作者:黄鹏程(马格)|阿里云实时计算Flink版产品负责人
简介
作为全球领先的实时计算技术团队,阿里云 Flink 团队致力于为企业提供高性能、高可靠、易用的实时数据处理解决方案,助力企业实现数据驱动的业务创新与价值创造。本篇内容将全面解读阿里云实时计算 Flink 版的产品架构、核心能力和技术优势,后续将为大家继续介绍 Flink 的场景与案例。
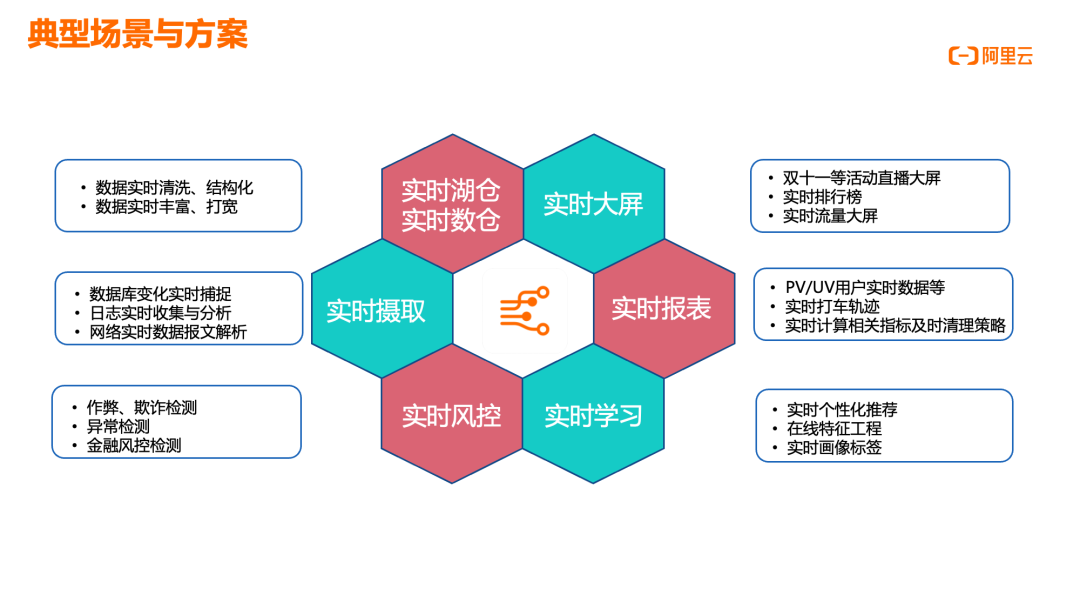
典型场景与方案
Flink 技术在多个业务场景中展现出了强大的实时处理能力。首先是实时湖仓和实时数仓场景,通过 Flink 实现数据的实时摄入、清洗、结构化、丰富和打宽,构建分层的数据仓库;其次是实时大屏场景,应用于双十一等活动直播大屏、实时排行榜和实时流量监控,展示 PV/UV 等用户实时数据;第三是实时摄取场景,通过 Flink CDC 能力实时捕获数据库变化,结合日志实时收集与分析、网络实时数据报文解析,实现全面的实时数据处理;第四是实时报表场景,提供即时业务洞察;第五是实时风控场景,包括作弊、欺诈检测、异常检测和金融风控;最后是实时学习场景,应用于实时个性化推荐、在线特征工程和实时画像标签构建。这些场景共同构成了 Flink 技术在企业级实时数据处理领域的完整解决方案,满足不同行业客户对实时数据处理的多样化需求。
01
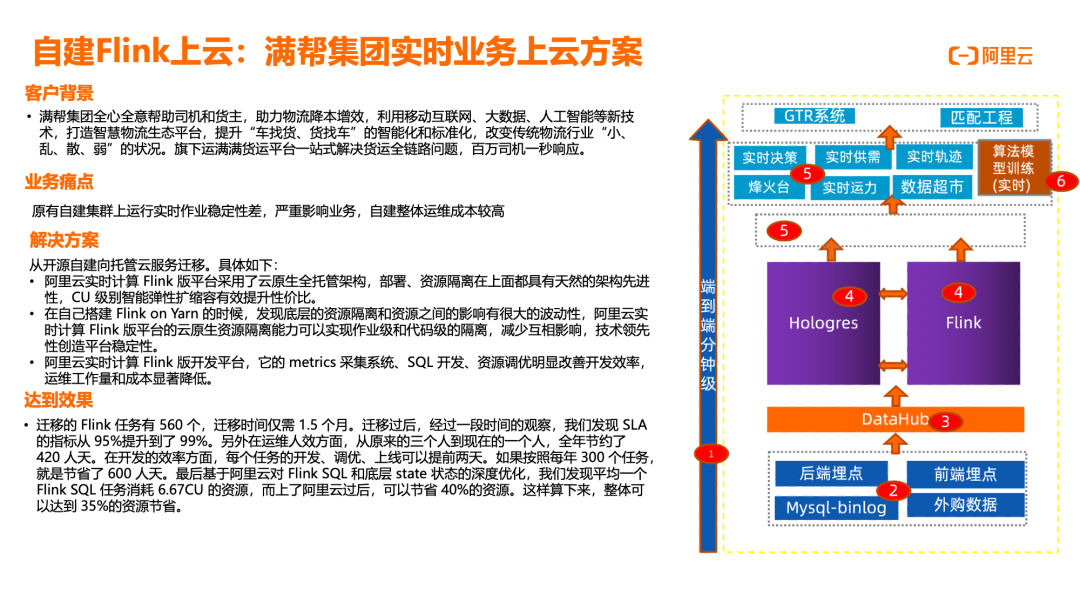
自建Flink上云:满帮集团降本35%
满帮集团致力于打造智慧物流生态平台,利用移动互联网、大数据和人工智能技术提升 "车找货、货找车" 的智能化和标准化水平,改变传统物流行业 "小、乱、散、弱" 的状况。旗下运满满货运平台一站式解决货运全链路问题,实现百万司机一秒响应。在业务发展过程中,满帮集团面临原有自建 Flink 集群稳定性差、运维成本高等痛点。通过迁移到阿里云实时计算 Flink 版平台,客户实现了从开源自建向托管云服务的成功转型。阿里云实时计算 Flink 版采用云原生全托管架构,在部署和资源隔离方面具有天然的架构先进性,CU 级别智能弹性扩缩容有效提升了资源利用效率和性价比。针对客户在自建 Flink On Yarn 环境中遇到的资源隔离和相互影响问题,阿里云平台提供了作业级和代码级的资源隔离能力,显著提升了平台稳定性。此外,阿里云 Flink 开发平台的 Metrics 采集系统、SQL 开发环境和资源调优工具大幅改善了开发效率,降低了运维成本。迁移效果显著:560 个 Flink 任务仅用 1.5 个月完成迁移;SLA 指标从 95% 提升至 99%;运维人员从三人减少至一人,全年节约 420 人天;每个任务的开发、调优、上线时间平均提前两天,按每年 300 个任务计算,可节省 600 人天;基于阿里云对 Flink SQL 和底层 State 状态的深度优化,平均每个 Flink SQL 任务资源消耗从 6.67 CU 降至 4 CU,节省 40% 资源,整体资源节省达 35%。
02
开源体系融合
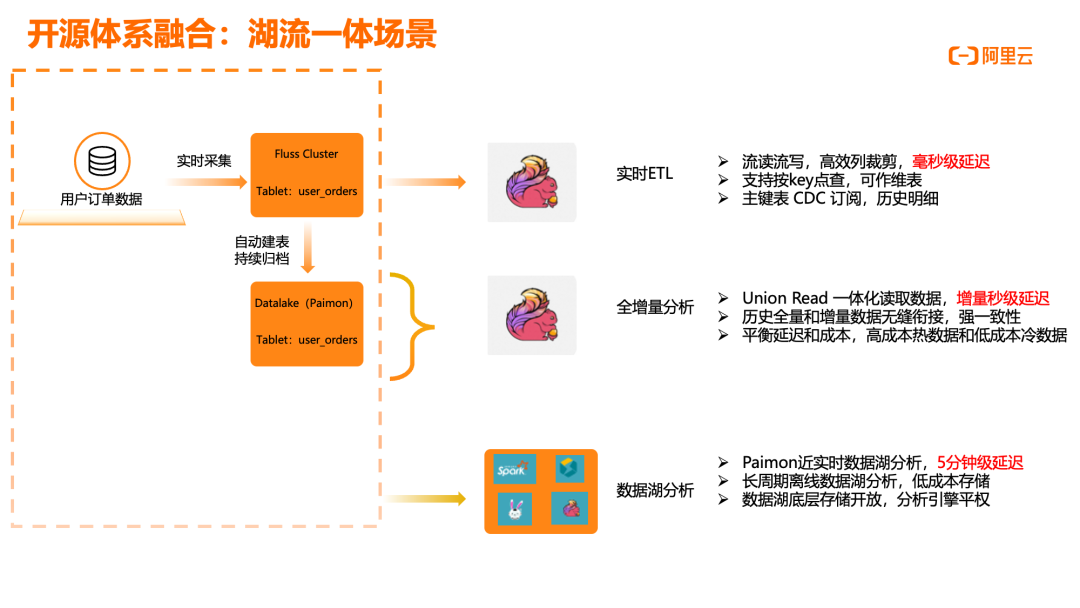
湖流一体场景:Flink+Fluss+Paimon
湖流一体架构是阿里云实时计算 Flink 版的重要应用场景,通过整合流处理和湖存储优势,提供统一的数据处理体验。在这一架构中,用户订单等业务数据通过 Flink CDC 实时摄入,经过 Fluss 流存储实现毫秒级延迟的数据处理。Fluss 提供流读流写能力,支持高效列裁剪,可作为维表进行按 Key 点查,同时支持 CDC 订阅,保证历史明细数据的完整性。数据在 Fluss 中经过实时 ETL 处理后,通过自动建表和持续归档机制,无缝流转至基于 Paimon 的 DataLake 存储层。Paimon 作为流批一体湖表格式,支持统一读取全量和增量数据,实现历史数据和实时数据的强一致性衔接。这种架构在平衡延迟和成本方面具有显著优势,能够将高成本热数据和低成本冷数据分层存储,同时保持数据的可查询性和一致性。阿里云 Flink 作为核心计算引擎,实现了湖流一体的数据处理能力,通过 DLF 3.0 统一元数据管理,确保数据口径一致,提供正确性保障。用户可根据业务时效性需求,灵活选择不同的计算和存储模式,构建端到端的实时数据处理链路。这种架构特别适用于需要同时处理实时数据和历史数据的场景,如用户行为分析、实时推荐系统和业务监控等,为企业提供一体化的数据处理解决方案。
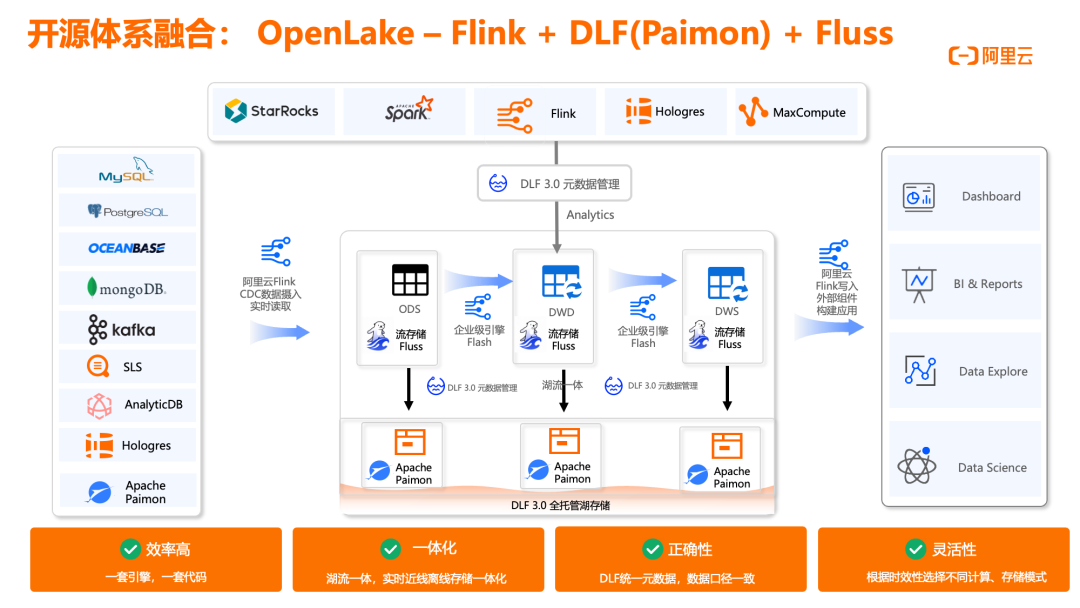
OpenLake -- Flink + DLF(Paimon) + Fluss
Openlake 架构是阿里云基于 Flink、DLF 和 Fluss 构建的开放数据湖解决方案,旨在实现流批一体的数据处理能力。在这一架构中,业务数据从多种源头(如 Kafka、RDS、日志文件、数据库日志等)通过 Flink CDC 和 Flink SQL 实时摄入,经过处理后写入 Paimon 表,构建 ODS、DWD、DWS 等多层数据模型。Paimon 作为流批一体湖表格式,存储在 OSS 云原生对象存储上,通过 DLF 数据湖平台进行统一的元数据管理和数据治理。DLF 提供智能的湖仓管理与优化能力,支持权限管理、存储优化和企业级安全及血缘能力,确保低成本的湖仓存储。这一架构的核心优势在于一套引擎、一套代码实现高效数据处理,湖流一体架构实现存储一体化,DLF 统一元数据确保数据口径一致,同时可根据时效性灵活选择不同计算和存储模式。Flink 作业处理后的数据可直接输出至 Dashboard、BI 报表、数据科学分析和数据探索等应用场景,实现端到端的数据价值挖掘。这种架构特别适合需要同时处理实时和离线数据的复杂业务场景,通过统一分层标准,实现 "One Data,多处分析" 的数据治理理念,为企业提供完整的数据服务生态圈。
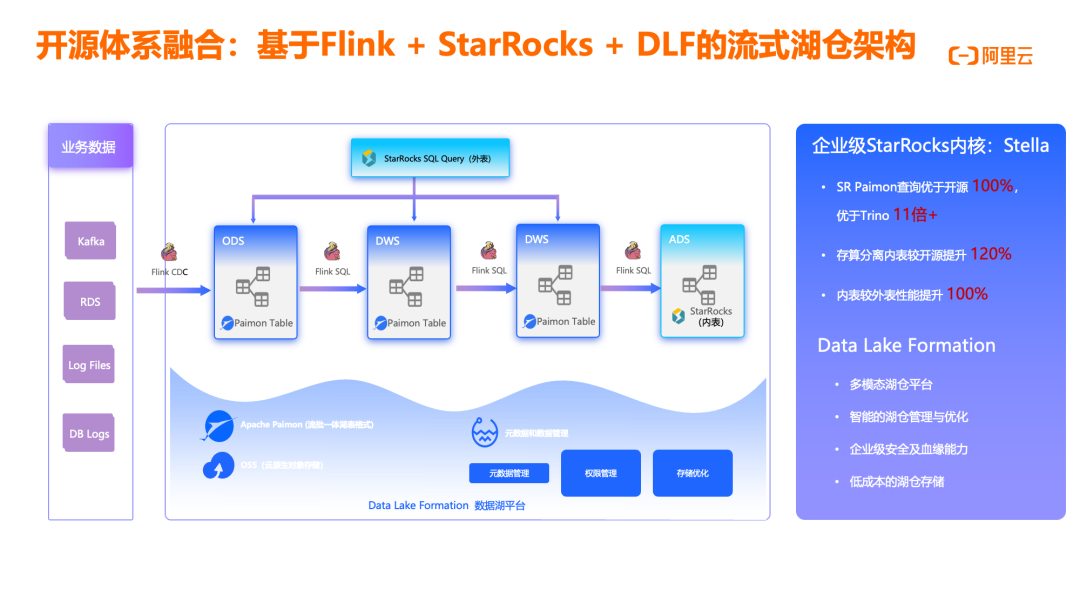
基于Flink + StarRocks + DLF(Paimon)的流式湖仓架构
基于 Flink、StarRocks 和 DLF 构建的流式湖仓架构是阿里云提供的一种高性能实时分析解决方案。在这一架构中,业务数据从 Kafka、RDS、日志文件等多种源头,通过 Flink CDC 和 Flink SQL 进行实时处理,写入 Paimon 湖表。Paimon 表作为统一的数据存储层,支持流批一体访问模式,可通过 StarRocks 外表方式直接查询,也可导入至 StarRocks 内表获得更高性能。阿里云企业级 StarRocks 内核 Stella 在查询性能方面表现卓越:Paimon 查询性能优于开源 100%,优于 Trino 11 倍以上;存算分离内表较开源提升 120% 性能;内表较外表性能提升 100%。Data Lake Formation 多模态湖仓平台提供智能的湖仓管理与优化能力,支持企业级安全及血缘能力,实现低成本的湖仓存储。Flink 与 StarRocks 的深度集成,使用户能够构建端到端的实时数仓,满足从数据摄入、处理到分析展示的全链路需求。这一架构特别适合需要高并发、低延迟查询的实时分析场景,如实时监控大盘、用户行为分析和业务指标追踪等,为企业提供统一、高效、灵活的数据分析平台。
03
阿里云自研产品融合
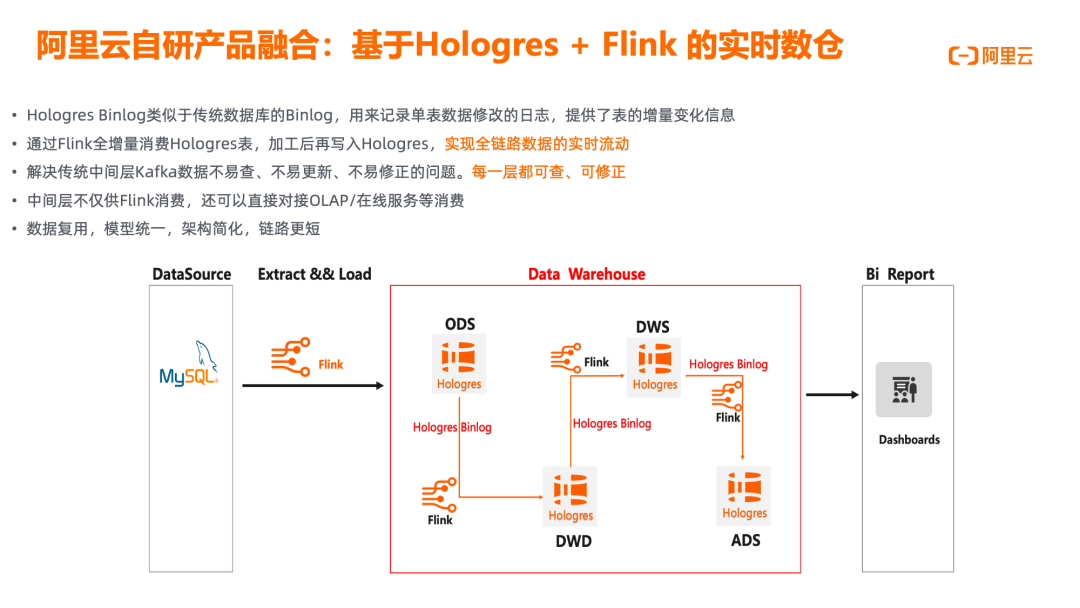
基于Hologres + Flink的实时数仓
基于 Hologres 和 Flink 构建的实时数仓架构,通过 Hologres Binlog 能力实现全链路数据的实时流动。Hologres Binlog 类似于传统数据库的 Binlog,记录单表数据修改日志,提供表的增量变化信息。通过 Flink 全增量消费 Hologres 表,加工后再写入 Hologres,实现数据在各层之间的实时流转。这种架构解决了传统中间层 Kafka 数据不易查询、不易更新、不易修正的问题,使每一层数据都可查询、可修正。中间层数据不仅可供 Flink 消费,还可直接对接 OLAP 和在线服务等消费方,实现数据复用。整个架构模型统一,链路简短,效率更高。相比传统 Flink+Kafka 架构,Hologres+Flink 方案在数据一致性、查询便捷性、模型统一性等方面具有显著优势,特别适合需要实时数仓分层且对数据质量要求高的业务场景,如金融风控、实时营销和运营分析等。Hologres 作为 HSAP 系统,同时支持高吞吐写入和低延迟查询,为实时数仓提供一体化的存储和计算能力,大幅降低架构复杂性和运维成本。
PolarDB MySQL + Flink + ADB MySQL实时数仓
PolarDB MySQL + Flink + ADB MySQL 构建的实时数仓架构,充分利用了阿里云数据库产品的 Binlog 能力,实现端到端的实时数据流转。ADB MySQL 作为分析型数据库,具备超大规模数据写入实时可见、强一致性保证、毫秒级查询响应等优势,复杂 SQL 查询速度相比传统关系型数据库快 10 倍,支持计算资源按需在线扩缩容、分时弹性和按需弹性等功能。在这一架构中,Flink CDC 首先实时捕获 PolarDB MySQL 的 Binlog 变更,将其同步至 ADB MySQL 的 ODS 层;接着,Flink 作业从 ODS 层消费数据,经过清洗、转换等处理,写入 DWD 层;进一步,Flink 可再次消费 DWD 层的 Binlog,聚合计算后写入 DWS 层;最终,经过处理的数据可直接服务于 BI Dashboard 和业务应用。整个链路延迟控制在秒级甚至毫秒级,确保业务决策的实时性。这一架构特别适合需要高并发 OLTP 和复杂分析相结合的业务场景,如电商交易分析、金融风控和实时报表等,为企业提供从交易到分析的一体化解决方案。PolarDB MySQL 作为高性能 OLTP 数据库,确保交易系统的稳定运行;ADB MySQL 作为分析型数据库,提供强大的 OLAP 能力;Flink 作为计算引擎,连接两者,构建完整的实时数仓体系。

04
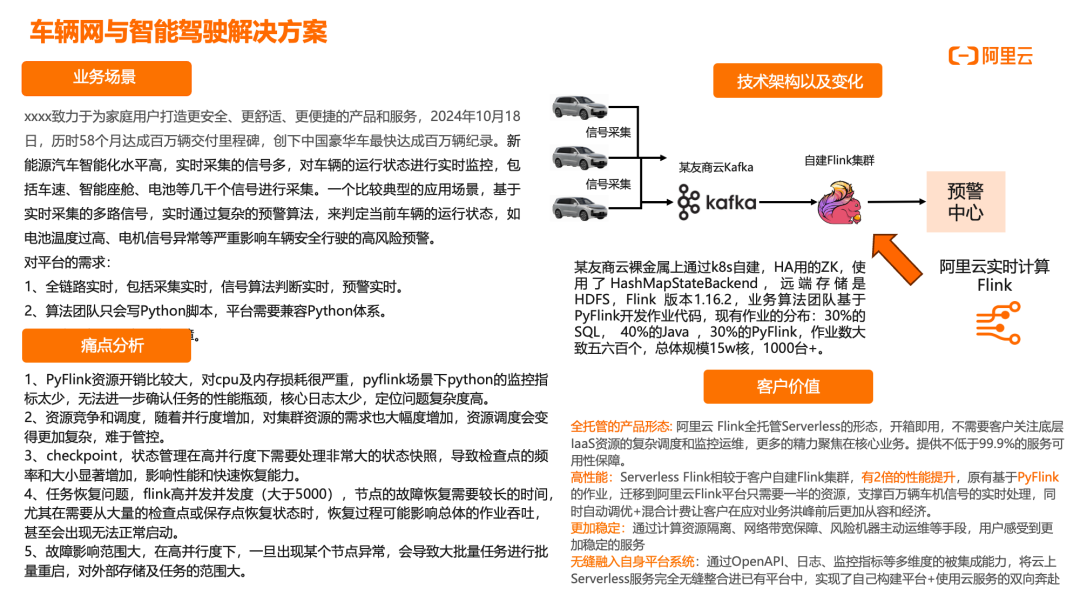
车辆网与智能驾驶解决方案
某造车新势力致力于为家庭用户提供更安全、更舒适、更便捷的产品和服务,于 2024 年 10 月 18 日达成百万辆交付里程碑,创下中国豪华车最快达成百万辆纪录。作为新能源汽车企业,其实时采集的信号多,需要对车辆运行状态进行实时监控,包括车速、智能座舱、电池等几千个信号。典型应用场景是基于实时采集的多路信号,通过复杂预警算法判定当前车辆运行状态,如电池温度过高、电机信号异常等高风险情况,确保车辆安全行驶。对平台的核心需求包括:全链路实时(采集实时、算法判断实时、预警实时)、兼容 Python 技术栈、高可靠性保障。原有架构部署在某友商云 Kafka 和自建 Flink 集群上,使用 PyFlink 开发,存在诸多痛点:PyFlink 资源开销大,CPU 及内存损耗严重,监控指标少,问题定位困难;资源竞争和调度复杂,随并行度增加,资源需求大幅增加;高并行度下 Checkpoint 和状态管理困难,影响性能和恢复能力;任务故障恢复时间长,尤其在高并发(大于 5000)场景下,节点故障恢复需要较长时间;故障影响范围大,单点异常导致大批量任务重启。迁移到阿里云实时计算 Flink 平台后,客户获得显著价值:全托管 Serverless 形态,开箱即用,无需关注底层 IaaS 资源调度和监控运维,更多精力聚焦核心业务,提供不低于 99.9% 的服务可用性保障;高性能,Serverless Flink 相比自建集群有 2 倍性能提升,PyFlink 作业只需一半资源,支撑百万辆车机信号实时处理,结合自动调优和混合计费,应对业务洪峰更加从容经济;更稳定的服务,通过计算资源隔离、网络带宽保障、风险机器主动运维等手段,提供企业级稳定性;无缝融入现有平台系统,通过 OpenAPI、日志、监控指标等多维度被集成能力,将云服务无缝整合进已有平台,实现自主构建平台与云服务的双向协同。整体架构上,车机原始数据经 EMQ 消息网关传入 Kafka,Flink 进行报文解码/解密后写入 Kafka DW 层,进一步实时写入 Hologres 和 MaxCompute,分别支撑实时特征工程和离线特征工程,为 AI 诊断模型提供数据支持,构建完整的车辆故障预测链路。
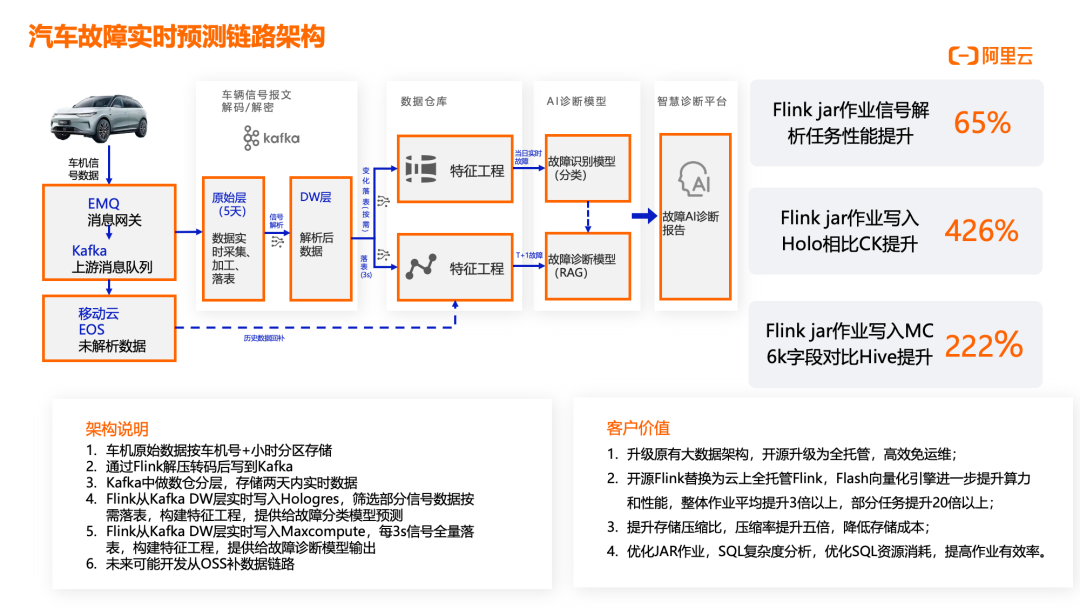
汽车故障实时预测链路架构
某电动汽车企业升级原有大数据架构,将开源组件升级为全托管服务,替换开源 Flink 为云上全托管 Flink,采用 Flash 向量化引擎提升算力和性能。整体作业性能平均提升 3 倍以上,部分任务性能提升达 20 倍;提升存储压缩比,压缩率提升五倍,显著降低存储成本;优化 JAR 作业和 SQL 复杂度,提高作业有效率。在具体性能指标方面,Flink JAR 作业信号解析任务性能提升 65%;Flink JAR 作业写入 MaxCompute 6k 字段对比 Hive 提升 222%;Flink JAR 作业写入 Hologres 相比 ClickHouse 提升 426%。架构上,车机原始数据按车机号 + 小时分区存储,通过 Flink 解压转码后写入 Kafka;Kafka 中做数仓分层,存储两天内实时数据;Flink 从 Kafka DW 层实时写入 Hologres,筛选部分信号数据按需落表,构建特征工程,提供给故障分类模型预测;Flink 从 Kafka DW 层实时写入 MaxCompute,每 3 秒信号全量落表,构建特征工程,提供给故障诊断模型;未来计划开发从 OSS 补数据链路,完善数据治理体系。这一架构为企业提供了完整的车辆故障预测能力,通过实时数据分析和 AI 模型结合,提前预警潜在故障,提升车辆安全性和用户体验。
实时数据湖架构
某新能源汽车企业的自动驾驶业务覆盖高速、城市、泊车等全场景高阶智能驾驶功能,支持驾舱一体集成,兼容多种芯片,实现算力灵活拓展。业务需要提供在线分析、准实时数据加工(分钟级)、快速数据导出、算法运算和数据服务等能力。原有技术痛点包括:依赖 Hive 实现历史数据更新,需要通过分区覆写或 Merge 操作,时延高、成本高、链路复杂;数据接入开发和维护工作量大,数据源 Schema 变更无法自适应,需要人工介入;Flink 任务无法动态调整资源,车端数据有明显波峰波谷,资源调整需重启作业,代价大;自动驾驶数据量大,构建全链路实时处理能力成本高;大数据集群基本部署在一个机房,容灾能力差,存在数据安全隐患。解决方案是构建以 Flink+Paimon 为核心的实时数据湖,为自动驾驶模型训练提供预处理能力,全面提升时效性。存储层采用 OSS 数据湖,湖格式采用 Paimon,数据分钟级实时可见,简单稳定,一键同步,时延低、成本低、链路复杂度低。计算引擎引入全新 Flink C++ Native 执行架构,支持指令、数据全面向量处理;全新内存管理,避免 JVM 瓶颈,较开源 Flink 性能提升 3-4 倍。商业化 Flink 开发平台支持作业资源自动调优,提高资源配置效率,提供同城跨可用区作业运行能力,同一个作业在一个可用区,当出现问题时系统会在另一个可用区带状态拉起(项目空间级别),实现 RPO=0,RTO=分钟级。数据从车端传回,经 Flink 解析后写入 Kafka,非结构化文件如视频图像存储在 OSS,描述性数据写入 PolarDB,标签信息写入 MongoDB,最终统一由 Flink 接入数据湖(Paimon),进行数据打宽、聚合判断,写入 ES,为模型训练提供场景检索服务,构建完整的自动驾驶数据预处理体系。
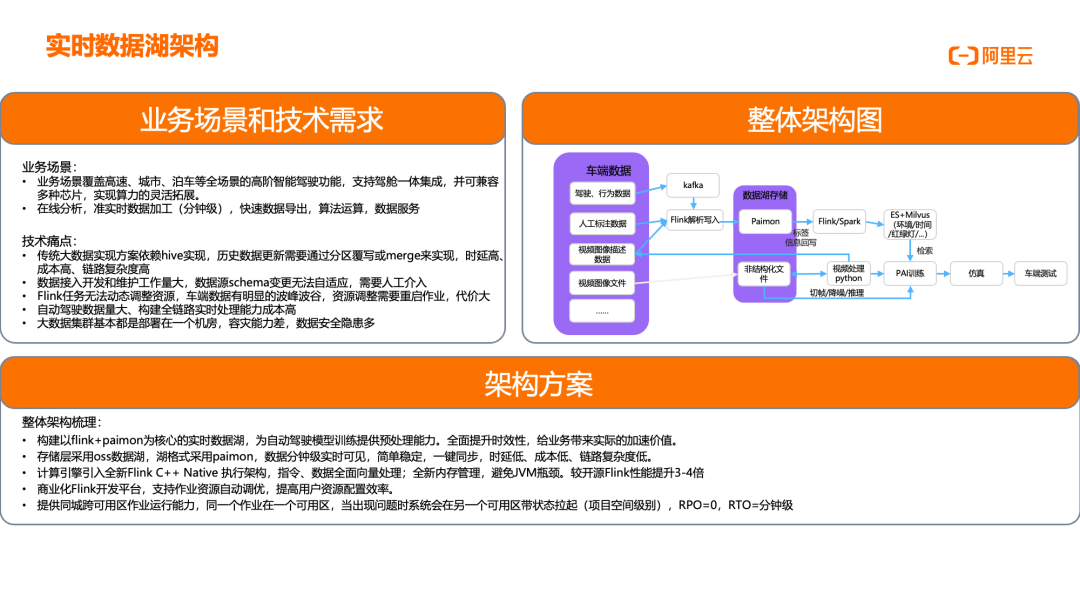 智能驾驶汽车数据预处理
智能驾驶汽车数据预处理
自动驾驶业务需要收集并处理车端传回的雷达、摄像头、驾驶行为、人工标注等数据,利用大数据技术进行合并、聚合、切帧、合成等预处理动作,最终提供给自动驾驶训练平台。功能性需求包括:提供非结构数据接入、更新、处理能力;具备千亿级高性能检索分析能力;支持弹性与冷热分层。非功能性需求包括:千亿半结构数据分钟级实时处理能力;千亿标注数据秒级查询检索;支持容灾和高可用能力。架构方案采用 Flink+Paimon 为核心的实时数据湖,全面提升时效性。业务流程上,传感器、驾驶行为数据由车端传回 Kafka,由 Flink 统一解析和消费;摄像头、雷达、激光雷达等数据由车端打包上传至 OSS,同时上传数据的描述性信息(结构化)写入 PolarDB,由 Flink 解析接入;人工打标团队对原始数据进行标注,标注后数据上传至 MongoDB,再由 Flink 解析接入;摄像头、雷达、激光雷达等数据会经过平台进行图像合并、切帧等操作,生成新的视频/图像数据,同时标签数据会进行补充和更新写入 MongoDB;以上数据统一由 Flink 接入数据湖(Paimon),进行数据打宽、聚合判断,最后写入 ES,为模型训练提供场景检索服务。这一架构实现了从数据采集、处理到服务的全链路实时化,大幅提升自动驾驶模型训练效率,加速智能驾驶能力迭代。
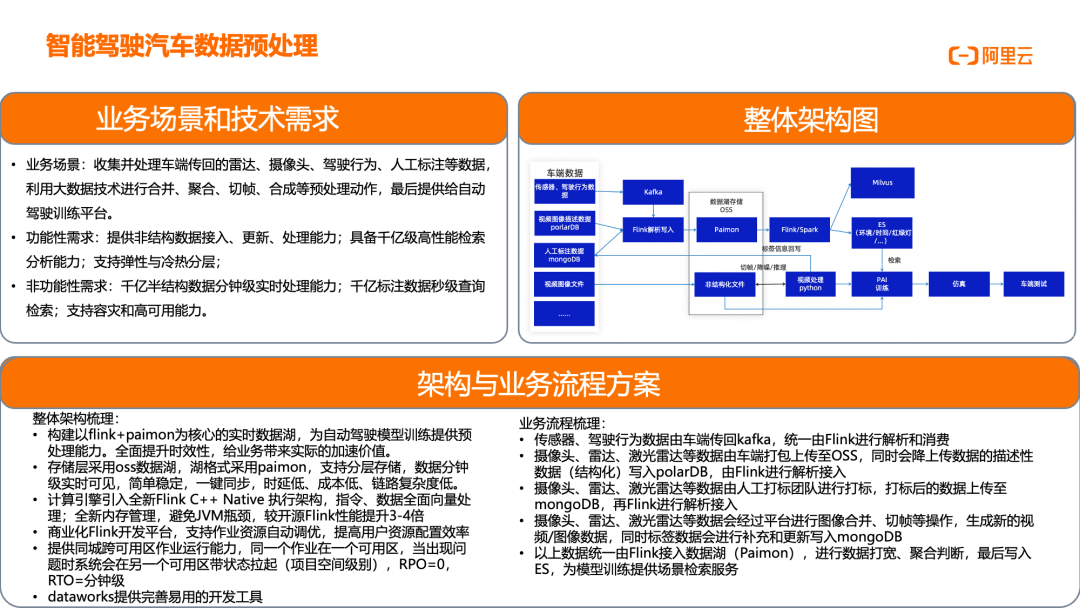
海量车机数据实时接入与分析
车联网场景需要处理海量车机信号数据,构建大数据实时离线一体平台,提供海量信号实时写入、准实时计算分析、离线计算和数据服务的全维度一体化数据分析解决方案。整体架构包含 EMQX 等消息网关(支持 MQTT 协议)、Kafka/DataHub 消息队列、车机信号数据、Flink 实时数据计算、Hologres 实时数据分析、MaxCompute 离线数据计算、DataWorks 数据智能开发治理平台等组件。车机信号报文经解码/解密后,通过 Flink(JAR 作业)进行实时采集、加工、落表,进入数据仓库;DataWorks 提供数据集成能力;Flink 进行实时数据计算,Hologres 提供实时数据分析;DataV 生成数据可视化;MaxCompute 负责离线数据计算;QuickBI 和第三方 BI Portal 提供报表能力;DataWorks 数据服务提供 API 接口。这一架构的核心价值在于:Serverless 全托管 SaaS 级云数仓,智能化运维,企业级稳定性;Flink Flash Engine 提供开源 Flink 5 倍以上性能,100% 兼容开源,用户作业无缝迁移;高性能离在线计算引擎(MaxCompute 连续 6 年 TPC-BB 世界冠军、Hologres TPC-H 世界排名第一)、极致弹性能力;离线数据秒级查询分析,毫秒级实时 HSAP 分析服务;全数据生命周期数据安全能力、金融级容灾备份高可用。该架构成功解决了车联网领域的核心痛点,包括车机信号报文数据秒级上报、数据量大且实时性要求高、需根据用户自定义协议进行报文解析等问题,为车企提供完整的车辆数据分析能力。
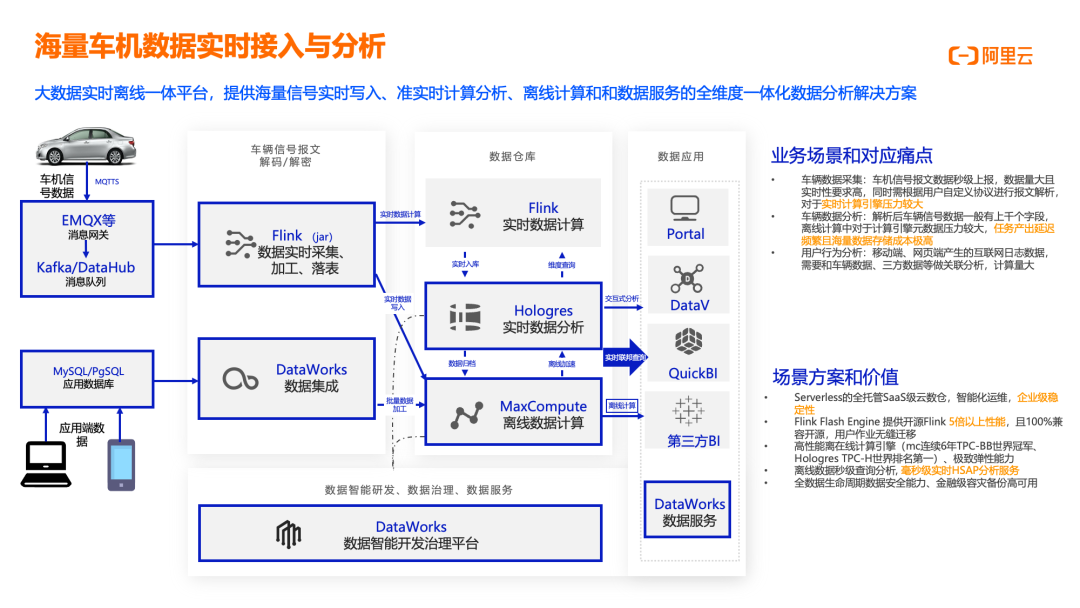
车机信号报文数据实时接入
车机信号报文数据接入场景聚焦于高并发二进制加密数据的稳定实时接入解析,满足全量数据准实时写入和关键数据实时写入需求。业务场景中,车机信号报文数据通过 EMQX 等消息网关(MQTT 协议)传入 Kafka/DataHub 消息队列,同时原始报文归档至 OSS。Flink(JAR 作业)负责数据实时解密/解析,支持原始报文按需解析。核心痛点包括:海量数据解析难,车机信号报文数据秒级上报,数据量大且实时性要求高,需根据用户自定义协议进行报文解析,对实时计算引擎压力大;流量峰谷差异大,车辆信号数据量由车辆移动频率决定,实时数据解析任务需要为早晚高峰预留大量资源,波谷时资源浪费明显;平台稳定性要求高,车端数据秒级上报,应用端查询秒级返回,全链路最低秒级延迟。解决方案的核心价值在于:高性能实时计算引擎,Flink Flash Engine 提供开源 Flink 5 倍以上性能,100% 兼容开源,用户作业无缝迁移,显著提高实时计算效率;智能调优+资源弹性,Flink 资源可根据上游数据流量进行弹性扩缩容,有效提高计算资源使用率,降低车联网信号报文解析成本;企业级实时大数据分析平台,全托管 Serverless 的 Flink 云服务,支持作业开发、数据调试、运行与监控、自动调优、智能诊断等全生命周期能力。这一方案已在多个车联网客户中成功落地,为车企提供稳定、高效、经济的车机信号数据处理能力。
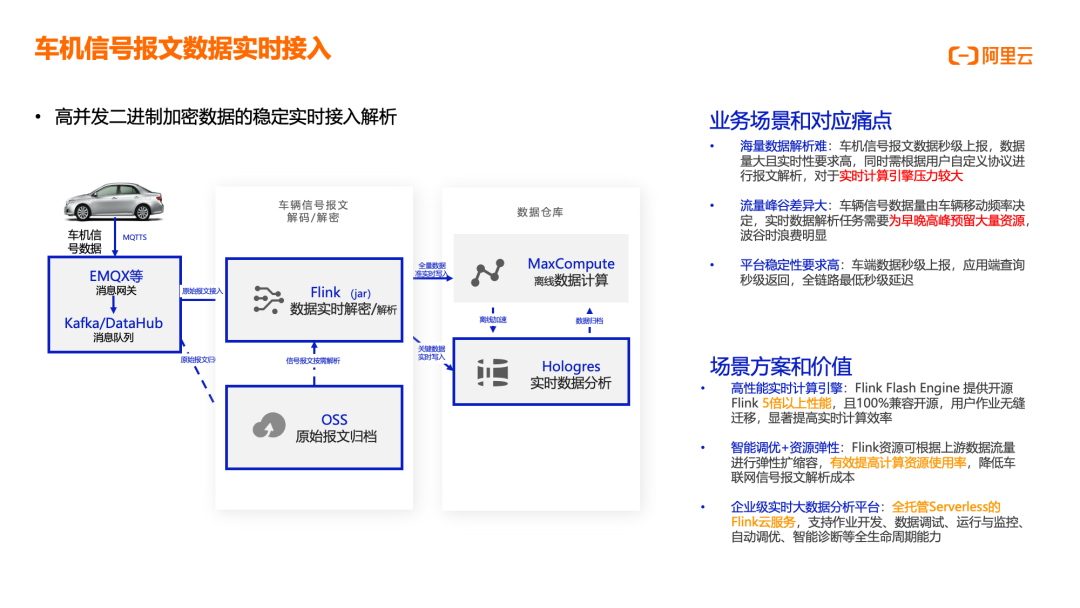
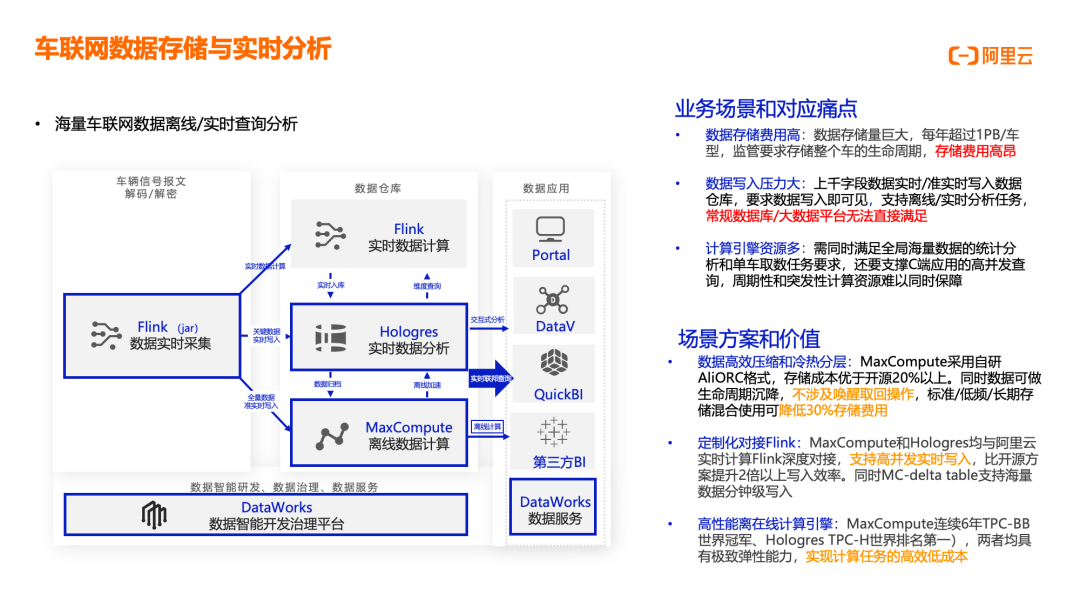
车联网数据存储与实时分析
车联网数据存储与分析场景针对海量车联网数据的离线/实时查询分析需求,解决存储成本高、写入压力大、计算资源多等痛点。业务场景中,车辆信号报文经解码/解密后,通过 Flink(JAR 作业)实时采集,进入数据仓库;Flink 进行实时数据计算,Hologres 提供实时数据分析;MaxCompute 负责离线数据计算;DataWorks 提供数据智能研发、数据治理、数据服务能力;交互式分析支持维度查询;DataWorks 数据服务提供离线加速和数据归档功能。核心痛点包括:数据存储费用高,数据存储量巨大,每年超过 1PB/车型,监管要求存储整个车的生命周期,存储费用高昂;数据写入压力大,上千字段数据需实时/准实时写入数据仓库,要求数据写入即可见,支持离线/实时分析任务,常规数据库/大数据平台难以满足;计算引擎资源多,需同时满足全局海量数据的统计分析和单车取数任务要求,还要支撑 C 端应用的高并发查询,周期性和突发性计算资源难以同时保障。解决方案的核心价值在于:数据高效压缩和冷热分层,MaxCompute 采用自研 AliORC 格式,存储成本优于开源 20% 以上,数据可做生命周期沉降,不涉及唤醒取回操作,标准/低频/长期存储混合使用可降低 30% 存储费用;定制化对接 Flink,MaxCompute 和 Hologres 均与阿里云实时计算 Flink 深度对接,支持高并发实时写入,比开源方案提升 2 倍以上写入效率,MC-Delta Table 支持海量数据分钟级写入;高性能离在线计算引擎,MaxCompute 连续 6 年 TPC-BB 世界冠军、Hologres TPC-H 世界排名第一,两者均具有极致弹性能力,实现计算任务的高效低成本执行。该方案已在多家车企成功落地,为车联网业务提供高性价比的数据存储与分析能力。
05
实时分析与大屏解决方案
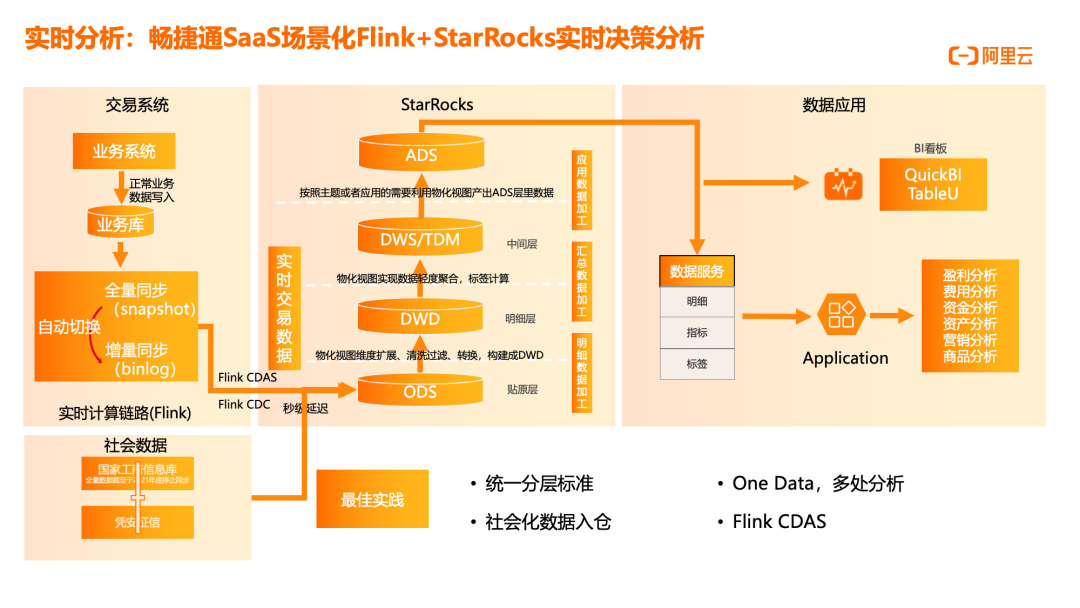
畅捷通SaaS场景化Flink+StarRocks实时决策分析
畅捷通作为企业级软件服务提供商,专注于财务管理、ERP、CRM 等领域,通过阿里云决策分析解决方案提升财务管理效率、优化经营决策和提升客户服务水平。在具体实施中,Flink CDC 实时捕获业务系统(2000 多张 ODS 表)的数据变化,通过 CDAS(Create Database As)语法实现整库同步,将数据实时同步至 StarRocks。StarRocks 作为高性能分析型数据库,支持物化视图、维度扩展、清洗过滤、转换等能力,构建 DWD 明细层;进一步通过物化视图实现数据轻度聚合、标签计算,形成 DWS 汇总层;最终按照主题或应用需要产出 ADS 应用层数据。这一架构实现了从 OLTP 到 OLAP 的实时数据流转,支持秒级延迟的业务分析。具体成果包括:财务数据自动化处理,财务人员工作效率提高 30%;财务数据分析,发现经营风险,帮助企业避免损失;客户数据分析,提高客户满意度,降低客户流失率。技术实现上,离线数据通过 DataWorks 集成至 MaxCompute,日均 5000~6000 个任务,增量约 100+GB/天;实时数据通过 Flink CDC 和 Kafka 接入,Hologres 提供交互式分析能力;数据服务通过 DataWorks 数据服务、QuickBI、邮件/AMP/AppFlyer 等渠道推送至业务端。这一方案充分发挥了 Flink+StarRocks 在实时分析场景的优势,为 SaaS 企业提供场景化的实时决策分析能力。
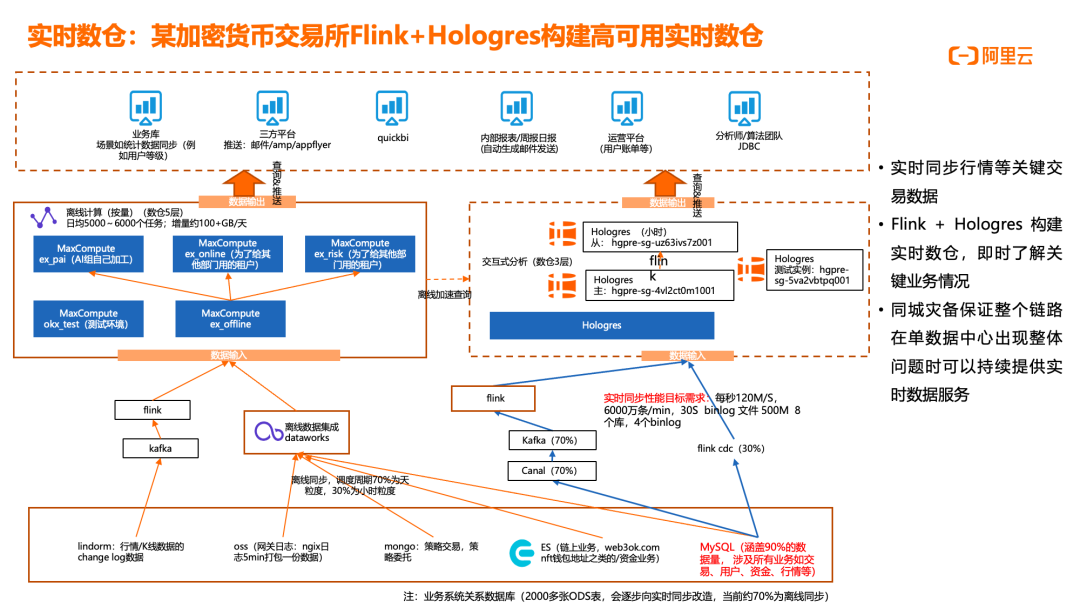
某加密货币交易所Flink+Hologres构建高可用实时数仓
某加密货币交易所采用 Flink+Hologres 构建实时数仓,即时了解关键业务情况,包括交易、用户、资金、行情等核心业务数据。架构上,业务数据从多个源头(MySQL、Kafka、Lindorm、ES、OSS、MongoDB 等)通过 Flink CDC(30%)和 Kafka(70%)接入,经 Flink 处理后写入 Hologres 和 MaxCompute。Hologres 作为实时数仓核心,提供毫秒级查询响应;MaxCompute 负责离线计算,日均 5000~6000 个任务,增量约 100+GB/天;DataWorks 提供统一调度和数据治理能力;QuickBI 和三方平台提供报表和推送服务。性能目标要求每秒 120M/s,6000 万条/分钟,30 秒 Binlog 文件 500M,涉及 8 个库,4 个 Binlog。原有架构使用 Canal(70%)进行离线同步,调度周期 70% 为天粒度,30% 为小时粒度,性能和实时性不足。新架构通过 Flink+Hologres 实现秒级延迟,满足关键交易数据实时同步需求。同时,系统采用同城灾备架构,保证整个链路在单数据中心出现整体问题时可以持续提供实时数据服务,确保业务连续性。技术细节上,Hologres 主从实例分别部署在不同可用区,Flink 作业通过 JDBC 连接业务库,实时同步行情等关键交易数据;离线加速查询从 Hologres 到 MaxCompute,实现数据分层;Kafka 用于三方平台推送,包括邮件、AMP、AppFlyer 等渠道;Hologres 测试实例支持开发测试需求。这一架构为加密货币交易所提供了高性能、高可用的实时数据处理能力,支撑核心业务决策。
06
实时风控解决方案
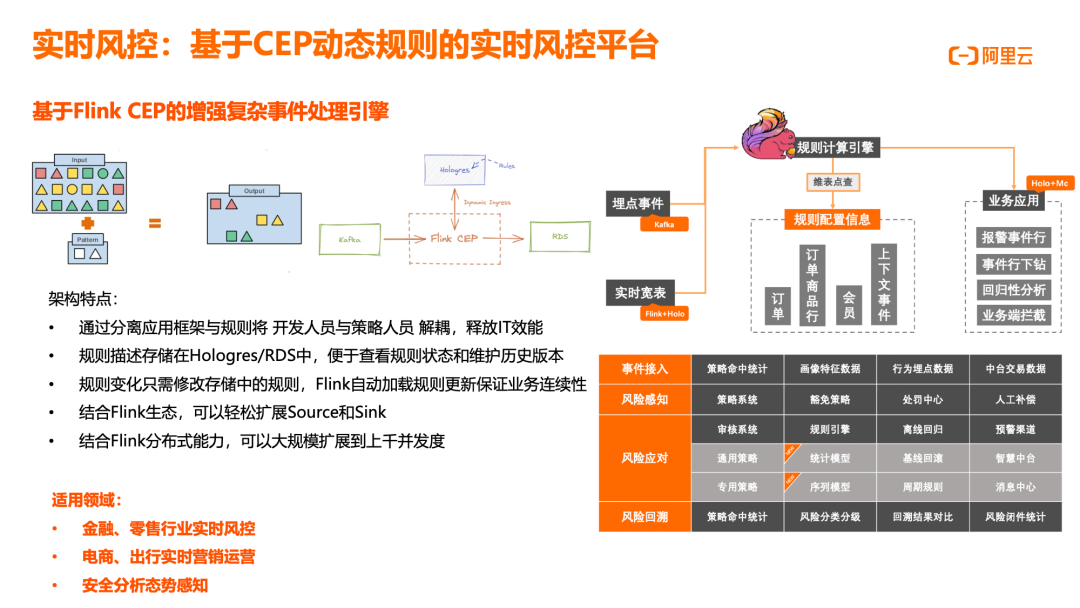
基于CEP动态规则的实时风控平台
基于 Flink CEP 的增强复杂事件处理引擎架构,通过分离应用框架与规则,将开发人员与策略人员解耦,释放 IT 效能。规则描述存储在 Hologres/RDS 中,便于查看规则状态和维护历史版本;规则变化只需修改存储中的规则,Flink 自动加载规则更新,保证业务连续性;结合 Flink 生态,可轻松扩展 Source 和 Sink;结合 Flink 分布式能力,可大规模扩展到上千并发度。适用领域包括金融、零售行业实时风控,电商、出行实时营销运营,安全分析,态势感知等。
钱大妈Flink+Hologres实时风控与营销系统构建
钱大妈作为社区生鲜连锁品牌,以 "不卖隔夜肉" 为品牌理念,已在全国布局近 30 座城市,门店总数突破 3000 多家,服务家庭超 1000 万。除数仓分析场景外,钱大妈面临业务系统中的风控需求,如每季度营销费用中被羊毛党薅走正常用户利益,导致用户口碑下降和活动运营预算攀升,造成资损。钱大妈与阿里云 Flink 实时计算团队共建实时风控规则引擎,精确识别羊毛党以防营销预算流失。该解决方案已应用于钱大妈集团内部生产环境,未引入新技术组件和编程语言,最大化复用 Flink 资源实现实时风控场景需求,降低新组件引入的潜在运维风险和研发团队学习成本。具体优势包括:解耦 Flink 作业逻辑开发和业务规则定义;业务规则存储在 Database 中,便于查看规则状态和历史版本;规则变更只需修改 Database 存储的规则,Flink 自动加载更新作业中的规则列表;结合 Flink 生态能够轻松集成事件异构数据源的读取与写入;结合 Flink 分布式能力,可大规模扩展至数千并发度匹配运行规则。钱大妈基于 Flink、Hologres 构建了离线和实时数据一体化的全渠道数据中台,为各业务线提供 BI 报表及数据接口支持,实时风控解决方案成为其中重要组成部分,有效保障了营销活动的正常运行。

07
实时AI与推理解决方案
直播评论的实时智能情感分析
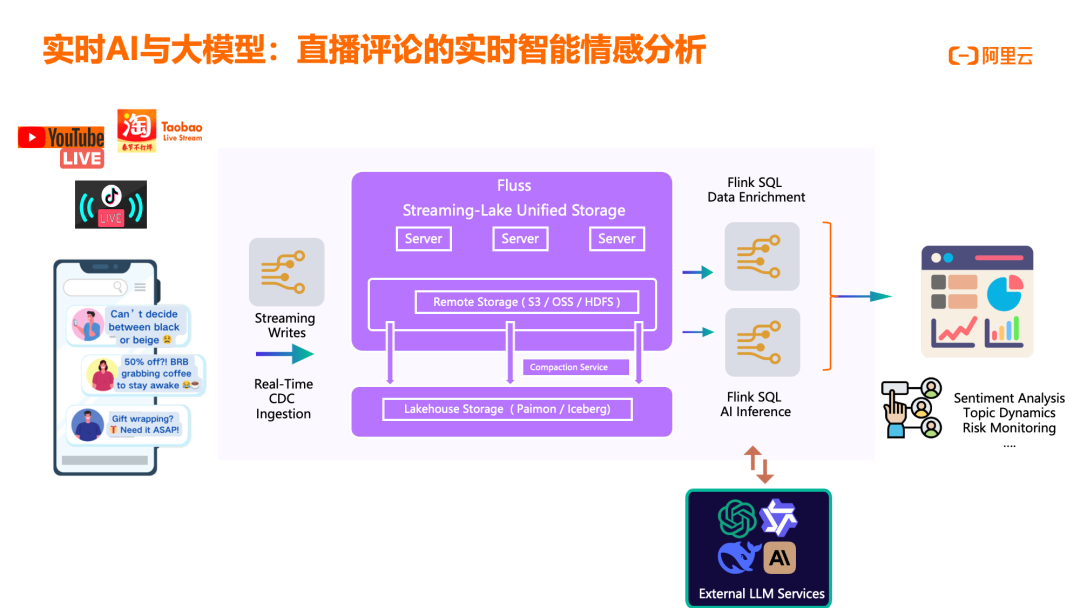
直播评论的实时智能情感分析场景,通过 Flink 实现从数据采集到 AI 推理的端到端实时处理。架构上,多种源端数据(评价文本)经清洗后以 JSON 格式推送至 Kafka;Flink 流式消费 Kafka 中数据,使用 AI Function 异步 HTTP 调用形式调用百炼大模型服务,结果返回异步队列,将生成的三级标签数据回写至 Kafka;Kafka 中数据推送给下游业务消费,做进一步分析。这一架构融合了 Streaming Writes、Real-Time CDC Ingestion、Lakehouse Storage(Paimon/Iceberg)、AI Inference、External LLM Services 等能力,支持 Sentiment Analysis、Topic Dynamics、Risk Monitoring 等多种应用。
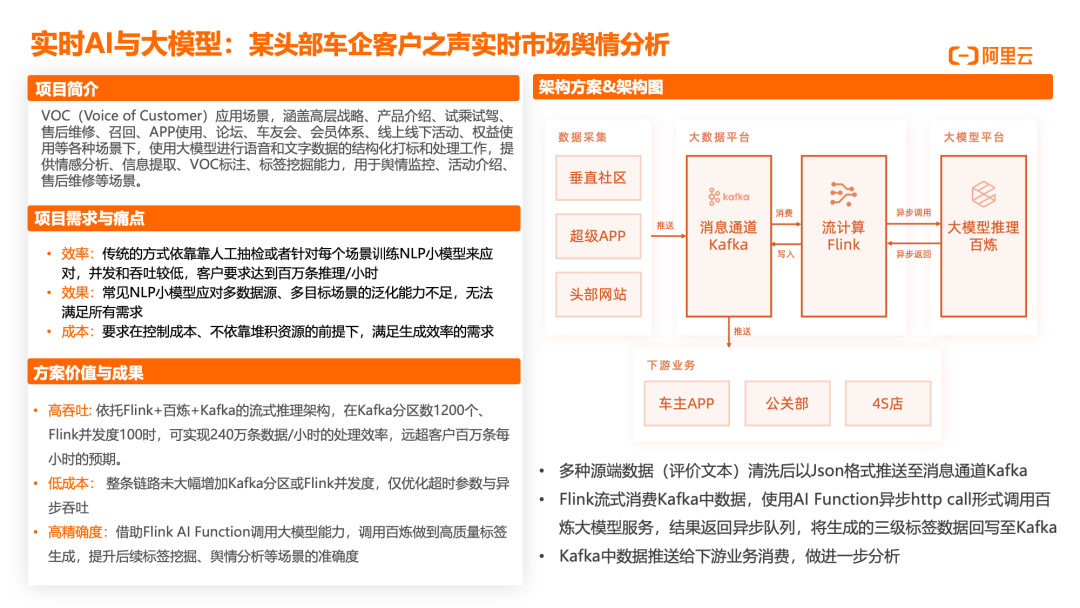
某头部车企的客户之声实时舆情分析
(Voice Of Customer,VOC)实时市场舆情分析项目,涵盖高层战略、产品介绍、试乘试驾、售后维修、召回、APP 使用、论坛、车友会、会员体系、线上线下活动、权益使用等各种场景,使用大模型进行语音和文字数据的结构化打标和处理,提供情感分析、信息提取、VOC 标注、标签挖掘能力,用于舆情监控、活动介绍、售后维修等场景。项目需求包括:高吞吐,依托 Flink+百炼+Kafka 的流式推理架构,在 Kafka 分区数 1200 个、Flink 并发度 100 时,实现 240 万条数据/小时的处理效率,远超客户百万条每小时的预期;低成本,整条链路未大幅增加 Kafka 分区或 Flink 并发度,仅优化超时参数与异步吞吐;高精确度,借助 Flink AI Function 调用大模型能力,调用百炼做到高质量标签生成,提升后续标签挖掘、舆情分析等场景的准确度。技术挑战在于:传统方式依靠人工抽检或针对每个场景训练 NLP 小模型,并发和吞吐较低,客户要求达到百万条推理/小时;常见 NLP 小模型应对多数据源、多目标场景的泛化能力不足,无法满足所有需求;要求在控制成本、不依靠堆积资源的前提下,满足生成效率需求。该方案成功解决了上述挑战,为车企提供了实时、精准的市场舆情分析能力,助力产品优化和营销决策。

▼ 「实时计算 Flink 版」 ▼
复制下方链接或者扫描左边二维码
即可免费试用阿里云 Serverless Flink,体验新一代实时计算平台的强大能力!
了解试用详情:https://free.aliyun.com/?productCode=sc

▼ 关注「Apache Flink」 ▼
回复 FFA 2025 获取大会资料


点击「阅 读 原文」 跳转阿里云实时计算 Flink~********