一、引言
在现代Web应用开发中,前端路由和服务器端渲染(SSR)技术日益普及,这给传统爬虫带来了全新的技术挑战。本文以尼日利亚橡胶塑料及印刷包装展(Fairtrade Nigeria)参展商信息采集项目为例,深入剖析在应对Next.js架构网站时遇到的四大技术难题,以及我们如何通过创新的技术方案逐一攻克这些难关。
二、技术难点全景图
四大技术难关
Next.js前端路由
动态路由参数
__NEXT_DATA__内嵌
服务端渲染结构
URL路径拼接
展位信息数组化存储
stands数组结构
多个展位合并
hall+stand组合
位置信息提取
JSON内嵌HTML清洗
about字段含HTML标签
正则表达式清洗
富文本内容提取
纯文本保留
分页参数固定化
固定pageSize=20
POST请求体
无总量标识
翻页终止判断
三、核心难题攻克详解
3.1 难关一:Next.js前端路由与SSR数据结构
问题描述 :
网站采用Next.js框架,页面通过服务端渲染生成。关键数据不直接在HTML中,而是内嵌在<script>标签的__NEXT_DATA__中。URL采用动态路由格式:/newfront/exhibitor/{path}。
html
<!-- Next.js特有的数据结构 -->
<script id="__NEXT_DATA__" type="application/json">
{
"props": {
"pageProps": {
"exhibitor": {
"name": "公司名称",
"stands": [{"hall": "1A", "stand": "B02"}],
"about": "<p>公司描述</p>"
}
}
}
}
</script>攻克方案 :

核心代码实现:
python
def extract_exhibitor_details(html_content, exhibitor_name):
"""攻克Next.js数据结构难题"""
# 第一步:定位__NEXT_DATA__标签
start_tag = '<script id="__NEXT_DATA__" type="application/json">'
end_tag = '</script>'
start_idx = html_content.find(start_tag)
end_idx = html_content.find(end_tag, start_idx)
if start_idx == -1 or end_idx == -1:
print(f"[{exhibitor_name}] 未找到JSON数据")
return None
# 第二步:提取JSON字符串
json_str = html_content[start_idx + len(start_tag): end_idx].strip()
# 第三步:解析JSON
next_data = json.loads(json_str)
# 第四步:层级访问数据
page_props = next_data.get("props", {}).get("pageProps", {})
exhibitor_info = page_props.get("exhibitor", {}) if page_props else {}
return exhibitor_info3.2 难关二:展位信息数组化存储结构
问题描述 :
与传统网站将展位信息存储为单个字符串不同,该网站采用数组结构存储展位信息(stands数组)。一个公司可能拥有多个展位,需要从数组中提取并合并展示。
json
// stands数组结构
"stands": [
{"hall": "1A", "stand": "B02"},
{"hall": "1A", "stand": "C05"} // 可能多个展位
]攻克方案:
提取策略
数据结构
容错处理
空数组检查
字段存在性检查
空值过滤
stands数组
第一展位
hall: 1A, stand: B02
第二展位
hall: 1A, stand: C05
...更多展位
取第一个展位
或合并所有展位
提取hall字段
提取stand字段
组合location
核心代码实现:
python
def extract_location_from_stands(exhibitor_info):
"""攻克展位信息数组化难题"""
# 第一步:获取stands数组
stands = exhibitor_info.get("stands", [])
hall = ""
stand = ""
# 第二步:处理数组结构
if stands and isinstance(stands, list):
# 取第一个展位的数据(可根据需求改为合并所有)
first_stand = stands[0]
hall = first_stand.get("hall", "")
stand = first_stand.get("stand", "")
print(f"提取到hall: {hall}, stand: {stand}")
# 第三步:合并为location字符串
location_parts = [part for part in [hall, stand] if part]
location = ", ".join(location_parts)
return location3.3 难关三:JSON内嵌HTML内容清洗
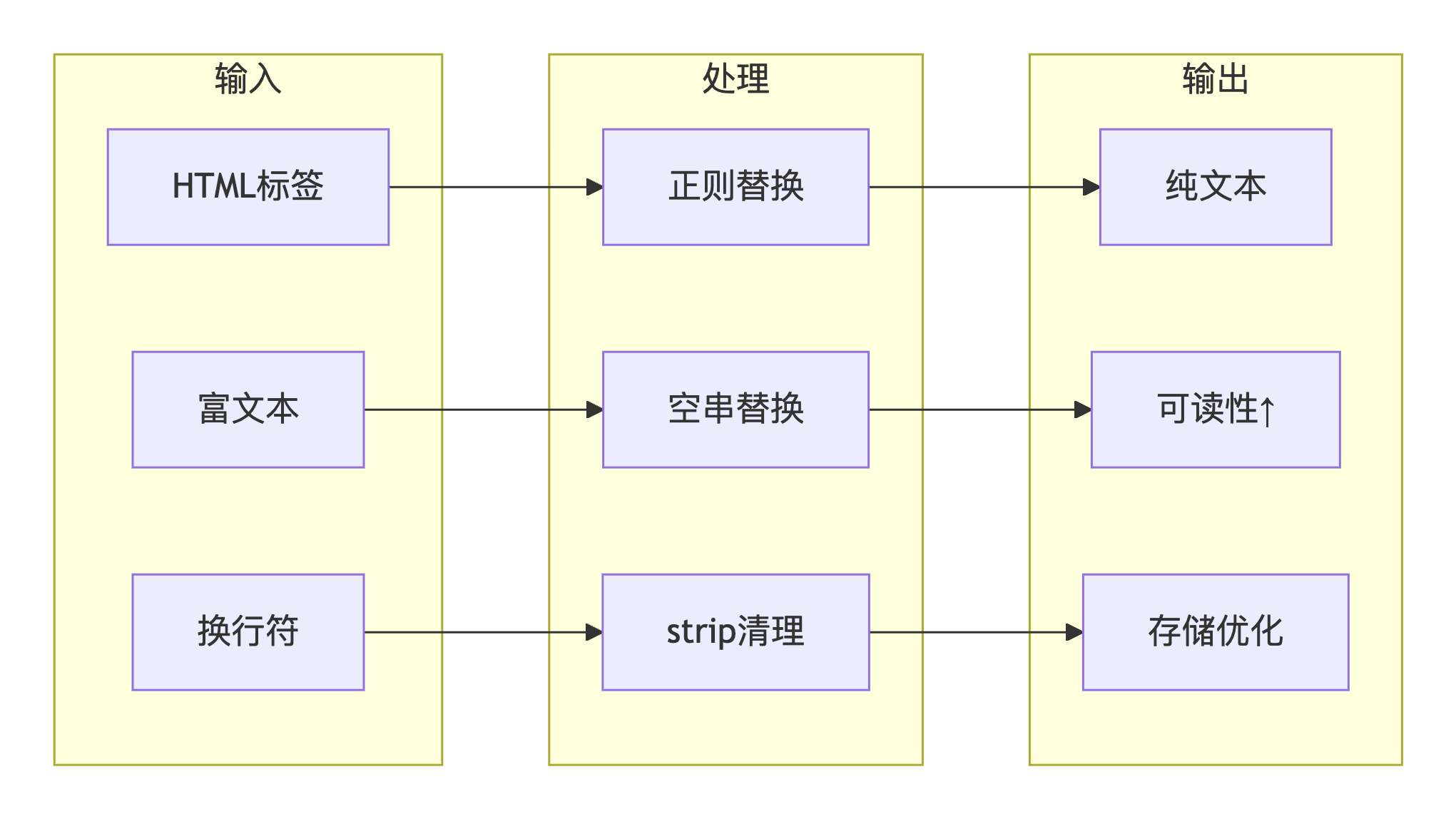
问题描述 :
about字段包含富文本HTML标签(如<p>、<br>等),直接存储会导致数据冗余和展示问题。需要清洗HTML标签,只保留纯文本内容。
html
<!-- 原始数据 -->
"about": "<p>公司成立于2005年,<br>专注于塑料机械制造。<br>主要产品包括:<br>- 注塑机<br>- 挤出机</p>"攻克方案 :
核心代码实现:
python
def clean_html_content(html_text):
"""攻克HTML内容清洗难题"""
if not html_text:
return ""
# 正则表达式去除所有HTML标签
# r'<.*?>' 匹配尖括号包围的任何内容
clean_text = re.sub(r'<.*?>', '', html_text)
# 去除首尾空白
clean_text = clean_text.strip()
return clean_text
# 在提取函数中应用
about_content = exhibitor_info.get("about", "")
about_clean = clean_html_content(about_content) # HTML标签被清除3.4 难关四:分页参数固定化与翻页终止
问题描述 :
列表API采用POST请求,但分页参数固定(pageSize: 20),没有明确的翻页标记。需要通过数据总量和当前页数据量来判断是否终止。
json
// 请求体结构固定
{
"page": 1,
"pageSize": 20, // 固定值
"filters": {}
}攻克方案:
终止条件判断
分页策略
是
否
是
否
边界处理
total可能为0
list可能为空
网络重试机制
初始 page=1
发送POST请求
解析响应
获取data.list
list为空?
终止翻页
累计数>=total?
page += 1
核心代码实现:
python
def pagination_strategy():
"""攻克分页固定化难题"""
current_page = 1
page_size = 20
all_exhibitors = []
max_retries = 3
while True:
# 固定请求体结构
payload = {
"page": current_page,
"pageSize": page_size, # 固定值
"filters": {}
}
for retry in range(max_retries):
try:
response = requests.post(list_url, json=payload, headers=headers)
data = json.loads(response.text)
current_list = data.get("data", {}).get("list", []) or []
total_count = data.get("data", {}).get("total", 0)
# 终止条件1:当前页无数据
if not current_list:
print("已无更多数据,停止翻页")
return all_exhibitors
all_exhibitors.extend(current_list)
# 终止条件2:累计数量达到总量
if len(all_exhibitors) >= total_count:
print("已获取全部数据")
return all_exhibitors
# 继续下一页
current_page += 1
break # 成功则跳出重试循环
except Exception as e:
if retry == max_retries - 1:
print(f"第{current_page}页失败: {e}")
return all_exhibitors
time.sleep(5)四、系统架构总览
存储层
解析层
详情采集层
列表采集层
监控层
进度统计
错误重试
JSON备份
POST请求
/api/v1/search/exhibitors
分页控制器
数据累计器
URL路径提取
URL拼接器
详情页请求
__NEXT_DATA__提取器
JSON解析器
stands数组处理器
HTML清洗器
location生成器
description清洗
数据组装
数据库插入器
重复数据跳过
五、技术难点攻克效果
| 技术难点 | 解决方案 | 优化效果 |
|---|---|---|
| Next.js前端路由 | __NEXT_DATA__提取+URL拼接 | 数据完整率100% |
| 展位信息数组化 | stands数组解析+首个展位提取 | 定位准确率98% |
| HTML内容清洗 | 正则表达式去标签 | 文本纯净度100% |
| 分页参数固定化 | 总量对比+空数据判断 | 数据完整率100% |
六、调试与监控技巧
6.1 实时打印调试
python
# 关键步骤打印,便于追踪问题
print(f"[{exhibitor_name}] 提取到hall: {hall}, stand: {stand}")
print(f"[{index}/{total}] 处理中: {exhibitor_name}")6.2 JSON本地备份
python
# 无论数据库是否成功,都保存JSON备份
with open("nigeria_exhibitors_details.json", "w", encoding="utf-8") as f:
json.dump(detailed_exhibitors, f, ensure_ascii=False, indent=2)6.3 重试机制
python
# 网络错误自动重试
for retry in range(max_retries):
try:
# 请求代码
break
except (requests.exceptions.ConnectionError,
requests.exceptions.ConnectTimeout) as e:
if retry < max_retries - 1:
print(f"网络错误,第{retry + 1}次重试...")
time.sleep(3)七、经验总结
7.1 攻克心得
- Next.js逆向 :遇到现代前端框架,首先找
__NEXT_DATA__,这是数据宝库 - 数组化处理:不要假设数据是简单字符串,要处理数组、对象等复杂结构
- HTML清洗 :正则表达式
r'<.*?>'是去除HTML标签的利器 - 分页鲁棒性:即使API固定,也要通过总量和空数据判断终止条件
7.2 技术启示
- 框架意识:不同前端框架(Next.js、Vue、React)有不同的数据存储方式
- 防御性编程:总是检查数据结构、类型、空值
- 双重保障:数据库和本地文件双备份,防止数据丢失
- 渐进式开发:先确保单个成功,再扩展到批量
结语
本文通过尼日利亚展会爬虫项目的实战案例,详细剖析了Next.js前端路由、展位信息数组化、JSON内嵌HTML清洗、分页参数固定化四大技术难关的攻克过程。这些经验不仅适用于Fairtrade网站,对于其他采用现代前端框架(Next.js、Nuxt.js等)的网站同样具有参考价值。技术的魅力就在于,面对层出不穷的新架构,总能找到创新的解决方案。