这篇文章开始介绍千问系列的VL多模态模型,包括Qwen-VL、Qwen2-VL、Qwen2.5-VL、Qwen3-VL
Transformer介绍可以看:深度学习基础-5 注意力机制和Transformer
多模态基础知识点可以看:多模态-1 基础理论
Qwen-VL原论文:《Qwen-VL: A Versatile Vision-Language Model for Understanding, Localization, Text Reading, and Beyond》
Qwen-VL采取的也是类似BLIP2的适配器方法(BLIP2详细介绍可以看:多模态-5 BLIP2),在图像编码器和语言大模型(LLM)之间插入一个适配器,对齐图像特征、文本特征的语义,但是Qwen-VL在自己的训练数据集上分阶段的重新训练了图像编码器和语言大模型,而BLIP2只训练适配器Q-Former。
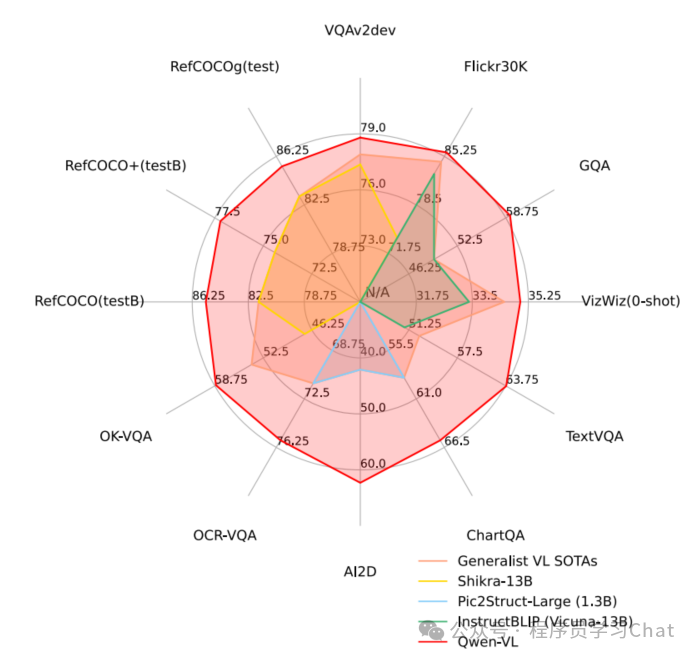
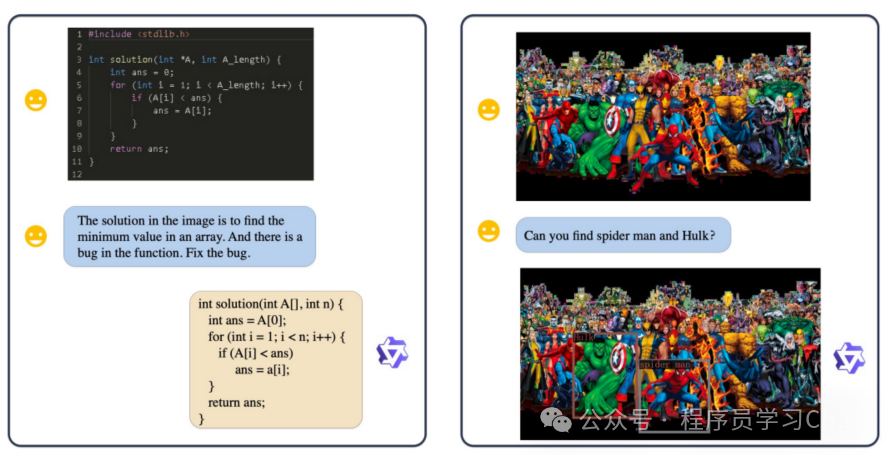
以往的VL模型一般都是面向英文的,Qwen-VL支持中英双语,中文友好,而且除了支持图像理解、问答任务外,还支持Grounding任务(多模态模型的Grounding任务介绍可以看:多模态-7 Grounding DINO)、OCR文本提取,在多个公开评测数据集上,达到了当时最优的开源模型效果。



一 模型结构
模型结构如下:

整体由以下三个组件构成:
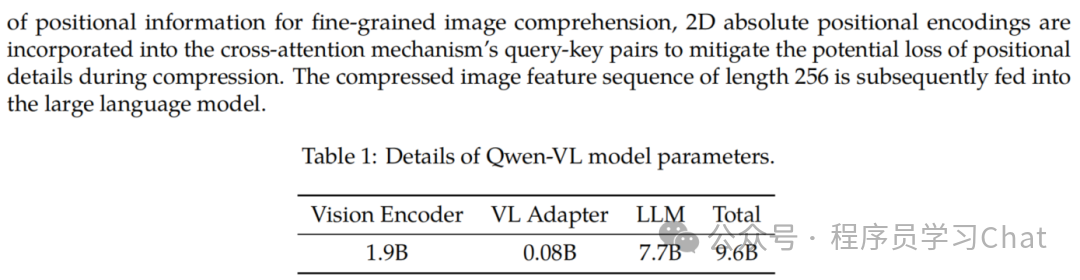
1)图像编码器:Vision Encoder,论文中使用的是ViT结构,ViT的详细介绍可以看:计算机视觉Transformer-1 基础结构
2)视觉-语言特征适配器:VL Adapter,cross attention层,负责从图像编码器输出结果中提取和文本最相关的视觉特征,将视觉特征转换为语言大模型可以理解的特征(语义对齐)
3)语言大模型:LLM,论文中使用的是Qwen 7B

而且ViT输出的图像特征编码序列长度过大,会增加整体模型的计算负担

VL Adapter由交叉注意力层(cross attention)+位置编码构成




为了统一处理图像编码器输出的图像特征编码表示和文本特征编码表示,Qwen-VL在图像特征编码表示的前后添加了img/img标记,用于标记一个图像特征编码表示的开始和结束,img类似于BERT中的cls标记符号,但是二者存在一些区别



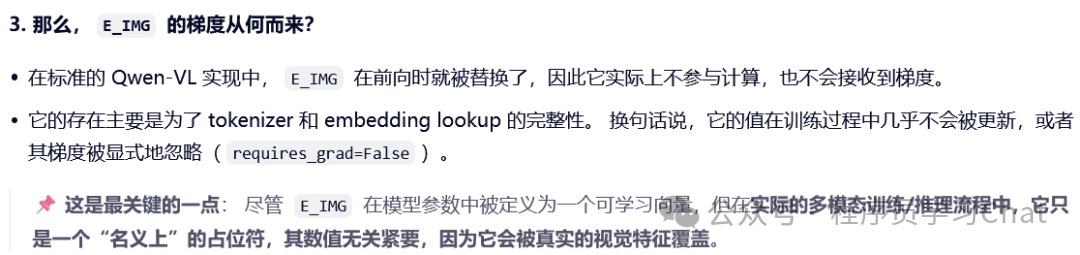
img 是一个"名义上可学习、实际上被忽略"的占位符向量,不参与训练,随机初始化成什么值都没有关系,它的主要作用就是标记图像特征编码表示的起止,可以自然的将图像编码特征引入到以往语言模型输入处理的流程中。
类似img标签,为了让Qwen-VL具备Grounding的能力,需要将物体的bounding box也引入进来,Qwen-VL利用box/box符号标记一个bounding box的起止,并且对物体的坐标值进行了转换,将坐标值转换到0,1000范围内

需要注意box标记是一个随模型训练可学习的向量


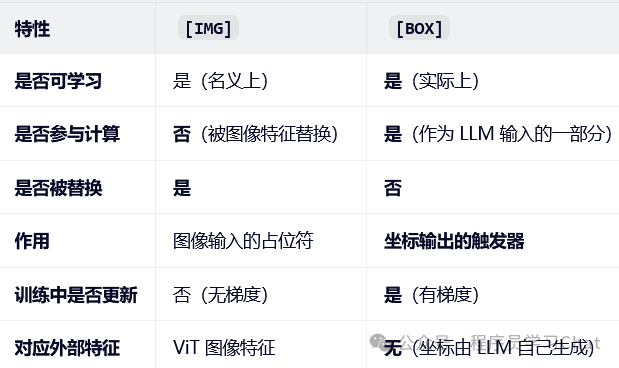

为了让Qwen-VL能建立起bounding box和对应图像区域的关联,引入了ref/ref符号表示,简单理解就是告诉模型bounding box区域对应的内容是什么


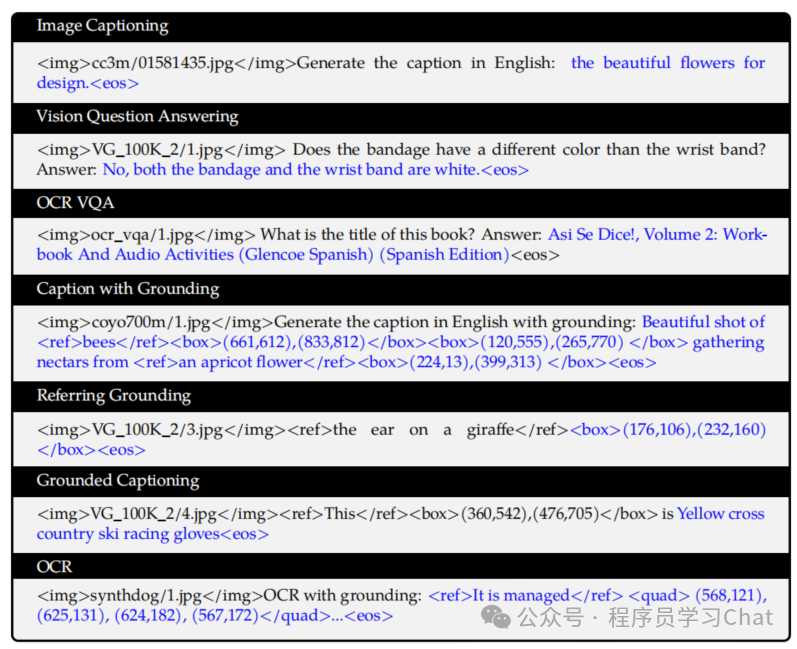
一个完整结合img、box、ref三者的训练数据如下:



ref标记在 Qwen-VL 中是一个纯粹的、结构性的文本标记。它与 box标记成对出现,共同构成一种"富文本"格式,用于在训练数据和模型输出中,显式、无歧义地将一段文本描述与其在图像中的空间位置(bounding box)绑定到一起。在训练时它教会模型"当看到<ref>X</ref><box>Y</box>时,X描述的就是Y这个框里的东西",在推理时它允许模型以同样结构化的格式回答问题,从而下游应用可根据这些标记符号进行精确的解析和可视化。
二 训练
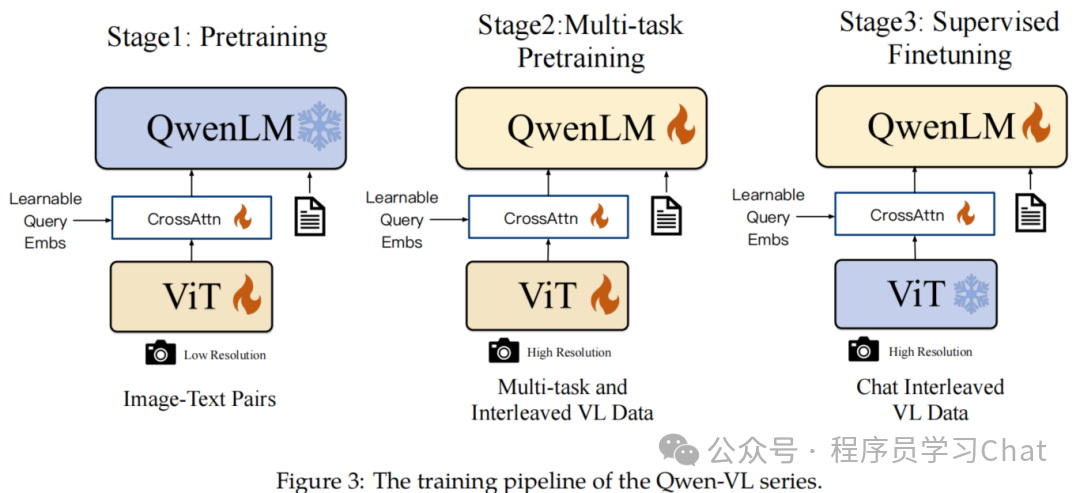



Qwen-VL的训练整体分为三个阶段:
1)Pre-training:预训练,学习通用的图像-文本语义对齐,冻结 LLM,只训练 ViT 和 VL Adapter
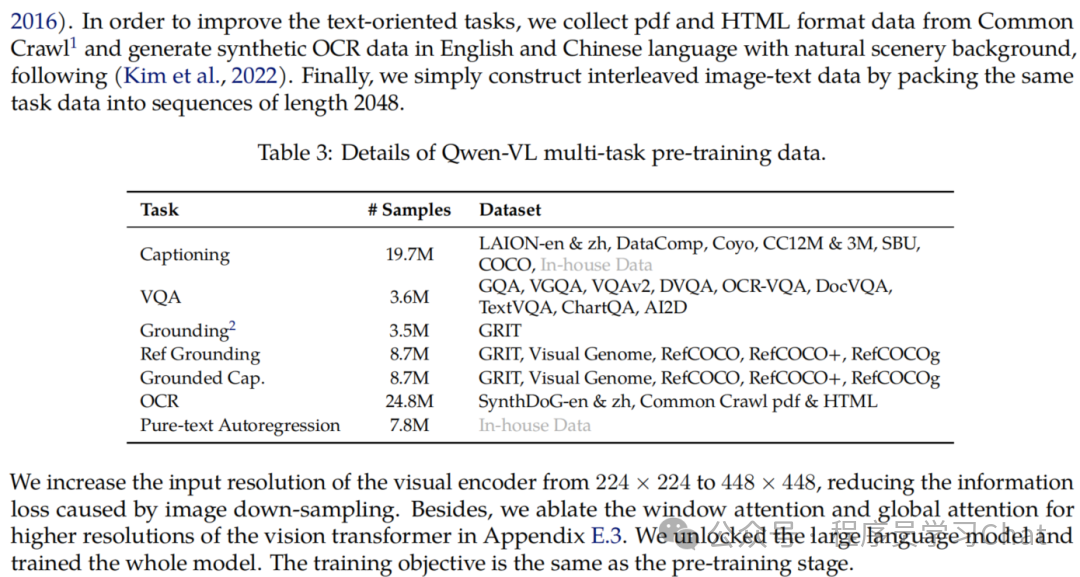
2)Multi-task Pre-training:多任务预训练,学习细粒度的视觉理解(OCR、定位),解冻 LLM,使用高分辨率输入,7个VL任务联合训练
3)Supervised Fine-tuning:监督微调,学习指令遵循和对话能力,使用对话数据,冻结 ViT,只训练 LLM 和 Adapter

2.1 Pre-training


2.2 Multi-task Pre-training



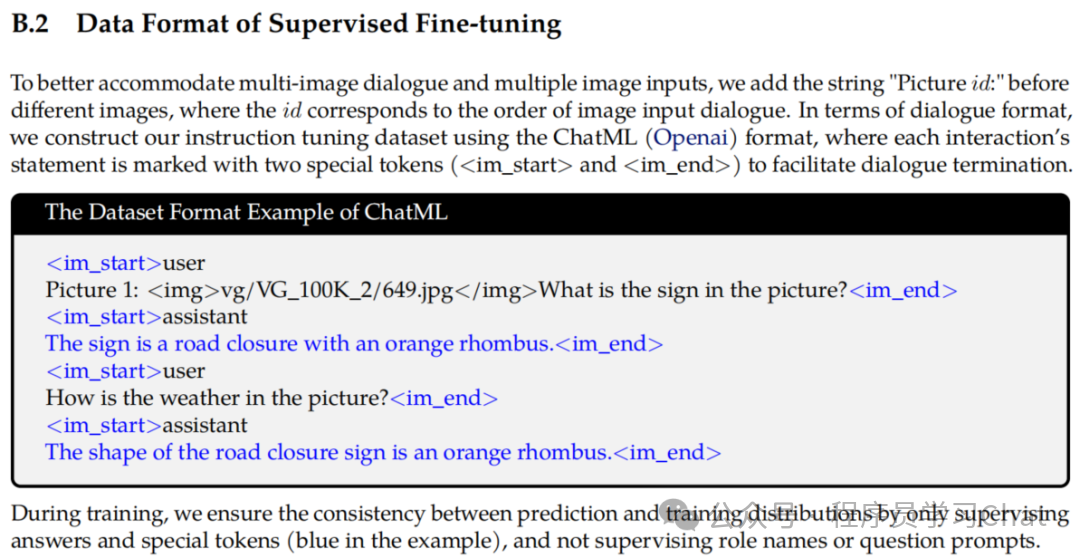
2.3 Supervised Fine-tuning


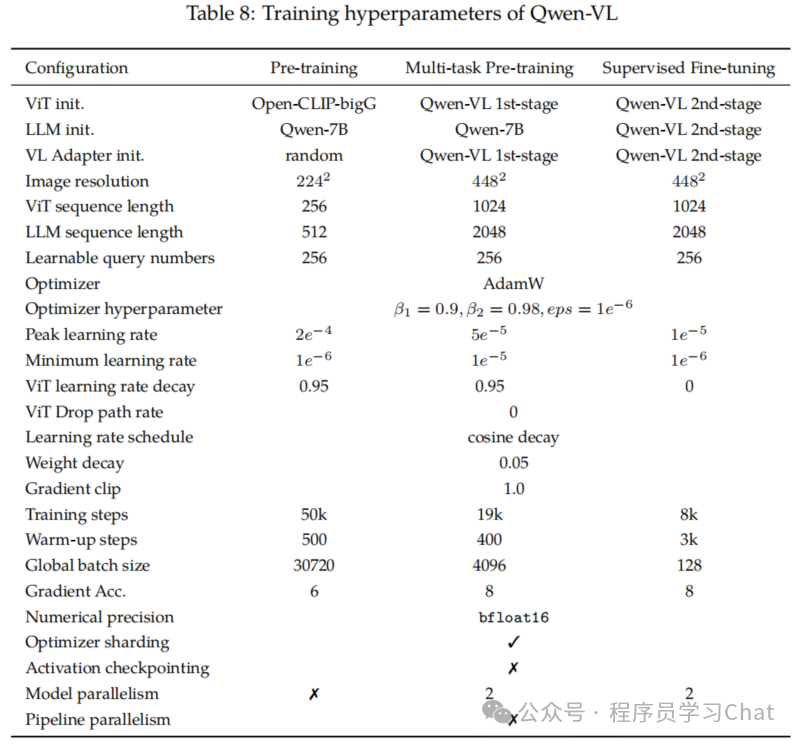
2.4 训练细节

三 数据集构建
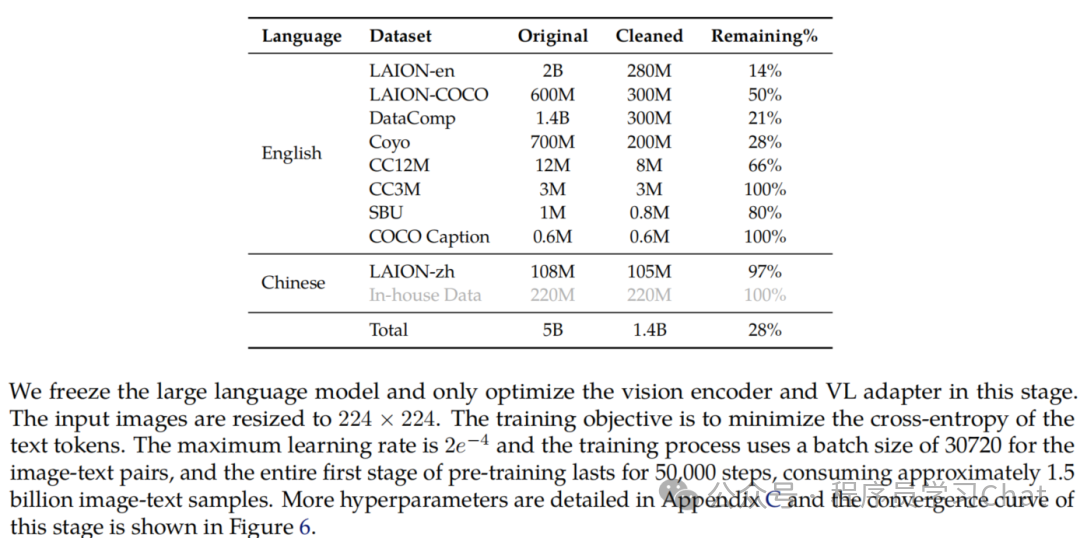
3.1 数据处理
3.1.1 图文数据处理






3.1.2 VQA、Grounding数据处理




3.1.3 OCR数据处理


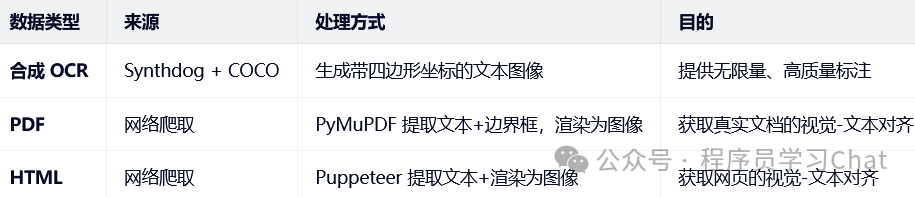
ocr数据合成:

PDF处理:


HTML处理:

3.2 数据格式

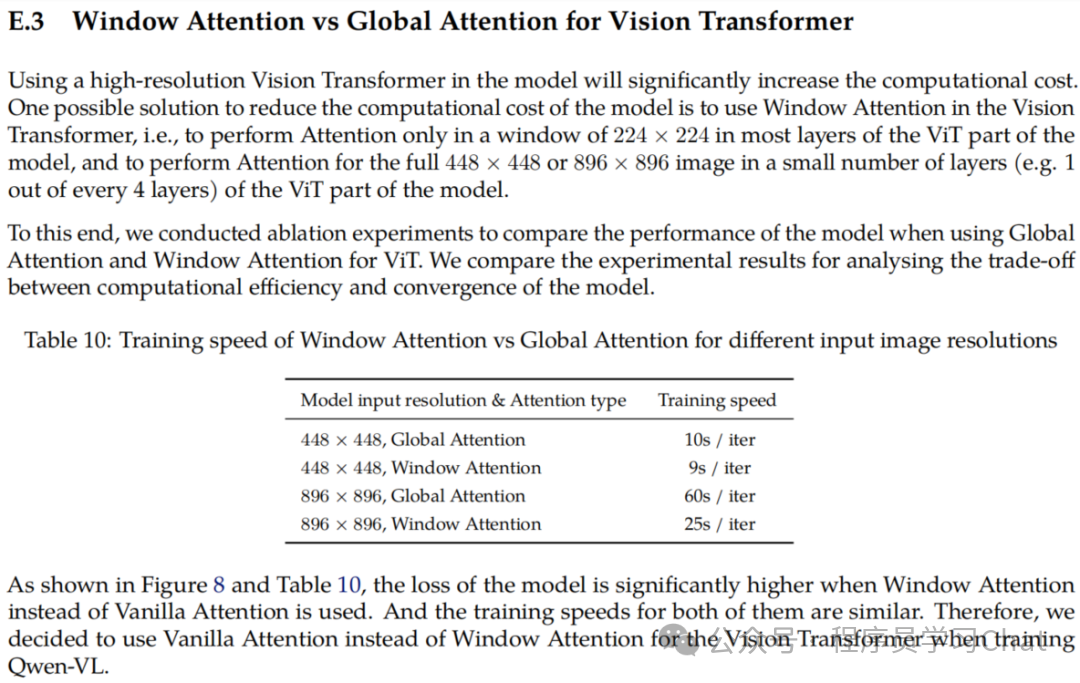
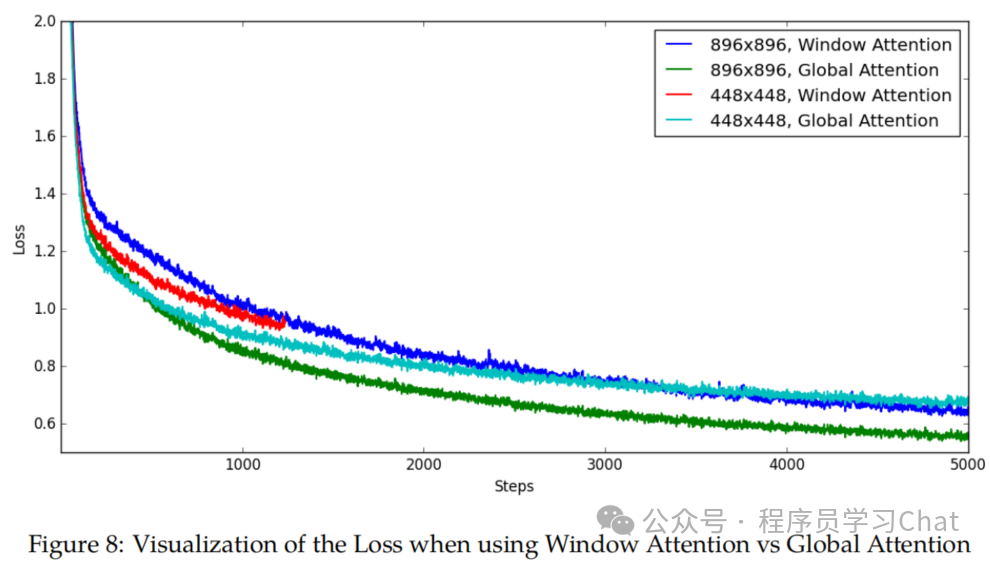
四 实验结果








