目录
1.导入库和加载模型
python
from transformers import AutoModelForCausalLM, AutoTokenizer
# 假设Qwen是一个生成式模型,并且我们有它的权重和分词器
model_name = r"D:\learn\damodel\Qwen2.5-1.5B-Instruct"
# 加载模型和分词器
tokenizer = AutoTokenizer.from_pretrained(model_name) # 对文本进行分词,创建一个分词器tokenizer:Qwen2Tokenizer
model = AutoModelForCausalLM.from_pretrained(model_name)#加载预训练模型AutoModelForCausalLM:因果关系大模型,问一答一,适合做文本生成任务
AutoTokenizer:加载分词器,分词器的作用就是把我们说的话(提示词)转换成模型能理解的数字,也就是后面出现的input_ids。
model_name:这里填入的是我们下载的模型文件地址,上篇文章中就是模型的下载
2.构建提示词
python
# 定义一个Prompt模板
prompt_template = "请判断以下文本属于哪个类别:\"{}\"可选择的类别有正面,负面,中立"
# 预处理输入文本
input_text = "这部电影真是太差劲,我非常不喜欢!" # 领域:识别你是否具有抑郁症,把这段话上到上面花括号中
prompt_input = prompt_template.format(input_text)prompt_template:这里是给模型下达指令的模版。{}是一个占位符,里面就放我们问模型的问题。也就是input_text。
input_text:用来放我们需要模型回答的问题。
prompt_input就是用format方法把input_text放入到prompt_template中的{}里面。
3.编码输入
python
# 对Prompt进行编码
inputs = tokenizer(prompt_input, return_tensors="pt")tokenizer()分词器就是一个翻译官,它把人类语言翻译成模型语言。
return_tensor="pt":指定返回的数据格式是pytorch的张量(pt就是pytorch的缩写),这是因为model是一个pytorch模型,他只能处理张量。
inputs:是一个字典。其中一个关键部分是input_ids,是prompt_input翻译后的结果,用来给模型理解。另一部分是attention_mask,一串由0和1组成的数字,用来告诉模型哪些token是需要关注的内容(1),哪些是填充的(0),相当于人类对一句话抓重点。
4.模型推理(生成文本)
python
# 使用模型进行推理(生成文本)
output_sequences = model.generate(
inputs.input_ids,
max_new_tokens=512,
attention_mask=inputs.attention_mask
)model.generate():这是模型开始工作的核心函数,根据我们的输入,一个token一个token的预测接下来可能出现的token(其实token的意思就是最小的切分单元,就像一个字对人类来说是最小的切分单元一样,我们读文章可以说成逐字阅读,模型就是逐token)。
inputs.input_ids:把翻译好的问题传给模型。
max_new_tokens=512:这是限制模型生成的token数(可以理解为写作文限制字数),这里是不能超过512
attention_mask:把注意力掩码也传给模型,确保模型能关注重点。
output_sequences:这是一个包含生成结果的数字 ID 的张量。其实就是模型要进行回答生成内容,一个token一个token的进行生成,每一个token都是他们选取的最高概率的token的id。然后按顺序放在这个序列里面,直到内容生成结束。这里面的内容就是生成结果,只不过是机器语言版本的结果,稍后需要翻译为人能理解的文字。
5.解码与输出
python
# 解码生成的文本
generated_text = tokenizer.decode(output_sequences[0], skip_special_tokens=True)
print(generated_text)
# 提取生成的回答部分(去除Prompt部分)
text = generated_text[len(prompt_input):]tokenizer.decode():分词器这个翻译官的另一个任务,把模型生成的一串数字翻译成我们的能看懂的文字,也称为解码。
output_seqences0:因为模型生成会用不同方法生成,就会有多个序列,所以我们通常取一个就行了。
skip_special_token=true:解码的时候,跳过那些模型用的特殊标记,让我们输出更加干净。其实就是模型在进行上面工作的时候,留下的备注,就像我们预习课文的时候,标标画画,备注上自己能理解的需要注意的。这些特殊标记包括CLS用于标记开头、SEP用来分隔句子、PAD用来填充长度、UNK标注生僻字......
当 skip_special_tokens=False(其他不变),可以和后面结果进行对比
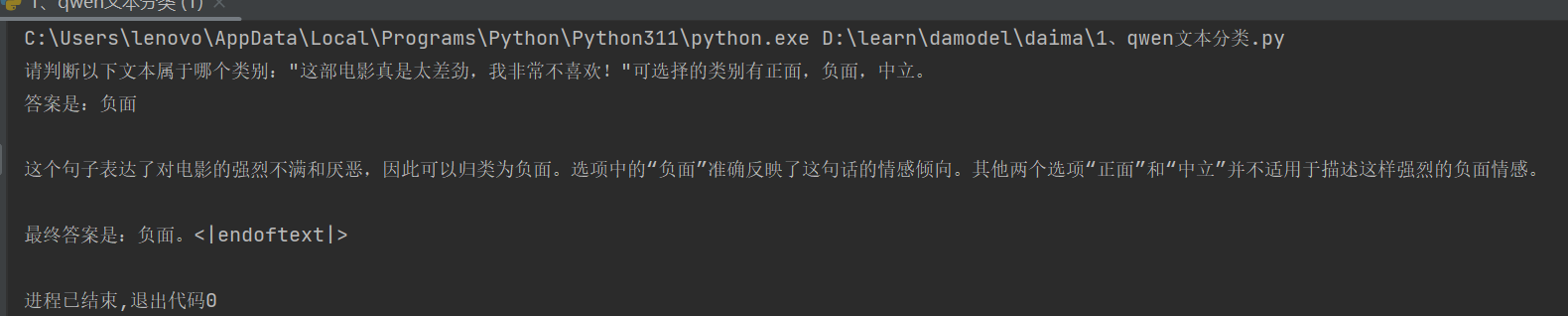
接下来的print就是输出模型生成的所有内容。
text = generated_textlen(prompt_input):,这里利用字符串切片把我们输入的问题部分从生成的完整文本中切掉,只提出新生成的答案部分,并赋值给了text。
在整个过程中,分词器就是我们模型的翻译官,是人类语言与机器语言的介质。
运行结果:
