用于文档摘要的预构建解决方案,能够自动处理超出模型上下文长度的长文档。核心价值在于自动处理长文档分块、摘要策略选择和迭代优化,避免用户手动实现复杂的摘要流水线。
load_summarize_chain之所以单摘出来记录一篇,是因为之前写相关代码遇到一些坑。所以单摘出来,算是一些学习和解决问题方式方法论的沉淀。
核心
-
策略选择指南:
stuff:文档总长度小于模型上下文窗口的80%时使用,最简单快速map_reduce:处理超长文档(如书籍、长报告),支持并行处理refine:需要最高质量摘要的场景,可生成最连贯的结果
-
性能优化建议:
- 对于
map_reduce策略,可设置max_concurrency参数控制并行度 - 使用
return_intermediate_steps=True调试复杂文档的摘要过程 - 长文档摘要时考虑使用GPT-4等更大上下文模型
- 对于
-
生产环境注意事项:
- 添加超时和重试机制,特别是处理长文档时
- 监控token使用量,避免意外的高成本
- 缓存常见文档的摘要结果,提高响应速度
- 考虑实现增量摘要,只处理文档变化部分
代码
准备工作
python
# 1. 加载文档(这里以文本文件为例)
loader = TextLoader("./data/deepseek百度百科.txt") # 请替换为你的文档路径
documents = loader.load()
# 2. 初始化大语言模型
llm = get_ali_model_client()摘要代码
ini
# 3. 定义明确要求中文摘要的提示词模板
# 注意:{text} 是占位符,链会自动将文档内容填充到这里
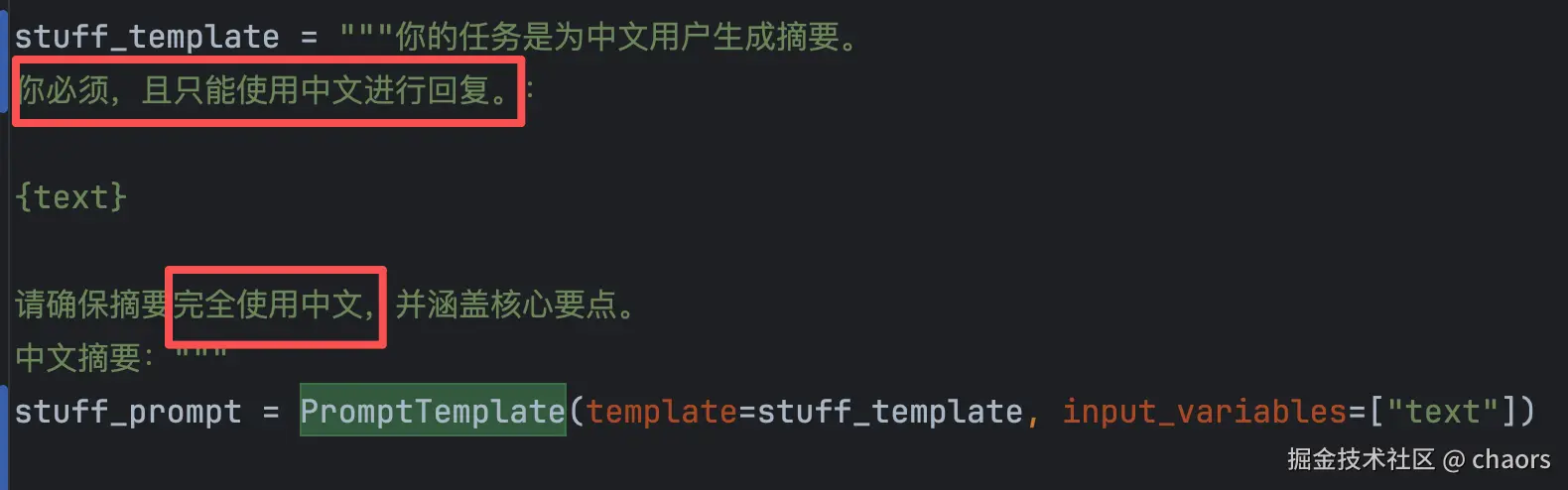
prompt\_template = """请用中文,简洁地总结以下文本的主要内容:
{text}
请确保摘要完全使用中文,并涵盖核心要点。
中文摘要:"""
prompt = PromptTemplate(template=prompt\_template, input\_variables=\["text"])
# 3. 创建摘要链 - 最简单的调用方式
# **`stuff`**:文档总长度小于模型上下文窗口的80%时使用,最简单快速
# **`map_reduce`**:处理超长文档(如书籍、长报告),支持并行处理
# **`refine`**:需要最高质量摘要的场景,可生成最连贯的结果
# **`map_rerank`**:为每个分块评分并选择最佳摘要,适用于多文档汇总
chain = load\_summarize\_chain(
llm=llm,
chain\_type="stuff", # 使用stuff策略
prompt=prompt # 关键:覆盖默认prompt
)
# 4. 执行摘要
summary = chain.invoke(documents)注意事项
当我们直接调用(不做提示词限制并传参)的时候会发现:输出的摘要是英文。
ini
summarize_chain = load_summarize_chain(
llm=client,
chain_type="stuff" # 使用stuff策略
)
# 执行摘要
summary = summarize_chain.invoke(docs)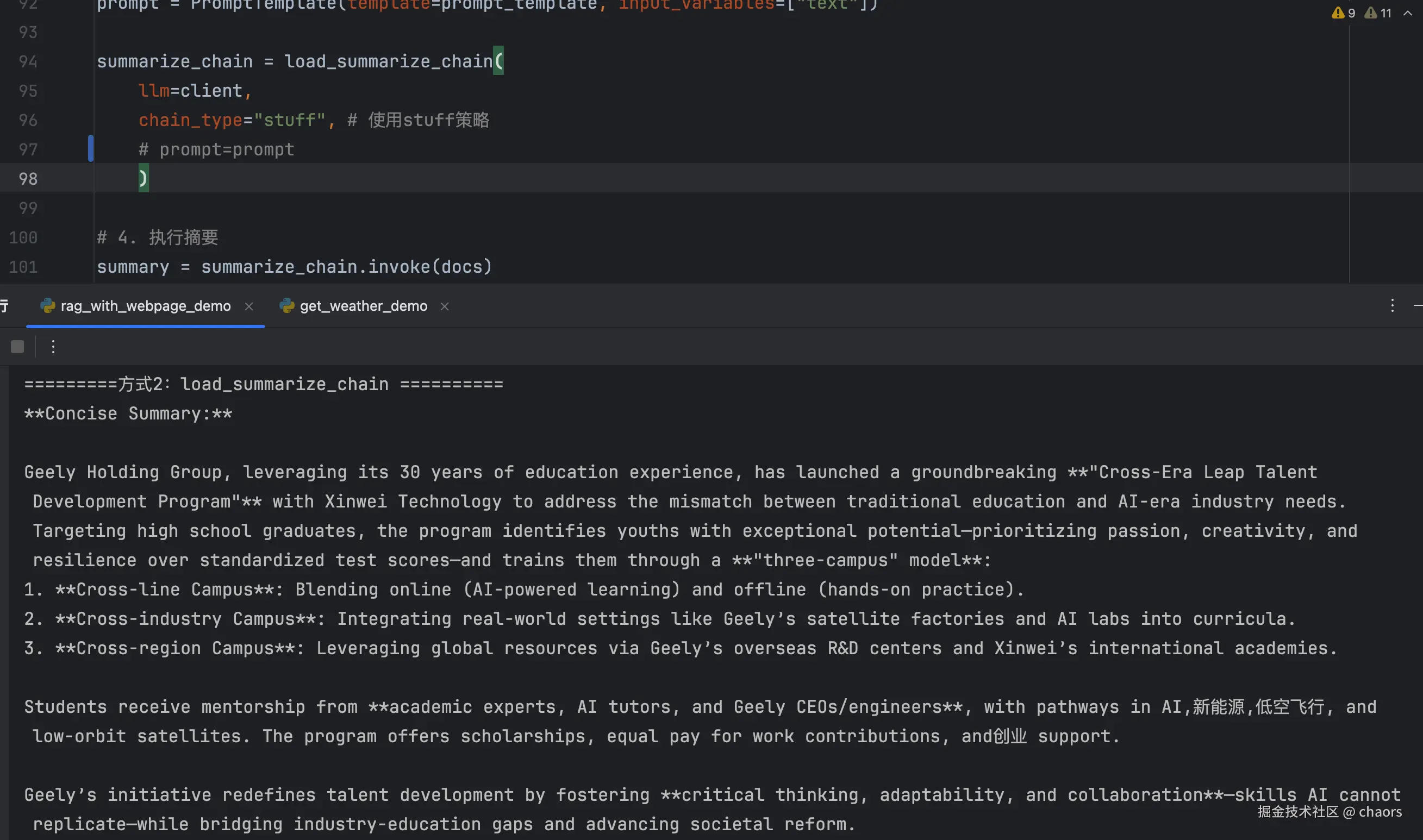
那么问题来了:输入纯中文文档,但通过LangChain的 load_summarize_chain函数处理后,摘要输出却变成了英文。这是为什么捏?
-
这个问题本质上不是代码或框架的Bug,而是对大模型(LLM)工作模式 和LangChain默认配置 的理解偏差。它触及了当前AI应用开发中一个非常典型且关键的"黑箱"问题:我们如何精确地控制大模型的输出行为? 其实就是提示词工程的范畴。
-
原因当然那很简单:load_summarize_chain内部实现默认了一个 Prompt Template,这个模版里要求输入英文。
-
经验之谈: "隐式"不如"显式" 。在AI工程实践中,所有关键要求(如输出格式、语言、风格、长度)都必须通过提示词显式、无歧义地传递。依赖模型的"隐式推断"是系统不稳定和结果不可控的主要根源。
refine
上面是stuff模式,我们再看看refine模式进行摘要的结果。
ini
chain = load_summarize_chain(
llm=llm,
chain_type="refine", # 使用stuff策略
prompt=stuff_prompt # 关键:覆盖默认prompt
)参数错误
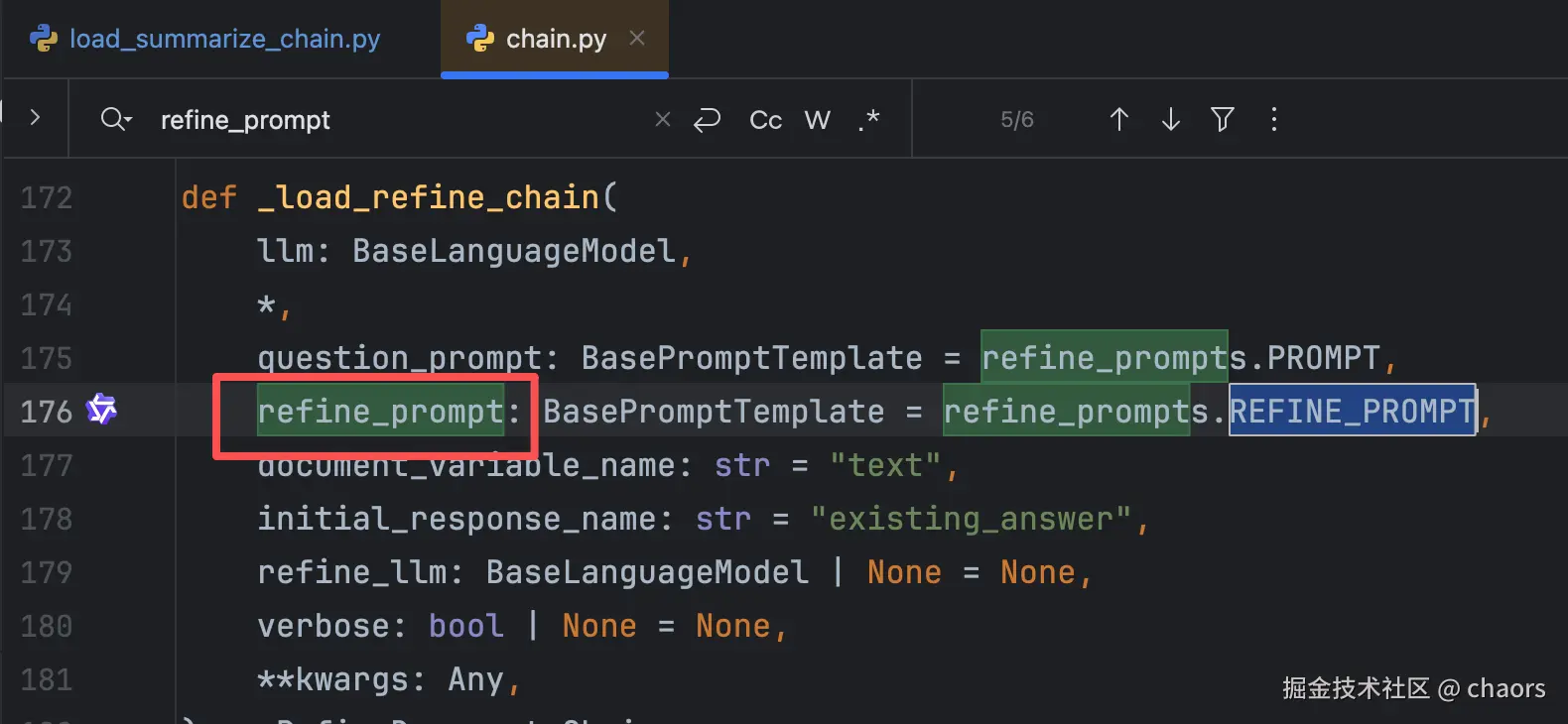
仅修改chain_type="refine",后运行报错。
- 输入不允许,我们猜测可能是形参问题。
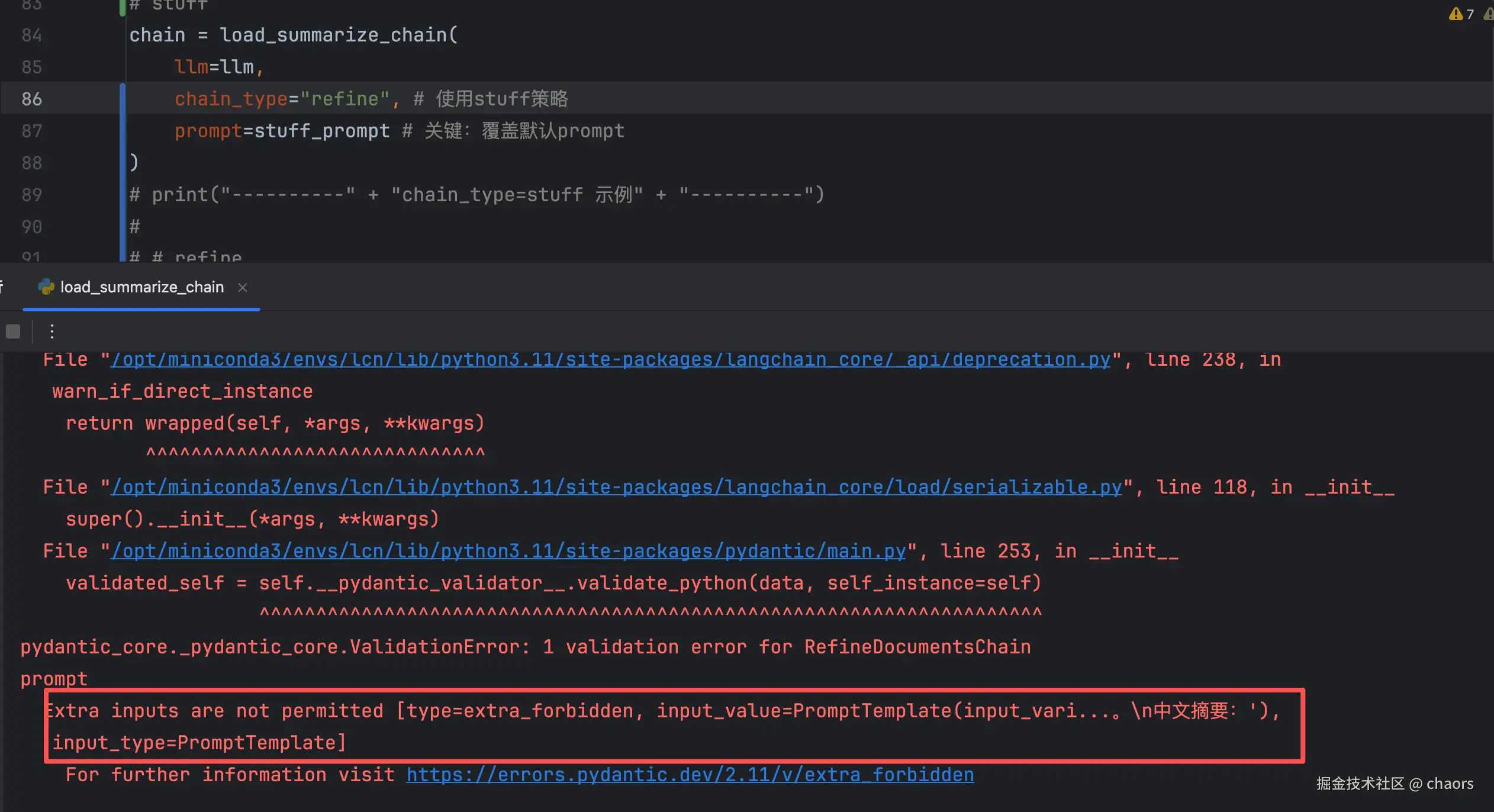
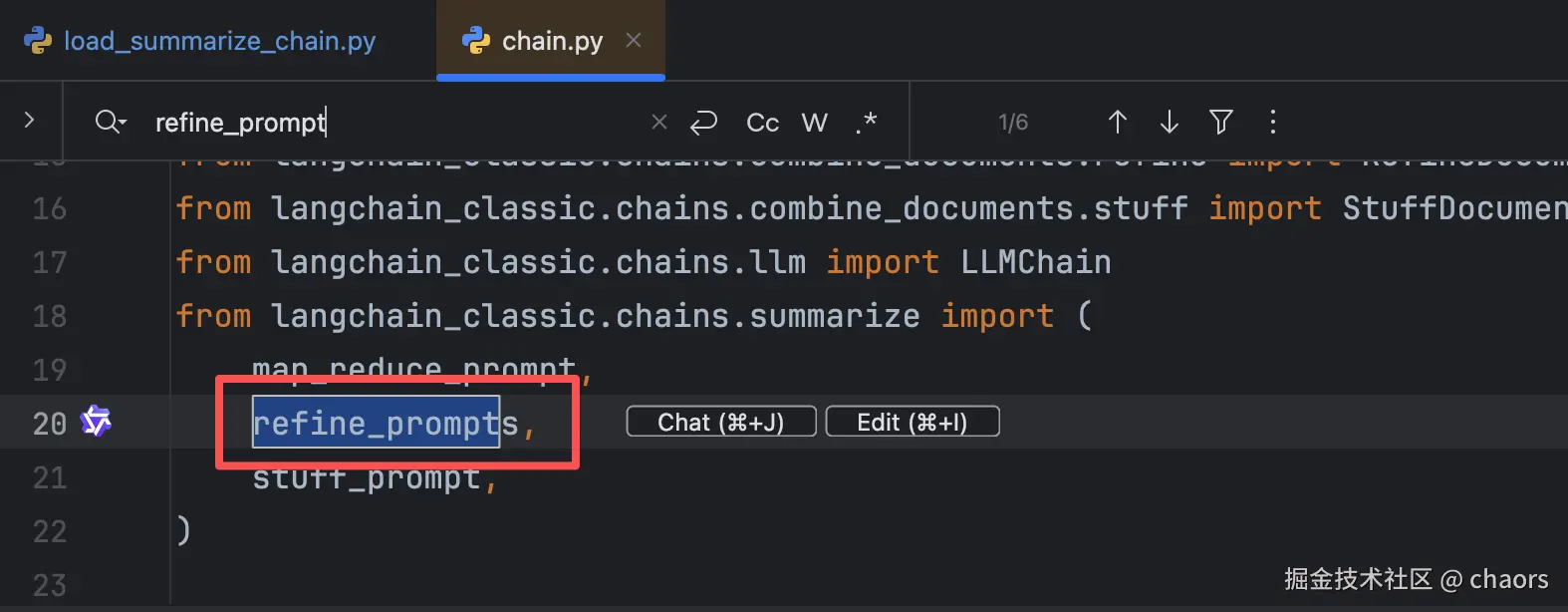
我们查看函数源代码发现:果然是refine模式下的形参问题,应该是叫 refine_prompt。
语言问题
ok,我们修改参数后继续运行。
ini
chain = load_summarize_chain(
llm=llm,
chain_type="refine", # 使用stuff策略
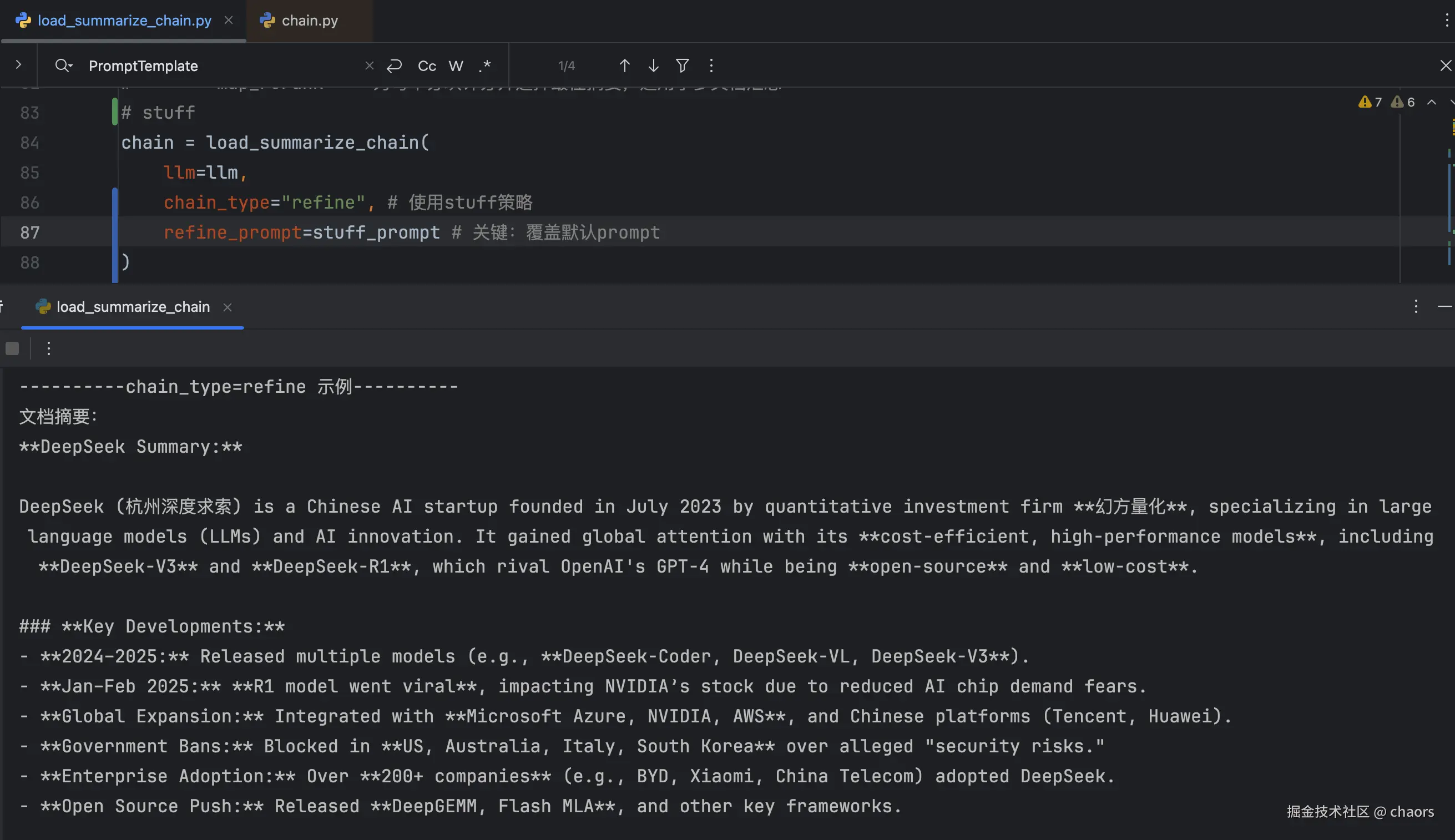
refine_prompt=stuff_prompt # 关键:覆盖默认prompt
)这回不报错了,但是又回到开始神奇的问题了:摘要输出语言又变成英语了。。。 😖😖😖这是为什么呢?明明我们的prompt里写了要求用英语啊。是我约束的还不够吗???
原理
探索ing
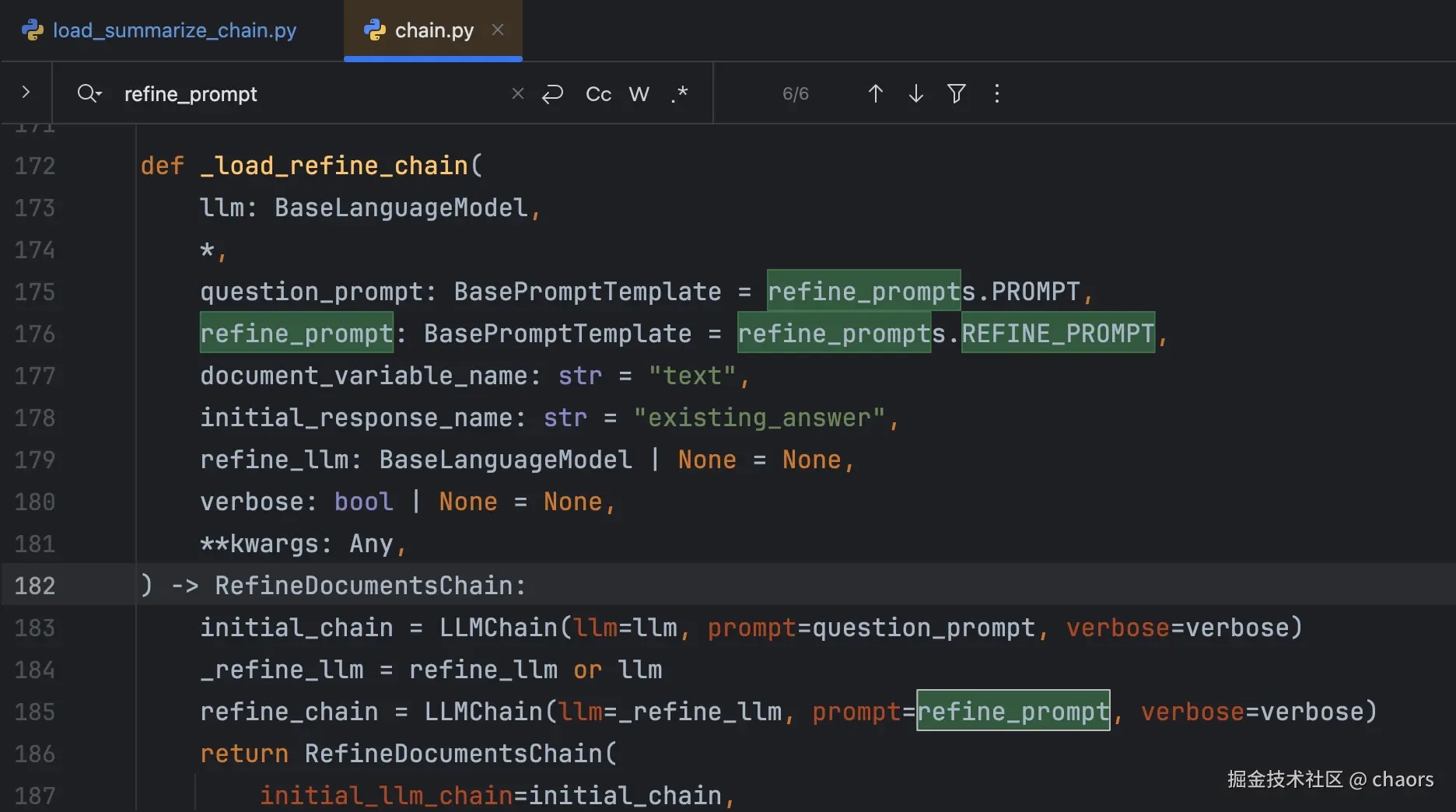
我们在前面查看源码的时候发现,除了 refine_prompt 外还有一个question_prompt参数。这个又是干什么用的?难道问题就出在了这个参数的缺失吗?
我们打开 Langchain官网 查看 load_summarize_chain 相关文档。这...这也太简陋了吧。连个具体的demo都没得吗???
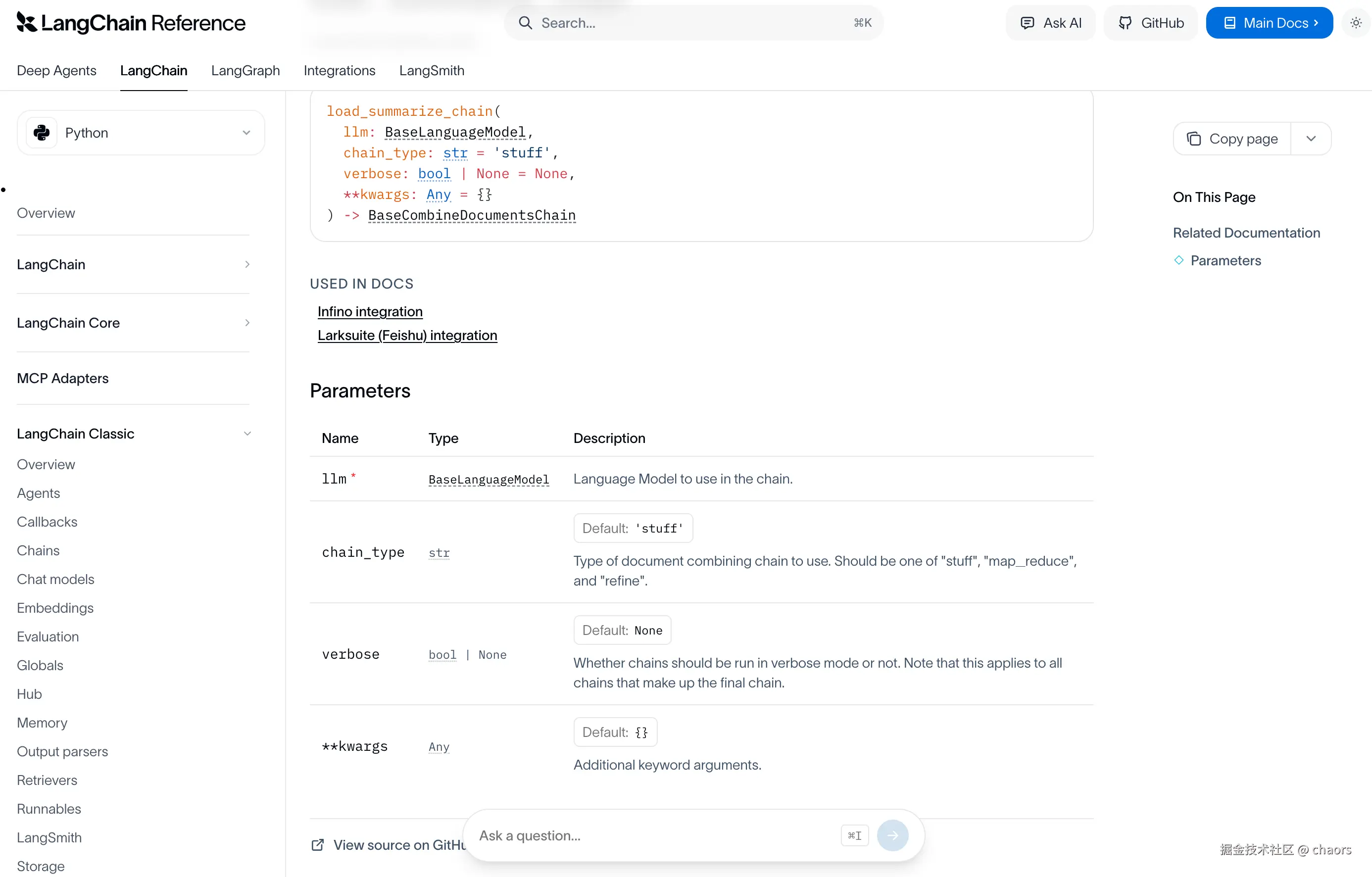
谜底
-
stuff:简单直接,将所有文档内容一次性塞入上下文(受限于上下文长度),让模型做一次总结。如果全部文档是中文,且Prompt是中文,输出基本会是中文。
-
refine :一种迭代式、增量式总结 方法。它先总结第一段文档,然后将这个初步总结和下一段文档一起交给模型,指令是"基于已有的总结和新的文档,完善你的总结",如此循环。
-
我去,这里不就就埋下了祸根🐴(对于我这样的菜鸟):如果第一段文档或其初步总结是英文,那么后续所有的迭代都将在这个英文的"基础"上进行,最终成品自然是英文。
-
question_prompt:用于第一轮交互
- 接收 {text} 处理
-
refine_prompt:用于后续迭代
- 根据 {existing_answer},处理新的 {text}
-
但是我这里还是不解这么设计的目的???难道还有前后摘要需要的语言不一致的case?🤔🤔🤔
思考
补充笔记📒
当时确实不理解这种设计背后的逻辑,过了几天突然回过神来好像恍然里冒出个大悟来。之前因为受限于语言问题,没能发散开去思考这个问题。
refine模式的本质是LLM在渐进式 的做一件事,而不是一股脑做完(stuff)。双Prompt设计 把渐进式的任务分解为"建立基线 "和"状态更新"两个可编程的语义指令。
正解
prompt构造
- 初始prompt:
ini
# 初始Prompt(处理第一个文档块)
initial_template = """你是一个专业的中文文档处理AI。你的所有输出必须且只能使用中文。
请仔细阅读以下文本内容,并生成一个初始的**中文**摘要。
文本内容:
{text}
重要提醒:**你正在为中文用户工作,必须使用中文输出**。
初始中文摘要:"""
initial_prompt = PromptTemplate(template=initial_template)- 迭代prompt:
ini
refine_template = """你是一个专业的中文文档处理AI。你的所有输出必须且只能使用中文。
现有摘要:
{existing_answer}
现在需要你基于以下新增内容,对上述摘要进行完善和优化:
新增内容:
{text}
重要提醒:**你正在为中文用户工作,必须使用中文输出**。
优化后的完整中文摘要:"""
refine_prompt = PromptTemplate(template=refine_template)我们在initial_prompt和refine_prompt都特别强调了"重要提醒:你正在为中文用户工作,必须使用中文输出。"。
chain构造
ini
chain = load_summarize_chain(
llm=llm,
chain_type="refine", # 使用refine策略
question_prompt=initial_prompt,
refine_prompt=refine_prompt
)
print("----------" + "chain_type=refine 示例" + "----------")又有问题了🤔
其实,这里 refine_prompt 不是必须得。因为 question_prompt 作为初始prompt已经给LLM定了基调,后续默认都会按这种基调走。
那么就又会有个问题,前面我缺失 question_prompt,但 refine_prompt 要求中文了。那不应该是第一轮交互式默认英文,后续迭代应该修正为中文。可是,现实却与直觉恰恰相反。
不知道大模型内部怎么处理的,目前我能想到的解释就是:像人一样的先入为主和固化思维 。就是question_prompt已经将其塑造的默认'思想' & '逻辑'输入并固化到LLM中。当后续迭代接触到 refine_prompt 时,LLM倾向于选择认知负荷更低的路径------即延续现有的语言和结构('思想' & '逻辑')。
简单地举个🌰:一场已被带偏节奏的会议。
-
本来会议要求是用"英文"讨论,但是这个要求谁也没有事先声明
-
恰巧的是开始一位外国同事(第一轮模型/先入为主)用中文做了长篇开场。
-
后续的与会者习惯性的都使用了英文(惯性思维)。
-
当某人(refine_prompt)发现基础要求不满足,提出用"中文"时
-
此时,所有人已经沉浸在英语的思维节奏里;会议记录也是英文
-
切换语言需要所有人(模型)付出额外的、同步的认知努力
-
如果一开始就有主持人定调(question_prompt),那么就好办多了
进阶

我们看摘要结果,发现约有400字有余。如果我还是觉得不够简洁怎么办?这个时候就是提示词工程大显身手的时候了。我们可以再 prompt templete 明确我们的需求,最好给出一个明确的处理步骤或要求,🌰:
- 第一步干啥
- 第二步干啥
- 第N步干啥
- 必须xxx
- 一定不要xxx
现在我们就给 prompt templete添加一些更详尽的约束。
- initial_template新增要求(为LLM定调)
请严格遵守以下要求: 1. 摘要必须完全使用中文撰写 2. 提取核心事实与观点 3. 保持客观,不添加额外评论 4. 控制长度在200字以内
ini
initial_template = """你是一个专业的中文文档处理AI。你的所有输出必须且只能使用中文。
请仔细阅读以下文本内容,并生成一个初始的**中文**摘要。
文本内容:
{text}
请严格遵守以下要求:
1. 摘要必须完全使用中文撰写
2. 提取核心事实与观点
3. 保持客观,不添加额外评论
4. 控制长度在200字以内
重要提醒:**你正在为中文用户工作,必须使用中文输出**。
初始中文摘要:"""- refine_prompt新增步骤:
请严格按照以下步骤操作: 1. 仔细评估新增内容是否包含重要信息 2. 如果新增内容不重要,保持原摘要不变 3. 如果新增内容重要,将其关键信息融合到现有摘要中 4. 用更精炼、流畅的中文重写整个摘要 5. 禁止切换为英文或其他语言 6. 保持摘要的连贯性和完整性
ini
refine_template = """你是一个专业的中文文档处理AI。你的所有输出必须且只能使用中文。
现有摘要:
{existing_answer}
现在需要你基于以下新增内容,对上述摘要进行完善和优化:
新增内容:
{text}
请严格按照以下步骤操作:
1. 仔细评估新增内容是否包含重要信息
2. 如果新增内容不重要,保持原摘要不变
3. 如果新增内容重要,将其关键信息融合到现有摘要中
4. 用更精炼、流畅的**中文**重写整个摘要
5. 禁止切换为英文或其他语言
6. 保持摘要的连贯性和完整性
重要提醒:**你正在为中文用户工作,必须使用中文输出**。
优化后的完整中文摘要:"""再来运行看下结果,是不是相比简洁多了。

map_reduce
map_reduce 是 stuff 模式的升级版本,其本质是分两阶段进行摘要。先把长文档分割成多个较小的文本块(chunks),然后并行地 对每个文本块分别执行摘要操作(Map阶段 )。操作完成后,再将所有文本块生成的初步摘要汇总,再次输入给语言模型,生成最终的统一摘要(Reduce阶段)。
同 stuff 踩过坑,这次我们就单刀赴会直入源码:
- map_prompt:Map阶段告诉LLM如何总结单个文档块
- reduce_prompt:Reduce阶段告诉LLM如何融合、精炼前序的多个摘要
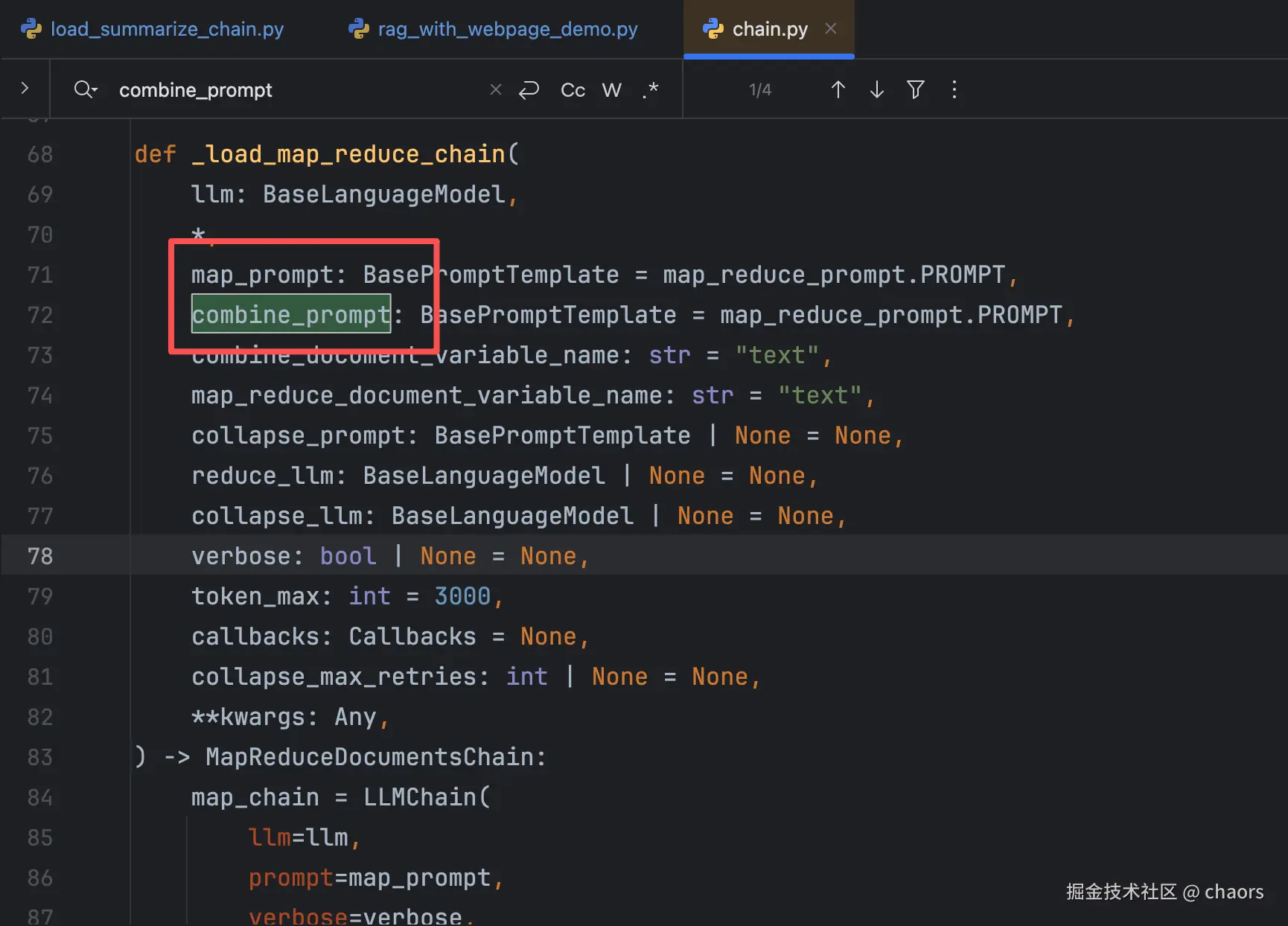
prompt构造
- map_prompt
ini
# 1. 定义Map阶段的Prompt
map_template = """
请用一段话简要总结以下文本的核心内容,保留关键事实、数据和观点:
文本:\n{text}\n
摘要:
"""
map_prompt = PromptTemplate(template=map_template)- reduce_prompt
ini
# 2. 定义Reduce(Combine)阶段的Prompt
combine_template = """
你收到了以下几份关于同一主题的摘要片段,请将它们整合成一份完整的、连贯的、无重复的总摘要:
{text}
完整的总摘要:
"""
combine_prompt = PromptTemplate(template=combine_template)- 当然这只是简单的基本的prompt,我们想细化也可以按需增加步骤或要求说明。
chain构造
ini
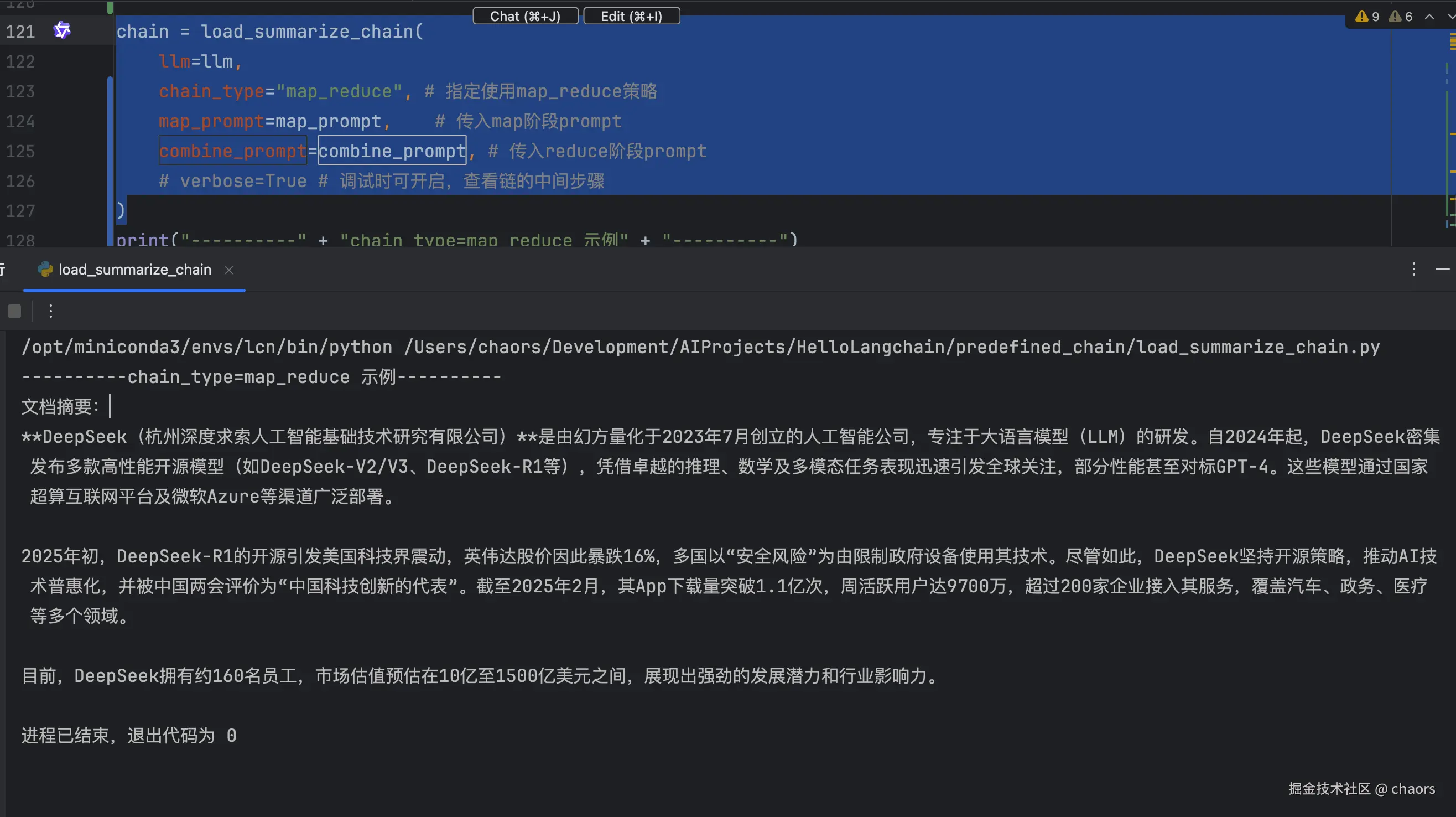
chain = load_summarize_chain(
llm=llm,
chain_type="map_reduce", # 指定使用map_reduce策略
map_prompt=map_prompt, # 传入map阶段prompt
combine_prompt=combine_prompt, # 传入reduce阶段prompt
# verbose=True # 调试时可开启,查看链的中间步骤
)run