LLM 基础与提示词工程:从 API 调用到 Prompt 优化技巧
系列文章 :RAG 与 LangChain 开发实战(1/7)
阅读时间 :约 15 分钟
前置知识:Python 基础
一、为什么需要学习 LLM 开发?
大语言模型(LLM)正在改变我们构建应用的方式。但直接使用原始 API 存在诸多挑战:
- 知识时效性:模型训练数据有截止时间,无法获取最新信息
- 领域知识缺乏:无法覆盖特定行业或企业内部知识
- 幻觉问题:模型可能"一本正经地胡说八道"
- 数据安全:敏感数据不能随意发送给公共模型
RAG(检索增强生成) 技术正是为解决这些问题而生。而 LangChain 框架则让 RAG 开发变得简单高效。
本系列将从 LLM 基础开始,带你完整掌握 RAG 开发的全流程,最终实现一个可落地的智能客服系统。
二、环境准备与 API 调用
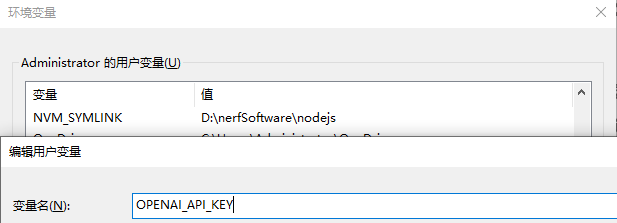
2.1 环境变量配置
最佳实践:永远不要将 API Key 硬编码在代码中!
将API Key配置进环境变量中
需要配置两个:
变量名:OPENAI_API_KEY
变量值:你的API Key
变量名:DASHSCOPE_API_KEY
变量值:你的API Key
bash
client = OpenAI(
#配置了环境变量可以不写api_key,自动读取
#api_key=os.getenv("OPENAI_API_KEY"),
base_url="https://dashscope.aliyuncs.com/compatible-mode/v1",
)配置了环境变量可以不写api_key,自动读取
2.2 使用 OpenAI 兼容接口调用模型
python
from openai import OpenAI
import os
client = OpenAI(
base_url="https://dashscope.aliyuncs.com/compatible-mode/v1",
)
messages = [
{"role": "user", "content": "你是谁"},
{"role": "user", "content": "输出 1-10 数字"},
]
completion = client.chat.completions.create(
model="qwen3.5-plus",
messages=messages,
extra_body={"enable_thinking": True},
stream=True
)
is_answering = False
print("\n" + "=" * 20 + "思考过程" + "=" * 20)
for chunk in completion:
delta = chunk.choices[0].delta
if hasattr(delta, "reasoning_content") and delta.reasoning_content is not None:
if not is_answering:
print(delta.reasoning_content, end="", flush=True)
if hasattr(delta, "content") and delta.content:
if not is_answering:
print("\n" + "=" * 20 + "完整回复" + "=" * 20)
is_answering = True
print(delta.content, end="", flush=True)关键点:
stream=True启用流式输出,提升用户体验enable_thinking=True开启深度思考模式(部分模型支持)messages列表可携带历史对话,实现上下文理解
三、提示词工程(Prompt Engineering)
3.1 什么是提示词工程?
Prompt Engineering (提示工程)也称为 In-Context Prompting,指在不更新模型权重的情况下,通过设计输入提示来引导模型行为,获得所需结果的方法。
最简单的例子:
讲个笑话3.2 核心优化技巧
技巧 1:Few-Shot 少样本学习
当模型学习过大量数据后,只需少量示例就能快速理解新任务。
示例:抽取产品信息
请抽取产品名称和核心卖点 2 个字段,格式为 Json,我提供 2 个示例。
示例 1:
输入:MacBookPro 高效节能,性能强大,适合牛马工作使用
输出:{"产品名称":"MacBookPro","产品卖点":"高效节能,性能强大"}
示例 2:
输入:联想笔记本拥有 RTX4060 独立显卡,畅玩游戏,丝滑流畅
输出:{"产品名称":"联想笔记本","产品卖点":"畅玩游戏,丝滑流畅"}
请处理:华为 MatepadPro,高清大屏,长效续航,你的好帮手。技巧 2:Zero-Shot 零样本学习
模型能用已有知识推理新类别。
示例:情感分析
请判断"''包围的用户评论中的情感倾向,输出 正面或负面。"
"这款代餐鸡胸肉饱腹感很强,吃起来也不柴,很推荐!"模型知道"饱腹感强"、"不柴"、"很推荐"都是正面词汇,从而判断为正面情感。
技巧 3:清晰表达需求
任何 Prompt 技巧都不如清晰表达需求重要。
实用技巧清单:
-
角色设定:让模型充当某个角色(如面试官),它会自主扮演
-
使用分隔符 :用
'''、[]、XML 标签标明输入的不同部分'''在此插入文本''' -
拆分任务:对复杂任务指定执行步骤
-
提供示例:本质是 Few-Shot 学习
3.3 幻觉问题与解决方案
幻觉:模型一本正经地胡说八道。
经典解决方案:使用参考文本回答
python
prompt = """
根据下文中三重引号引起来的文章来回答问题。
如果在文章中找不到答案,请写"我找不到答案",不要自己造答案。
'''
<在此插入文档>
'''
问题:<在此插入问题>
"""这正是 RAG 技术的核心思想!
四、核心概念总结
4.1 关键知识点
| 概念 | 说明 |
|---|---|
| API 调用 | 使用 OpenAI 兼容接口调用大模型 |
| 流式输出 | stream=True 实现打字机效果 |
| 上下文历史 | messages 列表携带对话历史 |
| Few-Shot | 提供示例让模型快速理解任务 |
| Zero-Shot | 无需示例,直接用已有知识推理 |
| 幻觉 | 模型编造信息,需用参考文本约束 |
4.2 本质理解
不管是 RAG 还是 Agent 智能体,亦或是其它围绕模型的各类复杂开发工作,本质上都可以简单总结为:在提示词上下功夫。
五、下一步
本文介绍了 LLM 基础调用和提示词工程技巧。但直接操作原始 API 存在以下问题:
- 不同模型的接口不统一
- 提示词模板管理混乱
- 无法方便地串联多个步骤
- 缺少文档处理、向量存储等高级功能
下一篇 我们将介绍 LangChain 框架,它通过统一的接口和组件化的设计,让 LLM 应用开发变得简单高效。
系列文章导航
- LLM 基础与提示词工程:从 API 调用到 Prompt 优化技巧(本文)
- LangChain 框架入门:模型抽象与 Prompt 模板
- LangChain 进阶:Chain 链与输出解析器
- LangChain 记忆与文档处理:让 AI 拥有长期记忆
- RAG 核心概念与向量存储
- RAG 实战 (上):知识库构建
- RAG 实战 (下):智能客服系统
版权声明:本文基于学习笔记整理,转载请注明出处。