卷积神经网络(Convolutional Neural Network,CNN)是深度学习中最重要的模型结构之一,尤其适合处理图像、视频等具有空间结构的数据。与普通多层感知机(MLP)直接把输入展开为一维向量不同,卷积神经网络会尽量保留图像中的局部邻域关系,通过卷积核在图像上滑动,自动学习边缘、纹理、形状等层级特征。
MLP 可以通过多层"线性变换 + 非线性激活"学习复杂非线性关系。但是,如果直接用 MLP 处理图像,通常需要把二维图像展开成一维向量,这会削弱图像原有的空间结构信息。
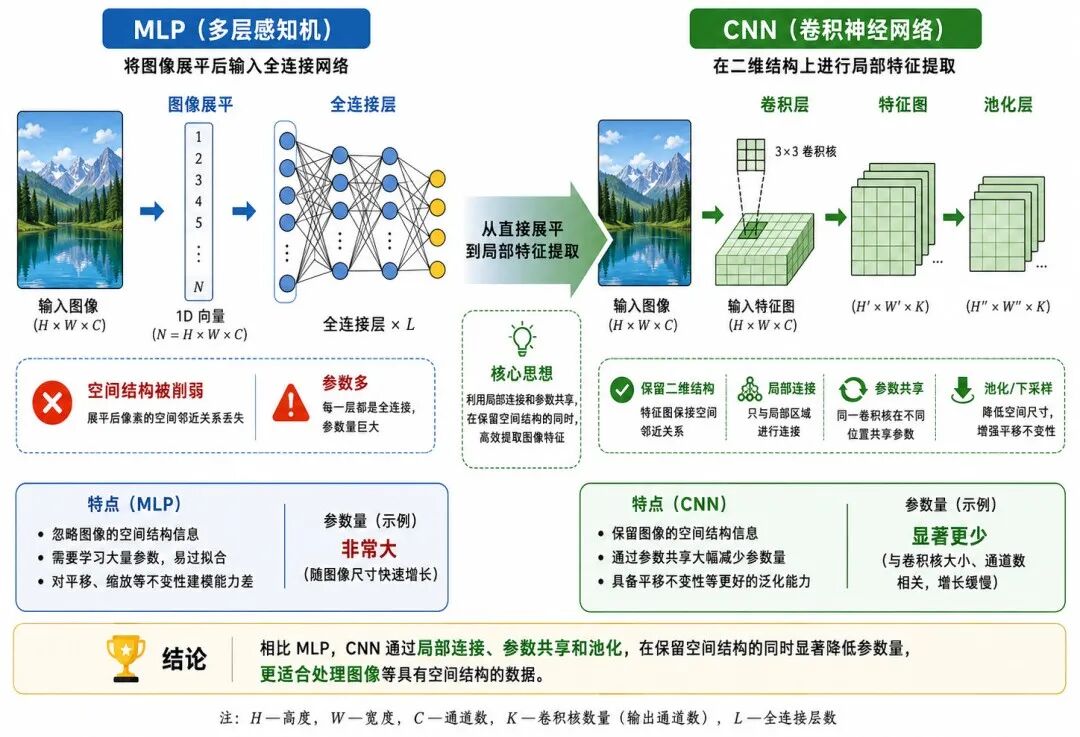
图 1:从 MLP 到卷积神经网络
卷积神经网络正是为了解决这类问题而发展起来的。它通过局部连接、权重共享、特征图、池化等机制,使模型能够更有效地从图像中提取空间特征,并逐层形成从低级视觉特征到高级语义特征的表示。
一、为什么需要卷积神经网络
图像数据与普通表格数据不同。
在表格数据中,每一列通常表示一个明确特征,例如面积、楼龄、收入、消费次数等。而在图像中,每个像素本身并不总是具有独立语义。一个像素是否重要,往往取决于它周围像素的排列关系。
例如,在一张手写数字图片中:
• 相邻像素共同形成笔画
• 笔画组合形成局部结构
• 局部结构进一步组合成数字整体
• 数字类别取决于这些空间结构的整体模式
如果把图像直接展平成一维向量,再交给 MLP 处理,模型虽然仍然可以训练,但会遇到几个问题。
第一,空间结构被削弱。
原本相邻的像素在展平后可能相距很远,模型不容易直接利用局部邻域关系。
第二,参数数量可能过大。
如果一张图像大小为 224 × 224 × 3,展平后就是 150528 个输入值。若直接连接到一个有 1000 个神经元的隐藏层,仅第一层就会产生大量参数。
第三,模型难以自动利用平移不变性。
图像中的同一个边缘、纹理或局部形状,可能出现在不同位置。普通全连接网络需要在不同位置重复学习类似特征。
卷积神经网络的基本思想是:用较小的卷积核在图像上滑动,在不同位置重复检测相同局部模式。
这样做带来两个重要好处:
• 局部连接:每个神经元只关注局部区域
• 权重共享:同一个卷积核在整张图像上重复使用
因此,CNN 比普通 MLP 更适合处理图像这类具有空间结构的数据。
二、卷积运算的基本思想
卷积神经网络的核心操作是卷积(Convolution)。在图像处理中,可以把卷积理解为:用一个小矩阵在图像上滑动,并对局部区域进行加权求和。
这个小矩阵通常称为卷积核(Kernel)或滤波器(Filter)。
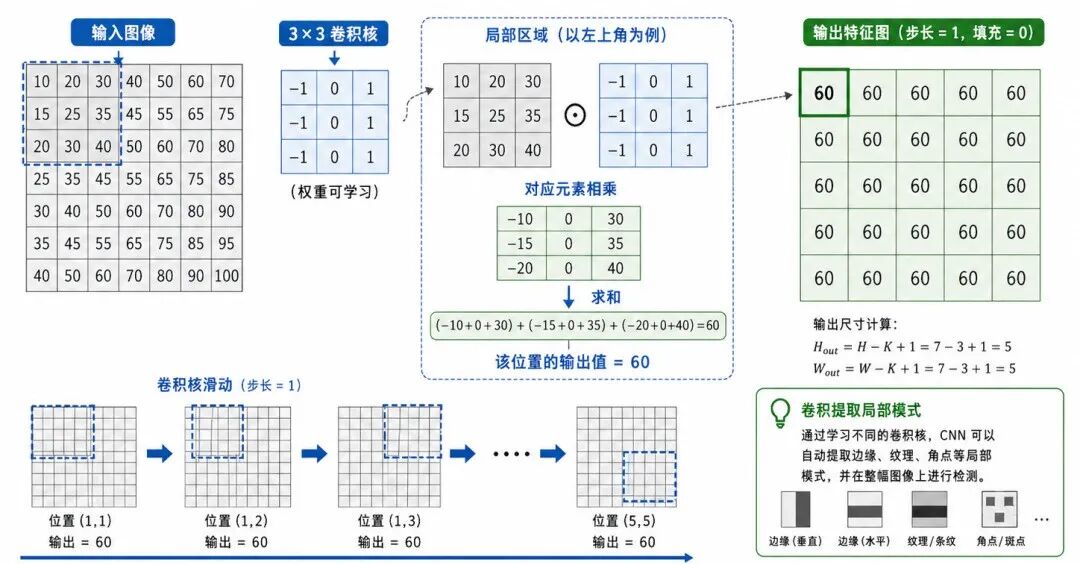
图 2:卷积核在图像上滑动并生成特征图
假设输入图像是一个二维矩阵,卷积核也是一个较小的二维矩阵。卷积核每次覆盖图像中的一个局部区域,然后把对应位置相乘并求和,得到输出特征图中的一个数值。
对于二维输入,简化的卷积计算可以写为:
其中:
• X 表示输入图像或输入特征图
• K 表示卷积核
• S(i,j) 表示输出特征图在位置 (i,j) 的值
• m、n 表示卷积核内部的位置索引
• ∑ 表示对局部区域内的元素求和
从直观角度看,卷积核像一个"局部模式检测器"。
不同卷积核可以学习不同视觉模式:
• 有的卷积核可能检测水平边缘
• 有的卷积核可能检测垂直边缘
• 有的卷积核可能检测斜线纹理
• 更深层的卷积核可能检测局部形状或物体部件
在 PyTorch 中,torch.nn.Conv2d 用于对由多个输入平面组成的输入信号执行二维卷积,常用于图像特征提取。
三、卷积层的关键概念
理解 CNN,需要掌握几个核心概念:卷积核、步幅、填充、通道和特征图。
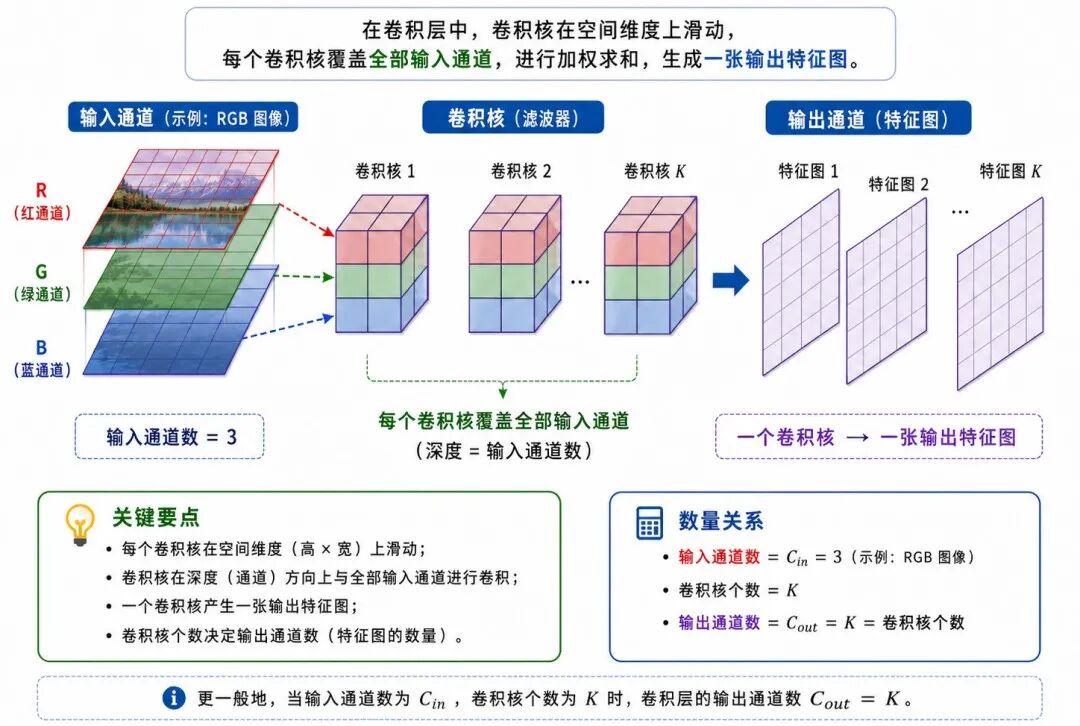
图 3:卷积层中的卷积核、通道与特征图
1、卷积核:局部特征检测器
卷积核是一个可学习的小矩阵。训练开始时,卷积核中的数值通常是随机初始化的;训练过程中,模型会通过反向传播不断调整这些数值,使卷积核逐渐学会对任务有用的局部模式。
例如,一个 3 × 3 卷积核可以写成:
其中:
• K 表示卷积核
• k₁₁、k₁₂、...、k₃₃ 表示卷积核中的可学习参数
• 3 × 3 表示卷积核覆盖的局部区域大小
卷积核越大,每次看到的局部区域越大;卷积核越小,计算更轻量,也更容易堆叠成深层结构。
在现代 CNN 中,3 × 3 卷积非常常见,因为它既能捕捉局部结构,又具有较好的计算效率。
2、步幅:卷积核每次移动的距离
步幅(Stride)表示卷积核每次滑动的距离。
如果 stride = 1,卷积核每次移动 1 个像素;如果 stride = 2,卷积核每次移动 2 个像素。
步幅越大,输出特征图的尺寸通常越小。
可以简单理解为:
• 小步幅:保留更多空间细节
• 大步幅:更快降低特征图尺寸
3、填充:控制边缘信息与输出尺寸
填充(Padding)是在输入图像边缘补充额外像素,常见做法是在边缘补 0。
填充的作用主要有两个:
• 让卷积核能够覆盖图像边缘区域
• 控制输出特征图的空间尺寸
如果没有填充,卷积核在滑动时无法完全覆盖边缘像素,输出尺寸会逐层变小。适当填充可以缓解这一问题。
4、通道:从灰度图到彩色图
图像通常具有通道(Channel)。
例如:
• 灰度图通常有 1 个通道
• 彩色 RGB 图像通常有 3 个通道
• 卷积层输出的特征图也可以有多个通道
在 CNN 中,每个输出通道通常对应一个卷积核学习到的一类特征。多个卷积核会生成多个输出通道,也就是多张特征图。
例如,一个卷积层可以把输入从 3 个通道变成 32 个通道:
apache
nn.Conv2d(in_channels=3, out_channels=32, kernel_size=3)其中:
• in_channels=3 表示输入有 3 个通道
• out_channels=32 表示输出 32 个特征通道
• kernel_size=3 表示使用 3 × 3 卷积核
在 PyTorch 中,二维卷积层的输入通常具有形状 N、C、H、W,分别表示批量大小、通道数、高度和宽度;Conv2d 的 in_channels 和 out_channels 用来指定输入与输出通道数量。
5、特征图:卷积层的输出
卷积层的输出称为特征图(Feature Map)。一张特征图可以理解为某个卷积核在图像不同位置上的响应强度。
如果某个位置与卷积核学习到的模式相似,响应值通常较高;如果不相似,响应值可能较低。
从直观角度看,特征图回答的是:某种局部模式在图像的哪些位置出现得比较明显?
随着网络层数加深,特征图表达的内容也会逐渐抽象:
go
边缘、角点→ 纹理、笔画→ 局部形状→ 物体部件→ 类别相关语义四、池化层与空间尺寸压缩
卷积层负责提取局部特征,但如果一直保留完整空间尺寸,计算量会很大,而且模型可能过度关注细节位置。
池化层(Pooling Layer)用于降低特征图的空间尺寸,同时保留主要响应信息。
最常见的是最大池化(Max Pooling)。它在局部区域中取最大值,例如在 2 × 2 区域中选出最大响应。
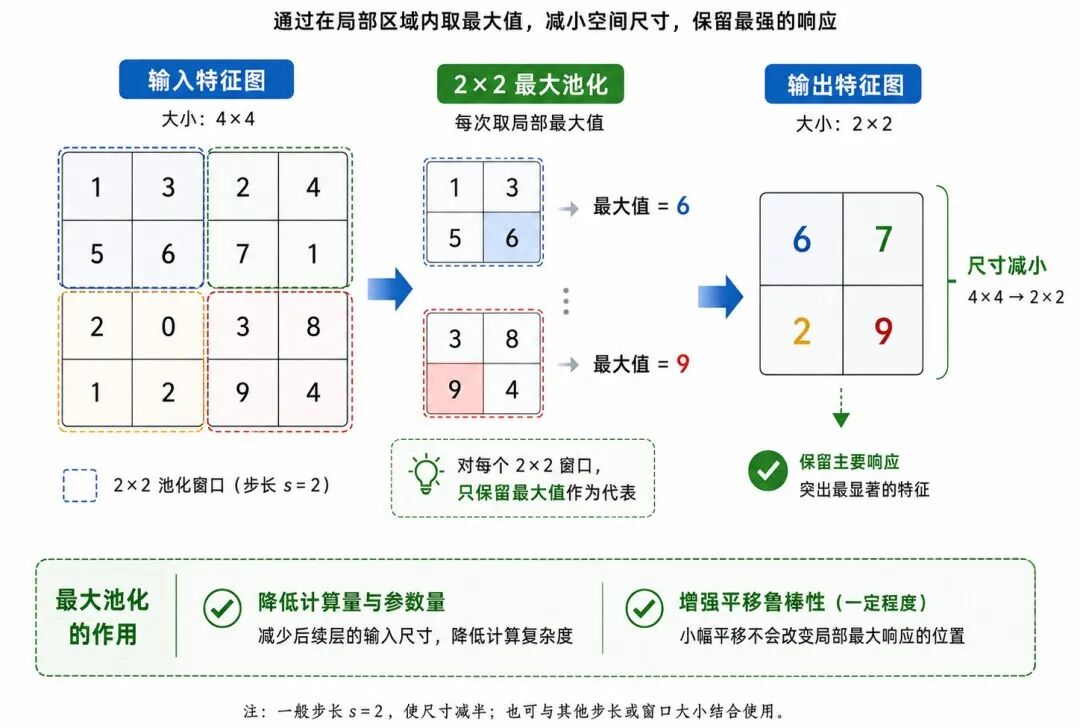
图 4:最大池化如何压缩特征图尺寸
最大池化可以写为:
其中:
• X 表示输入特征图
• Y(i,j) 表示池化后在位置 (i,j) 的值
• R(i,j) 表示当前位置对应的局部区域
• max 表示取最大值
从直观角度看,最大池化保留的是局部区域中最明显的特征响应。
池化层的作用包括:
• 降低特征图尺寸
• 减少计算量
• 增强一定程度的位置鲁棒性
• 保留局部区域中最显著的特征
例如,一个 2 × 2 最大池化层通常会把特征图的高和宽约缩小一半。
在 PyTorch 中,torch.nn.MaxPool2d 用于对由多个输入平面组成的输入信号执行二维最大池化,输入形状通常也按 N、C、H、W 组织。
需要注意的是,池化并不是 CNN 中唯一的下采样方式。现代网络中,也常用步幅卷积(Strided Convolution)来替代部分池化操作。
五、CNN 的典型结构
一个基础 CNN 通常由三类模块组成:
卷积层 → 激活函数 → 池化层 → 全连接层 → 输出层
更具体地说,常见图像分类 CNN 可以写成:
go
输入图像→ 卷积层→ ReLU→ 池化层→ 卷积层→ ReLU→ 池化层→ 展平→ 全连接层→ 输出类别得分其中:
• 卷积层负责提取局部特征
• ReLU 负责引入非线性
• 池化层负责压缩空间尺寸
• 展平操作把多维特征图转换成一维向量
• 全连接层负责综合特征并输出类别得分
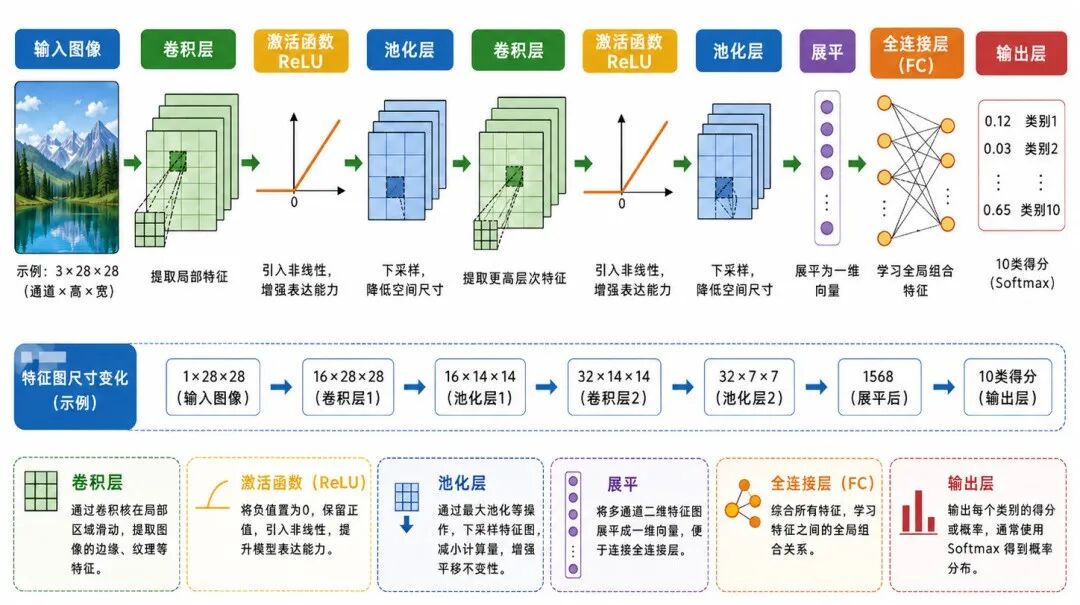
图 5:卷积神经网络的典型结构
在图像分类任务中,CNN 的前半部分通常称为特征提取器,后半部分通常称为分类器。
可以简单理解为:
• 特征提取器:从图像中提取有用视觉特征
• 分类器:根据这些特征判断类别
例如,对于手写数字识别任务,前面的卷积层可能学习笔画、弯曲结构、局部纹理等特征,后面的全连接层则根据这些特征判断数字类别。
六、CNN 为什么适合图像任务
CNN 适合图像任务,主要来自三个结构优势:局部感受野、权重共享和层级特征学习。
1、局部感受野
局部感受野(Local Receptive Field)表示一个神经元只关注输入中的局部区域。
在图像中,局部像素往往具有强相关性。例如,一个边缘通常由相邻像素共同形成。卷积层利用局部感受野,可以优先学习这些局部结构,而不必一开始就连接整张图像。
这比普通全连接层更符合图像数据的空间规律。
2、权重共享
权重共享(Weight Sharing)表示同一个卷积核在图像不同位置重复使用。
如果一个卷积核学会检测某种边缘模式,那么它可以在整张图像的不同位置检测同样的模式。
这带来两个好处:
• 大幅减少参数数量
• 提高对位置变化的适应能力
例如,同一个竖直边缘可能出现在图像左侧、右侧或中间。通过权重共享,CNN 不需要为每个位置单独学习一套参数。
3、层级特征学习
CNN 的浅层通常学习低级特征,深层逐渐学习更抽象的高级特征。
可以粗略理解为:
• 浅层:边缘、角点、纹理
• 中层:局部形状、部件
• 深层:物体结构、类别语义
这种层级特征学习能力,是 CNN 在图像识别任务中表现优异的重要原因。
4、与 MLP 的对比
如果用 MLP 直接处理图像,通常需要展平输入。这样会削弱空间结构,同时带来大量参数。
而 CNN 在卷积阶段保留了图像的二维结构,通过局部连接和权重共享更高效地提取空间特征。
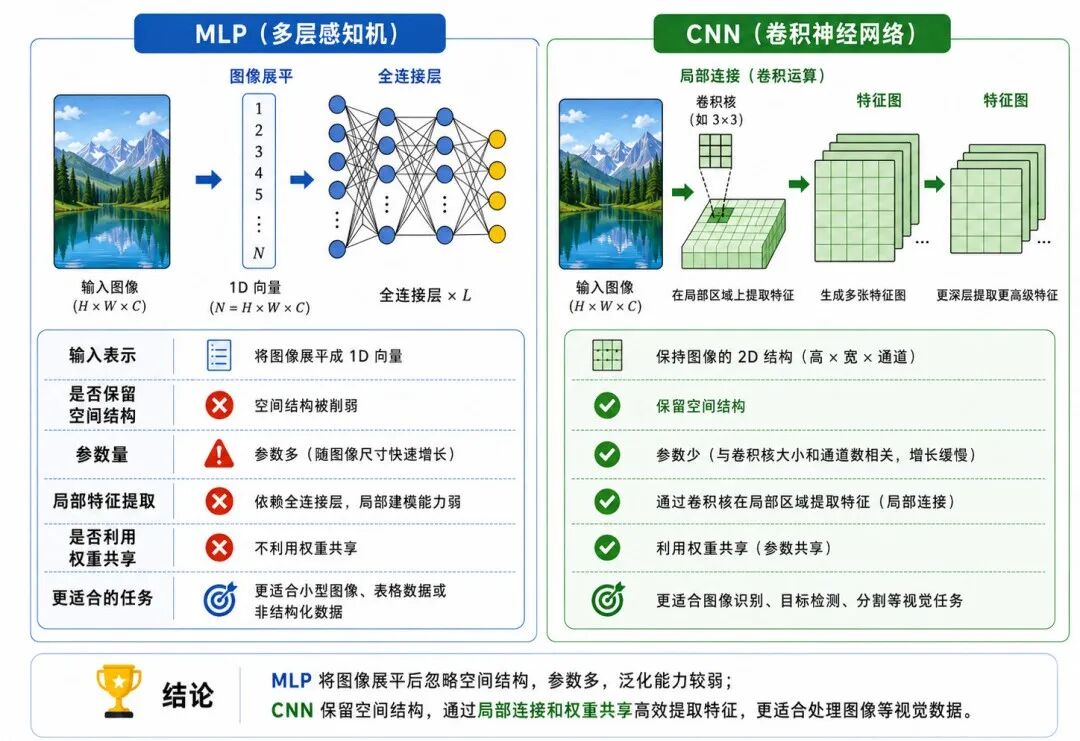
图 6:MLP 与 CNN 处理图像方式的对比
可以简单对比为:
• MLP:把图像展平成向量,再进行全连接计算
• CNN:保留图像空间结构,用卷积核逐层提取局部特征
七、PyTorch 实现:手写数字分类 CNN
下面使用 PyTorch 构建一个简单 CNN,完成 MNIST 手写数字分类任务。
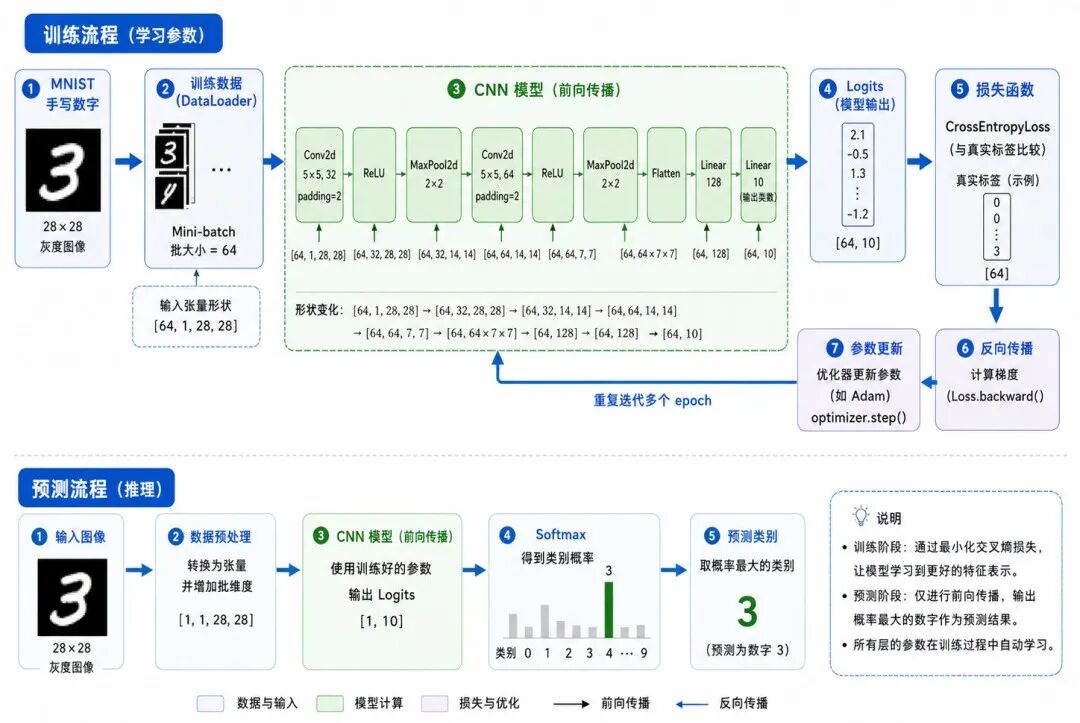
图 7:CNN 在 MNIST 上的训练与预测流程
MNIST 是经典手写数字图像数据集,图像为 0 到 9 的数字类别。Torchvision 提供了 torchvision.datasets.MNIST 数据集接口,可以通过 root、train、transform、target_transform、download 等参数加载数据。
1、导入库并设置环境
python
import torch # PyTorch 主库import torch.nn as nn # 神经网络模块(层、损失函数等)import torch.optim as optim # 优化器模块(SGD、Adam等)
from torch.utils.data import DataLoader # 数据加载器,批量加载数据from torchvision import datasets, transforms # torchvision提供常用数据集和图像预处理工具这里使用:
• torch.nn 定义神经网络层
• torch.optim 定义优化器
• DataLoader 按小批量加载数据
• torchvision.datasets 加载 MNIST 数据集
• torchvision.transforms 进行图像预处理
2、准备 MNIST 数据集
python
# 图像预处理:将 PIL 图像转为张量,并标准化到均值和标准差(基于 MNIST 统计值)transform = transforms.Compose([ transforms.ToTensor(), # 将 (H,W) 或 (H,W,C) 转为 (C,H,W),值域 [0,1] transforms.Normalize((0.1307,), (0.3081,)) # 标准化:减去均值0.1307,除以标准差0.3081])
# MNIST 训练集(60000张手写数字图片)train_dataset = datasets.MNIST( root="./data", # 数据集存放目录 train=True, # 加载训练集 download=True, # 如果本地没有则自动下载 transform=transform # 应用上述预处理)
# MNIST 测试集(10000张图片)test_dataset = datasets.MNIST( root="./data", train=False, download=True, transform=transform)
# 训练数据加载器:批次大小64,每个 epoch 打乱顺序train_loader = DataLoader( train_dataset, batch_size=64, shuffle=True)
# 测试数据加载器:批次大小1000,无需打乱test_loader = DataLoader( test_dataset, batch_size=1000, shuffle=False)其中:
• ToTensor() 将图像转换为张量
• Normalize() 对图像进行标准化
• train=True 表示加载训练集
• train=False 表示加载测试集
• download=True 表示如果本地没有数据则自动下载
• DataLoader 用于按批量读取数据
MNIST 是灰度图像,因此输入通道数为 1。每张图片大小为 28 × 28。
3、定义 CNN 模型
ruby
# 定义一个简单的 CNN 模型(适用于 MNIST 28x28 灰度图)class SimpleCNN(nn.Module): def __init__(self): super().__init__()
# 特征提取部分:卷积 + ReLU + 池化(两层) self.features = nn.Sequential( # 第一层卷积:输入单通道 → 16通道,3x3卷积核,padding=1保持尺寸 nn.Conv2d( in_channels=1, out_channels=16, kernel_size=3, padding=1 ), nn.ReLU(), nn.MaxPool2d(kernel_size=2), # 2x2池化,尺寸减半:28→14
# 第二层卷积:16通道 → 32通道,3x3卷积核,padding=1保持尺寸 nn.Conv2d( in_channels=16, out_channels=32, kernel_size=3, padding=1 ), nn.ReLU(), nn.MaxPool2d(kernel_size=2) # 再次池化:14→7 )
# 分类部分:展平 → 全连接 → ReLU → 输出10类 self.classifier = nn.Sequential( nn.Flatten(), # 展平为向量:32*7*7=1568维 nn.Linear(32 * 7 * 7, 128), # 全连接层:1568 → 128 nn.ReLU(), nn.Linear(128, 10) # 输出10个类别logits )
def forward(self, x): x = self.features(x) # 提取特征 x = self.classifier(x) # 分类输出 return x
# 实例化模型model = SimpleCNN()这个 CNN 可以分为两部分。
第一部分是特征提取器:
Conv2d → ReLU → MaxPool2d → Conv2d → ReLU → MaxPool2d
第二部分是分类器:
Flatten → Linear → ReLU → Linear
输入图像尺寸变化过程为:
go
输入:1 × 28 × 28第一次卷积后:16 × 28 × 28第一次池化后:16 × 14 × 14第二次卷积后:32 × 14 × 14第二次池化后:32 × 7 × 7展平后:32 × 7 × 7 = 1568输出:10 个类别得分其中:
• 第一个卷积层把 1 个输入通道变成 16 个特征通道
• 第二个卷积层把 16 个通道变成 32 个通道
• 两次最大池化分别把空间尺寸减半
• 最后一层输出 10 个类别得分,对应数字 0 到 9
4、定义损失函数和优化器
ini
# 定义损失函数:交叉熵损失(适用于多分类,内部包含 Softmax)criterion = nn.CrossEntropyLoss()
# 定义优化器:Adam 自适应学习率优化器,学习率 0.001,优化模型的全部参数optimizer = optim.Adam(model.parameters(), lr=0.001)其中:
• CrossEntropyLoss 用于多分类任务
• Adam 是常用优化器,lr=0.001 表示学习率,model.parameters() 表示把模型所有可训练参数交给优化器
需要注意,CrossEntropyLoss() 直接接收模型输出的 logits,不需要在模型最后手动添加 Softmax。PyTorch 文档说明,CrossEntropyLoss 可用于 C 类分类任务,并计算输入 logits 与目标类别之间的交叉熵损失。
5、训练模型
python
num_epochs = 3 # 训练轮数
for epoch in range(num_epochs): model.train() # 切换到训练模式(启用Dropout、BatchNorm等) total_loss = 0.0
# 遍历训练集的所有批次 for images, labels in train_loader: # 1. 前向传播:计算预测输出 outputs = model(images) # 输入图像,得到logits loss = criterion(outputs, labels) # 计算交叉熵损失
# 2. 反向传播与参数更新 optimizer.zero_grad() # 清空旧梯度 loss.backward() # 反向传播,计算梯度 optimizer.step() # 更新模型参数
# 累加当前批次的损失(按样本数加权) total_loss += loss.item() * images.size(0)
# 计算本轮平均损失(总损失 / 总样本数) avg_loss = total_loss / len(train_loader.dataset)
print(f"Epoch [{epoch + 1}/{num_epochs}], Loss: {avg_loss:.4f}")这段训练代码体现了 PyTorch 中最常见的训练闭环:
前向传播 → 计算损失 → 清空旧梯度 → 反向传播 → 更新参数
其中:
• model.train() 表示进入训练模式
• outputs = model(images) 表示前向传播
• loss = criterion(outputs, labels) 表示计算损失
• optimizer.zero_grad() 用于清空旧梯度
• loss.backward() 用于自动计算梯度
• optimizer.step() 用于更新参数
6、评估模型
python
# 切换到评估模式(关闭Dropout、BatchNorm等训练行为)model.eval()
correct = 0 # 正确预测的样本数total = 0 # 总样本数
# 禁用梯度计算,降低内存占用并加速with torch.no_grad(): for images, labels in test_loader: outputs = model(images) # 前向传播,得到logits predicted = outputs.argmax(dim=1) # 取概率最大的类别作为预测
total += labels.size(0) # 累计本批次样本数 correct += (predicted == labels).sum().item() # 累计正确预测数
# 计算测试集准确率accuracy = correct / totalprint(f"测试集准确率:{accuracy:.4f}")其中:
• model.eval() 表示进入评估模式
• torch.no_grad() 表示不计算梯度
• outputs.argmax(dim=1) 取最大得分对应的类别
• accuracy 表示测试集准确率
对于多分类任务,模型输出的是 10 个类别得分。哪个类别得分最高,模型就预测为哪个数字。
7、查看单个批次的形状变化
为了帮助理解 CNN 中张量形状的变化,可以打印一个批次的输入和输出形状:
apache
# 从训练数据加载器中获取一个批次(64张图像)images, labels = next(iter(train_loader))
print("输入图像形状:", images.shape) # 期望 (64,1,28,28)
# 将图像输入模型,得到预测logitsoutputs = model(images)
print("输出结果形状:", outputs.shape) # 期望 (64,10)可能看到类似结果:
css
输入图像形状: torch.Size([64, 1, 28, 28])输出结果形状: torch.Size([64, 10])其中:
• 64 表示 batch_size
• 1 表示灰度图像通道数
• 28 × 28 表示图像高和宽
• 10 表示 10 个类别得分
这说明模型把一批 28 × 28 的手写数字图像,转换成了对应 10 个类别的预测得分。
八、CNN 的适用场景、局限与扩展方向
卷积神经网络是计算机视觉中的基础模型之一。它非常适合处理具有空间结构的数据,但也并不是所有任务中的唯一选择。
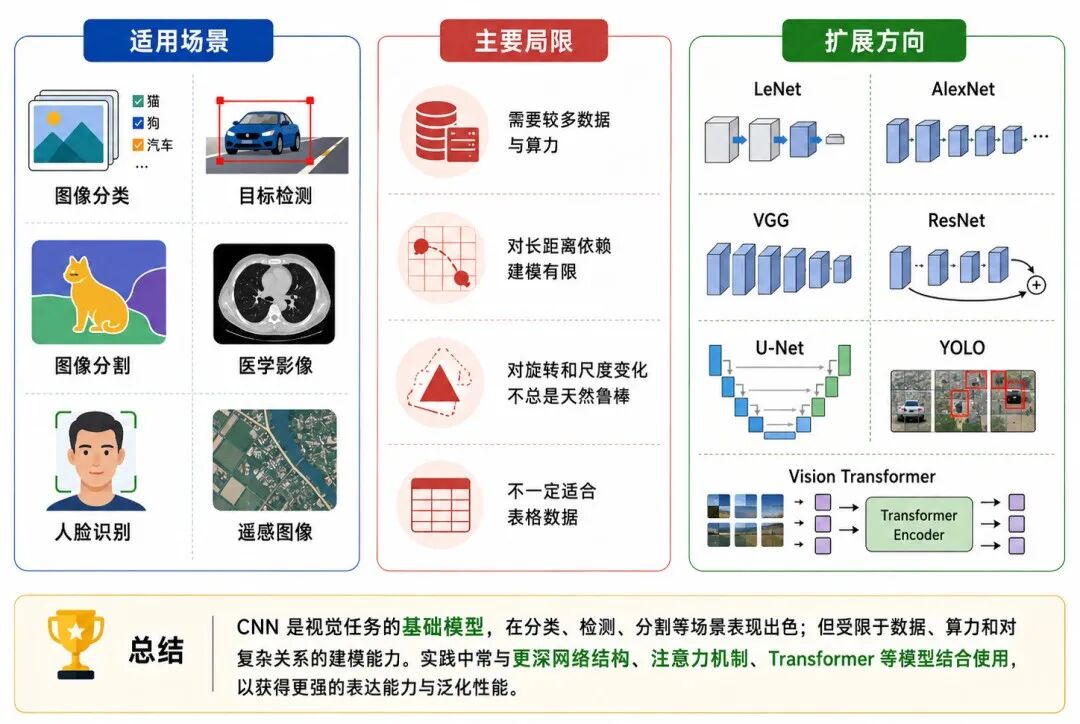
图 8:CNN 的适用场景、局限与扩展方向
1、适用场景
CNN 常用于图像和视觉相关任务,例如:
• 图像分类
• 目标检测
• 图像分割
• 人脸识别
• 医学影像分析
• 遥感图像分析
• 视频理解中的局部空间特征提取
在这些任务中,局部结构和空间模式通常很重要,因此 CNN 具有天然优势。
2、主要优势
CNN 的主要优势包括:
• 能保留图像空间结构
• 参数量相对全连接网络更少
• 能自动学习局部特征
• 对局部平移具有一定鲁棒性
• 能逐层形成从低级到高级的视觉表示
• 适合作为复杂视觉模型的基础模块
其中,局部连接和权重共享是 CNN 高效处理图像的重要原因。
3、主要局限
CNN 也有一些局限:
• 对大规模数据和算力有一定需求
• 深层 CNN 训练时需要合理初始化、归一化和优化策略
• 对长距离依赖关系的建模能力有限
• 对图像外的结构化表格数据未必优于传统方法
• 对旋转、尺度变化等复杂变换仍可能需要数据增强或特殊结构
在一些现代视觉任务中,CNN 常与注意力机制、Transformer 或多尺度结构结合,以提升特征表达能力。
4、扩展方向
从基础 CNN 出发,可以继续学习以下模型和技术:
• LeNet:早期经典 CNN
• AlexNet:推动深度 CNN 发展的代表模型
• VGG:使用小卷积核堆叠深层网络
• ResNet:通过残差连接缓解深层网络训练困难
• U-Net:常用于医学图像分割
• YOLO:常用于目标检测
• Vision Transformer:将 Transformer 引入视觉任务
这些模型虽然结构更复杂,但都可以从卷积、特征图、下采样、非线性激活和端到端训练等基础思想出发理解。
📘 小结
卷积神经网络通过卷积核、局部连接、权重共享和池化等机制,更有效地处理图像中的空间结构。它能够逐层学习从边缘、纹理到形状和类别语义的视觉特征,是计算机视觉中的基础模型。理解 CNN,有助于继续学习 ResNet、U-Net、YOLO 和 Vision Transformer 等更复杂的视觉模型。

"点赞有美意,赞赏是鼓励"