前言 :在信息检索(IR)领域,如何弥合用户简短查询与长文档之间的"词汇鸿沟"一直是核心挑战。传统的查询扩展方法(如RM3)效果有限,而大语言模型(LLM)的涌现为这一老问题带来了新解。微软研究院提出的 Query2doc 框架,巧妙地利用 LLM 强大的知识记忆和生成能力,通过"少样本提示(Few-shot Prompting)"生成伪文档来扩展查询。本文将对这篇发表于 2023 年的佳作进行深度解读,剖析其如何利用 LLM 赋能传统检索系统。
📄 论文基本信息
| 项目 | 内容 |
|---|---|
| 论文标题 | Query2doc: Query Expansion with Large Language Models |
| 中文译名 | Query2doc:基于大语言模型的查询扩展 |
| 作者 | Liang Wang, Nan Yang, Furu Wei |
| 所属机构 | Microsoft Research (微软研究院) |
| 发表年份 | EMNLP 2023 |
| 核心领域 | Information Retrieval (信息检索), Query Expansion (查询扩展), LLM Application |
| 代码/数据开源 | 生成的伪文档数据集已开源至 Hugging Face (intfloat/query2doc_msmarco) |
研究背景与痛点
信息检索系统主要分为两类:基于词法的稀疏检索 (如 BM25)和基于嵌入的稠密检索 (如 DPR, SimLM)。尽管稠密检索在有标签数据上表现优异,但稀疏检索在跨域场景下仍具竞争力。然而,两者都面临一个共同难题:查询通常简短、模糊且缺乏背景信息 ,导致与目标文档存在严重的词汇不匹配(Lexical Gap)。
现有的解决方案存在明显局限:
- 传统查询扩展(如 RM3):依赖伪相关反馈或外部词典(如 WordNet),但在现代数据集上提升有限,甚至可能引入噪声。
- 文档扩展(如 doc2query):虽然有效,但需要训练专门的生成模型并更新整个文档索引,成本高且不灵活。
- 大模型应用缺失:大多数最先进的稠密检索器并未利用 LLM 的强大生成能力进行查询增强。
💡 核心思路 :利用 LLM 在海量语料上预训练获得的知识记忆 和语言模式,针对用户查询生成一段包含丰富相关信息的"伪文档"。将这段伪文档与原查询拼接,形成增强后的新查询,从而指导检索系统更准确地找到目标文档。这种方法无需微调检索模型,也无需更改索引,具有极高的通用性。
🛠️ 核心方法:Query2doc 架构详解
Query2doc 的核心流程非常简单高效,主要包含两个步骤:伪文档生成 与查询重构。
1. 伪文档生成 (Pseudo-document Generation)
- 技术路线 :采用 少样本提示(Few-shot Prompting) 策略。
- Prompt 设计 :
- 指令 :
Write a passage that answers the given query:(写一段回答给定查询的文章)。 - 示例 :从训练集中随机采样 k=4 个
<Query, Passage>对作为上下文示例。 - 输入 :当前用户查询
。
- 指令 :
- 输出 :LLM 生成一段伪文档
- 模型选择 :主要使用 OpenAI 的
text-davinci-003,实验也验证了 GPT-4 及不同参数量模型的效果。
2. 查询重构与检索 (Query Rewriting & Retrieval)
根据检索类型的不同,采取不同的拼接策略:
(1) 稀疏检索 (Sparse Retrieval, e.g., BM25)
由于伪文档长度远大于原查询,直接拼接会导致原查询关键词权重被稀释。
- 策略 :重复原查询。
- 公式 :
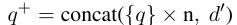
- 参数:实验发现重复次数 n=5 效果最佳,无需针对不同数据集调优。
- 目的:平衡原查询与伪文档的权重,确保核心关键词在倒排索引中仍有高权重。
(2) 稠密检索 (Dense Retrieval, e.g., DPR, SimLM)
稠密检索基于语义向量,对长度不敏感。
- 策略 :直接拼接。
- 公式 :
- 训练适配 :
- 设置一(基础训练):使用对比损失(Contrastive Loss)训练 DPR,仅使用 BM25 硬负样本。
- 设置二(蒸馏训练):在 SOTA 模型(如 SimLM, E5)基础上,引入交叉编码器(Cross-Encoder)教师模型进行知识蒸馏(KL 散度损失 + 对比损失)。
3. 与传统方法的对比
- vs. 伪相关反馈 (PRF):传统 PRF 依赖初始检索结果(往往含噪),而 Query2doc 直接利用 LLM 生成高质量相关内容,不依赖初始检索质量。
- vs. HyDE:HyDE 仅使用伪文档的向量进行检索,假设伪文档与真实文档语义一致;Query2doc 则保留原查询,发现两者互补能带来更大提升。
实验结果与分析
作者在多个基准数据集上进行了广泛评估,包括 MS-MARCO, TREC DL (In-domain) 以及 BEIR 基准中的五个低资源数据集 (Zero-shot OOD)。
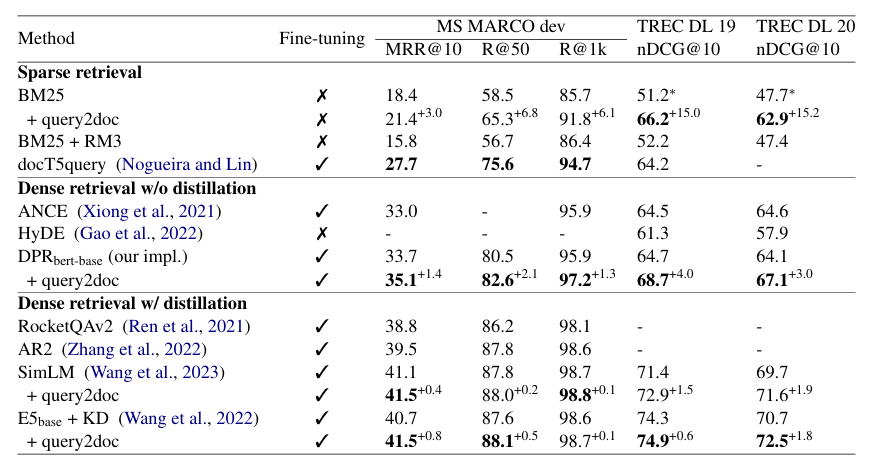
1. 域内评估 (In-Domain Evaluation)
- 稀疏检索 (BM25) :
- 显著提升 :
BM25 + query2doc在 MS-MARCO 上 MRR@10 提升 3.0 ,在 TREC DL 2019/2020 上 nDCG@10 提升高达 15.0/15.2。 - 对比优势 :远超传统 RM3 方法,且无需像
docT5query那样进行昂贵的模型训练和索引重建。
- 显著提升 :
- 稠密检索 (Dense Retrieval) :
- 普遍增益:在 DPR, SimLM, E5 等模型上均观察到性能提升。
- 边际效应:随着基线模型变强(如引入蒸馏或中间预训练),Query2doc 带来的增益有所减小(例如 SimLM 仅提升 0.4~1.5),但依然保持正向收益。
2. 零样本跨域评估 (Zero-shot OOD)
- 表现不一:在实体密集型数据集(如 DBpedia)上提升巨大(+5.7);但在某些特定领域(如 NFCorpus, Scifact)出现轻微下降,归因于训练数据(MS-MARCO)与评估领域的分布差异。
- 鲁棒性:总体而言,在大多数低资源场景下优于强基线。
3. 关键分析洞察
(1) 模型规模至关重要 (Scaling Law)
- 实验:对比了从 1.3B (babbage) 到 175B (davinci-003) 再到 GPT-4 的不同模型。
- 结论 :性能随模型规模增大而稳步提升。小模型生成的文本较短且事实错误多;
davinci-003优于早期版本;GPT-4 效果最佳(nDCG@10 达到 69.2/64.5),但因配额限制未用于主实验。
(2) 数据效率与正交性
- 实验:在不同比例的标注数据上训练 DPR。
- 结论 :无论标注数据多少,
DPR + query2doc始终比基线高出约 1% 。这证明该方法与监督信号的缩放是正交的,即使在数据稀缺时也能发挥作用。
(3) 组合策略的有效性
- 实验:对比"仅用原查询"、"仅用伪文档"、"两者结合"。
- 结论 :原查询与伪文档是互补的。两者结合的效果显著优于单独使用任一部分,特别是在稀疏检索中。
(4) 案例分析与幻觉问题
- 优点:生成的伪文档能提供详细的背景信息,大幅减少词汇不匹配。
- 缺点 :LLM 可能产生事实性幻觉(如搞错歌曲发行的年份)。虽然有时不易察觉,但这限制了其在对准确性要求极高场景的应用。
💡 主要创新点总结
- 简单而高效:无需微调检索模型,无需改变模型架构,仅通过 Prompt 工程即可即插即用,与现有 IR 进展正交。
- 通用性强:同时适用于稀疏检索(BM25)和稠密检索(DPR, SimLM, E5),且在域内和跨域场景下均有效。
- 知识蒸馏新范式:通过 Prompt 将 LLM 的海量知识"蒸馏"到查询中,解决了传统查询扩展知识源有限的问题。
- 实证发现:揭示了 LLM 规模对查询扩展质量的决定性影响,以及原查询与生成内容互补的重要性。
局限性与未来展望
尽管效果显著,论文也坦诚指出了以下局限:
- 延迟问题 (Latency) :
- LLM 推理慢:自回归生成导致每次查询需额外增加 >2000ms 的延迟(相比 BM25 的 16ms)。
- 索引搜索慢:扩展后的查询词增多,导致倒排索引搜索时间增加。
- 对策:实际部署需权衡性能与延迟,或采用异步生成、缓存策略。
- 事实幻觉 (Hallucination):LLM 生成的伪文档可能包含错误信息,误导检索系统。
- 成本问题:调用大规模 LLM API(如生成 55 万个伪文档花费近 5000 美元)成本较高。
- 跨域适应性:在分布差异极大的领域(如生物医学),直接使用通用领域 Few-shot 示例效果可能下降。
未来方向:
- 探索更小、更快的专用模型进行生成。
- 研究基于语义相似度的动态 Few-shot 示例选择。
- 引入自我验证机制(如迭代 Prompt)以减少幻觉(虽实验显示 GPT-4 自我修正能力有限)。
总结
《Query2doc: Query Expansion with Large Language Models》是一篇将大语言模型能力巧妙应用于传统信息检索任务的优秀论文。它证明了利用 LLM 生成伪文档进行查询扩展是一种简单、通用且高效的方法,能够显著提升各类检索系统的性能,尤其是在处理长尾、模糊查询时效果惊人。
尽管面临延迟和成本的挑战,但 Query2doc 为检索增强提供了一条新的技术路径:不再仅仅依赖模型内部参数的记忆,而是利用生成式 AI 动态地构建更丰富的查询语义。对于从事搜索引擎优化、RAG 系统构建的研究者和工程师来说,这是一篇极具参考价值的文章。
参考文献 :
1 Wang L, Yang N, Wei F. Query2doc: Query Expansion with Large Language ModelsJ. arXiv preprint arXiv:2303.07678, 2023.