High-Precision Dichotomous Image Segmentation via Depth Integrity-Prior and Fine-Grained Patch Strategy
基于深度完整性先验与细粒度补丁策略的高精度二值图像分割
DIS:二值图像分割,将图像像素级划分为前景目标 与背景两类
通过单目深度估计得到的伪深度图中蕴含的深度完整性规律作为先验指导
结合8×8 细粒度图像分块(补丁)的特征提取策略
单目深度估计模型(DAM-v2)生成的伪深度图:
- 伪深度图:从单张 RGB 彩色图像中推断出的场景深度信息图,每个像素值代表该位置的 "深度"(离拍摄镜头的远近),无需真实的深度传感器,易获取、成本低;
- 深度完整性规律 :前景目标区域的深度值具有极强的稳定性(方差极小),而背景区域的深度值是混沌、杂乱的(方差大)
为这一先验设计了深度完整性先验损失函数,通过两个约束让模型学习这一规律:
- 深度稳定性约束:惩罚深度值与前景平均深度偏差大的误检、偏差小的漏检;
- 深度连续性约束:加重深度梯度突变处(物体边界)的分割错误惩罚,让分割边界与深度边界对齐。
细粒度补丁策略:
- 补丁(Patch) :将整幅高分辨率图像均匀划分为多个小图像块,让模型能聚焦每个小块的局部细节
- 细粒度:相比粗粒度分块,8×8 的分块更精细
- 自适应策略 :结合特征选择与提取模块(FSE) ,对包含目标边界的补丁进行加权增强,同时抑制非目标区域的补丁特征
摘要
高精度二值图像分割(DIS)任务旨在从高分辨率图像中提取细粒度的目标物体。现有方法面临着两难困境:非扩散类方法推理效率较高,但受限于语义表达能力薄弱、空间先验鲁棒性不足,易出现检测误判与漏检问题;扩散类方法依托强大的生成先验,分割精度表现优异,却存在计算成本过高的弊端。
为解决这一问题,本文发现由单目深度估计模型生成的伪深度信息,能够提供关键的语义理解依据,可快速区分目标物体与背景间的空间差异。受此现象启发,本文提出了一项全新的研究见解 ------ 深度完整性先验:在伪深度图中,前景目标区域的深度值始终保持稳定,其方差远低于背景区域杂乱无章的深度分布。
为充分利用该先验特征,本文设计了深度融合先验网络(PDFNet)。具体而言,该网络通过深度融合 RGB 视觉特征与伪深度特征,构建多模态交互建模机制,实现由深度信息引导的结构感知;同时提出一种全新的深度完整性先验损失函数,以此显式约束分割结果的深度一致性;此外,本文还设计了带有自适应补丁选择的细粒度感知增强模块,完成对目标边界敏感的细节优化。
值得关注的是,仅含 9400 万个参数的 PDFNet(参数量不足扩散类模型的 11%)取得了当前最优的分割性能,不仅超越了所有非扩散类方法,部分指标也优于扩散类方法。相关代码已开源,地址为:https://github.com/Tennine2077/PDFNet。
理解1
非扩散类方法推理效率较高,但受限于语义表达能力薄弱、空间先验鲁棒性不足,易出现检测误判与漏检问题
非扩散类方法:指除扩散模型外的传统图像分割算法,核心是 CNN、Transformer 等架构
跑的快、参数量小、实用性强,但存在两个致命的技术短板,最终导致分割结果容易出错:
- 语义表达能力薄弱:特征提取多依赖浅层视觉特征(颜色、纹理、边缘),缺乏对物体高层语义信息的理解,无法区分 "视觉相似但语义不同" 的区域
- "书架是需要提取的目标,沙发是背景" 的语义,会把沙发花纹误判为前景,或把书架纹理漏检为背景。
- 空间先验鲁棒性不足:
- "空间先验" 指模型对物体空间结构、位置关系的先验知识。例如:前景物体的空间轮廓是连续的、背景的空间分布是杂乱的
- "鲁棒性" 即稳定性,指在复杂场景下(如物体遮挡、背景纹理复杂、透明物体),模型仍能稳定利用空间先验做判断
- 模型 "抓不住" 物体的空间结构,难以平衡全局结构 和局部细节 ,同时,在复杂场景下(如透明玻璃、物体遮挡、颜色相似的前景和背景),这类模型原本就薄弱的空间先验知识会完全失效,无法稳定区分前景和背景
理解2
本文发现由单目深度估计模型生成的伪深度信息,能够提供关键的语义理解依据,可快速区分目标物体与背景间的空间差异。
单目深度估计模型 :仅通过单张 RGB 彩色图像(无需双目相机、激光雷达等深度传感器),就能推断出图像中每个像素 "离拍摄镜头远近" 的模型(本文用的是 DAM-v2)
伪深度信息 / 伪深度图 :由单目深度估计模型生成的深度分布图像,并非真实的物理深度数据,因此叫 "伪深度";伪深度图中每个像素的数值代表该位置的深度值,数值越接近,代表空间位置越相近
深度完整性先验:在伪深度图中,前景目标区域的深度值始终保持稳定,其方差远低于背景区域杂乱无章的深度分布。
例如:一张照片中,桌面摆件 作为前景目标,其整体的深度值几乎一致(都在镜头前的同一空间位置);而墙面、地面、窗外景色等背景区域,不同位置的深度值差异极大(墙面近、窗外远,地面有高低差)
理解3
本文设计了深度融合先验网络(PDFNet)。具体而言,该网络通过深度融合 RGB 视觉特征与伪深度特征,构建多模态交互建模机制,实现由深度信息引导的结构感知;同时提出一种全新的深度完整性先验损失函数,以此显式约束分割结果的深度一致性
RGB 视觉特征与伪深度特征:视觉 + 空间
多模态交互建模:"模态" 指 RGB 视觉、伪深度两种不同类型的特征;"交互建模" 是让这两种特征在模型中相互交流、相互引导,而非各自独立计算
跨模态注意力(CoA) 和特征选择与提取(FSE) 模块实现这种交互
深度融合:在模型的多阶段特征提取、细化解码过程中,进行全流程的深度融合
显式约束:区别于传统模型 "隐式学习" 特征关联,PDFNet 直接把****"分割结果要符合深度完整性规律"****写进损失函数;模型训练时,若分割结果的深度一致性差(比如前景深度杂乱、边界与深度梯度错位),损失值就会大幅升高,模型会被迫调整参数,直到分割结果贴合深度信息的规律。
引言
高精度二值图像分割(DIS)(Qin 等人,2022)是一项关键的计算机视觉任务,旨在从高分辨率(HR)图像中以像素级精度勾勒出前景目标。对于图像编辑(Goferman 等人,2011)、增强现实(Tian 等人,2022;Qin 等人,2021)等众多要求高保真人机交互的实际应用而言,实现如此精细化的分割变得愈发重要。尽管数字成像技术的发展让高分辨率图像的获取变得轻而易举,但要将这些丰富的视觉细节转化为准确的分割掩码,依旧极具挑战性,在复杂场景下更是如此。
二值图像分割的研究主要遵循两大技术路线:非扩散范式与扩散范式。与扩散类方法相比,非扩散类方法(如卷积神经网络(Qin 等人,2022;Pei 等人,2023;Zhou 等人,2023)和 Transformer 架构(Kim 等人,2022;Zheng 等人,2024a;Yu 等人,2024a))通常具备轻量化(参数量大于 1000 万且小于 3 亿)和推理速度更快(每秒帧数大于 3)的优势。然而,这类方法在处理高分辨率图像时面临一个根本性瓶颈:当扩大感受野以捕捉全局结构时,对精细细节的建模能力会随之减弱;反之,当缩小感受野以保留局部细节时,对全局结构的建模效果又不尽如人意(Yu 等人,2024a)。最终,受限于这一瓶颈,模型的语义表达能力薄弱、空间先验缺乏鲁棒性,导致分割结果频繁出现误检和漏检问题。
扩散类方法(Xu 等人,2025;Yu 等人,2025)将超大规模的预训练扩散模型作为骨干网络,并通过后训练利用数十亿图像数据中的先验信息。这类方法能显著提升复杂场景下分割结果的一致性,但代价是参数量庞大(超过 8.65 亿)且推理速度极慢(每秒帧数小于 1),这一特性使其无法应用于实际场景。
为突破这一困境,我们需要一种适配该任务的先验信息,且需满足三大核心标准:易获取性(能从现有成熟模型中低成本推导得到)、高性能(参数量少且推理速度快)、强指导性(能清晰区分目标物体与背景)。我们发现,由深度任意模型 V2(DAM-v2)(Yang 等人,2024b)生成的伪深度图中,天然蕴含着一种深度完整性先验:分割目标区域的深度方差显著低于背景区域的深度方差(图 1 ),这为二值图像分割任务提供了强有力的指导。同时,DAM-v2 生成的伪深度图也满足易获取(可通过现成的 DAM-v2 直接得到)和高性能(基础版 DAM-v2 的推理速度每秒帧数大于 10)的特性。受这一先验信息的启发,我们提出了深度融合先验网络(PDFNet)(图 2d)。该网络架构通过融入深度完整性先验信息,专门针对高分辨率细粒度目标分割任务做了优化。为此,我们引入伪深度图构建多模态交互建模机制,并借助跨模态注意力实现由深度信息引导的结构感知;同时提出一种全新的深度完整性先验损失函数,通过约束目标区域对应伪深度图的均值,提升分割结果的深度一致性。此外,我们对多视角聚合网络(MVANet)的多补丁输入策略做了改进,将补丁规模从 2×2 提升至 8×8,并设计了带有自适应补丁选择的细粒度感知增强模块,实现对边界敏感的细节优化。在 DIS-5K 数据集上,深度融合先验网络(PDFNet)的性能超越了所有非扩散类模型,且仅用扩散类模型 DiffDIS(Yu 等人,2025)不到 11% 的参数量,就达到了与其相当的性能,取得了当前最优的研究成果。
本文的主要贡献可总结如下:
- 创新性地提出深度完整性先验,有效减少了现有非扩散类方法的误检与漏检问题;
- 设计了全新的深度完整性先验损失函数,提升了分割结果在深度维度上的一致性;
- 构建了带有自适应补丁选择的细粒度感知模块,通过将补丁密度大幅提升至 8×8,在强化边界敏感细节优化的同时,有效抑制了非目标区域的特征干扰;
- 验证了非扩散范式的深度融合先验网络(PDFNet),仅需扩散类方法不到 11% 的计算成本,就能取得媲美甚至超越扩散类方法的当前最优性能。
图一
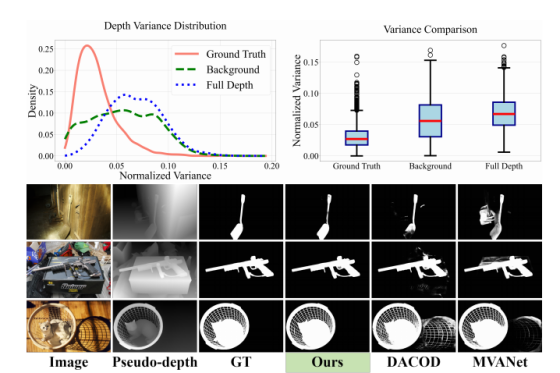
图 1:我们为 DIS-TR 数据集生成伪深度图,并分别计算了真实标注区域、背景区域以及整张图像的深度方差。结果表明,真实标注区域的深度方差显著更低。从视觉效果上看,本文所提方法的分割精度优于 RGB-D 模型 DACOD 和二值图像分割模型 MVANet。
DIS-TR(二值图像分割的训练数据集)
深度方差概率密度分布图:
- 横轴:归一化的深度方差;深度,指的是单目模型生成的伪深度图中,每个像素对应的深度数值(代表该像素在场景中的远近)。方差是统计学中衡量一组数据波动大小的指标。方差越小 ,说明这个区域里的深度值越稳定、越一致,几乎没有波动;方差越大,说明这个区域里的深度值忽高忽低,波动剧烈、分布混乱。归一化:把所有计算出的深度方差数值,通过数学变换缩放到了统一区间内。目的是消除不同图像、不同区域的数值尺度差异,让前景、背景、全图的方差分布,能放在同一个横轴上公平对比,统一了统计的量纲
- 纵轴:对应方差出现的密度(频次 / 概率);纵轴是概率密度,这里用的是核密度估计(KDE)的统计结果,区别于简单的计数频次。纵轴数值越高,代表「横轴对应的这个深度方差值,在对应区域里出现的概率越高、越普遍」;纵轴数值越低,代表这个方差值在对应区域里极少出现、非常罕见。
- 红色线(前景 GT 区域):峰值集中在横轴最左侧(极低方差区间),纵轴峰值最高,且快速衰减到 0。说明:前景目标的深度值,绝大多数都高度稳定、几乎没有波动,低方差是前景的核心特征。
- 绿色线(背景区域)、蓝色线(全图):峰值出现在横轴更靠右的位置,纵轴峰值更低,且分布更分散。说明:背景的深度值普遍波动更大、更混乱,高方差是背景的核心特征。
箱线图:统计可视化方式,量化对比了前景、背景、全图三类区域的深度方差分布差异
构成:
- 横轴:3 个统计类别,分别是Ground Truth(前景真实标注区域)、Background(背景区域)、Full Depth(整张图像)
- 纵轴:Normalized Variance,即归一化后的深度方差,数值越大,代表该区域内的深度值波动越大、分布越混乱
- 最下端的横线(下须) :排除异常值后的最小值 ,代表该类别深度方差的常规最低水平。箱子的下沿 :下四分位数(Q1) ,意味着该类别里 25% 的数据,方差都小于这个值。箱子中间的红线 :中位数(Q2) ,是数据的核心集中趋势指标 ------50% 的数据小于这个值,50% 的数据大于这个值。箱子的上沿 :上四分位数(Q3) ,意味着该类别里 75% 的数据,方差都小于这个值。箱子的高度 :四分位距(IQR) ,即 Q3-Q1,代表中间 50% 核心数据的波动范围;箱子越矮,数据越集中、稳定性越强。最上端的横线(上须) :排除异常值后的最大值 ,代表该类别深度方差的常规最高水平。上下须外的空心圆圈 :异常值,即偏离了常规分布的极端数据点
- 前景 GT 区域的中位数红线,仅在 0.03 左右;而背景、全图的中位数红线在 0.06 左右,几乎是前景的 2 倍。这直接量化证明:前景目标的深度值天生波动极小、高度一致,而背景的深度值普遍波动更大、更混乱。前景 GT 的箱子高度(四分位距)远小于背景和全图,上下须的长度也更短。说明绝大多数前景区域的深度方差,都集中在极低的区间,数据一致性极强;而背景和全图的方差波动范围极大,深度分布没有稳定规律。
Image:原始输入的高分辨率 RGB 图像,1024×1024 分辨率
Pseudo-depth:单目深度估计模型生成的伪深度图(论文的核心输入),仅用单张 2D RGB 图像,通过成熟的单目深度估计模型(论文用的是 SOTA 的 DAM-v2,Depth Anything Model v2),预测出的每个像素对应的「场景远近信息」。图中像素越亮,代表该位置离镜头越近;越暗代表离镜头越远。
GT:分割的真实标注(Ground Truth,白色为前景目标)
Ours:论文提出的 PDFNet 的分割结果,Prior of Depth Fusion Network(深度先验融合网络)
对比模型:
- DACOD:主流的 RGB-D 分割对比模型,2023 年提出的、深度辅助伪装目标检测(COD)领域的 SOTA 模型,和 PDFNet 一样,属于同时使用 RGB 图像 + 深度(Depth)信息的双模态分割模型。伪装目标检测:核心目标同样是做像素级二值分割,把和背景高度融合、「伪装隐藏」的前景目标(比如枯叶里的蝴蝶、草丛里的变色龙)从复杂背景中精准提取出来。它和 DIS 的核心诉求完全一致,只是目标的隐藏性更强、分割难度更高。深度辅助:哪怕伪装目标和背景的颜色、纹理高度相似,二者在场景中的远近(深度)也大概率存在差异,深度信息能给模型提供极强的前景 - 背景区分依据。SOTA:业内顶尖水平。
- MVANet:高精度二值分割(DIS)领域的 SOTA 对比模型,2024 年 CVPR 提出的、高精度二值图像分割领域的非扩散范式 SOTA 模型。MVANet 的核心创新是多视图 patch 输入架构,而 PDFNet 正是在它的基础上,完成了核心升级(把 2×2 patch 升级到 8×8、引入深度完整性先验、设计 FSE 模块等)。作者用它做对比,就是为了证明:PDFNet 在 DIS 任务上,全面超越了之前的非扩散范式 SOTA。
图二
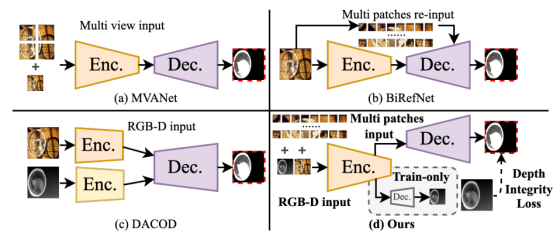
图 2 本文所提 PDFNet 网络与其他适用于二值图像分割(DIS)任务或 RGB-D 伪装目标检测(COD)任务的现有方法对比
(a) 多视角聚合网络(MVANet,Yu 等人,2024a):采用 4 个图像补丁结合原始图像作为多视角输入;
(b) 双边参考网络(BiRefNet,Zheng 等人,2024a):将原始图像输入编码器,并将原始图像的补丁重新输入解码器;
(c) 深度辅助伪装目标检测网络(DACOD,Wang 等人,2023):采用双模态联合学习模式;
(d) 本文方法:输入原始图像、深度图及多尺度图像补丁,加入深度完整性先验损失并设计深度细化分支。
注:Enc. = 编码器,Dec. = 解码器。
(编码器) :分割网络的 "特征提取器",负责把输入图像转换成深层语义特征;(解码器):分割网络的 "结果生成器",负责把编码器提取的特征,还原成最终的像素级分割掩码
(a) MVANet:DIS 领域非扩散范式:
- 核心设计 :Multi view input(多视图输入):把原始图像切成 2×2 的 4 个局部 patch,加上完整原始图像,组成多视图输入,一同送入编码器提取特征,再经解码器输出分割结果。
- 核心局限:仅使用 RGB 单模态信息,没有利用深度的空间结构先验;同时受限于 "全局感受野和局部细节无法兼顾" 的瓶颈
(b) BiRefNet:
- 核心设计 :Multi patches re-input(多 patch 重输入):先把完整原始图像送入编码器提取全局特征,再把原始图像切成多个 patch,重新送入解码器做局部细节增强。
- 核心局限:同样是 RGB 单模态模型,没有引入深度的结构引导;patch 仅在解码器侧补充输入,无法和全局特征做深度的协同优化
(c) DACOD:RGB-D 伪装目标检测:
- 核心设计 :RGB-D input(RGB + 深度双输入双编码器):用两个完全独立的编码器,分别处理 RGB 彩色图像和深度图,再把两路特征简单送入同一个解码器融合,最终输出分割结果。
- 核心局限:仅做了浅层的双模态特征拼接,没有挖掘深度数据中 "前景深度稳定、背景深度混乱" 的核心规律(即论文提出的深度完整性先验);同时没有结合多 patch 的细粒度细节增强,对前景边界和结构的约束不足。
(d) Ours(论文提出的 PDFNet):核心创新架构:
- 多模态 + 多 patch 的融合输入 :同时输入完整 RGB 图像、伪深度图(RGB-D 双模态)、8×8 的高密度多 patch,把双模态的全局结构信息、多 patch 的细粒度细节信息结合,而不是像前序模型要么只用单模态、要么只用多视图、要么双编码器简单融合。
- 共享编码器的跨模态交互:不用 DACOD 的双独立编码器,而是用共享编码器同时处理 RGB、深度、patch 三路特征,通过专门的跨模态注意力模块做深度的特征交互,实现 "深度引导的结构感知",而非简单的特征拼接。
- 训练专属的深度优化分支:虚线框内的Train-only Dec.(仅训练时启用的深度解码器),通过深度重构任务,引导编码器同时学习 "分割" 和 "深度估计" 的双重特征,强化模型对前景目标的结构感知能力。
- 核心创新的损失约束 :加入了前序所有模型都没有的Depth Integrity Loss(深度完整性先验损失),用 "前景深度稳定、背景深度混乱" 的统计规律,直接约束分割结果,从根源上减少误检、漏检
深度解码器(Train-only Dec.) ,只在训练阶段启用、参与模型的参数学习;一旦训练完成,推理部署时会直接把这个分支整个删掉,完全不占用计算资源、不增加推理耗时
完整的优化迭代逻辑:
- 深度解码器输出一张预测的深度图,和 DAM-v2 的高保真标准答案做对比,用 SILog 计算出损失值;
- 如果预测的深度图和标准答案差距很大,SILog 损失就会很高,模型就会收到反馈:「我提取的特征里,关于 3D 空间结构的信息太少、不准,必须调整」;
- 模型通过反向传播,更新共享编码器的权重参数,让编码器提取的特征里,包含更多、更精准的深度结构信息;
- 反复迭代这个过程,编码器慢慢就学会了:既要提取分割需要的颜色、纹理、边缘特征,也要提取深度估计需要的 3D 空间、结构完整性特征。
这个深度重构分支,通过「共享编码器 + 辅助深度任务」的设计,给编码器强行注入了 3D 空间结构先验
相关工作
高精度二值图像分割
高精度二值图像分割(High-Precision Dichotomous Image Segmentation, DIS)旨在从复杂场景中精准勾勒出精细复杂的目标,是一项极具挑战性的任务。早期方法为该任务奠定了基础基准(Qin et al. 2022)。后续的非扩散范式方法则通过多尺度细化(Pei et al. 2023; Kim et al. 2022)、辅助先验(Zhou et al. 2023)与多视角分析(Zheng et al. 2024a; Yu et al. 2024a)等技术路径,不断寻求性能提升。近年来,扩散模型逐渐兴起,这类方法借助大规模数据集学习到的强大生成先验,有效提升了分割质量(Xu et al. 2025; Yu et al. 2025)。
然而,这两类技术范式都存在着核心的性能权衡问题:传统方法难以平衡全局与局部特征线索,极易出现误检与漏检问题(Yu et al. 2024a);与之相反,扩散模型虽具备更高的分割精度,却带来了极高的计算开销,严重限制了其实际落地应用。我们提出的 PDFNet 网络,正是为了解决这一权衡难题。该框架引入了全新的深度完整性先验,对分割结果的结构一致性进行约束;该先验与自适应局部块融合策略相结合,实现了兼具高保真度与极高推理效率的图像分割。
单目深度估计
单目深度估计是计算机视觉领域的一项基础任务,其目标是从单张 RGB 图像中推断出场景的深度信息。早期的深度学习相关研究,率先利用自监督视差信号实现了该任务的端到端求解(Godard, Mac Aodha, and Brostow 2017)。而以深度万物模型(Depth Anything Model, DAM)为代表的大规模模型的出现,带来了该领域的范式革新:这类模型基于 Transformer 架构,通过海量数据预训练,大幅提升了深度估计的精度与全局一致性(Yang et al. 2024a)。
其后续迭代版本 DAM-v2 则通过知识蒸馏技术,解决了真实数据标注的瓶颈问题:先在合成数据上训练教师模型,再通过教师模型引导学生模型在带伪标签的真实图像上学习(Yang et al. 2024b)。DAM-v2 取得了业界顶尖的性能表现(例如在 DA-2K 数据集上准确率达 97.1%(Yang et al. 2024b)),已成为生成高可靠性伪深度图的业界事实标准。
自监督视差信号--->深度万物模型---> DAM-v2
单目深度估计:仅用单张 2D 彩色图片,推算出场景中每个像素的 3D 空间远近(深度)
自监督视差信号:
- 用无需人工标注的自监督视差信号,解决了深度估计任务 "真实深度标注成本极高、难以大规模获取" 的核心痛点;
- / 人工采集的真实深度标注数据
- 3D 物体在左、右两张图中的像素位置会产生偏移,这个偏移量就是视差 。视差和深度有严格的数学反比关系:视差越大,物体离镜头越近;视差越小,物体离镜头越远。只要算出精准的视差,就能直接换算出对应的深度值
- 让数据自己监督自己,完全无需人工标注:模型从左图预测出视差后,能用这个视差把左图完美映射、合成出对应的右图;合成效果越精准,就说明视差预测越准,对应的深度估计也就越准。
- 实现了端到端的全自动求解:输入单张 RGB 图,神经网络就能直接输出完整的像素级深度图,无需人工设计多阶段的处理流程
- RGB 图像)→ 神经网络自动完成所有特征学习、视差 / 深度计算 → 输出端(完整的像素级深度图)。整个过程无需人工设计中间步骤、无需人工干预特征提取,模型会自动学习从 RGB 图到深度图的映射关系,实现了从输入到输出的全自动、无人工干预的求解
DAM-v2 :
- 在合成数据上训练「教师模型」:
- :大规模计算机渲染的合成 3D 数据集。
- 3D 建模软件渲染虚拟场景时,每个像素的深度值是渲染引擎直接输出的,绝对精准、零成本、无噪声、无空洞,想要多少数据就能生成多少,完全没有标注成本。
- :在合成数据上,把教师模型训到极致精度,让它彻底学会「从 RGB 图像的纹理、光影、轮廓,还原 3D 场景深度几何规律」的核心能力,成为一个深度估计领域的 "专家"。
- :直接在合成数据上训的模型,放到真实图像上效果会极差,这就是「域偏移问题」------ 合成数据和真实图像的画风、光照、纹理分布不一样,模型泛化性极差,没法直接落地使用。这也是为什么不能直接用教师模型,必须通过蒸馏把能力迁移给学生模型。
- 知识蒸馏,用教师模型引导学生模型在真实图像上学习:「让已经学会核心能力的大模型(教师),把自己的知识 "教" 给小模型(学生)」,不用人工标注,只用教师模型的输出作为监督信号,就能让学生模型继承教师的能力,同时适配目标场景
- :把互联网上海量的、无任何标注的真实 RGB 图像,输入到已经训好的教师模型中;教师模型输出的深度预测结果,就作为这张真实图像的伪标签(Pseudo Label)------ 相当于老师给真实图片出了一套 "标准答案",虽然不是 100% 完美的真实采集 GT,但精度足够高,完全能当训练的监督信号。
- :用这些「真实 RGB 图 + 教师模型生成的伪深度标签」,训练学生模型。训练的核心目标,就是让学生模型输出的深度图,和教师模型给出的伪标签尽可能一致。
用于稠密预测任务的真实 / 伪深度图
深度感知方法通过真实深度或伪深度线索,对各类稠密预测任务进行性能增强。其中,基于真实深度的方法,将传感器采集的几何信息与 RGB 数据进行融合(Zhong et al. 2024; Hu et al. 2024; Wang et al. 2024, 2023);与之不同,基于伪深度的方法直接从 RGB 输入生成深度信息,已被证实能有效应用于实例分割(Yu et al. 2024b)、医学影像(Zheng et al. 2024b)等诸多领域(Schön, Ludwig, and Lienhart 2023; Sun et al. 2023)。
针对高精度二值图像分割任务,我们借助伪深度信息,提出了全新的深度完整性先验。我们在网络框架中设计了专用的多模态融合模块与专属损失函数,将该先验落地实现,以此增强分割结果的结构连贯性。
方法
在本节中,我们将详细介绍所提方法,包括如图 3 所示的整体架构与各核心组件。
整体架构
图三
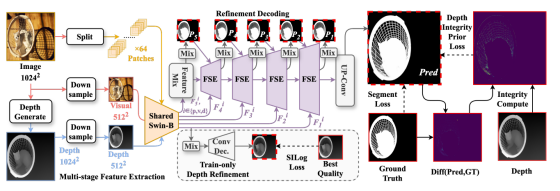
图 3 本文提出的 PDFNet 网络整体流程
深度生成
深度万物模型 v2(DAM-v2)在合成与真实图像构成的大规模混合数据集上完成训练,以保证高预测精度。该模型可将输入图像 I∈RB×3×H×W 映射为取值范围在 0, 1 内的归一化深度图 D∈RB×1×H×W。
在合成与真实图像构成的大规模混合数据集上完成训练:
- 合成数据 :计算机生成的图像,带有精确的、像素级完美的深度真值
- 真实数据:真实世界拍摄的照片
- 混合训练 :先让模型在合成数据上学习深度估计的基本能力,再通过知识蒸馏等技术在大量无标签的真实数据上进一步提升泛化能力
- 先让模型在合成数据上学习深度估计的基本能力:这个阶段训练出的模型,能够进行深度估计,但可能只在和合成数据相似的场景下表现好
- 再通过知识蒸馏等技术在大量无标签的真实数据上进一步提升泛化能力:知识蒸馏是一种模型压缩和知识迁移技术,教师模型 :就是我们在第一步训练好的那个模型。它虽然没有见过真实世界的数据,但它已经掌握了从图像中估计深度的"基础知识"。现在,我们让它去看海量的真实世界照片,并让它"猜"出每一张照片的深度图。这个"猜"出来的结果,就是一张伪深度图 。学生模型 :可以是一个新的、或者和教师模型结构相同的模型。它的学习目标有两个:学习真实数据本身 :它也要看那些真实照片;模仿教师的输出 :它的任务是,不仅要看真实照片,还要努力让自己估计出的深度图,尽可能接近"教师模型"为同一张照片生成的伪深度图。
- 对教师而言 :它用自己从合成数据中学到的"知识",为海量真实世界图像生成了"软标签"(伪深度图)。这个过程让教师的"知识"得以在真实数据上应用和检验。对学生而言 :它通过模仿教师的输出,间接地学到了教师从合成数据中掌握的深度估计能力。同时,因为它直接接触了海量真实的、多样化的图像,它学到的知识会更加泛化,能够更好地应对真实世界中各种复杂、多变的场景。
- 泛化能力 :关注的是模型面对****"没见过的新东西"**** 时的表现。鲁棒性 :关注的是模型面对****"被干扰的旧东西"****时的表现。
- 模型压缩:让小模型去模仿大模型的输出(软标签),最终达到接近大模型的精度,但保持了小体积、低算力的优势
PDFNet 是直接使用 DAM-v2 的输出作为输入和监督信号
输入图像:I ∈ R^{B×3×H×W}:B(Batch size):一次输入多少张图片。例如 B=1 就是一次一张。
输出深度图:D ∈ R^{B×1×H×W}:输出的深度图与输入图像分辨率相同,每个像素都有一个深度值。
归一化深度图:取值范围在 0, 1 内:原始的深度值理论上可以是任意正数,数值范围很大;将一整张图的深度值统一缩放到 0 到 1 之间,统一尺度 ,稳定训练 :神经网络处理 0,1 区间的数值比处理任意大数更容易收敛。数值是相对的,但物体内部的稳定性规律(前景方差小、背景方差大)在相对深度中依然成立。
多阶段特征提取
受共享编码器框架的启发 (Yu et al. 2024a; Bochkovskiy et al. 2025),我们的模型采用跨模态架构以促进特征交互。给定一张高分辨率 RGB 图像 I∈RB×3×H×WI ∈RB ×3×H ×W 及其对应的深度图 D∈RB×1×H×W,一个主编码器提取多尺度视觉特征和深度特征,分别为 {Fiv}i=14和 {Fid}i=14。为了捕捉细粒度细节,一个并行分支将输入图像划分为 64 个块,重新组织为大小为 R64×B×3×H8×W8的批次。一个专用的块编码器随后处理这些块,产生特征 {Fipj}i=063,这些特征随后被重组成高分辨率特征序列 {Fip}i=14。最后,一系列跨尺度的 3×3卷积融合这些多级特征流,产生最终表示 {F5v,F5d,F5p}。在此设计中,{Fiv,Fid}提供全局空间上下文,而 {Fip}负责高保真细节表示。这种多分支架构旨在增强模态互补性和特征一致性。
「主编码器双模态分支 + 并行细粒度分块分支」的共享编码器跨模态架构
主编码器:

核心是同时提取 RGB 和深度两种模态的多尺度特征
主编码器采用论文指定的 Swin-B 骨干网络,是经典的金字塔结构,会分 4 个阶段逐步下采样提取特征,因此输出 4 组特征(i=1 到 4):

- 浅层特征(i=1/2)尺寸大,保留边缘、纹理等细节
- 深层特征(i=3/4)尺寸小、感受野大,捕捉目标的全局语义与空间结构
共享编码器:用同一套骨干网络同时处理 RGB 和深度图,而非两个完全独立的编码器,既能让两种模态的特征天然空间对齐,减少模态差异,又能控制参数量,实现高效的跨模态特征交互。
只用同一套骨干网络(Swin-B)的参数,同时接收 RGB 图像和深度图的输入,在同一个特征提取流程里,分别输出两种模态、一一对应的多尺度特征。
- RGB 和深度图经过完全相同的计算规则、同一套网络参数 处理,输出的特征在尺寸、感受野、空间坐标、语义层级上是严格一一对应的,天然实现空间对齐。同时,两种模态的特征在同一个语义空间里学习,大幅缩小了模态差异,让 RGB 的纹理信息和深度的几何信息能真正互补,而非强行拼接。
- 又能控制参数量,只用一套 Swin-B 参数,同时处理两种模态,编码器参数量依然保持在 90M 左右,直接砍掉了近一半的编码器参数量
- 在特征提取的每一个多尺度阶段(论文里的 4 个编码阶段),都能同时拿到同尺度、同空间的 RGB 和深度特征,从编码阶段就可以做跨模态的交互与融合。
独立编码器的痛点:
- 输出的特征很容易出现空间错位,融合时颜色和几何信息对不上,同时,两套网络学习的是两套完全不同的语义体系,会出现严重的「模态鸿沟」,融合效果大打折扣
- 如果做两套独立编码器,光编码器部分参数量就会翻倍到 180M
- 两套编码器各自闭环学习,RGB 编码器学不到深度的几何约束,深度编码器也学不到 RGB 的纹理语义,只能在编码的最后一步做浅层的特征拼接,跨模态信息交互严重滞后,无法在特征提取过程中就实现互相引导、互相补充
并行分块分支:

为什么要做分块处理:主编码器处理整张高分辨率图时,下采样过程会压缩、丢失微小的边缘、纹理细节;而把原图切成均匀的小块,每个小块单独编码,编码器的感受野仅覆盖这个小块,能精准捕捉小块内的细粒度细节,不会被全局背景干扰。
- 把输入的 H×W 原图,均匀切成 8 行 8 列,共8×8=64 个不重叠的小块,每个小块的尺寸是 8H×8W(比如输入 1024×1024 的图,每个小块就是 128×128);
- 把 64 个小块重组为新的批次:原本 1 张图变成 64 个小块,批次维度从 B 变成 64×B,最终张量尺寸为 R64×B×3×8H×8W,可以用专用的块编码器批量处理;
- 块编码器对 64 个小块分别提取 4 个阶段的多尺度特征,得到 {Fipj}j=063(j=0 到 63 对应 64 个小块的特征);
- 把 64 个小块的特征,按照原图的空间位置重新拼接,还原成和主编码器特征同尺寸的 4 组多尺度特征 {Fip}i=14,实现和主分支特征的空间对齐。


多级特征流:指的是共享 Swin-B 编码器输出的、3 组严格空间对齐的 4 阶段多尺度特征,也是融合操作的原始输入
F5i不是 Swin-B 原生直接输出的特征,而是 Swin-B 输出的F1i~F4i,经过论文中提到的「一系列跨尺度 3×3 卷积」做双向多尺度融合后,得到的全局聚合特征
跨尺度 3×3 卷积:3×3卷积 + RMSNorm归一化 + SiLU激活,核心作用是特征通道对齐、跨尺度特征融合,是生成 F5 全局特征、解码器特征融合的核心组件
细化解码
与经典的 U-Net 架构不同,我们的解码器在每个阶段都集成了特征选择与提取(Feature Selection and Extraction, FSE)模块。如图 3 所示,FSE 模块的设计目的是动态增强显著特征,该过程以上一阶段预测结果中提取的边界与完整性线索为条件。同时,该模块采用交叉注意力机制,渐进式融合多模态信息。此外,编码器的浅层特征会被系统地融入解码器的上采样路径中,以丰富上下文细节、优化空间精度。
经典 U-Net :
- 编码器逐层下采样,提取从浅到深的多尺度特征
- 解码器逐层上采样,把高层语义特征恢复到高分辨率
- 每一层上采样后,直接和编码器同尺度的浅层特征做通道拼接,再通过固定的 2 个 3×3 卷积做特征融合(跳跃连接)
在编码器下采样过程中,特征图的分辨率不断降低,每个像素代表的是原始图像中一个较大区域的信息,这些低分辨率特征图上的一个点,其实是对该区域整体内容的高度抽象
上采样的任务就是把这个抽象的"点"的信息,重新"铺开"到对应的空间区域上,让每个原始像素都能获得一个预测值。这个过程不是无中生有,而是基于已有的抽象信息,通过空间位置的映射 和邻域信息的插值来完成的
上采样的常见实现方式:双线性插值 / 最近邻插值(固定规则):
- 原理 :假设低分辨率特征图尺寸为 2×22×2,要上采样到 4×44×4。新图上的每个像素,根据它在原图中的位置,通过周围已知像素的值加权平均计算出来。
- 为什么能得到像素级输出:因为插值公式为每个输出位置都计算了一个具体的数值,直接生成了高分辨率图。虽然这种方法没有引入新信息,但它将低分辨率特征平滑地扩展到了每个像素上。
上采样的常见实现方式:转置卷积(可学习的上采样):
- 原理:可以理解为普通卷积的逆过程。普通卷积用一个滑窗将大图变成小图;转置卷积则是将输入特征图上的一个点,乘以一个可学习的卷积核,然后将这个核的值"铺"到输出图的对应区域(可能重叠)。
- 为什么能得到像素级输出:转置卷积的每个输出位置都是由输入特征图和可学习的权重计算得到的,因此可以针对不同的输入内容自适应地生成细节。通过堆叠多个转置卷积层,网络可以逐步恢复出精细的空间结构。
经典 U-Net 的核心局限:
- 特征融合是无引导、无差别的:不管特征里是目标前景还是无用背景,都会全部拼接融合,容易引入噪声;
- 只能处理单模态 RGB 特征,无法利用额外的先验信息;
- 融合逻辑是固定死的,不会根据上一轮的预测结果动态调整,无法针对性优化误检、漏检区域。
U-Net 解码器的每个阶段,核心是「上采样 + 固定卷积融合」;而 PDFNet 解码器的每个上采样阶段,核心是论文自研的 FSE 模块,先通过 FSE 做动态特征增强,再做后续的上采样和融合。
U-Net 是 "无差别全量融合",FSE 是 "用预测结果做引导,只增强对分割有用的特征"
- 边界线索:
- "哪里是需要精细化的目标边缘",后续会针对性增强包含边界的 patch 特征,优化分割的边界精度。
- 完整性线索:
- ReLU 阈值化,得到目标内部的完整性区域图
- "哪里是前景目标的连续内部区域",后续会用它引导深度特征增强,强化论文核心的「深度完整性先验」,减少误检、漏检
动态增强的核心逻辑:
模型用上一轮的预测结果,先判断 "哪里是目标、哪里是边界、哪里是没用的背景",再针对性加权增强目标和边界区域的特征,抑制背景区域的无效特征。比如:8×8 的细粒度 patch 里,只有包含目标边界的 patch 会被放大权重,纯背景 patch 被抑制;深度特征里,只有目标内部的区域会被完整性线索加权增强,强化前景深度一致性。
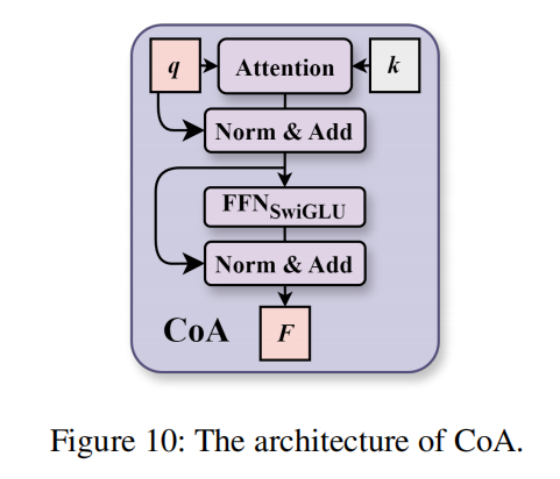
交叉注意力机制(CoA):论文里设计的 Cross-modal Attention 模块(对应代码里的CoA类),通过 QKV 交叉注意力,实现三个模态特征的双向交互:用深度和 patch 特征增强视觉特征,同时用视觉特征补全深度和 patch 特征的全局上下文
渐进式融合 :不是只在编码器末尾做一次融合,而是解码器的每个阶段都做一次跨模态融合,从最深层到最浅层,逐步把深度先验、细粒度细节融入到分割特征中,越靠近输出层,特征的细节越丰富、结构越完整。
编码器的浅层特征,会先输入到 FSE 模块中,经过「边界 / 完整性线索筛选 + 跨模态注意力融合」之后,再融入到解码器的上采样路径中。只保留和目标相关的有效细节,过滤冗余的背景信息,既用浅层特征补充了高分辨率的空间细节、优化边界精度,又不会破坏目标的全局结构完整性。
深度优化
为正则化特征学习过程,我们通过一个专用解码器引入了深度优化任务。该策略具有双重作用:一方面引导共享编码器学习同时有益于分割与深度估计的特征表示,另一方面通过伪深度重构目标,迫使模型从 RGB 图像中提取细粒度细节。深度优化解码器本身采用简洁高效的架构:每个阶段由两个堆叠的 3×3 卷积块构成,卷积块后接 SiLU 激活函数(Elfwing, Uchibe, and Doya 2018)与 RMSNorm 归一化,最后通过一个 3×3 卷积层输出深度预测结果。
这个深度优化分支 ,是和主分割解码器并行的辅助训练解码器,二者共享同一个 Swin-B 编码器
它仅在训练阶段启用,用于给主分割任务做特征正则化和辅助监督;推理阶段可直接移除,不会增加任何计算耗时
双重作用:
- 引导共享编码器学习同时有益于分割与深度估计的特征表示
- 需要的特征:前景 / 背景的二分类语义、目标边界的细粒度细节、像素级的分类能力;
- 需要的特征:场景的 3D 空间结构、目标的整体轮廓完整性、前景与背景的空间层级关系
- 3D 结构建模」的双重需求
- 通过伪深度重构目标,迫使模型从 RGB 图像中提取细粒度细节
- RGB 图像的编码特征中,重建出 DAM-v2 生成的高精度伪深度图
- RGB 图像中提取到边缘轮廓、微小纹理、局部连续结构等极细粒度的细节信息,否则深度重构的误差会非常大
深度优化解码器层级结构 = 渐进式上采样解码 + 多阶段深度监督 每个解码阶段核心单元 = 2个堆叠的3×3卷积块 单个卷积块 = 3×3卷积 + RMSNorm归一化 + SiLU激活函数 最终输出头 = 1个3×3卷积层,输出单通道深度预测图
- 输入共享编码器输出的多尺度特征:F1~F4 层级特征 + F5 全局聚合特征;
- 从最深层(F4+F5)开始,逐层上采样 + 特征融合,每个阶段经过 2 个 3×3 卷积块处理;
- 每个解码阶段输出一个侧边深度预测,用于多尺度深度监督;
- 最终经过 2 次上采样还原到原始输入尺寸,通过末尾的 3×3 卷积层,输出最终的深度预测图
训练监督:该分支的训练采用SILog 损失(尺度不变对数误差),这是单目深度估计领域的标准损失函数,对深度的尺度变化不敏感
- 该分支仅在训练时启用,用于特征正则化;推理时直接移除,不会给模型带来任何额外的推理耗时
- 该模块使用的深度监督信号,来自 DAM-v2 生成的伪深度图,不需要人工标注任何真实深度数据,零额外标注成本
- 该分支的梯度会和主分割任务的梯度一起,反向更新共享 Swin-B 编码器,让编码器的特征同时被「分割语义」和「深度结构」双重约束
- 和主分割解码器一致,深度优化解码器也采用了多阶段深度监督,每个解码阶段的侧边输出都会计算损失,进一步强化编码器的多尺度细节建模能力
特征正则化:在模型训练过程中,给特征的学习过程增加一些额外的约束或限制,目的是让模型学习到的特征具有某些我们希望的性质
深度监督与多特征融合
遵循高精度二值图像分割(DIS)领域的通用做法(Qin et al. 2022; Yu et al. 2024a; Zheng et al. 2024a),我们在多个阶段施加深度监督。最终预测结果 P 会经过渐进式上采样,并与编码器浅层特征融合(Yu et al. 2024a; Liang et al. 2021)以优化目标边界,深度解码器中也采用了相同的策略。
多阶段深度监督 和渐进式上采样 + 多特征融合两大核心部分
通俗来说,常规分割模型只在最终输出层 用标注 GT 计算损失、反向传播更新参数;而深度监督(Deep Supervision) ,是在解码器的每一个中间解码阶段,都输出一个预测结果,每个结果都用 GT 计算损失,共同参与反向传播
PDFNet 把深度监督策略同时应用到了主分割解码器 和深度精炼解码器两个分支
- 主解码器包含 4 个 FSE 模块,对应 4 个中间解码阶段,加上最终输出,一共生成 6 个不同尺度的分割预测结果,(4 个 FSE 模块负责生成side_1~side_44 个侧边输出,再加上前置初始预测 side_5 和最终输出 final_output),每个预测结果都会上采样到 GT 尺寸,计算「加权 BCE + 加权 IoU+SSIM 损失」,共同参与反向传播。
- 和主解码器对称,深度解码器也采用了相同的多阶段深度监督:4 个中间解码阶段 + 最终输出,一共生成 5 个深度预测结果,每个结果都计算 SILog 深度损失,同步参与训练监督。
作用:
- 解决梯度消失问题:多阶段的损失会给解码器每一层、编码器每一层都提供直接的梯度信号,避免梯度在深层网络中衰减,让编码器浅层能充分学习到高分辨率的边缘细节。
- 多尺度特征解耦学习:深层解码阶段的监督,强制模型学习目标的全局结构和语义,减少漏检;浅层解码阶段的监督,强制模型学习目标的细粒度边界和纹理,提升分割精度,完美解决了「全局结构和局部细节无法兼顾」的核心矛盾。
- 提升训练稳定性与收敛速度:密集的监督信号让模型训练更稳定,收敛速度更快,同时泛化性更强,在复杂纹理、低对比度场景下依然能保持鲁棒性。
PDFNet 的渐进式上采样,是从解码器最深层的低分辨率特征开始,每一个解码阶段只做 2 倍上采样,和对应尺度的编码器特征融合优化后,再进入下一个解码阶段,逐步还原到原始输入分辨率,全程没有跳跃式的大倍率上采样。
PDFNet 的融合逻辑 :编码器的浅层特征不会直接拼接到解码器,而是先送入当前阶段的 FSE 模块,经过「边界 / 完整性线索筛选 + 跨模态注意力融合」提纯后,再和解码器上采样后的特征融合。
把提纯后的浅层特征,和解码器上采样的特征融合,给上采样过程补充高分辨率的边界细节,同时不会引入噪声破坏全局结构。
特征选择与提取模块(FSE)
基于图像块的编码器通过限制感受野提升了细节提取能力,但同时丢失了上下文关联。为解决该问题,我们设计了如图 4 所示的 FSE 模块,它能够基于上一阶段的预测结果动态增强图像块特征,使模型聚焦于目标边界区域。
FSE 模块首先对上一阶段的预测结果 Pi+1∈RB×1×H×W 进行边界 - 完整性分离:通过平均池化操作得到 Ppi+1,再计算绝对差值得到边界图 Bi,以此增强边缘梯度。上述操作的数学表达式如下:
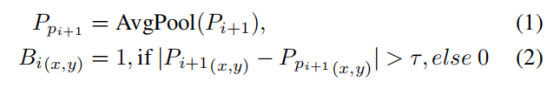
其中,平均池化的核尺寸为 (H/8,W/8),以适配不同分辨率的输入;τ 为一个小的常数,取值为 0.1。将原始预测结果 Pi+1 减去二值边界响应 Bi,再通过 ReLU 阈值化处理,得到边界抑制后的目标完整性图 Si,该特征图聚焦于目标内部连续区域的特征表征。
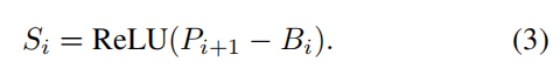
该策略通过差值放大机制增强边界敏感性,同时通过非线性抑制保持目标内部结构的一致性。
我们将边界响应图 Bi 切分为 64 个图像块,与基于图像块的输入一一对应。经过二值化筛选后,得到每个图像块的边界响应分数 Bdi,并通过加权机制为每个图像块分配对应权重,选择性增强包含目标边界的图像块特征。给定二值边界图 Bi∈{0,1}H×W,将其切分为 N=64 个无重叠的图像块:
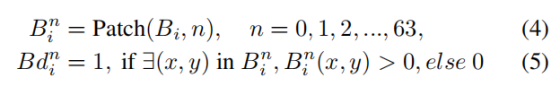
其中,Bin∈{0,1}8H×8W 表示第 n 个图像块。
其次,为实现高效的多模态融合,我们提出了跨模态注意力(Cross-modal Attention, CoA)模块。该模块基于交叉注意力机制,通过查询 - 键 - 值(QKV)交互与 Q/K 投影,动态增强模态间的互补信息。其具体流程包括:(1) 计算像素序列间的注意力权重;(2) 将原始查询与经 RMSNorm 归一化的注意力输出融合;(3) 采用基于 SwiGLU 的前馈网络(FFN)与残差连接,生成最终特征 F。为提升内存效率,我们通过对应阶段的平均池化,对原始特征 Fiv、Fid、Fip 进行压缩,得到 FPiv、FPid、FPip(Yu et al. 2024a; Wu et al. 2022; Zhu et al. 2019)。将这些特征序列化后拼接,生成视觉 - 深度跨模态嵌入 FPivd 与视觉 - 图像块跨模态嵌入 FPivp,实现模态间的持续交互。在计算 CoA 前,先对图像特征进行序列化处理以优化注意力计算;随后通过 CoA 建立跨模态特征关联,将深度特征与局部细节特征的结构约束,通过 Fiu 动态融入全局上下文:
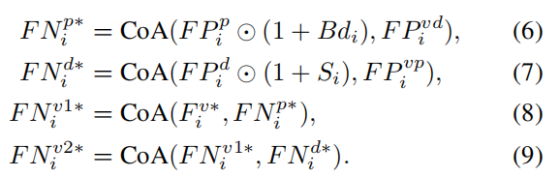
最终,视觉特征、图像块特征与深度特征的更新方式如下:
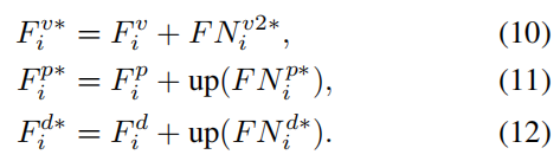
基于 patch 的细粒度分支能捕捉极致细节,但会丢失全局上下文;全局视觉 / 深度分支有完整场景语义,但细粒度边界表现力不足。
它的核心设计逻辑是:以上一阶段的分割预测为动态引导,先拆分出「目标边界」和「目标主体完整性」两大关键线索,再用线索自适应增强有效特征、抑制背景噪声,最终通过跨模态注意力融合 RGB、深度、patch 三大分支的互补信息,同时解决「细节丢失」和「上下文断裂」两大问题。
PDFNet 的 patch 分支会把输入图像切成 8×8=64 个独立小块,每个小块单独编码:
- 优势:每个小块的感受野极小,能捕捉到目标边缘的极细粒度细节,解决高分辨率图像下边界模糊的问题;
- 致命缺陷:每个小块独立处理,完全丢失了「块与块之间的空间关联」和「全局场景上下文」------ 模型不知道这个小块是前景目标的一部分,还是背景的杂乱纹理,最终导致误检、漏检、目标结构破碎。
它以上一阶段的分割预测为 "导航图",精准找到包含目标边界的 patch,只增强这些有效 patch 的特征,同时抑制纯背景 patch 的噪声;再通过跨模态注意力给 patch 特征补全全局上下文,最终实现「既保留细粒度边界细节,又不丢失全局结构完整性」
- 边界 - 完整性分离(BIS)------ 生成动态引导的 "指挥棒"
- :解码器上一阶段的分割预测结果 Pi+1(尺寸为 B×1×H×W,B 是批次,H/W 是特征图高宽)
- Bi:
- 先对预测结果做核大小为 (H/8,W/8) 的平均池化,池化相当于对每个 8×8 的小块内的像素取平均值,得到平滑后的预测图 Ppi+1;
- 计算原始预测和平滑预测的像素级绝对差值,具体做法是计算每个像素位置 (x,y)上的绝对差值,差值大于阈值 τ=0.1 的位置标记为 1(边界像素),否则为 0,最终得到二值边界图 Bi。
- 核心作用:精准定位目标的边缘区域,后续用它来引导 patch 分支的边界细节增强。
- Si:
- 用原始预测结果减去边界图,再经过 ReLU(把所有负数变成 0,正数保持不变) 过滤负值,(由于 Pi+1原本在 0~1 之间,减去 1 后,边界区域的值会变成负数或 0),得到目标完整性图 Si。
- 核心作用:剔除边界后,剩下的就是目标内部的连续主体区域,后续用它来引导深度分支的全局结构完整性增强。
- 自适应 patch 选择与加权 ------ 精准增强边界细节,抑制背景噪声
- patch 切分对齐 :把边界图 Bi 切成和 patch 分支完全对应的64 个无重叠小块(8×8 分块,和 patch 分支的输入切分规则完全一致,目的是让边界信息能够与原始图像块一一对应),Bin 代表第 n 个边界小块
- 计算边界响应分数 * Bdin*:对每个边界小块做二值化判断 ------ 只要这个小块里存在任意一个边界像素,就给这个 patch 打分为 1,否则为 0,64 个图像块就对应了 64 个二值标记,组成一个长度为 64 的二值向量,标记了哪些图像块是"边界块"
- 自适应加权增强 :用 (1+Bdi) 对 patch 分支的特征做逐 patch 加权。
- 包含目标边界的 patch:权重为 2,特征被2 倍增强,放大边界细节信号;
- 纯背景无边界的 patch:权重为 1,特征保持不变,无额外增强,间接抑制了背景噪声。
- CoA 跨模态注意力融合 ------ 补全全局上下文,多模态信息互补
-
- 为了降低显存占用,先对原始的视觉特征 Fiv、深度特征 Fid、patch 特征 Fip 做平均池化压缩,得到压缩后的特征 FPiv、FPid、FPip
- FPivd 是视觉 + 深度特征拼接的跨模态嵌入,FPivp 是视觉 + patch 特征拼接的跨模态嵌入
- CoA(Q,K,V) 是论文提出的跨模态注意力模块,输入查询 Q、键值对 KV,输出交叉注意力增强后的特征
- 特征全局上下文补全:
- 输入 Q:边界加权增强后的 patch 特征;输入 KV:视觉 + 深度的全局融合特征
- 核心作用:让 patch 特征通过交叉注意力,从视觉 / 深度分支中学习到全局场景上下文,彻底解决「patch 分支独立处理、丢失空间关联」的缺陷,让模型知道 "这个边界 patch 属于哪个目标、在场景中的什么位置"
-
- 输入 Q:完整性图加权后的深度特征;输入 KV:视觉 + patch 的融合特征
- 核心作用:用目标完整性图强化深度特征的前景主体区域,同时通过交叉注意力,给深度特征补充 patch 分支的细粒度边界细节,让深度特征同时具备「全局结构完整性」和「边界精准度」,强化论文核心的「深度完整性先验」
-
- 先用增强后的 patch 特征,通过交叉注意力增强视觉主分支特征,给主分支补充细粒度边界细节;
- 再用增强后的深度特征,继续迭代增强视觉主分支特征,给主分支补充全局结构完整性先验;
- 最终输出的 FNiv2∗,就是同时融合了「细粒度边界细节、深度全局结构、视觉语义上下文」的增强特征。
- 残差特征更新 ------ 融合增强信息,保证特征稳定性
- 对视觉、patch、深度三个分支的原始特征,和 FSE 模块增强后的特征做残差相加;
- 对压缩过的 patch 和深度增强特征,用up()上采样还原到原始特征尺寸,保证尺寸匹配;
- 最终输出增强后的三大分支特征 Fiv∗、Fip∗、Fid∗,送入解码器的下一个阶段
深度完整性先验损失
我们利用了一个核心观测规律:正确分割的目标区域内,深度值具有极高的内部一致性。我们将该特性形式化为深度完整性先验,它反映了真实世界物体固有的结构连贯性。为在训练过程中对该先验进行约束,我们设计了对应的损失函数,对偏离两大核心原则的预测结果施加惩罚,两大原则分别为:内部深度稳定性、边界对齐的深度连续性。
第一个组成部分我们称之为深度稳定性约束,其设计灵感来源于目标掩码区域内深度值的统计分布。该约束旨在缓解两类常见的分割错误:(1) 假阳性(FP):深度值与目标均值偏差显著的像素被错误划入前景;(2) 假阴性(FN):深度值与目标均值一致的像素被错误划入背景。为此,我们的损失函数基于每个像素与目标均值的深度偏差,自适应地为每个像素分配惩罚权重:与目标均值深度偏差大的假阳性像素,会受到高额惩罚;反之,深度偏差小的假阴性像素,同样会受到高额惩罚,以促使模型将其划入前景。具体而言,我们首先计算真实标注掩码区域 M 内的深度均值 μ:
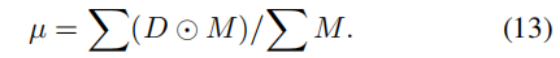
随后,损失函数基于深度差值的平方,对标准交叉熵项进行选择性加权,对假阳性与假阴性区域施加差异化惩罚:
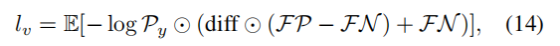
其中,D 为深度图,P 为预测概率图,Py 表示像素级预测的正确性。diff、FP、FN 的表达式如下:
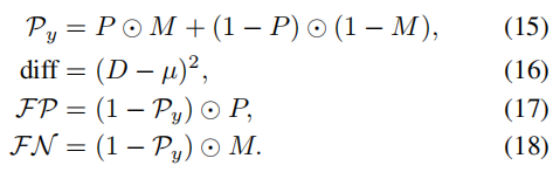
第二个组成部分为深度连续性约束。该损失的设计依据是:物体边界与深度图的剧烈跳变存在强相关性。它通过对深度梯度大的位置出现的分割错误施加更高权重,对上述相关性进行约束,对应的损失项旨在降低预测掩码与深度梯度之间的空间不一致性:
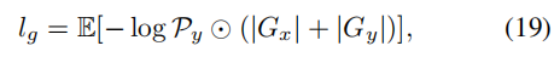
其中,Gx 与 Gy 分别为通过索贝尔算子计算的水平与垂直方向深度梯度。
上述两个约束共同作用,迫使模型利用深度线索学习结构更连贯的特征表示,提升模型区分目标内部与边界的能力。最终的深度完整性先验损失 linte 为两个分量的平均值:
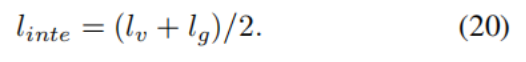
深度完整性先验损失,它的本质是:把现实世界中「物体内部深度稳定、物体边界深度突变」的物理规律,做成可训练的数学约束,逼着模型的分割结果和真实物体的 3D 结构对齐,让分割更精准、更符合真实物理逻辑。
深度完整性先验 :现实世界里,一个完整的物体(比如杯子、书架、人),它到相机镜头的距离(深度)在物体内部是高度稳定、平滑的,深度值的方差极小;而背景是杂乱无章的,深度值跳变剧烈、方差极大。
反过来想:一个正确的分割结果,圈出来的前景区域,必须刚好是「深度值稳定的连续区域」。如果模型把深度差极大的背景像素圈进了前景(误检),或者把深度和目标一致的物体像素漏掉了(漏检),就打破了这个物理规律,我们就用损失函数惩罚这种错误。
这个损失的核心目的:用深度的物理规律,给分割任务加一层「结构合理性」的约束,解决传统分割只看像素外观、不理解物体结构的问题。
- 深度稳定性约束(解决误检、漏检核心问题)
-
- 假阳性(FP):把背景像素错误识别成前景(误检)
- 假阴性(FN):把前景像素错误识别成背景(漏检)
-
- 计算目标的「标准深度均值」
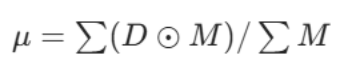
-
- :输入的伪深度图,每个像素值代表这个位置离镜头的距离;M:真实标注(GT)的前景掩码,前景像素值为 1,背景为 0;⊙:矩阵逐元素相乘,只保留前景区域的深度值;μ:真实前景目标区域内,所有像素的平均深度值
-
- 定义「像素预测正确性」和「深度偏差」
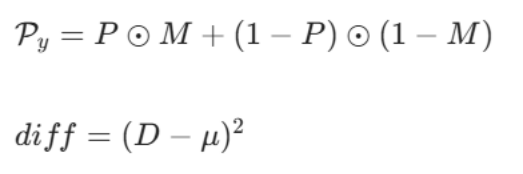
-
- :模型输出的前景概率预测图,每个像素值是 0~1 之间的连续值,代表模型判断「这个像素属于前景目标」的概率;
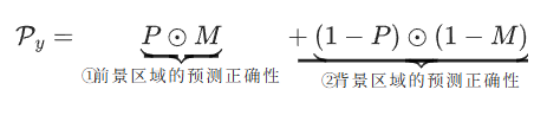
-
- :像素级预测的正确性。模型预测对了(前景像素判为前景、背景像素判为背景),这个值就接近 1;预测错了,就接近 0
-
- Py是深度完整性先验损失的核心基础,论文中后续的损失计算为:−logPy,利用了对数的非线性特性
-
- :每个像素的深度值和目标平均深度的差的平方。diff 越大,说明这个像素离目标的标准深度越远,越不可能是这个物体的一部分
-
- 定义误检、漏检区域
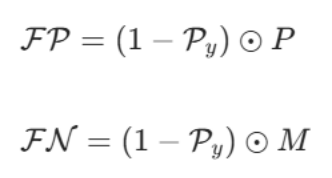
-
-
- FP:假阳性区域,也就是「模型预测为前景,但 GT 里是背景」的误检像素;
- FN:假阴性区域,也就是「模型预测为背景,但 GT 里是前景」的漏检像素。
- 假阳性(FP,False Positive) :也叫误检,像素真实属性是背景(* M=0* ),但模型错误预测为前景(* P≈1* )。
- 假阴性(FN,False Negative) :也叫漏检,像素真实属性是前景(* M=1* ),但模型错误预测为背景(* P≈0* )。
- 代表「像素预测正确的程度」,那么 1−Py 就代表像素预测错误的程度
- 先筛出所有预测错误的像素,再从错误像素里,精准挑出「模型认为是前景」的像素,而这部分像素,恰好就是标准定义里的假阳性
- 先筛出所有预测错误的像素,再从错误像素里,精准挑出「真实属性是前景」的像素,这部分像素恰好就是标准定义里的假阴性
-
-
- 第四步:差异化加权惩罚,精准打击错误
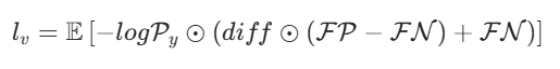
-
- FP)、漏检(FN)两类错误,结合深度信息做自适应差异化惩罚 ------ 错得越违背深度完整性规律,罚得越重
-
- :数学期望,在图像分割任务中,等价于对整张图所有像素的损失值求全局平均 ,最终输出一个标量损失值,用于模型反向传播优化;−logPy:像素级交叉熵基础惩罚项。Py 是像素预测正确性(预测对了≈1,预测错了≈0),因此这个项的特性是:预测越错,数值越大,惩罚越重 ;预测完全正确时,数值为 0,无惩罚;diff:像素深度偏差:每个像素的深度值D,和真实前景目标的平均深度μ的差的平方。diff 越大,代表这个像素的深度和目标物体差距越远,越不可能是前景的一部分;FP:假阳性(误检)区域掩码:只有「真实是背景,模型错误判为前景」的像素,这里值为非 0,其他所有像素值为 0;FN:假阴性(漏检)区域掩码:只有「真实是前景,模型错误判为背景」的像素,这里值为非 0,其他所有像素值为 0
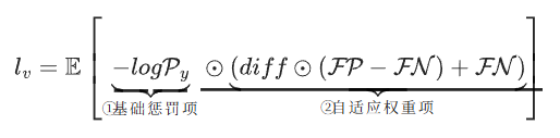
-
-
- 基础惩罚项 * −logPy*:决定「这个像素该不该罚」
- 自适应权重项:决定「这个像素该罚多重」
- *E* 全局平均:把所有像素的「基础惩罚 × 自适应权重」加起来求平均,得到最终的标量损失值,用于模型的梯度下降优化
- FP 和 FN:因此FP和FN也是完全互斥的
-
-
- 区域:FP=1(非 0),FN=0;
-
- 越大,说明这个像素的深度和目标物体差距越远,根本不属于前景,模型却把它误判进来了,就会给基础惩罚乘以一个极大的权重
-
- 区域:FP=0,FN=1(非 0);
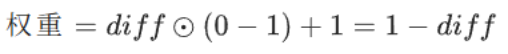
- 区域:FP=0,FN=1(非 0);
-
- 越小,说明这个像素的深度和目标物体几乎一致,本来就是前景的一部分,模型却把它漏掉了,就会给基础惩罚乘以一个极大的权重
-
- FP=0,FN=0(既不误检,也不漏检);
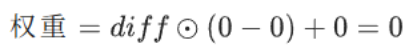
- 完全不产生任何惩罚。
- FP=0,FN=0(既不误检,也不漏检);
-
- 最终,这个约束会逼着模型:只圈出深度和目标均值一致的区域,完美避开深度差异大的背景,也不会漏掉物体内部的像素,从根源上减少误检和漏检
- 深度连续性约束(解决边界不准的问题)
- 不同物体的交界处(也就是目标的真实物理边界),深度才会出现连续性的断裂 ------ 杯子的深度和桌面的深度完全不同,相邻像素的深度值发生剧烈跳变,对应的深度梯度会呈指数级放大
- = 同一个物体的内部;深度不连续 = 物体的边界
- 现实世界中,物体的边缘,必然对应深度图的剧烈跳变处,比如杯子和桌面的交界处,深度会从杯子的距离突然变成桌面的距离;所以,模型的分割边界,必须和深度跳变的位置精准对齐,否则就会被惩罚
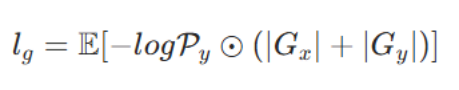
- 、Gy:用 Sobel 算子计算的深度图水平、垂直方向的梯度,梯度绝对值的和,代表这个位置的深度变化剧烈程度;梯度值越大,说明这里深度跳变越厉害,越大概率是物体的真实边界
- 深度梯度大的位置(真实物体边界),模型的分割预测错了,就给这个错误乘以梯度值,大幅提高惩罚力度;如果在深度平滑的区域(物体内部 / 背景内部)预测错了,惩罚相对更小
- 最终的深度完整性先验损失
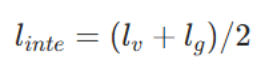
- 加权 BCE 损失、加权 IoU 损失、SSIM 损失加在一起,共同训练模型
损失函数
我们对解码器每一层的输出与最终预测结果均施加监督,同时也对深度优化解码器每一层的输出进行监督。其中,解码器各层输出的监督损失记为 lfi,最终结果的监督损失记为 lf。
对于分割任务的监督,我们遵循分割任务的通用做法,采用加权二元交叉熵损失(Wei, Wang, and Huang 2020)(lwBCE)、加权交并比损失(Wei, Wang, and Huang 2020)(lwIoU)、结构相似性损失(Wang et al. 2004)(lSSIM)的组合(该组合被绝大多数分割任务采用,Qin et al. 2022; Yu et al. 2024a; Zheng et al. 2024a),并加入我们提出的深度完整性先验损失(linte):
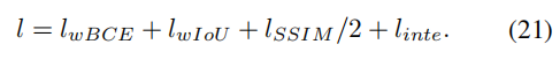
对于深度优化任务的监督,我们采用绝大多数深度估计任务通用的尺度不变对数误差(Ranftl et al. 2020)(SILog)损失。最终,我们的整体损失函数形式如下:
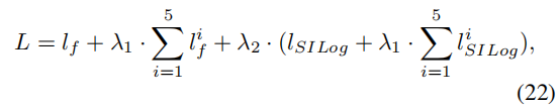
其中,权重参数 λ1 与 λ2 分别设置为 0.5 与 0.1。
以高精度二值分割(DIS)为主任务,融合分割领域通用的多损失组合、深度监督策略,再嵌入论文核心创新的深度完整性先验,同时用深度估计辅助任务强化结构特征学习
- 单张分割预测的核心损失
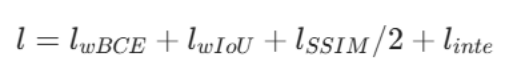
- :结构相似性损失,聚焦分割掩码的整体结构完整性和边界平滑度 。SSIM 原本是图像质量评价指标,核心是衡量两个图像的结构相似度,这里用来约束预测掩码和 GT 的结构一致性,尤其能优化传统损失容易忽略的「边缘连续性、目标整体形状」,避免分割结果出现破碎、边缘锯齿的问题。除以 2 是为了平衡数值范围:SSIM 损失的数值量级和 BCE、IoU 不同,除以 2 后能避免它主导训练过程,同时保留结构约束能力
- 端到端训练的总损失公式
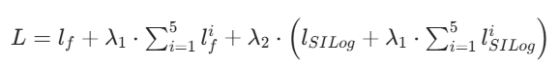
- 深度监督策略 和深度细化辅助任务,解决深层网络梯度消失、渐进式细化效果不足、深度先验引导力弱的问题。
- 的分割解码器、深度细化解码器,都是渐进式上采样的多级结构:解码器有 5 个中间层,每个层都会输出一个对应分辨率的中间预测结果,最终层输出最终的高分辨率预测结果。
- 梯度消失,中间层的渐进式细化能力无法充分发挥。
- 深度监督 ,就是对解码器的每一层中间输出,都单独计算损失、施加监督 ,让每一层都能得到直接的梯度信号,既能缓解梯度消失,又能强制解码器的每一层都专注于对应分辨率的细节优化,尤其适配高分辨率分割的渐进式细化需求,这也是 DIS 领域的通用 SOTA 实践。
- lf 最终预测结果的主损失:分割解码器最终输出的高分辨率预测结果
- 分割解码器的深度监督:λ1⋅∑i=15lfi
-
- 深度细化分支的辅助监督:λ2⋅(lSILog+λ1⋅∑i=15lSILogi)
-
- ,是一个和分割解码器并行的专用深度解码器,核心作用是引导共享编码器学习同时适配分割和深度估计的特征,强化深度完整性先验的引导力
-
- (尺度不变对数误差)的核心优势是:不关注深度的绝对数值,只关注深度的相对变化和空间结构,完美适配论文的伪深度图监督场景 ------ 它能强制模型学习到「前景内部深度连续、边界深度跳变」的结构规律,而不是拟合深度的绝对数值,和深度完整性先验的目标完全契合。
- :深度解码器最终输出的尺度不变对数误差损失,是深度估计任务的行业通用标准损失;
- :深度解码器第i层中间输出的 SILog 损失,同样采用深度监督策略;
-
- 1=0.5:和分割分支保持一致的中间层监督权重,保证训练逻辑统一;
- 2:整个深度分支的总权重,论文中固定为 0.1。
图四
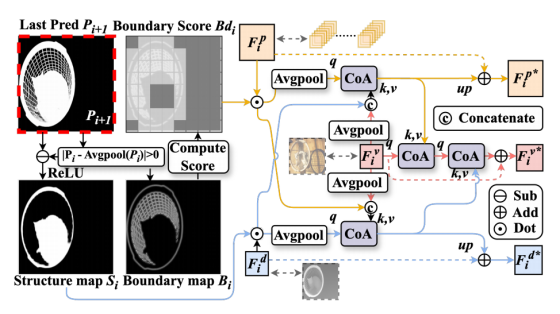
图 4 特征选择与提取(Feature Selection and Extraction, FSE)模块
图十
跨模态注意力(CoA)
利用交叉注意力机制,CoA 通过查询-键-值交互动态分配模态间权重,其中互补信息通过 Q/K 投影被选择性增强。该过程包括:(1)像素序列之间的注意力 (Vaswani 2017) 计算 Att(Q,K),(2)原始 Q 与 RMSNorm 归一化 (Zhang and Sennrich 2019) 的注意力输出的集成,(3)通过具有残差连接的 FFNSwiGLU (Shazeer 2020) 进行非线性增强,以产生最终表示 FF。视觉架构如图 10 所示。
CoA 模块核心目标是让三个语义完全不同的模态特征,动态学习彼此的互补信息,放大对分割有用的有效信号、抑制背景噪声
传统的多模态融合(直接通道拼接 + 卷积),只是对特征做物理层面的叠加,无法建立模态间的语义级关联
而 CoA 基于交叉注意力(Cross-Attention) 机制,完美解决了这个问题:它让一个模态的特征(查询 Q),主动去关注另外两个模态特征(键 K、值 V)里的互补信息,实现动态的、语义级的、内容感知的多模态融合,而不是静态的通道叠加
- 计算像素序列间的注意力权重
- rearrange操作,把 2D 的特征图(格式B×C×H×W,批次 × 通道 × 高 × 宽)reshape 成 1D 的像素序列(格式B×(H×W)×C),也就是 Transformer 标准的 token 化格式,每个像素对应一个 token
- Self-Attention,Q/K/V 都来自同一个特征)不同,CoA 的查询 Q 和键值对 KV 来自完全不同的模态 ,这也是 "跨模态" 的核心含义
- 先通过 Q 和 K 的点积计算,得到像素级的注意力权重(权重越高,代表当前 Q 的像素,越需要关注 KV 对应像素的信息)
- 再用注意力权重对 V 做加权求和,输出注意力增强后的特征
- 将原始查询与经 RMSNorm 归一化的注意力输出融合
- 先对步骤 1 输出的注意力结果,做RMSNorm 归一化:相比传统 LayerNorm,RMSNorm 计算量更小、训练更稳定,尤其适配视觉 Transformer 的多尺度特征,不会破坏特征的空间语义信息
- 把归一化后的注意力输出,和原始的查询 Q做残差相加(融合),再经过 Dropout 做正则化
- 设计目的:
- 避免注意力计算带来的原始特征信息丢失,保留查询特征的基础语义,同时融入跨模态的增强信息
- 缓解深层网络的梯度消失问题,让梯度可以通过残差分支直接回传,保证训练的稳定性;
- 实现 "基础语义 + 跨模态互补信息" 的有机结合,不会因为注意力计算过度改写原始特征的核心语义。
- 采用基于 SwiGLU 的前馈网络(FFN)与残差连接,生成最终特征 F
- 对步骤 2 输出的特征,先做 RMSNorm 归一化,再送入基于 SwiGLU 激活的前馈网络(FFN) 做非线性变换,放大对分割任务有用的有效信号,抑制背景噪声和冗余信息;
- 对 FFN 的输出做 Dropout 正则化后,和步骤 2 的输入做第二次残差连接,最终输出跨模态增强后的完整特征。
组会问题
Swin-B为什么要这样划分?
这需要看Swin Transformer的原始论文,它是在VIT模型上进行改进的,并且也是做了不同patch大小的实验的,最后发现4×4 Patch精度和速度的平衡最好,然后Swin-T的补丁合并模块为什么是2x2,其实它是在模仿 CNN 的 "分层下采样 + 通道数翻倍" 设计,但它不是简单的丢弃像素,而是融合相邻 Patch 的信息,同时降低计算量
渐进式上采样是怎么做的
生成最终的分割掩码是经过了三次上采样和两次浅层特征融合;具体操作是将1024的原始图像和伪深度图沿通道进行拼接后再下采样4倍得到预处理后的浅层特征;之后将F1阶段的特征做第一次上采样,然后与浅层特征第一次融合,做第二次上采样后再与浅层特征做第二次融合,最后再做第三次上采样,最终经过一个卷积层,得到最终的高分辨率分割图,分辨率为1024x1024
Swin-B 作为纯卷积 + Transformer 窗口注意力 的骨干网络,天生支持可变尺寸输入
不管输入图像多大,都按 "4×4 像素" 划分为不重叠的 Patch,然后把每个 Patch 的像素展平成特征向量
对当前阶段的特征图,按 "2×2 相邻 Patch" 合并,每次下采样 2 倍、通道数翻倍。
PDFNet 能实现 "全局分支 + 细粒度 Patch 分支复用同一 Swin-B 编码器",完全依赖 Swin-B 的这个特性:
- 同一编码器处理两种不同尺寸的输入:因为 Swin-B 支持可变尺寸,所以不需要为两个分支设计不同的编码器 ------ 复用权重既控制了参数量,又保证了三个分支的特征在 "同一个语义空间" 里
- 推理时可以适应不同分辨率的图像
F5全局特征的作用
生成初始掩码,为第一个FSE模块提供边界指导信号
三个并行分支的初步融合,为后续的解码器提供了三模态融合后的全局基底,不是从零开始的
F5逐元素相加的原因
"逐元素相加" 的本质是快速聚合三个分支的全局语义共识 ,它不需要复杂的交互,只需要把三个分支都认可的 "目标区域""背景区域" 的信号叠加起来,就能生成一个粗略但整体结构正确的初始分割掩码 P5,所以没有采用复杂的融合方式
边界图包括前景的中间区域?
首先平均池化的核大小是H/8,W/8,不是小核,会忽略一些小范围的波动
其次,边界图是由上一阶段的初始预测掩码生成的,这个时候前景区域的内部已经基本上是平滑的了
评价指标
F-measure 是 精确率(Precision)和召回率(Recall)的加权调和平均
- Fβmax 指遍历所有二值化阈值后,能得到的最大 F-measure 值,避免了单一阈值选择对结果的干扰
- 在 F-measure 的基础上,引入了像素级权重分配:对目标边界、小目标、薄结构等关键区域的像素分配更高权重,对前景内部平坦区域的像素分配更低权重,专门针对高精度分割的 "细节优先" 需求设计
- 结构度量:专门为显著性检测、二值分割设计的结构一致性指标,核心是同时评估两个维度的相似度
- 增强对齐度量:是介于 "像素级精度" 和 "结构级精度" 之间的综合指标,基于增强对齐矩阵,同时捕捉全局统计一致性 和局部像素对齐度,既评估目标的整体定位是否准确,也评估局部细节、薄结构的贴合度
- 平均绝对误差MAE:模型输出的 0-1 前景概率图,与真值二值掩码(0 = 背景,1 = 前景)之间,所有像素绝对差值的平均值
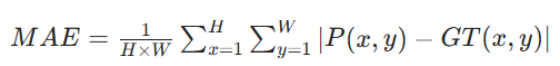
AdamW 优化器
AdamW 是 Adam 优化器的改进版 ,核心是修正了「权重衰减(Weight Decay)」的实现方式
权重衰减是最常用的正则化手段 ,目的是防止模型过拟合------ 简单说就是 "让模型参数不要变得太大",避免模型过度记住训练数据的噪声。
Adam 是自适应学习率优化器,它会为每个参数维护 "一阶矩(动量)" 和 "二阶矩(梯度平方的均值)",动态调整每个参数的学习率
AdamW 的解决思路非常简单直接:不要把 L2 正则化加到损失函数里,而是把 "权重衰减" 变成一个 "独立的步骤"
DIS
Dichotomous Image Segmentation:二分图像分割 或高精度二值图像分割
二值图像分割中的二值
"二值" 指的是输出的分割结果只有两种可能的像素值,通常是:
- 0(黑色):代表背景
- 255(白色):代表前景(目标物体)
伪深度图的像素值的单位
单目深度估计生成的伪深度图中,像素值无单位,一般都会做归一化处理至【0,1】区间
因为单目深度估计本身是尺度模糊的,仅从单张 RGB 图像无法推断出真实的物理深度,只能学习到场景中物体的相对深度关系,因此模型输出的深度值本质是相对深度,无物理单位
深度方差归一化的原因
归一化是为了把所有计算出的深度方差数值,通过数学变换缩放到了统一区间内,消除不同图像、不同区域的数值尺度差异
箱子的高度代表中间 50% 核心数据的方差的波动范围
看这中间 50% 的核心数据,核心目的是剥离异常值、噪声的干扰
为什么叫细化解码和深度优化
细化是指精细化,解码器的每一个阶段都嵌入了FSE(特征选择提取)模块 ,会根据前一阶段的分割预测结果,动态筛选并增强关键特征:聚焦目标边界的高权重特征、抑制背景的无效特征,能够精细分割
并且采用深度监督策略,对解码器每一层的输出都进行分割监督,让网络从粗到细、逐层优化分割掩码
深度优化是对「伪深度图」进行重建优化,同时反向对编码器的深度特征提取能力进行精细化打磨
并且采用深度监督策略,对深度解码器每一层的输出都计算 SILog 损失,让网络逐层优化深度特征的表征
双线性插值下采样
下采样(降分辨率)方法,通过计算目标像素周围 4 个原始像素的加权平均值(距离越近,权重越大)生成降采样后的值
双线性插值的本质是先做水平方向线性插值,再做垂直方向线性插值
沿batch进行拼接,没有沿通道进行拼接,没有在编码时融合在一起提取特征,而是在细化解码时融合特征来解码,这样的好处是什么
保证单模态特征的提取精度:独立提取让编码器能针对每种模态的特性做精准特征学习
补丁合并模块中将通道数压缩为原来的1/2
直接拼接得到的 4个通道存在冗余:4 个特征图来自 "相同位置像素的拆分",特征高度相似,直接用于后续计算会导致计算量激增且无额外收益
将图像按4x4像素划分为一个补丁,每个补丁含16个像素,将每个补丁在通道方向展平,得到16x3维特征,此时特征图形状变为H/4,W/4,48
核心原因正是Transformer 架构的编码器只能处理 "序列形式的 token(令牌)",无法直接处理二维网格状的图像像素------ 将图像划分为 4×4 补丁并展平为一维特征,本质是完成 "图像像素→Transformer 可处理 token" 的格式转换
相比于之前的MVANet的2x2补丁补充输入,PDFNet改成了8x8,补丁数量增多,单个补丁的感受野变小,丢失了局部上下文
丢失局部上下文,网络无法判断「这个 Patch 里的边缘,是物体的边缘,还是背景的纹理」,最终出现大量误检
论文通过双分支职责完全解耦,完美解决了这个问题:
- 全局分支:专职负责提供完整的全局场景上下文和物体整体结构,告诉网络「什么是前景、什么是背景,物体的整体轮廓是什么」;
- Patch 分支:完全不用管全局结构,只需要专职负责「把边缘细节抠准」,有全局分支做兜底,不会出现上下文丢失导致的误检。
相比于MVANet的区别,为什么MVANet在提高块数划分时性能下降,而PDFNet却可以划分为8x8
MVANet将原图和多个 patches 作为独立输入送入编码器,没有专门的主干分支来保留全局语义信息,当 Patch 数量增多时,缺乏全局指导
MVANet 没有设计有效的 Patch 间交互或融合机制,局部特征之间缺乏关联
PDFNet是主分支保留全局特征,细粒度分支增强细节,二者通过FSE模块深度融合
PDFNet的英文
Prior of Depth Fusion Network :深度先验融合网络
为什么Bdi对细粒度特征加权,Si对深度特征加权
通过 Bdi的引导,细粒度特征会选择性增强那些位于物体边缘的 Patch 特征,同时抑制那些位于平滑背景区域的 Patch 特征。这既保留了边界的精细度,又防止了背景纹理的过拟合
Si是通过从预测结果中减去边界 Bi得到的完整性图(或称内部区域图)。它代表的是"物体内部不需要边界细节的平滑区域"
深度特征在物体内部区域被加强,强制模型在预测这些区域时,参考深度图的平滑性
预测掩码的分辨率问题
P1 和最终的分割掩码的分辨率相差较大:
最终的 Pred 是经过多阶段上采样、融合多尺度浅层特征后,得到的与输入原图(1024×1024)尺寸一致的全分辨率分割结果,核心目标是实现像素级的高精度分割,因此和中间层 P1 的分辨率相差较大
P5是全局特征生成的分割掩码,P4是最深层特征生成的分割掩码,他们用来监督的真实分割掩码是一样的,这合理吗?
二者的特征语义、聚焦的学习重点有本质区别,同一个 GT 会引导它们学习完全不同的能力,形成互补约束
结构相似性损失SSIM
核心是从人眼视觉特性出发,衡量预测结果与真实标签的结构、轮廓、纹理相似度,通过最小化损失让预测贴合真值
它从 3 个互补的维度,衡量两张图像的相似性:亮度分量、对比度分量和结构分量
分别是衡量两张图的平均像素值的接近程度、衡量两张图的像素值标准差的接近程度和衡量两张图像素间的空间线性相关性
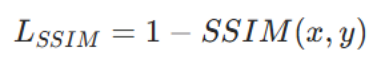
wBCE+wIoU 负责整体像素级分类精度,SSIM 损失负责强化结构与边缘约束,深度完整性先验损失linte负责强化前景深度一致性
数据集DIS-5K
DIS-TE 是 DIS-5K 数据集内专门用于模型性能测试的测试集统称
DIS-TR:训练集
DIS-VD:验证集
patch的消融实验为什么只做8x8后直接到16x16了
PDFNet 的主干编码器采用Swin Transformer-Base(Swin-B) ,而 Swin Transformer 的核心设计就是基于 2 的幂次的窗口划分、补丁合并与下采样机制
Swin-B 原生的补丁划分是 4×4,补丁合并模块每次以 2 倍倍率下采样、通道数翻倍,全程遵循 2 的幂次的尺度设计;
扩散模型是怎么进行图像分割的
扩散模型的本质是逐步加噪的前向过程+逐步去噪的反向过程,分割任务就是把这个框架适配到掩码生成上
- 前向加噪过程:给真实分割掩码(GT) 逐步加入高斯噪声,一共 T 步,每一步都在上一步的基础上加一点噪声,最终纯掩码会变成完全随机的高斯噪声
- 反向去噪过程:训练一个带条件注入的 UNet 网络,输入带噪掩码 + 当前步数 + RGB 图像条件,输出这一步添加的噪声预测。训练目标是让预测噪声和前向过程中真实添加的噪声尽可能一致。训练完成后,就可以从纯随机噪声出发,用这个 UNet 迭代 T 步,每一步都减去预测的噪声,逐步还原出符合 RGB 图像条件的分割掩码。
例如:DiffDIS扩散模型进行图像分割的流程:
训练时:
- 训练数据预处理:
- 输入样本对:取自 DIS-5K 训练集 DIS-TR 的 3000 组样本,每组包含「1024×1024 高分辨率 RGB 图像 I」+「对应二值分割真值掩码 M(GT)」
- 掩码值域对齐:将 0,1 的二值真值掩码 M,线性映射到 SD 模型标准的 -1,1 值域
- 图像条件编码:将 RGB 图像 I 送入冻结的 DINOv2 编码器,提取 4 个层级的多尺度特征
- 前向加噪过程(固定无参数):为 UNet 生成不同噪声强度的训练样本
- 带条件引导的 UNet 噪声预测前向传播:目标是让 UNet 在图像条件引导下,精准预测添加到掩码上的噪声
- 输入:带噪掩码M_t、时间步t、多尺度图像条件特征F_img
- 输出:UNet 最终输出对该步添加噪声的预测结果ε_pred
- 损失计算与反向传播
推理时:从纯随机高斯噪声出发,用训练好的 UNet,在 RGB 图像条件引导下,迭代去噪生成与输入图像匹配的分割掩码
swin-T的补丁合并模块,为什么要归一化处理
- 不同通道、不同空间位置的特征数值范围差异很大,直接送入后续线性层会导致数值不稳定,模型难以收敛;LayerNorm 会对每个样本的特征做归一化,让特征分布均值接近 0、方差接近 1,消除尺度差异
- 深度神经网络中,特征尺度剧烈变化会导致梯度过大或过小,破坏训练稳定性。归一化后,特征分布更平滑,梯度在反向传播时能更稳定地流动,避免梯度消失或爆炸