1.YOLO 简介
(1)YOLO含义
- YOLO 是 You Only Look Once 的缩写,意思是只看一眼就能检测出目标。
(2)一些概念
- mAP (平均精度): mean Average Precision
2.YOLO v1
(1)原理(流程)
-
第一步 图像分割 S×S :
-
将图像分割为 S×S 个网格。若一个目标的中心落在某个网格中,那这个网格就负责来预测这个目标,比如下图:
-

-
第二步 每个网格预测 B(一般取2) 个 bounding box 和 C 个类别的分数:
-
bounding box 包含5个参数 :4个位置参数x,y,w,h 和 1个confidence值。其中x,y相对于小网格,w,h相对于整个图像的宽高,数值都在0~1,这四个参数用于预测bounding box的位置。
-
confidence = Pr(Object) × IOU。 Pr(Object)表示是否存在目标,存在取1,不存在取0。而IOU就是bounding box和真实目标框的交并比。所以confidence可以简单的理解为IOU。
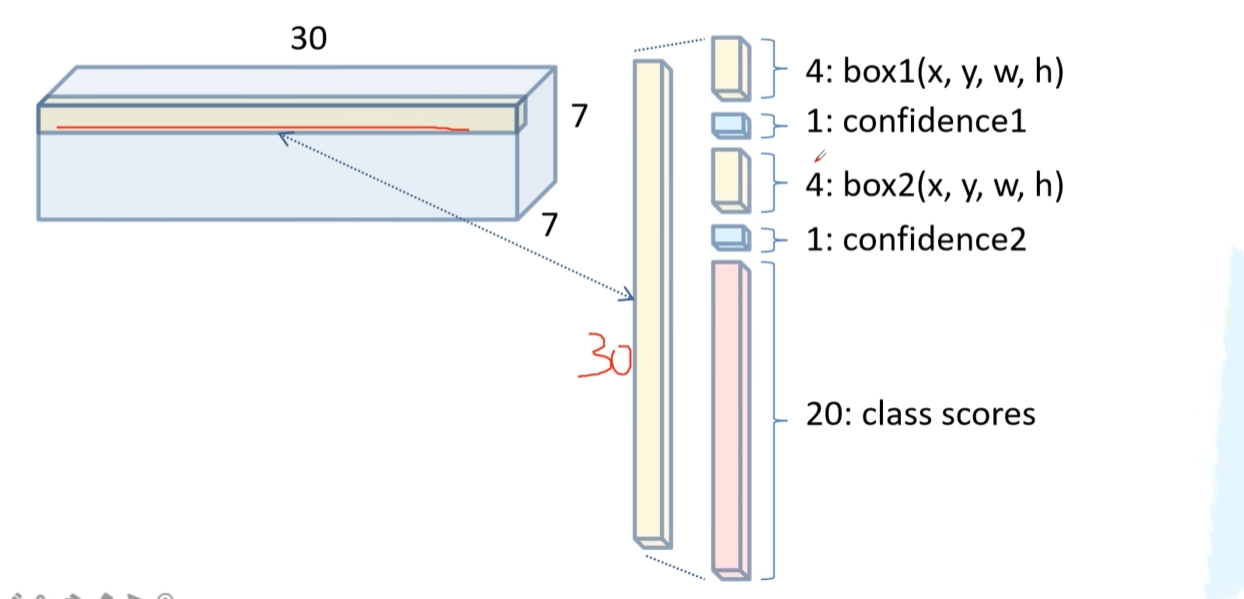
- eg:S=7,B=2,20个类别,那最后要预测 7×7×30 个参数。 S×S×(B×5+C)
-
最后网络输出:
-
每个向量可以看作对 对应网格 的预测值。
-
第三步 目标概率 :
-
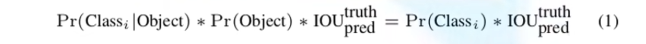
-
我们可以看出,最后给出的目标概率,既包含了 它是某个目标的概率 ,也包含了边界框和真实边界框的重合程度
(2)网络结构
- 标s-2表示步距为2,没标默认是1

(3)损失函数

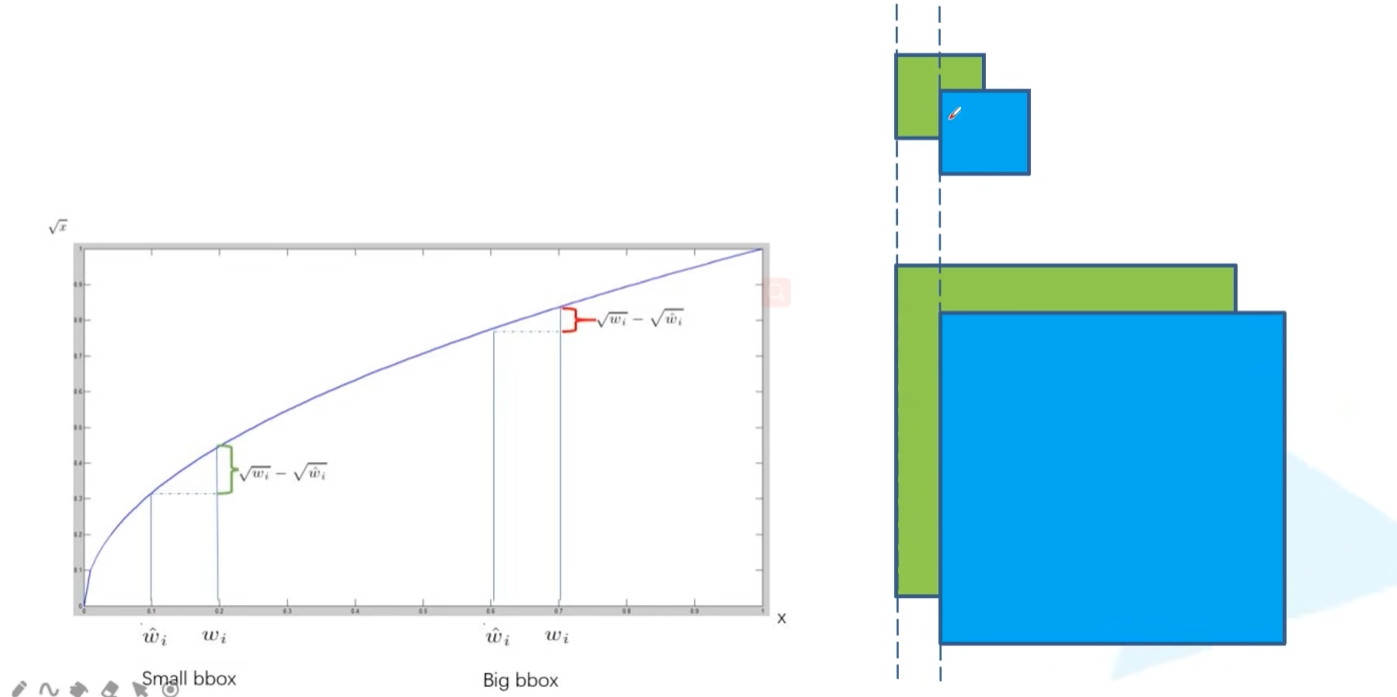
- 对于bounding box损失中,w和h使用根号的解释(下图):右边可以看出,对于小目标和大目标,预测框相对于真实框偏移相同长度,小目标的IOU应该更小一点,但是如果不用根号,那大小目标的IOU都一样了。
(4)YOLO v1 的问题
- 对于小的群体性的目标预测很差
- 当目标出现了新的尺寸或配置的时候,预测结果很差(YOLO v2 用anchor的方法解决)