一、视频椒盐噪声添加与中值滤波
椒盐噪声是图像中常见的噪声类型,表现为随机出现的黑白亮点 / 暗点。我们可以通过编程为视频逐帧添加椒盐噪声,并使用中值滤波进行降噪处理。
1. 核心代码实现
python
import cv2
import numpy as np
# 定义添加椒盐噪声的函数
def add_peppersalt_noise(image, n=10000):
# 避免修改原图,复制帧数据
result = image.copy()
# 获取单帧图像的高、宽
h, w = image.shape[:2]
# 生成n个噪声点
for i in range(n):
# 随机生成噪声点的坐标
x = np.random.randint(0, h)
y = np.random.randint(0, w)
# 随机生成黑色(0)或白色(255)噪声
if len(image.shape) == 3: # 彩色图(3通道)
result[x, y] = [0, 0, 0] if np.random.randint(0, 2) == 0 else [255, 255, 255]
else: # 灰度图(单通道)
result[x, y] = 0 if np.random.randint(0, 2) == 0 else 255
return result
# 打开视频文件(摄像头用0)
video_capture = cv2.VideoCapture('test.avi')
# 检查视频是否成功打开
if not video_capture.isOpened():
print("无法打开视频文件/摄像头!")
exit()
# 循环读取视频帧(逐帧处理)
while True:
ret, frame = video_capture.read()
# 读取失败(视频结束)则退出
if not ret:
break
# 对当前帧添加椒盐噪声
noise_frame = add_peppersalt_noise(frame, n=10000)
# 中值滤波降噪(核大小为奇数)
median = cv2.medianBlur(noise_frame, 3)
# 显示原图、加噪声帧、滤波后帧
cv2.imshow('原视频', frame)
cv2.imshow('噪声处理的视频', noise_frame)
cv2.imshow('平滑处理后的视频', median)
# 按ESC键(27)退出,60ms/帧控制播放速度
if cv2.waitKey(60) == 27:
break
# 释放资源,关闭窗口
video_capture.release()
cv2.destroyAllWindows()2. 关键知识点解析
- 椒盐噪声生成:通过随机生成坐标点,为像素赋值 0(黑色)或 255(白色),模拟椒盐噪声;
- 逐帧处理 :视频本质是连续的图像帧,通过
cv2.VideoCapture.read()逐帧读取并处理; - 中值滤波 :
cv2.medianBlur()是处理椒盐噪声的最优算法之一,通过取邻域像素中值替换当前像素,有效去除孤立噪声点。
运行结果(出现乱码问题):
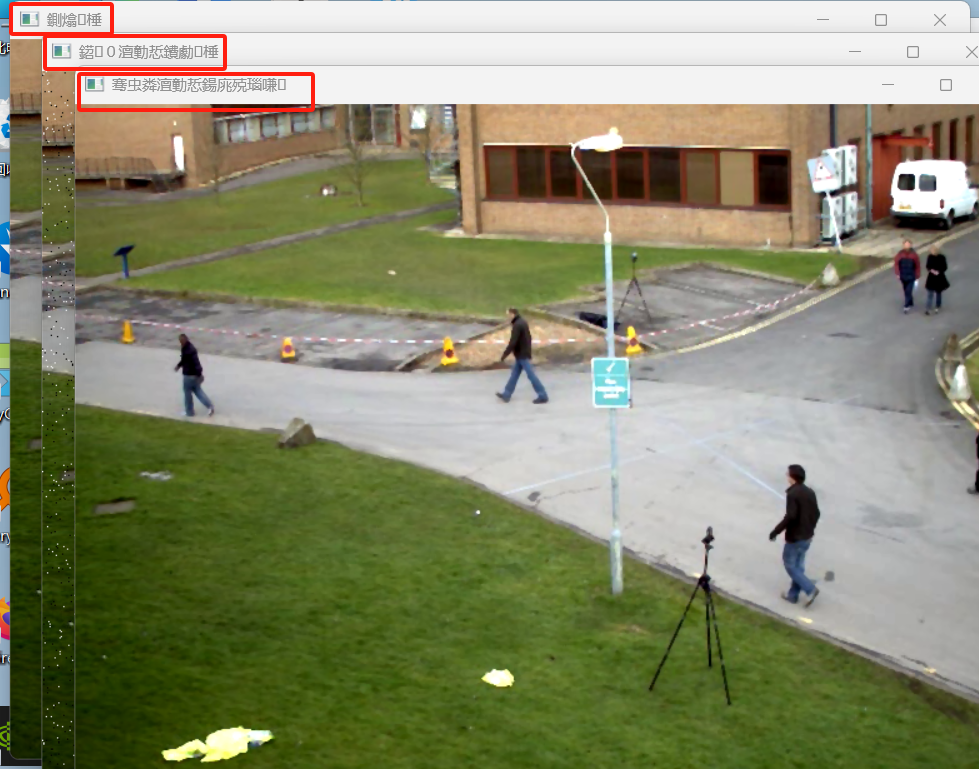
二、 PyCharm 及系统配置改为中文模式(完整步骤)
一、步骤 1:
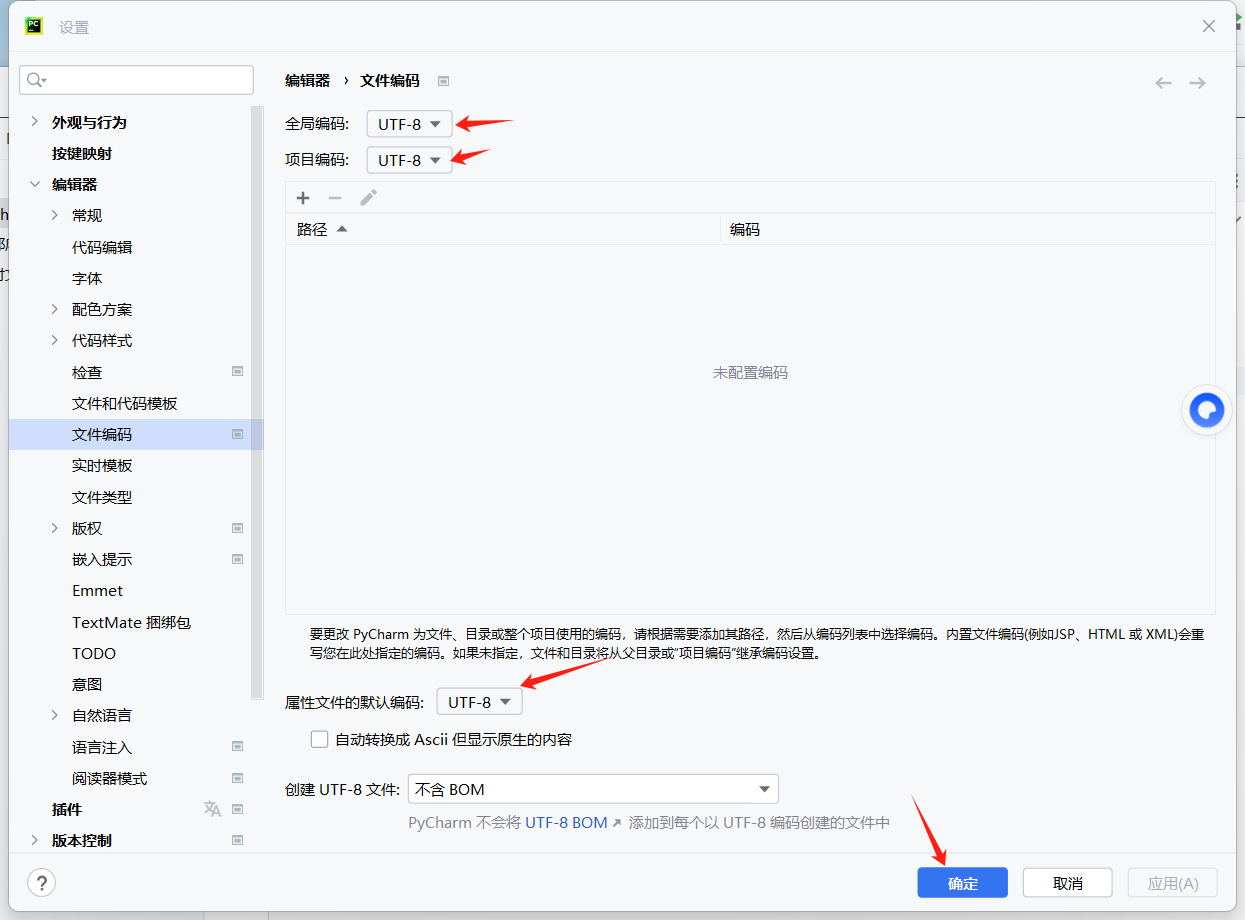
修改 PyCharm 编码配置(保持 UTF-8,适配中文)
UTF-8 是兼容中文的最优编码,无需更换,仅确认配置为中文环境适配:
- 打开 PyCharm → 点击顶部菜单栏【File】→ 选择【Settings】(快捷键
Ctrl+Alt+S)。 - 依次展开:【Editor】→【File Encodings】(中文界面下显示:【编辑器】→【文件编码】)。
- 确保以下 3 个选项全部设置为
UTF-8(中文显示为「UTF-8」):- Global Encoding(全局编码)
- Project Encoding(项目编码)
- Default encoding for properties files(属性文件的默认编码)
- 点击【OK】(中文:【确定】)保存配置。
二、步骤 2:
修改 PyCharm 启动参数(强制中文编码 + 中文界面)
修正原步骤笔误,同时添加中文界面参数,从根源让 PyCharm 显示中文:
-
打开 PyCharm → 点击顶部菜单栏【Help】→ 选择【Edit Custom VM Options...】(中文:【帮助】→【编辑自定义 VM 选项...】)。
-
若弹出「是否创建文件」提示,点击【Create】(中文:【创建】)确认。
-
在打开的文件末尾添加以下 3 行代码(修正原步骤中 -Dconsole.encoding=UTF-8 被拆分的错误):
python# 强制中文编码(解决中文乱码) -Dfile.encoding=UTF-8 -Dconsole.encoding=UTF-8 # 强制PyCharm界面显示中文 -Duser.language=zh -Duser.country=CN -
按 Ctrl+S 保存文件 → 关闭 PyCharm 所有窗口,重启 PyCharm 使参数生效。

三、步骤 3:
修改 Windows 系统区域设置(适配中文,解决 OpenCV 乱码)
这是解决 OpenCV 窗口中文乱码的关键,全程中文操作:
-
按下 Windows 键 + R → 输入
control→ 回车,打开【控制面板】。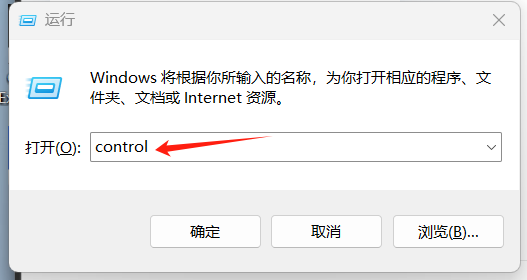
-
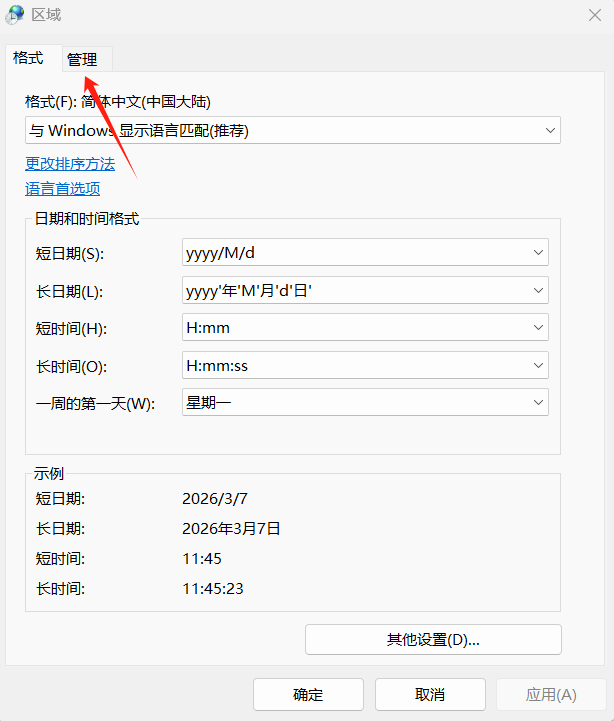
点击【时钟和区域】(部分系统显示:【时间和语言】→【区域】)。

-
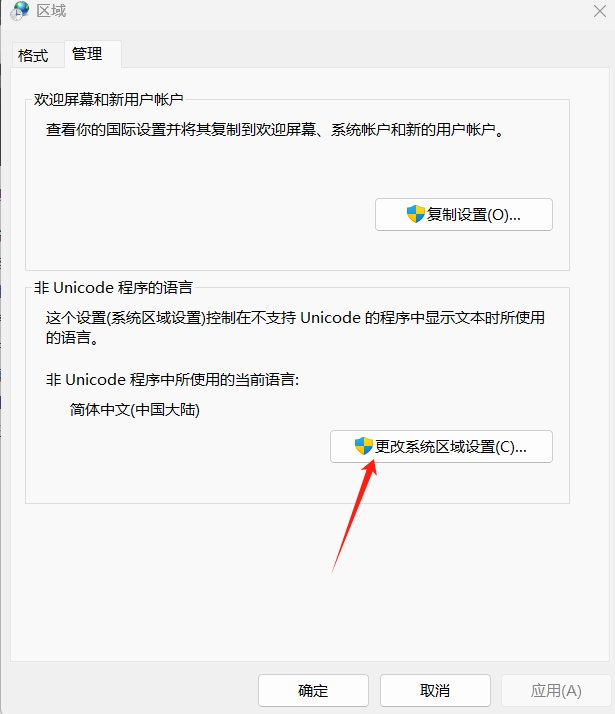
选择【区域】→ 切换到【管理】选项卡(中文界面:【区域】→【管理】)。
-
点击【更改系统区域设置】(中文:【更改系统区域设置】):
- 在弹出的窗口中,「当前系统区域设置」选择【中文 (简体,中国)】。
- 取消勾选【Beta 版:使用 Unicode UTF-8 提供全球语言支持】(这是 OpenCV 窗口中文乱码的核心原因)。
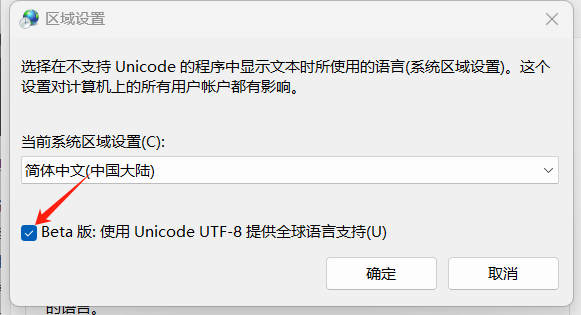
-
点击【确定】→ 按提示重启电脑,使系统设置生效。
无中文乱码的运行结果:

三、图像形态学操作
形态学操作是基于形状的图像处理方法,核心是通过结构元素(kernel)对图像进行变换,常见操作包括腐蚀、膨胀、开运算、闭运算。
1. 图像腐蚀
腐蚀操作会 "收缩" 图像中的白色区域(前景),可用于去除小的亮斑、细化轮廓。
python
import cv2
import numpy as np
# 读取图像
sun = cv2.imread('sun.png')
cv2.imshow('原始图像', sun)
# 定义结构元素(核),大小为3×3,类型为uint8
kernel = np.ones((3, 3), np.uint8)
# 执行腐蚀操作,迭代次数为2
erosion_1 = cv2.erode(sun, kernel, iterations=2)
cv2.imshow('腐蚀后图像', erosion_1)
cv2.waitKey(0)参数说明:
• kernel:结构元素大小,越大腐蚀效果越明显;
• iterations:迭代次数,次数越多,腐蚀程度越深。
2. 图像膨胀
膨胀操作与腐蚀相反,会 "扩张" 图像中的白色区域,可用于填补前景中的小孔、连接断裂的轮廓。
python
# 读取图像
wenzi = cv2.imread('wenzi.png')
cv2.imshow('原始文字图像', wenzi)
# 定义2×2结构元素
kernel = np.ones((2, 2), np.uint8)
# 执行膨胀操作,迭代次数为2
wenzi_new = cv2.dilate(wenzi, kernel, iterations=2)
cv2.imshow('膨胀后文字图像', wenzi_new)
cv2.waitKey(0)3. 开运算与闭运算
开运算和闭运算是腐蚀、膨胀的组合操作,适用于更复杂的图像修复场景。
(1)开运算:先腐蚀后膨胀
作用:平滑轮廓、断开窄的狭颈、消除细的突出物(如指纹上的毛刺)。
python
# 读取指纹图像
zhiwen = cv2.imread('zhiwen.png')
cv2.imshow('原始指纹', zhiwen)
kernel = np.ones((2, 2), np.uint8)
# 开运算:cv2.MORPH_OPEN
zhiwen_open = cv2.morphologyEx(zhiwen, cv2.MORPH_OPEN, kernel)
cv2.imshow('开运算后指纹', zhiwen_open)
cv2.waitKey(0)(2)闭运算:先膨胀后腐蚀
作用:弥合间断、填补孔洞、连接断裂的轮廓(如修复断裂的指纹)。
python
# 读取断裂的指纹图像
zhiwen_duan = cv2.imread('zhiwen_duan.png')
cv2.imshow('断裂指纹', zhiwen_duan)
kernel = np.ones((4, 4), np.uint8)
# 闭运算:cv2.MORPH_CLOSE
zhiwen_close = cv2.morphologyEx(zhiwen_duan, cv2.MORPH_CLOSE, kernel)
cv2.imshow('闭运算后指纹', zhiwen_close)
cv2.waitKey(0)4. 形态学梯度运算
形态学梯度是膨胀图像 - 腐蚀图像的结果,能够突出图像中灰度变化剧烈的区域(即边缘),常用来提取物体的轮廓。
python
import cv2
import numpy as np
# 读取文字图像
wenzi = cv2.imread('wenzi.png')
cv2.imshow('原始文字', wenzi)
# 定义2×2结构元素
kernel = np.ones((2,2), np.uint8)
# 单独执行膨胀操作
pz_wenzi = cv2.dilate(wenzi, kernel, iterations=1)
cv2.imshow('膨胀后文字', pz_wenzi)
# 单独执行腐蚀操作
fs_wenzi = cv2.erode(wenzi, kernel, iterations=1)
cv2.imshow('腐蚀后文字', fs_wenzi)
# 形态学梯度(膨胀-腐蚀)
bianyuan = cv2.morphologyEx(wenzi, cv2.MORPH_GRADIENT, kernel)
cv2.imshow('文字边缘(梯度运算)', bianyuan)
cv2.waitKey(0)
cv2.destroyAllWindows()原理与作用:
- 膨胀会让前景区域变大,腐蚀会让前景区域变小,两者的差值恰好能勾勒出前景的边缘;
- 相比传统边缘检测算法(如 Canny),形态学梯度对低对比度图像的边缘提取更稳定,且计算速度更快。
5. 顶帽与黑帽操作
顶帽和黑帽是基于开运算、闭运算的衍生操作,主要用于提取图像中局部亮 / 暗的细节特征。
(1)顶帽操作(TOPHAT)
公式 :顶帽 = 原始图像 - 开运算结果作用:提取比周围区域亮的细节(如深色背景中的亮斑、文字)。
(2)黑帽操作(BLACKHAT)
公式 :黑帽 = 闭运算结果 - 原始图像作用:提取比周围区域暗的细节(如浅色背景中的暗斑、瑕疵)。
python
import cv2
import numpy as np
# 读取图像
sun = cv2.imread('sun.png')
cv2.imshow('原始图像', sun)
# 定义2×2结构元素
kernel = np.ones((2,2), np.uint8)
# 开运算(用于对比)
open_sun = cv2.morphologyEx(sun, cv2.MORPH_OPEN, kernel)
cv2.imshow('开运算结果', open_sun)
# 顶帽操作
tophat = cv2.morphologyEx(sun, cv2.MORPH_TOPHAT, kernel)
cv2.imshow('顶帽操作结果', tophat)
# 闭运算(用于对比)
close_sun = cv2.morphologyEx(sun, cv2.MORPH_CLOSE, kernel)
cv2.imshow('闭运算结果', close_sun)
# 黑帽操作
blackhat = cv2.morphologyEx(sun, cv2.MORPH_BLACKHAT, kernel)
cv2.imshow('黑帽操作结果', blackhat)
cv2.waitKey(0)
cv2.destroyAllWindows()应用场景:
• 顶帽:检测纸张上的白色划痕、提取复杂背景中的亮色文字;
• 黑帽:检测金属表面的黑色瑕疵、识别织物上的暗斑