1、大模型训练相关知识
概述:在大模型的训练过程中需要解决两个问题,一是效率问题即提高模型训练的速度,二是显存问题即GPU能否完成一次完整的模型训练。针对上面的问题提出了并行训练的操作方式,关于并行训练主要有以下几种类型:
- 数据并行:该方式是指将大模型复制多份到多个GPU上,然后每块GPU上跑一定量的数据,最终将每块GPU上得到的梯度加和求平均值,再去更新相关权重;该方式可以加快模型训练速度,但是前提必须是一块GPU可以单独完成一次完整的模型训练。
- 模型并行:是指将大模型的各部分网络层分别放置在多块GPU上进行训练,该方式解决了单个GPU不够大无法容纳整个模型训练的问题,但同样也会需要更多的通信时间
- 张量并行(流水线并行):是将张量分成不同的部分分别放在不同GPU上进行训练,减少了对单卡显存的需求,但也需要更多的数据通信时间
- 混合并行:将上面介绍的并行方式混合使用的方式,例如大模型
BLOOM就是用的混合方式
混合精度
混合精度也就是对模型中参数权重存储精度的控制,合理控制其参数权重精度可以提高模型的存储效率以及模型训练和推理速度。
- 在进行权重更新的操作时尽量采用高精度(
FP32)- 前向计算等操作时则不需要太高的精度(
FP16)- 在使用优化器
Adam时,其中始终会保留有一份高精度的模型参数权重信息(FP32)
Deepspeed
概述:
Deepspeed是一款微软发布的提高模型训练速度框架,通过采用不同的策略一提高模型的训练速度、节约模型的存储成本。主要的部分就是零冗余优化器ZeRO,
一般有以下几种模式:
stage0-baseline:类似数据并行stage1-pos:将优化器部分分不到各个GPU上stage2-pos+g:将优化器以及梯度分散到各个GPU上stage3-pos+g+p:将优化器、梯度以及权重参数分布到各个GPU上
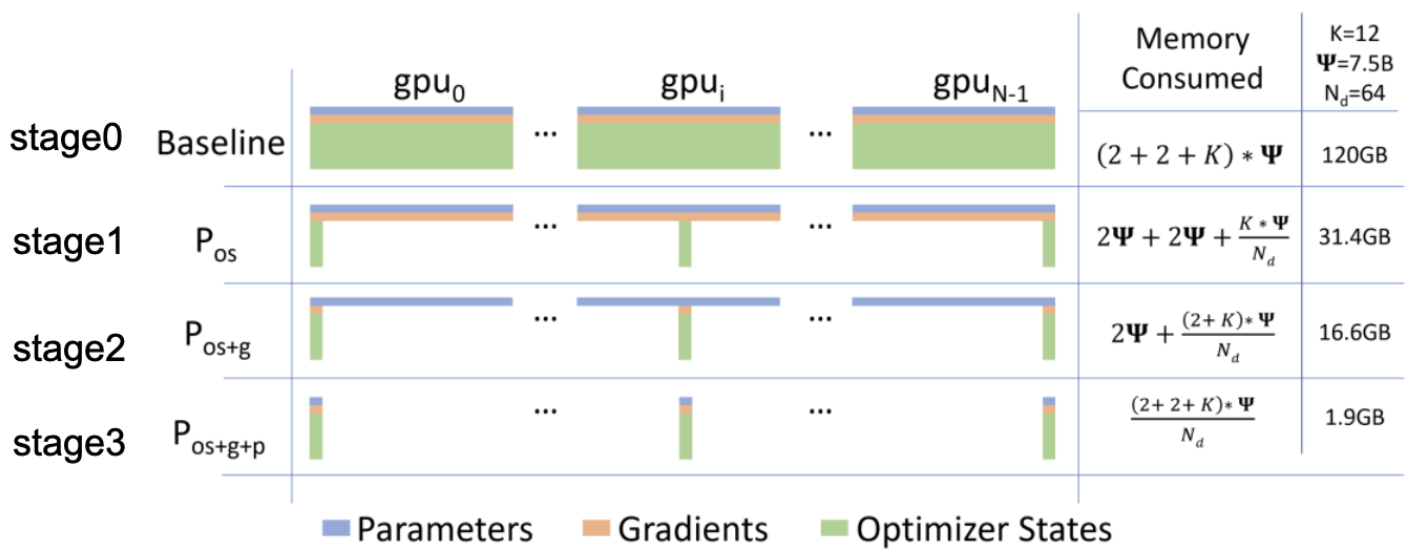
最后还有ZeRO-offload,将一部分数据放置在内存中,用CPU进行计算(同样是为了解决显存不足的问题)。
训练速度比较:stage0>stage1>stage2>stage2+offload>stage3>stage3+offload
显存利用率上:stage0<stage1<stage2<stage2+offload<stage3<stage3+offload
PEFT微调
概述:在一次性训练整个大模型由于成本问题无法实现时,则可以通过最小化微调参数的数量缓解大模型预训练模型的成本。
一般有以下几种方式:
-
prompt-tuning:该微调方式是对不同的任务加上对应的虚拟token,然后在大模型的embedding层中加入这些虚拟token的向量,在真正进行训练过程中只更新这些token对应的embedding层向量。 -
prefix-tuning:在大模型的前面加上一个小网络层结构(小模型),训练时让数据先过这个小模型,在过这个大模型,最终权重的更新只更新前面那个小模型。 -
p-tuning&p-tuningV2:在embedding层序列化训练数据时拼接上和任务类型对应的向量,同样的大模型训练过程中也只需要更新对应的新加入的向量。 -
Adapter:该种微调方式是在大模型网络结构中的添加一个网络结构(Adapetr),在模型训练过程中只更新这个网络结构的权重参数,例如在Transformer结构中的FeedForward层的后面加上一个Adapter网络层,如下图: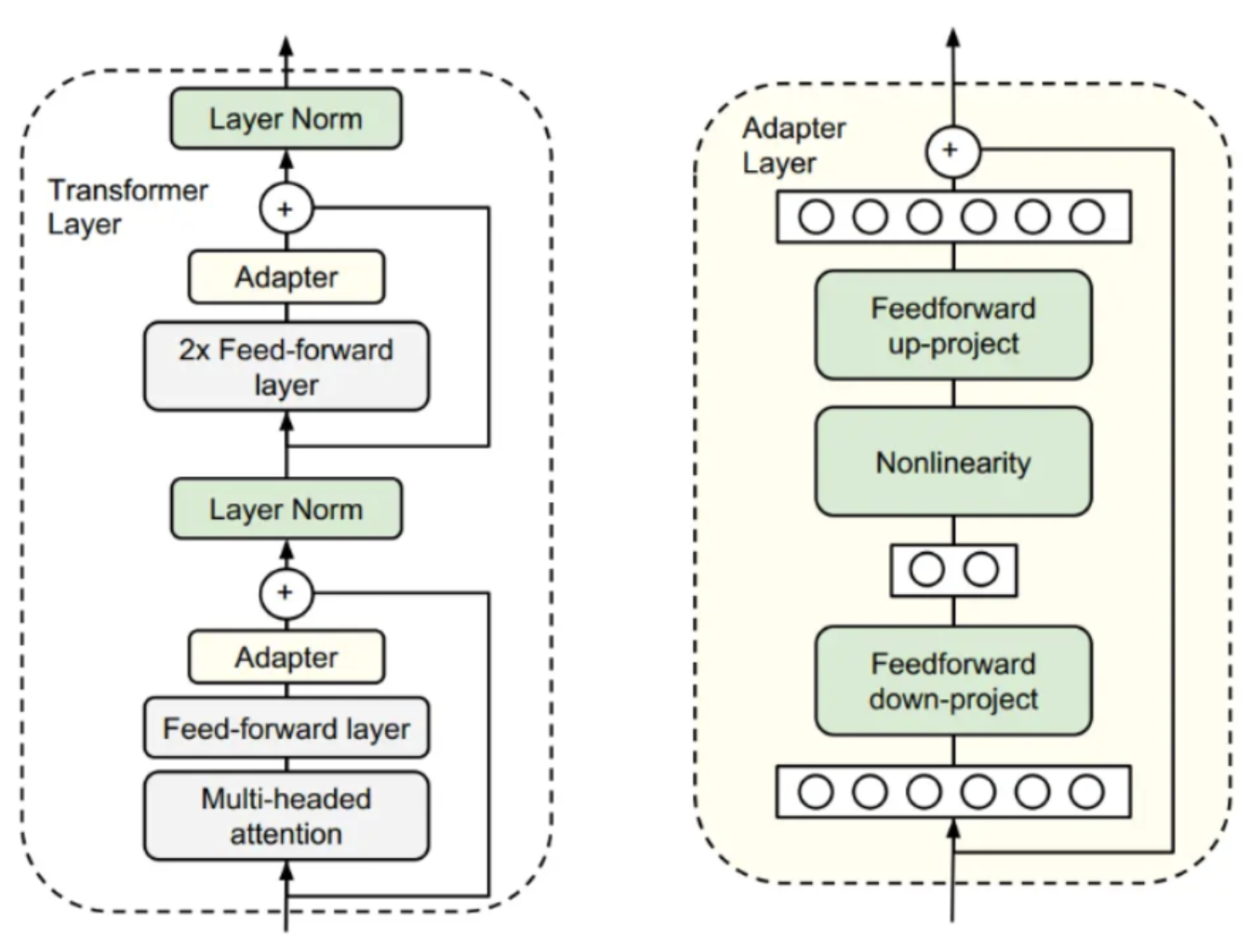
-
LoRA:该种微调方式也是Adapter的优化版,将Adapter按照自己的意愿随意的融入到大模型的各个网络结构模块中,其中是一种并行的结构,Adapter结构类似是Linear1+Norm+Linear2,其中对应的Linear2这个模块在初始化时是0,其目的是为了保证模型训练最开始的位置是原大模型的未被微调的最初状态,减少随机对于模型微调的影响,防止模型训歪了;然后Adapter其他的部分就是会正常随机初始化。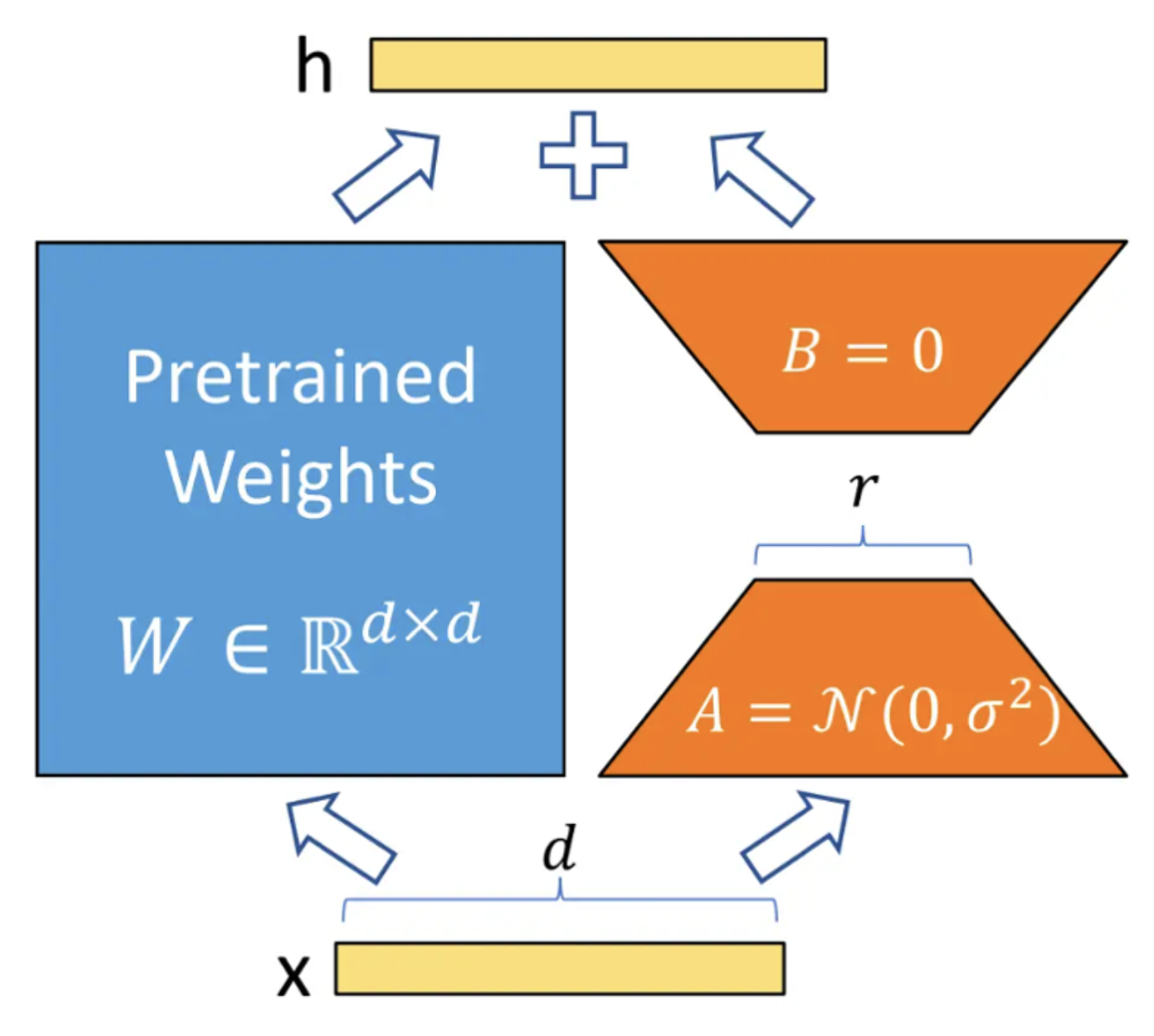
代码实现使用PEFT-LoRA微调12层Bert模型,代码参考Give:PEFT_TRAIN分支
2、Agent
概述:Agent简单的来讲就是给大模型安装的手脚,使大模型不仅可以和你聊天,还能切实的帮你做事。具有以下特点:
- 专用环境
- 保留记忆
- 任务规划
- 使用工具
详细初步内容参考博客:https://blog.csdn.net/tjz991129/article/details/157547586
3、kvcache以及LLM通用能力评价方式
kvcache
kvcache简单的来讲就是在模型最推理过程中的self-attention时,缓存下k*v的矩阵,然后每次新的token进来只需要在这个缓存的矩阵上拼接更新就行,避免了许多重复的计算,加快了推理的过程。本质上也就是以空间换时间。

LLM通用能力评价方式
概述:在世界范围内有一些公共的数据集用于测试大模型的泛化能力,本质上都是一些涵盖这种知识集的题库,看模型能够得到多少分。
一些相关题库:
- MMLU
- CMMLU
- GSM8K:数学题数据集
- HumanEval:代码数据集
- GPQA
- MATH
- Chatbot Arena:多个模型做同一个题目,然后由人来进行打分
- 用ChatGPT来给各个模型的答案进行打分