适合岗位:AI 大模型开发 / NLP 算法工程师
关键词:RAG、检索增强生成、大模型幻觉、Embedding、混合检索、Chunk 优化
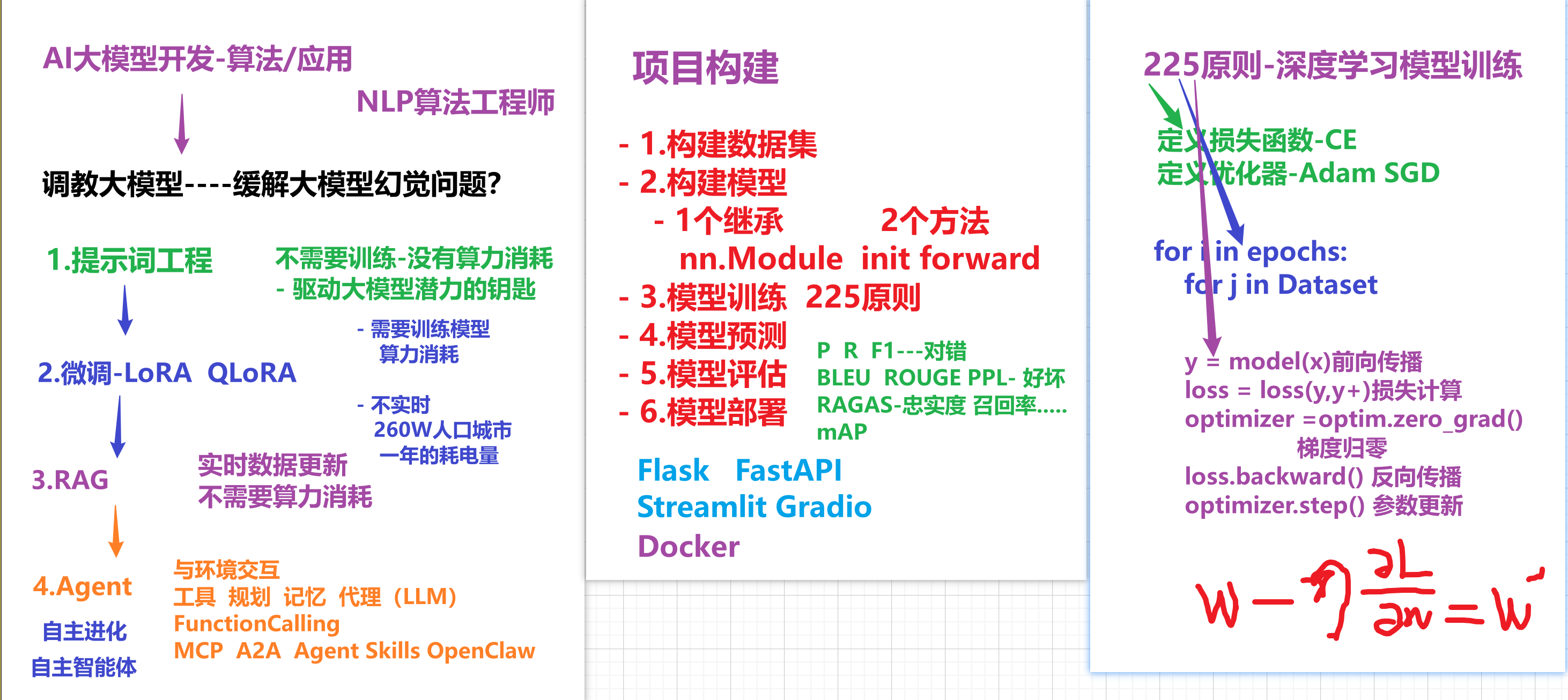
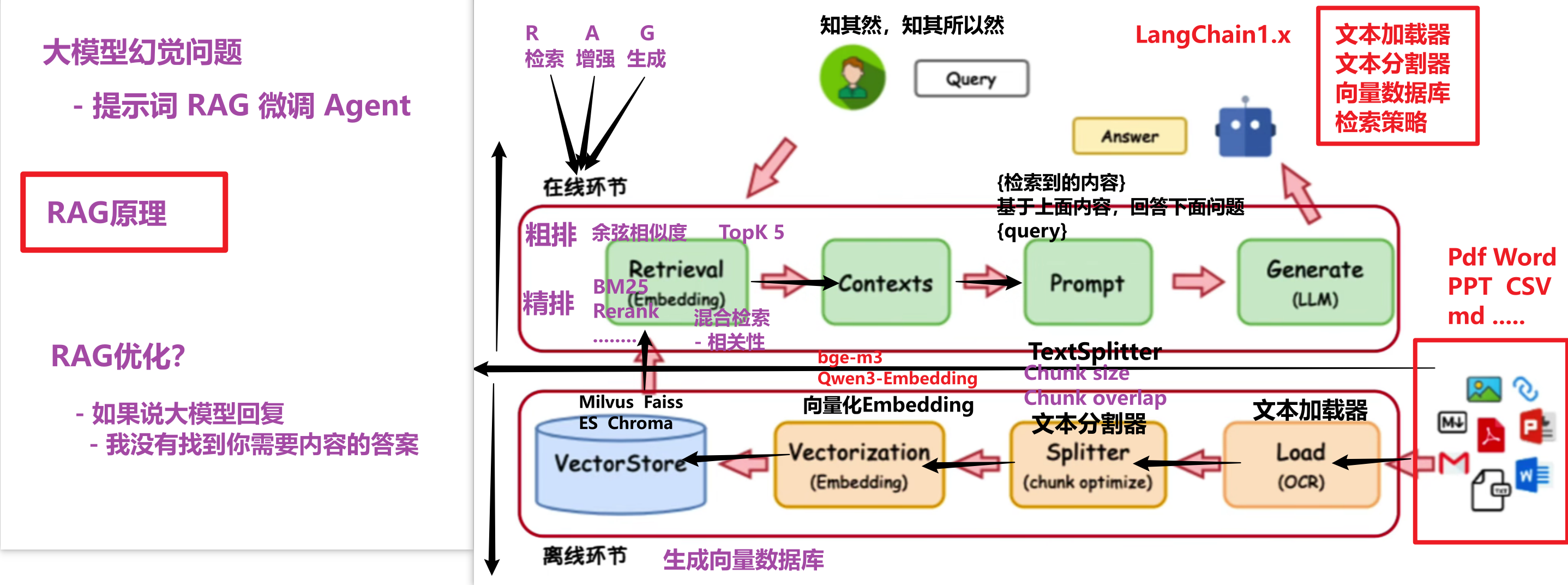
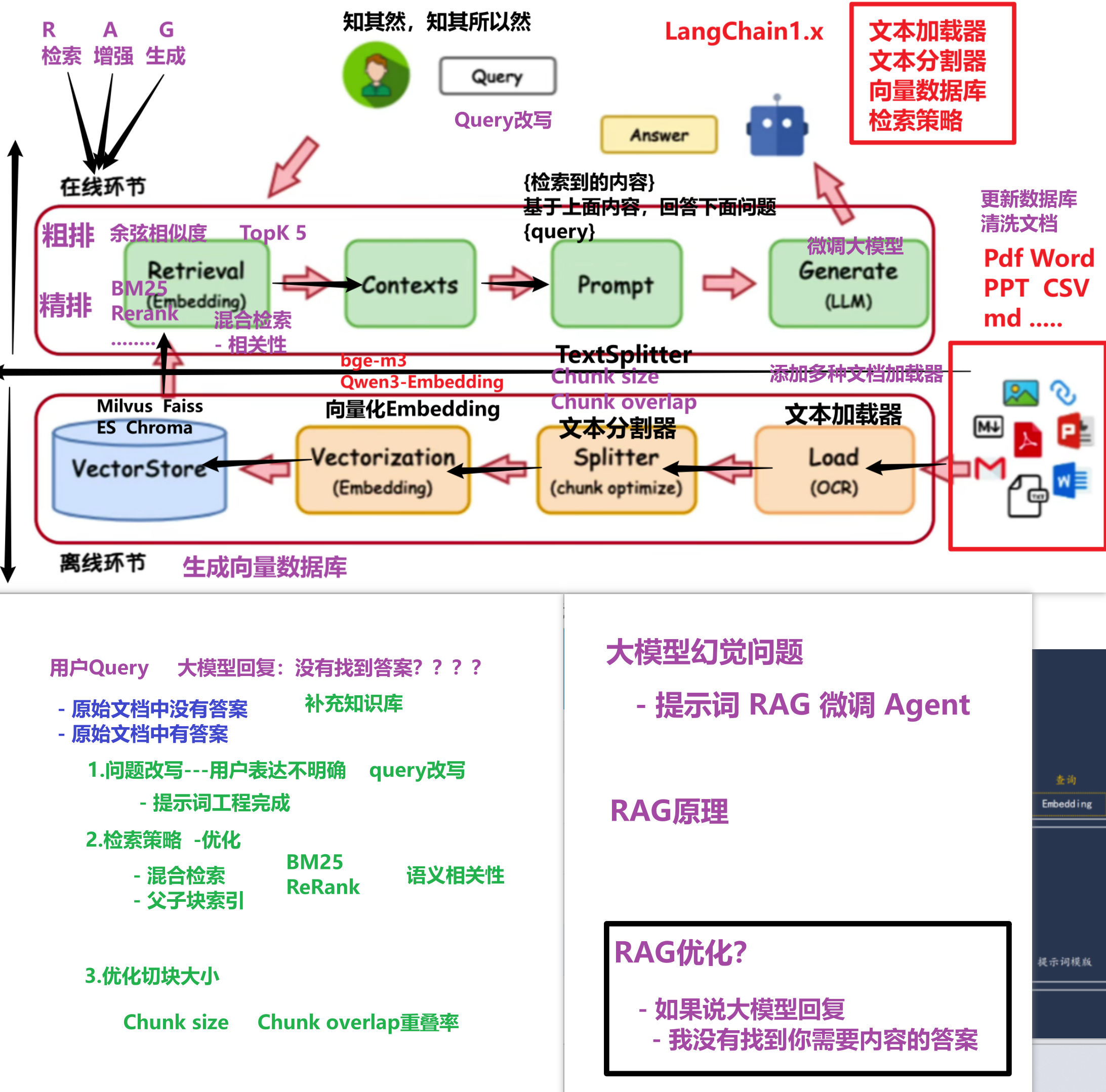
一、RAG 是什么?(必问)
RAG = Retrieval + Augmented + Generation
| 阶段 | 做什么 |
|---|---|
| 检索 Retrieval | 从知识库中查找与用户问题相关的文档片段 |
| 增强 Augmented | 把检索到的内容拼接到 Prompt 中 |
| 生成 Generation | 大模型基于"问题 + 检索内容"生成答案 |
一句话回答
RAG 是一种让大模型不依赖内部知识 、而是实时从外部知识库检索信息来回答问题的方法。
为什么需要 RAG?
| 方案 | 是否需要训练 | 算力消耗 | 数据实时性 |
|---|---|---|---|
| 提示词工程 | ❌ | 低 | ❌ 不更新 |
| 微调 (LoRA/QLoRA) | ✅ | 高 | ❌ 不实时 |
| RAG | ❌ | 低 | ✅ 实时更新 |
| Agent | ❌ | 中 | ✅ 实时 |
面试回答要点:
-
RAG 解决了大模型知识过时 和幻觉问题
-
不需要重新训练,成本低
-
知识库可随时更新
二、RAG 核心流程(在线 + 离线)
离线环节(建库)
原始文档 (PDF/Word/PPT/CSV/md)
↓
文本加载器 Load (OCR)
↓
文本分割器 Splitter
├── Chunk size(块大小)
└── Chunk overlap(重叠率)
↓
向量化 Embedding(Qwen3-Embedding / bge-m3)
↓
向量数据库 VectorStore(Milvus / Faiss / ES / Chroma)
在线环节(检索 + 生成)
用户 Query
↓
Query 改写(优化用户表达不清晰的问题)
↓
检索 Retrieval
├── 粗排:余弦相似度 / BM25,取 TopK(如 TopK=5)
└── 精排:ReRank(混合检索优化相关性)
↓
Contexts(检索到的上下文)
↓
Prompt(拼接:问题 + 上下文)
↓
Generate (LLM)
↓
Answer
三、RAG 优化方案(面试高频)
当大模型回复 "我没有找到答案" 时,按以下顺序排查优化:
1.先思考query在rag知识库中有没有
1.1没有的话那就对rag系统进行知识补充
1.2有的话那就是检索出现的问题, 针对性进行:query改写,检索策略优化
1. Query 改写
问题:用户表达不明确,关键词不匹配
解法:
-
用大模型对原始 Query 进行改写/扩写
-
生成多个相似问题去检索
2. 检索策略优化
| 优化点 | 说明 |
|---|---|
| 混合检索 | 向量检索(语义)+ 关键词检索(BM25),取两者交集/加权 |
| ReRank | 粗排后,用更精细的模型(如 bge-reranker)重新排序 |
| 父子块索引 | 父块存粗粒度信息,子块存细粒度,检索时粗召回 + 细精排 |
3. Chunk 优化
| 参数 | 说明 | 经验值 |
|---|---|---|
| Chunk size | 每个文本块的大小(按 token 或字符) | 256-512 tokens |
| Chunk overlap | 块之间的重叠长度,防止语义断裂 | 10-20% |
建议:子块看文档中的段落字数大小,父块看一个父级标题下有几个段落存在
面试回答:
-
size 太小:上下文不完整,信息缺失
-
size 太大:引入噪声,检索精度下降
-
overlap 太小:关键信息被切分到两个块中
4. 提示词工程
在 Prompt 中明确:
-
如果检索到的内容不足以回答问题,回复"根据现有资料无法回答",对大模型幻觉进行压制
-
强制模型只基于检索内容回答,不编造
5. 补充知识库
如果原始文档中确实没有答案:
-
增量更新向量数据库
-
清洗文档质量
四、大模型幻觉问题与 RAG 的关系
幻觉来源
-
大模型为了"强行回答"而编造信息
-
训练数据中没有相关内容
缓解幻觉的四种方案
| 方案 | 说明 | 适用场景 |
|---|---|---|
| 提示词工程 | 强制模型"不知道就说不知道" | 快速兜底 |
| RAG | 从知识库检索事实依据 | 知识密集型任务 |
| 微调 | 用特定领域数据训练模型 | 领域适配 |
| Agent | 让模型调用外部工具验证 | 复杂推理 |
面试加分回答
RAG 是目前缓解幻觉最实用 的方案,因为它不需要重新训练,且知识库可实时更新。但如果检索到的内容是错误的,RAG 反而会放大错误,所以检索质量是关键。
五、RAG vs 微调 vs Agent(对比表)
| 维度 | RAG | 微调 | Agent |
|---|---|---|---|
| 是否需要训练 | ❌ | ✅ | ❌ |
| 算力消耗 | 低 | 高 | 中 |
| 数据实时性 | ✅ 实时 | ❌ 静态 | ✅ 实时 |
| 可解释性 | ✅ 可溯源 | ❌ 黑盒 | ✅ 可追踪 |
| 适用场景 | 知识问答、客服 | 风格迁移、领域适配 | 工具调用、多步推理 |
六、常见面试题 & 参考答案
Q1:RAG 的检索阶段有哪些优化手段?
参考答案:
-
Query 改写:用户问题→多个检索问题
-
混合检索:向量 + BM25
-
ReRank:粗排后精排
-
父子块索引
-
调整 Chunk size 和 overlap
Q2:Chunk size 怎么选?
参考答案:
-
256-512 tokens 是比较常见的区间
-
太小会导致信息不完整,太大引入噪声
-
需要根据文档类型和任务实验确定
Q3:RAG 和微调怎么选?
参考答案:
-
需要实时更新的知识(如新闻、FAQ)→ RAG
-
需要改变模型风格/行为(如客服语气、代码生成)→ 微调
-
两者可以结合:微调让模型学会"如何使用检索到的信息",RAG 提供实时知识
Q4:RAG 中向量数据库有哪些选型?
参考答案:
-
开源:Milvus、Faiss(Facebook)、Chroma、ES(Elasticsearch)
-
选型考虑:数据规模、查询延迟、是否支持混合检索、部署成本
Q5:Embedding 模型有哪些?
参考答案:
-
bge-m3(BAAI)
-
Qwen3-Embedding(阿里)
-
OpenAI text-embedding-3
-
Cohere Embed
七、一张图总结 RAG 优化路径
用户说"没找到答案"
↓
- 原始文档中真的有答案吗?
├── 没有 → 补充知识库
└── 有 → 往下排查
↓
- 用户表达清晰吗?
├── 不清晰 → Query 改写
└── 清晰 → 往下排查
↓
- 检索策略是否最优?
├── 混合检索?
├── ReRank?
└── 父子块索引?
↓
- Chunk 参数是否合适?
├── size 太大/太小?
└── overlap 足够?
↓
- Prompt 是否正确约束模型?
└── "只基于检索内容回答"
八、面试速记卡
| 概念 | 一句话解释 |
|---|---|
| RAG | 检索 + 增强 + 生成 |
| Chunk size | 文本块大小,影响检索精度 |
| Chunk overlap | 块重叠,防止语义断裂 |
| 混合检索 | 向量 + 关键词 |
| ReRank | 粗排后精排 |
| Query 改写 | 优化用户输入 |
| 幻觉 | 模型编造答案 |
| Embedding | 文本→向量 |