这是我在我的网站中截取的文章,有更多的文章欢迎来访问我自己的博客网站rn.berlinlian.cn,这里还有很多有关计算机的知识,欢迎进行留言或者来我的网站进行留言!!!
作者正在学习斯坦福大学的CS224N课程。此文章的图片均来自该课程视频,之后会继续更新斯坦福大学CS224N课程,以及加上补充的知识,让我们一起探讨NLP的世界!!
第一节:语言模型任务回顾
在深入研究复杂的神经网络架构之前,我们首先需要明确:什么是语言模型(Language Modeling)?
简单来说,语言模型的目标是预测序列中下一个出现的词。假设我们已经有了一个单词序列 x(1), x(2), ... , x(t),模型的核心任务就是计算在给定这些已知词的条件下,下一个词 x(t+1) 出现的概率分布:
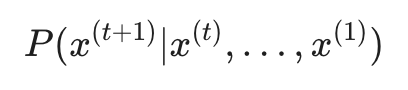
这里的 x(t) 可以是文档中的任何单词,而模型输出的则是一个针对整个词汇表(Vocabulary)的概率分布,告诉我们哪个词最有可能接着出现。
从命名实体识别(NER)中寻找灵感
在之前的讨论中,我们已经见识过**窗口模型(Window-based Model)**在命名实体识别(NER)任务中的表现。在 NER 中,我们通常对中心词进行分类(例如判断"Paris"是否是一个地点)。
既然这种基于窗口的结构能够很好地捕捉局部上下文信息,我们自然会产生一个想法:能不能利用类似的"窗口"结构来预测下一个词,从而构建一个语言模型呢?
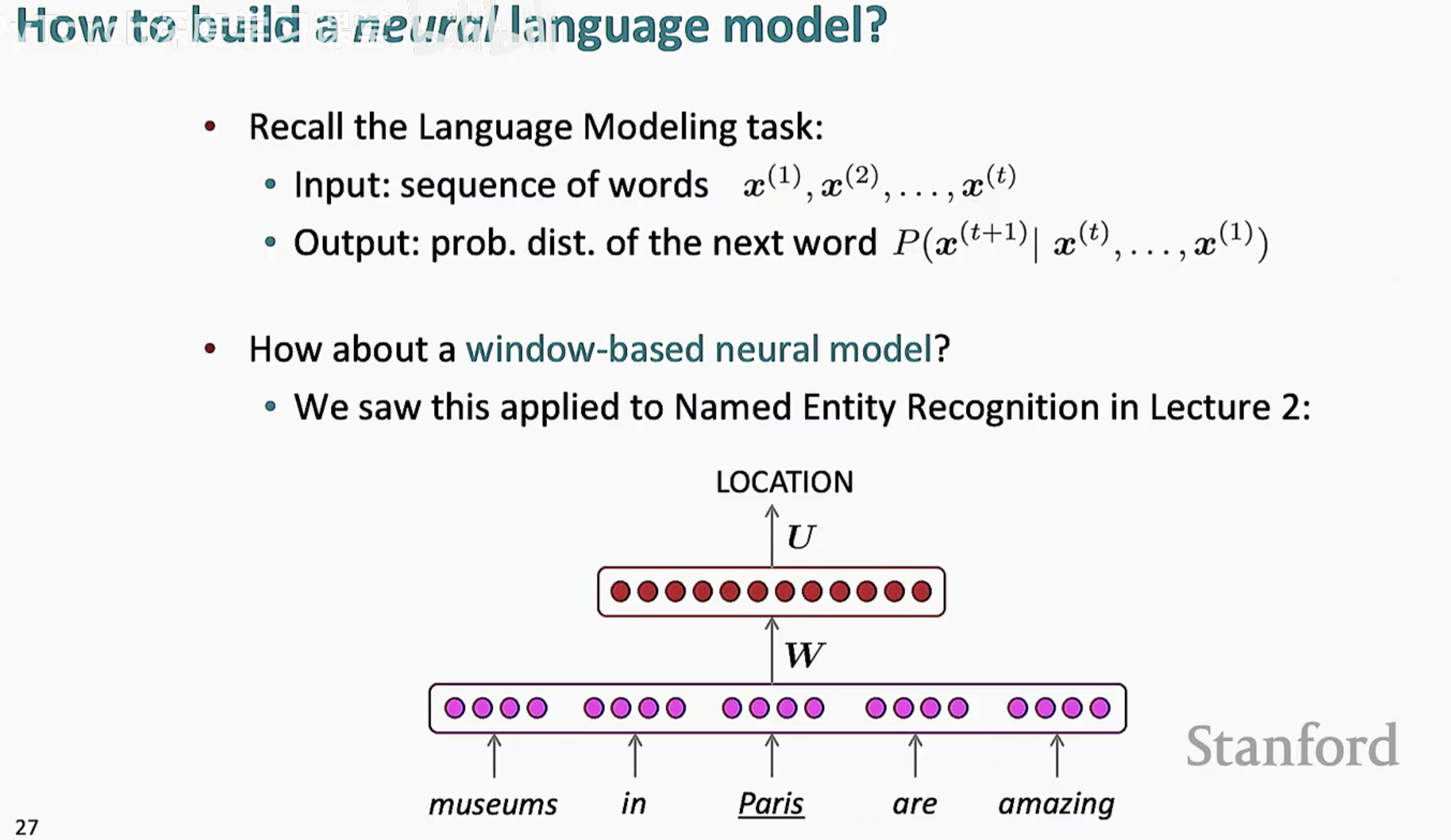
第二节:固定窗口模型的核心架构
为了克服传统 n-gram 模型的局限性,Bengio 等人在 2003 年提出了固定窗口神经语言模型(Fixed-window Neural Language Model)。这种模型不再依赖于简单的频率计数,而是通过神经网络学习词与词之间的特征关联。
整个模型的计算过程可以分为以下四个核心步骤:
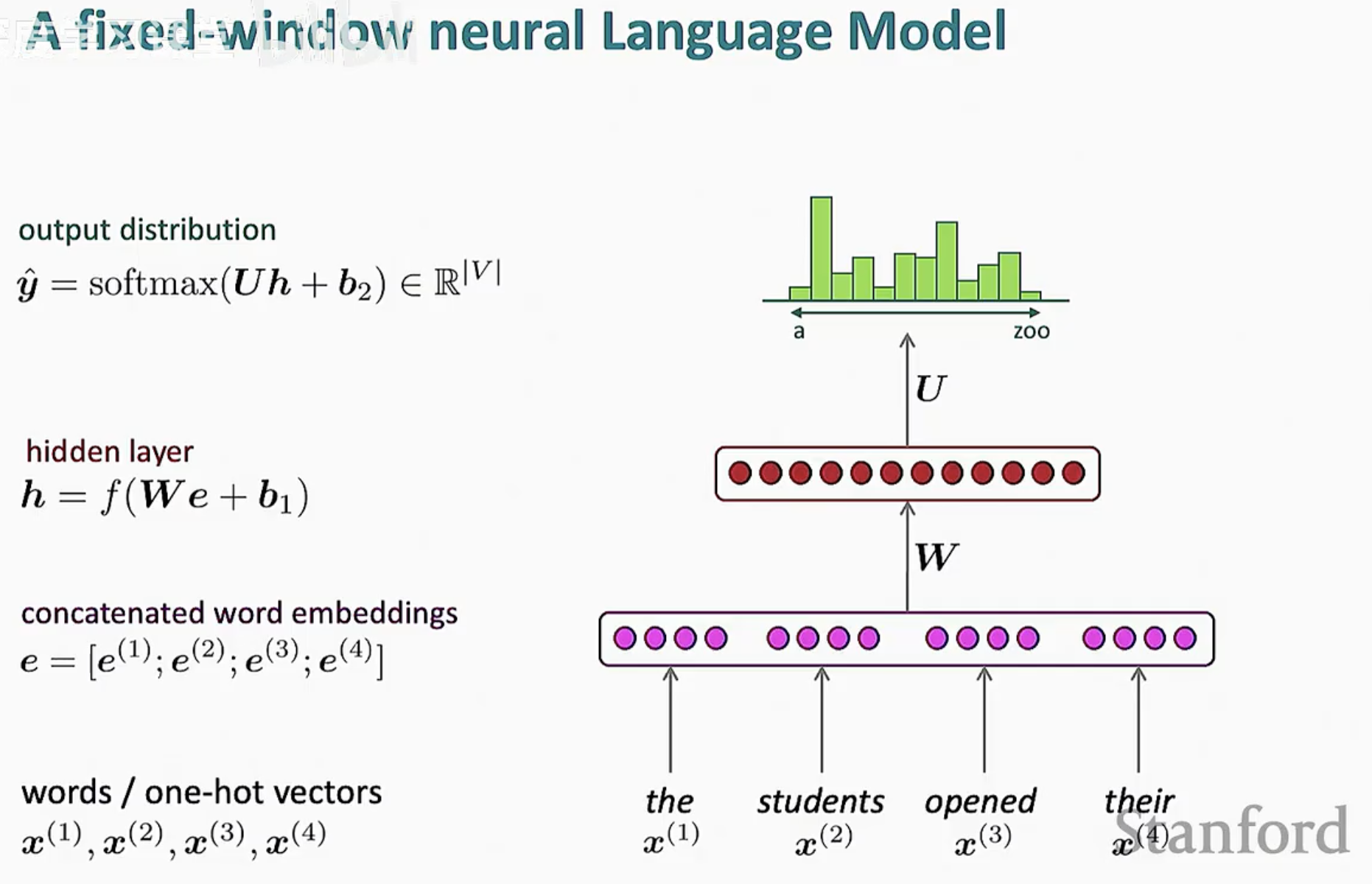
1. 输入层:从单词到词向量 (Words to Embeddings)
首先,我们将窗口内的每个单词 x(t) 表示为一个 one-hot 向量。随后,通过查表操作将其转换为稠密的低维词向量(Word Embeddings)。在下图中,我们选取了长度为 4 的窗口(包含 "the", "students", "opened", "their")。
2. 拼接机制 (Concatenation)
我们将这 4 个词向量按顺序拼接在一起,形成一个巨大的输入向量 e:
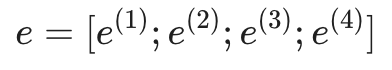
如果每个词向量的维度是 d,那么 e 的维度就是 4d。这就是模型获取上下文信息的方式。
3. 隐藏层计算 (Hidden Layer)
拼接后的向量 e 会通过一个线性层(乘以权重矩阵 W 并加上偏置 b1),然后应用非线性激活函数 f(通常是 tanh 或 ReLU)得到隐藏层状态 h:
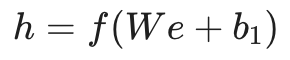
这一步负责提取上下文中的高阶语义特征。
4. 输出层与 Softmax (Output Distribution)
最后,隐藏层 h 通过另一个权重矩阵 U 被映射回词汇表的大小 |V|。通过应用 Softmax 函数,我们将输出转换为一个概率分布 ^y,表示词汇表中每个词作为下一个词出现的概率:
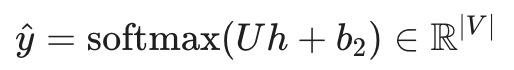
第三节:范式转移:对比传统 n-gram 模型
将语言模型从基于统计的 n-gram 转向神经网络,是自然语言处理史上的一个里程碑。这一转变不仅是算法的更迭,更是对语言建模本质理解的升华。
1. 核心改进 (Improvements)
相比于传统的 n-gram 模型,固定窗口神经模型带来了两个革命性的优势:
-
解决稀疏性问题 (No sparsity problem): 传统的 n-gram 极度依赖单词在语料库中的精确出现频率。如果某个词组从未出现过,概率就是零。而神经模型将单词映射到连续的向量空间,即使是模型从未见过的短语,只要单词在语义上与已知词接近,模型就能通过计算得出合理的概率预测。
-
存储开销优化: n-gram 需要存储所有观察到的 n 元组及其计数,随着 n 的增大,存储量呈指数级爆炸。而神经模型只需存储权重矩阵(如 W 和 U)以及词向量,参数量相对固定且高效。
第四节:局限性分析
尽管固定窗口神经语言模型相比 n-gram 有了质的飞跃,但它在设计上存在一些"硬伤",这些问题直接催生了后来的循环神经网络(RNN)。
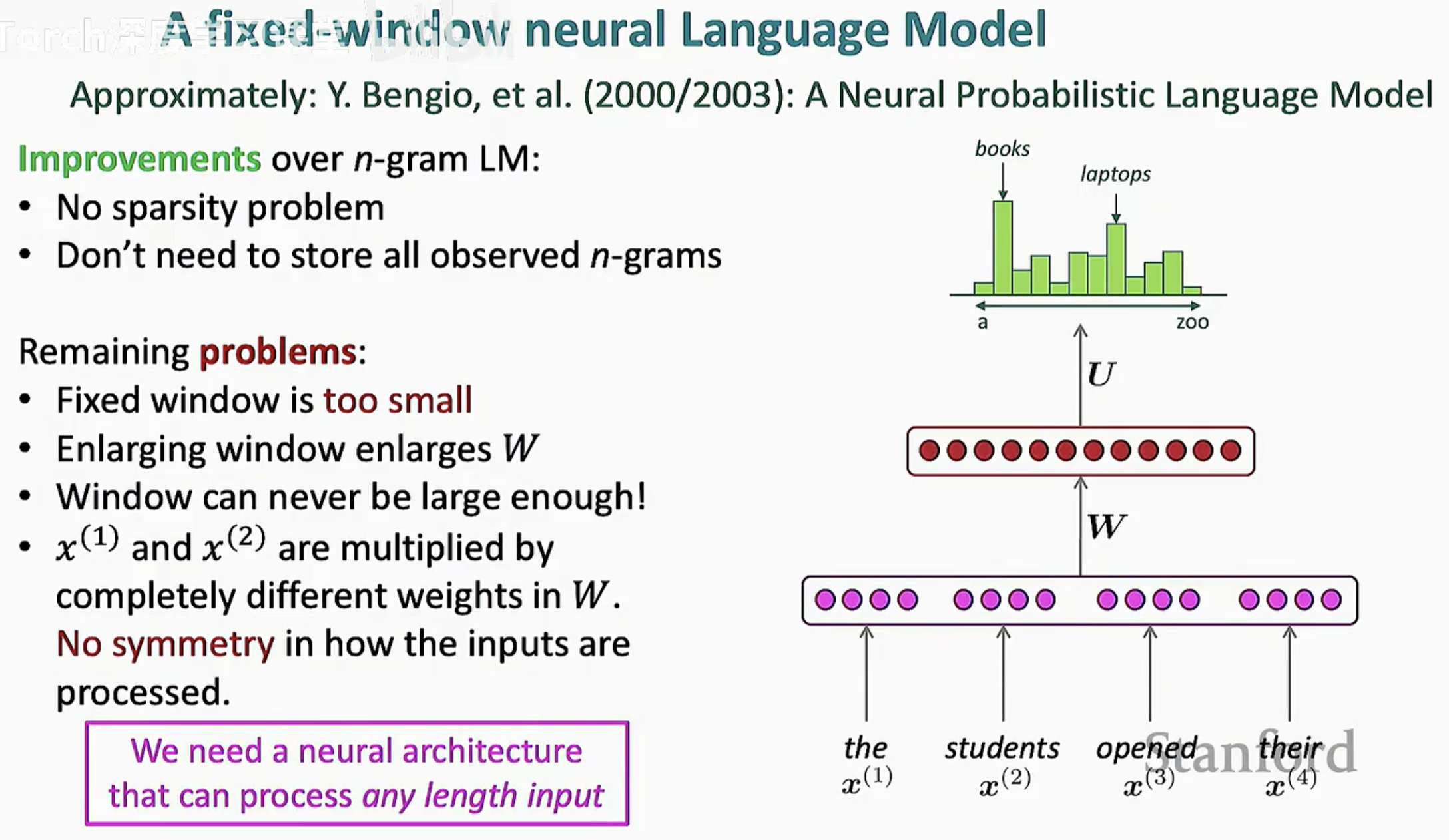
1. 剩余的挑战 (Remaining Problems)
-
固定窗口的局限性: 模型只能看到预设长度的上下文(如前 4 个词)。如果预测下一个词需要依赖更远的信息(比如一段话开头的名词决定了结尾的动词形式),固定窗口模型就会"顾此失彼"。
-
权重不均衡与对称性缺失: 在输入层,位置 1 的词和位置 2 的词是乘以权重矩阵 W 中完全不同的部分。这意味着模型无法学习到"无论单词出现在窗口的哪个位置,其语法功能是一致的"这一语言规律。
-
窗口大小与计算成本: 如果你想增加上下文长度,权重矩阵 W 就会成比例地增大,这使得模型难以扩展到超长文本。
-
这是我在我的网站中截取的文章,有更多的文章欢迎来访问我自己的博客网站rn.berlinlian.cn,这里还有很多有关计算机的知识,欢迎进行留言或者来我的网站进行留言!!!
作者正在学习斯坦福大学的CS224N课程。此文章的图片均来自该课程视频,之后会继续更新斯坦福大学CS224N课程,以及加上补充的知识,让我们一起探讨NLP的世界!!