前言
在前两篇文章中强化学习:3 分钟读懂强化学习的底层逻辑, 从 0 上手强化学习:用 Q-Learning 玩冰湖游戏,新手也能懂,我们一起从零手写了一个基于 Q-Learning 的强化学习智能体。它通过不断试错、更新 Q 表,最终学会了走出冰湖迷宫。但传统 Q-Learning 存在明显局限:智能体只能处理训练中见过的状态,面对未知场景无法泛化;同时 Q 表结构简单,难以应对复杂的现实业务场景。
如果把智能体原本 "查表式" 的大脑,替换为 ChatGPT、DeepSeek 这类大语言模型,会带来怎样的改变?这正是当下人工智能领域最热门的方向 ------LLM Agent(大模型智能体)。它的核心运行逻辑,与我们之前实现的 Q-Learning 一脉相承,依旧遵循观察 --- 思考 --- 行动的闭环。唯一的本质区别是:大模型智能体不再需要从零开始试错学习,其本身已具备强大的语言理解、逻辑推理与知识储备。
今天,我将以 Java 开发者熟悉的面向对象思维为切入点,带你理解大模型智能体的核心架构,并亲手将 "超级大脑" 融入代码,实现属于你的第一个 AI 助手。
一、 思维转换:Agent 到底是什么?
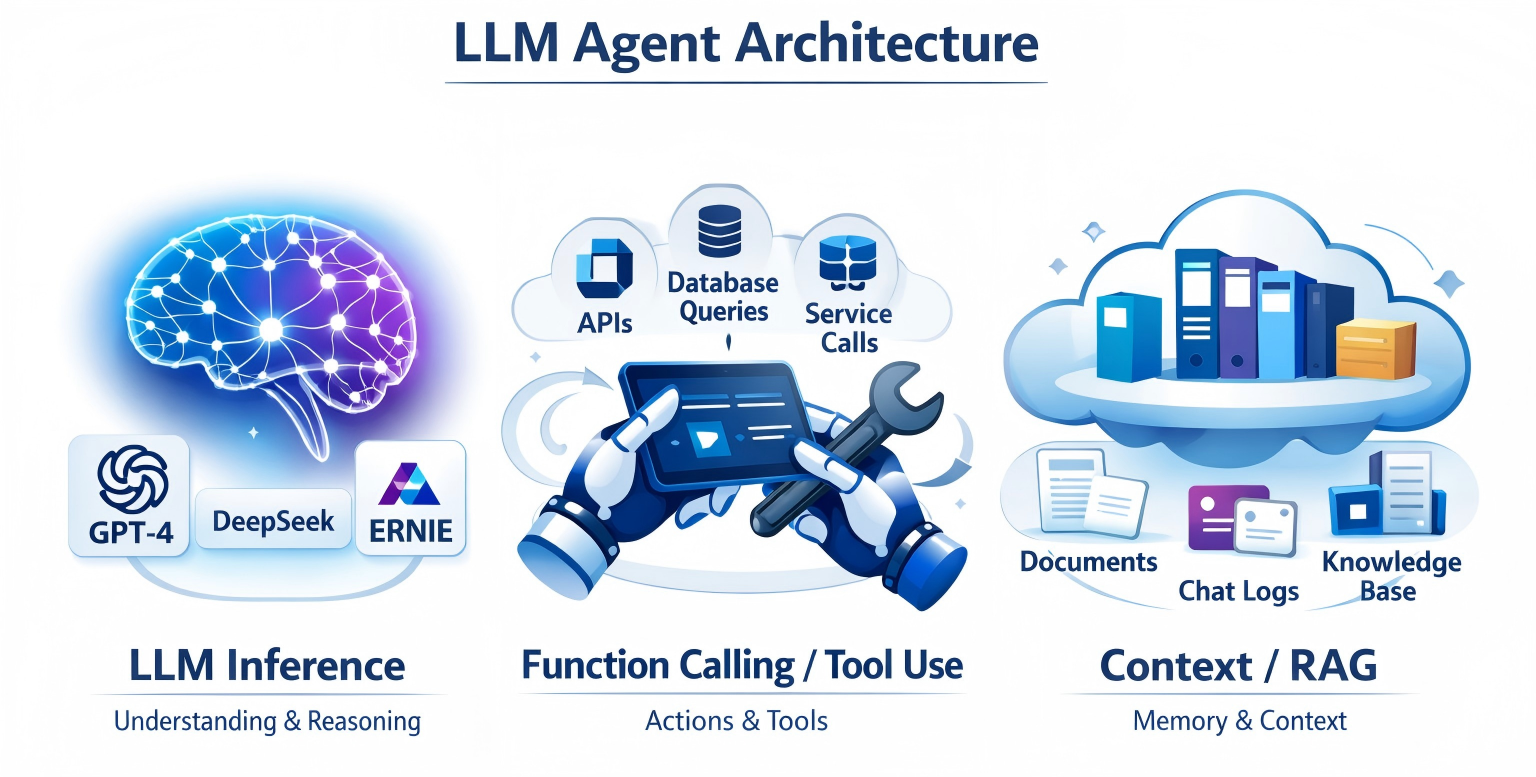
传统强化学习开发中,开发者需要自主设计算法、定义奖励函数、维护并更新策略表,开发成本高且泛化能力有限。而在大语言模型时代,构建一个可用的 LLM Agent,只需掌握三大核心组件。对于后端开发者而言,这一架构极易理解与落地:
-
**大脑(LLM Inference)**无需从零训练神经网络,直接接入 GPT-4、DeepSeek、文心一言等成熟大模型的 API。以自然语言提示词(Prompt)作为输入,大模型完成理解、推理并输出决策结果,承担智能体的 "思考中枢" 角色。
-
**双手(Function Calling / Tool Use)**这是工程落地的关键。大模型本身存在天然局限:无法直接查询数据库、获取实时数据、执行高精度数学计算。作为开发者,我们提前封装工具函数(Tools),类比 Java 中的 Service 层业务方法,并通过提示词告知大模型调用规则,让大模型在需要时主动调用外部能力。
-
**记忆(Context / RAG)**大模型本身无状态,不具备长期记忆能力。我们可以借鉴后端 HTTP Session 的管理思路,将用户历史对话、企业知识库(PDF、数据库、文档)检索出的相关信息作为上下文,持续传递给大模型,让智能体拥有连贯的 "记忆"。
二、 核心原理解析:ReAct 模式
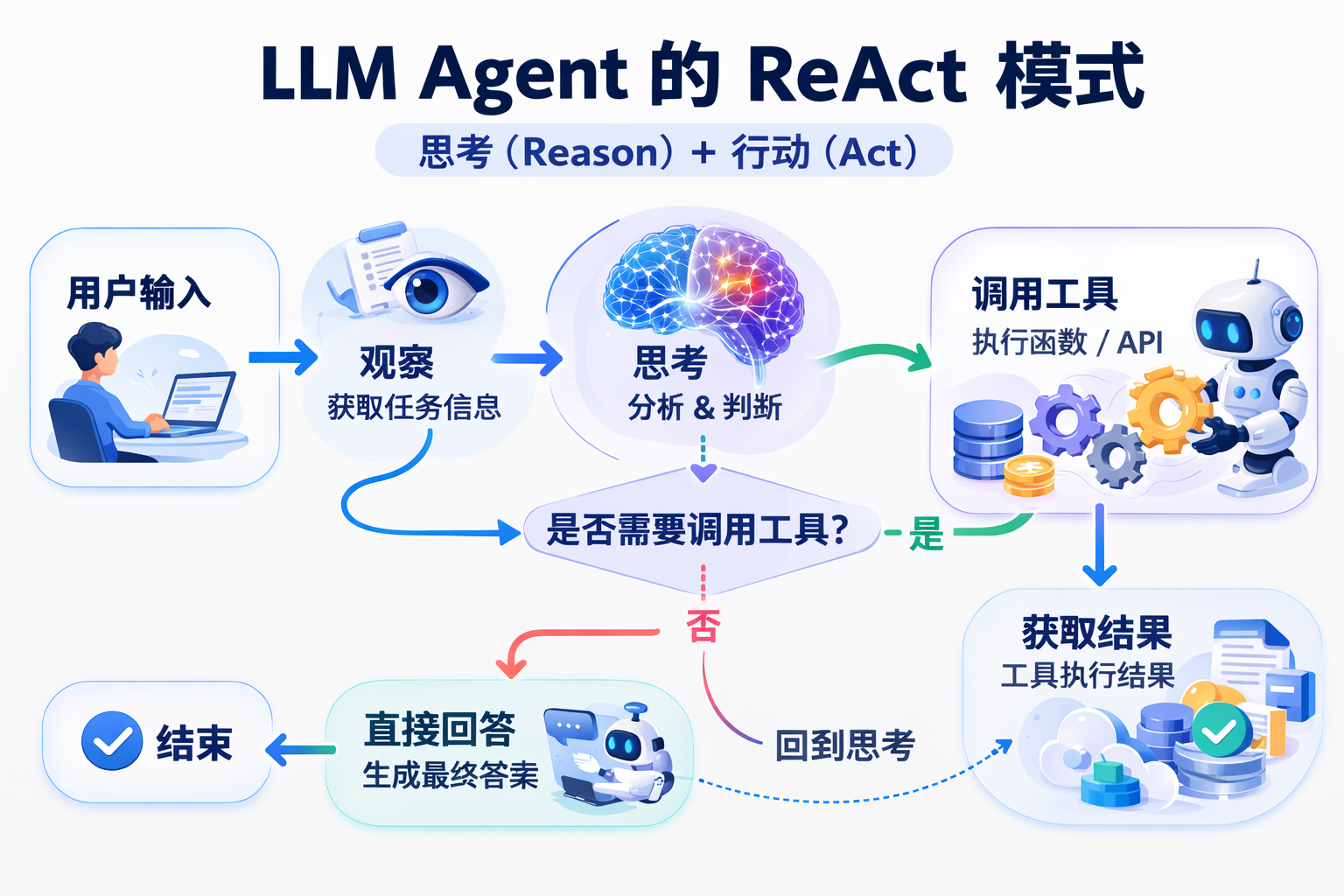
目前业界最主流的 Agent 运行逻辑被称为 ReAct (Reason + Act,即思考+行动) 模式。它是一个经典的 While 循环:
- 观察 (Observe):接收用户的指令。
- 思考 (Reason):大模型分析指令,决定是直接回答,还是需要调用外部工具。
- 行动 (Act):如果需要工具,大模型会生成调用参数,由我们(代码)去执行具体的函数逻辑。
- 反馈 (Observation):将函数的执行结果返回给大模型,大模型基于结果再次思考,直到得出最终答案。
三、 手把手实操:用 Python 写一个最简 Agent 引擎
为了让你彻底吃透 ReAct 循环的底层逻辑,本节不依赖任何复杂框架,仅用最基础的 Python 代码,手写一个极简但完整的 Agent 核心引擎。
背景设定 :大模型在数学计算上容易出现幻觉(错误结果)。我们实现一个智能体:当用户询问数学问题时,不依赖大模型估算,而是精准调用本地乘法函数,保证结果可靠。
在 VS Code 中新建一个文件夹,并在里面新建一个文件名为 agent_demo.py,将以下代码复制进去:
# agent_demo.py
# ======================
# 1. 定义工具集 (Agent的双手)
# 类比 Java 中的 Service 层方法
# ======================
def multiply_tool(a, b):
"""乘法计算工具"""
print(f" [系统日志] 执行乘法工具: {a} * {b}")
return a * b
def get_weather_tool(city):
"""模拟天气查询工具"""
print(f" [系统日志] 请求天气接口: {city}")
return f"{city} 今天晴转多云,气温25℃"
# ======================
# 2. 模拟大模型 (Agent的大脑)
# 真实场景替换为模型 API 调用
# ======================
def mock_llm_brain(user_query):
"""
模拟大模型的意图识别与决策能力:
解析用户问题 → 决定直接回答 或 调用工具
"""
if "乘" in user_query or "*" in user_query:
return {
"action": "call_tool",
"tool_name": "multiply",
"args": [123, 456]
}
elif "天气" in user_query:
return {
"action": "call_tool",
"tool_name": "get_weather",
"args": ["北京"]
}
else:
return {
"action": "reply",
"content": "您好,我是 AI 助手,支持乘法计算与天气查询。"
}
# ======================
# 3. Agent 主引擎 (ReAct 循环)
# ======================
def run_agent(query):
print(f"\n用户: {query}")
print("Agent: 思考中...")
# 限制最大步数,避免死循环
max_steps = 3
for step in range(max_steps):
# 1. 思考:交给大模型决策
response = mock_llm_brain(query)
# 2. 决策:直接回答
if response["action"] == "reply":
print(f"Agent: {response['content']}")
break
# 3. 决策:调用工具
elif response["action"] == "call_tool":
tool_name = response["tool_name"]
args = response["args"]
# 执行对应工具
tool_result = None
if tool_name == "multiply":
tool_result = multiply_tool(args[0], args[1])
elif tool_name == "get_weather":
tool_result = get_weather_tool(args[0])
# 输出工具结果
print(f" [工具返回] {tool_result}")
# 整合结果并回复
print(f"Agent: 已完成任务,结果为:{tool_result}")
break
# ======================
# 4. 测试运行
# ======================
if __name__ == "__main__":
print("=== 测试 1:常规对话 ===")
run_agent("你好,你能做什么?")
print("\n=== 测试 2:乘法计算(触发工具)===")
run_agent("帮我计算 123 乘 456")代码与原理对照讲解
Tools 层 对应 "Agent 的双手",是纯业务函数,与后端接口逻辑一致,负责执行具体任务。LLM Brain对应 "Agent 的大脑",本例用简单规则模拟;真实开发中替换为 HTTP 请求调用大模型 API。ReAct 循环对应核心流程:
- Observe:接收用户 query
- Reason:mock_llm_brain 做决策
- Act:调用 multiply /get_weather 工具
- Observation:拿到结果并回复用户
运行与观察
运行代码后,控制台会依次输出:
- 常规闲聊的直接回复
- 计算任务时的工具调用日志与精准结果 56088。
出现以上输出,说明你已经从底层理解了 LLM Agent 的工作机制。
结尾
从 Q-Learning 查表式的传统智能体,到基于大模型的 LLM Agent,本质都是感知 --- 决策 --- 执行 的强化学习思想。不同的是,大模型为智能体提供了开箱即用的认知能力,而我们后端开发者的价值,在于为它加上可靠的工具 与可控的记忆,让 AI 真正落地到业务中。
本文实现的极简引擎,是所有复杂 Agent 框架(如 LangChain、AutoGPT)的底层原型。后续我们将在此基础上,接入真实大模型 API、实现动态参数提取、接入数据库与 RAG 知识库,一步步构建可用于生产环境的企业级 AI 助手。
如果你是 Java 后端开发者,不必因为示例使用 Python 而困惑 ------ 下一篇,我会将这套 ReAct 思想完整迁移到 Java 中,用 SpringBoot 实现一个生产可用的 LLM Agent。