

🔥个人主页:北极的代码(欢迎来访)
🎬作者简介:java后端学习者
✨命运的结局尽可永在,不屈的挑战却不可须臾或缺!
前言:
大家好,我是代码不加冰,又到了每日刷题的时间,我们继续攻克二叉树相关的题目。
摘要:
本文探讨了如何找出二叉树最底层最左边节点的值,提出了两种解法:BFS层序遍历和DFS深度优先搜索。BFS解法通过队列按层遍历,记录每层第一个节点,最终返回最后一层的第一个节点值。DFS解法则利用递归优先遍历左子树,当遇到更深层的叶子节点时更新结果。文章通过示例和详细执行步骤演示了两种方法的实现过程,并分析了其核心机制。最终指出DFS通过先左后右的遍历顺序和深度比较机制,能够准确找到最底层最左边的节点。两种方法各有特点,BFS直观易理解,DFS代码更简洁。
题目背景:
给定一个二叉树的 根节点
root,请找出该二叉树的 最底层 最左边节点的值。假设二叉树中至少有一个节点。
示例 1:
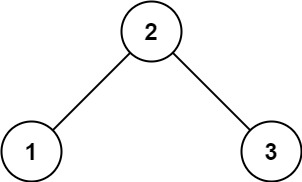
输入: root = [2,1,3] 输出: 1示例 2:
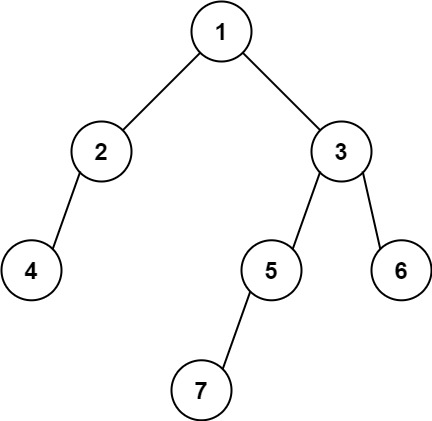
输入: [1,2,3,4,null,5,6,null,null,7] 输出: 7提示:
- 二叉树的节点个数的范围是
[1,104]-231 <= Node.val <= 231 - 1
题目解析:
我们根据题目来看,要我们找到二叉树最底层,左下角的节点的值,首先我们应该找到二叉树深度最大的那一层,然后找到左子节点。因此就这样整体来看,层序遍历很容易实现,最后一层就是最深的地方,有我们要找的树左下角的值。但递归同样也可以实现,我们都来实现一下。
解法一:BFS(层序遍历)--- 记录每层第一个节点
核心思想
一层一层往下遍历,记录每一层的第一个节点的值。当遍历完所有层后,最后一次记录的值就是最底层最左边的值。
我们先:
创建一个队列,先把根节点放进去
初始化
result为根节点的值(如果树只有一层,答案就是根节点)
java
while (!queue.isEmpty()) { int size = queue.size();
while 循环:只要队列里还有节点,就继续处理
size:当前层的节点数量 (因为队列里放的就是当前层的所有节点)
java
for (int i = 0; i < size; i++) { TreeNode node = queue.poll();
遍历当前层的每一个节点
queue.poll():从队列头部取出一个节点
java
if (i == 0) { result = node.val; }
关键 :如果
i == 0,说明这是当前层的第一个节点(最左边)把这个节点的值更新到
result中随着一层一层往下,
result依次被更新为:第1层最左边 → 第2层最左边 → 第3层最左边 → ... → 最后一层最左边
java
if (node.left != null) queue.offer(node.left); if (node.right != null) queue.offer(node.right);
把当前节点的左孩子和右孩子加入队列(成为下一层的节点)
因为队列是先进先出,所以下一层的节点会按从左到右的顺序被处理
java
return result;
- 循环结束后,
result记录的就是最后一层第一个节点的值
举例演示
树:
1 / \ 2 3 / / \ 4 5 6 / 7
层数 当前层节点 第一个节点 result更新为 第1层 1 1 1 第2层 2, 3 2 2 第3层 4, 5, 6 4 4 第4层 7 7 7 关于while循环和for循环
当我们需要按层处理 时(比如记录每层的第一个节点),就必须知道当前这一层有多少个节点。
size在for循环开始前就固定了,它记录的是当前层的节点数量。这样:
for 循环只处理当前层的 size 个节点
新加入的孩子节点不会在本轮被处理,留到下一轮
所以 i == 0 就能准确知道这是当前层的第一个节点
执行过程可视化
以树为例:
text
1 / \ 2 3 / / \ 4 5 6第1轮
while循环(处理第1层)
步骤 操作 队列变化 说明 开始 队列 = 1 - - int size = queue.size()size = 1 1 记录第1层有1个节点 for第1次迭代poll()取出1\[\] i=0,记录result=1 加入1的孩子 2,3 左2右3 for结束- 2,3 第1层处理完毕 第2轮
while循环(处理第2层)
步骤 操作 队列变化 说明 开始 队列 = 2,3 - - int size = queue.size()size = 2 2,3 记录第2层有2个节点 for第1次迭代poll()取出23 i=0,记录result=2 加入2的孩子 3,4 左4 for第2次迭代poll()取出34 i=1,不记录 加入3的孩子 4,5,6 左5右6 for结束- 4,5,6 第2层处理完毕 第3轮
while循环(处理第3层)
步骤 操作 队列变化 说明 int size = queue.size()size = 3 4,5,6 记录第3层有3个节点 for第1次迭代poll()取出45,6 i=0,记录result=4 for第2次迭代poll()取出56 i=1,不记录 for第3次迭代poll()取出6\[\] i=2,不记录 while判断队列为空 \[\] 循环结束 最终 result = 4 (最底层最左边的节点)
对比之下,我们还有一个优化的简单方法
在上面中,我们需要利用for循环来确定每层,然后还要处理每层的第一个节点,这样做起来有点麻烦,我们可以灵活利用队列的性质,我们在入队的时候从右往左添加,因此每次先处理的都是右节点,左节点都是后处理的,因此这样循环下去,最后一个节点就是最后一层的左节点,就是我们的答案,我们不需要处理具体是哪一层,也不需要处理第一个节点,比较巧妙。
解法二:BFS(层序遍历)- 从右向左入队
1
/ \
2 3
/ / \
4 5 6
/
7完整执行流程表
| 轮次 | 取出前队列 | poll()取出 |
队列变化 | 加入孩子 | 取出后队列 |
|---|---|---|---|---|---|
| 1 | 1 | 1 | \[\] | 先加右3,再加左2 | 3, 2 |
| 2 | 3, 2 | 3 | 2 | 先加右6,再加左5 | 2, 6, 5 |
| 3 | 2, 6, 5 | 2 | 6, 5 | 先加右(null),再加左4 | 6, 5, 4 |
| 4 | 6, 5, 4 | 6 | 5, 4 | 右null,左null | 5, 4 |
| 5 | 5, 4 | 5 | 4 | 先加右7,再加左(null) | 4, 7 |
| 6 | 4, 7 | 4 | 7 | 右null,左null | 7 |
| 7 | 7 | 7 | \[\] | 右null,左null | \[\] |
循环结束,返回 node.val = 7
解法三:DFS(深度优先搜索)- 优先遍历左子树
java
java
class Solution {
private int maxDepth = -1;
private int result = 0;
public int findBottomLeftValue(TreeNode root) {
dfs(root, 0);
return result;
}
private void dfs(TreeNode node, int depth) {
if (node == null) return;
// 到达叶子节点时检查
if (node.left == null && node.right == null) {
if (depth > maxDepth) {
maxDepth = depth;
result = node.val;
}
return;
}
// 关键:先左后右,确保同深度时优先记录左边的
dfs(node.left, depth + 1);
dfs(node.right, depth + 1);
}
}递归树结构
dfs(1, depth=0)
|
┌────────────────┴────────────────┐
│ │
dfs(2, 1) dfs(3, 1)
│ │
dfs(4, 2) ┌─────────┴─────────┐
│ │ │
叶子节点4 dfs(5, 2) dfs(6, 2)
│ │ │
更新答案 dfs(7, 3) 叶子节点6
│ │ │
叶子节点7 更新答案?
更新答案逐步执行详解
全局变量初始状态
text
maxDepth = -1 result = 0第1步:
dfs(1, 0)text
节点: 1, 深度: 0 检查: 不是叶子节点(有左孩子2和右孩子3) 先递归左子树: dfs(2, 1)第2步:
dfs(2, 1)text
节点: 2, 深度: 1 检查: 不是叶子节点(有左孩子4) 先递归左子树: dfs(4, 2)第3步:
dfs(4, 2)第一次更新答案text
节点: 4, 深度: 2 检查: 是叶子节点(左右都为null) depth(2) > maxDepth(-1) ? ✅ 是 更新: maxDepth = 2, result = 4 return (返回上层) 此时状态: maxDepth=2, result=4text
1 / \ 2 3 / / \ 4 ← 当前 5 6 / 7第4步:回到
dfs(2, 1),继续执行text
节点2的递归左子树完成
继续执行: dfs(2的右子树, depth+1)
节点2的右孩子为null → dfs(null, 2) 直接返回
dfs(2, 1) 执行完毕,返回到 dfs(1, 0)
第5步:回到
dfs(1, 0),继续执行右子树text
节点1的左子树执行完毕 继续执行右子树: dfs(3, 1)第6步:
dfs(3, 1)text
节点: 3, 深度: 1 检查: 不是叶子节点(有左孩子5和右孩子6) 先递归左子树: dfs(5, 2)第7步:
dfs(5, 2)text
节点: 5, 深度: 2 检查: 不是叶子节点(有左孩子7) 先递归左子树: dfs(7, 3)第8步:
dfs(7, 3)第二次更新答案text
节点: 7, 深度: 3 检查: 是叶子节点(左右都为null) depth(3) > maxDepth(2) ? ✅ 是 更新: maxDepth = 3, result = 7 return 此时状态: maxDepth=3, result=7text
1 / \ 2 3 / / \ 4 5 6 / 7 ← 当前第9步:回到
dfs(5, 2),继续执行text
节点5的左子树完成 继续执行: dfs(5的右子树, depth+1) 节点5的右孩子为null → dfs(null, 3) 直接返回 dfs(5, 2) 执行完毕,返回到 dfs(3, 1)第10步:回到
dfs(3, 1),继续执行右子树text
节点3的左子树执行完毕 继续执行右子树: dfs(6, 2)第11步:
dfs(6, 2)text
节点: 6, 深度: 2 检查: 是叶子节点(左右都为null) depth(2) > maxDepth(3) ? ❌ 否 (2 > 3 为假) 不更新答案 return 此时状态不变: maxDepth=3, result=7text
1 / \ 2 3 / / \ 4 5 6 ← 当前 / 7第12步:所有递归完成
text
dfs(6, 2) 返回 → dfs(3, 1) 返回 → dfs(1, 0) 返回 最终: result = 7 ✅
📈 深度与答案变化追踪
| 执行顺序 | 节点 | 深度 | 是否叶子 | depth > maxDepth? | maxDepth变化 | result变化 |
|---|---|---|---|---|---|---|
| 初始 | - | - | - | - | -1 → -1 | 0 → 0 |
| 1 | 1 | 0 | ❌ | - | -1 | 0 |
| 2 | 2 | 1 | ❌ | - | -1 | 0 |
| 3 | 4 | 2 | ✅ | 2 > -1 ✅ | -1 → 2 | 0 → 4 |
| 4 | 2(右null) | - | - | - | 2 | 4 |
| 5 | 3 | 1 | ❌ | - | 2 | 4 |
| 6 | 5 | 2 | ❌ | - | 2 | 4 |
| 7 | 7 | 3 | ✅ | 3 > 2 ✅ | 2 → 3 | 4 → 7 |
| 8 | 5(右null) | - | - | - | 3 | 7 |
| 9 | 6 | 2 | ✅ | 2 > 3 ❌ | 3 | 7 |
| 结束 | - | - | - | - | 3 | 7 |
为什么 DFS 能找到最底层最左边的节点
核心机制
| 机制 | 作用 |
|---|---|
| 先左后右 | 确保同一深度下,左边的节点先被访问 |
| depth > maxDepth | 只有遇到更深的叶子节点时才更新(等于时不更新) |
| 叶子节点才更新 | 只有最底层的节点才有资格成为答案 |
题目答案:
java
import java.util.*;
class Solution {
public int findBottomLeftValue(TreeNode root) {
Queue<TreeNode> queue = new LinkedList<>();
queue.offer(root);
int result = root.val;
while (!queue.isEmpty()) {
int size = queue.size();
for (int i = 0; i < size; i++) {
TreeNode node = queue.poll();
// 每层的第一个节点记录为结果
if (i == 0) {
result = node.val;
}
if (node.left != null) {
queue.offer(node.left);
}
if (node.right != null) {
queue.offer(node.right);
}
}
}
return result;
}
}
java
import java.util.*;
class Solution {
public int findBottomLeftValue(TreeNode root) {
Queue<TreeNode> queue = new LinkedList<>();
queue.offer(root);
TreeNode node = root;
while (!queue.isEmpty()) {
node = queue.poll();
// 关键:先右后左,这样最后一个节点就是最底层最左边的
if (node.right != null) {
queue.offer(node.right);
}
if (node.left != null) {
queue.offer(node.left);
}
}
return node.val;
}
}
java
import java.util.*;
class Solution {
public int findBottomLeftValue(TreeNode root) {
Queue<TreeNode> queue = new LinkedList<>();
queue.offer(root);
TreeNode node = root;
while (!queue.isEmpty()) {
node = queue.poll();
// 关键:先右后左,这样最后一个节点就是最底层最左边的
if (node.right != null) {
queue.offer(node.right);
}
if (node.left != null) {
queue.offer(node.left);
}
}
return node.val;
}
}结语:如果对你有帮助,请**点赞,关注,收藏,**你的支持就是我最大的鼓励!