理解文件
Linux下⼀切皆⽂件(键盘、显⽰器、⽹卡、磁盘......这些都是抽象化的过程)
归类认知
• 对于0KB的空⽂件是占⽤磁盘空间的
• ⽂件是⽂件属性(元数据)和⽂件内容的集合(⽂件=属性(元数据)+内容)
• 所有的⽂件操作本质是⽂件内容操作和⽂件属性操作
系统角度
• 对⽂件的操作 本质是进程对⽂件的操作
• 磁盘的管理者是操作系统
• ⽂件的读写本质不是通过C语⾔/C++的库函数来操作的(这些库函数只是为⽤⼾提供⽅便),⽽ 是通过⽂件相关的**系统调⽤接⼝**来实现的
回顾C⽂件接⼝
- fopen 是打开文件的。比如:
FILE *fp = fopen("myfile", "w");
意思就是:打开一个叫 myfile 的文件,准备往里面写。
- FILE * 叫文件指针。你可以先把它粗暴理解成: "以后我要通过它操作这个文件"
不用现在深究结构体。
- fwrite 是写文件。比如:
fwrite(msg, strlen(msg), 1, fp);
意思就是: 把 msg 这段内容写到 fp 对应的文件里
4.fread 是读文件。比如:
fread(buf, 1, 10, fp);
意思就是: 从文件里读一些内容,放进 buf
- stdout 其实就是"屏幕"。 比如:
fprintf(stdout, "hello\n");
这就是往屏幕输出。所以:
-
printf("hello\n")
-
fprintf(stdout, "hello\n")
本质差不多。
- C 程序默认有 3 个特殊文件:
**- stdin:键盘输入
- stdout:屏幕输出
- stderr:错误输出到屏幕**
打开文件
FILE *fp = fopen("myfile", "w");
要点:
-
fopen 用来打开文件,返回值类型是 FILE *
- FILE * 可以理解为"C 标准库中的文件流对象" -
打开失败返回 NULL
-
如果文件名没有写路径,比如 "myfile",那么它是相对当前进程的工作目录 cwd 来查找或创建的
-
不是相对源码目录,也不是固定相对可执行程序所在目录
即:文件名如果没写路径,就在"当前运行目录"里找或创建
写文件
这一小节讲的是:如何通过 C 标准库把数据写入文件。
cpp
FILE *fp = fopen("myfile", "w");
const char *msg = "hello bit!\n";
fwrite(msg, strlen(msg), 1, fp);
fclose(fp);要点:
-
fopen("myfile", "w")
-
以写方式打开
-
文件不存在就创建
-
文件存在通常会清空原内容
-
fwrite 用来向文件流写数据
-
fclose 用来关闭文件流,关闭前通常会刷新缓冲区
fwrite 参数含义: fwrite(ptr, size, nmemb, stream);
-
ptr:待写入数据的起始地址
-
size:每个元素的大小
-
nmemb:元素个数
-
stream:目标文件流
返回值:
-
返回成功写入的"元素个数"
-
不是固定意义上的"字节数"
想表达:
-
用 fopen(..., "w") 打开文件
-
用 fwrite 往里写
-
用完要 fclose
你先掌握这个模板:
FILE *fp = fopen("a.txt", "w");
fwrite("hello\n", 6, 1, fp);
fclose(fp);
读文件
这一小节讲的是:如何通过 C 标准库从文件中读数据。
cpp
FILE *fp = fopen("myfile", "r");
char buf[1024];
ssize_t s = fread(buf, 1, strlen(msg), fp);
if (s > 0) {
buf[s] = 0;
printf("%s", buf);
}
if (feof(fp)) break;
fclose(fp);要点:
-
fopen("myfile", "r")
-
只读打开
-
文件必须存在
-
fread 从文件流中读取数据到缓冲区
-
fread 读出来的是原始字节,不会自动补字符串结束符 \0
-
如果后面要把缓冲区当字符串打印,通常要手动补 \0
fread 参数含义:
fread(ptr, size, nmemb, stream);
-
ptr:读到哪里
-
size:每个元素大小
-
nmemb:最多读取多少个元素
-
stream:从哪个文件流读
返回值:
-
返回成功读取的元素个数
-
当 size == 1 时,返回值数值上才等于读取的字节数
想表达:
-
用 fopen(..., "r") 打开文件
-
用 fread 读取内容
-
读完再关掉
你先只要知道:
-
"r" 是读
-
"w" 是写
输出到显示器有哪些方法
cpp
fwrite(msg, strlen(msg), 1, stdout);
printf("hello printf\n");
fprintf(stdout, "hello fprintf\n");屏幕输出本质上也是文件流输出。
要点:
-
printf 默认写到 stdout
-
fprintf(stdout, ...) 明确指定写到标准输出流
-
fwrite(..., stdout) 也能直接向标准输出流写
它真正想表达的是:
-
终端输出不特殊,本质也是对文件流的写操作
-
"往屏幕打印"这件事,在 C 标准库视角里,就是"往 stdout 写"
想表达:
-
输出到屏幕,本质也是"往一个文件里写"
-
那个文件就叫 stdout
所以这几种都能打印:
printf("hello\n");
fprintf(stdout, "hello\n");
fwrite("hello\n", 6, 1, stdout);
你只要先记:
- stdout 就是标准输出,也就是屏幕
stdin stdout stderr
C 程序启动时默认打开的三个标准流。
定义上它们都是:
extern FILE *stdin;
extern FILE *stdout;
extern FILE *stderr;
含义:
-
stdin:标准输入,默认对应键盘
-
stdout:标准输出,默认对应显示器终端
-
stderr:标准错误,默认也对应显示器终端
这一节真正想表达的是:
**- C 程序一启动,系统和库就已经帮你准备好了三个可直接使用的流
- 它们和普通 fopen 得到的流在类型上是统一的,都是 FILE ***
想表达:
C 程序一启动,系统默认给你准备了 3 个地方:
-
stdin:从键盘读
-
stdout:往屏幕写普通内容
-
stderr:往屏幕写错误内容
你现在先背,不用深究。
打开模式
这节最重要,你只记最常用的 3 个就够了:
-
"r":读文件,文件必须存在
-
"w":写文件,文件不存在就创建,存在就清空
-
"a":追加写,写到文件最后面
在程序的当前路径下,那系统怎么知道程序的当前路径在哪⾥呢?
使⽤ ls /proc/ 进程 id -l命令查看当前正在运⾏进程的信息:

cwd:指向当前进程运⾏⽬录的⼀个符号链接。
• exe:指向启动当前进程的可执⾏⽂件(完整路径)的符号链接
打开⽂件,本质是进程打开,所以,进程知道⾃⼰在哪⾥,即便⽂件不带路径,进程也知道。由此OS 就能知道要创建的⽂件放在哪⾥
1. 操作的核心句柄:FILE*
这是C库文件操作的唯一通行证。
-
如何获取 :通过
FILE* fp = fopen("文件名", "模式")获得。 -
本质是什么 :
FILE是一个由C标准库定义的结构体类型。FILE*指针指向的这个结构体内,封装了两个至关重要的东西:-
底层文件描述符(fd):一个整数,是操作系统识别文件的真实ID。
-
用户级缓冲区 :一块内存区域,用于提升I/O效率,也是后续许多有趣现象(如
fork后输出重复)的根源。
-
三个默认流 :C程序启动时自动打开三个 FILE*类型的流:
-
stdin:标准输入(对应文件描述符 0),通常为键盘。 -
stdout:标准输出(对应文件描述符 1),通常为显示器。 -
stderr:标准错误(对应文件描述符 2),通常为显示器。
记住这个模式 :缓冲区 + 循环fread/while(!feof)是处理任何流式数据的标准方法。
文件打开模式:意图的声明
fopen的第二个参数------模式字符串,直接决定了你的操作意图:
| 模式 | 含义 | 文件不存在时 | 文件存在时 |
|---|---|---|---|
"r" |
只读 | 打开失败 | 正常打开 |
"w" |
只写 | 创建新文件 | 清空原内容 |
"a" |
追加写 | 创建新文件 | 在末尾追加 |
"r+" |
读写 | 打开失败 | 从头开始读写 |
"w+" |
读写 | 创建新文件 | 清空原内容 |
"a+" |
读写 | 创建新文件 | 读从头,写从尾 |
特别警示 :"w"和"w+"的清空(Truncate)行为是许多数据丢失bug的元凶,使用时务必小心。
系统⽂件I/O是打开⽂件最底层的⽅案。
在学习系统⽂件IO之前,先要了解下如何给函数传递标志位,该⽅法在系统⽂件IO接⼝中 会使⽤到:
打开⽂件的⽅式不仅仅是fopen,ifstream等流式,语⾔层的⽅案,其实系统⽂件I/O才是打开⽂件最底层的⽅ 案。不过,在学习系统⽂件IO之前,先要了解下如何给函数传递标志位,该⽅法在系统⽂件IO接⼝中 会使⽤到:
上一节讲的是 fopen/fread/fwrite,这一节讲的是更底层的 open/read/write/close。
-
上一节是"库函数"
-
这一节是"系统调用接口"
-
后面讲 fd、重定向、shell,都是建立在这一节上的
系统文件 I/O 到底想表达什么
这整节其实想让你明白 4 件事:
-
文件 IO 最底层靠的是系统调用,不是 fopen
-
Linux 用 fd 来表示"打开的文件"
-
重定向的本质是"让某个 fd 指向了别的文件"
-
C 库的 FILE* 和 Linux 的 fd 不是一层东西,但它们一定有关系
传递标志位的方法
这一小节先没讲文件,而是先讲按位或 |、按位与 &。
示例大意是:
cpp
#define ONE 0x1
#define TWO 0x2
#define THREE 0x4
func(ONE | TWO);它想表达的是:
-**一个函数的某个参数,可以同时携带多个"开关"
- 这些开关通常用二进制位来表示
- 系统调用里大量使用这种设计**
为什么先讲这个?因为后面你会看到:
open("myfile", O_WRONLY | O_CREAT, 0644);
这里的 O_WRONLY | O_CREAT 就是多个标志位组合。
**- | 用来组合多个标志
-
& 用来检测某个标志是否存在
-
系统接口常常这么设计,因为省参数、可扩展**
-
flags 通常是"多个选项组合后的结果"
**- 组合用 |
- 判断是否包含某选项用 &**
hello.c 写文件
这里把上一节的 fopen + fwrite 换成了系统调用版本:
cpp
int fd = open("myfile", O_WRONLY | O_CREAT, 0644);
write(fd, msg, len);
close(fd);这一小节想讲的是:
-
不用 FILE*,直接用系统提供的 fd
-
不用 fwrite,直接用 write
-
不用 fclose,直接用 close
核心变化:
-
C 库那套对象是 FILE*
-
系统调用这套对象是 int fd
这里的 fd 是文件描述符,你先粗暴记成:
fd 就是操作系统分给这个打开文件的编号。
这节还出现了:
umask(0);
它的作用是暂时不让"权限掩码"干扰演示,好让 0644 更直观地生效。你现在不用深挖,先知道:
-
open(..., O_CREAT, 0644) 里的 0644 是"想给新文件设置的初始权限"
-
但最终权限还会受 umask 影响
这一小节你必须掌握:
-
open 打开文件,返回 fd
-
write 往 fd 里写
-
close 关闭 fd
-
O_WRONLY | O_CREAT 的意思
-
第三个参数 0644 是创建文件时用的权限
你该记的笔记:
-
open 成功返回非负整数 fd,失败返回 -1
-
write(fd, buf, len) 返回实际写入的字节数
-
close(fd) 用来关闭文件描述符
-
O_CREAT 只有在可能创建文件时才有意义
-
0644 是八进制权限
hello.c 读文件
这部分把读文件改成系统调用版:
cpp
int fd = open("myfile", O_RDONLY);
ssize_t s = read(fd, buf, strlen(msg));
close(fd);这一小节想表达:
-
读文件的系统调用版本是 open + read + close
-
read 和 write 是成对理解的
-
它们操作的都是 fd
read 的核心意思:
read(fd, buf, n);
意思是:
-
从 fd 对应文件里读最多 n 个字节
-
放到 buf 里
-
返回实际读到的字节数
这一节想让你形成的认知是:
-
系统调用不管"字符串"不"字符串"
-
它只管字节流
-
你要读多少字节、写多少字节,都得自己控制
你要掌握:
-
O_RDONLY 是只读打开
-
read 返回实际读取的字节数
-
返回 0 通常表示读到文件结尾
-
返回 < 0 说明出错
你该做笔记:
-
read/write 都是"按字节数"工作的
-
read 返回 0 很重要,通常表示 EOF
-
系统调用处理的是原始字节,不懂字符串语义
接口介绍
这里正式给出 open 原型:
cpp
int open(const char *pathname, int flags);
int open(const char *pathname, int flags, mode_t mode);这一小节是在系统整理 open 的参数和常见选项。
它重点讲了这些标志:
**- O_RDONLY:只读
- O_WRONLY:只写
- O_RDWR:读写
- O_APPEND:追加写
- O_CREAT:文件不存在就创建**
这一节最重要的意思有两个。
第一: O_RDONLY / O_WRONLY / O_RDWR 这三者里,必须选一个,而且只能选一个。
因为你总得告诉系统:这次打开到底是读、写,还是读写。
第二: 像 O_CREAT、O_APPEND 这种,是附加选项。所以它们通常和前面三种主模式组合使用。
例如:
cpp
open("a.txt", O_WRONLY | O_CREAT, 0644);
open("a.txt", O_WRONLY | O_APPEND);这一节你必须掌握:
-
pathname 是路径
-
flags 是打开方式和附加选项的组合
-
mode 只有在需要创建文件时才有意义
-
flags 常常通过按位或 | 组合
你该做笔记:
-
open 有两个常见版本
-
需要创建文件时才传第三个参数 mode
-
O_RDONLY / O_WRONLY / O_RDWR 三选一
-
O_CREAT / O_APPEND 是附加选项
open 函数返回值
这一节表面上讲 open 返回值,实际上是在引出"库函数 vs 系统调用"。
它想表达的是:
-
fopen/fclose/fread/fwrite 是 C 标准库函数
-
open/close/read/write/lseek 是系统调用接口
-
库函数通常是对系统调用的封装
这节不是要你背定义,而是要你建立层次感:
上层:
-
printf
-
fopen
-
fread
-
fwrite
下层:
-
open
-
read
-
write
-
close
你要理解:
-
库函数更方便
-
系统调用更接近 OS
-
系统调用才是更底层的"真入口"
这一节你必须掌握:
-
open 成功返回文件描述符
-
open 失败返回 -1
-
系统调用和库函数不是一回事
该记笔记:
-
库函数:更方便,更上层
-
系统调用:更底层,直接向 OS 请求服务
-
f# 系列很多都是对系统调用的封装
3-6 文件描述符 fd
这部分是整节最核心的内容。
一句话先说透:
fd 本质上就是一个整数编号,用来代表"这个进程打开的某个文件"。
你不要把它理解得太玄。现在先记:
-
打开一个文件后,系统返回一个整数
-
以后读写就靠这个整数
-
这个整数就叫文件描述符 fd
3-6-1 0 & 1 & 2
这一小节讲的是默认的三个文件描述符:
-
0:标准输入
-
1:标准输出
-
2:标准错误
通常默认对应:
-
0 -> 键盘
-
1 -> 屏幕
-
2 -> 屏幕
示例里写:
read(0, buf, sizeof(buf));
write(1, buf, strlen(buf));
write(2, buf, strlen(buf));
意思就是:
-
从键盘读
-
往标准输出写
-
往标准错误写
这一节真正想表达的是:
-
Linux 进程一启动,默认就已经打开了 0、1、2
-
所以后面 C 库里的 stdin/stdout/stderr,最终一定和这三个 fd 有关系
你必须掌握:
-
0/1/2 的意义
-
read(0, ...) 就是在读标准输入
-
write(1, ...) 就是在写标准输出
-
write(2, ...) 就是在写标准错误
这节最该记笔记:
-
0 标准输入
-
1 标准输出
-
2 标准错误
3-6-2 文件描述符的分配规则
这里做了一个实验:
-
正常 open 一个文件,通常得到 fd = 3
-
如果先 close(0),再 open,那新打开的文件可能拿到 fd = 0
-
如果先 close(2),再 open,可能拿到 fd = 2
它想表达的是:
新分配的 fd,总是当前最小可用的那个编号。
这是非常重要的规则。
为什么这条规则这么关键?
因为它直接解释了后面的"重定向为什么能成立"。
比如你先把 1 关掉,再打开一个文件,那么这个文件很可能正好占据 1。
那以后所有写到 1 的内容,就自然写进这个文件了。
你必须掌握:
-
fd 不是随机分配的
-
分配规则是"最小可用下标"
-
这条规则和重定向密切相关
你该记笔记:
-
默认 0/1/2 已经占用,所以普通新文件常从 3 开始
-
open 会返回当前最小可用 fd
3-6-3 重定向
这里做了一个实验:
close(1);
int fd = open("myfile", O_WRONLY | O_CREAT, 0644);
printf("fd: %d\n", fd);
如果 1 先被关掉,那么 open 很可能返回 1。
于是原本写到屏幕的内容,变成写到文件里。
这一节想表达的是:
重定向的本质,不是"printf 会魔法变身",而是 1 号 fd 不再指向屏幕了。
这句话是这章最关键的理解之一。
你必须理解:
-
printf 默认最终会往标准输出写
-
标准输出底层对应 fd = 1
-
如果 1 不再代表屏幕,而代表某个普通文件
-
那 printf 的内容就会进这个文件
这就是输出重定向。
你该做笔记:
-
重定向的本质:改变 0/1/2 所对应的目标
-
不是应用层 API 变了,而是底层 fd 指向变了
3-6-4 使用 dup2 系统调用
这里开始讲更正规、也更常用的重定向方式:
dup2(oldfd, newfd);
它的意思是:
让 newfd 指向和 oldfd 一样的打开文件对象。
比如:
int fd = open("./log", O_CREAT | O_RDWR);
dup2(fd, 1);
效果就是:
-
让 1 号文件描述符改为指向 log
-
以后所有写到 1 的输出,都进入 log
为什么要用 dup2?
因为"先 close(1) 再 open()"是一种借助分配规则的做法,比较绕。
dup2 更直接,就是明确指定:
- 我就要把 1 改到这里来
这节你必须掌握:
-
dup2(oldfd, newfd) 的含义
-
它是重定向的核心系统调用
-
shell 的 >、<、>> 本质上都离不开这类操作
你该做笔记:
-
dup2(fd, 1):把标准输出重定向到 fd
-
dup2(fd, 0):把标准输入重定向到 fd
-
dup2(fd, 2):把标准错误重定向到 fd
3-6-5 在 minishell 中添加重定向功能
这一小节是前面知识的综合应用。
它想表达的是:
-
shell 里的重定向不是嘴上说说
-
本质上就是 shell 在启动子进程后、执行新程序前,先把 0/1/2 调整好
-
然后程序一运行,就天然以为自己的标准输入输出就是现在这个样子
最关键的一句话是:
重定向应该由子进程在 exec 前完成。
为什么?
因为你如果在父进程里改:
-
父进程自己的标准输入输出也会被改掉
-
shell 本身就乱了
正确流程通常是:
-
shell 解析命令
-
发现有 >、<、>>
-
fork 创建子进程
-
子进程里 open 目标文件
-
子进程里用 dup2 改 0/1/2
-
子进程 exec 执行目标程序
这样程序启动后,看到的标准输入输出已经被重定向好了。
你作为学习者至少要理解到:
-
shell 重定向不是程序自己做的
-
是 shell 在启动程序之前替你做好了
-
重定向和程序替换 exec 不冲突,因为 fd 会被继承
你该做笔记:
-
重定向应在子进程中完成
-
要在 exec 前做
-
exec 不会自动恢复 0/1/2
这一整节你最少要掌握什么
最低要求:
-
会写 open/read/write/close
-
知道 fd 是文件描述符
-
知道 0/1/2 分别是什么
-
知道 open 返回新 fd
-
知道 read/write 处理的是字节
中等要求:
-
理解 flags 为什么能用 |
-
理解 fd 分配规则是"最小可用"
-
理解重定向本质是修改 0/1/2 的目标
-
理解 dup2 是重定向核心接口
较好掌握:
-
能说清楚库函数和系统调用的区别
-
能解释为什么 shell 重定向必须在子进程里做
-
能把 stdout 和 fd=1 联系起来
这一节最值得做笔记的地方
优先级最高的是这 8 条:
-
系统文件 IO 常用接口:open/read/write/close
-
open 成功返回 fd,失败返回 -1
-
read/write 返回实际读写的字节数
-
0/1/2 分别是标准输入、标准输出、标准错误
-
fd 的分配规则是"当前最小可用编号"
-
重定向的本质是改变 0/1/2 的指向
-
dup2(oldfd, newfd) 是重定向关键接口
-
shell 中重定向应由子进程在 exec 前完成
次优先级是:
-
O_RDONLY / O_WRONLY / O_RDWR
-
O_CREAT / O_APPEND
-
mode 只在创建文件时有意义
-
库函数和系统调用的层次区别
理解"⼀切皆⽂件"
进程、磁盘、显⽰器、键盘这样硬件设备也被抽象成了⽂件,你可以使⽤访问⽂件的⽅法访 问它们获得信息;甚⾄管道,也是⽂件;将来我们要学习⽹络编程中的socket(套接字)这样的东西, 使⽤的接⼝跟⽂件接⼝也是⼀致的。
开发者仅需要使⽤⼀套API和开发⼯具,即可调取Linux系统中绝⼤部分的 资源。举个简单的例⼦,Linux中⼏乎所有读(读⽂件,读系统状态,读PIPE)的操作都可以⽤ read 函数来进⾏;⼏乎所有更改(更改⽂件,更改系统参数,写PIPE)的操作都可以⽤ 数来进⾏。它们被操作系统抽象成了"可以像文件那样访问的对象"。
"一切皆文件"不是说 Linux 里所有东西都真的是磁盘上的普通文件。
它真正的意思是:
Linux 把很多不同的资源,尽量用"像操作文件一样"的统一方式来操作。
"一切皆文件"的最大价值是:统一抽象、统一接口、降低学习和使用成本。
第一层:底层到底靠什么实现
内核结构体 struct file 和 struct file_operations。
struct file: 内核里用来表示**"一个被打开的文件对象"的结构体。**
注意,这里说的是"被打开的文件对象",不是磁盘上文件名本身。
当进程执行 open() 时,内核会在内部创建对应的数据结构来管理这次打开行为,其中就有 struct file。它里面有几个你现在要知道的成员:
-
f_pos: f_pos 记录当前读写偏移位置。意思是当前读写位置,也就是"文件指针现在走到哪了"。 比如你已经读了前 100 个字节,那 f_pos 就会往后移动。
-
f_flags:**f_flags 记录打开文件时的一些标志位信息。**意思是: 这个文件是以什么标志打开的,比如: - 只读 - 只写 - 追加 - 非阻塞
-
f_mode:它描述"能怎么用这个文件"。意思是: - 对这个打开文件对象的访问模式 比如可读、可写之类。
- f_op:这个是最重要的。 它指向 struct file_operations。
你可以把 file_operations 理解成:
这类文件支持哪些操作,以及这些操作具体该怎么做。比如这类对象如果支持读,那它就要提供"读"的实现函数。 如果支持写,就要提供"写"的实现函数。 如果支持定位,就要提供 llseek 的实现函数。
所以你会看到里面有很多函数指针: - read - write - open - llseek - mmap - ioctl - release
-flush - fsync
这里最关键的理解只有一句:
用户调用的是统一的系统调用接口,但内核会根据这个对象对应的 file_operations,跳到不同的底层实现。
第二层:为什么不同东西都能用 read/write,但内部行为却不同
你表面上看到的是: read(fd, buf, size); write(fd, buf, size);
看起来好像读普通文件、读键盘、读管道、读 socket 都一样。
但实际上它们内部根本不是一套逻辑。
比如:
-
读普通文件:从磁盘文件数据中取内容
-
读键盘:从终端输入缓冲里取内容
-
读管道:从内核管道缓冲区里取内容
-
读 socket:从网络接收缓冲区里取内容
为什么你还能统一写成 read?
因为:
-
对用户来说,系统调用入口统一了
-
对内核来说,不同对象的 file_operations->read 不一样
也就是说: 接口统一了,实现没有统一。不同资源可以共用同一个接口名,但底层实现函数可以完全不同。
这就是 Linux 抽象的强大之处。
第三层 :file_operations 到底在扮演什么角色
file_operations 是系统调用和具体设备/文件实现之间的桥。
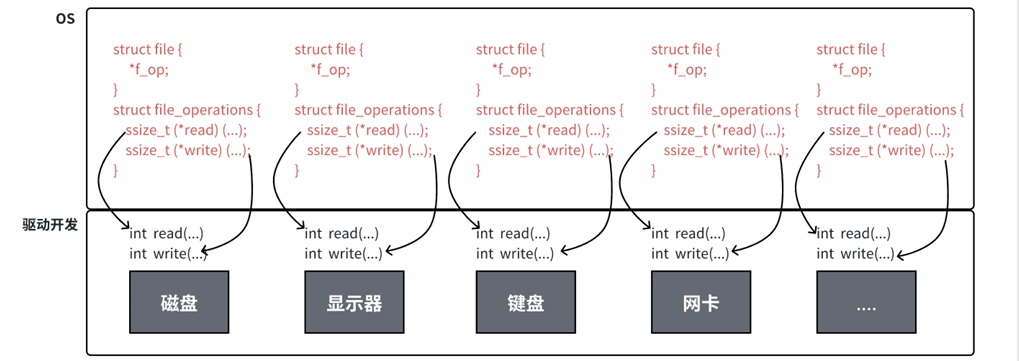
你调用 read(fd, ...) 时,不是直接神奇地就读到了。
中间大致发生的事情是:
-
你传进来一个 fd
-
内核先根据 fd 找到对应的 struct file
-
再从 struct file 里找到 f_op
-
再看 f_op->read 指向哪个具体函数
-
然后去执行那个具体函数
即: fd 先找到 struct file --> struct file 里有 f_op --> f_op 决定这个对象的具体读写行为即具体操作函数
所以你看到的 read 是统一的, 但真正干活的是后面那个被回调的具体实现函数。
核心:
**- 每个外设都可以有自己的 read/write
- 但对程序员暴露出来的接口形式尽量统一**
总结
-
"一切皆文件"不是说所有东西都是普通磁盘文件
-
它真正表示:很多资源都被抽象成了可按文件方式访问的对象
-
统一接口的好处是降低学习和使用成本
-
同样的 read/write,底层实现可以不同
-
struct file 表示内核中的已打开文件对象
-
struct file_operations 决定这个对象支持哪些操作以及如何实现
-
f_pos:当前读写位置
-
f_flags:打开标志
-
f_mode:访问模式
-
f_op:操作方法表,最关键
缓冲区
缓冲区就是先把数据暂时放在内存里,不马上和设备打交道。 比如:
-
你想写文件,不一定每写 1 个字节就立刻写磁盘
-
你想读文件,也不一定每读 1 个字节就立刻找磁盘拿
-
可以先在内存里攒一批,再一次性处理
这块"先临时放一下数据的内存",就叫缓冲区。
这节主要想讲 5 件事:
-
缓冲区是什么
-
为什么要有缓冲区
-
缓冲区有哪几种工作方式
-
为什么 printf 和 write 行为不一样
-
为什么 FILE* 和 fd 一定有关系
什么是缓冲区
缓冲区就是内存里预留出来的一块空间,用来临时存放输入或输出的数据。
分两种理解:
-
输入缓冲区:先把外部数据放进内存,再给程序慢慢用
-
输出缓冲区:程序先把数据写进内存,之后再统一发给外设
你可以把它理解成"中转站"。 比如写文件时:没缓冲区:你每写一次,系统就得真去写一次磁盘
有缓冲区:你先写进内存,等积累一些再统一写磁盘
这个"先攒一会"的地方,就是缓冲区。
-
缓冲区的本质是内存空间
-
它是输入输出过程中的中间层
-
它存在的目的,是暂存数据,不是永久存储数据
-
缓冲区 = 内存中的临时存储区域
-
输入缓冲区:先接住输入数据
-
输出缓冲区:先攒住输出数据
为什么要引入缓冲区机制
缓冲区的核心价值是提升效率,让快的 CPU 和慢的设备之间更协调。
-
缓冲区的根本目的是提高效率
-
它减少系统调用次数
-
它减少设备访问次数
-
它协调"CPU 快、外设慢"的速度矛盾
-
引入缓冲区的原因:减少系统调用、减少上下文切换、减少设备访问、提高整体
效率
- 缓冲区本质是时间换空间,或者说用内存换效率
缓冲类型
标准 I/O 的 3 种缓冲方式:
- 全缓冲: 缓冲区不满,就先不真正输出。等缓冲区满了,或者你主动刷新,才真正进行 I/O。适合普通文件
常见场景: - 普通磁盘文件 为什么磁盘文件常用全缓冲? 因为磁盘本来就慢,最适合"攒一批再统一写"。
-
全缓冲:满了再刷
-
适合普通文件
- 行缓冲: 遇到换行 \n 时就刷新。 当然,如果缓冲区先满了,也会刷新。
常见场景: - 终端上的标准输入输出 为什么终端适合行缓冲?因为终端交互需要"别太慢",但也没必要每个字符都立刻系统调用。
例如:
printf("hello\n"); 因为有换行,通常能很快看到输出。 但如果你写: printf("hello"); 可能就不一定立刻看到。
-
行缓冲:遇到换行就刷新
-
常见于终端交互
- 无缓冲:不在 C 标准库这一层先攒数据,直接尽快交给系统调用。 - stderr 通常是不带缓冲区的,因为错误信息通常希望马上看到,不能憋着。
-
无缓冲:尽快输出
-
常见于 stderr
了默认规则,还会在什么时候刷新: 1. 缓冲区满了 2. 显式调用刷新语句,比如 fflush
几个常见触发点:
-
fflush(stdout)
-
fclose(fp)
-
程序正常退出时,标准库通常也会做刷新
同样是输出,什么时候真正写出去,取决于缓冲策略。
cpp
#include <stdio.h>
#include <string.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
#include <unistd.h>
int main() {
close(1);
int fd = open("log.txt", O_WRONLY | O_CREAT | O_TRUNC, 0666);
if (fd < 0) {
perror("open");
return 0;
}
printf("hello world: %d\n", fd);
close(fd);
return 0;
}本来你以为:1 已经被重定向到 log.txt, printf 往标准输出写,所以文件里应该有内容
但结果文件居然空的。原因是:
printf 不是直接写文件,它先写到 C 库的缓冲区里。 而这时标准输出已经不连终端了,而是连到普通文件。于是 stdout 的缓冲方式从"行缓冲"变成了"全缓冲"。
于是即使你打印了: printf("hello world: %d\n", fd); 带了换行也没用,因为现在不是终端,不按"行缓冲"规则来了。它会按"全缓冲"走:
-
缓冲区没满
-
你又没 fflush
-
内容就还留在用户缓冲区里
-
后面直接 close(fd),关的是底层 fd,不是 stdout 这个 FILE*
-
所以 stdout 自己的缓冲数据可能没来得及正确冲出去
这就是为什么文件空了。解决方法: fflush(stdout); 这一句就是强制把 stdout 的用户级缓冲刷到底层去。
即:- printf 走的是 stdout
-
stdout 有自己的 C 库缓冲
-
重定向到普通文件后,stdout 常变成全缓冲
-
所以内容可能先留在内存里,不会立刻进文件
-
fflush(stdout) 能强制刷出去
还有⼀种解决⽅法,刚好可以验证⼀下stderr是不带缓冲区的,代码如下:
cpp
#include <stdio.h>
#include <string.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
#include <unistd.h>
int main() {
close(2);
int fd = open("log.txt", O_WRONLY | O_CREAT | O_TRUNC, 0666);
if (fd < 0) {
perror("open");
return 0;
}
perror("hello world");
close(fd);
return 0;
}stderr 通常是不带缓冲的。 所以错误信息一产生,标准库基本立刻交给底层输出,不会像 stdout 那样先憋在用户缓冲区里。
-
stdout 常常有缓冲
-
stderr 常常无缓冲
-
所以错误信息更容易"立刻看到"
FILE
这一小节是整个缓冲区章节最关键、最难但也最值的部分。
因为IO相关函数与系统调⽤接⼝对应,并且库函数封装系统调⽤,所以本质上,访问⽂件都是通 过fd访问的。 • 所以C库当中的FILE结构体内部,必定封装了fd。
cpp
#include <stdio.h>
#include <string.h>
int main()
{
const char *msg0="hello printf\n";
const char *msg1="hello fwrite\n";
const char *msg2="hello write\n";
printf("%s", msg0);
fwrite(msg1, strlen(msg0), 1, stdout);
write(1, msg2, strlen(msg2));
fork();
}
return 0;正常在终端运行时,大概看到:printf fwrite write 各输出一次
但如果你把输出重定向到文件:./hello > file 就会发现: write 只出现一次 printf 和 fwrite 可能各出现两次。原因分两层:
第一层:printf/fwrite 有用户级缓冲
它们是 C 标准库函数,不是直接的系统调用。所以它们先把数据写入 stdout 对应的 FILE 缓冲区。当输出被重定向到普通文件后,stdout 往往是全缓冲。于是:
-
printf/fwrite 写的数据先留在缓冲区
-
还没真正写到文件
第二层:fork 会复制进程用户空间
fork() 后:
-
子进程会得到父进程用户空间的一份副本
-
缓冲区里的那份"还没刷出去的数据"也被复制了
于是父子进程退出时都会刷新自己的缓冲区。结果就是:
-
同一份缓冲数据被刷了两次
-
所以 printf/fwrite 输出重复了
那为什么 write 不重复?因为: write 是系统调用,不走 C 库的这一层用户级缓冲。
它调用时就直接往内核那边去了。所以在 fork 之前,它早就写完了,不会在用户缓冲区里留一份待刷新的副本。
这部分一定要理解透:
-
printf/fwrite 有 C 库缓冲
-
write 没有 C 库这一层缓冲
-
fork 复制的是用户空间数据
-
所以会复制 printf/fwrite 留在缓冲区里的内容
-
不会复制已经通过 write 交出去的那种"未刷新用户缓冲"
这就是整节最难但最重要的地方。
总结
-
printf/fwrite 和 write 不是同一层的东西
-
printf/fwrite 有 C 标准库提供的用户级缓冲
-
write 是系统调用,不带这层缓冲
-
FILE* 内部一定封装了 fd 和缓冲信息
什么说 FILE 内部一定封装了 fd?因为:
-
printf/fwrite 最终也得写到某个具体目标
-
底层真正访问文件还是要靠 fd
-
所以 FILE* 内部不可能脱离 fd 存在
FILE 不是"和 fd 无关的另一套系统",而是"库层对 fd 的封装 + 加上缓冲区等管
理信息"。
简单设计一下 libc 库
一个 C 标准库文件对象,最少就应该包含这几类信息:
-
底层文件描述符 fd
-
一块缓冲区
-
当前缓冲区里用了多少
-
刷新策略是什么
-
什么时候把缓冲区内容真正写出去
作为学习者,不需要手写完整 libc, 但必须理解这个设计思想。
-
FILE 不是只有一个"文件句柄"那么简单
-
它至少包含 fd + buffer + flush policy
-
C 标准库就是靠这层封装,在系统调用上面提供更方便的 IO
-
FILE = fd + 缓冲区 + 状态信息 + 刷新策略
-
库函数是在系统调用基础上的再封装
总结
缓冲区,最核心的理解链
-
write 是系统调用,直接更靠近 OS
-
printf/fwrite 是库函数,在 write 上面又包了一层
-
这层额外封装里最重要的功能之一,就是"用户级缓冲区"
-
所以 printf/fwrite 和 write 的行为可能不同
-
fork 时,用户空间缓冲区会被复制
-
于是可能出现重复输出
-
FILE* 内部因此一定封装了 fd 和缓冲信息
优先级最高的 8 条:
-
缓冲区是内存中的临时数据区
-
引入缓冲区是为了提高效率
-
全缓冲:满了才刷
-
行缓冲:遇到换行刷
-
无缓冲:尽快刷
-
stdout 连终端时常是行缓冲,连普通文件时常变全缓冲
-
stderr 通常无缓冲
-
fflush(stdout) 用来强制刷新
第二优先级:
-
printf/fwrite 有 C 库用户级缓冲
-
write 没有这层用户级缓冲
-
fork 会复制用户空间缓冲区
-
FILE = fd + buffer + 状态管理
必须掌握哪些内容
最低要求:
-
知道缓冲区是内存中的临时存储区
-
知道缓冲区的作用是提高效率
-
知道 3 种缓冲:全缓冲、行缓冲、无缓冲
-
知道 stdout 和 stderr 的默认缓冲策略可能不同
中等要求:
-
理解为什么重定向后 printf 不一定立刻写进文件
-
理解 fflush(stdout) 的作用
-
理解 printf/fwrite 和 write 的区别在"有没有 C 库缓冲"
较好掌握:
-
理解 fork 为什么会导致缓冲内容重复输出
-
理解 FILE* 内部封装了 fd
-
理解 glibc 在系统调用之上加了一层用户级 IO 管理