一、什么是结构方程模型?
SEM结构方程模型是一种基于因子分析、线性回归方法、用于分析错综复杂变量之间路径关系的一种模型。
SEM结构方程模型可以用于探索变量之间的关系。它通过将变量之间的因果关系与测量误差纳入统一的分析框架中来分析数据,从而可同时评估多个变量之间的关系。这些变量可以是观测数据(如问卷调查中的各项指标)或潜在变量(如认知、情感、信仰等难以直接观察的因素)。
与线性回归不一样的是,SEM是以量表为单位的,也就是将量表通过因子分析降维成1个主成分(多个变量转化为一个变量),再进行路径分析。
二、结构方程模型的数据要求
1、多个变量:结构方程模型需要多个变量来建立因果关系模型。这些变量可以是观测到的变量,如问卷调查中的题目得分,也可以是潜变量,如心理特征。
2、大样本量:由于结构方程模型需要估计大量参数,通常建议样本量至少在200以上。
3、正态分布:结构方程模型假设变量服从正态分布,如果数据不服从正态分布,则需要进行数据转换或使用非参数方法。(如何检验数据正态性)
4、缺失值处理:由于数据缺失的存在,需要对缺失值进行处理,例如使用最大似然估计或多重插补等方法。
5、独立观测:结构方程模型假设每个观测之间是相互独立的,需要确保观测之间不存在相关性或依赖性。
三、结构方程模型案例操作
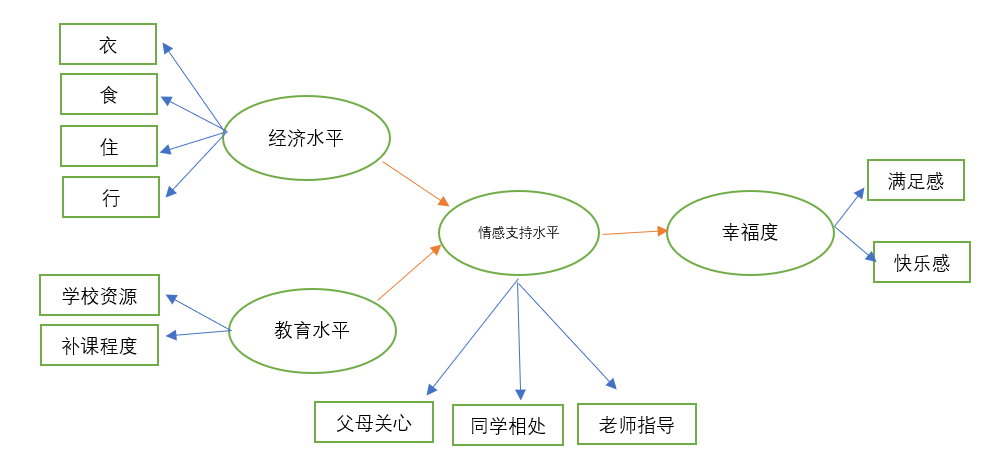
案例:研究"幸福感"的影响因素,有四个因子可能对幸福感有影响,他们分别是:经济水平、受教育程度、情感支持。
每个因子又由多个变量组成,其中经济水平包括(衣、食、住、行)、情感支持包括(父母关心、同学相处、老师指导)、受教育程度包括(学校资源、补课程度)、幸福度包括(满足感、开心感),通过路径分析可以得到这四个变量如右图所示路径关系作用于幸福感。
下面是R语言的代码去实现结构方程
bash
# load plspm
library(plspm)
library(readxl)
library(dplyr)
# 选择数据的第3-38列
mydata <- read_xlsx("pattern_analysis.xlsx") %>%
dplyr::select(3:38) %>%
na.omit() %>%
as.data.frame()
# 对GEP和生态系统类型面积除以面积
mydata$GEP00_23 <- mydata$GEP00_23 / mydata$area
mydata$TJ00_23 <- mydata$TJ00_23 / mydata$area
mydata$forest00_23 <- mydata$forest00_23 / mydata$area
mydata$nature00_23 <- mydata$nature00_23 / mydata$area
mydata$wetland00_23 <- mydata$wetland00_23 / mydata$area
mydata$csha00_23 <- mydata$csha00_23 / mydata$area
mydata$grass00_23 <- mydata$grass00_23 / mydata$area
mydata$wood00_23 <- mydata$wood00_23 / mydata$area
mydata$crop00_23 <- mydata$crop00_23 / mydata$area
mydata$roadlength <- mydata$roadlength / mydata$area
mydata$pop00_23 <- mydata$pop00_23 / mydata$area
# load dataset satisfaction
mydata <- subset(mydata, select = c(area, GEP00_23,
pop00_23,roadD,
tem00_23,pre00_23,
DEM,slope,
forest00_23,crop00_23))
# define path matrix (inner model)
# 5个潜变量之间的路径关系,1表示存在路径,0表示不存在路径
# ESV MET ECO GEO LUCC
ECO <- c(0,0,0,0,0)
GEO <- c(0,0,0,0,0)
MET <- c(1,1,0,0,0)
LUCC <- c(1,1,1,0,0)
ESV <- c(1,1,1,1,0)
sat_path <- rbind(ECO, GEO, MET, LUCC, ESV)
# define list of blocks (outer model)
sat_blocks <- list(3:4, 7:8, 5:6, 9:10, 2:2) # 5个潜变量,每个潜变量对应的观测变量的列索引
# vector of modes (reflective indicators)
# 反射指标(A)和形成指标(B)的模式,分别对应每个潜变量
sat_modes <- c("A", "A", "A", "B", "A")
# apply plspm with bootstrap validation
satpls <- plspm(mydata, sat_path, sat_blocks, modes = sat_modes,
scaled = FALSE, boot.val = TRUE) # br = 10000, # Bootstrap重复次数(10,000次) seed = 123 # 设定随机种子保证结果可重现
# default print
satpls
# summary of results
summary(satpls)
# plot inner model results
plot(satpls, what = "inner")
# plot outer model loadings
plot(satpls, what = "loadings")
# plot outer model weights
plot(satpls, what = "weights")
# 参考plspm的基础设计参考文献
https://mp.weixin.qq.com/s/koLGa4cJHgUw5OplyGlPmg
结构方程模型原理及应用