目录
[那 repl_backlog_buffer 缓冲区是什么时候写入的呢?](#那 repl_backlog_buffer 缓冲区是什么时候写入的呢?)
Redis主从同步中的增量和完全同步怎么实现?
完全同步
完全同步可以理解为:当从节点第一次连接主节点,或主从之间的增量同步无法完成时,主节点会把自己当前所有的数据(全量数据)一次性发送给从节点,让从节点的数据集和主节点完全一致
发生时机
1.初次建立连接:当一个从服务器首次连接到主服务器时,会第一次同步
2.从服务器数据丢失:如发生断电等突发情况,从服务器丢失数据会从主服务器同步
3.从服务器长时间没有同步主服务器数据
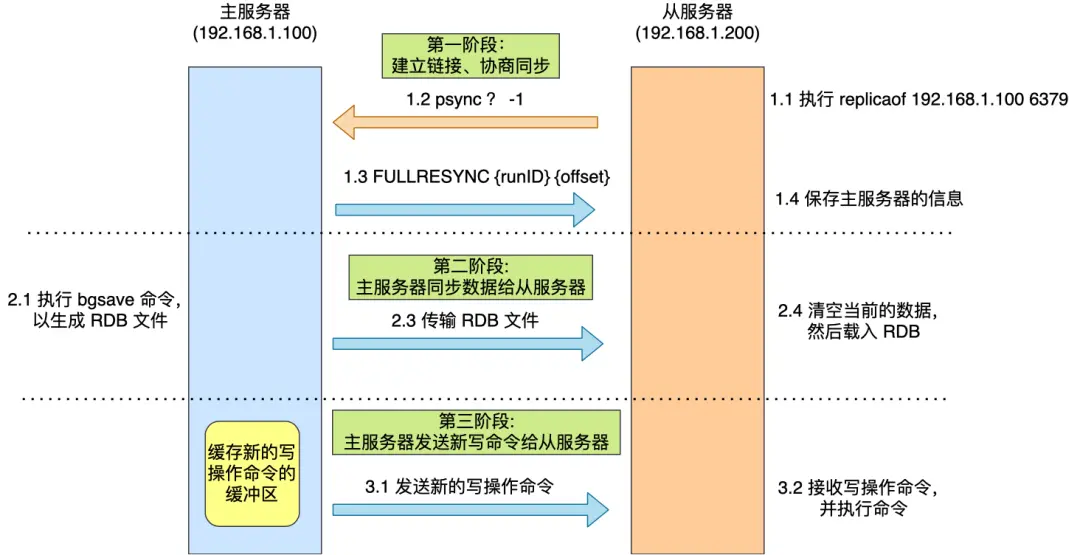
主从服务器第一次完全同步有三个阶段:
1.从服务器与主服务器建立连接、协商同步
2.主服务器生成RDB快照文件传输给从服务器
3.主服务器将在从服务器同步数据的期间,主服务器接受到的新写的操作命令传输给从服务器
分为6步:1.从服务器发送SYNC命令给主服务器,请求同步
2 .主服务器生成RDB快照文件
3.主服务器传输RDB文件
4.从服务器解析RDB文件
5.主服务器写新写命令 给从服务器,新写的命令会存储在replication backlog buffer文件中
6.**传输命令:**在RDB文件传输完成后会立马传输replication backlog buffer文件给从服务器来保持数据一致
写命令
就是指所有会改变数据的命令 ,不仅仅是 "写入新数据",而是涵盖了增、删、改三类操作的指令。
增量同步
Redis 主从复制中的增量同步(Partial Resynchronization) ,是指主从节点完成首次全量同步后,或从节点短暂断线重连后,主节点仅将从节点缺失的写操作命令(而非全量数据)同步给从节点,使从节点快速恢复与主节点数据一致的同步方式。
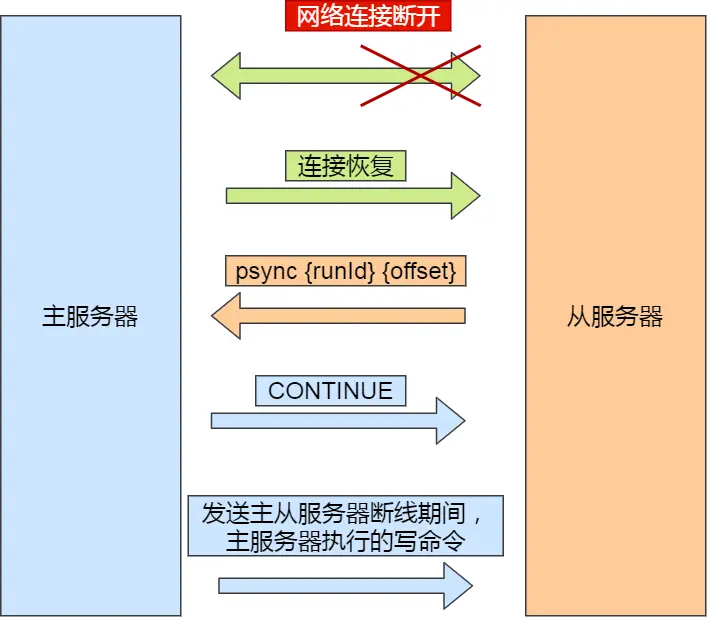
主要有三个步骤:
1.从服务器发送PSYNC命令给主服务器,告知偏移量和比较节点ID,看是否是之前的主服务器ID,此时offset的参数值不是-1,代表不是第一次连接主服务器
2.若主服务器与传来的节点ID一致,则发送CONTINUE命令,告诉从服务器接下来要开始增量同步
3.根据偏移量来发送 从服务器断线期间主服务器执行的写命令
主服务器怎么知道要将哪些增量数据发送给从服务器呢?
依托两个东西
1.repl_backlog_buffer: 一个环形的缓冲区,会存入写命令,用于从服务器重新连接后找到差异数据
2.replication offset: 偏移量,根据此参数可以比较主从服务器的差异在哪里
当从服务器连接上主服务器后,会把从服务器的复制偏移量salve _repl_offset和主服务器的master_repl_offset进行对比,来确定增量同步哪些数据
主服务器偏移量:master_repl_offset
从服务器偏移量:salve _repl_offset
那 repl_backlog_buffer 缓冲区是什么时候写入的呢?
在主服务器发送写命令给从服务器时,会把写命令写进repl_backlog_buffer
当从服务器连接上主服务器后,会根据主从服务器的复制偏移量 salve _repl_offset和主服务器的master_repl_offset的差距,来确定用那种方式进行同步
若差距过大 ,内容不在repl_backlog_buffer缓冲区里那么就需要采用完全同步
若差距比较小 ,内容能在repl_backlog_buffer缓冲区里找到,那么就可以采用增量同步
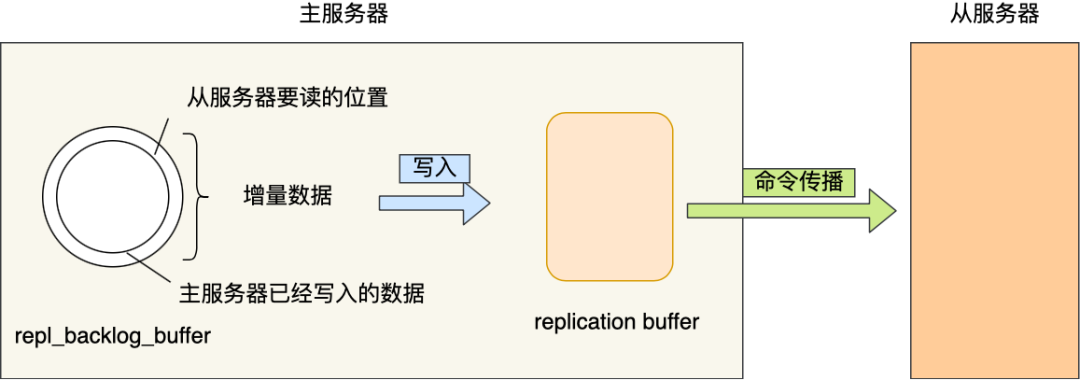
因为repl_backlog_buffer是一个环形缓冲区,默认大小是 1M,所以当数据写满后,会覆盖最开始的数据,若主服务器写入速度过快远远超过从服务器的读取速度,很快就会覆盖之前的数据,想要同步已经覆盖的数据,就要采取完全同步会消耗许多性能
因此为了避免频繁的采用完全同步的情况,我们可以扩大缓冲区的大小,减少数据没被读取就完全被覆盖的概率