前言
本文将详细讲解如何通过KMeans 无监督聚类算法,定位股票历史价格的密集成交区,进而精准识别关键支撑位与压力位。整套方案基于 miniQMT 量化终端的 xtquant 行情接口实现,全程采用 Python 代码开发,适合量化交易从业者、股票技术分析爱好者、Python 金融数据分析人群学习参考。
本篇为系列文章的上篇,核心内容包括:开发环境搭建、QMT 行情数据获取、KMeans 算法原理详解,以及该算法在量化交易中的经典应用场景;下篇将进入实战环节,完成聚类算法落地、支撑压力位可视化与策略有效性验证。
一、开发环境准备
1.1 依赖库安装
本文代码基于 Python 开发,需要提前安装行情接口、数据处理、算法计算、可视化相关的依赖库,打开终端执行以下 pip 命令即可一键安装:
pip install pandas numpy matplotlib scipy scikit-learn xtquant各依赖库核心作用说明:
pandas/numpy:金融数据处理与数值计算核心库matplotlib:K 线与聚类结果可视化scipy/scikit-learn:KMeans 聚类算法实现与科学计算xtquant:miniQMT 终端官方 Python 行情 & 交易接口
1.2 基于 xtquant 的行情数据获取函数
我们先封装一个通用的股票历史行情获取函数,后续所有聚类分析的数据源均通过该函数生成,支持日 K、周 K、月 K 多周期,以及多种复权方式配置。
import pandas as pd
from xtquant import xtdata
def get_hq(code, start_date='19900101', period='1d', dividend_type='front_ratio', count=-1):
"""
基于xtquant下载并获取股票历史行情数据
:param code: 股票代码,格式如 600000.SH
:param start_date: 行情起始日期,格式YYYYMMDD
:param period: K线周期,支持 1d(日K)/1w(周K)/1mon(月K) 等
:param dividend_type: 除权方式,可选 none(不复权)/front(前复权)/back(后复权)/front_ratio(等比前复权)/back_ratio(等比后复权)
:param count: 获取K线数量,-1为获取起始日期以来全部数据
:return: 包含OHLCV数据的DataFrame,索引为日期
"""
# 关闭接口hello打印
xtdata.enable_hello = False
# 增量下载历史行情数据
xtdata.download_history_data(stock_code=code, period=period, incrementally=True)
# 获取行情数据
history_data = xtdata.get_market_data_ex(
field_list=['open', 'high', 'low', 'close', 'volume', 'amount', 'pre_close'],
stock_list=[code],
period=period,
start_time=start_date,
count=count,
dividend_type=dividend_type
)
# 转换为DataFrame并格式化日期索引
df = history_data[code]
df.index = pd.to_datetime(df.index.astype(str), format='%Y%m%d')
df['date'] = df.index
return df函数使用示例:获取贵州茅台 2023 年以来的前复权日 K 行情
df = get_hq('600519.SH', start_date='20230101', period='1d', dividend_type='front_ratio')
print(df.head())二、KMeans 聚类算法核心原理
2.1 什么是 KMeans 聚类
KMeans 是经典的无监督机器学习算法,核心特点是无需提前标注数据标签,算法可自主从数据中挖掘规律,完成数据的自动分类。
它的核心任务是:将输入的 N 个数据点,自动划分为 K 个互不重叠的「簇(Cluster)」,每个簇对应一个「聚类中心点(Center)」,最终保证同一簇内的数据点相似度最高,不同簇间的数据点差异最大。
对应到股票分析场景中,我们将股票的历史价格(收盘价 / 高低价)作为输入数据点,KMeans 就能自动帮我们找到历史走势中成交最密集的几个价格水平,而这些价格密集区,正是市场共识最强的支撑位与压力位。
2.2 通俗理解:股价与电梯的类比
我们用一个生活化的例子,彻底搞懂 KMeans 在价格分析中的逻辑:我们可以把股价比作一部大楼里的电梯,不同的股价水平就是大楼的不同楼层,每天的收盘价就是电梯的停靠记录。
- 过去一段时间,电梯在很多楼层都停过,但有的楼层只短暂停靠 1 次,有的楼层却反复停靠,人流量极大;
- 作为大楼管理员,我们核心想知道的,就是这部电梯最常停靠的核心楼层有哪些。
而 KMeans 算法,就是帮我们找到这些核心楼层的工具,对应关系如下:
| 电梯场景 | 股票价格分析场景 |
|---|---|
| 电梯楼层 | 股价水平 |
| 电梯停靠次数 | 股价在该价位的出现频率 / 成交量 |
| 核心停靠楼层 | 聚类中心点(价格密集区) |
这些市场记忆最深刻的「核心楼层」,就是我们要找的关键位置:
- 股价上行时,到达该价位容易遇到大量卖盘,形成压力位;
- 股价下行时,到达该价位容易遇到大量买盘,形成支撑位。
2.3 KMeans 的迭代计算步骤
KMeans 算法的执行过程,就是不断优化聚类中心点位置的迭代过程,核心分为 4 步,我们继续沿用电梯的例子讲解:
- 初始化中心点:随机选择 K 个楼层,作为初始的「核心停靠楼层」(K 为我们提前设定的聚类数量);
- 数据点分配:把每一次电梯的停靠记录(每一个历史价格),全部分配到离它最近的那个核心停靠楼层,形成 K 个分组;
- 更新中心点:针对每个分组,重新计算该分组内所有停靠楼层的平均值,将这个平均值作为新的「核心停靠楼层」;
- 迭代收敛:重复执行步骤 2 和步骤 3,直到核心停靠楼层的位置不再发生显著变化,算法收敛,最终输出 K 个聚类中心点。
2.4 数学定义:最小化平方误差和 SSE
KMeans 算法的优化目标,是最小化所有数据点到其所属聚类中心的平方误差和(SSE),对应的数学公式如下:
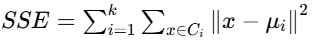
公式中各参数含义:
- k:提前设定的聚类簇数量;
- Ci:第i个聚类簇的数据集合;
- μi:第i个聚类簇的中心点;
- ∥x−μi∥2:数据点x到其所属簇中心点μi的欧氏距离平方。
简单来说,算法的核心目标,就是找到一组最优的中心点,让每个价格数据点,到它所属的聚类中心点的距离之和最小,最终得到的中心点,就是价格最集中的区域。
三、KMeans 在量化交易中的经典应用
除了本文核心讲解的「价格密集区与支撑压力位识别」,KMeans 在量化交易领域还有诸多成熟的应用场景,这里给大家做一个全面的梳理:
- 股票池聚类分组:将全市场股票的因子特征(市盈率、市净率、波动率、换手率、动量等)作为输入,算法会自动将特征相似的股票归为一类,帮助我们识别同风格、同走势的股票,构建差异化股票池。
- 板块与行业效应分析:对同一行业 / 概念板块内的个股进行聚类,识别板块内走势高度联动的核心个股,挖掘板块龙头与跟风标的,辅助板块轮动策略开发。
- 量化因子分层回测:对单因子或多因子合成值进行聚类,自动完成因子值的分层(如高动量、中动量、低动量),替代传统的等频 / 等距分层方式,更贴合因子的实际分布特征,为多因子策略的分层回测与选股打下基础。
- 异常交易行为识别:对股票的量价特征、分时成交数据进行聚类,识别出与正常走势差异极大的异常数据点,辅助捕捉异动个股、规避极端行情风险。
- 交易策略参数优化:对策略的历史回测参数与收益结果进行聚类,找到最优的参数区间,避免参数过拟合,提升策略的样本外稳健性。
下篇预告
本篇我们完成了算法原理的讲解与基础环境的搭建,下篇我们将进入核心实战环节:
- 基于上文的行情函数,提取股票价格数据,完成 KMeans 聚类的代码实现;
- 讲解聚类数量 K 的最优值选择方法(肘部法则);
- 完成支撑位、压力位的可视化绘制,与 K 线图叠加展示;
- 基于聚类结果,构建简单的支撑压力位交易策略,并完成回测验证。