我把本地文档 RAG 做成了可用系统:Flask + Vue3 + LangChain + FAISS(多知识库 + 流式输出)
很多 RAG Demo 都停留在"能回答一次问题",但真正要用起来,至少还要解决这几件事:
- 多个知识库隔离(不同业务、不同团队互不影响)
- 文档管理(上传、列表、删除、URL 入库)
- 多轮会话记忆(不仅是检索,还要记住上下文)
- 流式输出(边生成边展示,减少等待焦虑)
我把这些做成了一个完整项目:docs-rag-chat。
技术栈是 Flask + Vue3 + LangChain + FAISS,后端支持按 app_id 隔离知识库,前端支持实时流式渲染答案。
项目地址:https://github.com/eagle1949/docs-rag-chat
项目图片: 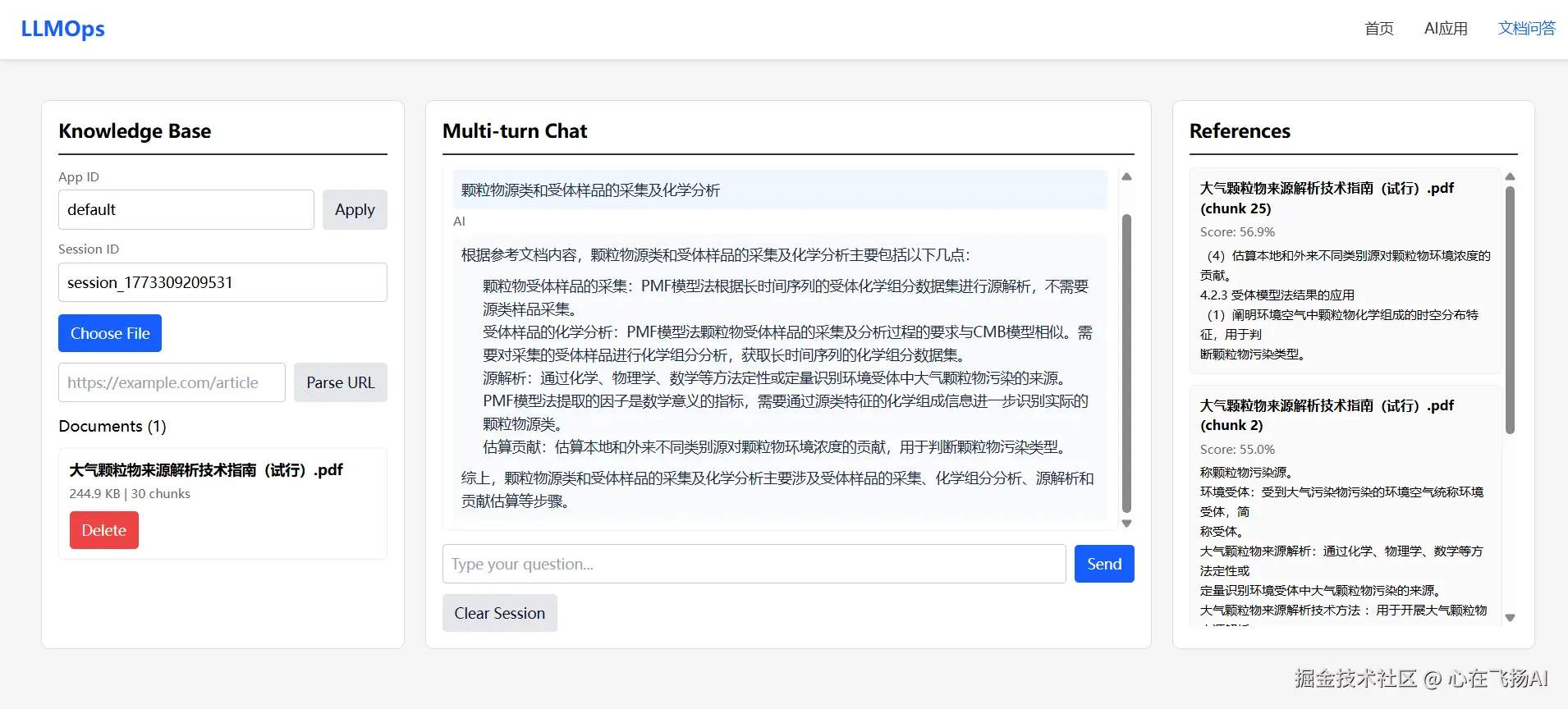
1. 项目结构和整体链路
核心链路可以概括为:
- 文档入库:上传文件 / URL 抓取
- 文档切分:按 chunk 切成可检索片段
- 向量化存储:写入 FAISS
- 问答检索:相似召回 + LLM 生成
- 会话记忆:摘要 + 最近对话
- 流式返回:SSE token 推送到前端
简化架构:
text
Vue3 Frontend
-> Flask RAG API
-> DocumentLoader (md/txt/pdf/url)
-> DocumentSplitter (chunk=500, overlap=50)
-> FAISS VectorStore (Qianfan Embeddings)
-> ChatOpenAI (Moonshot by default)
-> SummaryBufferMemory (session level)2. 多知识库隔离是怎么做的
我没有把所有文档都堆到一个索引里,而是按 app_id 做目录级隔离。
每个 app 独立维护:
data/rag/{app_id}/documents(原始文件)data/rag/{app_id}/faiss_index(向量索引)data/rag/{app_id}/documents_meta.json(文档元信息)storage/chat_history/{app_id}(会话记忆文件)
这样做的好处是:
- 检索准确率更稳(避免跨业务语料干扰)
- 清理和迁移简单(按 app 维度操作)
- 未来做权限控制更自然
3. 入库链路:不只支持文件,也支持 URL
文件上传
支持 .md / .txt / .pdf,并做了基础校验:
- 扩展名校验
- 文件大小限制(10MB)
- 上传后写入 app 对应目录
URL 入库
对 http/https 链接执行网页解析,转换为文档再切分入库。
这点非常实用:很多知识都在内部 wiki / 在线文档,不一定是本地文件。
4. 问答策略:检索 + 记忆融合,不是二选一
我在问答链路里做了一个实用取舍:
- 优先处理"会话型问题"(例如"我叫什么名字"),避免被检索噪声干扰
- 文档型问题走向量召回(TopK=3)
- 当检索为空但会话历史存在时,仍允许按历史上下文回答
- 两边都不足时,明确返回"无法回答",避免幻觉
召回分数用了一个简单映射:
python
confidence = 1 / (1 + distance)只保留 confidence >= 0.2 的片段。
5. SSE 流式返回:用户体验提升最明显的一步
后端提供流式接口:
POST /apps/{app_id}/rag/ask/stream
事件协议分三类:
token:增量文本done:结束标记 + sourceserror:异常信息
前端通过 ReadableStream + TextDecoder 按行解析 data:,实时拼接到答案区域。
实际体验是:用户不用等整段生成完才看到内容,感知速度会快很多。
6. 快速启动(本地可跑)
后端
bash
cd Backend
uv sync
uv run python -m app.http.app或直接:
bash
cd Backend
run_backend.bat前端
bash
cd frontend
npm install
npm run dev后端默认 http://127.0.0.1:5000
前端默认 http://127.0.0.1:5173
7. API 示例(按 app_id 隔离)
上传文档
bash
curl -X POST "http://127.0.0.1:5000/apps/default/rag/documents/upload" \
-F "file=@your_doc.md"URL 入库
bash
curl -X POST "http://127.0.0.1:5000/apps/default/rag/url/upload" \
-H "Content-Type: application/json" \
-d '{"url":"https://example.com/article"}'问答(流式)
bash
curl -N -X POST "http://127.0.0.1:5000/apps/default/rag/ask/stream" \
-H "Content-Type: application/json" \
-d '{"question":"总结这份文档","session_id":"session_001"}'8. 这个项目适合谁
- 想做企业内部知识库问答的同学
- 想做"可维护"RAG,而不只是 demo 的同学
- 想练一遍"前后端 + 检索 + 会话 + 流式输出"全链路的人
9. 后续计划
- 混合检索(向量 + BM25)
- 重排序(Rerank)
- 可观测性(请求链路、召回质量监控)
- 鉴权和多用户管理
- Docker 一键部署
如果你也在做 RAG 项目,欢迎看看这个仓库并提 issue。
如果这篇文章对你有帮助,也欢迎点个 Star 支持一下: