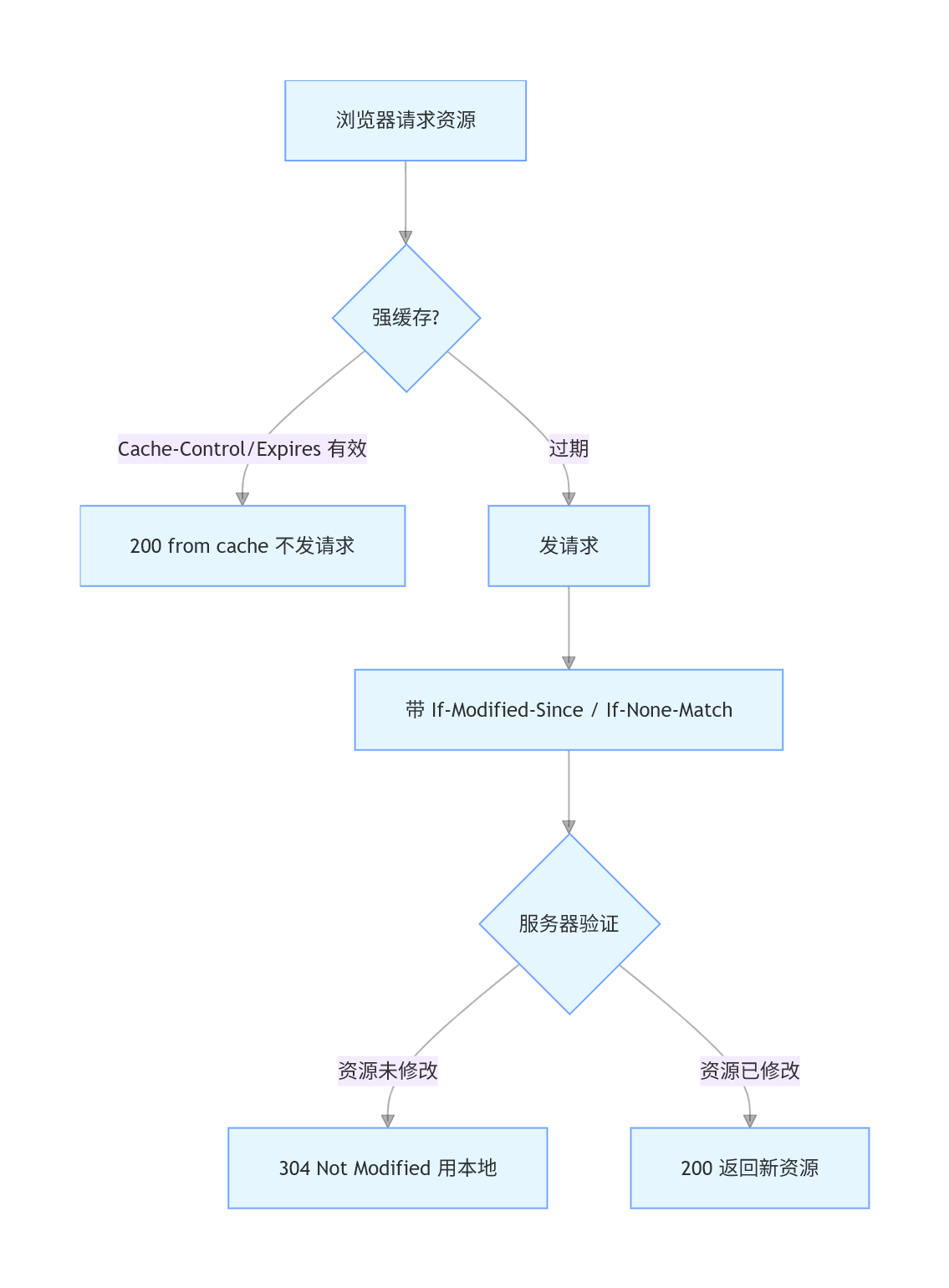
2. 缓存整体流程
浏览器执行缓存先查浏览器缓存中的强缓存,然后再决定是否用协商缓存。
- 先查强缓存
- 有效:直接用本地,不发请求(200 from cache)
- 无效:发请求,走协商缓存
- 再查协商缓存
- 服务端验证未修改:304 Not Modified,用本地缓存
- 已修改:200 + 新资源
3. 强缓存(不发请求)
作用
资源未过期,直接本地读取,不和服务器通信。
字段
- Cache-Control(HTTP/1.1,主流)
max-age=秒数:相对过期时间no-cache:不走强缓存,直接走协商缓存no-store:完全不缓存(最强禁用)
- Expires(HTTP/1.0,旧)
- 绝对时间,受本地时间影响
优先级:Cache-Control > Expires
4. 协商缓存(发请求,但省流量)
作用
强缓存过期后,问服务器资源是否更新。
第一组:Last-Modified / If-Modified-Since
- 服务端返回:
Last-Modified: 最后修改时间 - 浏览器请求带:
If-Modified-Since: 上次时间 - 服务端对比:没变 → 304;变了 → 200 + 新内容
第二组:ETag / If-None-Match(更精准)
- 服务端返回:
ETag: 资源唯一标识(哈希) - 浏览器请求带:
If-None-Match: 上次标识 - 服务端对比:一致 → 304;不一致 → 200 + 新内容
优先级:ETag > Last-Modified
明确:缓存规则完全由服务器通过响应头控制,浏览器只是遵守规则。
5.强制缓存和协商缓存的触发是由什么决定的呢?
5.1强制缓存和协商缓存的触发,由 Cache-Control 直接决定
浏览器的缓存决策流程是分层判断 的,Cache-Control 是第一层(强制缓存层)的 "总开关",它的指令直接决定:
- 是否进入「强制缓存判断」
- 如果强制缓存不生效,是否进入「协商缓存」
- 还是直接跳过所有缓存,发全新请求
5.1.2决策表(核心)
| Cache-Control 指令 | 强制缓存是否生效 | 协商缓存是否触发 | 最终行为总结 |
|---|---|---|---|
max-age=3600(有有效期) |
生效 | 不触发(过期前) | 有效期内直接用缓存(0 请求);过期后触发协商缓存 |
no-cache |
不生效 | 触发 | 每次都发请求(带协商标识),服务器判断是否用缓存 |
no-store |
不生效 | 不触发 | 完全不缓存,每次发全新请求(不带任何缓存标识) |
| 无 Cache-Control 字段 | 不生效 | 触发 | 走默认协商缓存流程 |
5.1.3关键结论:
Cache-Control 是通过是否允许浏览器 "自主判断使用缓存" 来控制流程:
- 只要指令允许强制缓存(如
max-age)→ 浏览器先判断强制缓存,生效则不走协商; - 只要指令禁止强制缓存(如
no-cache)→ 跳过强制缓存,直接走协商缓存; - 只要指令禁止缓存(
no-store)→ 跳过所有缓存,发全新请求。
5.2拆解 Cache-Control 控制逻辑的底层原理
我们以"动态页面(个人中心)用 no-cache"为例,一步步看 Cache-Control 是如何和浏览器缓存规则、HTTP 流程联动的:
5.2.1 Cache-Control: no-cache 的字面意思(先纠偏)
很多人误以为 no-cache = "不缓存",但真实含义是:
"不允许浏览器直接使用本地缓存(强制缓存失效),必须先向服务器验证(走协商缓存)"。
它的核心是:缓存依然会存,但用之前必须问服务器。
5.2.2 动态页面用 no-cache 的完整执行流程(和 HTTP 联动)
假设你访问 https://xxx.com/user/123(个人中心),服务器返回 Cache-Control: no-cache + ETag: "user123-v1":
第一次访问(无缓存):
-
浏览器查本地缓存 → 无 → 发 1 次请求;
-
服务器返回:
javascriptHTTP/1.1 200 OK Cache-Control: no-cache # 禁止强制缓存 ETag: "user123-v1" # 协商缓存标识 # 个人中心页面内容(如用户名、头像、订单) -
浏览器依然会把页面内容 + ETag 存到本地缓存 (注意:
no-cache不是不存,是不用)。
第二次访问(有缓存,但 no-cache 生效):
-
浏览器查本地缓存 → 有页面 + ETag,但看到
Cache-Control: no-cache; -
浏览器决策:
no-cache禁止强制缓存 → 跳过强制缓存判断; -
浏览器构造请求,带上协商缓存标识:
javascriptGET /user/123 HTTP/1.1 If-None-Match: "user123-v1" # 本地存的ETag -
服务器判断:
- 如果用户数据没改(如没换头像、没下单)→ 返回
304 Not Modified,浏览器用本地缓存; - 如果用户数据改了 → 返回
200 OK + 新页面 + 新 ETag,浏览器更新缓存。
- 如果用户数据没改(如没换头像、没下单)→ 返回
5.3 对比:如果动态页面用 max-age=3600(错误做法)
- 第一次访问:存缓存 + 规则;
- 第二次访问:浏览器看
max-age没过期 → 直接用本地缓存(0 请求); - 问题:用户改了头像,但浏览器还显示旧头像(强制缓存生效,没问服务器)→ 数据不一致。
这就是为什么动态页面必须用 no-cache:禁止浏览器自主用缓存,每次都问服务器,保证数据最新。
6. 为什么 ETag 比 Last-Modified 好?
- 精度更高 :秒内多次修改,
Last-Modified识别不出 - 内容不变不算改 :文件改了但内容一样,
ETag不变(资源唯一标识) - 时间不准问题:部分服务器无法精确获取修改时间
7.浏览器缓存整个流程是什么?(必考题)
**问:**从浏览器输入 URL 到页面展示,说说浏览器缓存的完整流程。
答:
- 浏览器先判断 强缓存 是否有效:
- 通过
Cache-Control(优先)或Expires判断。 - 有效:直接使用本地缓存,不发请求,状态码 200 from cache。
- 通过
- 强缓存失效,则发送 HTTP 请求,进入 协商缓存:
- 请求头带上
If-Modified-Since或If-None-Match。
- 请求头带上
- 服务端对比缓存标识:
- 资源未修改:返回 304 Not Modified,浏览器继续使用本地缓存。
- 资源已修改:返回 200 + 新资源,并更新缓存。
8.强缓存和协商缓存有什么区别?
**问:**强缓存、协商缓存的区别是什么?
答:
- 是否发请求
- 强缓存:不发请求,直接本地读取。
- 协商缓存:会发请求,但可能只返回头信息,不返回 body。
- 判断依据
- 强缓存:
Cache-Control/Expires。 - 协商缓存:
Last-Modified / ETag。
- 强缓存:
- 状态码
- 强缓存命中:200(from cache)。
- 协商缓存命中:304 Not Modified。
9.为什么有了 Last-Modified 还需要 ETag?
**问:**已经有 Last-Modified 了,为什么还要设计 ETag?
答:
- 精度更高Last-Modified 只能精确到秒,秒内多次修改无法识别,ETag 是内容哈希,能精准识别。
- 内容不变就不变文件修改时间变了,但内容没变,ETag 不变,不会重复传输。
- 避免服务器时间不准有些服务器无法准确获取文件修改时间,会导致 Last-Modified 失效。
- 优先级 同时存在时,ETag 优先级高于 Last-Modified。
10. 总结
浏览器请求资源时,先判断强缓存是否有效 ,有效直接用本地缓存;无效则发送请求,带上协商缓存标识,服务端验证通过返回 304 继续使用缓存,否则返回 200 和最新资源。
三、内存缓存(from memory cache)与硬盘缓存(from disk cache)
1.浏览器的缓存是缓存在哪里呢?
浏览器缓存分 4 层 ,按查找优先级从高到低:
-
Memory Cache(内存缓存)
- 存放位置:浏览器进程内存
- 特点:最快、关闭标签页就消失
- 作用:当前页面快速复用资源(小图、脚本、样式)
-
Disk Cache(硬盘缓存)
- 存放位置:本地硬盘(浏览器用户数据目录)
- 特点:容量大、持久化、重启浏览器还在
- 绝大多数静态资源都存在这里
-
Service Worker Cache
- 存放位置:硬盘独立存储区
- 特点:程序员可手动控制,支持离线缓存(PWA)
-
Push Cache(HTTP/2 推送缓存)
- 存放位置:内存
- 特点:会话级缓存,生命周期极短
浏览器读取缓存的优先级始终是:先查内存缓存 → 内存无缓存 → 再查硬盘缓存。
2.怎么判断强缓存生效?
1. 看 Network 面板三个标志
满足 全部 才叫强制缓存生效:
- Status Code = 200 OK
- Size 列显示
from memory cache- 或
from disk cache
- 没有发送请求
- Request Headers 区域是灰色 / 不显示请求
2. 强制缓存 vs 协商缓存 区别
| 类型 | 是否发请求 | 状态码 | 表现 |
|---|---|---|---|
| 强制缓存 | 不发 | 200 OK (from cache) | 直接读本地 |
| 协商缓存 | 发请求 | 304 Not Modified | 问服务器是否过期 |
状态码的请求 200 from cache代表强缓存生效;状态码的请求304 Not Modified代表协商缓存生效。
3. 内存缓存(from memory cache)
内存缓存是浏览器将解析 / 编译后的资源(如已执行的 JS、渲染后的图片)存入当前浏览器进程的内存中,核心特点:
- 极速读取:内存读写无需磁盘 I/O 操作,直接从进程内存中调取,响应时间可低至 0ms,是浏览器缓存中最快的层级;
- 进程级时效性:内存缓存与浏览器进程强绑定 ------ 关闭标签页 / 浏览器窗口后,进程销毁,内存缓存会被立即清空;
- 容量限制:内存空间有限,浏览器仅会将高频访问、体积较小的核心资源(如常用 JS、Base64 图片)存入内存缓存。
4. 硬盘缓存(from disk cache)
硬盘缓存是浏览器将资源文件直接写入本地硬盘(如浏览器的缓存文件夹),核心特点:
- 读取效率稍低:读取时需执行硬盘 I/O 操作,再重新解析文件内容,速度慢于内存缓存,但远快于网络请求;
- 持久化存储:缓存不随浏览器进程销毁而消失,关闭标签页 / 浏览器后,硬盘缓存仍会保留(直到缓存过期 / 被清理);
- 容量宽松:硬盘存储空间远大于内存,浏览器会将体积较大、访问频率稍低的资源(如 CSS、字体文件、未即时使用的图片)存入硬盘缓存。
5. 浏览器资源缓存的默认规则以及浏览器渲染规则
浏览器会根据资源类型和使用场景,默认分配缓存存储位置:
- 存入内存缓存:JS 文件(解析执行后)、图片(渲染后)、页面 DOM 结构等 "即时复用" 的资源;
- 存入硬盘缓存:CSS 文件(需重新解析渲染)、字体文件、视频 / 音频片段、体积较大的静态资源等。
5.1浏览器渲染页面时为什么会出现先加载出来文字内容,然后才能加载出来样式?为什么有的时候会先加载出来图片占位,之后才会完整显示图片资源?
首先明确:
- HTML 文字不阻塞 → 最先渲染
- CSS 阻塞渲染 → 样式必须等 CSSOM 构建完
- 图片不阻塞布局,只阻塞绘制 → 先占位,后显示
跟缓存放内存还是硬盘没有半毛钱关系。
5.1.1Memory Cache 与 Disk Cache 跟「资源类型」无关,只跟 2 件事有关:
- 当前是否正在使用
- 页面打开、正在渲染 → 放 Memory Cache
- 页面关掉、闲置 → 移去 Disk Cache
- 系统内存压力
- 内存够 → 尽量放内存
- 内存不够 → 直接放硬盘
真正的规则:
- 图片、JS、CSS、字体 既可以在内存,也可以在硬盘
- 内存缓存:会话级、快、关页面就没
- 硬盘缓存:持久化、慢、重启还在
5.1.2浏览器渲染流程:
浏览器渲染是严格流水线:
- 解析 HTML → 生成 DOM
- 解析 CSS → 生成 CSSOM
- DOM + CSSOM → 合成 Render Tree
- **Layout(布局 / 重排)**计算:元素在哪、多大、占多少空间
- **Paint(绘制 / 重绘)**真正把像素画到屏幕
- Composite(合成)
5.1.3图片为什么会 "先占位"?
当浏览器解析到:
javascript
<img src="a.jpg" width="200" height="200">步骤 1:HTML 解析遇到 img
- 浏览器只做一件事 :知道这个标签要占 200×200 的位置
- 它不会等图片下载
- 它不会等图片解码
直接进入 Layout。
步骤 2:Layout 阶段
- 布局引擎直接给图片留好空位
- 页面其他内容(文字、div)正常排版→ 你看到的空白占位框,就是这一步出来的。
步骤 3:异步线程去加载 / 读取图片
浏览器开网络线程 / IO 线程去做:
- 网络请求 或
- 读 Disk Cache 或
- 读 Memory Cache
这完全是异步的,不阻塞布局.
步骤 4:图片下载 / 读取完成 → 解码
JPG/PNG/WebP 都是压缩格式,必须解码成位图才能画。
解码也是异步、耗时的。
步骤 5:解码完毕 → 通知主线程 → Paint
图片到位了,浏览器才会把图片画到占位框里。
5.2为什么给 img 设置 width/height 能优化布局偏移?
没有设置 width/height 时,布局阶段无法确定图片的占位尺寸 ,会先按「默认尺寸」占位,等图片加载完成后触发二次布局(重排),从而导致布局偏移。
5.2.1一句话底层结论:
设置 width/height 能让浏览器在「第一次布局」时就确定图片的准确占位,避免图片加载完成后触发「重排(Reflow)」,从而消除布局偏移。
分两种对比场景拆解:
场景 1:未设置 width/height(导致布局偏移)
javascript
<!-- 无尺寸 -->
<img src="big.jpg">渲染流程:
- 第一次布局:浏览器不知道图片尺寸,只能按「默认占位(比如 0×0 或浏览器默认的小尺寸)」计算布局 → 页面其他元素按这个 "临时尺寸" 排版。
- 图片加载完成 :浏览器拿到图片的真实尺寸(比如 800×600),发现「之前的占位尺寸不对」→ 触发二次布局(重排)。
- 二次布局 :重新计算图片和周边元素的位置 → 页面元素 "突然移位" → 这就是布局偏移(CLS,Cumulative Layout Shift),也是谷歌核心网页指标(Core Web Vitals)的重要项。
场景 2:设置 width/height(消除布局偏移)
html
<!-- 有尺寸 -->
<img src="big.jpg" width="800" height="600">
<!-- 或用 CSS 设置 -->
<img src="big.jpg" style="width:800px; height:600px;">渲染流程:
- 第一次布局:浏览器直接用设置的 800×600 计算占位 → 周边元素按这个准确尺寸排版。
- 图片加载完成:尺寸和预设一致 → 无需二次布局,只触发「重绘(Paint)」(仅画图片,不改变布局)。
- 最终效果:图片占位从一开始就准确,加载完成后只有 "填充图片" 的视觉变化,无任何元素移位 → 消除布局偏移。
拓展:5.3 为什么现在推荐「宽高比」而非固定尺寸?
移动端适配场景下,固定宽高会变形,最优方案是「预设宽高比 + 自适应尺寸」:
css
/* 核心:用 padding-top 模拟宽高比(比如 16:9) */
.img-container {
position: relative;
width: 100%;
padding-top: 56.25%; /* 9/16=56.25% */
}
.img-container img {
position: absolute;
top: 0;
left: 0;
width: 100%;
height: 100%;
object-fit: cover;
}原理:padding-top 是相对父元素宽度计算的,能固定宽高比,布局阶段就确定占位,同时适配不同屏幕宽度。
拓展:5.4布局偏移的本质:重排(Reflow)vs 重绘(Repaint)
- 重排(Reflow):布局重新计算 → 性能消耗大(涉及整个页面排版)。
- 重绘(Repaint) :仅重新绘制像素 → 性能消耗小(只改图片区域)。设置 img 宽高的核心价值:把重排变成重绘,既消除偏移,又优化性能。
拓展:5.4面试高频追问:如果不知道图片真实宽高怎么办?
答:① 服务端返回图片宽高(接口字段),前端渲染时动态设置;② 用骨架屏 / 占位图(比如和图片宽高比一致的灰色块),替代空白占位;③ 用 CSS aspect-ratio(现代浏览器支持):
css
img {
width: 100%;
aspect-ratio: 16/9; /* 固定宽高比,布局阶段确定占位 */
}总结
- 设置 img 的 width/height 核心作用是让浏览器在第一次布局时确定准确占位,避免图片加载后触发重排导致布局偏移。
- 布局偏移的本质是「无预设尺寸 → 临时占位 → 二次重排」,设置尺寸能将重排转为轻量的重绘。
- 移动端最优解是「宽高比占位」(padding-top 或 aspect-ratio),兼顾适配和无偏移。
回顾上述:
浏览器缓存分为 Memory Cache、Disk Cache、Service Worker Cache 和 Push Cache,其中最常用的是内存缓存和硬盘缓存。
强制缓存由
Cache-Control和Expires控制,生效时浏览器不发送任何请求,直接从本地读取 ,表现为200 OK (from memory/disk cache);如果发送请求并返回 304,则是协商缓存,说明强制缓存已失效。Memory Cache 和 Disk Cache 不是按资源类型分的 ,而是按是否在使用、内存压力决定。图片、CSS、JS 都可内存可硬盘。
图片先占位、后显示,是因为浏览器布局 (Layout) 不等待图片加载与解码,只根据宽高占好位置,图片异步加载解码完成后才执行绘制 (Paint)。
即使图片在内存缓存 ,也需要异步解码,所以仍然会先占位再显示。
文字先出、样式后出,是因为 CSS 阻塞渲染 ,图片占位是因为 布局与加载异步分离,两者原理完全不同。
深度拓展:内存缓存 vs 硬盘缓存的核心知识点
一、存储优先级与加载逻辑(完整流程)
浏览器加载资源时,缓存的查询顺序是多层级的,内存 / 硬盘缓存仅属于 "强制缓存" 的存储载体,完整流程:
javascript
A[浏览器请求资源] --> B{查内存缓存}
B -->|有且未过期| C[from memory cache,0请求]
B -->|无| D{查硬盘缓存}
D -->|有且未过期| E[from disk cache,0请求]
D -->|无/已过期| F{强制缓存失效}
F --> G[发请求走协商缓存]
G --> H[服务器返回304/200]
H --> I[更新硬盘/内存缓存]关键补充:
- 内存缓存的优先级高于硬盘缓存,但仅对 "当前会话未销毁" 的资源有效(比如刷新页面时,内存缓存未清空,优先读取);
- 关闭标签页重新打开时,内存缓存已清空,会优先读取硬盘缓存。
二、核心区别对比表
| 维度 | 内存缓存(from memory cache) | 硬盘缓存(from disk cache) |
|---|---|---|
| 存储位置 | 浏览器进程内存 | 本地硬盘(缓存文件夹) |
| 读取速度 | 极快(0ms 级,无 I/O) | 较快(ms 级,需硬盘 I/O) |
| 持久性 | 会话级(关闭标签 / 浏览器即清空) | 持久化(直到缓存过期 / 清理) |
| 容量限制 | 小(受进程内存限制) | 大(受硬盘空间限制) |
| 存储资源类型 | JS、渲染后图片、DOM 结构 | CSS、字体、大体积静态资源 |
| 触发刷新(F5) | 大概率保留(进程未销毁) | 完全保留 |
| 强制刷新(Ctrl+F5) | 清空 | 清空 |
三、影响缓存存储位置的关键因素
并非资源类型决定存储位置,浏览器会综合判断以下条件:
- 资源体积:体积<100KB 的小资源(如小图标、短 JS)更易存入内存;体积大的资源(如大图片、完整 CSS)优先存入硬盘;
- 访问频率:高频访问的资源(如页面核心 JS)会被浏览器 "升级" 到内存缓存;
- 浏览器策略:不同浏览器(Chrome/Firefox/Safari)的缓存策略略有差异(如 Firefox 对 CSS 的缓存更倾向于内存);
- 内存占用率:当浏览器内存占用过高时,会自动将部分内存缓存 "降级" 到硬盘缓存,释放内存。
四、如何区分内存 / 硬盘缓存?
通过 Chrome DevTools 可直观验证,步骤如下:
- 打开 DevTools(F12)→ 切换到 Network 面板 → 勾选「Disable cache」(先取消勾选);
- 访问目标网站,首次加载所有资源显示
200 OK(服务器返回); - 第一次刷新(F5):
- JS / 图片显示
from memory cache(内存缓存生效); - CSS 显示
from disk cache(硬盘缓存生效);
- JS / 图片显示
- 关闭标签页,重新打开:
- 所有资源均显示
from disk cache(内存缓存已清空);
- 所有资源均显示
- 强制刷新(Ctrl+F5):
- 所有资源显示
200 OK(跳过内存 / 硬盘缓存,发全新请求)。
- 所有资源显示
五、性能优化视角:如何利用内存 / 硬盘缓存提升体验?
- 优先让核心资源进内存缓存:
- 页面首屏的核心 JS(如框架代码、初始化逻辑)尽量精简体积(<100KB),提升进入内存缓存的概率;
- 图片资源优先使用 Base64 内嵌(小图标),解析后直接存入内存,减少硬盘 I/O。
- 合理设置硬盘缓存的有效期:
- CSS / 字体文件设置较长的
max-age(如max-age=86400*7),利用硬盘缓存的持久性,减少重复请求; - 动态资源(如用户头像)设置
no-cache+配置ETag,跳过强制缓存,但仍可利用硬盘缓存做协商缓存验证。
- CSS / 字体文件设置较长的
- 避免不必要的缓存占用:
- 非核心资源(如非首屏图片)通过
lazyload延迟加载,避免过早占用内存缓存; - 敏感资源(如支付页面)设置
no-store,禁止存入内存 / 硬盘缓存。
- 非核心资源(如非首屏图片)通过
六、常见误区纠正
- 误区 1 :
from memory cache比from disk cache更 "高级"→ 正确:两者是不同存储载体,无优劣之分 ------ 内存缓存快但不持久,硬盘缓存慢但持久,浏览器会自动适配; - 误区 2:CSS 一定存在硬盘缓存→ 正确:并非绝对!如果 CSS 体积极小(如仅几行)且高频访问,浏览器也会将其存入内存缓存;
- 误区 3:刷新页面会清空所有缓存→ 正确:普通刷新(F5)仅清空部分内存缓存,硬盘缓存完全保留;只有强制刷新(Ctrl+F5)才会清空所有缓存。
总结
- 浏览器强制缓存的存储载体分为内存缓存(极速、临时)和硬盘缓存(稍慢、持久),读取顺序为「内存→硬盘」;
- 存储位置由资源体积、访问频率、浏览器策略共同决定,而非仅由资源类型(JS/CSS)决定;
- 优化缓存的核心是:让核心资源进内存缓存提升速度,让非核心资源进硬盘缓存减少请求,同时通过
Cache-Control控制缓存有效期。
晚安啦煲仔们!!!
明天又是新的一天,加油加油!!!😀😀😀