一、现代卷积神经网络
1.1 AlexNet
1.1.1 理论背景解析
在2012年之前,神经网络并不受待见,几个核心原因:
- 传统特征工程的主导 :以前的计算机视觉专家并不直接把图片像素喂给分类器(如SVM),而是纯手工设计复杂的数学公式去提取图片的特征(比如SIFT提取关键点、HOG提取边缘方向)。当时大家认为:数据特征的好坏,比算法本身更重要。
- 表征学习的觉醒(Representation Learning) :以Hinton为首的一拨人认为,特征不应该是由人类手工设计的,而应该由机器自己从数据中"学"出来。 神经网络底层的卷积层学边缘、颜色;中层学纹理、局部(眼睛、轮廓);高层学整体(人脸、汽车)。
- 促成爆发的两个"缺失成分" :
- 数据(ImageNet):以前的数据集太小(几万张小图),神经网络参数多,极易过拟合。李飞飞团队构建的ImageNet(100多万张高清大图,1000个类别)喂饱了贪婪的深层网络。
- 算力(GPU) :CPU的核心少且复杂,适合做各种逻辑跳转;而深度学习的核心是海量的"矩阵乘法"。GPU虽然单个核心弱,但有成千上万个核心,可以大规模并行计算。AlexNet的作者利用两块GTX 580 GPU写出了极快的CUDA卷积算子,打破了算力瓶颈。
1.2.2 AlexNet的核心创新点
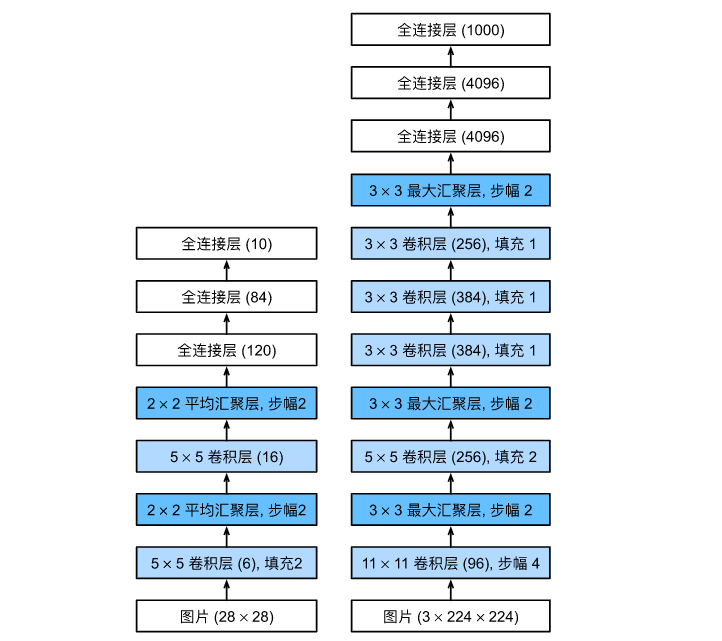
从LeNet(左)到AlexNet(右)
相比于1998年的LeNet,2012年的AlexNet并没有本质上颠覆数学原理,但做出了几个极为关键的工程和网络设计创新:
- 更深更宽的网络 :从LeNet的5层(2卷3全)变成了8层(5卷3全),并且通道数大幅增加。
- 激活函数:引入 ReLU
- 以前用 Sigmoid。Sigmoid在输入值特别大或特别小时,梯度几乎为0(这叫梯度消失),导致网络深了之后,底层参数根本无法更新。
- ReLU (Rectified Linear Unit) :f(x)=max(0,x)f(x) = \max(0, x)f(x)=max(0,x)。只要输入大于0,梯度永远是1,完美解决了正区间的梯度消失问题,而且计算极其简单(不需要算指数),极大加快了训练速度。
- 控制过拟合的利器:Dropout(暂退法)
- AlexNet包含两个拥有4096个神经元的巨大全连接层,参数量占了整个网络的90%以上,极易过拟合。
- Dropout在训练时,随机让一半的神经元"失活"(输出置0),强迫网络不依赖某几个特定的神经元,从而学到更鲁棒的特征。
- 数据增强(Data Augmentation):通过对原始图像进行随机裁剪、翻转、改变亮度等操作,相当于人为凭空造出了无数张新图片,进一步对抗过拟合。
- 重叠最大池化(Overlapping Max Pooling):LeNet用的是平均池化,AlexNet用最大池化,并且池化窗口(3x3)大于步幅(2),使得池化区域有重叠,保留了更多局部信息。
1.2.3 代码实现(Pytorch)
1. 定义网络结构
python
from d2l import torch as d2l
import torch
from torch import nn
net = nn.Sequential(
# --- 第1部分:特征提取(卷积层) ---
# 第1层:卷积层 + ReLU + 最大池化层
# 输入通道1(灰度图),输出通道96。因为图片放大了(224x224),所以用很大的11x11卷积核去捕捉全局特征。
# 步幅为4,大幅度成比例缩小图片的宽和高(224 -> 54)。padding=1是为了尺寸凑整。
nn.Conv2d(1, 96, kernel_size=11, stride=4, padding=1),
nn.ReLU(), # 使用ReLU激活函数
# 3x3的池化窗口,步幅为2,发生了重叠池化(54 -> 26)
nn.MaxPool2d(kernel_size=3, stride=2),
# 第2层:卷积层 + ReLU + 最大池化层
# 输入通道96,输出增加到256。卷积核缩小为5x5。
# padding=2保证了卷积前后特征图长宽不变(26 -> 26)。
nn.Conv2d(96, 256, kernel_size=5, padding=2),
nn.ReLU(),
# 再次重叠池化(26 -> 12)
nn.MaxPool2d(kernel_size=3, stride=2),
# 第3、4、5层:连续三个卷积层(中间没有池化)
# 连续的卷积有助于提取更复杂、更抽象的深层组合特征。
# 第3层:通道数激增到384,卷积核变为常规的3x3,padding=1保持尺寸不变(12 -> 12)
nn.Conv2d(256, 384, kernel_size=3, padding=1),
nn.ReLU(),
# 第4层:通道数保持384不变,尺寸不变(12 -> 12)
nn.Conv2d(384, 384, kernel_size=3, padding=1),
nn.ReLU(),
# 第5层:通道数降回256,尺寸不变(12 -> 12)
nn.Conv2d(384, 256, kernel_size=3, padding=1),
nn.ReLU(),
# 最后一个池化层(12 -> 5)
nn.MaxPool2d(kernel_size=3, stride=2),
# --- 第2部分:分类器(全连接层) ---
# 将多维的特征图(Batch_Size, 256, 5, 5)拉平为一维向量(Batch_Size, 256*5*5 = 6400)
nn.Flatten(),
# 第6层:全连接层
# 输入维度6400,输出维度4096(参数量巨大:6400*4096 = 2600万个权重!)
nn.Linear(6400, 4096),
nn.ReLU(),
nn.Dropout(p=0.5), # 训练时随机丢弃50%的神经元,防止过拟合
# 第7层:全连接层
# 输入4096,输出4096
nn.Linear(4096, 4096),
nn.ReLU(),
nn.Dropout(p=0.5),
# 第8层:输出层
# 原版AlexNet输出是1000(ImageNet的类别数)。
# 这里因为我们要跑Fashion-MNIST数据集,只有10个类别衣服,所以输出改为10。
nn.Linear(4096, 10)
)2. 观察每一层的输出形状变化
这其实是非常好的Debug习惯,通过传入一个模拟的假数据(Dummy input),来看看网络每一层到底把图片的尺寸变成了多少。
python
# 生成一个随机张量,形状为 (批量大小=1, 通道数=1, 高=224, 宽=224)
X = torch.randn(1, 1, 224, 224)
# 遍历神经网络中的每一层
for layer in net:
X = layer(X) # 将张量传给当前层,更新X
# 打印当前层的类名(如Conv2d)以及输出后的形状
print(layer.__class__.__name__, 'output shape:\t', X.shape)输出:
Conv2d Output shape: torch.Size([1, 96, 54, 54])
ReLU Output shape: torch.Size([1, 96, 54, 54])
MaxPool2d Output shape: torch.Size([1, 96, 26, 26])
Conv2d Output shape: torch.Size([1, 256, 26, 26])
ReLU Output shape: torch.Size([1, 256, 26, 26])
MaxPool2d Output shape: torch.Size([1, 256, 12, 12])
Conv2d Output shape: torch.Size([1, 384, 12, 12])
ReLU Output shape: torch.Size([1, 384, 12, 12])
Conv2d Output shape: torch.Size([1, 384, 12, 12])
ReLU Output shape: torch.Size([1, 384, 12, 12])
Conv2d Output shape: torch.Size([1, 256, 12, 12])
ReLU Output shape: torch.Size([1, 256, 12, 12])
MaxPool2d Output shape: torch.Size([1, 256, 5, 5])
Flatten Output shape: torch.Size([1, 6400])
Linear Output shape: torch.Size([1, 4096])
ReLU Output shape: torch.Size([1, 4096])
Dropout Output shape: torch.Size([1, 4096])
Linear Output shape: torch.Size([1, 4096])
ReLU Output shape: torch.Size([1, 4096])
Dropout Output shape: torch.Size([1, 4096])
Linear Output shape: torch.Size([1, 10])3. 读取数据集与训练
python
# 设置批量大小为128(每次喂给网络128张图片)
batch_size = 128
# 加载Fashion-MNIST数据集
# 注意核心修改:resize=224。
# Fashion-MNIST原本的图片只有28x28,这对AlexNet的11x11大卷积核和多次池化来说太小了(池化几次就没了)。
# 所以这里强行把图片放大到224x224。在实际工程中,除非用迁移学习,否则不推荐把小图强行放大,这里仅为教学演示AlexNet原版结构。
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size, resize=224)
# 设置学习率为0.01(相对较小,因为网络深了容易梯度爆炸或震荡),训练10个Epoch(轮次)
lr, num_epochs = 0.01, 10
# 调用d2l封装好的训练函数。
# d2l.try_gpu()会自动检测电脑是否有Nvidia显卡或者Mac的MPS,有的话就把模型和数据搬到GPU上算,否则用CPU。
d2l.train_ch6(net, train_iter, test_iter, num_epochs, lr, d2l.try_gpu())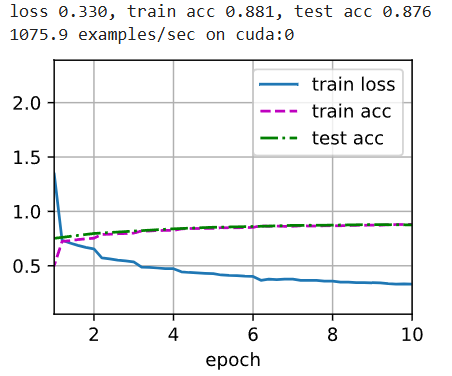
一些思考题
- 显存和计算资源主要消耗在哪?
- 显存(参数量 Memory) :主要消耗在全连接层(Dense/Linear)。刚才我们算过,第一个全连接层就有约2600万个参数,占了巨大显存空间。
- 计算量(FLOPs) :主要消耗在卷积层(Conv2D)。因为全连接层只做一次大规模矩阵乘法,而卷积层需要在图片的每一个像素位置滑动进行点乘和相加,尤其是通道数很大时,计算量极为惊人。
- 如何设计一个能直接在28x28上工作的AlexNet?
- 不需要强行放大图片。
- 去掉第1层的11x11大卷积核,改为3x3或5x5,去掉stride=4(改为stride=1)。
- 减少池化层的数量,因为28x28池化3次就只剩3x3了,不够后续处理。
- 如果把Dropout和ReLU加到老版的LeNet里会怎样?
- 效果会提升!ReLU会加快LeNet的收敛速度,Dropout能让LeNet在测试集上表现更好(泛化能力更强)。
- 另:在卷积神经网络博客里面已经做了这个尝试,效果相当好
1.2 VGG
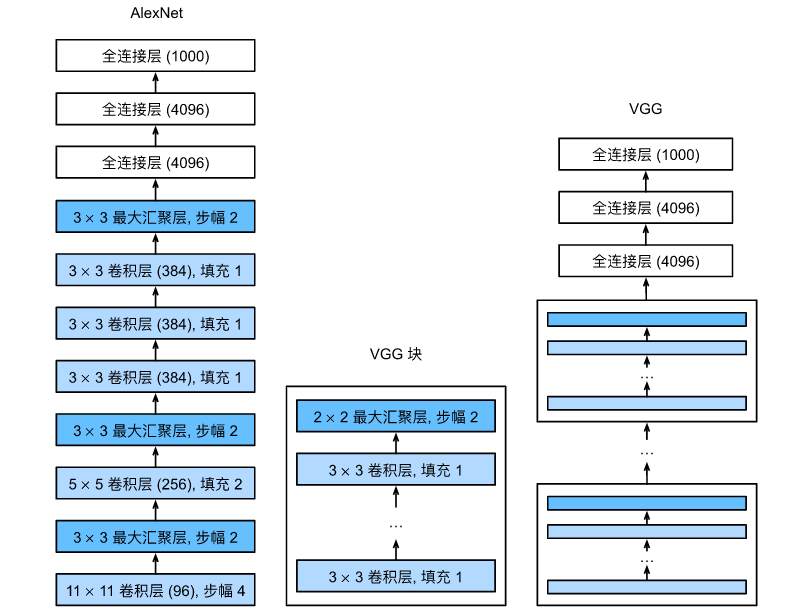
从AlexNet到VGG,它们本质上都是块设计。
如果说AlexNet证明了"深度学习是有效的",那么VGG(Visual Geometry Group)就证明了"深度学习是可以被模块化、标准化设计的"。
1.2.1 核心思想
在VGG之前,AlexNet虽然赢了比赛,但它的网络结构很像"手工拼凑"出来的。第一层用11×1111 \times 1111×11的卷积核,第二层用5×55 \times 55×5,后面又切成3×33 \times 33×3......这让后来的研究者很困惑:如果我要设计更深的网络,我该怎么选卷积核?有没有规律可循?
VGG的作者(牛津大学的研究团队)提出了两个极其重要的概念,深刻影响了直至今日的AI模型设计(包括ResNet、Transformer):
1. "块(Block)"的概念
像写代码时把重复逻辑封装成"函数"一样,VGG把**"几个相同的卷积层 + 一个池化层"封装成了一个 "VGG块"。整个网络不再是一个个神经层堆叠,而是一个个"块"的堆积**。这种高度的模块化,让设计上百层的网络变得非常容易。
2. 深而窄 > 浅而宽(小卷积核的胜利)
VGG彻底抛弃了AlexNet里的11×1111 \times 1111×11和5×55 \times 55×5大卷积核,全部采用最小的 3×33 \times 33×3 卷积核。
- 数学原理 :两个 3×33 \times 33×3 卷积层的感受野(能看到的图片范围)等于一个 5×55 \times 55×5 卷积层;三个 3×33 \times 33×3 等于一个 7×77 \times 77×7。
- 优势 :使用多个 3×33 \times 33×3 卷积,不仅参数量更少,而且多出了好几次ReLU激活函数,让网络的非线性表达能力大大增强。
1.2.2 代码实现
1. 定义 VGG 块 (VGG Block)
一个VGG块包含:指定数量的 3×33 \times 33×3 卷积层(带着ReLU) + 1个最大池化层。
python
from d2l import torch as d2l
import torch
from torch import nn
def vgg_block(num_convs, in_channels, out_channels):
layers = [] # 用一个列表来临时装载我们要搭建的层
# 循环添加卷积层
for _ in range(num_convs):
# 核心:全部使用 3x3 卷积,且 padding=1。
# padding=1 的精妙之处在于:输入和输出的特征图(长宽)尺寸完全不变!
layers.append(nn.Conv2d(in_channels, out_channels,
kernel_size=3, padding=1))
layers.append(nn.ReLU())
# 第一个卷积层把 in_channels 变成了 out_channels
# 块内后续的卷积层,输入输出都是 out_channels 了
in_channels = out_channels
# 在经过了几个尺寸不变的卷积层提取特征后,最后加一个池化层
# kernel_size=2, stride=2 的作用是:将特征图的长和宽精确减半!
layers.append(nn.MaxPool2d(kernel_size=2, stride=2))
# *layers 是 Python 的解包(Unpacking)语法
# 相当于把列表里的元素一个个拿出来喂给 nn.Sequential
return nn.Sequential(*layers) 2. 定义 VGG-11 网络
VGG-11 包含 8个卷积层 + 3个全连接层 = 11层(带有权重的层才算作网络深度)。
python
# 定义网络架构的超参数:(该块中卷积层的个数, 该块的输出通道数)
conv_arch = ((1, 64), (1, 128), (2, 256), (2, 512), (2, 512))
def vgg(conv_arch):
conv_blks = []
in_channels = 1 # 输入是单通道灰度图 (Fashion-MNIST)
# 1. 卷积层部分(特征提取器)
for (num_convs, out_channels) in conv_arch:
# 调用刚才写好的函数,构建块并塞进列表
conv_blks.append(vgg_block(num_convs, in_channels, out_channels))
in_channels = out_channels # 为下一个块做准备
# 2. 拼装整个网络
return nn.Sequential(
*conv_blks, # 解包5个VGG块
nn.Flatten(), # 将多维特征图拉平为一维向量,准备喂给全连接层
# 3. 全连接层部分(分类器)
# 为什么输入维度是 out_channels * 7 * 7 ?
# 因为原始图片是 224x224。经过5个池化层,每次减半:224 -> 112 -> 56 -> 28 -> 14 -> 7。
# 最后的通道数 out_channels 是 512,所以扁平化后长度为 512 * 7 * 7 = 25088。
nn.Linear(out_channels * 7 * 7, 4096), nn.ReLU(), nn.Dropout(0.5),
nn.Linear(4096, 4096), nn.ReLU(), nn.Dropout(0.5),
nn.Linear(4096, 10)) # 输出10类
net = vgg(conv_arch)3. 训练网络(缩水版 VGG)
正宗的VGG参数量达到了1.3亿,如果直接里跑,哪怕用GPU也要等很久。所以我们搞了个**"缩水版"**。
python
ratio = 4
# 把每个块的输出通道数全部除以4(64变成16,512变成128...)
# 计算量和参数量呈平方级下降,极大加快了训练速度,用于教学演示
small_conv_arch = [(pair[0], pair[1] // ratio) for pair in conv_arch]
net = vgg(small_conv_arch)
# 像AlexNet一样加载数据并训练
lr, num_epochs, batch_size = 0.05, 10, 128
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size, resize=224)
d2l.train_ch6(net, train_iter, test_iter, num_epochs, lr, d2l.try_gpu())输出:
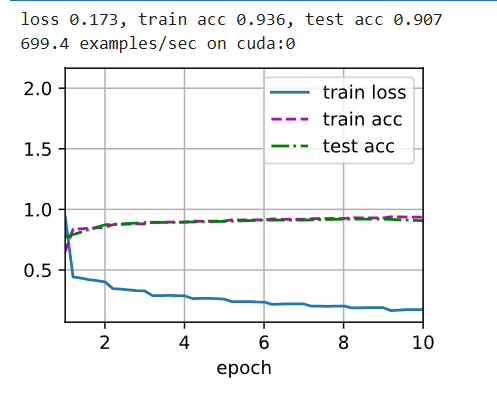
一些练习题
1. 打印层的尺寸时,我们只看到8个结果,而不是11个结果。剩余的3层信息去哪了?
pythonX = torch.randn(size=(1, 1, 224, 224)) for blk in net: X = blk(X) print(blk.__class__.__name__, 'output shape:\t', X.shape)
Sequential output shape: torch.Size([1, 64, 112, 112]) Sequential output shape: torch.Size([1, 128, 56, 56]) Sequential output shape: torch.Size([1, 256, 28, 28]) Sequential output shape: torch.Size([1, 512, 14, 14]) Sequential output shape: torch.Size([1, 512, 7, 7]) Flatten output shape: torch.Size([1, 25088]) Linear output shape: torch.Size([1, 4096]) ReLU output shape: torch.Size([1, 4096]) Dropout output shape: torch.Size([1, 4096]) Linear output shape: torch.Size([1, 4096]) ReLU output shape: torch.Size([1, 4096]) Dropout output shape: torch.Size([1, 4096]) Linear output shape: torch.Size([1, 10])解答:
因为在深度学习中,"网络层数"(如VGG-11, VGG-16)只计算带有学习参数的层 (即卷积层
Conv2D和全连接层Linear)。
- VGG-11 的组成:
conv_arch中定义了 1+1+2+2+2 = 8个卷积层 ,加上最后的 3个全连接层 ,共计 11层。- 为什么代码遍历打印出来的结果没有11个?因为代码中
for blk in net:遍历的是nn.Sequential里面的最外层元素。前5个元素是打包好的VGG块(里面藏了8个卷积层),后几个元素是展平层、全连接层。打印的是模块结构,而不是严格按权重层来数的。2. 与AlexNet相比,VGG的计算要慢得多,而且它还需要更多的显存。分析出现这种情况的原因。
解答:
- 计算更慢(FLOPs剧增) :VGG在较浅的层就使用了大量的通道数(比如第一个块输出64通道,第二个就128通道)。大量的通道数配合频繁的 3×33 \times 33×3 卷积滑动,导致矩阵乘法计算量远超AlexNet。
- 显存需求更大(参数量爆炸) :最大的罪魁祸首在于第一个全连接层。AlexNet池化后的特征图是 256×5×5256 \times 5 \times 5256×5×5,而VGG最后池化后的特征图是 512×7×7512 \times 7 \times 7512×7×7。
导致第一个全连接层的权重矩阵为:(512×7×7)×4096=25088×4096≈1亿个参数(512 \times 7 \times 7) \times 4096 = 25088 \times 4096 \approx \mathbf{1亿个参数}(512×7×7)×4096=25088×4096≈1亿个参数!光这一层就占用了约400MB的显存,这是极为恐怖的。3. 尝试将Fashion-MNIST数据集图像的高度和宽度从224改为96。这对实验有什么影响?
解答:
如果把输入直接改成 96,代码会直接报错崩溃(Crash)!
- 推导: 96 经过 5 个 VGG块(5次除以2),尺寸变化为:96→48→24→12→6→396 \rightarrow 48 \rightarrow 24 \rightarrow 12 \rightarrow 6 \rightarrow 396→48→24→12→6→3。
- 原因: 到了全连接层前,特征图尺寸变成了 3×33 \times 33×3。展平后的长度应该是
out_channels * 3 * 3。但是,在代码的nn.Linear(out_channels * 7 * 7, 4096)中,7×77 \times 77×7 被硬编码(写死了)。维度不匹配,PyTorch 就会报错。- 引申:这也是后来全卷积网络(FCN)和全局平均池化(Global Average Pooling, 在ResNet中应用)诞生的原因------为了摆脱全连接层对输入图片尺寸的死板要求。
4. 请参考VGG论文中的表1构建其他常见模型,如VGG-16或VGG-19。
解答:
有了 VGG块的模板,构建更深的网络只需要改一行代码(修改超参数
conv_arch):
VGG-16 (13个卷积层 + 3个全连接):
前面2个块各有2个卷积层,后面3个块各有3个卷积层。
pythonvgg16_arch = ((2, 64), (2, 128), (3, 256), (3, 512), (3, 512)) net_vgg16 = vgg(vgg16_arch)VGG-19 (16个卷积层 + 3个全连接):
前面2个块各有2个卷积层,后面3个块各有4个卷积层。
pythonvgg19_arch = ((2, 64), (2, 128), (4, 256), (4, 512), (4, 512)) net_vgg19 = vgg(vgg19_arch)这也正是讲义开头所说的:"通过使用循环和子程序,可以很容易地实现重复架构。" VGG让网络设计从"拼砖头"变成了"搭积木"。
1.3 NIN
如果说 VGG 解决了"网络如何搭得更深"的问题,那么 NiN 就彻底解决了"全连接层参数爆炸"的问题 。NiN 提出的两大核心创新------1×11 \times 11×1 卷积 和全局平均池化(GAP),成为了后来几乎所有现代卷积神经网络(如 ResNet, Inception, MobileNet 等)的标准配置。
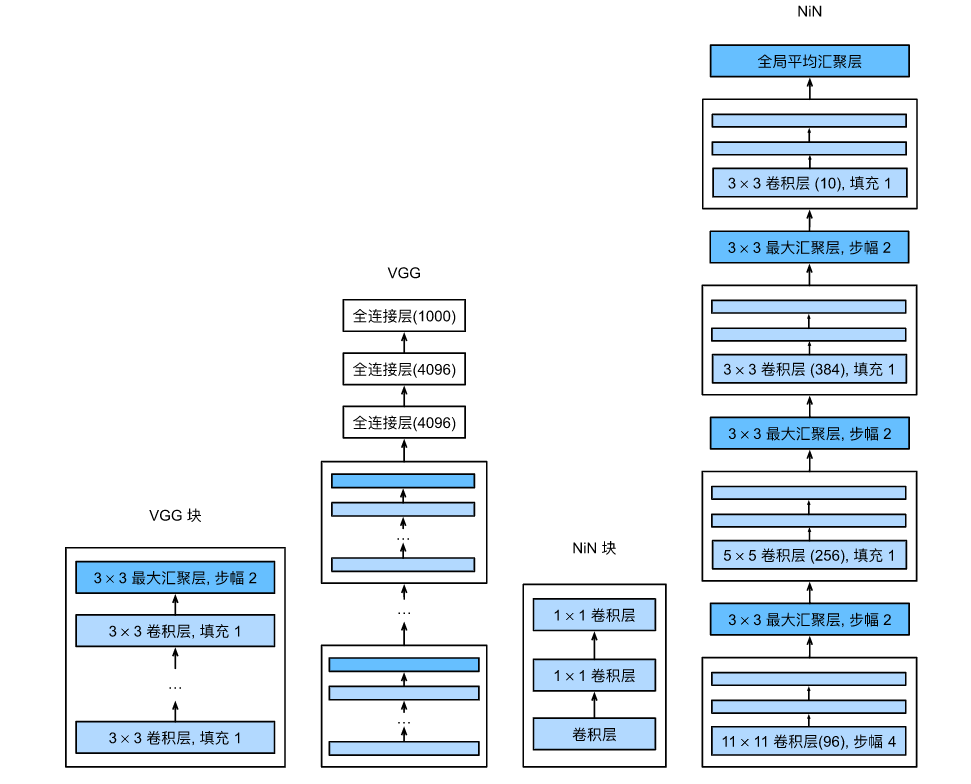
对比 VGG 和 NiN 及它们的块之间主要架构差异。
1.3.1 NiN 的两大核心创新
在 NiN 之前(包括 AlexNet 和 VGG),网络架构都是"两段式":
- 前半部分:卷层 + 池化层(提取空间特征)。
- 后半部分:把特征图拉平(Flatten),接上几个巨大的**全连接层(MLP)**来输出分类结果。
痛点在于全连接层(FC层):
以 VGG 为例,第一个全连接层的参数量高达 1 亿,这不仅极度消耗显存,而且由于参数太多,极其容易过拟合(Overfitting)。此外,把二维的图片拉平成一维,也破坏了空间结构。
NiN 团队心想:能不能彻底干掉全连接层? 他们做出了两点创新:
创新 1:NiN 块(本质是引入 1×11 \times 11×1 卷积)
普通的卷积层只用一个线性滤波器扫过图片,提取特征的能力有限。
NiN 提出:我们在每一次普通卷积之后,加上两个 1×11 \times 11×1 卷积层。
- 为什么是 1×11 \times 11×1 卷积? 想象你站在特征图的某一个像素点上,垂直往下看所有的通道(Channels)。1×11 \times 11×1 卷积不对空间(高和宽)做任何改变,它只对通道维度进行跨通道的线性组合。
- 等价性: 一个 1×11 \times 11×1 卷积层 + ReLU 激活,等价于在图片每一个像素位置上单独作用的一个全连接层(多层感知机 MLP)。这大大增强了网络在局部区域的非线性表达能力。
创新 2:全局平均池化(Global Average Pooling, GAP)
如何不用全连接层输出分类结果?
假设我们要对 10 种衣服分类(Fashion-MNIST):
- NiN 把最后一个卷积层的输出通道数,强行设定为 10(也就是类别数)。
- 此时我们得到 10 张特征图,比如每张大小是 5×55 \times 55×5。
- 全局平均池化 :对这 10 张特征图,每张图求一个平均值 。这样 10×5×510 \times 5 \times 510×5×5 的张量,瞬间变成了 10×1×110 \times 1 \times 110×1×1 的向量(10个数字)。
- 这 10 个数字直接作为 10 个类别的预测分数(Logits)送去算损失。
- 优势:GAP 没有任何权重参数,彻底消除了过拟合的重灾区,参数量锐减。
1.3.2 代码实现
1. 定义 NiN 块 (NiN Block)
python
import torch
from torch import nn
from d2l import torch as d2l
def nin_block(in_channels, out_channels, kernel_size, strides, padding):
return nn.Sequential(
# 第一层:普通的卷积层,负责提取感受野内的空间特征
# 由用户决定 kernel_size, strides, padding
nn.Conv2d(in_channels, out_channels, kernel_size, strides, padding),
nn.ReLU(),
# 第二层:1x1 卷积层。
# 注意:输入和输出通道都是 out_channels,尺寸不变。相当于在像素点上做全连接。
nn.Conv2d(out_channels, out_channels, kernel_size=1),
nn.ReLU(),
# 第三层:又一个 1x1 卷积层。
# 为什么要两个 1x1?因为两层加上非线性激活,才构成一个真正的"多层感知机",拟合能力更强。
nn.Conv2d(out_channels, out_channels, kernel_size=1),
nn.ReLU())2. 定义完整的 NiN 网络
NiN 的整体架构借鉴了 AlexNet(使用了 11×1111\times1111×11, 5×55\times55×5, 3×33\times33×3 等不同的感受野)。
python
net = nn.Sequential(
# 第 1 个 NiN 块:模拟 AlexNet 的第一层
# 输入通道1(灰度图),输出通道96,大卷积核 11x11,步幅为4(大幅缩小尺寸)
nin_block(1, 96, kernel_size=11, strides=4, padding=0),
nn.MaxPool2d(3, stride=2), # 池化层进一步降采样
# 第 2 个 NiN 块
nin_block(96, 256, kernel_size=5, strides=1, padding=2),
nn.MaxPool2d(3, stride=2),
# 第 3 个 NiN 块
nin_block(256, 384, kernel_size=3, strides=1, padding=1),
nn.MaxPool2d(3, stride=2),
nn.Dropout(0.5), # 在预测分类前加入 Dropout,防止特征共适应,进一步正则化
# 第 4 个 NiN 块(分类块)
# 将上一层的 384 个通道,直接降维映射到 10 个通道(因为我们要分10类)
nin_block(384, 10, kernel_size=3, strides=1, padding=1),
# 全局平均池化层 GAP
# nn.AdaptiveAvgPool2d((1, 1)) 是 PyTorch 的自适应平均池化。
# 无论前面传过来的特征图长宽是多少 (比如 5x5),它都会把每个通道强制平均成 1x1 的大小。
# 结果形状:(Batch_Size, 10, 1, 1)
nn.AdaptiveAvgPool2d((1, 1)),
# 最后用 Flatten 把多余的维度去掉
# (Batch_Size, 10, 1, 1) -> (Batch_Size, 10)
# 这 10 个数字就直接作为最终的分类预测得分,不需要 Linear
nn.Flatten()
)3. 查看输出形状
python
X = torch.rand(size=(1, 1, 224, 224))
for layer in net:
X = layer(X)
print(layer.__class__.__name__, 'output shape:\t', X.shape)输出:
Sequential output shape: torch.Size([1, 96, 54, 54])
MaxPool2d output shape: torch.Size([1, 96, 26, 26])
Sequential output shape: torch.Size([1, 256, 26, 26])
MaxPool2d output shape: torch.Size([1, 256, 12, 12])
Sequential output shape: torch.Size([1, 384, 12, 12])
MaxPool2d output shape: torch.Size([1, 384, 5, 5])
Dropout output shape: torch.Size([1, 384, 5, 5])
Sequential output shape: torch.Size([1, 10, 5, 5])
AdaptiveAvgPool2d output shape: torch.Size([1, 10, 1, 1])
Flatten output shape: torch.Size([1, 10])训练
python
lr, num_epochs, batch_size = 0.1, 10, 128
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size, resize=224)
d2l.train_ch6(net, train_iter, test_iter, num_epochs, lr, d2l.try_gpu())输出:
loss 0.325, train acc 0.880, test acc 0.880
994.4 examples/sec on cuda:0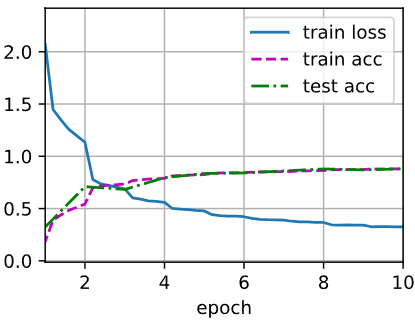
一些练习题
1. 调整NiN的超参数,以提高分类准确性。
解答:可以尝试:1. 增加每个 block 的通道数(如 96->128, 256->512);2. 修改学习率和 Batch Size;3. 增加数据增强(如随机裁剪、翻转)。NiN 比较难收敛,有时需要较小的初始学习率配合学习率衰减。
2. 为什么NiN块中有两个 1×11\times 11×1 卷积层?删除其中一个,然后观察和分析实验现象。
解答:
- 为什么是两个 :在神经网络理论中,单层 感知机(等于只有一层 1×11\times 11×1 卷积)只能解决线性可分问题;至少需要两层 加上非线性激活函数(ReLU),才能逼近任意复杂的非线性函数。所以两个 1×11\times 11×1 卷积构成了一个微型的多层感知机(MLP),能在不改变空间结构的前提下,充分融合各通道的特征。
- 删除一个的后果 :如果只保留一个 1×11\times 11×1 卷积,网络的非线性拟合能力会下降。你会观察到模型在训练集上的收敛速度变慢,最终的准确率(Accuracy)可能会降低 1%~3% 左右。
3. 计算NiN的资源使用情况(对比 AlexNet/VGG)。
解答:
- 参数数量 :极少 !因为干掉了全连接层,参数几乎全在第一层的 11×1111\times1111×11 卷积和后续的特征提取卷积中。相比 AlexNet 动辄 6000 万参数,NiN 通常只有几百万参数,锐减 90% 以上。
- 计算量(FLOPs) :偏高 。虽然参数少了,但 1×11\times11×1 卷积相当于在图片的每一个像素点 上都做了一次矩阵乘法。如果特征图很大(比如 54×5454\times5454×54),这个计算量是相当恐怖的,导致 NiN 训练速度偏慢。
- 训练显存:由于卷积层多,前向传播时需要保存大量中间特征图(Activations)用于反向传播算梯度,显存占用不低。
- 预测显存:较低。预测时不需要保存中间梯度,只需保留当前层和下一层的数据即可。
4. 一次性直接将 384×5×5384 \times 5 \times 5384×5×5 的表示缩减为 10×5×510 \times 5 \times 510×5×5 的表示,会存在哪些问题?
解答 :
这是著名的信息瓶颈(Information Bottleneck)问题 。
如果用一个普通的 1×11\times 11×1 或 3×33\times 33×3 卷积,直接把 384 个通道压缩到 10 个通道,通道数骤降了 38 倍!
这就像一条八车道的高速公路突然收缩成一条乡间小道,大量的高维抽象特征(比如各种纹理、边缘组合)会被不可逆转地丢失/挤压掉 。
这会导致网络损失大量的表达能力,准确率崩塌。后续的 ResNet(残差网络)中的 Bottleneck 设计,也是通过极其精巧的方式(先降维再升维)来规避这个问题的。
1.4 GoogLeNet
**GoogLeNet(也叫 Inception v1)**是2014年ImageNet大赛的冠军模型。
如果说VGG的贡献是"网络可以堆得很深",NiN的贡献是"去掉了全连接层",那么GoogLeNet的贡献就是:"网络不仅可以很深,还可以很宽,并且计算效率极高!"
1.4.1 为什么要有Inception块?
在GoogLeNet之前,设计神经网络有一个让人头疼的问题:我到底该用多大的卷积核?
- 图片里的物体如果很小(比如远处的狗),用 1×11 \times 11×1 或 3×33 \times 33×3 的小卷积核更好。
- 如果物体很大(比如占据全图的人脸),用 5×55 \times 55×5 或 11×1111 \times 1111×11 的大卷积核更好。
GoogLeNet的作者(谷歌团队)给出了一个简单粗暴但极其聪明的答案:"小孩子才做选择,我全都要!"
1.4.2 Inception块的"多管齐下"
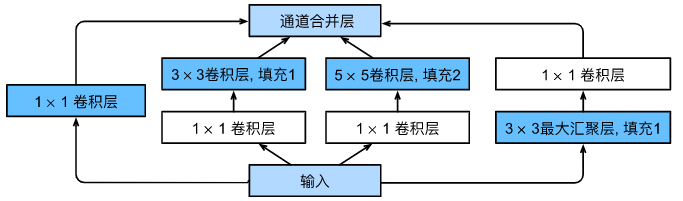
Inception块的架构
在同一个模块(Inception块)里,作者设计了四条并行的路线:
- 路线1 :1×11 \times 11×1 卷积(看单个像素的通道融合)
- 路线2 :3×33 \times 33×3 卷积(看局部细节)
- 路线3 :5×55 \times 55×5 卷积(看更大范围的轮廓)
- 路线4 :3×33 \times 33×3 最大池化(提取最显著的特征)
把这四条路线提取到的特征,在通道维度上拼接到一起(Concatenate)。这样,网络自己就能在训练中学习到,针对当前的图片,到底哪条路线的特征最有用。
1.4.3 1×11 \times 11×1 卷积的"降维打击"(瓶颈设计 Bottleneck)
如果你同时做这么多复杂的卷积,计算量和通道数会瞬间爆炸!
为了解决这个问题,作者大量借鉴了 NiN 的思想,在 3×33 \times 33×3 和 5×55 \times 55×5 卷积的前面,以及池化层的后面,强行插入了 1×11 \times 11×1 卷积。
- 作用 :1×11 \times 11×1 卷积能在不改变图片长宽的前提下,大幅压缩通道数(降维)。
- 效果 :这使得 GoogLeNet 虽然看起来极其复杂、网络很深,但它的参数量实际上只有 AlexNet 的十二分之一!
1.4.4 代码实现
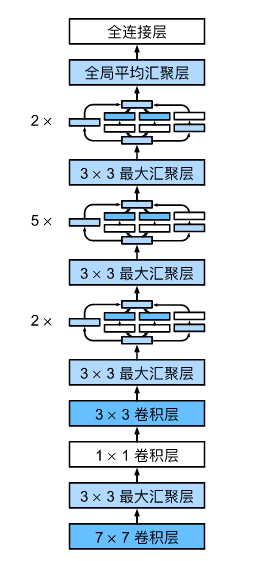
GoogLeNet架构
GoogLeNet一共使用9个Inception块和全局平均汇聚层的堆叠来生成其估计值。Inception块之间的最大汇聚层可降低维度。 第一个模块类似于AlexNet和LeNet,Inception块的组合从VGG继承,全局平均汇聚层避免了在最后使用全连接层。
1. 定义 Inception 块
python
from d2l import torch as d2l
import torch
from torch import nn
from torch.nn import functional as F
class Inception(nn.Module):
# c1--c4 是我们为四条路径指定的输出通道数
def __init__(self, in_channels, c1, c2, c3, c4, **kwargs):
super(Inception, self).__init__(**kwargs)
# 路线 1:最简单的单 1x1 卷积
self.p1_1 = nn.Conv2d(in_channels, c1, kernel_size=1)
# 路线 2:1x1 卷积 (降维) -> 接 3x3 卷积
# 【关键点】padding=1 保证了 3x3 卷积后,图片的长宽不变
self.p2_1 = nn.Conv2d(in_channels, c2[0], kernel_size=1)
self.p2_2 = nn.Conv2d(c2[0], c2[1], kernel_size=3, padding=1)
# 路线 3:1x1 卷积 (降维) -> 接 5x5 卷积
# 【关键点】padding=2 保证了 5x5 卷积后,图片的长宽不变
self.p3_1 = nn.Conv2d(in_channels, c3[0], kernel_size=1)
self.p3_2 = nn.Conv2d(c3[0], c3[1], kernel_size=5, padding=2)
# 路线 4:3x3 最大池化 -> 接 1x1 卷积 (降维)
# stride=1 和 padding=1 保证了池化后长宽不变
self.p4_1 = nn.MaxPool2d(kernel_size=3, stride=1, padding=1)
self.p4_2 = nn.Conv2d(in_channels, c4, kernel_size=1)
def forward(self, x):
# 分别将输入 x 送入四条路线,并经过 ReLU 激活
p1 = F.relu(self.p1_1(x))
p2 = F.relu(self.p2_2(F.relu(self.p2_1(x))))
p3 = F.relu(self.p3_2(F.relu(self.p3_1(x))))
p4 = F.relu(self.p4_2(self.p4_1(x)))
# 【核心操作】在通道维度(dim=1)上将四个输出拼接起来
# 因为前面精心设置了 padding,所以 p1~p4 的空间长宽完全一致,可以直接无缝拼接
return torch.cat((p1, p2, p3, p4), dim=1)2. 搭建 GoogLeNet 网络(五大模块)
GoogLeNet 把网络分成了 b1 到 b5 五个大模块(Block)。那些奇怪的通道数(如 (96, 208))是谷歌科学家用大量算力搜索出来的"最佳超参数",我们直接照抄即可。
python
# 模块 b1:前期特征提取(模仿 AlexNet 的开头)
# 使用 7x7 大卷积核快速降低图片分辨率
b1 = nn.Sequential(nn.Conv2d(1, 64, kernel_size=7, stride=2, padding=3),
nn.ReLU(),
nn.MaxPool2d(kernel_size=3, stride=2, padding=1))
# 模块 b2:进一步提取特征
# 1x1 卷积 + 3x3 卷积,通道数升到 192
b2 = nn.Sequential(nn.Conv2d(64, 64, kernel_size=1),
nn.ReLU(),
nn.Conv2d(64, 192, kernel_size=3, padding=1),
nn.ReLU(),
nn.MaxPool2d(kernel_size=3, stride=2, padding=1))
# 模块 b3:真正开始使用 Inception 块
# 串联 2 个 Inception 块,最后跟一个最大池化层降维
b3 = nn.Sequential(
# Inception(输入通道数, c1, (c2_0, c2_1), (c3_0, c3_1), c4)
Inception(192, 64, (96, 128), (16, 32), 32), # 输出通道:64+128+32+32 = 256
Inception(256, 128, (128, 192), (32, 96), 64), # 输出通道:128+192+96+64 = 480
nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
)
# 模块 b4:网络的中坚力量
# 疯狂串联 5 个 Inception 块,通道数一路飙升到 832
b4 = nn.Sequential(
Inception(480, 192, (96, 208), (16, 48), 64),
Inception(512, 160, (112, 224), (24, 64), 64),
Inception(512, 128, (128, 256), (24, 64), 64),
Inception(512, 112, (144, 288), (32, 64), 64),
Inception(528, 256, (160, 320), (32, 128), 128),
nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
)
# 模块 b5:收尾工作
# 2 个 Inception 块 + 全局平均池化(GAP)
b5 = nn.Sequential(
Inception(832, 256, (160, 320), (32, 128), 128),
Inception(832, 384, (192, 384), (48, 128), 128), # 最终输出通道:384+384+128+128 = 1024
nn.AdaptiveAvgPool2d((1,1)), # 从 NiN 学来的:把每个通道的特征图平均成 1x1,消灭全连接层的过拟合隐患
nn.Flatten() # 拉平为 1024 长度的向量
)
# 组装最终网络
# 最后接一个简单的全连接层,输出 10 个类别(Fashion-MNIST)
net = nn.Sequential(b1, b2, b3, b4, b5, nn.Linear(1024, 10))训练
python
lr, num_epochs, batch_size = 0.1, 10, 128
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size, resize=96)
d2l.train_ch6(net, train_iter, test_iter, num_epochs, lr, d2l.try_gpu())输出:
loss 0.239, train acc 0.907, test acc 0.862
1066.5 examples/sec on cuda:0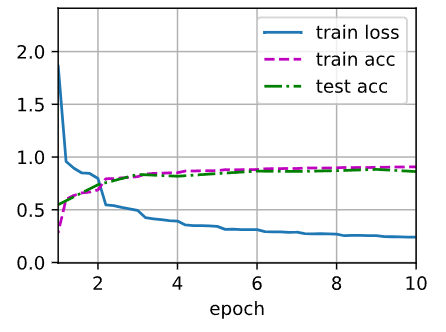
一些练习题
1. GoogLeNet的后续版本演进(V2, V3, V4)是什么?
- Inception V2 :引入了批量归一化(Batch Normalization)。大大加快了训练速度,让模型不再那么挑剔初始化的参数。
- Inception V3 :提出了非对称卷积分解 。把一个 5×55 \times 55×5 的卷积拆成两个 3×33 \times 33×3 的卷积串联;甚至把一个 3×33 \times 33×3 拆成一个 1×31 \times 31×3 加上一个 3×13 \times 13×1。这不仅进一步减少了参数,还增加了非线性层数。(目前工程中最常用的是V3)。同时引入了**标签平滑(Label Smoothing)**防止过拟合。
- Inception V4 (Inception-ResNet):打不过就加入。看到了何恺明发明的 ResNet(残差网络)太猛了,于是把"残差连接"和 Inception 结合在一起,训练速度和准确率进一步起飞。
2. 使用GoogLeNet的最小图像大小是多少?
解答:32×3232 \times 3232×32(理论极限)。
- 我们来数一下网络中有多少次空间降采样(使得长宽减半的操作)。
b1中有一个stride=2的卷积和一个stride=2的池化(除以 4)。b2,b3,b4中各有一个stride=2的最大池化(各除以 2)。- 总计缩小的倍数是:2×2×2×2×2=322 \times 2 \times 2 \times 2 \times 2 = \mathbf{32}2×2×2×2×2=32 倍。
- 如果输入图像小于 32×3232 \times 3232×32(比如 28×2828 \times 2828×28),经过五次减半后,特征图尺寸会变成 0(或者小于1),卷积操作就会报错崩溃。所以输入尺寸必须至少是 32×3232 \times 3232×32。
3. 将AlexNet、VGG和NiN的模型参数大小与GoogLeNet进行比较。后两个网络架构是如何显著减少模型参数大小的?
解答:
- 参数量对比:VGG(约 1.3 亿) >>> AlexNet(约 6000 万) > GoogLeNet(约 500 万) > NiN(约 200 万)。
- 减少参数的核心秘诀 :
- 全局平均池化(GAP):NiN 和 GoogLeNet 都彻底抛弃了巨大的第一层全连接层。你要知道,VGG 的第一个全连接层就占了 1 亿个参数!换成 GAP 后,这里参数量直接变成了 0。
- 1×11 \times 11×1 卷积降维(瓶颈层) :GoogLeNet 在执行昂贵的 3×33 \times 33×3 和 5×55 \times 55×5 卷积之前,先用 1×11 \times 11×1 卷积把厚厚的通道数"压缩"变薄,算完之后再拼接。这让 GoogLeNet 可以在保持极高深度的同时,控制住了参数爆炸。
1.5 批量规范化
批量规范化(Batch Normalization, 简称 BatchNorm 或 BN)。
在2015年BN被提出之前,训练深层神经网络(比如超过20层)简直是一场噩梦,网络极容易因为梯度消失或爆炸而崩溃,研究人员只能小心翼翼地调节学习率和权重初始化。BN 的出现彻底改变了游戏规则,不仅能训练上百层的网络(如ResNet),还能使用极大的学习率,极大地缩短了训练时间。
1.5.1 核心理论
1. 为什么要用 BN?(痛点是什么)
- 输入标准化有效,那中间层呢? 我们知道在把数据喂给神经网络前,通常会把像素值减去均值除以标准差(变成均值为0,方差为1),这会让模型学得更快。但是,随着网络越来越深,数据经过一层层的矩阵乘法和激活函数,每一层输出的数据分布都在剧烈变化(这在原论文中被称为"内部协变量偏移 Internal Covariate Shift")。
- 后一层的痛苦:前一层权重的微小变化,会导致后一层接收到的数据分布大变。后一层总是被迫不断适应新的数据分布,导致整个网络学习极度缓慢。
1.5.2 BN 的数学原理
不管你前面的层把数据分布搞得多乱,我都在每一层强制把你拉回到"均值为0,方差为1"的标准正态分布。
具体步骤如下(针对某一个批次 Batch 的数据):
- 求均值 :μ=1m∑xi\mu = \frac{1}{m} \sum x_iμ=m1∑xi
- 求方差 :σ2=1m∑(xi−μ)2\sigma^2 = \frac{1}{m} \sum (x_i - \mu)^2σ2=m1∑(xi−μ)2
- 标准化 :x^i=xi−μσ2+ϵ\hat{x}_i = \frac{x_i - \mu}{\sqrt{\sigma^2 + \epsilon}}x^i=σ2+ϵ xi−μ (加一个极小的 ϵ\epsilonϵ 是为了防止分母为0)
- ★ 缩放和偏移(拉伸参数 γ\gammaγ 和 偏移参数 β\betaβ) :yi=γx^i+βy_i = \gamma \hat{x}_i + \betayi=γx^i+β
为什么要进行第4步?
如果只做到第3步,把所有数据都强制变成均值为0、方差为1,会严重破坏网络原本学到的特征表达能力 。比如某些特征本来就需要是非负的,你非要把它拉到0附近。
因此,BN 引入了两个可学习的参数 γ\gammaγ 和 β\betaβ。网络可以通过反向传播自己学习这两个参数。如果网络觉得不需要标准化,它可以学到 γ=σ\gamma = \sigmaγ=σ 且 β=μ\beta = \muβ=μ,从而完美还原原本的数据。这给了网络"选择的自由"。
1.5.3 训练模式 vs 预测模式
- 训练时:我们每次传入一个 Batch(比如 128 张图片),我们就计算这 128 张图片的均值和方差来进行标准化。
- 预测/推理时:用户可能一次只传 1 张图片进来测试,1张图片是没法算均值和方差的,怎么办?
- 解决办法 :在训练的过程中,BN 层会偷偷记录一个全局移动平均均值(moving_mean)和移动平均方差(moving_var)。到了预测阶段,就直接用这两个全局统计量来进行标准化。
1.5.4. 全连接层与卷积层的区别
- 全连接层 :作用在特征维度(也就是神经元个数)上。(即几个神经元几对参数)
- 卷积层 :作用在**通道(Channel)**维度上。如果输出有 64 个通道,就有 64 对 γ\gammaγ 和 β\betaβ。同一个通道内,不管是哪一张图片、哪个像素位置,全都在一起算均值和方差。
1.5.5 代码实现
1. 核心数学逻辑实现 (batch_norm 函数)
python
from d2l import torch as d2l
import torch
from torch import nn
# 这个函数实现了 BN 的纯数学计算逻辑
def batch_norm(X, gamma, beta, moving_mean, moving_var, eps, momentum):
# 【1. 判断模式】
# torch.is_grad_enabled() 用来判断当前是否在算梯度(即是否在训练模式)
if not torch.is_grad_enabled():
# 如果是预测模式:直接拿平时攒下来的全局变量 moving_mean 和 moving_var 来用
X_hat = (X - moving_mean) / torch.sqrt(moving_var + eps)
else:
# 如果是训练模式:
assert len(X.shape) in (2, 4) # 2代表全连接层(Batch, Features),4代表卷积层(Batch, Channels, H, W)
# 【2. 计算均值和方差】
if len(X.shape) == 2:
# 对于全连接层,沿着 Batch 维度(dim=0)求均值和方差
mean = X.mean(dim=0)
var = ((X - mean) ** 2).mean(dim=0)
else:
# 对于卷积层,沿着 Batch(dim=0), 高(dim=2), 宽(dim=3) 求均值和方差
# 唯独保留了通道维度(dim=1),因为每个通道要单独算一组统计量!
# keepdim=True 是为了让求完均值后的形状保持为 (1, Channels, 1, 1),方便后面广播机制做减法
mean = X.mean(dim=(0, 2, 3), keepdim=True)
var = ((X - mean) ** 2).mean(dim=(0, 2, 3), keepdim=True)
# 【3. 执行标准化】使用当前 Batch 算出来的均值和方差
X_hat = (X - mean) / torch.sqrt(var + eps)
# 【4. 更新全局统计量】(指数加权移动平均)
# momentum 通常设为 0.9。意味着旧均值占90%权重,当前batch的均值占10%权重。
moving_mean = momentum * moving_mean + (1.0 - momentum) * mean
moving_var = momentum * moving_var + (1.0 - momentum) * var
# 【5. 缩放和偏移】乘以学习参数 gamma,加上学习参数 beta
Y = gamma * X_hat + beta
# 返回标准化后的结果,以及更新后的全局变量 (使用 .data 防止把它们加入计算图求梯度)
return Y, moving_mean.data, moving_var.data2. 将逻辑封装成 PyTorch 的 Layer (BatchNorm 类)
python
class BatchNorm(nn.Module):
# num_features: 全连接层的节点数,或卷积层的通道数
# num_dims: 2 表示全连接,4 表示卷积
def __init__(self, num_features, num_dims):
super().__init__()
if num_dims == 2:
shape = (1, num_features)
else:
shape = (1, num_features, 1, 1)
# 【非常关键】:gamma 和 beta 是网络的权重参数,需要通过反向传播更新!
# 所以必须用 nn.Parameter 包装起来。gamma 初始化为 1,beta 初始化为 0。
self.gamma = nn.Parameter(torch.ones(shape))
self.beta = nn.Parameter(torch.zeros(shape))
# moving_mean 和 moving_var 不是通过梯度更新的,而是自己手动算出来的。
# 所以它们只是普通的 Tensor,不需要求导。
self.moving_mean = torch.zeros(shape)
self.moving_var = torch.ones(shape)
def forward(self, X):
# 确保全局统计量和输入 X 都在同一个设备上(比如都在同一块 GPU 上)
if self.moving_mean.device != X.device:
self.moving_mean = self.moving_mean.to(X.device)
self.moving_var = self.moving_var.to(X.device)
# 调用前面写的数学逻辑函数
Y, self.moving_mean, self.moving_var = batch_norm(
X, self.gamma, self.beta, self.moving_mean,
self.moving_var, eps=1e-5, momentum=0.9)
return Y3. 将 BN 应用于 LeNet (简明实现/调包方式)
python
net = nn.Sequential(
nn.Conv2d(1, 6, kernel_size=5),
nn.BatchNorm2d(6), # 紧跟在卷积层后面,参数是上一层的输出通道数 6
nn.Sigmoid(), # 放在激活函数前面
nn.AvgPool2d(kernel_size=2, stride=2),
nn.Conv2d(6, 16, kernel_size=5),
nn.BatchNorm2d(16),
nn.Sigmoid(),
nn.AvgPool2d(kernel_size=2, stride=2),
nn.Flatten(),
nn.Linear(256, 120),
nn.BatchNorm1d(120), # 全连接层使用 1d,参数是神经元个数 120
nn.Sigmoid(),
nn.Linear(120, 84),
nn.BatchNorm1d(84),
nn.Sigmoid(),
nn.Linear(84, 10) # 最后一层分类输出,不需要加 BN
)输出:
loss 0.263, train acc 0.903, test acc 0.841
31039.2 examples/sec on cuda:0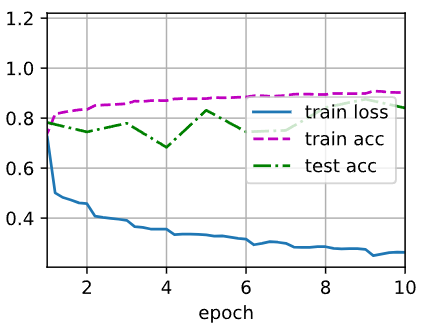
查看gamma 和 beta参数:
python
net[1].gamma.reshape((-1,)), net[1].beta.reshape((-1,))输出:
(tensor([0.3582, 2.4964, 2.7782, 2.7305, 3.0509, 3.8073], device='cuda:0',
grad_fn=<ViewBackward0>),
tensor([ 0.5304, -2.9976, 1.7180, -2.3712, 3.2242, 1.7507], device='cuda:0',
grad_fn=<ViewBackward0>))利用pytorch 中的BatchNorm再来一次
python
net = nn.Sequential(
nn.Conv2d(1, 6, kernel_size=5), nn.BatchNorm2d(6), nn.Sigmoid(),
nn.AvgPool2d(kernel_size=2, stride=2),
nn.Conv2d(6, 16, kernel_size=5), nn.BatchNorm2d(16), nn.Sigmoid(),
nn.AvgPool2d(kernel_size=2, stride=2), nn.Flatten(),
nn.Linear(256, 120), nn.BatchNorm1d(120), nn.Sigmoid(),
nn.Linear(120, 84), nn.BatchNorm1d(84), nn.Sigmoid(),
nn.Linear(84, 10))
d2l.train_ch6(net, train_iter, test_iter, num_epochs, lr, d2l.try_gpu())输出:
loss 0.264, train acc 0.904, test acc 0.878
48306.6 examples/sec on cuda:0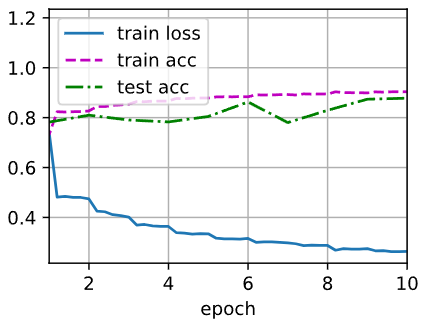
一些练习题:
- 在使用 BN 之前,我们是否可以从全连接层或卷积层中删除偏置参数(Bias)?为什么?
解答:是的,强烈建议删除(设置
bias=False)!
- 数学原因 :偏置相当于对特征图加上一个常数 bbb。但在紧随其后的 BN 层中,第一步操作就是计算均值 μ\muμ 并用数据减去均值。你加上去的这个常数 bbb 会导致均值 μ\muμ 也增加了 bbb。所以在执行 X−μX - \muX−μ 时,这个偏置 bbb 会被完完全全地抵消掉。
- 既然加了也是白加,不如直接删掉,还能节省一点点显存和计算量。BN 层自己的 β\betaβ 参数起到了原先偏置的作用。
- 比较LeNet在使用和不使用BN情况下的学习率。
解答:
- 不使用 BN :学习率通常只能设为
0.01到0.1左右,否则容易发散。收敛需要很多 Epoch。- 使用 BN :如前面代码所示,学习率可以飙升到
1.0甚至更大,且在头几个 Epoch 就能迅速达到很高的准确率。
- 我们是否需要在每个层中进行批量规范化?
解答:
目前主流的经验是:对于所有的中间层(卷积层/全连接层),都建议加 BN。 但是,网络的输出层(最后一层分类层)绝对不能加 BN。因为输出层输出的是原始预测分数(Logits),你需要保持这些分数的绝对大小以进行 Softmax 损失计算,标准化会彻底破坏这些预测结果。
- 可以通过批量规范化来替换暂退法(Dropout)吗?行为会如何改变?
解答:
在很多现代卷积网络(如 ResNet)中,BN 确实完全替代了 Dropout。
- 为什么 BN 也有正则化(防过拟合)效果? 因为在训练时,网络是使用当前 Batch 的均值和方差来进行标准化的。这相当于给每一次数据的传递加入了一些随机的"噪声"(因为每次抽样的 batch 不同,均值和方差都会波动)。这种随机噪声起到了和 Dropout 随机丢弃神经元类似的正则化效果。
- 通常不建议把 BN 和 Dropout 放在一起用(存在"方差偏移"冲突),如果非要用,一般放在全连接层部分。
5. 其他"规范化"转换?
由于 BN 严重依赖 Batch Size(如果 Batch Size 太小,算出来的均值和方差误差极大,网络会崩溃),后来研究者又提出了几种变体:
- Layer Normalization (LN) :在单个样本的特征维度上求均值方差,彻底摆脱对 Batch 的依赖。现在是 Transformer / 大语言模型(LLM) 的绝对标准配置。
- Instance Normalization (IN) :在单样本的单通道上求均值方差,多用于风格迁移 / 图像生成(GAN)。
- Group Normalization (GN):介于 LN 和 IN 之间,当显存不够、Batch Size只能设为 1 或 2 时用来替代 BN。
1.6 ResNet
2015年,何恺明(Kaiming He)团队提出的 ResNet 彻底解决了"深层网络无法训练"的千古难题,一举拿下了当时所有计算机视觉大赛的冠军。毫不夸张地说,现今几乎所有主流模型(包括 Transformer)的内部,都深深烙印着 ResNet 的思想。
1.6.1 核心思想
1.退化问题(Degradation Problem)与嵌套函数
在 ResNet 出现之前,人们发现了一个极其反直觉的现象:当网络层数加深时,模型不仅在测试集上表现变差(过拟合),甚至在训练集上的错误率也变高了.
- 直觉冲突 :假设一个 20 层的网络已经训练得很好了。我现在强行在它后面加 80 层,变成 100 层网络。最差的情况下,这新增的 80 层什么都不做(这叫恒等映射 Identity Mapping ,即 f(x)=xf(x) = xf(x)=x),100 层网络的表现至少应该和 20 层一模一样才对!为什么反而变差了?
- 真相 :神经网络极其不擅长 学习恒等映射 f(x)=xf(x) = xf(x)=x。让一堆经过非线性激活函数的权重层输出和输入一模一样的值,比登天还难。
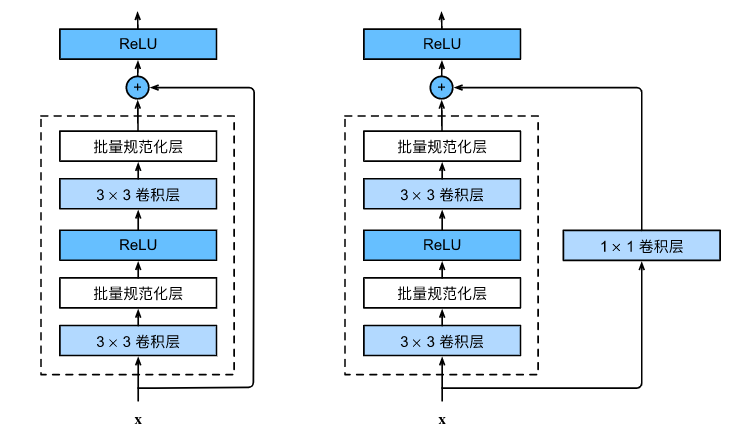
2. 破局之道:残差块(Residual Block)
既然网络很难学出 H(x)=xH(x) = xH(x)=x,何恺明认为我们可以改变一下网络的目标:
- 原来的网络要直接拟合出一个完美的映射 H(x)H(x)H(x)。
- 现在,我们让网络去拟合输入和输出之间的差值(残差) ,记作 F(x)=H(x)−xF(x) = H(x) - xF(x)=H(x)−x。
- 那么最终的输出就变成了:H(x)=F(x)+xH(x) = F(x) + xH(x)=F(x)+x。
这一个"+ x"简直是神来之笔:
- 如果新增的层真的不需要做什么,网络只需要把权重参数 F(x)F(x)F(x) 轻松地更新为 0 即可(因为有权重衰减正则化,变 0 很容易)。此时 H(x)=0+x=xH(x) = 0 + x = xH(x)=0+x=x,完美实现了恒等映射!
- 在反向传播求梯度时,+++ 号会将梯度无损地、原封不动地传给前一层。彻底解决了深层网络"梯度消失"的问题。
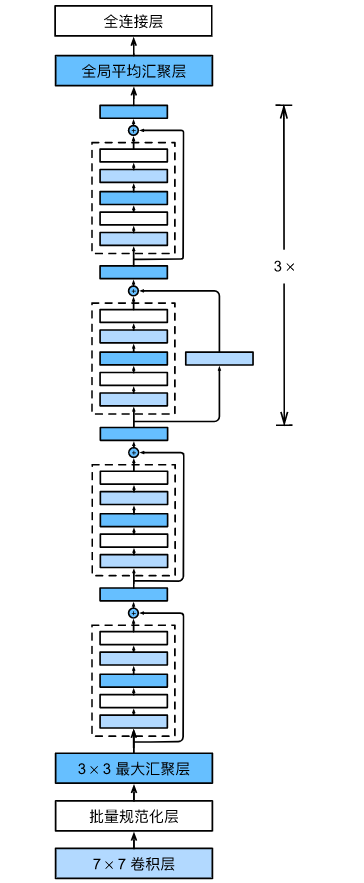
ResNet-18 架构
1.6.2 代码实现
1. 定义残差块 (Residual 类)
它包含两条路:一条是复杂的卷积路,另一条是直接连过去的"捷径(Shortcut/Skip Connection)"。
python
from d2l import torch as d2l
import torch
from torch import nn
from torch.nn import functional as F
class Residual(nn.Module):
# use_1x1conv: 是否需要使用 1x1 卷积来调整捷径的形状
# strides: 步幅。如果是2,不仅降低分辨率,通道数通常也会翻倍
def __init__(self, input_channels, num_channels, use_1x1conv=False, strides=1):
super().__init__()
# 第一层卷积:可能包含下采样(stride=2)
self.conv1 = nn.Conv2d(input_channels, num_channels,
kernel_size=3, padding=1, stride=strides)
# 第二层卷积:stride永远是1,保持尺寸不变
self.conv2 = nn.Conv2d(num_channels, num_channels,
kernel_size=3, padding=1)
# 捷径(Shortcut)分支
if use_1x1conv:
# 如果输入和输出的通道数或尺寸不一致,没法直接相加!
# 必须用一个 1x1 卷积,配合相同的 stride,把 X 的形状变换成和 Y 一样
self.conv3 = nn.Conv2d(input_channels, num_channels,
kernel_size=1, stride=strides)
else:
self.conv3 = None
# 每一个卷积层后都紧跟 BatchNorm
self.bn1 = nn.BatchNorm2d(num_channels)
self.bn2 = nn.BatchNorm2d(num_channels)
def forward(self, X):
# 路线 1:走两层卷积
Y = F.relu(self.bn1(self.conv1(X)))
Y = self.bn2(self.conv2(Y))
# 路线 2:走捷径
if self.conv3:
X = self.conv3(X)
# ★ 核心灵魂:在进入第二次 ReLU 之前,把捷径加进来! ★
Y += X
# 最后再激活
return F.relu(Y)2. 生成一个残差阶段 (resnet_block 函数)
ResNet 的整体架构是由几个大的"阶段(Stage)"组成的。每个阶段包含好几个残差块。
python
def resnet_block(input_channels, num_channels, num_residuals, first_block=False):
blk = []
for i in range(num_residuals): # 循环创建多个残差块
if i == 0 and not first_block:
# 每个 Stage 的【第一个块】,负责把特征图长宽减半 (stride=2),通道数翻倍
# 但是,整个网络的第一个 Stage (first_block=True) 除外,因为前面已经有过下采样了
blk.append(Residual(input_channels, num_channels,
use_1x1conv=True, strides=2))
else:
# 该 Stage 后续的块,全都是保持尺寸和通道不变的纯粹特征提取
blk.append(Residual(num_channels, num_channels))
return blk3. 组装完整的 ResNet-18
ResNet 的宏观架构极其优美、整齐,分为三个大部分:Stem(主干)、Body(躯干:4个Stage)和 Head(头部)。
python
# 1. Stem(主干):快速降低分辨率
# 输入 224x224 单通道图片,经过 7x7 大卷积和最大池化,迅速变成 56x56,64通道
b1 = nn.Sequential(nn.Conv2d(1, 64, kernel_size=7, stride=2, padding=3),
nn.BatchNorm2d(64), nn.ReLU(),
nn.MaxPool2d(kernel_size=3, stride=2, padding=1))
# 2. Body(躯干):4个残差阶段
# b2 的 first_block=True,尺寸不减半,仍为 56x56,通道 64
b2 = nn.Sequential(*resnet_block(64, 64, 2, first_block=True))
# 后面的阶段,每一次都在第一个块执行长宽减半、通道翻倍
b3 = nn.Sequential(*resnet_block(64, 128, 2)) # 输出: 28x28, 128通道
b4 = nn.Sequential(*resnet_block(128, 256, 2)) # 输出: 14x14, 256通道
b5 = nn.Sequential(*resnet_block(256, 512, 2)) # 输出: 7x7, 512通道
# 3. Head(头部):输出分类结果
# 利用 NiN 提出的全局平均池化 GAP,干掉巨大的全连接层矩阵
net = nn.Sequential(b1, b2, b3, b4, b5,
nn.AdaptiveAvgPool2d((1,1)), # 输出: 1x1, 512通道
nn.Flatten(), # 拉平为 512 维向量
nn.Linear(512, 10)) # 映射到 10 个类别注:为什么叫 ResNet-18?因为 b2∼b5b2 \sim b5b2∼b5 共有 4×2=84 \times 2 = 84×2=8 个残差块,每个块 2 层卷积,共 16 层。加上 b1b1b1 里的 1 层卷积和最后头部的 1 层全连接,共 18 层。
查看每层输出形状:
Sequential output shape: torch.Size([1, 64, 56, 56])
Sequential output shape: torch.Size([1, 64, 56, 56])
Sequential output shape: torch.Size([1, 128, 28, 28])
Sequential output shape: torch.Size([1, 256, 14, 14])
Sequential output shape: torch.Size([1, 512, 7, 7])
AdaptiveAvgPool2d output shape: torch.Size([1, 512, 1, 1])
Flatten output shape: torch.Size([1, 512])
Linear output shape: torch.Size([1, 10])训练:
python
Sequential output shape: torch.Size([1, 64, 56, 56])
Sequential output shape: torch.Size([1, 64, 56, 56])
Sequential output shape: torch.Size([1, 128, 28, 28])
Sequential output shape: torch.Size([1, 256, 14, 14])
Sequential output shape: torch.Size([1, 512, 7, 7])
AdaptiveAvgPool2d output shape: torch.Size([1, 512, 1, 1])
Flatten output shape: torch.Size([1, 512])
Linear output shape: torch.Size([1, 10])输出:
loss 0.016, train acc 0.996, test acc 0.859
1735.7 examples/sec on cuda:0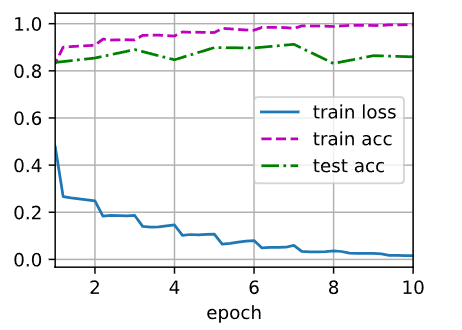
一些练习题
1. Inception块与残差块之间的主要区别是什么?
- 拓扑结构差异 :Inception 是"变宽",通过不同大小的卷积核(1x1, 3x3, 5x5)并行 提取特征,然后在通道维度上拼接(Concat) ;而残差块是"加深",通过一条直达的捷径和卷积层做元素级相加(Add)。
- 联系:如果把 Inception 块里只留下一条 3x3 的卷积路和一条 1x1 的卷积路,并且最后把拼接(Concat)改成相加(Add),那么 Inception 块就退化成了一个残差块。
2. 参考 ResNet 论文实现不同的变体(如 ResNet-34)。
只需要改变
num_residuals(每个模块里的残差块数量)。
ResNet-18 的块数是:
[2, 2, 2, 2]ResNet-34 的块数是:
[3, 4, 6, 3]。你只需要在代码中把组装模块的地方改成:
pythonb2 = nn.Sequential(*resnet_block(64, 64, 3, first_block=True)) b3 = nn.Sequential(*resnet_block(64, 128, 4)) b4 = nn.Sequential(*resnet_block(128, 256, 6)) b5 = nn.Sequential(*resnet_block(256, 512, 3))3. 什么是"bottleneck(瓶颈)"架构?
在 ResNet-50、101 和 152 这样极深的网络中,如果一直用 3x3 卷积,计算量会爆炸。何恺明引入了 Bottleneck 结构:
将原本的
[3x3卷积 -> 3x3卷积]替换为[1x1卷积(降维) -> 3x3卷积 -> 1x1卷积(升维)]。这样 3x3 卷积的通道数大大减少,就像一个"沙漏"或"瓶颈",在保持网络深度的同时极大地节约了参数和计算量。
4. 作者后来的"预激活(Pre-activation)"改进是什么?
- 原始版本(ResNet-v1) :
Conv -> BN -> ReLU -> Conv -> BN -> ADD -> ReLU。注意,相加之后还有一个 ReLU,这意味着捷径传过来的梯度必须经过 ReLU 的筛选(小于0直接截断)。- 改进版本(ResNet-v2) :
BN -> ReLU -> Conv -> BN -> ReLU -> Conv -> ADD。
何恺明发现,把 BN 和 ReLU 移到卷积之前,让加法(ADD)作为当前残差块的绝对最后一步。这样捷径上没有任何非线性阻挡,梯度可以真正意义上"畅通无阻"地回传,这在训练 1000 层以上的网络时极为有效!5. 为什么即使函数类是嵌套的,我们仍然要限制增加函数的复杂性?
因为数学上的"拟合能力强"不等于"泛化能力好"。
虽然 ResNet 理论上层数越多,训练误差可以降得越低(嵌套的保证),但如果盲目加深到 10000 层:
- 过拟合(Overfitting):模型会死记硬背训练集的噪声,导致测试集表现一塌糊涂。
- 计算资源限制:显存会爆炸,推理速度会慢到无法投入实际生产。
- 数值稳定性:尽管有捷径,极深网络依然会面临数值精度溢出或下溢的工程问题。
1.6.3 ResNet的梯度计算
ResNet 为何能够解决梯度消失?
何恺明团队在 2016 年发表的第二篇 ResNet 论文(Identity Mappings in Deep Residual Networks,即所谓的 ResNet-V2)中,给出了极其极其优雅的数学证明。
普通网络为什么会"梯度消失"?
假设我们有一个传统的"平原网络"(Plain Network,如 VGG)。
设 xlx_lxl 为第 lll 层的输入,WlW_lWl 为第 lll 层的权重,F\mathcal{F}F 为该层的非线性变换(卷积+激活)。
前向传播公式:
xl+1=F(xl,Wl) x_{l+1} = \mathcal{F}(x_l, W_l) xl+1=F(xl,Wl)
假设我们要计算损失函数 L\mathcal{L}L 对浅层 lll 的梯度(即反向传播传到底部的信号)。根据链式法则 ,从深层 LLL 传到浅层 lll,梯度为:
∂L∂xl=∂L∂xL⋅∂xL∂xl \frac{\partial \mathcal{L}}{\partial x_l} = \frac{\partial \mathcal{L}}{\partial x_L} \cdot \frac{\partial x_L}{\partial x_l} ∂xl∂L=∂xL∂L⋅∂xl∂xL
展开中间的偏导数 ∂xL∂xl\frac{\partial x_L}{\partial x_l}∂xl∂xL:
∂L∂xl=∂L∂xL⋅∏i=lL−1∂xi+1∂xi=∂L∂xL⋅∏i=lL−1∂F(xi,Wi)∂xi \frac{\partial \mathcal{L}}{\partial x_l} = \frac{\partial \mathcal{L}}{\partial x_L} \cdot \prod_{i=l}^{L-1} \frac{\partial x_{i+1}}{\partial x_i} = \frac{\partial \mathcal{L}}{\partial x_L} \cdot \prod_{i=l}^{L-1} \frac{\partial \mathcal{F}(x_i, W_i)}{\partial x_i} ∂xl∂L=∂xL∂L⋅i=l∏L−1∂xi∂xi+1=∂xL∂L⋅i=l∏L−1∂xi∂F(xi,Wi)
连乘效应
看最后那个连乘符号 ∏\prod∏ 。
假设网络有一百层,哪怕每一层的导数 ∂F∂xi\frac{\partial \mathcal{F}}{\partial x_i}∂xi∂F 只有 0.9(小于1)。
那么 0.9100≈0.0000260.9^{100} \approx 0.0000260.9100≈0.000026。
传到浅层时,梯度无限趋近于 0,这就叫梯度消失。浅层网络的权重根本得不到更新,彻底废掉。
ResNet 的前向传播
现在来看 ResNet。一个纯粹的残差块(ResNet-V2 预激活版本)的数学定义是:
xl+1=xl+F(xl,Wl) x_{l+1} = x_l + \mathcal{F}(x_l, W_l) xl+1=xl+F(xl,Wl)
这里,左边的 xlx_lxl 是走捷径(Shortcut)过来的,右边的 F\mathcal{F}F 是走卷积层计算出来的残差。
何恺明做了一个极为巧妙的数学操作:展开递归(Unrolling) 。
既然 xl+1=xl+F(xl)x_{l+1} = x_l + \mathcal{F}(x_l)xl+1=xl+F(xl),那么:
xl+2=xl+1+F(xl+1,Wl+1) x_{l+2} = x_{l+1} + \mathcal{F}(x_{l+1}, W_{l+1}) xl+2=xl+1+F(xl+1,Wl+1)
代入 xl+1x_{l+1}xl+1:
xl+2=xl+F(xl,Wl)+F(xl+1,Wl+1) x_{l+2} = \left x_l + \\mathcal{F}(x_l, W_l) \\right + \mathcal{F}(x_{l+1}, W_{l+1}) xl+2=xl+F(xl,Wl)+F(xl+1,Wl+1)
如果我们一直这样代入下去,从任意浅层 lll 到任意深层 LLL,前向传播的公式可以写成:
xL=xl+∑i=lL−1F(xi,Wi) x_L = x_l + \sum_{i=l}^{L-1} \mathcal{F}(x_i, W_i) xL=xl+i=l∑L−1F(xi,Wi)
核心洞见 1:
普通网络是 xL=F(F(F(...)))x_L = \mathcal{F}(\mathcal{F}(\mathcal{F}(...)))xL=F(F(F(...))) (乘法/嵌套模型 )。
而 ResNet 变成了 xL=xl+∑Fx_L = x_l + \sum \mathcal{F}xL=xl+∑F (加法模型 )!
深层的特征 xLx_LxL 等于浅层特征 xlx_lxl 加上这中间所有残差块输出的总和。
ResNet 的反向传播
现在,我们要对上面那个加法公式求梯度。
依然是求损失函数 L\mathcal{L}L 对浅层 xlx_lxl 的梯度:
∂L∂xl=∂L∂xL⋅∂xL∂xl \frac{\partial \mathcal{L}}{\partial x_l} = \frac{\partial \mathcal{L}}{\partial x_L} \cdot \frac{\partial x_L}{\partial x_l} ∂xl∂L=∂xL∂L⋅∂xl∂xL
把刚刚推导出的 xLx_LxL 表达式代入进去求偏导:
∂xL∂xl=∂∂xl(xl+∑i=lL−1F(xi,Wi)) \frac{\partial x_L}{\partial x_l} = \frac{\partial}{\partial x_l} \left( x_l + \sum_{i=l}^{L-1} \mathcal{F}(x_i, W_i) \right) ∂xl∂xL=∂xl∂(xl+i=l∑L−1F(xi,Wi))
由于 xlx_lxl 对 xlx_lxl 求导等于 111,我们得到:
∂xL∂xl=1+∂∂xl∑i=lL−1F(xi,Wi) \frac{\partial x_L}{\partial x_l} = 1 + \frac{\partial}{\partial x_l} \sum_{i=l}^{L-1} \mathcal{F}(x_i, W_i) ∂xl∂xL=1+∂xl∂i=l∑L−1F(xi,Wi)
把这个结果代回总的梯度公式中,得到最终的 ResNet 梯度公式:
∂L∂xl=∂L∂xL⋅(1+∂∂xl∑i=lL−1F(xi,Wi)) \frac{\partial \mathcal{L}}{\partial x_l} = \frac{\partial \mathcal{L}}{\partial x_L} \cdot \left( 1 + \frac{\partial}{\partial x_l} \sum_{i=l}^{L-1} \mathcal{F}(x_i, W_i) \right) ∂xl∂L=∂xL∂L⋅(1+∂xl∂i=l∑L−1F(xi,Wi))
把它拆开写:
∂L∂xl=∂L∂xL⋅1⏟无损直达梯度+∂L∂xL⋅∂∂xl∑F⏟穿过各层的衰减梯度 \frac{\partial \mathcal{L}}{\partial x_l} = \underbrace{ \frac{\partial \mathcal{L}}{\partial x_L} \cdot 1 }{\text{无损直达梯度}} + \underbrace{ \frac{\partial \mathcal{L}}{\partial x_L} \cdot \frac{\partial}{\partial x_l} \sum \mathcal{F} }{\text{穿过各层的衰减梯度}} ∂xl∂L=无损直达梯度 ∂xL∂L⋅1+穿过各层的衰减梯度 ∂xL∂L⋅∂xl∂∑F
看着最后这个公式,我们来分析为什么它完美解决了梯度消失:
1. 救命的" + 1 "
在普通网络中,梯度是 ∏\prod∏ (连乘)。而在 ResNet 中,括号里多出了一个加号:1 + ...。
这表示,无论右边的这坨 ∑F\sum \mathcal{F}∑F 衰减得有多么厉害(哪怕里面的权重烂到极点,梯度变成了 0.0000001),
整个括号里的值也至少是 1 + 0.0000001。
梯度永远不会因为连乘而变成 0!
2. "无损直达"的shortcut
把公式拆开看,梯度由两部分相加组成:
第一部分是 ∂L∂xL⋅1\frac{\partial \mathcal{L}}{\partial x_L} \cdot 1∂xL∂L⋅1。
这意味着,不管两层之间隔了多远(比如 LLL 是第1000层,lll 是第1层),深层的梯度信号都可以原封不动、不经过任何缩放或衰减(乘 1),直接通过捷径传回第1层。
3. 极低概率的完全抵消
有人可能会问:如果 ∂∂xl∑F\frac{\partial}{\partial x_l} \sum \mathcal{F}∂xl∂∑F 刚好等于 -1 呢?那 1 - 1 = 0,梯度不还是消失了吗?
何恺明在论文中指出,在一个包含成千上万样本的小批量(Mini-batch)训练中,对于所有的样本,这个偏导数恒等于 -1 的概率在统计学上几乎为零。
从数学推导上我们可以清晰地看到:
- 普通网络 的前向和反向传播都是连乘机制,必定导致指数级的梯度消失或爆炸。
- ResNet 巧妙地利用了捷径连接,把前向传播变成了累加 ,从而使得反向传播的偏导数中多出了一个常数 111。
- 这个 111 就像是一条无视任何阻碍的信息高速公路,保证了无论网络有多深,深层的误差都能不受阻碍地传到底层神经元手中。