什么是雨云图?
雨云图是一种用于可视化数据分布和比较多组数据的数据可视化图表。它巧妙地结合了多种元素,提供的信息比传统的箱线图或小提琴图更丰富、直观。
一张典型的雨云图通常包含以下"图层":
-
云(Cloud) :这是图的背景,通常是一个水平排列的小提琴图,展示了数据的整体概率密度分布(哪里数据点更密集)。
-
雨(Rain) :这是图中垂直的短划线或点,代表了每一个 原始数据 点。这能让你直接看到数据的实际分布和离散程度,避免被平滑的"云"掩盖细节。
-
其他元素 :通常会辅以箱线图 (显示中位数、四分位数)或均值/误差线,用于突出显示数据的集中趋势和离散度。
核心优点:在一张图中,你既能像小提琴图一样看到平滑的分布形状,又能像散点图一样看到每个具体的数据点,还能像箱线图一样看到关键的统计量,非常适合进行多组数据的比较。
简单的示例数据
假设我们要比较A、B、C三个小组在某个测试中的得分(满分100分)。我们生成一些简单的数据。
-
Group A: 成绩普遍较高,集中在80-95分。
-
Group B: 成绩中等,集中在70-85分。
-
Group C : 成绩较低且分散,集中在60-75分。
Python绘制雨云图代码
我们将使用 matplotlib, seaborn和 ptitprince库来绘制。ptitprince库提供了绘制雨云图的便捷函数 RainCloud。
首先,确保安装必要的库:
python
pip install matplotlib seaborn ptitprince下面是完整的代码:
python
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import ptitprince as pt
# 设置中文字体(如果标签需要中文)
plt.rcParams['font.sans-serif'] = ['SimHei', 'Arial Unicode MS', 'DejaVu Sans'] # 根据系统调整
plt.rcParams['axes.unicode_minus'] = False # 解决负号显示问题
# 1. 生成简单的示例数据
np.random.seed(2026) # 设置随机种子以保证结果可重复
data_dict = {
'Group': [],
'Score': []
}
# 为A、B、C三组生成不同分布的数据
for group_name, center, scale, n in [('A', 88, 5, 30),
('B', 78, 5, 30),
('C', 68, 8, 30)]:
data_dict['Group'].extend([group_name] * n)
# 生成数据并限制在0-100之间
scores = np.random.normal(loc=center, scale=scale, size=n)
scores = np.clip(scores, 0, 100) # 确保分数在合理范围
data_dict['Score'].extend(scores)
# 将数据转换为pandas DataFrame
df = pd.DataFrame(data_dict)
# 2. 使用PtitPrince绘制雨云图
plt.figure(figsize=(10, 6)) # 设置画布大小
# 使用Raincloud函数
# x: 分组变量(DataFrame的列名)
# y: 数值变量(DataFrame的列名)
# data: 数据DataFrame
# palette: 颜色主题
# bw: 小提琴图的平滑带宽,值越小越贴近数据细节
# width_viol: 小提琴图的宽度
# move: 将"雨点"(数据点)在水平方向上移动多少,避免完全重叠
ax = pt.RainCloud(x='Group', y='Score', data=df,
palette='Set3', # 配色方案
bw=0.2, # 带宽,控制密度估计的平滑程度
width_viol=0.6, # 小提琴图的宽度
move=0.2, # 数据点水平方向的抖动幅度
alpha=0.65, # 整体透明度
dodge=True) # 是否分组显示
# 3. 美化图表
plt.title('三组测试成绩分布雨云图 (Raincloud Plot)', fontsize=16, pad=20)
plt.ylabel('测试分数', fontsize=12)
plt.xlabel('小组', fontsize=12)
plt.grid(axis='y', alpha=0.3, linestyle='--') # 添加横向网格线,更易读
# 调整y轴范围,让图更美观
plt.ylim(df['Score'].min() - 5, df['Score'].max() + 5)
plt.tight_layout() # 自动调整子图参数,使之填充整个图像区域
plt.show()代码解析与图表说明
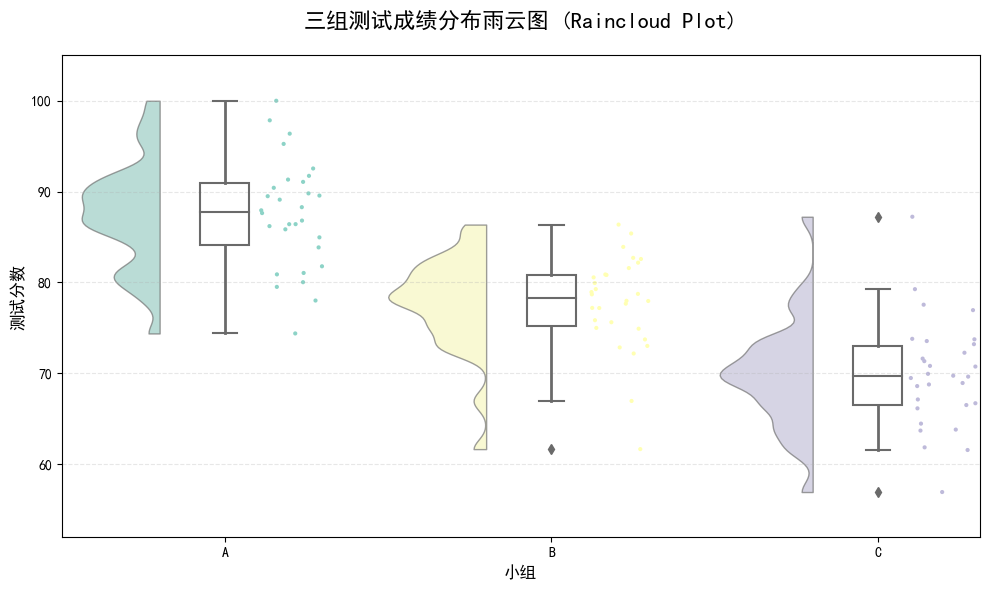
运行上述代码,你会得到一张包含以下元素的图:
-
左侧的"云" :每个小组对应一个小提琴图 ,展示了得分的概率密度 分布。中间宽的地方表示数据点密集。
-
右侧的"雨" :每个小组右侧的点就是原始数据。点的垂直位置是它的实际分数,水平方向有轻微抖动以防止完全重叠。这让你能直观看到数据的离散情况和异常值。
-
中间的 箱线图 元素 :在每个小提琴图内部,其实嵌入了一个微型的箱线图:
-
中间的粗线表示中位数。
-
箱体范围表示第25百分位数(Q1)到第75百分位数(Q3),即中间50%的数据范围。
-
通过这张图,你可以一目了然地得出:
-
整体分布:A组得分最高且集中,C组得分最低且相对分散。
-
具体数据:可以看到每个小组是否有特别高或特别低的异常分数。
-
统计比较:通过中位数线和箱体,可以快速比较各组的中位数和四分位距。
你可以通过调整 bw(带宽)、move(点偏移量)、palette(调色板) 等参数,来改变图表的显示风格以适应你的需求。