文章目录
一、图的基本概念
图的定义
图 G 是由顶点集 V 和边集 E 组成,记为 G=(V,E),其中 V(G) 表示图 G 中顶点的有限非空集;E(G) 表示图 G 中顶点之间的关系(边)集合。若 V={v1,v2,...,vn},则用 ∣V∣ 表示图 G 中顶点的个数,也称图 G 的阶,E={(u,v)∣u∈V,v∈V},用 ∣E∣ 表示图 G 中边的条数。
图是较线性表和树更为复杂的数据结构。
线性表中,除第一个和最后一个元素外,每个元素只有一个唯一的前驱和唯一的后继结点,元素和元素之间是一对一的关系;
在树形结构中,数据元素之间有着明显的层次关系,每个元素有唯一的双亲,但可能有多个孩子,元素和元素之间是一对多的关系;
而图形结构中,元素和元素之间的关系更加复杂,结点和结点之间的关系是任意的,任意两个结点之间都可能相关,图中元素和元素之间是多对多的关系。
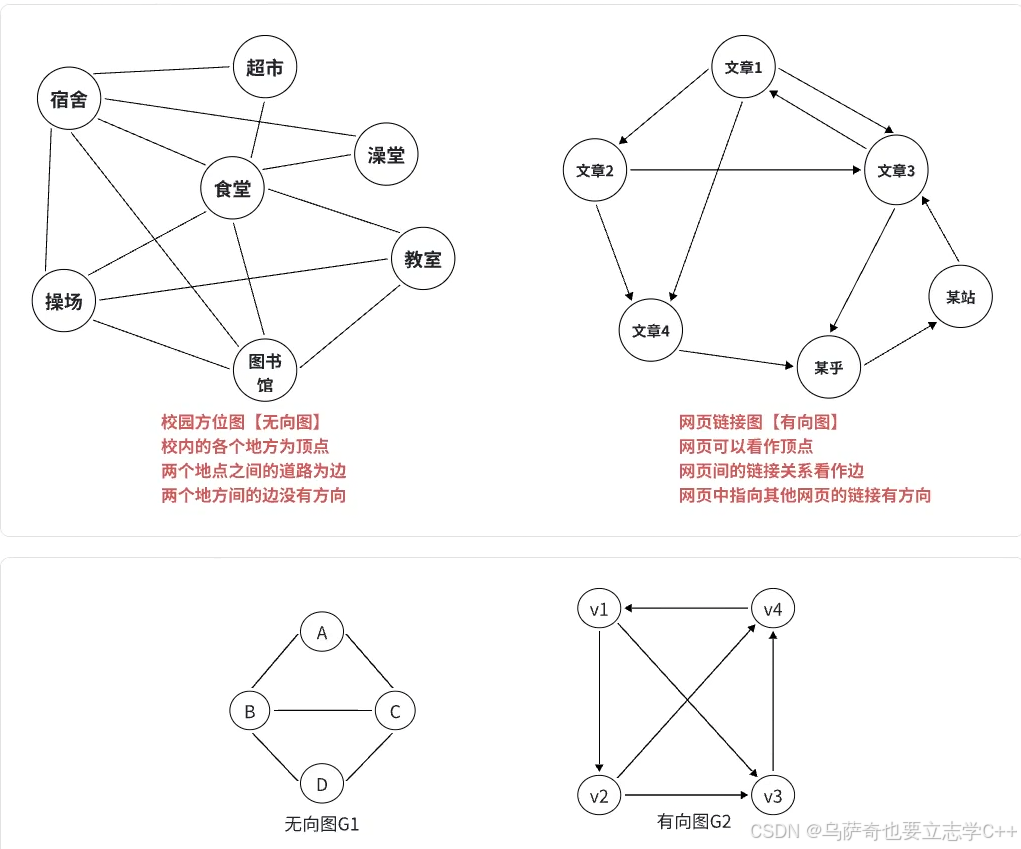
有向图和无向图
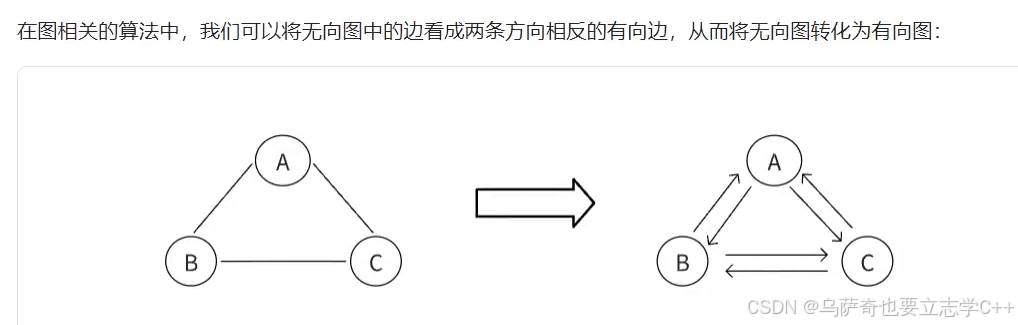
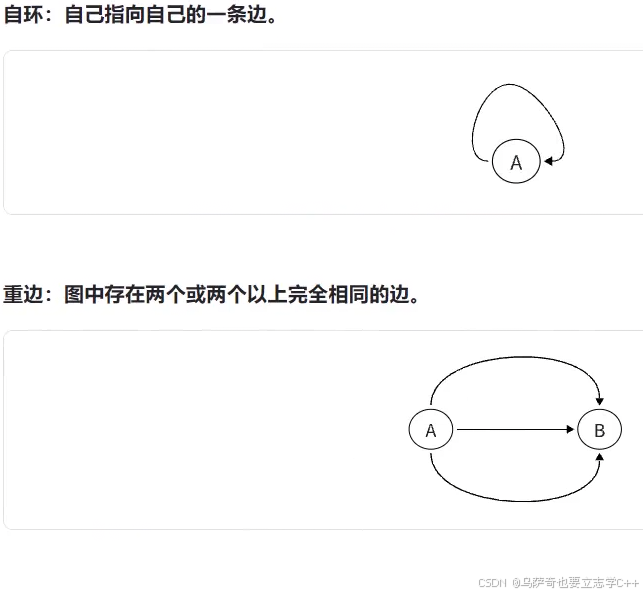
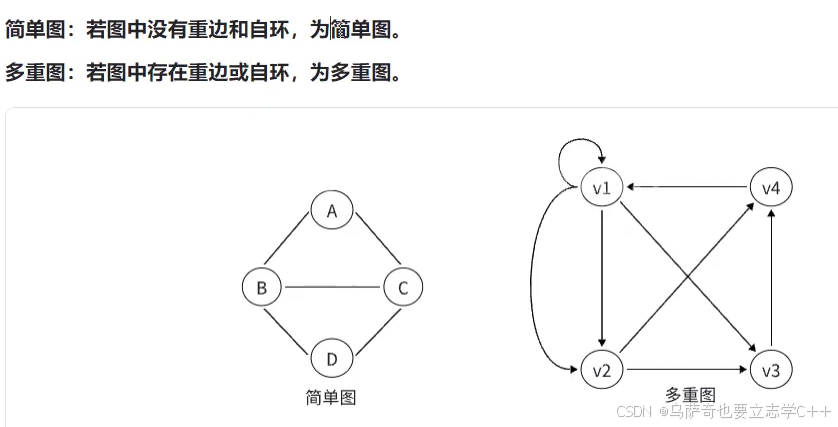
简单图与多重图
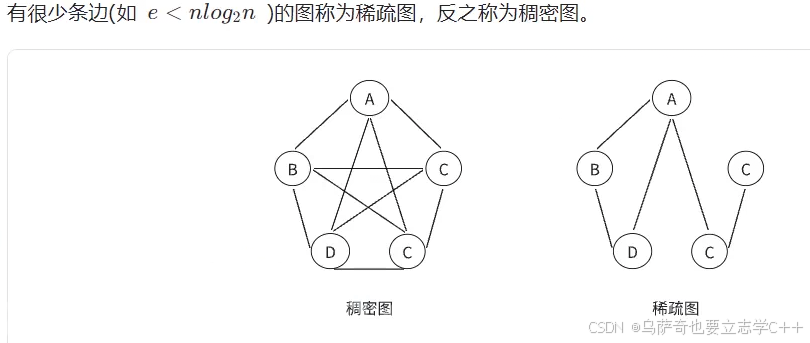
稠密图和稀疏图
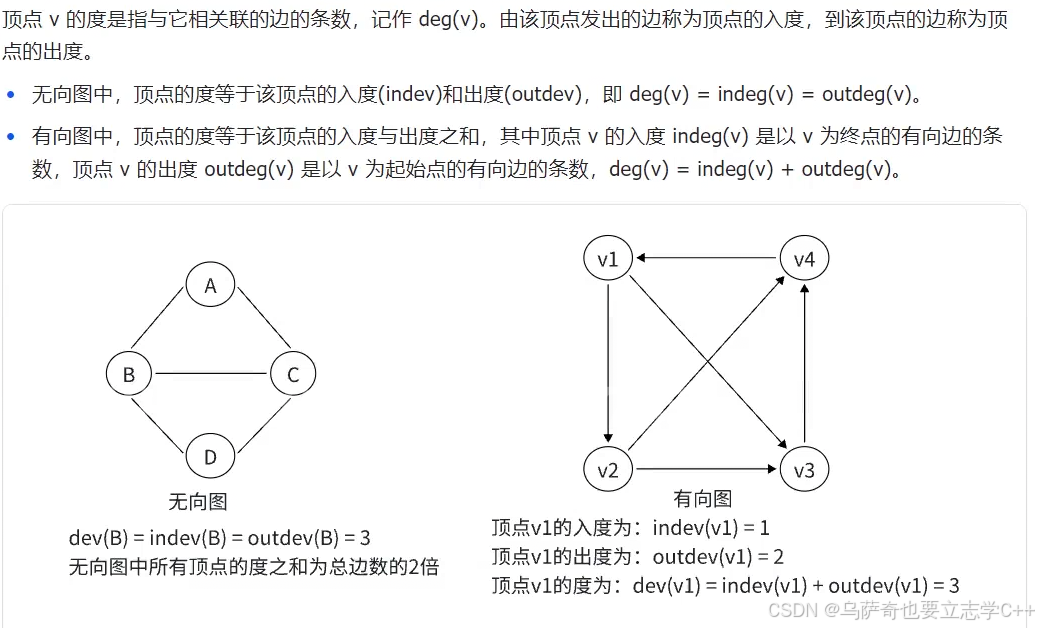
顶点的度
顶点 v 的度是指与它相关联的边的条数,记作 deg(v)。由该顶点发出的边称为顶点的出度,到达该顶点的边称为顶点的入度。
无向图中,顶点的度等于该顶点 的入度(indeg)和出度(outdev),即 deg(v)=indeg(v)=outdeg(v)。
有向图中,顶点的度等于该顶点的入度与出度之和,其中顶点 v 的入度 indeg(v) 是以 v 为终点的有向边的条数,顶点 v 的出度 outdeg(v) 是以 v 为起始点的有向边的条数,deg(v)=indeg(v)+outdeg(v)。
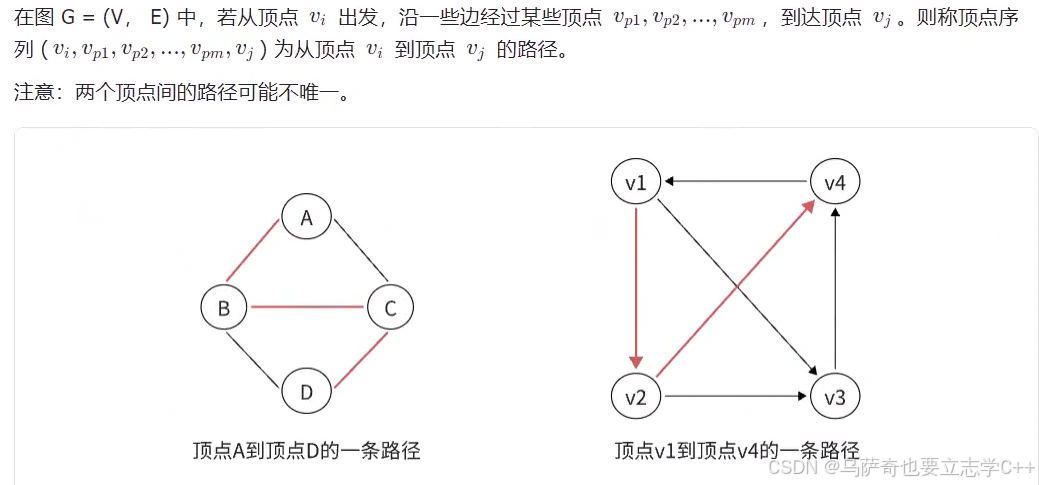
路径
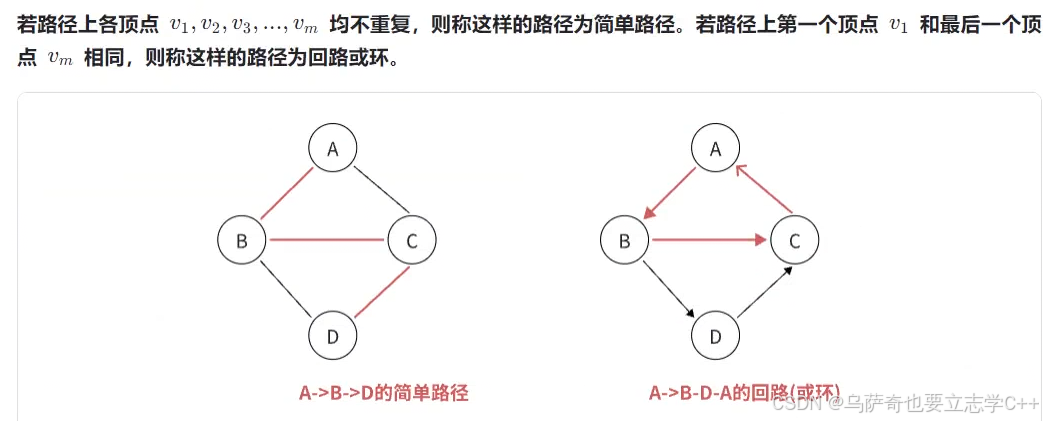
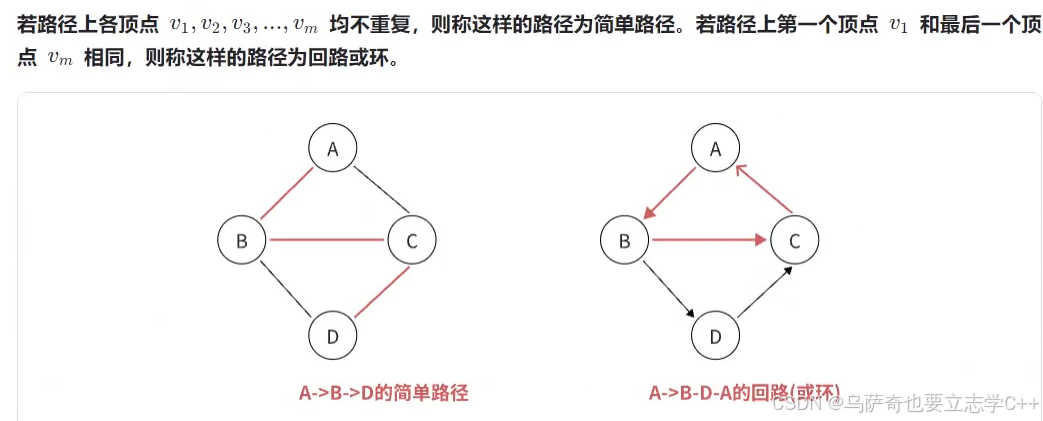
简单路径与回路
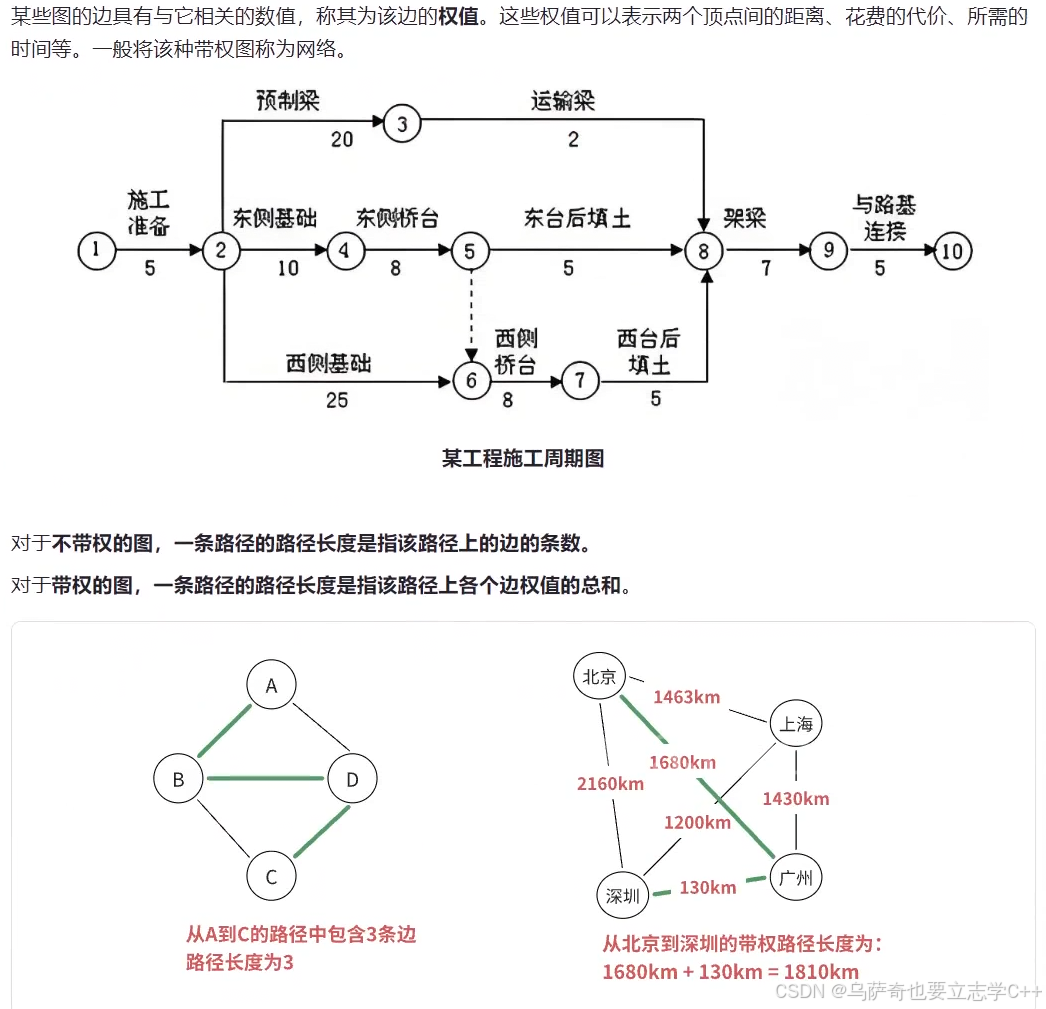
路径长度和带权路径长度
子图
G1_1 和 G1_2 为无向图 G1 的子图,G1_1 为 G1 的生成子图(G1_1包含G1的所有顶点)。
G2_1 和 G2_2 为有向图 G2 的子图,G2_1 为 G2 的生成子图(G2_1包含G2的所有顶点)。
连通图与连通分量
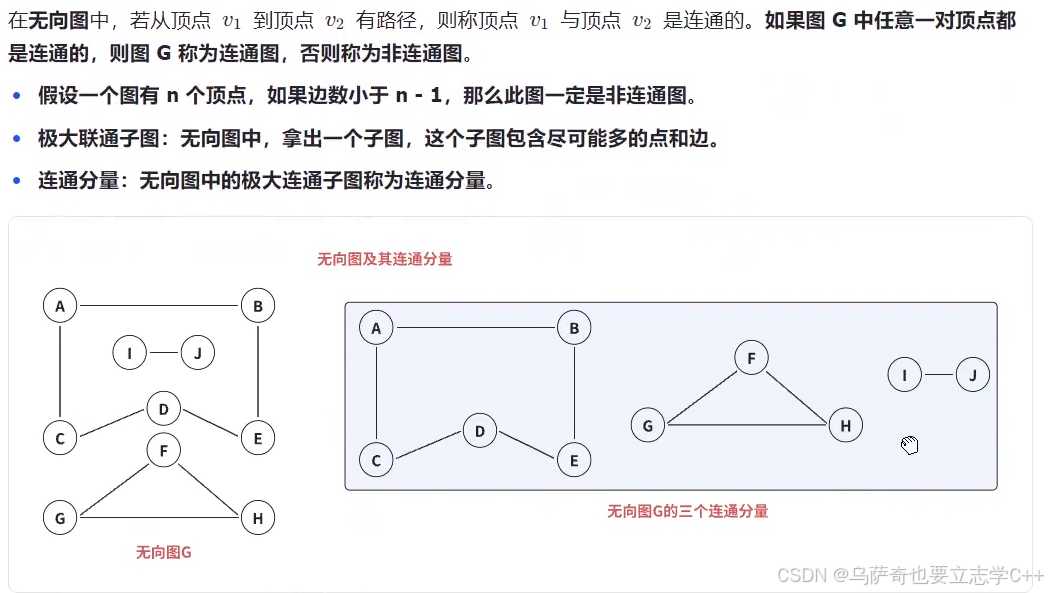
-
连通(连通性)
定义:在无向图中,如果从顶点 v1 到 v2 存在路径,就称 v1 和 v2 是连通的。
连通图:如果图中任意两个顶点都连通,这个图就是连通图;否则是非连通图。
判定条件:若一个有 n 个顶点的图,边数小于 n−1,则它一定是非连通图。
-
极大连通子图
定义:在无向图中,一个子图如果满足:
它本身是连通的;
再加入图中任何其他顶点或边,它就不再连通。那么这个子图就是极大连通子图。
-
连通分量
定义:无向图中的极大连通子图,就称为该图的连通分量。
直观理解:一个非连通图可以被拆分成若干个互不相交的连通子图,每一个这样的子图就是一个连通分量。例如,图中的无向图 G 就被拆分成了 3 个连通分量。
概念关系总结
连通是顶点之间的二元关系。
连通图是满足 "任意两顶点都连通" 这一整体性质的图。
极大连通子图是从图中 "抠" 出来的、不能再大的连通子图。
连通分量就是无向图中的所有极大连通子图,是对非连通图结构的分解。
生成树
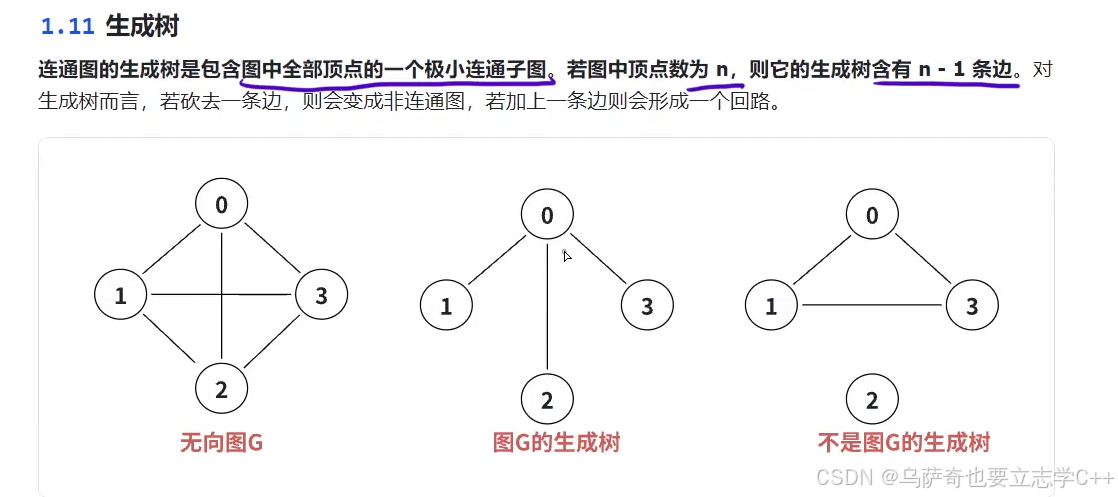
简单理解就是把原始图所有顶点拿出来在保证所有顶点都连通的前提下,用最少的边把它们连起来串成一颗1对多的树。
二、图的存储
图的存储有两种:邻接矩阵和邻接表:
- 其中,邻接表的存储⽅式与树的孩⼦表⽰法完全⼀样。因此,⽤ vector 数组以及链式前向星就能实现。
- ⽽邻接矩阵就是⽤⼀个⼆维数组,其中 edgesij 存储顶点 i 与顶点 j 之间,边的信息。
图的遍历分两种:DFS 和 BFS,和树的遍历⽅式以及实现⽅式完全⼀样。因此,可以仿照树这个数据结构来学习。
邻接矩阵
邻接矩阵,指用一个矩阵 (即二维数组) 存储图中边的信息 (即各个顶点之间的邻接关系),存储顶点之间邻接关系的矩阵称为邻接矩阵。
对于带权图而言,若顶点 vi 和 vj 之间有边相连,则邻接矩阵中对应项存放着该边对应的权值,若顶点 vi 和 vj 不相连,则用 ∞ (若权值都为正数,也可用-1)来代表这两个顶点之间不存在边。
对于不带权的图,可以创建一个二维的 bool 类型的数组,来标记顶点 vi 和 vj 之间有边相连。
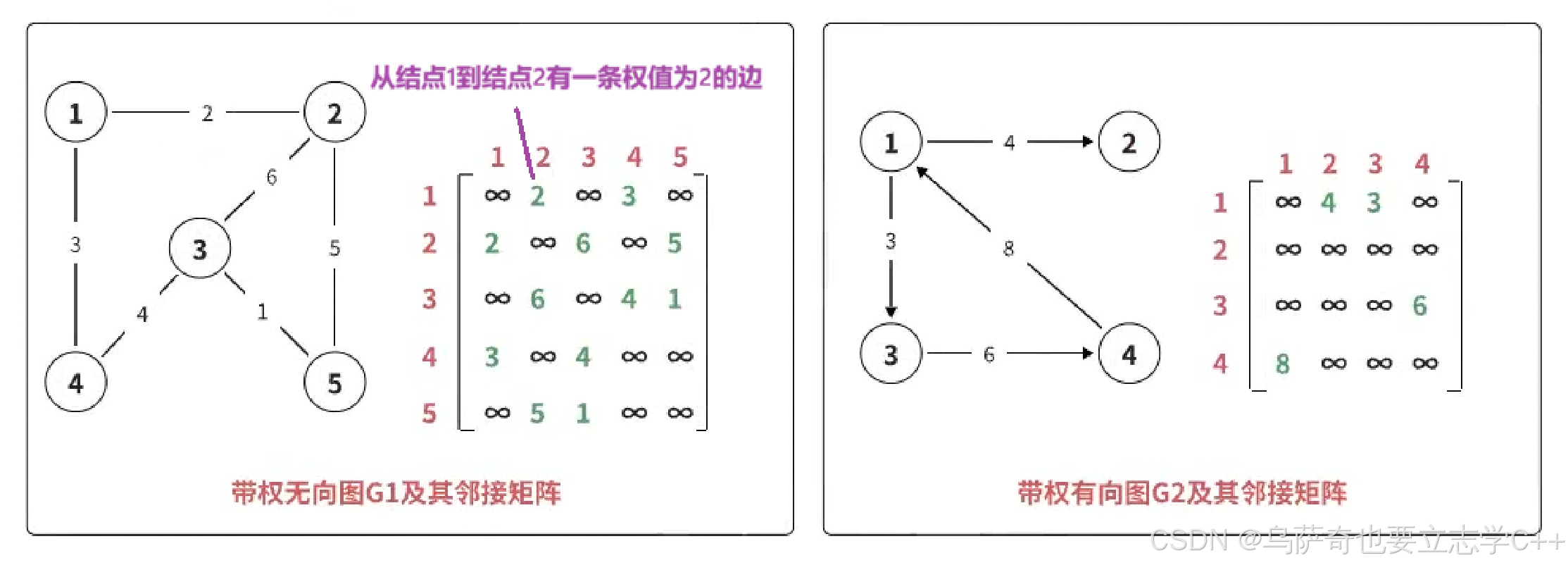
矩阵中元素个数为 n×n,即空间复杂度为 O(n2),n 为顶点个数,和实际边的条数无关,适合存储稠密图。
cpp
#include <iostream>
#include <cstring>
using namespace std;
const int N = 1010;
// 结点个数、边的个数
int n, m;
// i到j有一条权值为edges[i][j]的边
int edges[N][N];
int main()
{
memset(edges, -1, sizeof edges);
cin >> n >> m; // 读入结点个数以及边的个数
for(int i = 1; i <= n; i++)
{
int a, b, c; cin >> a >> b >> c;
// a - b 有一条边,权值为 c
edges[a][b] = c;
// 如果是无向边,需要反过来再存一下
edges[b][a] = c;
}
return 0;
}邻接表
用邻接表存储图类似于我们之前存储树的孩子表示法,孩子表示法是把某个结点的所有孩子结点以链表的形式挂在该节点后面,而对于图来说就是把和某个结点相邻的全部结点以链表的形式挂在该节点后面。
对于链表来说有两种存储方式:vector数组和链式向前星,不理解的读者点这里:vector数组和链式向前星详细介绍
vector 数组
和树的存储⼀模⼀样,只不过如果存在边权的话,我们的 vector 数组⾥⾯放⼀个结构体或者是 pair 即可。
cpp
#include <iostream>
#include <vector>
using namespace std;
// <与哪条边相连,该边的权值>
typedef pair<int, int> PII;
const int N = 1e5 + 10;
// 结点个数、边的个数
int n, m;
//结点i到结点edges[i].first.有一条权值为edges[i].second的边
vector<PII> edges[N];
int main()
{
cin >> n >> m; // 读入结点个数以及边的个数
for(int i = 1; i <= m; i++)
{
int a, b, c; cin >> a >> b >> c;
// a 和 b 之间有一条边,权值为 c
edges[a].push_back({b, c});
// 如果是无向边,需要反过来再存一下
edges[b].push_back({a, c});
}
return 0;
}链式前向星
和树的存储⼀模⼀样,只不过如果存在边权的话,我们多创建⼀维数组w,⽤来存储边的权值即可。
cpp
#include <iostream>
using namespace std;
const int N = 1e5 + 10;
// 链式前向星
int h[N], e[N * 2], ne[N * 2], w[N * 2], id;
int n, m;
// 其实就是把 b 头插到 a 所在的链表后面
void add(int a, int b, int c)
{
id++;
e[id] = b;
w[id] = c; // 多存一个权值信息
ne[id] = h[a];
h[a] = id;
}
int main()
{
cin >> n >> m; // 读入结点个数以及边的个数
for(int i = 1; i <= m; i++)
{
int a, b, c; cin >> a >> b >> c;
// a 和 b 之间有一条边,权值为 c
add(a, b, c); add(b, a, c);
}
return 0;
}数组含义
hN:表头数组,ha 表示从节点 a 出发的第一条边在 e 数组中的下标。初始值为 -1(表示没有边)。
eN*2:存储每条边指向的终点节点编号。
neN* 2:存储同一起点的下一条边的下标,用于构成链表。
wN\*2:存储每条边的权值。
id:全局计数器,用于分配边的下标。
add 函数
这个函数的作用是在图中添加一条从 a 指向 b,权值为 c 的有向边。它采用 "头插法" 将新边插入到以 a 为起点的链表头部:
id++:为新边分配一个唯一的下标。
eid = b:记录这条边指向的终点是 b。
wid = c:记录这条边的权值是 c。
neid = ha:让新边的 ne 指针指向原来的表头,建立链表连接。
ha = id:更新表头,让新边成为从 a 出发的第一条边。
main 函数
首先读入节点数 n 和边数 m。
然后循环 m 次,每次读入一条边的两个端点 a、b 和权值 c。
因为是无向图,所以需要调用两次 add 函数:
add(a, b, c):添加一条从 a 到 b 的边。
add(b, a, c):添加一条从 b 到 a 的边,以表示双向连通。
三、图的遍历
DFS
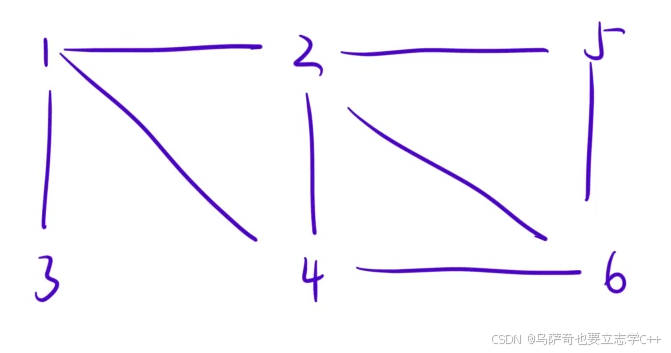
小编以上图为例,用dfs带大家走一遍:
递归:1------>2------>5------>6------>4 此时和4相邻的1、2都遍历过了,所以要递归返回:4------>6,对于6来说6相邻的2、5都遍历过了,故该结点是叶子结点,要继续返回(后续递归返回的结点5、2也是与之相邻的结点都遍历过了,直接返回,小编就不一一说明了):6------>5------>2------>1 此时对于1来说还有3没遍历过,所以继续递归:1------>3,3也是叶子结点,递归返回:3------>1.递归结束。
cpp
//邻接矩阵
#include <iostream>
#include <cstring>
#include <queue>
using namespace std;
const int N = 1010;
int n, m;
int edges[N][N];
bool st[N]; // 标记哪些点已经访问过
void dfs(int u)
{
cout << u << endl;
st[u] = true;
// 遍历所有孩⼦
for (int v = 1; v <= n; v++)
{
// 如果存在 u->v 的边,并且没有遍历过
if (edges[u][v] != -1 && !st[v])
{
dfs(v);
}
}
}
int main()
{
memset(edges, -1, sizeof edges);
cin >> n >> m; // 读⼊结点个数以及边的个数
for (int i = 1; i <= m; i++)
{
int a, b, c; cin >> a >> b >> c;
// a - b 有⼀条边,权值为 c
edges[a][b] = c;
// 如果是⽆向边,需要反过来再存⼀下
edges[b][a] = c;
}
return 0;
}
cpp
//邻接表------vector数组
#include <iostream>
#include <vector>
#include <queue>
using namespace std;
typedef pair<int, int> PII;
const int N = 1e5 + 10;
int n, m;
vector<PII> edges[N];
bool st[N]; // 标记哪些点已经访问过
void dfs(int u)
{
cout << u << endl;
st[u] = true;
// 遍历所有孩⼦
for (auto& t : edges[u])
{
// u->v 的⼀条边,权值为 w
int v = t.first, w = t.second;
if (!st[v])
{
dfs(v);
}
}
}
int main()
{
cin >> n >> m; // 读⼊结点个数以及边的个数
for (int i = 1; i <= m; i++)
{
int a, b, c; cin >> a >> b >> c;
// a 和 b 之间有⼀条边,权值为 c
edges[a].push_back({ b, c });
// 如果是⽆向边,需要反过来再存⼀下
edges[b].push_back({ a, c });
}
return 0;
}
cpp
//邻接表------链式向前星
#include <iostream>
#include <queue>
using namespace std;
const int N = 1e5 + 10;
// 链式前向星
int h[N], e[N * 2], ne[N * 2], w[N * 2], id;
int n, m;
// 其实就是把 b 头插到 a 所在的链表后⾯
void add(int a, int b, int c)
{
id++;
e[id] = b;
w[id] = c; // 多存⼀个权值信息
ne[id] = h[a];
h[a] = id;
}
bool st[N];
void dfs(int u)
{
cout << u << endl;
st[u] = true;
// 遍历所有的孩⼦
for (int i = h[u]; i; i = ne[i])
{
// u->v 的⼀条边
int v = e[i];
if (!st[v])
{
dfs(v);
}
}
}
int main()
{
cin >> n >> m; // 读⼊结点个数以及边的个数
for (int i = 1; i <= m; i++)
{
int a, b, c; cin >> a >> b >> c;
// a 和 b 之间有⼀条边,权值为 c
add(a, b, c); add(b, a, c);
}
return 0;
}BFS
cpp
//临接矩阵
#include <iostream>
#include <cstring>
#include <queue>
using namespace std;
const int N = 1010;
int n, m;
int edges[N][N];
bool st[N]; // 标记哪些点已经访问过
void bfs(int u)
{
queue<int> q;
q.push(u);
st[u] = true;
while (q.size())
{
auto a = q.front(); q.pop();
cout << a << endl;
for (int b = 1; b <= n; b++)
{
if (edges[a][b] != -1 && !st[b])
{
q.push(b);
st[b] = true;
}
}
}
}
int main()
{
memset(edges, -1, sizeof edges);
cin >> n >> m; // 读⼊结点个数以及边的个数
for (int i = 1; i <= m; i++)
{
int a, b, c; cin >> a >> b >> c;
// a - b 有⼀条边,权值为 c
edges[a][b] = c;
// 如果是⽆向边,需要反过来再存⼀下
edges[b][a] = c;
}
return 0;
}
cpp
//邻接表------vector数组
#include <iostream>
#include <vector>
#include <queue>
using namespace std;
typedef pair<int, int> PII;
const int N = 1e5 + 10;
int n, m;
vector<PII> edges[N];
bool st[N]; // 标记哪些点已经访问过
void bfs(int u)
{
queue<int> q;
q.push(u);
st[u] = true;
while (q.size())
{
auto a = q.front(); q.pop();
cout << a << endl;
for (auto& t : edges[a])
{
int b = t.first, c = t.second;
if (!st[b])
{
q.push(b);
st[b] = true;
}
}
}
}
int main()
{
cin >> n >> m; // 读⼊结点个数以及边的个数
for (int i = 1; i <= m; i++)
{
int a, b, c; cin >> a >> b >> c;
// a 和 b 之间有⼀条边,权值为 c
edges[a].push_back({ b, c });
// 如果是⽆向边,需要反过来再存⼀下
edges[b].push_back({ a, c });
}
return 0;
}
cpp
//邻接表------链式向前星
#include <iostream>
#include <queue>
using namespace std;
const int N = 1e5 + 10;
// 链式前向星
int h[N], e[N * 2], ne[N * 2], w[N * 2], id;
int n, m;
// 其实就是把 b 头插到 a 所在的链表后⾯
void add(int a, int b, int c)
{
id++;
e[id] = b;
w[id] = c; // 多存⼀个权值信息
ne[id] = h[a];
h[a] = id;
}
bool st[N];
void bfs(int u)
{
queue<int> q;
q.push(u);
st[u] = true;
while (q.size())
{
auto a = q.front(); q.pop();
cout << a << endl;
for (int i = h[a]; i; i = ne[i])
{
int b = e[i], c = w[i];
if (!st[b])
{
q.push(b);
st[b] = true;
}
}
}
}
int main()
{
cin >> n >> m; // 读⼊结点个数以及边的个数
for (int i = 1; i <= m; i++)
{
int a, b, c; cin >> a >> b >> c;
// a 和 b 之间有⼀条边,权值为 c
add(a, b, c); add(b, a, c);
}
return 0;
}以上就是小编分享的全部内容了,如果觉得不错还请留下免费的关注和收藏
如果有建议欢迎通过评论区或私信留言,感谢您的大力支持。
一键三连好运连连哦~~
