多图像医学视觉-语言大模型,Med-MIM 指令数据集!
论文:Medical Large Vision Language Models with Multi-Image Visual Ability
数据集与微调模型:https://github.com/Xikai97/Med-MIM
0、摘要
医疗大视觉 - 语言模型 (Medical Large Vision-Language Models, LVLMs)已在各类单图像问答 (Question Answering, QA)基准测试中展现出极具潜力的性能,但其在处理多图像临床场景的能力方面仍未得到充分探索。与单图像任务不同,涉及多图像的医疗任务通常需要复杂的视觉理解能力,例如时间推理 (temporal reasoning)和跨模态分析 (cross-modal analysis),而当前的医疗 LVLMs 对这些能力的支持尚显不足。(研究背景)
**本文构建了 Med-MIM 指令数据集,该数据集包含 83.2K 对医疗多图像 QA 数据,涵盖了四种类型的多图像视觉能力:时间理解、推理、比较与共指能力(co-reference)。**利用该数据集,本文对 Mantis 和 LLaVA-Med 进行了微调,从而得到了两个专门用于多图像分析的医疗 VLVM:MIM-LLaVA-Med 与 Med-Mantis。此外,本文开发了 Med-MIM 基准测试套件,以全面评估 LVLMs 的医疗多图像理解能力。
在 Med-MIM 基准测试上,本文评估了八种主流的 LVLMs(包括本文的两个模型)。实验结果表明,Med-Mantis 与 MIM-LLaVA-Med 在 Med-MIM 基准测试的保留子集 (held-in subsets)与未知子集(held-out subsets)上均取得了卓越性能,这证明了 Med-MIM 指令数据集能够有效增强 LVLMs 在医疗领域的多图像理解能力。
1、引言
1.1、研究意义与当前挑战
(1)现有医疗视觉-语言模型通常是为单图像任务设计的,缺乏针对多图像问答 的指令微调;(当前局限)
(2)如何整合来自不同来源的信息 以提供可靠的诊断;(当前挑战)
(3)现有的医疗视觉问答基准未能充分评估多图像理解能力 ,这在评估模型的临床多图像视觉理解能力方面留下了关键的空白;(现有不足)
1.2、本文贡献
(1)构建了包含 83.2K 个医疗多图像指令样本的 Med-MIM 指令数据集 。该数据集被划分为四个子集,分别用于提升 VLMs 的共指 (co-reference)、比较 (comparison)、推理 (reasoning)与时间理解(temporal understanding)能力;
(2)建立了 Med-MIM 基准测试,其中包含从 Med-MIM 指令数据集中衍生的保留评估子集。此外,构建了两个未知多图像数据集,以评估模型的泛化零样本多图像视觉能力;
(3)利用 Med-MIM 指令数据集,开发了两个专门用于多图像分析的医疗 VLMs:MIM-LLaVA-Med 与 Med-Mantis。将这些模型与多个当前最优的 VLMs 进行对比,实验结果表明,本文的模型在 Med-MIM 基准测试的保留子集与未知子集上均展现出更优异的多图像视觉性能;
2、方法
本文通过两个步骤构建 Med-MIM 指令数据集与基准测试:多图像数据准备 与指令数据集生成 (如图 1 所示)。在数据准备阶段,本文收集了两种类型的多图像样本:固有多图像样本与组合多图像样本。随后,结合迭代优化的 GPT-4o,用于生成固有 Med-MIM 指令数据集与保留评估子集。同时,通过在原始问答(QA)对后附加特定位置后缀,构建了组合 Med-MIM 指令数据集,以确保与多图像视觉理解的对齐。
Figure 1 | Med-MIM 数据集与基准测试生成流程示意图:
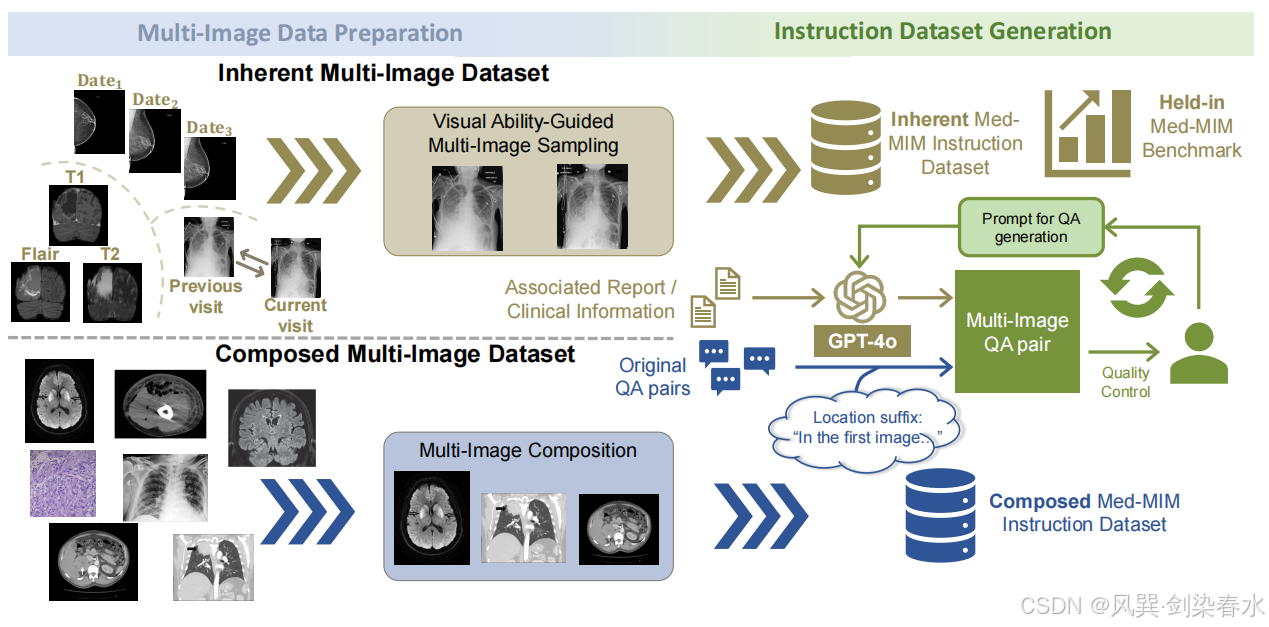
2.1、数据集收集
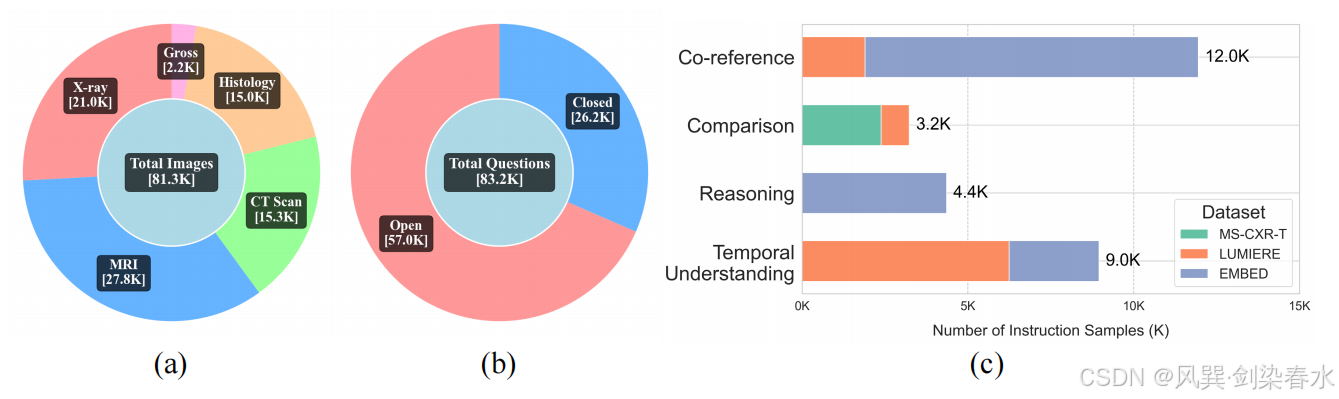
图 2 展示了所构建 Med-MIM 指令数据集的概览:该数据集包含 83.2K 个医疗多图像问答指令样本,涵盖五个主要领域。与以往的医疗指令数据集(如 PMC-VQA 或 LLaVA-Med VQA )主要基于公开文献不同,Med-MIM 指令数据集构建于两个来源:固有多图像数据集 与组合多图像数据集。
固有多图像数据集包含天然存在的多图像场景,例如纵向检查 、多模态 或多视角诊断 等。为了构建高质量的多图像数据集,本文基于各类视觉能力相关任务对多张图像进行分组,利用了三个大规模固有多图像数据集:MS-CXR-T、EMBED 与 LUMIERE。这三个数据集均包含按时间顺序排列的多访视图像,而 EMBED 与 LUMIERE 数据集进一步整合了多视角 与多模态数据。
为进一步提升数据集的丰富度并涵盖更广泛的医疗图像类型,本文通过手动对 LLaVA-Med VQA 数据集中的多张图像进行分组,构建了组合多图像数据集。本文将多图像序列的长度限制为最多三张,以便在有限的计算资源下,既能分组更多的多图像问答对,又能保证视觉 - 语言模型微调的可行性。
Figure 2 | Med-MIM 数据集的综合分析:(a) 图像模态组合;(b) 问题类型分布;( c ) 按照四种核心视觉能力分类的固有多图像数据集分布。
2.2、四种多图像视觉能力
遵循 MANTIS 的方法,可以将所有收集到的多图像样本划分为四个类别,分别对应四种不同的视觉能力(图 2 ( c ))。然而,针对医疗多图像,更具体的任务可与各类能力关联如下:
(1)时间理解 : 聚焦于多访视数据,并按照时间预测任务构建问答对。例如:"给定收集于 {date1} 和 {date2} 的两次连续访视,受试者在下一次访视中是否会患病?" 本文从 LUMIERE 和 EMBED 数据集中筛选出 9K 个时间理解相关样本。
(2)推理: 将推理类型的多图像任务限定为 EMBED 数据集中的多视角诊断,共收集到 4.4K 个样本。该大视觉 - 语言模型智能体将被要求从两个视角(颅尾位与中外侧位)对患者进行诊断,例如:"结合两张乳腺钼靶视图中观察到的特征,这些发现对应的 BI-RADS 分类是什么?"
(3) 比较: 通过对比多张图像,旨在寻找其相似性或差异性。在指令数据集中,本文从 MS-CXR-T 和 LUMIERE 数据集中获取了比较类型的多图像样本。需注意的是,尽管 MS-CXR-T 包含时间关系,但其实际任务是基于先前和当前访视确定进展状态,这要求模型找出两次访视之间的差异。例如:"请解释第一次与第二次 X 射线图像之间的差异。"
(4)共指: 从 LUMIERE 和 EMBED 数据集中构建共指相关子集,通过向模型提问如 "哪张图像(第一张还是第二张)代表了从上方拍摄乳房的视角?" 等问题。通过在问题中融入位置信息,旨在使视觉 - 语言模型能够同时理解图像位置与内容。此外,对于组合多图像数据集,本文也将其归类为共指子集。
为了编码正确的位置信息,本文通过添加如 "在第一张图像中" 或 "在第二张图像中" 等前缀,更新了原始单图像问答对(如图 1 所示)。
2.3、指令数据集生成
收集多图像集后,为每张图像整合文本数据,并生成对应的问答对。与组合 Med-MIM 指令数据集(可通过简单向原始问答对附加特定位置后缀,如 "在第一张图像中")不同,固有 Med-MIM 数据集需要更复杂的方法。为此,本文仅使用语言模型 GPT-4o 生成多图像问答对,利用与每张图像相关的医疗报告或临床信息。同时,本文引入人类评估者作为质量控制措施,对生成结果进行迭代优化,确保其准确性与清晰性。图 3 展示了一个由 GPT-4o 基于 MS-CXR-T 数据集两次访视的医疗报告生成的单图像问答示例。
Figure 3 | MS-CXR-T 数据集中生成的多图像问答对示例:

2.4、基于 Med-MIM 基准测试的多图像视觉能力评估
构建的 Med-MIM 基准测试包含两部分:
(a)保留部分 (Held-in part): 为全面评估四种多图像视觉能力,本文基于 Med-MIM 指令数据集构建了保留部分的 Med-MIM 基准测试,其中包含 2,968 个封闭式示例(时间、推理、共指能力分别为 903、454、208 和 1,403 个),以及 256 个开放式示例(分别为 30、30、136 和 60 个)。
(b)未知部分 (Held-out part): 由于医疗领域多图像视觉能力评估基准有限,本文从两个互补来源精选多图像案例,构建了未知部分的 Med-MIM 评估基准:VQA-RAD(提供结构化问答对,但基于单张医疗图像)与 ODIR(包含配对眼底图像,但缺乏标注问答对)。为适配标准 VQA-RAD 基准以适配多图像场景,本文基于图像模态、解剖位置和语义一致性对图像进行分组。随后,借鉴组合 Med-MIM 指令数据集的方法,从 VQA-RAD 合成组合多图像指令并构建 MIM-RAD 数据集。此外,对 ODIR 数据集采用与固有 Med-MIM 数据集生成相同的流程,生成了 MIM-ODIR 数据集。MIM-RAD 与 MIM-ODIR 两个基准测试均包含 300 个封闭式案例和 300 个开放式案例。
2.5、基于 Med-MIM 指令数据集的指令微调
选取两个主流的视觉 - 语言模型------LLaVA-Med 与 MANTIS 进行指令微调。LLaVA-Med 是医疗领域一款优秀的开源 VLM,而 MANTIS 则是在超过 700K 个多自然图像指令数据上训练得到的模型。
将 VLMs 微调 3 个 epoch,在 NVIDIA A40 GPU 上运行约 72 小时,最终得到两个专用模型:MIM-LLaVA-Med 与 Med-Mantis,二者均擅长理解医疗多图像。
为适配多图像与问题的输入,采用交错图像 - 文本格式,并重构图像嵌入,格式如下:"(image {id}: 图像嵌入 </Image>)"。采用负对数似然损失函数来衡量预测的下一个标记(token)与序列中实际下一个标记之间的差异。具体公式定义于公式 (1),其中 K K K 表示标准响应文本的总标记长度。
L N L L = − ∑ k = 1 K log p ( r k ∣ I , q 1 : S , r 1 : k − 1 ) , I = Concat ( T 1 , I 1 , ... , T N , I N ) . (1) \mathcal{L}{NLL} = -\sum{k=1}^{K} \log p(r^k | \mathcal{I}, q^{1:S}, r^{1:k-1}), \quad \mathcal{I} = \text{Concat}(T_1, I_1, \dots, T_N, I_N). \tag{1} LNLL=−k=1∑Klogp(rk∣I,q1:S,r1:k−1),I=Concat(T1,I1,...,TN,IN).(1) I \mathcal{I} I 由交错文本标记序列 ( T i T_i Ti) 与图像标记序列 ( I i I_i Ii) 构成。 log p ( r k ∣ I , q 1 : S , r 1 : k − 1 ) \log p(r^k | \mathcal{I}, q^{1:S}, r^{1:k-1}) logp(rk∣I,q1:S,r1:k−1) 表示:给定交错标记序列 I \mathcal{I} I、问题标记序列 q 1 : S q^{1:S} q1:S 以及响应序列 r 1 : k − 1 r^{1:k-1} r1:k−1 中的先前标记,生成第 k k k 个标记的概率。
3、实验与结果
3.1、基准和指标
(1)选取了六种不同的当前最优视觉 - 语言模型进行对比,包括:Med-Flamingo-9B 、Deepseek-VL-7B 、LLaVA-Med-7B 、InternVL2-8B 、Mantis-8B 以及 GPT-4o ;
(2)在封闭式(选择题)评估中,以准确率作为评价指标;在开放式(自由回答题)评估中,最终得分由 BERT 召回率、BLEU 分数和 rouge-L 召回率的平均值计算得出;
3.2、Med-MIM基准测试的主要结果
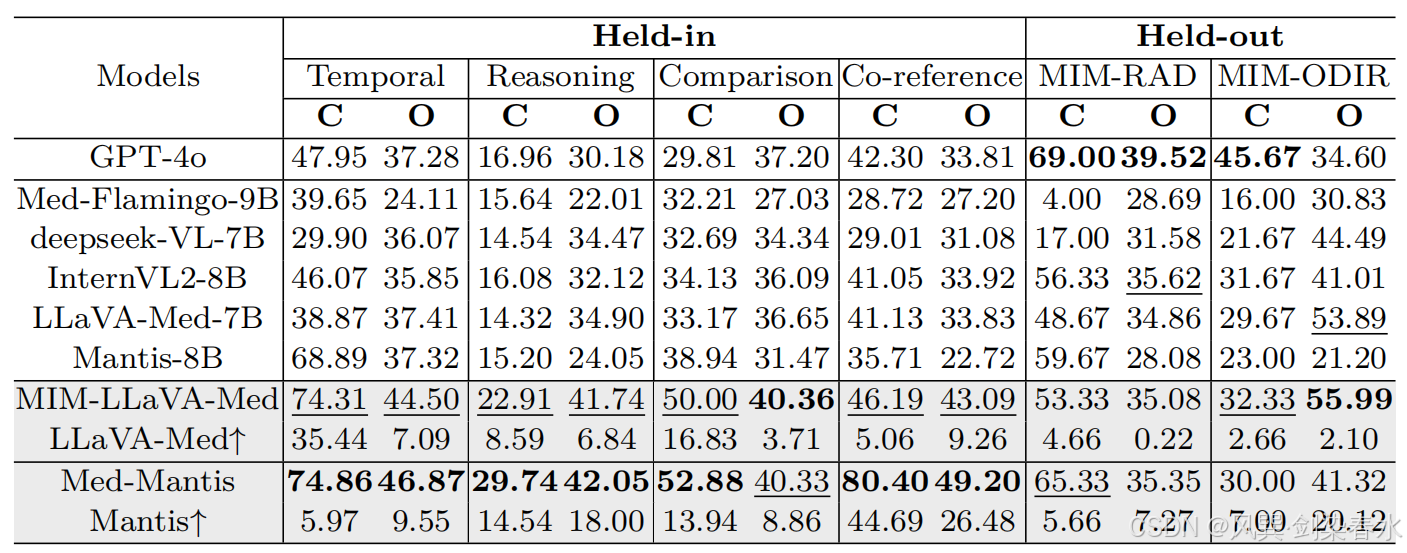
**Table 1 | 模型在保留型 Med-MIM 基准测试(时间理解、推理、比较、共指)以及未知型 Med-MIM 基准测试(MIM-RAD、MIM-ODIR)上的性能对比:**结果以百分比(%)表示。C 和 O 分别代表封闭式分数与开放式分数;
3.3、消融实验
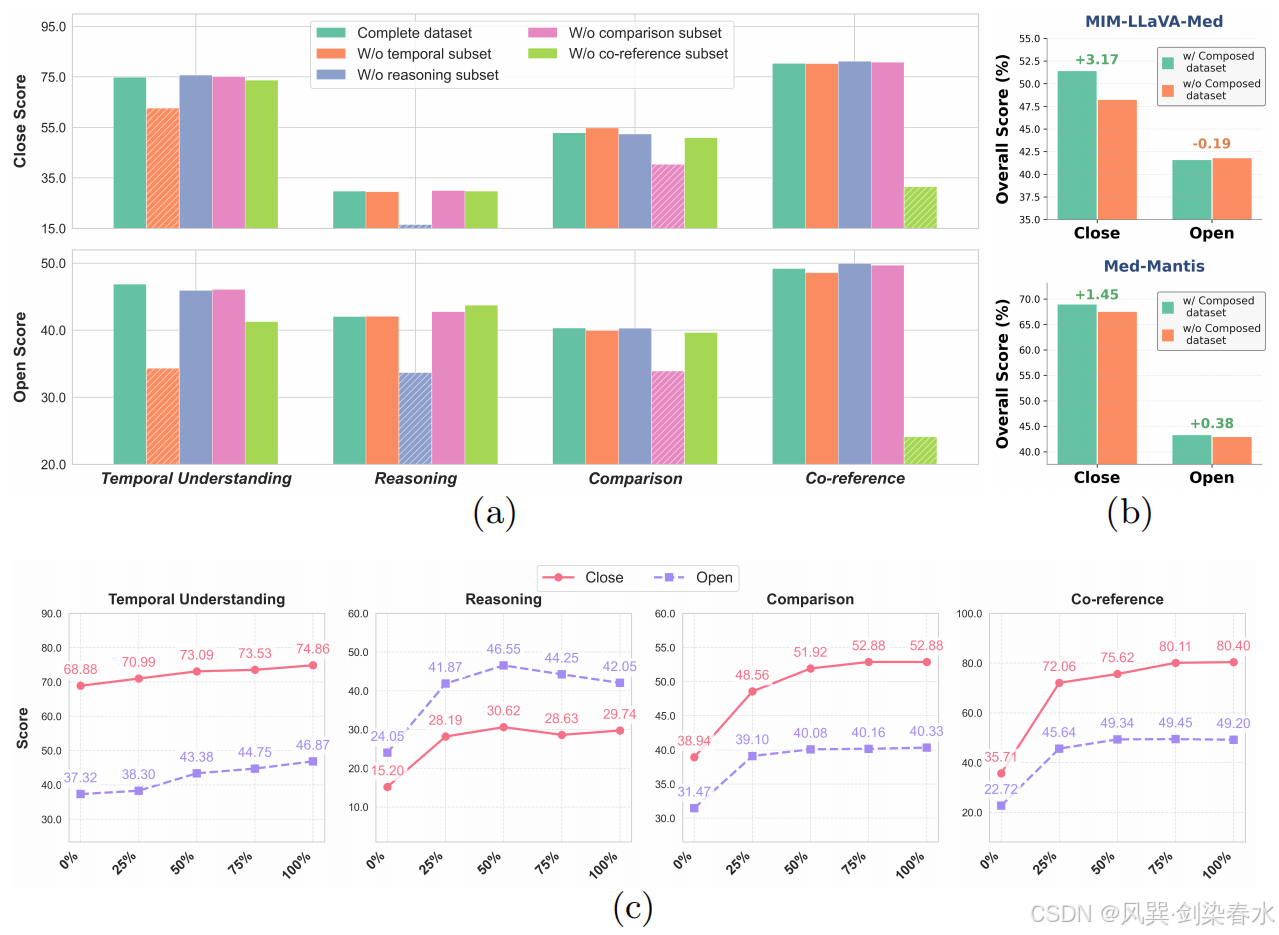
**Figure 4 | 消融实验结果:**包括:(a) Med-Mantis 模型在四个视觉能力子集上的表现;(b) Med-Mantis 与 MIM-LLaVA-Med 模型在使用与不使用组合 Med-MIM 指令数据集时的性能对比;(c ) 不同规模的 Med-MIM 指令数据集对 Med-Mantis 模型性能的影响;
3.4、个案研究
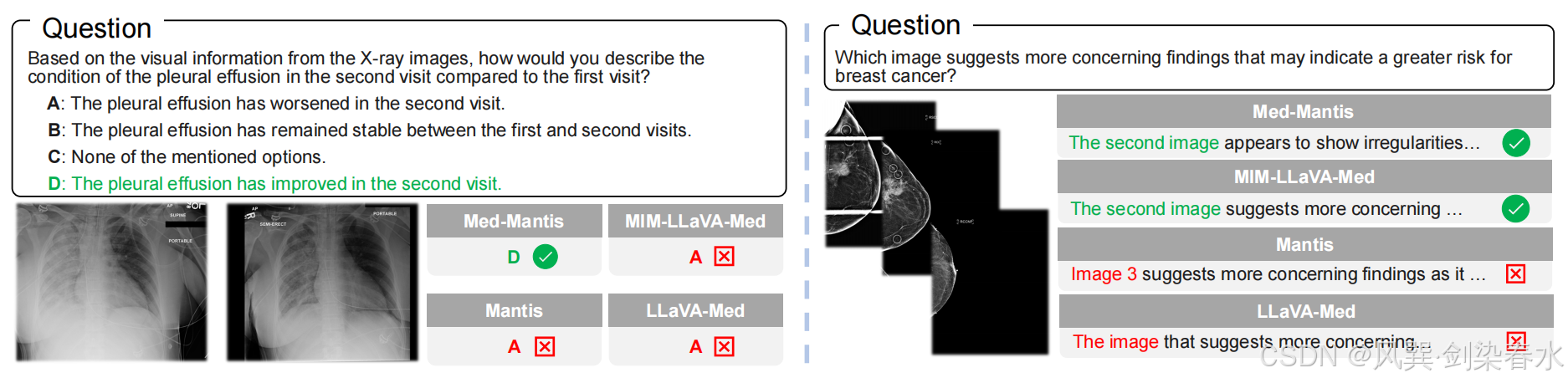
与原始 Mantis 和 LLaVA-Med 模型相比,Med-Mantis 和 MIM-LLaVA-Med 能够产生更准确的响应。
Figure 5 | 医学多图像理解中 LVLM 的案例研究:
多视图,多序列理解从临床角度出发( •̀ ω •́ )✧