一、多级缓存在项目中的实战落地
1.1 多级缓存核心原理
高并发系统的核心瓶颈永远不在应用CPU,而在网络IO、中间件压力、数据库磁盘IO 。多级缓存的核心思想是由近及远、层层拦截流量,优先让请求在离用户最近的层级被终止,避免穿透到下层昂贵的存储组件。
互联网标准多级缓存链路:
用户请求 → CDN/Nginx缓存 → JVM本地缓存 → Redis分布式缓存 → MySQL数据库
-
一级缓存(CDN/Nginx):拦截静态资源、静态页面、高频固定接口,抵御超大流量
-
二级缓存(JVM本地缓存):进程内内存,无网络IO,微秒级响应,拦截热点流量
-
三级缓存(Redis分布式缓存):集群共享缓存,保障多实例数据统一,承接全量普通缓存流量
-
底层数据库:兜底持久化存储,仅承接更新、新增、极低概率穿透流量
1.2 本地缓存优缺点 + 生产级改进方案
目前企业统一选型:Caffeine本地缓存(优于Guava Cache、LruCache)
1.2.1 本地缓存优点
-
无网络IO、无序列化开销、性能极致
-
不占用Redis连接数、带宽、CPU资源
-
Redis故障可兜底,避免服务雪崩
-
单机吞吐量极高,轻松支撑十万级QPS
-
减少远程缓存的读压力
-
分布式系统中,天然分布式缓存
1.2.2 本地缓存缺点
-
数据孤岛:多实例集群环境下,各实例缓存数据不一致
-
占用堆内存:缓存过多引发FullGC、OOM风险
-
容量有限,无法存储海量缓存数据
-
批量过期易产生瞬时流量击穿Redis
-
重启机器会导致数据丢失,进而增大Redis的读压力
1.2.3 生产改进优化方案
-
过期时间随机打散:统一Key增加±1~3分钟随机偏移,杜绝集中过期
-
Redis Pub/Sub消息同步失效:数据更新后广播清空所有实例本地缓存
-
冷热数据隔离:仅热点Key下沉本地,冷数据只存Redis
-
容量限流+淘汰策略:Caffeine基于W-TinyLFU精准淘汰冷数据,防止内存溢出
-
短过期自愈:本地缓存过期时间远小于Redis,依靠时间兜底修复不一致
1.3 多级缓存整体优点
-
极致提升接口性能:本地缓存无网络开销,RT从10ms级降至1ms级
-
大幅削峰降压:90%以上热点流量可被前置缓存拦截,Redis/DB压力骤降
-
高可用兜底:Redis集群抖动/宕机时,本地缓存可临时兜底,服务不雪崩
-
提升系统吞吐:突破Redis单机QPS上限,集群整体承载能力成倍提升
1.4 多级缓存整体缺点
-
数据一致性降低:层级越多,脏数据、不一致窗口越大
-
架构复杂度上升:需要维护多级缓存的更新、失效、同步逻辑
-
服务内存开销增加:每个实例独立缓存,集群部署内存叠加
-
运维难度提升:问题排查需要区分本地缓存、分布式缓存问题
1.5 多级缓存通用应用场景
适合场景(读多写少、允许短暂不一致)
-
电商商品详情、店铺信息、首页Banner、活动配置
-
系统字典、基础配置、地区数据、常量参数
-
资讯、文章、热搜、公告类静态内容
-
大促、秒杀等高QPS高并发场景
不适合场景 :金融交易、订单余额、库存扣减等强一致性、高频更新业务
二、热点Key探测原理与JDHotkey框架实战
2.1 热点Key产生原理
热点Key指:短时间内被海量并发访问的同一个Redis Key 。Redis Cluster采用槽位分片机制,热点Key只会落在单个节点,导致单节点CPU、带宽、连接数被打满,其他节点空闲,出现集群流量倾斜、局部雪崩。
本质成因:流量高度集中 + 数据分片无法拆分单Key流量。
2.2 热点探测详细使用场景(重点新增强化)
热点Key探测不是"可选优化",是大促、流量项目的必备防护体系,覆盖所有流量集中场景,分为四大类业务场景:
2.2.1 电商大促与秒杀场景(最高频)
-
秒杀单品、爆款活动商品、限时优惠券、拼团活动
-
大促首页、会场模板、活动弹窗配置
-
特点:瞬时流量爆炸,百万QPS集中单个Key,最容易引发Redis宕机
2.2.2 全局公共配置类场景
-
系统全局开关、功能灰度配置、运维控制开关
-
首页导航、Banner广告、推荐位数据
-
公共字典、地区码、常量配置
-
特点:常驻热点,全天高QPS,长期压榨Redis单节点
2.2.3 内容流量类场景
-
热搜榜单、热门文章、爆款短视频、实时资讯
-
直播场次信息、直播间在线配置
-
特点:突发热点不可预测,热点随舆情、活动动态切换,人工无法提前预判
2.2.4 异常流量防护场景(核心价值)
-
爬虫批量刷接口、恶意请求、流量攻击
-
业务Bug导致死循环频繁读取同一个Key
-
瞬时流量脉冲、流量突增导致临时热点
-
特点:非业务预期热点,必须依靠自动探测发现,人工排查滞后
总结:热点探测的核心价值
解决 人工梳理热点滞后、漏判、无法应对突发热点 的问题,实现热点自动发现、自动下沉、自动降温、自动恢复的全自动化治理。
2.3 热点Key带来的优缺点 & 热Key进内存的优势
2.3.1 热Key危害
-
Redis分片倾斜,单节点CPU100%、网卡打满
-
集群整体卡顿、正常业务命令阻塞超时
-
主从同步延迟激增,数据一致性错乱
-
严重时引发集群雪崩、服务大面积降级
2.3.2 热Key下沉本地内存的核心优势
-
彻底解放Redis:热点请求不再访问Redis,从根源解决单节点压力
-
性能极致提升:网络IO归零,接口RT大幅降低
-
集群流量均衡:热点流量分散至所有应用实例,不再集中单节点
-
强容错能力:Redis宕机不影响热点业务可用
2.5 JDHotkey框架简介
JDHotkey 是京东开源的轻量级、无侵入、全自动热Key探测与治理框架,是目前国内企业最常用的热Key解决方案。
核心能力:无埋点探测、滑动窗口统计、全局聚合判定、自动本地缓存下沉、热度自动升降级
2.5.1 热点Key探测关键核心指标
行业通用可落地的四大判定指标,满足任意阈值即判定为热Key:
-
绝对QPS阈值:单Key每秒访问次数超过预设值(如500次/s)
-
流量占比阈值:单Key访问量占当前实例总Redis流量占比过高
-
持续热度时长:高频访问持续一定时间,过滤瞬时脉冲流量
-
流量环比突增:短时间内访问量暴涨,识别突发舆情热点
2.6 JDHotkey完整实现流程 + 流程图
2.6.1 核心执行流程
-
请求拦截:框架拦截项目所有Redis操作请求,捕获Key与访问频次
-
本地滑动窗口统计:客户端基于时间窗口实时计数,平滑流量,防误判
-
候选热点上报:单实例达到阈值后,将Key上报服务端
-
全局聚合判定:服务端汇总所有实例数据,确认全局真正热点
-
广播热Key规则:通过Redis Pub/Sub将热Key推送全部服务节点
-
本地缓存加载:各节点自动将热Key缓存至本地Caffeine,后续请求直接本地命中
-
热度自动降级:定时检测热度,热点消失后自动清理本地缓存,流量切回Redis
2.6.2 如何实现热点探测
而对于分布式应用,对热 Key 的访问是分散在不同的机器上的,无法在本地独立地进行计算,因此,需要一个独立的、集中的热 Key 计算单元。 我们可以简单理解为:分布式应用节点感知热点规则配置,将热点数据进行上报,工作节点进行热点数据统计,对于符合阈值的热点进行推送给客户端,应用收到热点信息进行本地缓存等策略这五个步骤:
- 热点规则:配置热 Key 的上报规则,圈出需要重点监测的 Key
- 热点上报:应用服务将自己的热 Key 访问情况上报给集中计算单元
- 热点统计:收集各应用实例上报的信息,使用滑动窗口算法计算 Key 的热度
- 热点推送:当 Key 的热度达到设定值时,推送热 Key 信息至所有应用实例
- 热点缓存:各应用实例收到热 Key 信息后,对 Key 值进行本地缓存
2.6.3 结构化流程图
JDHotkey 工作流程图
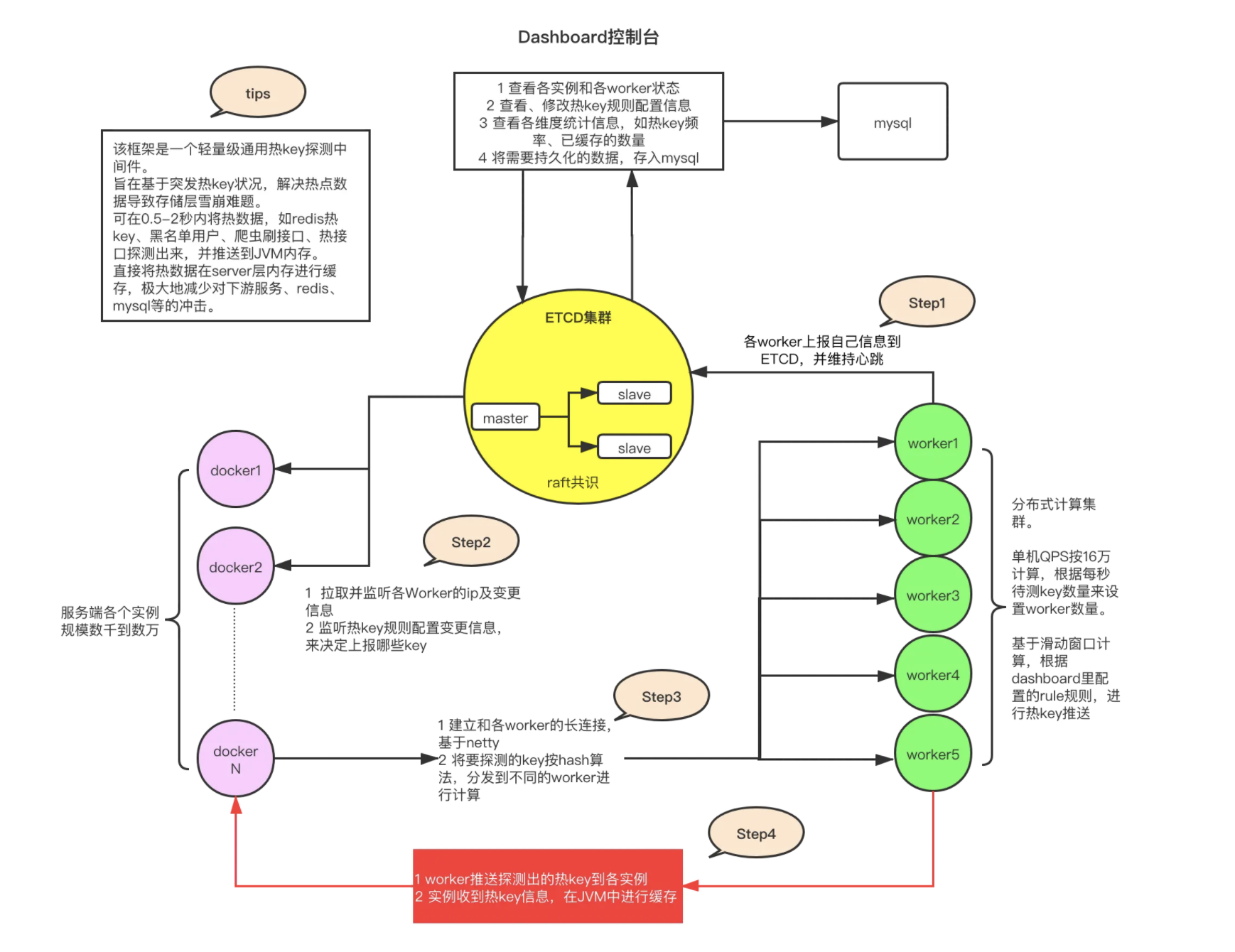
流程图说明:整体采用客户端采集+服务端聚合判定的去中心化架构,全程无人工干预,实现热Key「自动发现、自动下沉、长期守护、自动降级」的闭环治理。