****论文题目:****RETHINKING ATTENTION WITH PERFORMERS(重新思考对表演者的关注)
会议:ICLR2021
****摘要:****我们介绍了PERFORMERS,变压器架构,它可以估计正则(softmax)全秩注意变压器具有可证明的准确性,但只使用线性(而不是二次)空间和时间复杂度,而不依赖于任何先验,如稀疏性或低秩。为了近似softmax注意力核,PERFORMERS使用了一种新颖的通过正正交随机特征的快速注意力方法(FAVOR+),这可能是可扩展核方法的独立兴趣。除了softmax之外,还可以使用FAVOR+有效地建模可内核化的注意机制。这种表示能力对于首次在大规模任务中准确地将softmax与其他内核进行比较至关重要,超出了常规transformer的范围,并研究最佳注意力内核。执行者是与常规变压器完全兼容的线性架构,并具有强大的理论保证:注意矩阵的无偏或近乎无偏估计,均匀收敛和低估计方差。我们在从像素预测到文本模型再到蛋白质序列建模的丰富任务集上测试了performer。我们展示了与其他有效的稀疏和密集注意方法的竞争结果,展示了PERFORMERS利用的新型注意学习范式的有效性。
Performer 论文深度解读
2.1引言:为什么需要 Performer?
Transformer 自 2017 年被提出以来,已经在 NLP、计算机视觉、音乐生成、生物信息学等多个领域成为 SOTA 架构。然而,它的核心------softmax 注意力机制------有一个致命弱点:计算和内存开销随序列长度二次增长。
对于一个长度为 L 的序列,注意力矩阵需要O(L^2)的存储空间和O(L^2 d)的计算时间。当L达到数千甚至上万时(比如蛋白质序列可长达数万个氨基酸,高分辨率图像的像素序列可达上万),标准 Transformer 变得完全不可行。
社区已经提出了众多解决方案,但它们各有局限:
- Reformer(Kitaev et al., 2020)使用局部敏感哈希(LSH)实现稀疏注意力,但仅支持单向注意力,且要求查询和键集合相同。
- Longformer(Beltagy et al., 2020)使用滑动窗口注意力,依赖特定的稀疏模式。
- Linformer(Wang et al., 2020)通过低秩投影近似注意力,但仅支持双向注意力,且提供有偏估计。
- Linear Transformer(Katharopoulos et al., 2020)使用核函数替代 softmax,但在深层训练中表现出严重的数值不稳定性。
这些方法的共同问题是:它们都没有提供对标准 softmax 注意力的无偏、线性复杂度近似,且缺乏严格的理论保证。
Performer 正是为了填补这个空白而诞生的。
2.2 FAVOR+ 机制详解
FAVOR+ 的名字代表 Fast Attention Via positive Orthogonal Random features,由三个部分组成:FA(快速注意力)、OR(正交随机特征)、+(正随机特征)。
2.2.1 从核方法的角度理解注意力
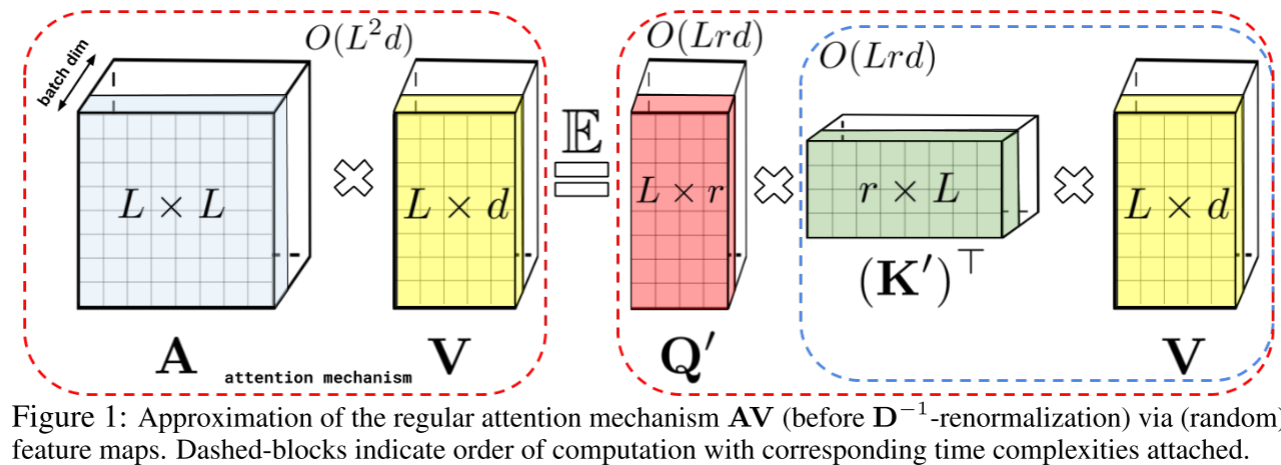
标准 softmax 注意力矩阵的 (i,j) 元素可以写成核函数的形式:
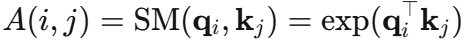
如果我们能找到一个随机特征映射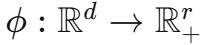 ,使得:
,使得:
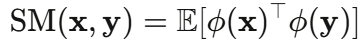
那么注意力矩阵就可以用 来近似,而计算可以巧妙地重新安排为:
来近似,而计算可以巧妙地重新安排为:
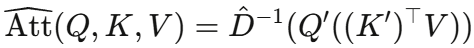
关键在于括号内的计算顺序:先计算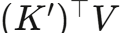 ,得到一个r*d的矩阵(不依赖于L),再与Q'相乘。这样总复杂度为O(Lrd),当
,得到一个r*d的矩阵(不依赖于L),再与Q'相乘。这样总复杂度为O(Lrd),当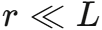 时,实现了线性复杂度。
时,实现了线性复杂度。
2.2.2 为什么三角函数特征行不通?
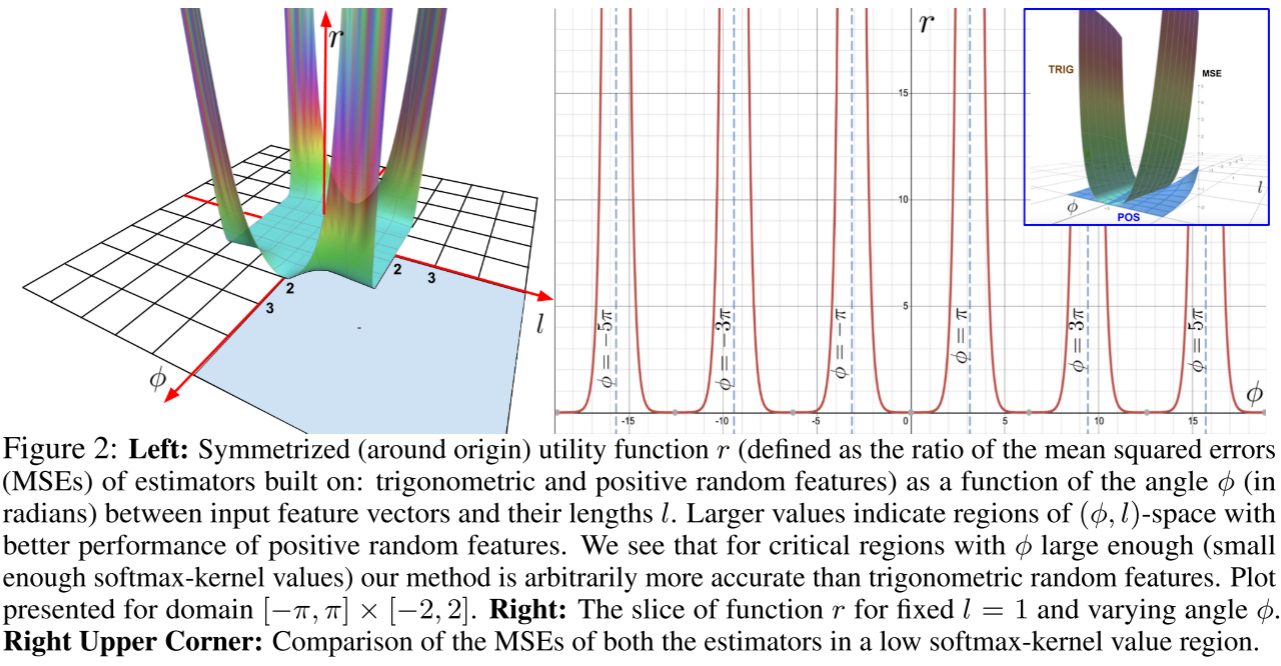
基于 Rahimi & Recht (2007) 的经典结果,softmax 核可以用三角函数随机特征来近似,映射中使用 sin 和 cos 函数。但这种方法有一个致命缺陷:sin 和 cos 产生的特征值可以是负数。
在注意力机制中,每个 token 的输出是 value 向量的凸组合,系数就是归一化后的注意力权重。当特征映射产生负值时:
- 核值估计可能为负,导致注意力权重为负;
- 归一化矩阵 D^{-1} 的对角元素可能为负;
- 训练完全崩溃或产生 NaN 值。
论文通过 Lemma 2 给出了精确的理论解释:三角函数特征的 MSE 在核值趋近 0 时趋向无穷。而在典型的注意力矩阵中,大量条目对应的是低相关 token 对,核值本就接近 0,因此误差会被大幅放大。
2.2.3 正随机特征:核心突破
论文提出的核心创新是使用指数函数替代三角函数来构造特征映射:
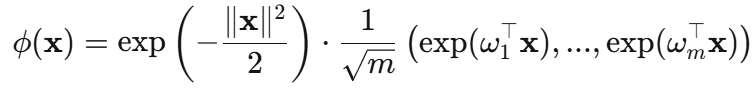
其中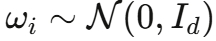 。由于 exp 函数始终为正,特征映射的所有分量都是正的,从根本上避免了负值问题。
。由于 exp 函数始终为正,特征映射的所有分量都是正的,从根本上避免了负值问题。
更进一步,论文还提出了双曲正弦版本(hyperbolic variant),同时使用 exp(u) 和 exp(-u),可以进一步降低方差,且效果严格优于使用两倍随机特征数的单指数版本。
2.2.4 正交特征:锦上添花
在正随机特征的基础上,通过 Gram-Schmidt 正交化使不同的随机向量  相互正交,可以在保持无偏性的同时进一步降低方差。论文的 Theorem 2 证明这种改进在任意维度 d 下都成立(而非仅在渐近情况下),且正交特征与正特征的组合尤为有效。
相互正交,可以在保持无偏性的同时进一步降低方差。论文的 Theorem 2 证明这种改进在任意维度 d 下都成立(而非仅在渐近情况下),且正交特征与正特征的组合尤为有效。
Theorem 4 进一步证明了注意力近似的一致收敛性 :只需 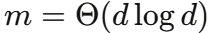 个随机投影,就能以任意精度近似注意力矩阵,且所需投影数不依赖于序列长度 L。
个随机投影,就能以任意精度近似注意力矩阵,且所需投影数不依赖于序列长度 L。
2.3 实验结果深度分析
2.3.1 计算效率
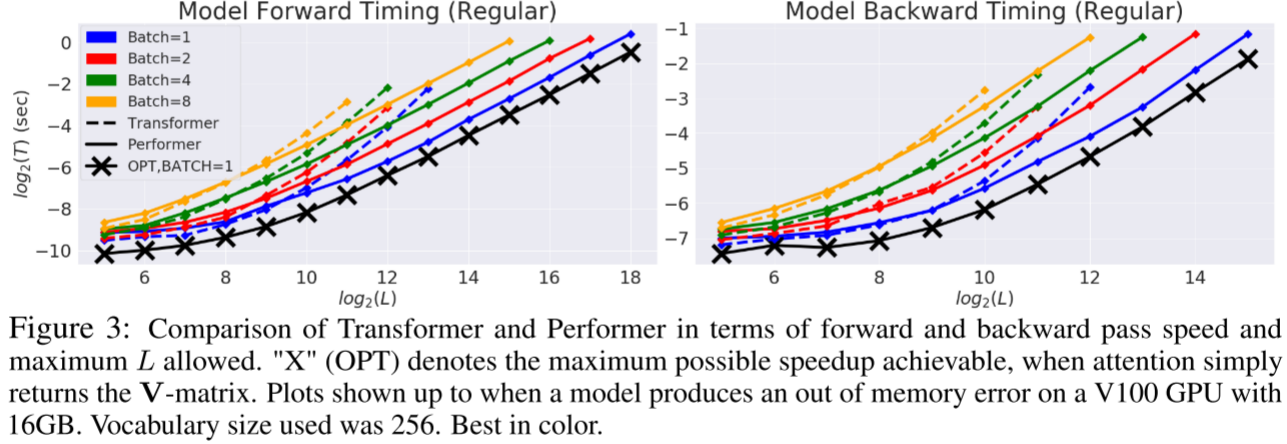
在标准 Transformer 配置 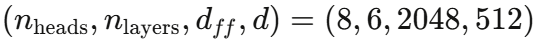 下,论文比较了 Transformer 和 Performer 的前向和反向传播速度。
下,论文比较了 Transformer 和 Performer 的前向和反向传播速度。


从 Figure 3 可以看到,Performer 的时间随 L 接近线性增长,且达到了接近最优的加速比------"X"(OPT) 线表示将注意力直接替换为恒等函数(直接返回 V 矩阵)的理论最优速度。在 V100 GPU (16GB) 上,当 Transformer 因内存不足而无法运行时,Performer 仍然能够正常工作。
2.3.2 注意力近似精度
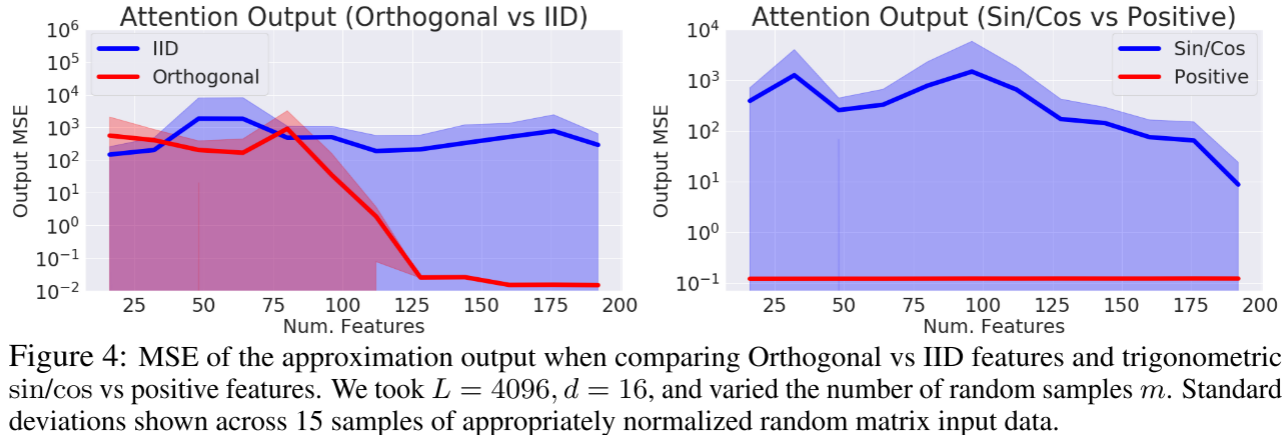
在 L=4096, d=16 的受控实验中(Figure 4),两个核心发现被验证:
- 正交 vs IID 特征:正交特征在所有随机特征数 m 下都产生更低的 MSE,且随着 m 增加优势更加明显。
- 正特征 vs 三角函数特征:正特征的 MSE 持续低于三角函数特征,差距可达数个数量级。
这些结果在 15 组随机数据样本上取得,标准差也较小,验证了 PORF(正正交随机特征)机制的可靠性。
2.3.3 Softmax 近似在 Transformer 模型中的表现
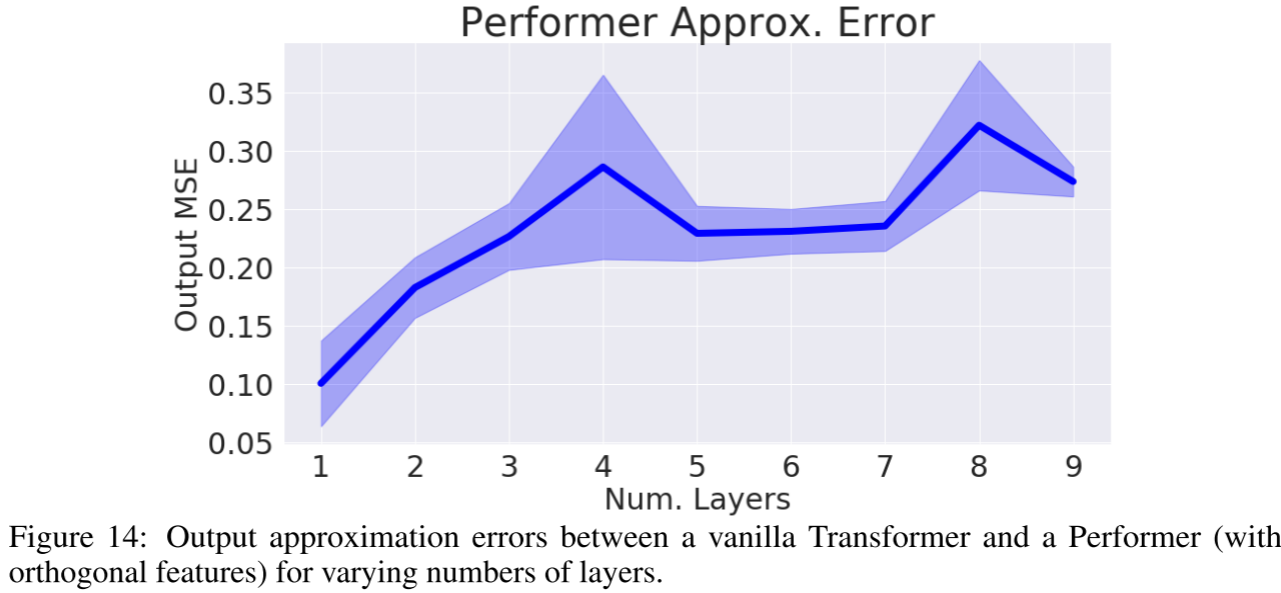
虽然单步注意力近似很紧,但小误差会通过多层 Transformer(MLP、多头注意力等)级联放大。从 Figure 14可以看到,近似误差随层数增加而显著增大。
这意味着:
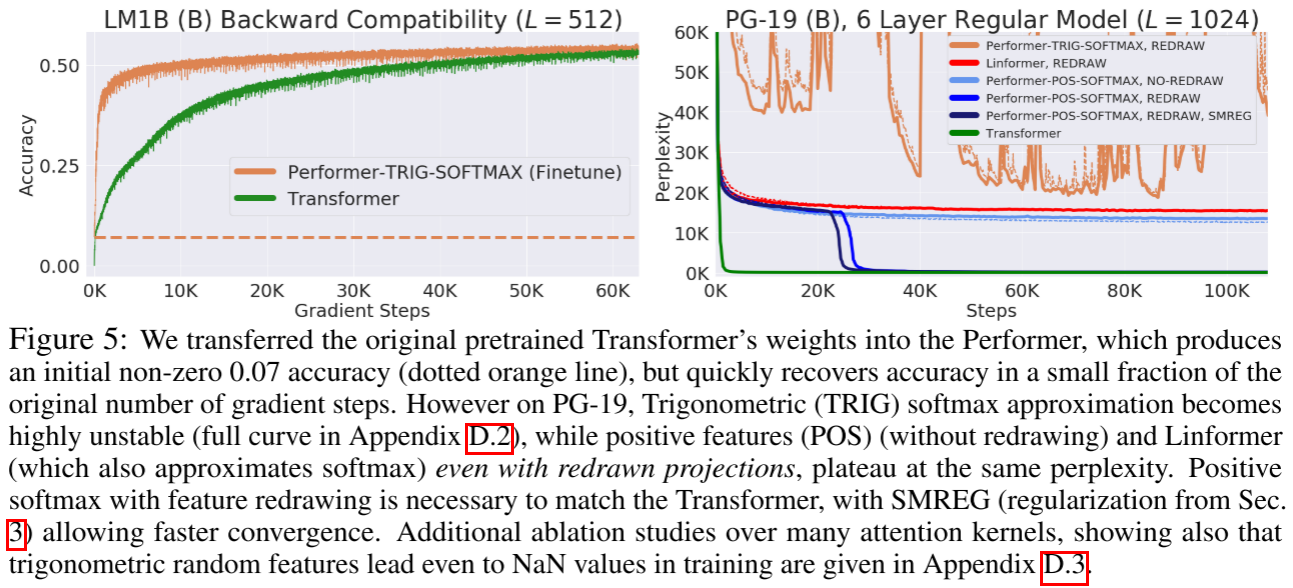
- 向后兼容需要微调:将预训练 Transformer 权重直接加载到 Performer 后,初始准确率约为 0.07,但通过少量梯度步骤即可快速恢复(Figure 5 左)。
- 正特征和特征重绘是必要的:在更大规模的 PG-19 数据集上(Figure 5 右),三角函数特征导致训练高度不稳定(甚至产生 NaN),而正特征配合定期重绘随机样本才能匹配标准 Transformer 的困惑度。正则化 softmax 核(SMREG)还能加速收敛。
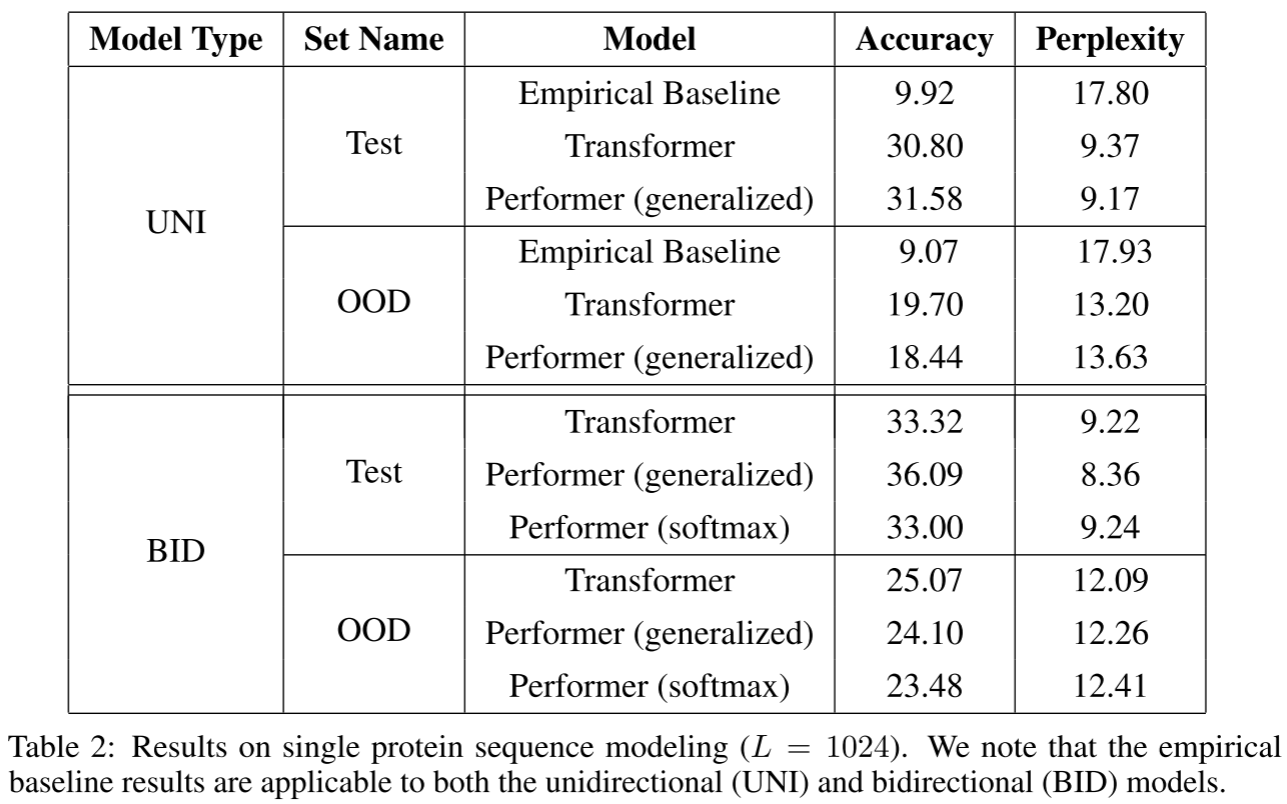
2.3.4 蛋白质序列建模:36 层深度模型
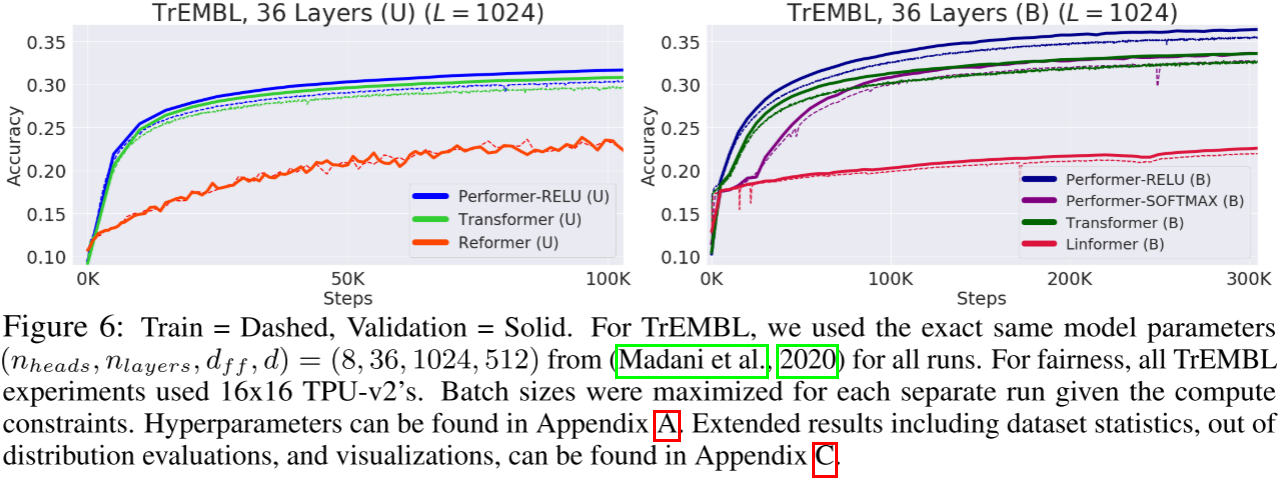
这是论文最令人印象深刻的实验之一。在 TrEMBL 蛋白质数据集上训练 36 层模型(与 ProGen 相同的配置),使用 16×16 TPU-v2:
单向模型(L=1024):
- Performer-ReLU:最高验证准确率
- Transformer:次之
- Reformer:显著下降
双向模型(L=1024):
- Performer-ReLU:最高验证准确率(约 36%)
- Performer-SOFTMAX:与 Transformer 一致(约 33%)
- Transformer:约 33%
- Linformer:显著下降
这说明两件事:(1)FAVOR+ 的 softmax 近似确实非常紧密;(2)广义注意力核(如 ReLU)在某些任务上可能优于 softmax。
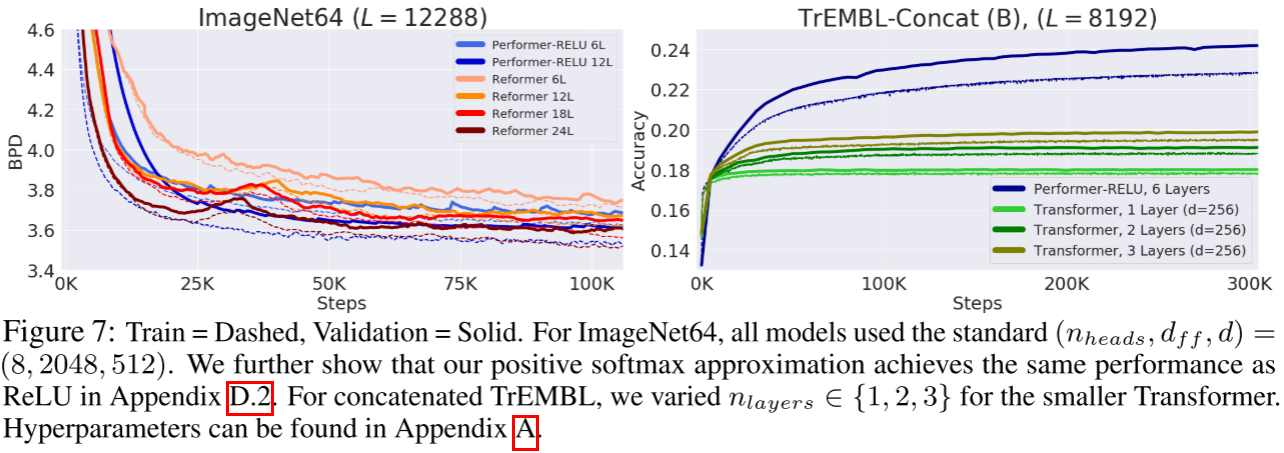
2.3.5 长序列任务:突破 Transformer 的极限
ImageNet64 像素预测(L=12288):
这个序列长度对标准 Transformer 完全不可行。在 (n_{\\text{heads}}, d_{ff}, d) = (8, 2048, 512) 的配置下:
| 模型 | 层数 | BPD |
|---|---|---|
| Performer-ReLU | 6 | ≈ 3.67 |
| Performer-ReLU | 12 | ≈ 3.55 |
| Reformer | 6 | ≈ 4.0 |
| Reformer | 12 | ≈ 3.67 |
| Reformer | 24 | ≈ 3.55 |
6 层 Performer 匹配 12 层 Reformer,12 层 Performer 匹配 24 层 Reformer,参数效率提升显著。
拼接蛋白质序列(L=8192):
标准 Transformer 即使 batch size=1 也内存溢出,被迫使用缩小版,最高准确率约 19%。Performer 使用标准架构、batch size=8 正常训练,准确率达约 24%。
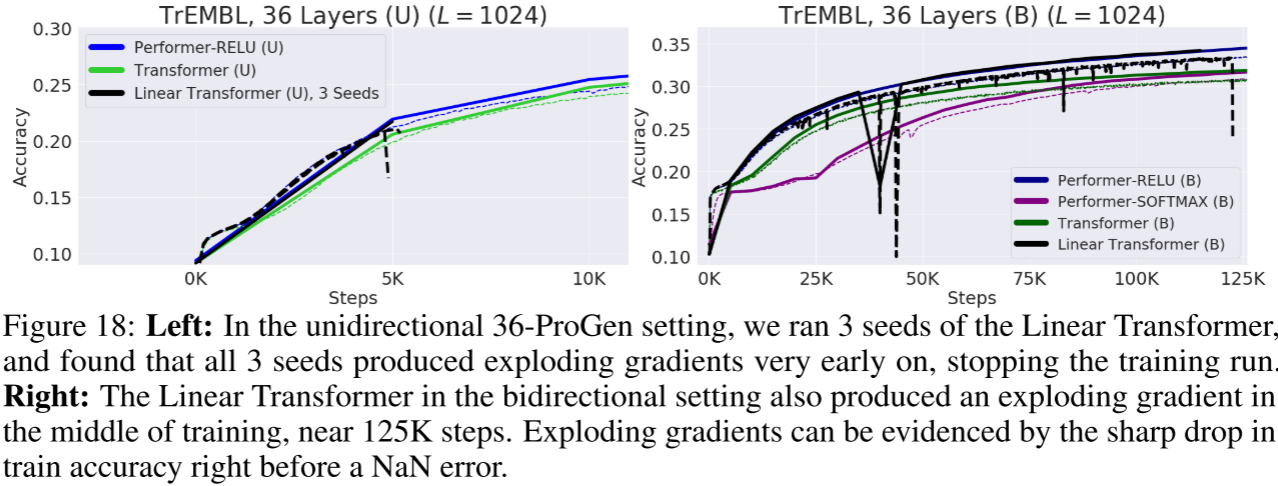
2.3.6 与 Linear Transformer 的对比
论文在附录中详细比较了 Performer 与 Linear Transformer(Katharopoulos et al., 2020)。在 36 层 TrEMBL 设置下:
- 单向:Linear Transformer 的 3 个种子都在训练早期就出现梯度爆炸,训练终止。
- 双向:Linear Transformer 在约 125K 步时也出现梯度爆炸。
相比之下,Performer 在相同设置下稳定训练,这得益于 FAVOR+ 机制中正特征和正交特征的数值稳定性。
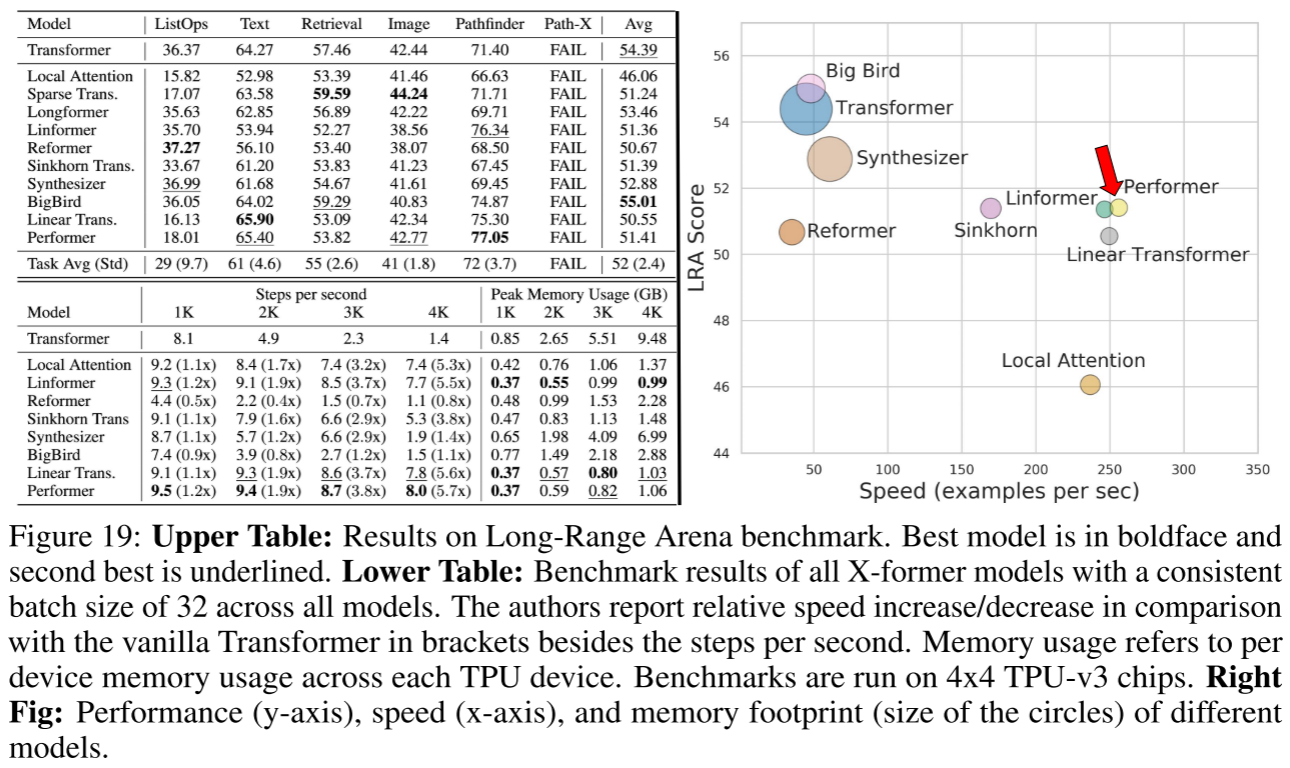
2.3.7 Long Range Arena 基准
在 LRA 基准上,Performer 与多种高效 Transformer 方法(Local Attention, Sparse Attention, Longformer, Sinkhorn, Synthesizer, BigBird, Linear Transformer)进行了全面比较。
在所有速度超过 100 examples/sec 的可扩展方法中,Performer 获得了最高的 LRA 综合得分(51.41),同时保持了最快的速度(8.0 步/秒 @ 4K 序列长度)和极低的内存占用(1.06 GB @ 4K)。
从速度-性能-内存三维综合来看(Figure 19 右图),Performer 位于帕累托最优前沿。
2.4 理论贡献总结
论文的理论贡献可以概括为四大定理:
| 定理 | 内容 | 意义 |
|---|---|---|
| Lemma 1 | softmax 核的正随机特征无偏分解 | 奠定 FAVOR+ 的理论基础 |
| Lemma 2 | 正特征 vs 三角函数特征的 MSE 精确公式 | 证明正特征在关键区域严格更优 |
| Theorem 1 | 正则化 softmax 核与标准 softmax 核的逼近关系 | 为 SMREG 提供理论保证 |
| Theorem 2 | 正交特征在任意 d 下降低 MSE | 证明 ORF+PRF 组合的普适优越性 |
| Theorem 3 | 正交特征的指数级尾部概率上界 | 提供严格的集中不等式 |
| Theorem 4 | 注意力近似的一致收敛 | 证明 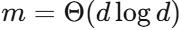 即可保证精度 即可保证精度 |
2.5 更广泛的影响
论文在 Broader Impact 部分讨论了 Performer 的多方面影响:
- 生物信息学:Performer 能够处理远超标准 Transformer 的蛋白质序列长度,为蛋白质相互作用预测、纳米颗粒疫苗设计等提供新工具。
- 环境:线性复杂度直接降低了计算资源消耗,减少了碳排放。
- 向后兼容:Performer 可以直接加载预训练 Transformer 权重,通过微调恢复性能,即使不需要微调,FAVOR+ 也可用于加速推理。
- 注意力机制的更广泛应用:FAVOR+ 可以应用于 Transformer 之外的注意力场景,如层次注意力网络、图注意力网络、图像处理和强化学习。
2.6 总结
Performer 论文的核心贡献在于首次提出了一种理论上严格、实践中可行的方法,以线性复杂度无偏近似标准 softmax 注意力。FAVOR+ 机制通过正随机特征解决了数值稳定性问题,通过正交随机特征进一步降低方差,通过广义核框架开辟了注意力核选择的新研究方向。
从实验角度看,Performer 在蛋白质建模、像素预测、语言模型等多个任务上展现了与标准 Transformer 竞争甚至更优的性能,同时在长序列场景下打破了标准 Transformer 的内存限制。在速度、内存和性能的综合考量下,Performer 代表了高效 Transformer 设计的一个重要里程碑。