摘要 :本文系统介绍 Transformer 中的 Decoder 模块:首先区分完整 Encoder+Decoder 与 Decoder-Only 两种架构的适用场景(前者适合机器翻译、摘要等强依赖源序列的 Seq2Seq 任务,后者适合续写、对话、语言模型等自回归生成);接着说明 Encoder+Decoder 结构中 Decoder 的组成(滞后标签输入、掩码自注意力、编码器-解码器交叉注意力等),以及 Encoder 与 Decoder 序列长度不一致时交叉注意力如何自然兼容;重点讲解 Teacher Forcing (训练时用真实上一词作输入、测试时用上一步预测作输入)与 shift right、SOS/EOS 标记的使用;最后阐明训练阶段如何通过因果掩码实现序列维度上的并行计算,而验证/测试阶段在时间步上必须串行解码的原因。
关键词:Transformer Decoder;Encoder-Decoder;Decoder-Only;序列到序列(Seq2Seq);Teacher Forcing;掩码自注意力(Causal Mask);编码器-解码器注意力(Cross-Attention);shift right;SOS/EOS;并行训练与串行推理
Decoder 是 Transformer 中至关重要的一环:它专门负责根据已有信息一步步生成输出序列 ,同时其用法非常灵活------既可以与 Encoder 搭档完成「先理解、再转译」的任务,也可以单独作为 Decoder-Only 模型做续写与生成。在之前的 Encoder 部分我们已介绍了 Encoder-Only 的典型场景;本文聚焦 Decoder 何时与 Encoder 搭档、何时单独使用,以及 Encoder+Decoder 结构中 Decoder 的内部机制(含 Teacher Forcing 与并行计算)。
首先回答一个核心问题:什么时候该用 Encoder+Decoder,什么时候更适合 Decoder-Only?
1 使用完整 Transformer 结构的任务
1.1 什么是「完整 Transformer」和「序列到序列」?
完整 Transformer 结构 指的是同时包含 Encoder(编码器) 和 Decoder(解码器) 的架构:Encoder 负责「理解」输入(例如源语言句子、长文章、图像特征等),Decoder 负责根据这份理解一步步生成输出序列(例如目标语言句子、摘要、字幕、答案等)。
序列到序列(Seq2Seq)的意思是:模型的输入是一个序列 (一串 token,如一句英文),输出是另一个序列(另一串 token,如一句中文)。两个序列长度和内容都可以不同。因此这类任务也叫「序列到序列」:从序列 A 映射到序列 B。完整 Transformer 正是为这类「先理解、再按步生成」的任务设计的------Encoder 把输入编码成内部表示,Decoder 结合该表示自回归地生成输出。
💡 理解要点:需要「先看完输入,再生成一段新内容」的任务,通常用 Encoder+Decoder;输入和输出都是「一串符号」(序列),所以叫序列到序列(Seq2Seq)。
下面几类任务都属于这一类,各举一个具体例子帮助理解。
1.2 机器翻译(Machine Translation)
含义:把一种语言的句子自动翻译成另一种语言。
具体例子:
- 输入(源序列):「I love natural language processing.」
- 输出(目标序列):「我喜欢自然语言处理。」
- Encoder 编码英文句子的语义,Decoder 根据该语义逐词生成中文。
1.3 文本摘要(Text Summarization)
含义:把较长文本压缩成短摘要或标题,保留核心信息。
具体例子:
- 输入(长文):一篇 2000 字的新闻(如「某市今日举行科技创新大会,市长出席并发表讲话......」)。
- 输出(摘要):一两句话的摘要,如「某市举行科技创新大会,市长强调加大研发投入。」
- Encoder 编码整篇文章,Decoder 生成缩短后的摘要序列。
1.4 图像字幕生成(Image Captioning)
含义:给一张图片生成一句或几句描述性文字(图生文)。图像会先通过视觉 Encoder(如 CNN 或 ViT)变成序列形式的特征,再交给 Transformer 的 Decoder 生成文字。
具体例子:
- 输入:一张照片(如一只猫在沙发上睡觉)。
- 输出(字幕):「A cat is sleeping on the sofa.」或「一只猫在沙发上睡觉。」
- 视觉 Encoder 提取图像特征,Decoder 根据这些特征逐词生成描述。
1.5 文本到语音(Text-to-Speech, TTS)
含义:输入是文本序列,输出是语音信号(可理解为「声学特征」或波形的序列)。很多现代 TTS 模型用 Encoder 编码文本,Decoder 生成梅尔谱或波形等序列。
具体例子:
- 输入:「今天天气真好。」
- 输出:对应的语音波形或声学特征序列,播放后是人声朗读「今天天气真好」。
- Encoder 编码文字及其韵律信息,Decoder 生成与之一一对应的语音序列。
1.6 问答系统(Question Answering)
含义 :给定一段上下文 (如一篇文档、一段对话)和一个问题 ,模型生成答案。上下文+问题一起作为「输入序列」被 Encoder 理解,Decoder 生成答案序列。
具体例子:
- 输入:上下文 = 「Transformer 由 Vaswani 等人于 2017 年提出,采用自注意力机制......」;问题 = 「Transformer 是哪一年提出的?」
- 输出:「2017 年。」(或「2017」)
- Encoder 编码「上下文+问题」,Decoder 只生成答案这一短序列。
2 使用 Decoder-Only 结构的任务
2.1 什么是 Decoder-Only?为什么不用 Encoder?
Decoder-Only 指的是只保留 Transformer 的解码器部分 ,不用独立的编码器。输入和输出在形式上往往是同一段序列 :模型看到的是「已有的一串 token」(如前半句话、对话历史、上下文+问题),然后自回归地 (一个词一个词地)往后生成,相当于「续写」。因此这类模型常被称为自回归模型 或生成模型。
和「完整 Encoder+Decoder」的区别可以简单理解为:
- Encoder+Decoder :先由 Encoder 完整理解 输入(如整句英文),再由 Decoder 根据这份理解生成另一个序列(如中文)。强调「先理解、再转译」,对源信息依赖高。
- Decoder-Only :没有单独的 Encoder,输入和生成都在同一个序列里。模型只根据「已经写出来的部分」预测下一个词,不断续写。更适合「续写、创造、自由生成」,对「严格按源句转译」的依赖较低。
💡 理解要点:Decoder-Only 像是「只拿一支笔续写」------看到前面的内容就接着写下去;Encoder+Decoder 像是「先通读原文,再另起一页翻译或总结」。前者适合续写、对话、自由生成;后者适合翻译、摘要等强依赖源序列的转换。
下面几类任务常用 Decoder-Only 实现,各举一个具体例子。
2.2 大语言模型 / 下一个词预测(Language Modeling)
含义:给定前面已有的文本,预测**下一个词(或 token)**是什么。大语言模型(如 GPT 系列)的核心训练目标就是这种「下一个词预测」;推理时则反复用「已生成内容 + 新预测的一个词」作为新输入,继续预测再下一个词,从而生成整段文本。
具体例子:
- 输入:「人工智能正在改变」
- 输出(下一个词):模型预测最可能的是「世界」「我们」「生活」等;若选「世界」,则下一轮输入变为「人工智能正在改变世界」,再预测下一个词,如此往复得到整句或整段。
2.3 文本生成(Text Generation)
含义 :给一个开头或提示,让模型续写成完整段落、文章或诗歌,强调「创造性续写」而不是逐字翻译。
具体例子:
- 输入(开头):「那年夏天,我第一次见到她。」
- 输出(续写):模型接着生成「她站在教室门口,阳光从身后打过来......」整段故事。
- 或输入半句诗「春江潮水连海平,」→ 模型续写「海上明月共潮生」等后续诗句。
2.4 代码补全(Code Completion)
含义:根据已经写出的代码(或注释),预测后面应该出现的代码片段,在 IDE 里常以「补全建议」形式出现。
具体例子:
- 输入 :
def read_file(path):加换行后光标在下一行。 - 输出(补全) :模型建议
with open(path, 'r') as f:或return open(path).read()等后续代码,用户可选择一个接受。
2.5 对话生成(Dialogue Generation)
含义 :给定对话历史 (多轮用户与系统的对话),模型生成下一句回复。用户和机器的发言都拼成一条长序列,模型在序列末尾「续写」下一条回复。
具体例子:
- 输入:用户:「有没有推荐的中餐馆?」 助手:「有的,附近有一家川菜馆评分很高。」 用户:「人均大概多少?」
- 输出:模型生成助手的下一句,如「人均大约 80 元左右,需要我帮你订位吗?」
2.6 问答(Decoder-Only 做法)
含义 :在 Decoder-Only 里,问答通常把「上下文(或文档)+ 问题」全部拼成一条输入序列 ,模型像「续写」一样逐词生成答案,而不是先经过独立 Encoder 再解码。例如 GPT 风格的「给一段文章 + 问题,直接生成答案」。
具体例子:
- 输入 :
文章:Transformer 由 Vaswani 等人于 2017 年提出...... 问题:Transformer 是哪一年提出的? 答案: - 输出:模型在「答案:」后面续写,如「2017 年。」与前面 Encoder+Decoder 的问答不同,这里没有单独的「编码器」把文章和问题编码,而是整段一起当上下文,由 Decoder 自回归生成答案。
2.7 Encoder+Decoder 与 Decoder-Only 如何选?
两类结构对应不同需求:
- 完整 Transformer(Encoder+Decoder)适合从一个序列转换到另一个序列 、且高度依赖源数据语义的任务(如翻译、摘要):Encoder 专门负责理解和压缩源信息,Decoder 在此基础上做「转译」。
- Decoder-Only 适合在已有内容基础上续写、创造、自由生成的任务(如对话、故事、代码补全):更强调「接着写下去」,对「严格逐句转译源序列」的依赖较低。
一句话:需要强依赖原文的转译 时倾向 Encoder+Decoder;需要续写、创造、生成时倾向 Decoder-Only。
🔍 选型参考:做机器翻译、文档摘要、图像描述等「有明确源输入且需忠实转译」的任务,优先考虑 Encoder+Decoder(如 T5、BART);做通用对话、代码补全、开放生成等「续写式」任务,多用 Decoder-Only(如 GPT、LLaMA)。
3 Encoder+Decoder 结构中的 Decoder
在明确「何时用 Encoder+Decoder」之后,本节说明在这种结构里 Decoder 长什么样、由哪些模块组成,以便理解后续的 Teacher Forcing 与并行计算。
3.1 Decoder 涉及的模块简介
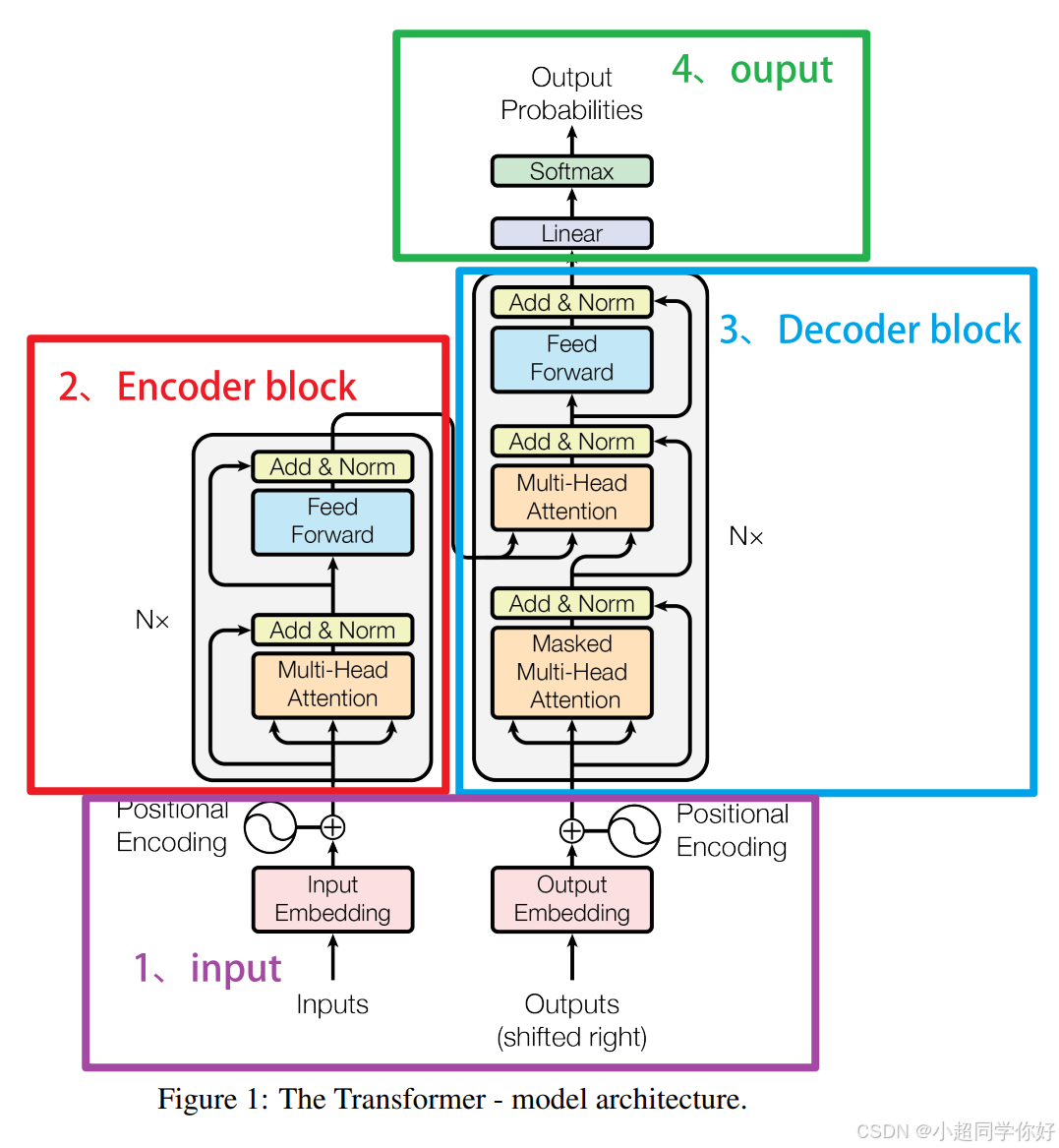
从结构图可以看出,Encoder 与 Decoder 在整体形态上很相似,但 Decoder 多出了「掩码」和「看 Encoder」的机制。整个 Decoder 包含以下核心部分:
-
输入与 Teacher Forcing 机制
Decoder 的输入是滞后 1 个时间步的标签序列 (shifted right),即用「真实已出现的词」作为输入,让模型在正确上文下预测下一个词,这种用标准答案作为输入的训练方式称为 Teacher Forcing(强制教学)。后文会详细展开。
-
Embedding 与位置编码
标签序列先经嵌入层得到向量,再与 Encoder 一样加上位置编码。注意:Decoder 的序列长度可以与 Encoder 的序列长度不同(例如源句 7 个词、目标句 6 个词),这一点由交叉注意力自然支持。
-
带掩码的自注意力层 (Masked Self-Attention)
为什么需要掩码? 推理时我们是一个词一个词生成的,当前词不可能已经知道后面的词;若训练时让模型看到「未来词」,就会造成信息泄露,与真实推理不一致。因此 Decoder 在 softmax 前对「未来位置」的注意力分数做掩码(通常置为负无穷),使位置 iii 只能依赖 0∼i0\sim i0∼i,与自回归生成逻辑一致。
-
编码器-解码器注意力层 (Encoder-Decoder Attention / Cross-Attention)
这是 Decoder 独有的层:Q 来自 Decoder 当前表示,K、V 来自 Encoder 输出。这样 Decoder 的每个位置都可以「查阅」整个源序列,从而利用源端信息生成目标词。
-
前馈神经网络、层归一化与残差连接
与 Encoder 一致:每个 Decoder 层包含前馈网络(通常为两层线性变换 + 中间 ReLU/GELU)、层归一化与残差连接。
3.2 Encoder 与 Decoder 的序列长度(Seq_len)不一致怎么办?
源句与目标句长度往往不同(例如中文 7 个词、英文 6 个词),因此 Encoder 输出与 Decoder 输入的序列长度 (LencL_{\text{enc}}Lenc 与 LdecL_{\text{dec}}Ldec)大多不一致。例如:
|------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| 输入Encoder 特征矩阵 | | x1 | x2 | x3 | x4 | x5 | |-----|--------|--------|--------|--------|--------| | 这 | 0.1821 | 0.4000 | 0.2248 | 0.4440 | 0.7771 | | 是 | 0.1721 | 0.5030 | 0.8948 | 0.2385 | 0.0987 | | 最好的 | 0.1342 | 0.8297 | 0.2978 | 0.7120 | 0.2565 | | 时代 | 0.1248 | 0.5003 | 0.7559 | 0.4804 | 0.2593 | | 也 | 0.1032 | 0.1477 | 0.7023 | 0.7224 | 0.2768 | | 是 | 0.1721 | 0.5030 | 0.8948 | 0.2385 | 0.0987 | | 最坏的 | 0.4263 | 0.4615 | 0.5169 | 0.7584 | 0.8388 | | 时代 | 0.1248 | 0.5003 | 0.7559 | 0.4804 | 0.2593 | | 输入Decoder 标签矩阵 | | y1 | y2 | y3 | y4 | y5 | |-------|--------|--------|--------|--------|--------| | It | 0.5621 | 0.8920 | 0.7312 | 0.2543 | 0.1289 | | was | 0.2314 | 0.6794 | 0.9823 | 0.8452 | 0.3417 | | the | 0.4932 | 0.2045 | 0.7531 | 0.6582 | 0.9731 | | best | 0.8342 | 0.2987 | 0.7642 | 0.2154 | 0.9812 | | of | 0.3417 | 0.5792 | 0.4821 | 0.6721 | 0.1234 | | times | 0.2531 | 0.7345 | 0.9812 | 0.5487 | 0.2378 | | it | 0.6523 | 0.1298 | 0.4576 | 0.9834 | 0.1876 | | was | 0.2314 | 0.6794 | 0.9823 | 0.8452 | 0.3417 | | the | 0.4932 | 0.2045 | 0.7531 | 0.6582 | 0.9731 | | worst | 0.1543 | 0.9271 | 0.3821 | 0.6745 | 0.4823 | | of | 0.3417 | 0.5792 | 0.4821 | 0.6721 | 0.1234 | | times | 0.2531 | 0.7345 | 0.9812 | 0.5487 | 0.2378 | |
我们通过 Transformer 的架构,可以看到:
Encoder 模块的输入比如是**Lenc×dmodelL_{\text{enc}} \times d_{\text{model}}Lenc×dmodel** 的矩阵(LencL_{\text{enc}}Lenc = encoder的源序列长度,dmodeld_{\text{model}}dmodel = 模型维度),经过了中间的多头注意力机制层,前馈神经网络层后,最终输出的依然是一张形状为 Lenc×dmodelL_{\text{enc}} \times d_{\text{model}}Lenc×dmodel 的矩阵。送入 Decoder 的交叉注意力时,这份矩阵会分别乘以 WKW_KWK、WVW_VWV 得到 K 和 V ,二者形状均为 Lenc×dmodelL_{\text{enc}} \times d_{\text{model}}Lenc×dmodel (若 dk=dv=dmodeld_k=d_v=d_{\text{model}}dk=dv=dmodel)。例如源序列 1300 个 token、dmodel=12288d_{\text{model}}=12288dmodel=12288 时,Encoder 输出为 1300×12288,得到的 K、V 也各为 1300×12288。
那么问题就来了,如果 Decoder 模块的输入是 Ldec×dmodelL_{\text{dec}} \times d_{\text{model}}Ldec×dmodel 的矩阵(LdecL_{\text{dec}}Ldec = decoder 的目标序列长度,dmodeld_{\text{model}}dmodel = 模型维度),经过带掩码的多头自注意力层后,输出的依然是 Ldec×dmodelL_{\text{dec}} \times d_{\text{model}}Ldec×dmodel 的矩阵。这份矩阵再经过一个线性层得到 Q ,形状为 Ldec×dkL_{\text{dec}} \times d_kLdec×dk ;而来自 Encoder 的 K 、V 形状为 Lenc×dkL_{\text{enc}} \times d_kLenc×dk 、Lenc×dvL_{\text{enc}} \times d_vLenc×dv 。从「序列长度」这一维来看,Q 有 LdecL_{\text{dec}}Ldec 行,K、V 有 LencL_{\text{enc}}Lenc 行,二者确实不一致。
那么,Transformer 模型具体是怎么处理这个问题的?
答案:不需要做任何特殊处理,交叉注意力的设计本身就允许 Lenc≠LdecL_{\text{enc}} \neq L_{\text{dec}}Lenc=Ldec。
在交叉注意力(Cross-Attention)里,计算的是「Decoder 的每个位置」对「Encoder 所有位置」的注意力:
- Q 来自 Decoder 当前表示,形状为 (Ldec,dk)(L_{\text{dec}}, d_k)(Ldec,dk)(每行是目标序列一个位置的查询向量)。
- K 、V 来自 Encoder 输出,形状为 (Lenc,dk)(L_{\text{enc}}, d_k)(Lenc,dk) 、(Lenc,dv)(L_{\text{enc}}, d_v)(Lenc,dv)(每行是源序列一个位置的键/值向量)。
注意力分数的计算为 Attention(Q,K,V)=softmax(QK⊤dk)V\text{Attention}(Q,K,V) = \text{softmax}\big(\frac{Q K^\top}{\sqrt{d_k}}\big) VAttention(Q,K,V)=softmax(dk QK⊤)V:
- QK⊤Q K^\topQK⊤ 的维度是 (Ldec,dk)×(dk,Lenc)=(Ldec,Lenc)(L_{\text{dec}}, d_k) \times (d_k, L_{\text{enc}}) = (L_{\text{dec}}, L_{\text{enc}})(Ldec,dk)×(dk,Lenc)=(Ldec,Lenc),即「每个目标位置对每个源位置的相似度」。
- 再与 V 相乘:(Ldec,Lenc)×(Lenc,dv)=(Ldec,dv)(L_{\text{dec}}, L_{\text{enc}}) \times (L_{\text{enc}}, d_v) = (L_{\text{dec}}, d_v)(Ldec,Lenc)×(Lenc,dv)=(Ldec,dv)。
因此,交叉注意力的输出 形状为 Ldec×dmodelL_{\text{dec}} \times d_{\text{model}}Ldec×dmodel :目标序列的每个位置都得到一个融合了「整个源序列」信息的向量。必须一致的是特征维度 dkd_kdk、dvd_vdv(通常都等于 dmodeld_{\text{model}}dmodel) ,而 LencL_{\text{enc}}Lenc 和 LdecL_{\text{dec}}Ldec 可以不同,这正是序列到序列任务中源句与目标句长度不一致时所需要的。
💡 理解要点 :想象你在写翻译------你写的每一句(Decoder 的每个位置)都可以回头翻看整篇原文(Encoder 的全部输出);原文有多少句、译文有多少句本来就可以不同。交叉注意力做的就是这样的事:只要求特征维度一致,序列长度不必相同。
3.3 Teacher Forcing
3.3.1 shift right 操作
Decoder 的输入是滞后 1 个时间步的标签序列 (shifted right):用「真实已经出现的词」作为输入,让模型在正确上文下预测下一个词,这种用标准答案当输入的训练方式就是 Teacher Forcing(强制教学)。下面先说明「为什么需要 shift」,再说明训练与推理时分别怎么做。
shift right 操作
首先,在序列到序列任务中,我们会将标签矩阵进行滞后操作(shift)。
比如,原来标签的序列是:[1, 2, 3, 4, 5],我们对这个序列向未来、向正向顺序的方向挪动位置一个,那么这个序列就变成了:[NaN, 1, 2, 3, 4]。
当表现为编码前的序列时,就是从[y1, y2, y3, y4]变成[NaN, y1, y2, y3, y4],因此这个过程也被叫做"向右滞后"(shift right),其实代表的是在序列的最前方腾挪出位置,将已有的序列向后挤。
在Transformer当中,我们一般会为解码器的输入标签添加起始标记"SOS"(start of sequence),并将这个起始标记作为标签序列的第一行,最终构成["sos", y1, y2, y3, y4]这样的序列。当进行embedding编码后,会呈现为👇
|----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| 输入Decoder 标签矩阵 | 索引 | | y1 | y2 | y3 | y4 | y5 | |----|-------|--------|--------|--------|--------|--------| | 0 | "sos" | 0.5651 | 0.2220 | 0.5112 | 0.8543 | 0.1239 | | 1 | It | 0.5621 | 0.8920 | 0.7312 | 0.2543 | 0.1289 | | 2 | was | 0.2314 | 0.6794 | 0.9823 | 0.8452 | 0.3417 | | 3 | the | 0.4932 | 0.2045 | 0.7531 | 0.6582 | 0.9731 | | 4 | best | 0.8342 | 0.2987 | 0.7642 | 0.2154 | 0.9812 | | 5 | of | 0.3417 | 0.5792 | 0.4821 | 0.6721 | 0.1234 | | 6 | times | 0.2531 | 0.7345 | 0.9812 | 0.5487 | 0.2378 | | 7 | it | 0.6523 | 0.1298 | 0.4576 | 0.9834 | 0.1876 | | 8 | was | 0.2314 | 0.6794 | 0.9823 | 0.8452 | 0.3417 | | 9 | the | 0.4932 | 0.2045 | 0.7531 | 0.6582 | 0.9731 | | 10 | worst | 0.1543 | 0.9271 | 0.3821 | 0.6745 | 0.4823 | | 11 | of | 0.3417 | 0.5792 | 0.4821 | 0.6721 | 0.1234 | | 12 | times | 0.2531 | 0.7345 | 0.9812 | 0.5487 | 0.2378 | |
起始标记(Start of Sequence,SOS)和结束标记(End of Sequence,EOS)在序列到序列(Seq2Seq)任务中起着重要的作用,特别是在自然语言处理(NLP)和机器翻译等任务中。
- 起始标记(SOS)的意义
标识序列的开始 :SOS标记用于指示解码器开始生成序列。这在训练和推理过程中都非常重要。
初始化解码器 :在解码阶段,解码器需要一个初始输入来开始生成输出序列。SOS标记作为解码器的第一个输入,帮助其启动生成过程。
模型一致性:通过在每个输出序列的开头添加SOS标记,模型在训练时可以学到序列生成的起点,从而在推理时保持一致的生成过程。
- 结束标记(EOS)的意义
标识序列的结束 :EOS标记用于指示生成的序列在何处结束。这对于模型在推理阶段停止生成非常重要。
控制生成长度 :在没有固定长度的输出序列中,EOS标记告诉模型何时停止生成,而不需要生成固定数量的时间步。这使得模型可以处理变长序列。
训练终止条件:在训练过程中,模型学会在适当的时候生成EOS标记,从而正确地结束序列。
假设我们有一个输入序列和一个目标序列:
- 输入序列:
y = ["这", "是", "最", "好", "的", "时", "代"] - 目标序列:
y = ["it", "was", "the", "best", "of", "times"]
在 Seq2Seq 任务训练时,Decoder 需要「已出现的目标词」作为输入,因此要准备三份数据并做如下区分:
- 编码器输入 :源序列(如中文句子)不需要添加 SOS/EOS。
- 解码器输入 :在目标序列前添加起始标记(SOS),供模型作为「上一个词」使用。
- 计算损失用的目标标签 :在目标序列末添加结束标记(EOS),用于监督模型学会何时停止生成。
处理后的序列就是:
- 编码器输入 :
["这", "是", "最", "好", "的", "时", "代"] - 解码器输入的标签 :
["SOS", "it", "was", "the", "best", "of", "times"] - 解码器用来计算损失函数的标签 :
["it", "was", "the", "best", "of", "times", "EOS"]
以下是一个简化的示例代码,展示如何使用PyTorch为序列添加起始标记和结束标记,并进行词嵌入:
py
import torch
import torch.nn as nn
# 假设词汇表大小(包括特殊标记如SOS和EOS)
vocab_size = 10
embedding_dim = 4
# 创建嵌入层
embedding_layer = nn.Embedding(vocab_size, embedding_dim)
# 假设索引0是SOS,索引1是EOS
SOS_token = 0
EOS_token = 1
# 目标序列的索引表示
target_sequence = [2, 3, 4, 5, 6] # 假设 "it", "was", "the", "best", "of"
# 添加起始标记和结束标记
decoder_input = [SOS_token] + target_sequence
decoder_output = target_sequence + [EOS_token]
# 转换为张量
decoder_input_tensor = torch.tensor(decoder_input)
decoder_output_tensor = torch.tensor(decoder_output)
# 嵌入
embedded_decoder_input = embedding_layer(decoder_input_tensor)
embedded_decoder_output = embedding_layer(decoder_output_tensor)
print("Decoder Input (with SOS):", decoder_input_tensor)
print("Decoder Output (with EOS):", decoder_output_tensor)
print("Embedded Decoder Input:", embedded_decoder_input)
print("Embedded Decoder Output:", embedded_decoder_output)打印:
Decoder Input (with SOS): tensor([0, 2, 3, 4, 5, 6])
Decoder Output (with EOS): tensor([2, 3, 4, 5, 6, 1])
Embedded Decoder Input: tensor([[-0.0425, 0.2930, -0.3895, -1.6590],
[-0.9277, -0.1985, 1.6883, 1.5838],
[-0.6614, 1.6603, 0.2338, 0.3172],
[-1.4791, -0.4578, -0.9611, 0.2102],
[ 0.9115, 0.9477, 0.6285, -1.0261],
[ 0.2483, 0.5679, -1.3950, 0.9890]], grad_fn=<EmbeddingBackward0>)
Embedded Decoder Output: tensor([[-0.9277, -0.1985, 1.6883, 1.5838],
[-0.6614, 1.6603, 0.2338, 0.3172],
[-1.4791, -0.4578, -0.9611, 0.2102],
[ 0.9115, 0.9477, 0.6285, -1.0261],
[ 0.2483, 0.5679, -1.3950, 0.9890],
[ 0.1113, -1.1856, 1.8317, -1.3278]], grad_fn=<EmbeddingBackward0>)3.3.2 训练过程
用一句话说清 Teacher Forcing :训练时,Decoder 在预测「下一个词」时,输入用的是标准答案里已经写好的「上一个词」,而不是模型自己刚才预测出来的词。也就是说,每一步都在「正确的上文」上学习,避免一步错、步步错,训练更稳定。
🔍 实际类比:就像学生做翻译练习时,老师每次提供的「上一句」都是参考答案而不是学生自己写的那句------这样即使某一句还没练熟,下一句也不会在错误基础上越错越远。Transformer 训练用的就是这种「用标准上文带路」的方式。
举一个翻译例子:源句「这是最好的时代」→ 目标句「It was the best of times」。训练时 Decoder 每一步的输入与要预测的对象是:
| 这一步要预测的是 | Teacher Forcing 下,Decoder 的输入(上一词) |
|---|---|
| It | SOS(起始符,没有「上一个词」) |
| was | It(标准答案里的词) |
| the | was |
| best | the |
| of | best |
| times | of |
也就是说,预测 "was" 时,模型看到的是标准答案里的 "It",而不是「如果不用 Teacher Forcing、模型上一步可能预测错的 It/This/That...」。这样即使模型某一步还没学好,也不会因为「上一步预测错了」导致后面整句都在错误上文上训练。
如果你做过时间序列预测,可以类比「带标签的滑窗」:把已经知道的真实值(过去的时间点或过去的词)当作输入特征的一部分,和别的特征一起喂给模型。Transformer 里做的也是这件事,只不过从「同一序列的过去→未来」推广到了「源序列 + 目标序列里已出现的词 → 目标序列的下一个词」。
和时间序列的区别:时间序列通常是「用同一段序列的前半段预测后半段」;而 Seq2Seq(如机器翻译)是「用源语言句子 + 目标语言里已经生成的部分,预测目标语言的下一个词」。前者是同一序列的续写,后者是跨序列的转译,但二者在「训练时用真实前文当输入」这一点上是相通的。
注意,Teacher Forcing 指的是训练的过程! 在验证和测试过程中,我们并不会知道标准答案是什么。
针对上面的例子,我们再讲的细致一些。
原始序列(Encoder 输入)X = "这","是","最","好","的","时","代"
真实标签(用于算损失)y = "it", "was", "the", "best", "of", "times"
ebd_X = 原始序列 X 的 embedding;ebd_y = Decoder 输入序列(带 SOS)的 embedding;yhat = 模型对整个 Decoder 输入序列的预测输出。
约定澄清(下文中的下标均按此约定):
- ebd_y :Decoder 输入序列的嵌入 = SOS, It, was, the, ...。
- ebd_y0 = SOS,ebd_y1 = It,ebd_y2 = was,...
- y(算损失用的目标):y0=It, y1=was, y2=the, ...
- yhat :约定「第 0 行是 SOS、后面才是模型预测」
- yhat0 = SOS(固定,非模型预测)
- yhat1 = 对第一个词的预测(应对应 It)
- yhat2 = 对第二个词的预测(应对应 was)
- ...
我们实际走的训练流程是:
- 第一步,输入 ebd_X & ebd_y0(仅 SOS)>> 输出 yhat1,对应真实标签 y0(It)
|----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|------|----------------------------------------------------------------------------------------------------------------------------------------------|
| 输入Encoder 特征矩阵 | 索引 | | y1 | y2 | y3 | y4 | y5 | |----|-----|--------|--------|--------|--------|--------| | 0 | 这 | 0.1821 | 0.4000 | 0.2248 | 0.4440 | 0.7771 | | 1 | 是 | 0.1721 | 0.5030 | 0.8948 | 0.2385 | 0.0987 | | 2 | 最好的 | 0.1342 | 0.8297 | 0.2978 | 0.7120 | 0.2565 | | 3 | 时代 | 0.1248 | 0.5003 | 0.7559 | 0.4804 | 0.2593 | | 输入Decoder 标签矩阵 | 索引 | | y1 | y2 | y3 | y4 | y5 | |----|-------|--------|--------|--------|--------|--------| | 0 | "sos" | 0.5651 | 0.2220 | 0.5112 | 0.8543 | 0.1239 | | 1 | It | 0.5621 | 0.8920 | 0.7312 | 0.2543 | 0.1289 | | 2 | was | 0.2314 | 0.6794 | 0.9823 | 0.8452 | 0.3417 | | 3 | the | 0.4932 | 0.2045 | 0.7531 | 0.6582 | 0.9731 | | 4 | best | 0.8342 | 0.2987 | 0.7642 | 0.2154 | 0.9812 | | 5 | of | 0.3417 | 0.5792 | 0.4821 | 0.6721 | 0.1234 | | 6 | times | 0.2531 | 0.7345 | 0.9812 | 0.5487 | 0.2378 | | 对应 ➡ | 真实标签y | 索引 | | |----|-------| | 0 | It | | 1 | was | | 2 | the | | 3 | best | | 4 | of | | 5 | times | | 6 | "eos" | |
-
第二步,输入 ebd_X & ebd_y:2(真实标签 SOS, It)>> 输出 yhat2,对应真实标签 y1(was)
Teacher Forcing 要点 :这里 Decoder 的输入用的是 ebd_y:2(即真实序列 SOS, It 的嵌入),而不是上一步的预测 yhat1。无论第一步预测成了 "It" 还是别的词,第二步都只用真实标签 "It" 作为「上一个词」输入。
|----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|------|----------------------------------------------------------------------------------------------------------------------------------------------|
| 输入Encoder 特征矩阵 | 索引 | | y1 | y2 | y3 | y4 | y5 | |----|-----|--------|--------|--------|--------|--------| | 0 | 这 | 0.1821 | 0.4000 | 0.2248 | 0.4440 | 0.7771 | | 1 | 是 | 0.1721 | 0.5030 | 0.8948 | 0.2385 | 0.0987 | | 2 | 最好的 | 0.1342 | 0.8297 | 0.2978 | 0.7120 | 0.2565 | | 3 | 时代 | 0.1248 | 0.5003 | 0.7559 | 0.4804 | 0.2593 | | 输入Decoder 标签矩阵 | 索引 | | y1 | y2 | y3 | y4 | y5 | |----|-------|--------|--------|--------|--------|--------| | 0 | "sos" | 0.5651 | 0.2220 | 0.5112 | 0.8543 | 0.1239 | | 1 | It | 0.5621 | 0.8920 | 0.7312 | 0.2543 | 0.1289 | | 2 | was | 0.2314 | 0.6794 | 0.9823 | 0.8452 | 0.3417 | | 3 | the | 0.4932 | 0.2045 | 0.7531 | 0.6582 | 0.9731 | | 4 | best | 0.8342 | 0.2987 | 0.7642 | 0.2154 | 0.9812 | | 5 | of | 0.3417 | 0.5792 | 0.4821 | 0.6721 | 0.1234 | | 6 | times | 0.2531 | 0.7345 | 0.9812 | 0.5487 | 0.2378 | | 对应 ➡ | 真实标签y | 索引 | | |----|-------| | 0 | It | | 1 | was | | 2 | the | | 3 | best | | 4 | of | | 5 | times | | 6 | "eos" | |
- 第三步,输入 ebd_X & ebd_y:3(SOS, It, was)>> 输出 yhat3,对应真实标签 y2(the)
|----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|------|----------------------------------------------------------------------------------------------------------------------------------------------|
| 输入Encoder 特征矩阵 | 索引 | | y1 | y2 | y3 | y4 | y5 | |----|-----|--------|--------|--------|--------|--------| | 0 | 这 | 0.1821 | 0.4000 | 0.2248 | 0.4440 | 0.7771 | | 1 | 是 | 0.1721 | 0.5030 | 0.8948 | 0.2385 | 0.0987 | | 2 | 最好的 | 0.1342 | 0.8297 | 0.2978 | 0.7120 | 0.2565 | | 3 | 时代 | 0.1248 | 0.5003 | 0.7559 | 0.4804 | 0.2593 | | 输入Decoder 标签矩阵 | 索引 | | y1 | y2 | y3 | y4 | y5 | |----|-------|--------|--------|--------|--------|--------| | 0 | "sos" | 0.5651 | 0.2220 | 0.5112 | 0.8543 | 0.1239 | | 1 | It | 0.5621 | 0.8920 | 0.7312 | 0.2543 | 0.1289 | | 2 | was | 0.2314 | 0.6794 | 0.9823 | 0.8452 | 0.3417 | | 3 | the | 0.4932 | 0.2045 | 0.7531 | 0.6582 | 0.9731 | | 4 | best | 0.8342 | 0.2987 | 0.7642 | 0.2154 | 0.9812 | | 5 | of | 0.3417 | 0.5792 | 0.4821 | 0.6721 | 0.1234 | | 6 | times | 0.2531 | 0.7345 | 0.9812 | 0.5487 | 0.2378 | | 对应 ➡ | 真实标签y | 索引 | | |----|-------| | 0 | It | | 1 | was | | 2 | the | | 3 | best | | 4 | of | | 5 | times | | 6 | "eos" | |
以此类推。
不难发现,在这个流程中我们实现了【利用序列 A(源句)+ 序列 B 的前半段(已生成的目标词)预测序列 B 的后半段(下一个目标词)】,既没有泄露未来标签,又为预测提供了最准确的上文,这就是 Teacher Forcing 的本质。
💡 理解要点 :训练时我们有完整真实标签,因此不必真的按时间步一步一步跑 。Decoder 通过掩码自注意力 + 编码器-解码器注意力的配合,可以一次性接收整段 Decoder 输入、在一次前向传播中并行得到所有位置的预测,再与真实标签逐位算损失。训练效率因此远高于按步展开的 RNN。
然而在验证和测试阶段没有真实标签,流程就不同了。
3.3.3 验证和测试过程
在测试和推理的过程中,我们并没有真实的标签矩阵,因此需要将上一个时间步预测的结果作为Decoder需要的输入。
还是上面这个例子,在验证和测试过程中:
- 第一步,输入 ebd_X & sos >> 输出写到yhat1。注意,这里yhat0的值就是 sos。
|----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|---|-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| 输入Encoder 特征矩阵 | 索引 | | y1 | y2 | y3 | y4 | y5 | |----|-----|--------|--------|--------|--------|--------| | 0 | 这 | 0.1821 | 0.4000 | 0.2248 | 0.4440 | 0.7771 | | 1 | 是 | 0.1721 | 0.5030 | 0.8948 | 0.2385 | 0.0987 | | 2 | 最好的 | 0.1342 | 0.8297 | 0.2978 | 0.7120 | 0.2565 | | 3 | 时代 | 0.1248 | 0.5003 | 0.7559 | 0.4804 | 0.2593 | | ➕ | 输入Decoder:sos编码序列 | 索引 | | y1 | y2 | y3 | y4 | y5 | |----|-------|--------|--------|--------|--------|--------| | 0 | "sos" | 0.5651 | 0.2220 | 0.5112 | 0.8543 | 0.1239 | |
|-------|----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|------|----------------------------------------------------------------------------------------------------------------------------------------------|
| 预测出 ➡ | 当前时间步的预测标签yhat | 索引 | | y1 | y2 | y3 | y4 | y5 | |----|-----|--------|--------|--------|--------|--------| | 1 | yyy | 0.5621 | 0.8920 | 0.7312 | 0.2543 | 0.1289 | | 对应 ➡ | 真实标签y | 索引 | | |----|-------| | 0 | It | | 1 | was | | 2 | the | | 3 | best | | 4 | of | | 5 | times | | 6 | "eos" | |
- 第二步,输入ebd_X & yhat:2 >> 输出写到yhat2。注意,yhat:2 指的是 yhat 的第一行和第二行。即,这里输入的是 ebd_X 以及实际输出的第0和1位,预测值写到yhat的第三行。
|----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|---|------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| 输入Encoder 特征矩阵 | 索引 | | y1 | y2 | y3 | y4 | y5 | |----|-----|--------|--------|--------|--------|--------| | 0 | 这 | 0.1821 | 0.4000 | 0.2248 | 0.4440 | 0.7771 | | 1 | 是 | 0.1721 | 0.5030 | 0.8948 | 0.2385 | 0.0987 | | 2 | 最好的 | 0.1342 | 0.8297 | 0.2978 | 0.7120 | 0.2565 | | 3 | 时代 | 0.1248 | 0.5003 | 0.7559 | 0.4804 | 0.2593 | | ➕ | 输入Decoder:yhat预测标签 (加入上一个时间步的预测结果) | 索引 | | y1 | y2 | y3 | y4 | y5 | |----|-------|--------|--------|--------|--------|--------| | 0 | "sos" | 0.5651 | 0.2220 | 0.5112 | 0.8543 | 0.1239 | | 1 | yyy | 0.5621 | 0.8920 | 0.7312 | 0.2543 | 0.1289 | |
|-------|----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|------|----------------------------------------------------------------------------------------------------------------------------------------------|
| 预测出 ➡ | 当前时间步的预测标签yhat | 索引 | | y1 | y2 | y3 | y4 | y5 | |----|-----|--------|--------|--------|--------|--------| | 2 | yyy | 0.3074 | 0.8774 | 0.0364 | 0.0649 | 0.4704 | | 对应 ➡ | 真实标签y | 索引 | | |----|-------| | 0 | It | | 1 | was | | 2 | the | | 3 | best | | 4 | of | | 5 | times | | 6 | "eos" | |
以此类推。
3.3.4 并行计算
上面已经分别说明了 训练 与 验证/测试 的逐步流程,下面把「为什么训练能并行、而推理必须串行」说清楚。
训练时的约定(复习):
原始序列(Encoder 输入)X = "这","是","最","好","的","时","代"
真实标签(用于算损失)y = "it", "was", "the", "best", "of", "times"
ebd_X = 原始序列 X 的 embedding;ebd_y = Decoder 输入序列(带 SOS)的 embedding;yhat = 模型对整个 Decoder 输入序列的预测输出。
约定:yhat0=SOS,模型预测从 yhat1 开始。
- 第一步 ,输入 ebd_X & ebd_y0 >> 输出 yhat1,对应真实标签 y0
- 第二步 ,输入 ebd_X & ebd_y:2 >> 输出 yhat2,对应真实标签 y1
- 第三步 ,输入 ebd_X & ebd_y:3 >> 输出 yhat3,对应真实标签 y2
- 以此类推(第 t 步:输入 ebd_X & ebd_y:t >> 输出 yhatt,对应 yt−1)
以及 Transformer 验证/测试过程中的流程(无真实标签,用上一步预测作为下一步输入):
- 第一步 ,输入 ebd_X & SOS >> 输出 yhat1(yhat0 固定为 SOS)
- 第二步 ,输入 ebd_X & yhat:2 >> 输出 yhat2,对应真实标签 y1
- 第三步 ,输入 ebd_X & yhat:3 >> 输出 yhat3,对应真实标签 y2
- 以此类推(第 t 步:输入 ebd_X & yhat:t >> 输出 yhatt)
训练阶段如何实现并行计算?
训练时我们有完整的真实标签(如 SOS, It, was, the, best, of, times),因此可以把整段 Decoder 输入 ebd_y 一次性送入模型,而不是真的按「第一步、第二步、......」逐次前向。Decoder 里的掩码自注意力 (causal mask)会保证:位置 iii 的表示只能看到位置 0,1,...,i0, 1, \ldots, i0,1,...,i,看不到 i+1i+1i+1 及之后的位置。这样,位置 iii 的输出在数学上等价于「只根据 SOS, ..., 第 iii 个真实词 预测下一个词」,与 Teacher Forcing 的逐步逻辑一致,但所有位置可以在同一次前向传播中同时计算 ,得到整条 yhat1, yhat2, ..., yhatT。因此训练时是按序列维度并行的:一次前向即可得到整句预测,再与真实标签逐位算损失,大大提高了训练效率(相对 RNN 的逐步展开)。
验证/测试阶段能否并行?
验证和测试时没有 真实目标序列,下一步的 Decoder 输入依赖上一步的预测结果 (yhat1、yhat2、...),因此在时间步维度上无法并行 :必须先算 yhat1,再以 SOS, yhat\[1] 为输入算 yhat2,再以 SOS, yhat\[1, yhat2] 为输入算 yhat3,如此自回归进行,直到生成 EOS 或达到最大长度。也就是说,单条序列的解码是严格按时间步串行 的。我们仍然可以在 batch 维度上并行(同时解码多条句子),但每条序列内部仍是逐步生成,这也是推理阶段通常比训练慢、且难以像训练那样「一次前向得到整句」的原因。
💡 小结 :训练 ------有完整真实标签 + 因果掩码 ⇒ 序列维度可并行,一次前向得到整句预测;推理------无真实标签,下一步依赖上一步预测 ⇒ 时间步必须串行,只能逐词生成。理解这一点有助于区分「训练快、推理慢」的成因,以及为何推理时常采用批量解码、KV 缓存等优化手段。