背景
先说个扎心的事实:你每天有多少时间是在做 "有创造力" 的工作,又有多少时间是在做 "复制粘贴" 式的流水线操作?
就拿我自己来说,最近在验证 xx 虚机需求,需要做一些重复性并且很耗时间的事儿,步骤大概是这样:
- 通过全网先找到能匹配创建虚机条件的物理机
- 找到物理机之后,打开运维管理平台网页搜索,填入参数,点击创建,等结果
- 每隔一段时间重复以上工作来反复验证
这些操作本身并不难,但它们有 3 个共同特点:重复、机械、吃时间。
更要命的是,这类工作根本没法"拒绝"😂,因为就是我负责的。一天下来,真正动脑子的事情没干几件,大部分时间都在当"人肉 API"。
那有没有一种可能,把这些流水线操作"教"给 AI,让它帮我干?
我负责思考和决策,它负责跑腿和执行。在飞书群里 @它一句话,它就帮我搞定。
这就是今天要聊的事,通过自定义 Skills,让 AI Agent 成为你的工作替身。
我最初本来想尝试 OpenClaw(小龙虾) 这个开源项目,它功能很全,但对我来说有几个问题:项目体量太大、代码改起来不方便,也不利于我去学习它,而且我对 TypeScript 不太熟悉。后来我参考了它的 Python 精简版 nanobot 的设计思路,用 Go 重新写了一个轻量版本,取名叫「皮皮虾」(PP-Claw)。它具备对话、记忆、技能、MCP、工具调用等基础能力,但真正让它变得"能干活"的,是 Skills 机制 一套让你把领域知识和操作流程"喂"给 AI 的标准化方案。
方案(自定义 Skills)
什么是 Skills
打个比方,你买了一台扫地机器人,它本身就会扫地、避障、回充。但它不知道你家的情况:哪个房间每天扫、哪个房间一周扫一次、阳台不用去、猫窝附近要绕开。你需要在 App 里画个地图、设好规则,它才能按你的需求干活。
Skills 就是你给 AI 画的那张"地图 + 规则"。
它不是代码,不需要你懂编程。它是一个 Markdown 文件,用写文档的方式,把某个操作流程描述清楚,调哪个接口、参数怎么填、结果怎么处理。AI 读了这个文件后,就具备了执行这项工作的"领域知识"。
一个 Skill 的结构其实很简单:
bash
vm-create-pro/
├── SKILL.md # 操作手册(唯一必须的文件)
├── scripts/ # 可选:脚本文件
├── references/ # 可选:参考资料
└── assets/ # 可选:模板、素材等核心就是那个 SKILL.md。
一个真实例子:虚机批量创建
来看一个实际在用的 Skill vm-create-pro,它解决的问题是"在宿主机上批量创建 KVM 虚机",不再需要手动点击和填写配置参数。
还记得前面提到的那套流水线操作吗?有了 Skill 之后,画风完全变了:
-
在飞书群里 @皮皮虾:"帮我找从这些设备列表中,找到能创建虚机的物理机,然后写入表格发给我"
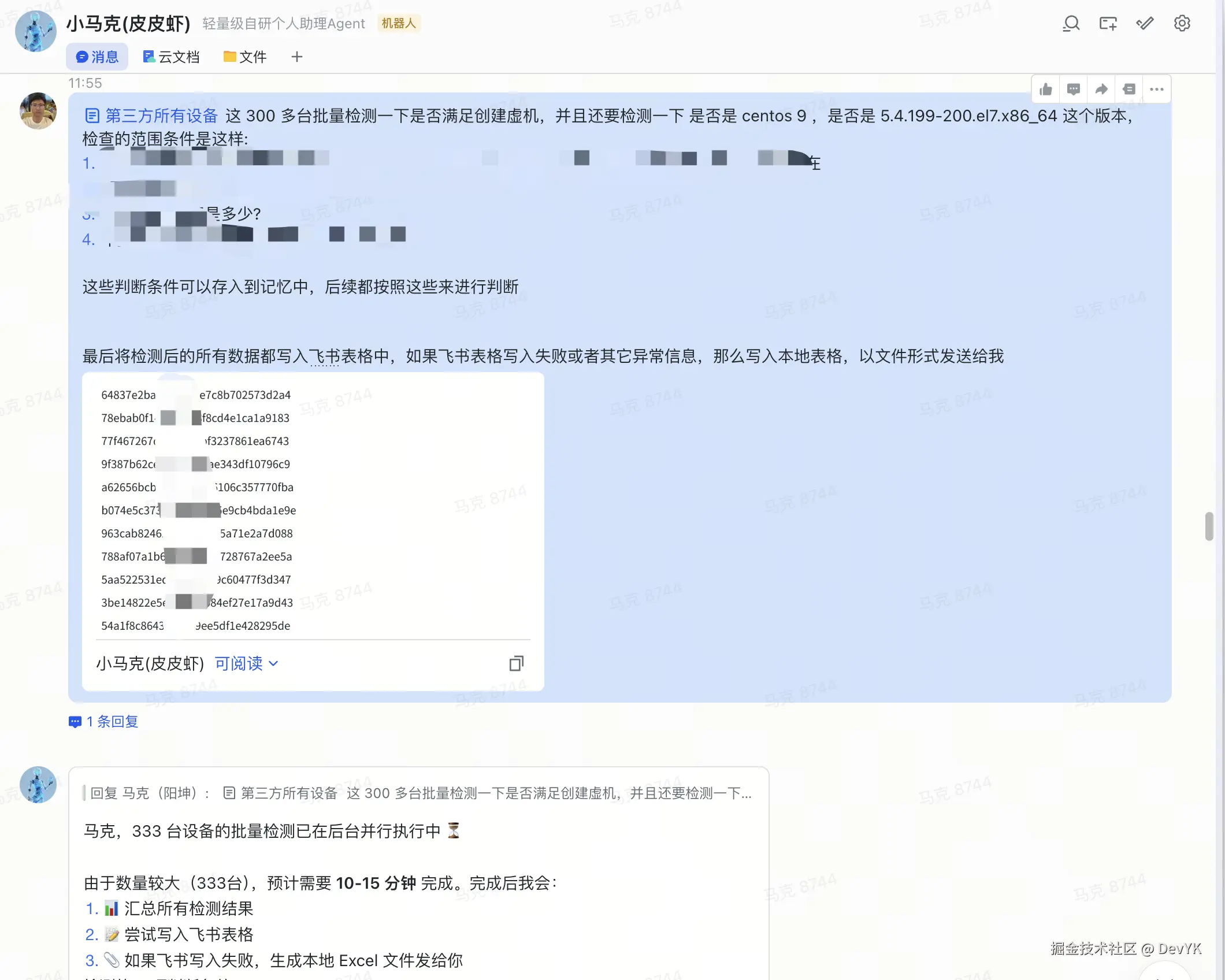
飞书群聊查找可用物理机
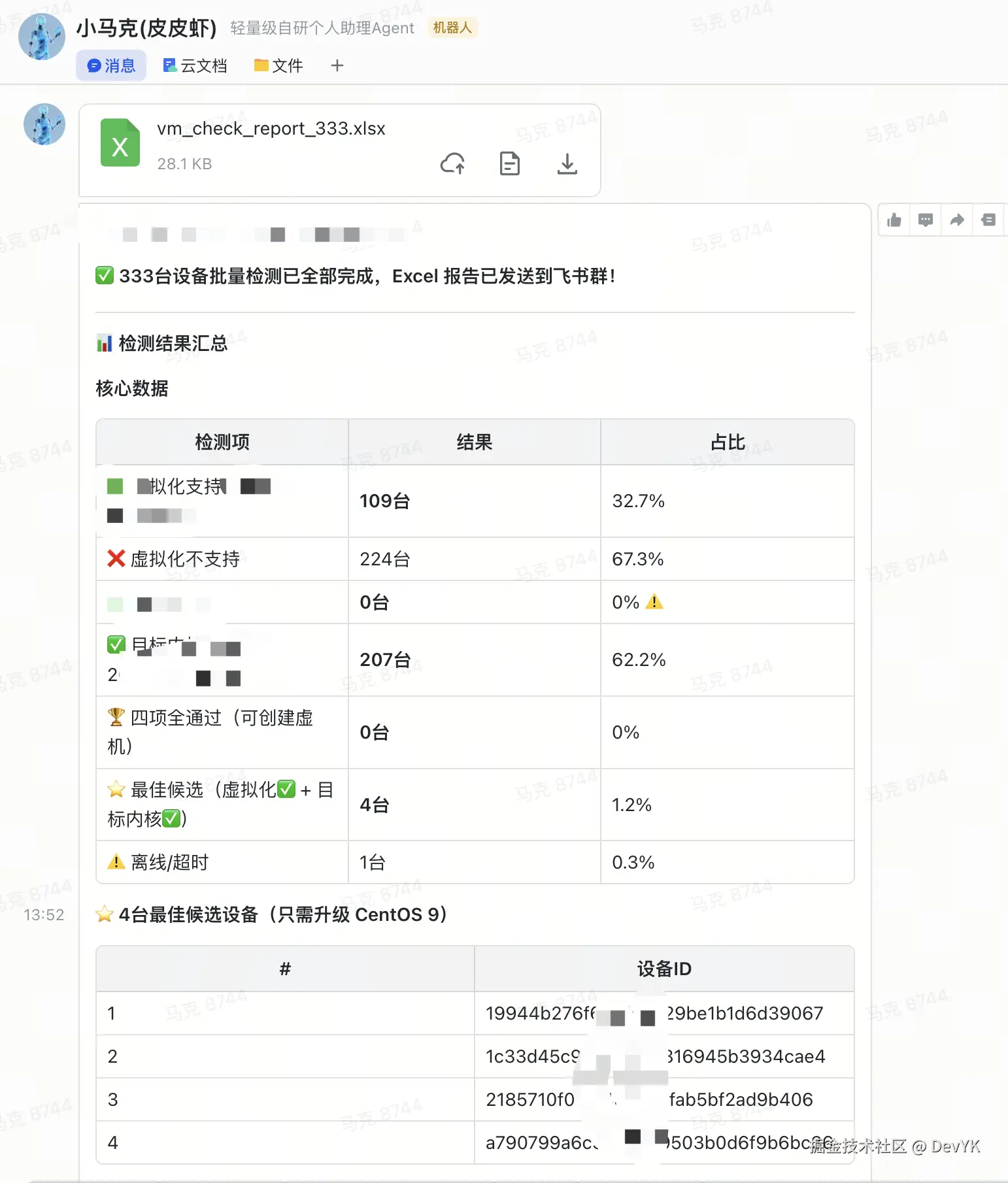
物理机查询结果表格
-
再次 @小马克(皮皮虾) 机器人,帮我批量创建虚机
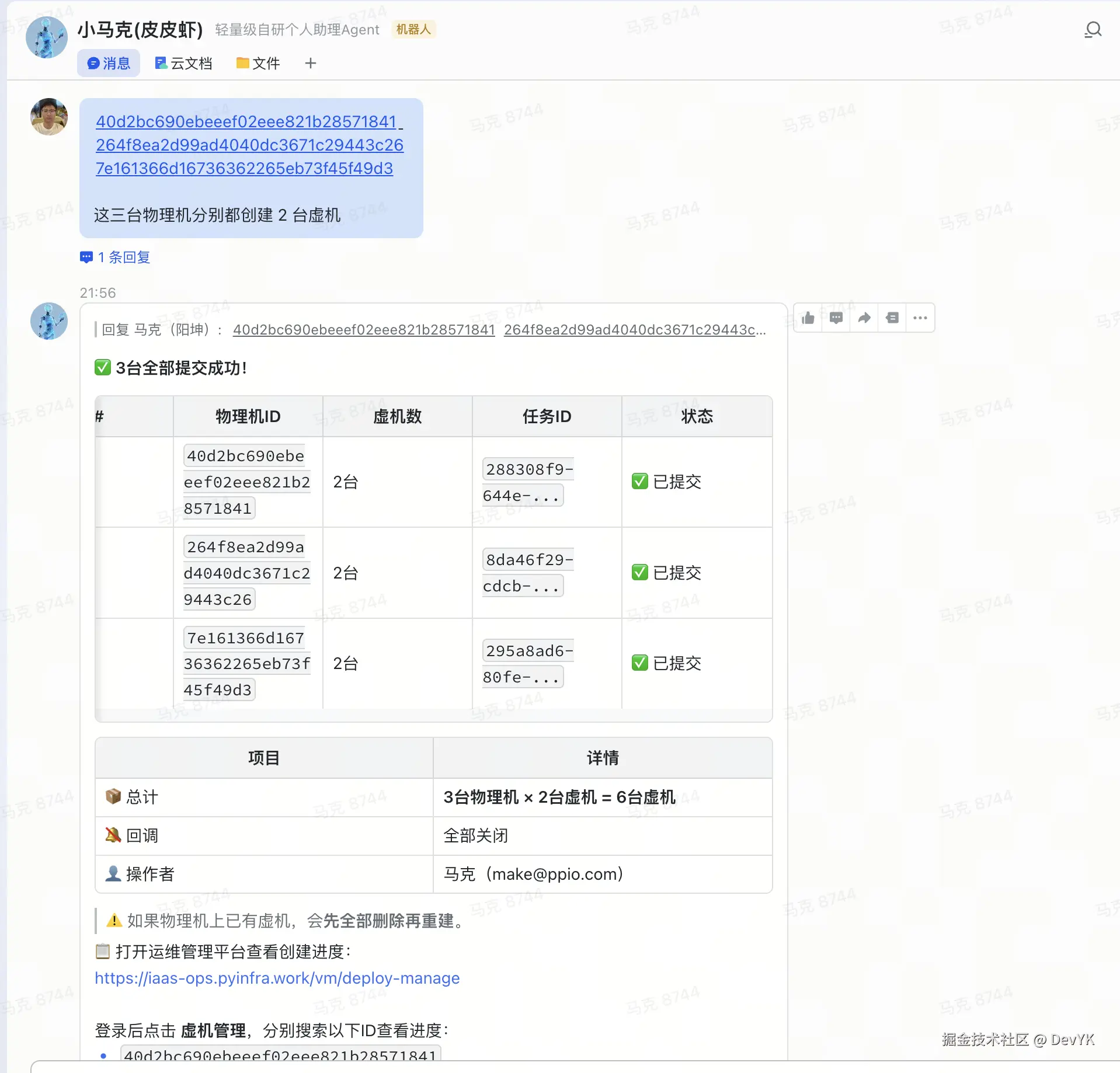
飞书群聊批量创建虚机
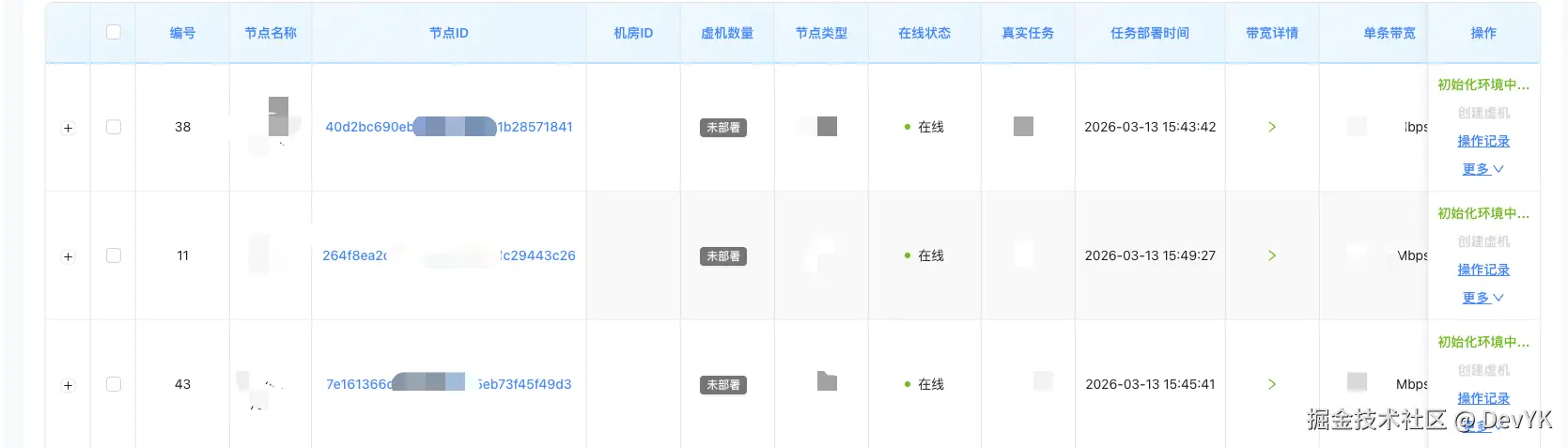
虚机创建结果反馈
如果再配合定时任务轮询检测,你甚至完全不需要在场,有一个手机就够了。
这就是 Skills 的魔力,它把"人的经验"变成了"AI 的能力"。
SKILL.md 长什么样
打开 vm-create-pro/SKILL.md,你会看到这样的结构:
yaml
---
name: vm-create-pro
description: 自动批量创建 KVM 虚机(VmCreatePro)。支持自定义回调 URL 和回调禁用开关。
当用户需要批量创建虚机、重置虚机、或触发 KVM 自动创建流程时使用本 skill。
---
# 虚机自动批量创建(VmCreatePro)
## 接口
**POST** `https://xxx.xxx.xxx/vmmanager/api/v1/vm_create_pro`
异步任务接口:提交后立即返回 request_id,后台按序完成:
**环境初始化 → 磁盘检测/自动分区 → 批量创建虚机 → 回调通知**
## 第一步:获取操作者信息
调用前需通过飞书 feishu-common 相关 skill 将触发本次操作的用户 open_id
反查为完整用户信息,再填入请求 Header...
## 第二步:请求参数
| 字段 | 类型 | 必填 | 说明 |
|------|------|------|------|
| machine_id | string | ✅ | 宿主机器 ID |
| gen_config.count | int | ✅ | 创建虚机数量,1~50 |
| gen_config.up_bandwidth_per_line | int | ❌ | 单条线路上行带宽(Mbps) |
## 请求示例
(完整的 HTTP 请求示例,包含 Header 和 Body)
## 注意事项
- 同一 machine_id 同时只能有一个进行中的任务
- 宿主机上已有虚机时会先全部删除再重建(reset 流程)
- count 范围:1 ≤ count ≤ 50看出来了吗?这就是一篇写给 AI 看的操作文档。它告诉 AI:
- 什么时候用(description 里写清楚触发条件)
- 怎么用(接口地址、参数、Header、注意事项)
- 操作顺序(先获取用户信息,再发请求)
你不需要写任何代码,只需要把脑子里"怎么做这件事"的知识,用 Markdown 写下来。
写好之后,直接把压缩包发给 Agent,让它自动安装:
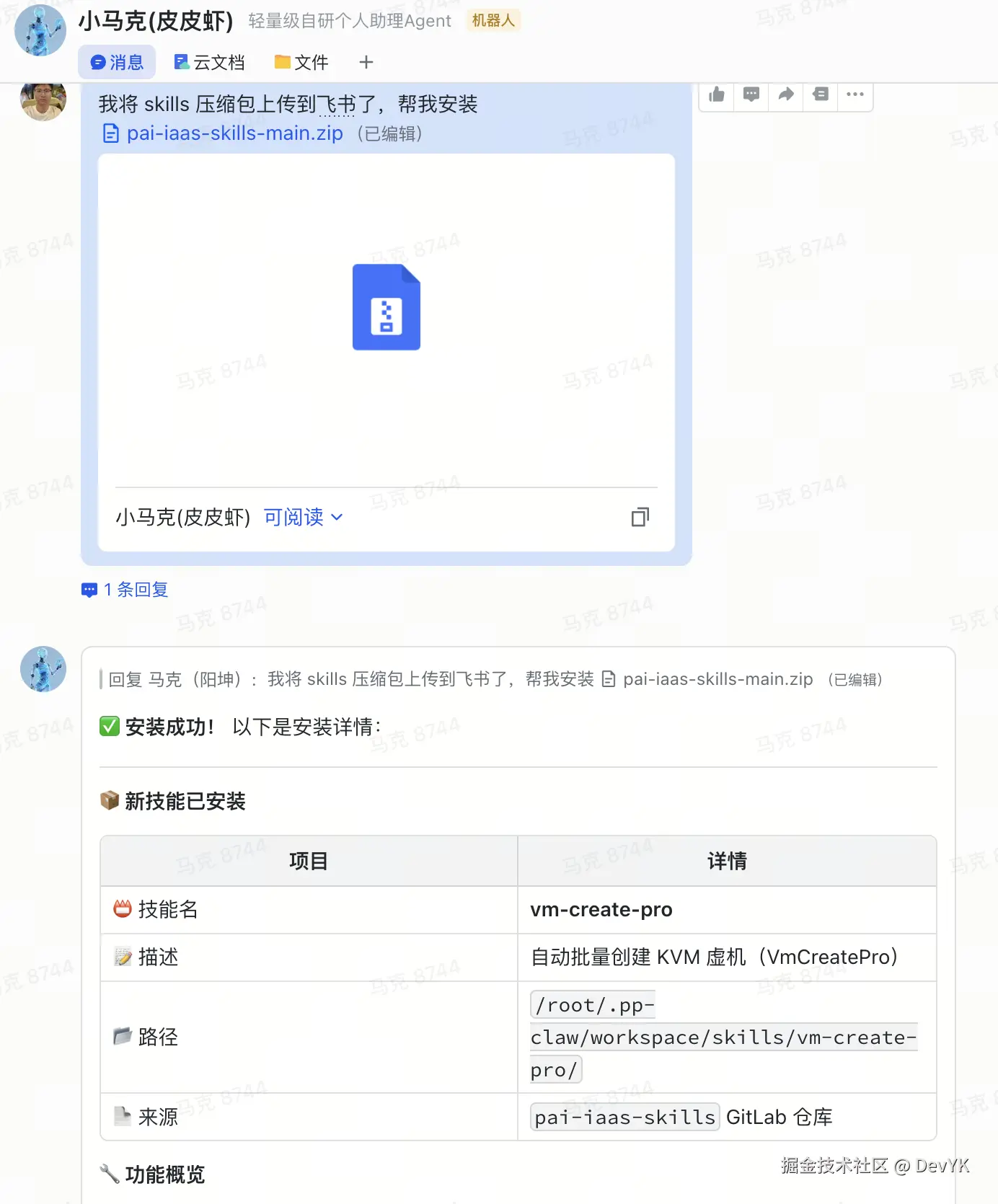
Skill 安装演示
原理
你可能会好奇:一个 Markdown 文件放在那里,AI 是怎么"学会"用它的?
这是整套机制最精妙的部分,我们一层一层来看。
三级加载机制
Skills 并不是一股脑全塞进 AI 的脑子里。想想看,如果你有 20 个 Skill,每个几千字,全部加载进去,AI 的上下文窗口(可以理解为"工作记忆")就被塞满了,反而什么都做不好。
所以我设计了一套渐进式加载机制,像洋葱一样分三层:
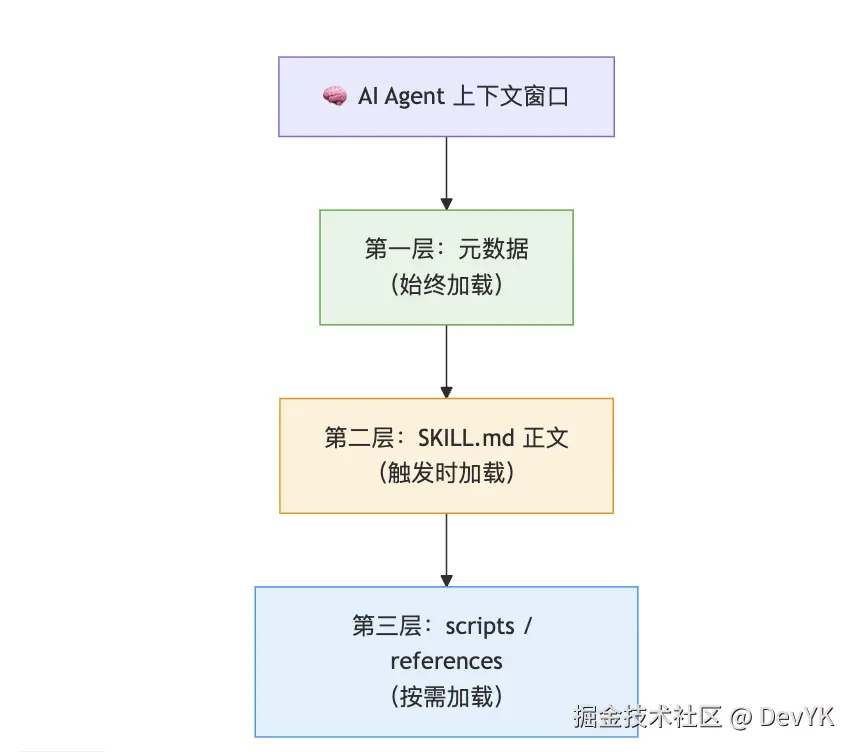
三级加载机制示意图
第一层:元数据(始终在场)
每个 Skill 的 name 和 description 会始终存在于 AI 的上下文中,大概就几十个字。AI 随时知道"我手上有哪些技能可以用"。
第二层:SKILL.md 正文(触发时加载)
只有当 AI 判断"这个问题需要用到 vm-create-pro 这个技能"时,才会把 SKILL.md 的完整内容读进来。这一步就像你翻开了操作手册。
第三层:脚本和参考资料(按需加载)
如果 SKILL.md 里引用了脚本或参考文档(比如 scripts/deploy.sh 或 references/schema.md),AI 会在需要的时候再去读取它们。
这套设计的好处是------20 个 Skill 和 1 个 Skill 对 AI 的负担几乎一样,因为绝大多数时候只加载了第一层的元数据。
完整工作流
当你在飞书群里 @皮皮虾说"帮我在 abc123 上开 2 台虚机",背后发生了什么?
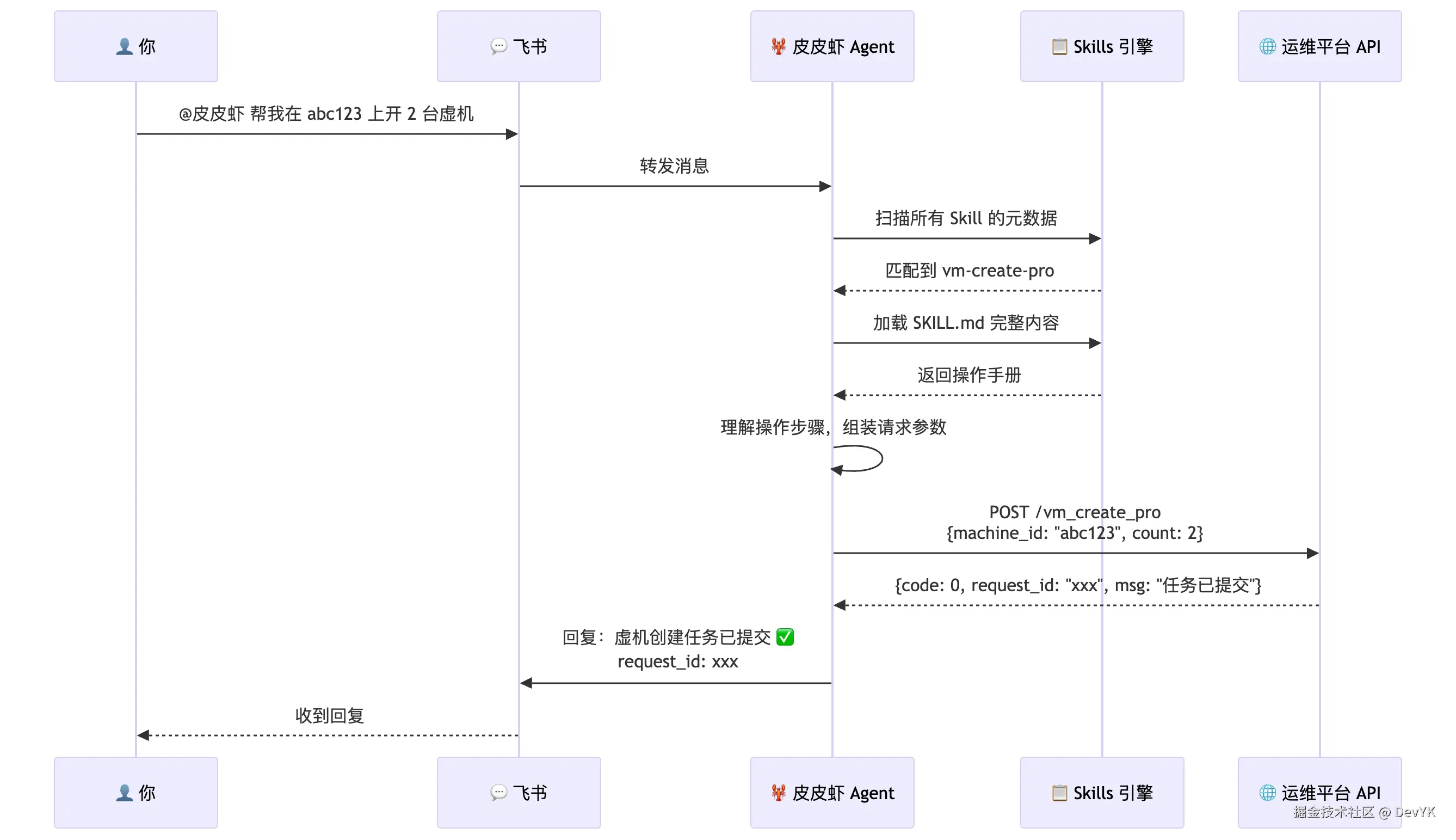
完整工作流时序图
拆解一下关键步骤:
- 消息接收:飞书渠道收到 @机器人 的消息,转给 Agent
- Skill 匹配 :Agent 扫描所有已注册 Skill 的
description,判断"批量创建虚机"匹配vm-create-pro - 知识加载 :读取
vm-create-pro/SKILL.md,获得完整操作指南 - 理解与执行:AI 根据操作手册,知道要先获取用户信息、再拼接参数、最后调用 API
- 结果回复:把 API 返回的结果格式化后回复到群里
整个过程中不需要写一行代码,只需要把操作文档写好,AI 就知道怎么干活了。
Skills 引擎在项目中的位置
从项目架构的角度看,Skills 引擎是这样嵌入到整个系统中的:
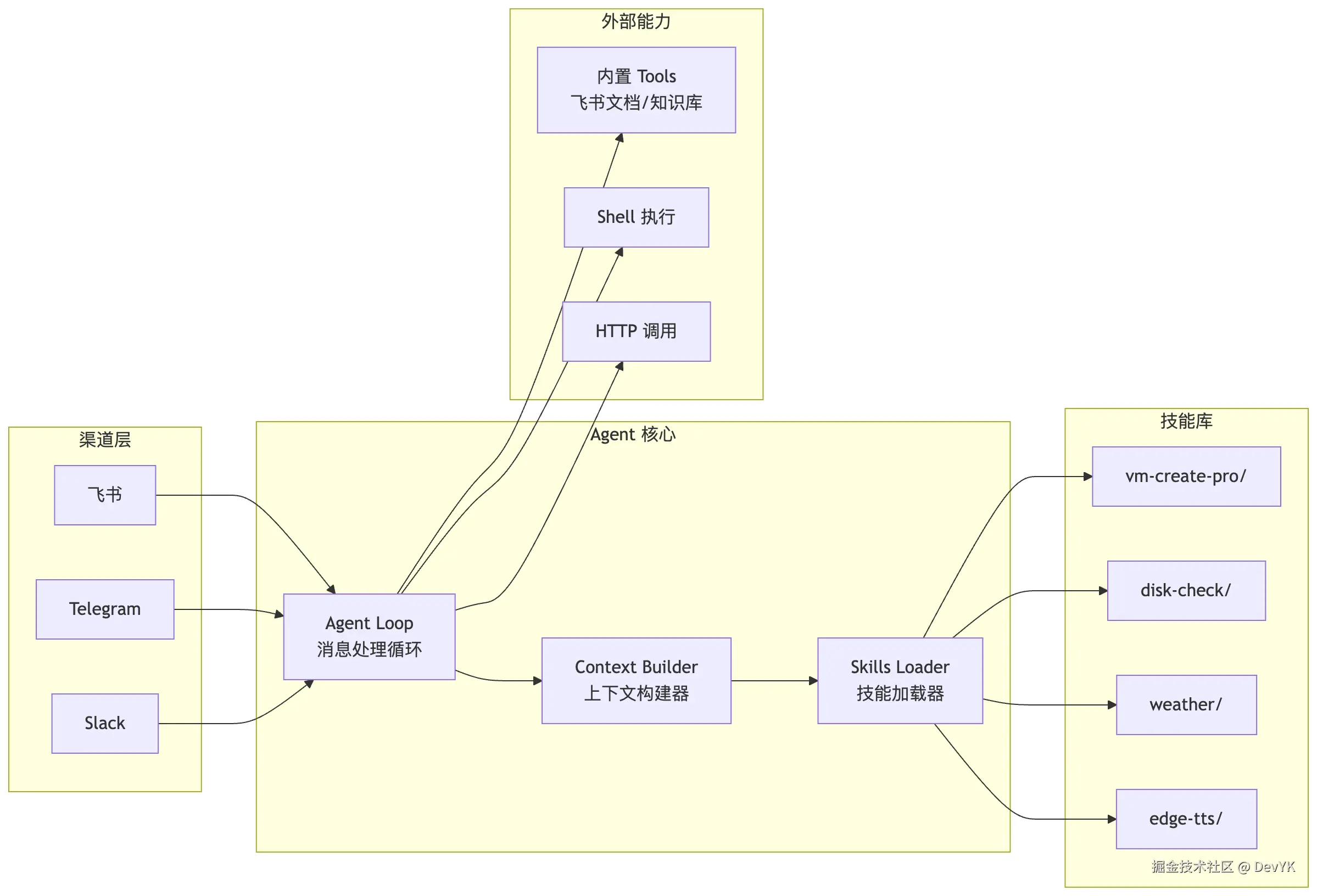
Skills 引擎架构图
Skills Loader 在系统启动时扫描技能目录,收集所有 Skill 的元数据。Context Builder 在构建系统提示词时,把这些元数据注入 AI 的上下文。当 AI 需要某个 Skill 时,通过文件读取工具加载完整内容。
Skills vs Tools:什么时候该用哪个
你可能注意到皮皮虾项目里还有 Tools(工具)的概念,比如 feishu_wiki、feishu_knowledge 这些。它们和 Skills 有什么区别?
| Skills | Tools | |
|---|---|---|
| 本质 | Markdown 文档(操作手册) | Go 代码(程序模块) |
| 编写门槛 | 会写文档就行 | 需要写代码 |
| 能力 | 指导 AI "怎么做" | 给 AI 提供"能做什么" |
| 类比 | 扫地机器人的清扫规则 | 扫地机器人的传感器和轮子 |
| 适合场景 | API 调用流程、排查手册、操作规范 | 需要精确控制的底层能力 |
简单说:Tools 是手,Skills 是脑子。Tools 提供原子能力(发 HTTP 请求、读文件、查数据库),Skills 告诉 AI 怎么组合使用这些能力来完成一件具体的事。
大多数情况下,你只需要写 Skills 就够了。只有当你需要一个 AI 本身不具备的底层能力时(比如调飞书 API、操作知识库),才需要开发 Tool。
如何使用皮皮虾
讲了这么多原理,来点实操。
第一步:部署皮皮虾
皮皮虾(PP-Claw)是开源项目,支持二进制直接部署和 Docker 一键部署。
bash
# 克隆项目
git clone https://github.com/yangkun19921001/PP-Claw.git
cd PP-Claw
export OPENAI_API_KEY=xxx
export OPENAI_BASE_URL=xxx
export MODEL=pa/claude-opus-4-6
export FEISHU_APP_ID=xxx
export FEISHU_APP_SECRET=xxx
# 配置文件
cp pp-claw.yaml.example ~/.pp-claw/pp-claw.yaml
# 启动
docker compose up -d第二步:编写你的第一个 Skill
假设你每天要做一件事:查询某台设备的基本信息。以前你需要打开平台,输入设备 ID,看结果。现在我们来把这个操作变成一个 Skill。
在项目的 skills/ 目录下创建:
objectivec
skills/
└── device-info/
└── SKILL.mdSKILL.md 的内容:
yaml
---
name: device-info
description: 查询设备基本信息。当用户问"查一下 xxx 设备的信息"、
"xxx 设备状态"、"设备详情"时使用本 skill。
---
# 设备信息查询
## 接口
**GET** `https://your-platform.com/api/v1/device/{device_id}`
## 使用方式
1. 从用户消息中提取设备 ID(通常是一串字母数字组合)
2. 调用上述接口
3. 将返回的 JSON 数据整理成易读的表格回复给用户
## 响应字段说明
| 字段 | 说明 |
|------|------|
| name | 设备名称 |
| status | 运行状态(online/offline) |
| ip | IP 地址 |
| region | 所在区域 |
| created_at | 创建时间 |
## 回复格式
用 Markdown 表格展示设备信息,重点标注状态。就这么简单。保存后重启皮皮虾(或者等它自动热加载),你就可以在飞书群里说:
@皮皮虾 帮我查一下 abc123 的设备信息
它会自动匹配到 device-info 这个 Skill,按照你写的步骤执行查询并回复。
第三步:编写复杂 Skill(以 vm-create-pro 为例)
对于更复杂的场景,SKILL.md 需要写得更详细。回到我们前面看到的虚机创建 Skill:
1. description 要写清楚触发条件
makefile
description: 自动批量创建 KVM 虚机(VmCreatePro)。
当用户需要批量创建虚机、重置虚机、或触发 KVM 自动创建流程时使用本 skill。这段话决定了 AI 什么时候会"想起"用这个 Skill。写得越精准,误触发越少。
2. 分步骤描述操作流程
先获取用户信息(第一步),再拼请求参数(第二步),这个顺序很重要。AI 会按你写的顺序来执行。
3. 提供请求示例
不要只写参数说明,一定要给一个完整的请求示例。对 AI 来说,一个例子顶一万字的说明。
4. 写清楚边界条件和注意事项
"同一 machine_id 同时只能有一个进行中的任务"------这类信息非常关键。如果不写,AI 可能会在并发场景下犯错。
第四步:迭代优化与最佳实践
Skill 不是写完就不管了。你会在实际使用中发现问题,然后持续改进:
- "它好像没理解我的意思"------可能是 description 写得不够精准,需要补充触发词
- "参数填错了"------可能是请求示例不够清晰,需要加注释
- "结果回复太乱了"------可能需要加一段"回复格式"的说明
这就像调整扫地机器人的清扫规则一样------根据实际效果不断优化。好在改一个 Markdown 文件的成本几乎为零。
根据我实际踩坑的经验,再总结几条编写建议:
- description 是灵魂:它决定 AI 能不能正确匹配到你的 Skill。多写几个同义词,覆盖用户可能的表述方式
- 给例子比讲道理有用:请求示例、响应示例、回复格式示例------AI 从例子中学习的效率远超纯文字描述
- 不要面面俱到:只写 AI 完成这项工作"必须知道"的信息。不需要的背景知识会浪费上下文空间
- 大文件拆出去 :如果 Skill 需要大量参考资料(比如 API 全量文档),放到
references/目录下,SKILL.md 里只写索引 - 一个 Skill 做一件事:不要把"查设备"和"建虚机"混在一个 Skill 里。拆开写,各司其职
总结
说到底,Skills 这套东西解决的是一个很朴素的问题:怎么把你脑子里的经验,低成本地复制给 AI。
它不需要你学新的编程语言,不需要你理解深度学习,甚至不需要你有任何 AI 背景。你只需要做一件事------把你干活的步骤,用 Markdown 写下来。
这听起来有点不可思议,但事实就是这样。当你的操作手册足够清晰,AI 就能替你干活。你把一天重复 10 次的操作变成一个 Skill,一年就省下几千次手动操作。
而且这件事有一个很棒的正向循环:

正向循环示意图
你把流水线工作交给 AI → 你腾出时间做更有创造力的事 → 你在新的工作中又发现了流水线环节 → 继续抽象成 Skill。
这不是要取代你,而是让你从"人肉 API"变回"思考者"。
最后一句话送给每一个还在做流水线工作的同学:
如果一件事你已经做了第三遍,就该想想怎么让 AI 帮你做第四遍了。
项目地址 :PP-Claw (皮皮虾)