目录:
-
- 一、环境准备
-
- [1、Anaconda 环境配置](#1、Anaconda 环境配置)
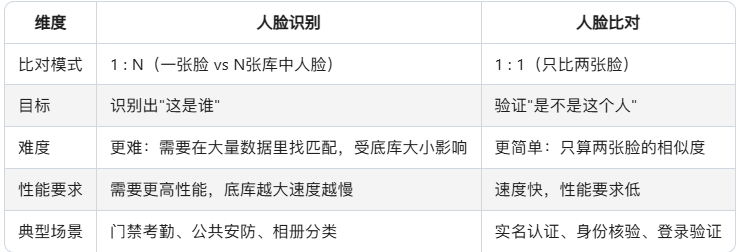
- 2、人脸识别和人脸比对有什么区别?
- 二、代码案例
- 三、运行结果
一、环境准备
1、Anaconda 环境配置
环境配置参考前面章节:
2、人脸识别和人脸比对有什么区别?
二、代码案例
1、训练人脸识别模型完整代码
python
import cv2
import os
import numpy as np
import json
# 1. 加载 Haar 级联人脸检测器
face_detector = cv2.CascadeClassifier("path/haarcascade_frontalface_default.xml")
# 2. 创建 LBPH 人脸识别器
recognizer = cv2.face.LBPHFaceRecognizer_create()
# 3. 准备人脸图像和对应的标签
def get_images_and_labels(dataset_path):
image_paths = []
for person_name in os.listdir(dataset_path):
person_dir = os.path.join(dataset_path, person_name)
ifnot os.path.isdir(person_dir):
continue
for image_name in os.listdir(person_dir):
image_path = os.path.join(person_dir, image_name)
image_paths.append((image_path, person_name))
face_samples = [] # 存裁剪好的人脸图像
ids = [] # 存每个人脸对应的数字ID
id_map = {} # 存数字ID和人名的对应关系
current_id = 0 # 从0开始给每个人分配ID
for image_path, person_name in image_paths:
# 读取照片,转成灰度图(LBPH算法只需要灰度图,彩色信息没用)
image = cv2.imread(image_path, cv2.IMREAD_GRAYSCALE)
if image is None: # 读失败跳过(比如文件损坏)
continue
# 用刚才加载的人脸检测器,找照片里的人脸
faces = face_detector.detectMultiScale(image,
scaleFactor=1.1, # 每次缩放1.1倍,检测多尺度人脸
minNeighbors=5, # 至少5个相邻检测框才认为是人脸,过滤误检
minSize=(30, 30) # 人脸至少30×30像素,太小忽略
)
# 把检测到的每个人脸,裁剪出来存起来,加上对应的ID
for (x, y, w, h) in faces:
# 裁剪:从原图中抠出人脸区域(y到y+h行,x到x+w列)
face_samples.append(image[y:y+h, x:x+w])
ids.append(current_id) # 加上ID
id_map[current_id] = person_name # 记录ID对应谁
current_id += 1 # 下一个人ID+1
return face_samples, np.array(ids), id_map
# 4. 训练
dataset_path = 'dataset'
print("正在加载人脸数据...")
faces, ids, id_map = get_images_and_labels(dataset_path)
if len(faces) == 0:
print("没有找到任何人脸图像,请检查 dataset 文件夹结构和内容!")
else:
print(f"共收集到 {len(faces)} 张人脸")
recognizer.train(faces, ids)
# 5. 保存模型和映射
recognizer.save('trainer.yml')
with open('id_map.json', 'w', encoding='utf-8') as f:
json.dump(id_map, f, ensure_ascii=False, indent=2)
print("模型训练完成")重点事项:
- 要求你的dataset文件夹必须是这个结构:

- trainer.yml和id_map.json两个文件有什么作用:
1、trainer.yml:训练好的LBPH人脸识别模型,后面识别的时候加载这个文件就能用
2、id_map.json:记录每个ID对应的人名,比如{0: "张三", 1: "李四"},识别出ID后就能查到人名。
2、使用模型做识别代码
python
import cv2
import json
# 1. 加载 Haar 级联人脸检测器
face_detector = cv2.CascadeClassifier("xxx/haarcascade_frontalface_default.xml")
# 2. 加载人脸识别模型
recognizer = cv2.face.LBPHFaceRecognizer_create()
recognizer.read('trainer.yml') # 训练好的模型
# 3. 加载 ID 到人名的映射
with open('id_map.json', 'r', encoding='utf-8') as f:
id_map = json.load(f)
# 4. 读取你要识别的图片
image_path = 'xxxxx\test_4.png'# 图片路径
image = cv2.imread(image_path)
if image isNone:
print(f"无法加载图片:{image_path}")
else:
# 转为灰度图(人脸检测和识别通常用灰度图)
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
# 5. 使用 Haar 检测人脸
faces = face_detector.detectMultiScale(gray, scaleFactor=1.1, minNeighbors=5, minSize=(30, 30))
if len(faces) == 0:
print("未在这张图片中检测到人脸。")
else:
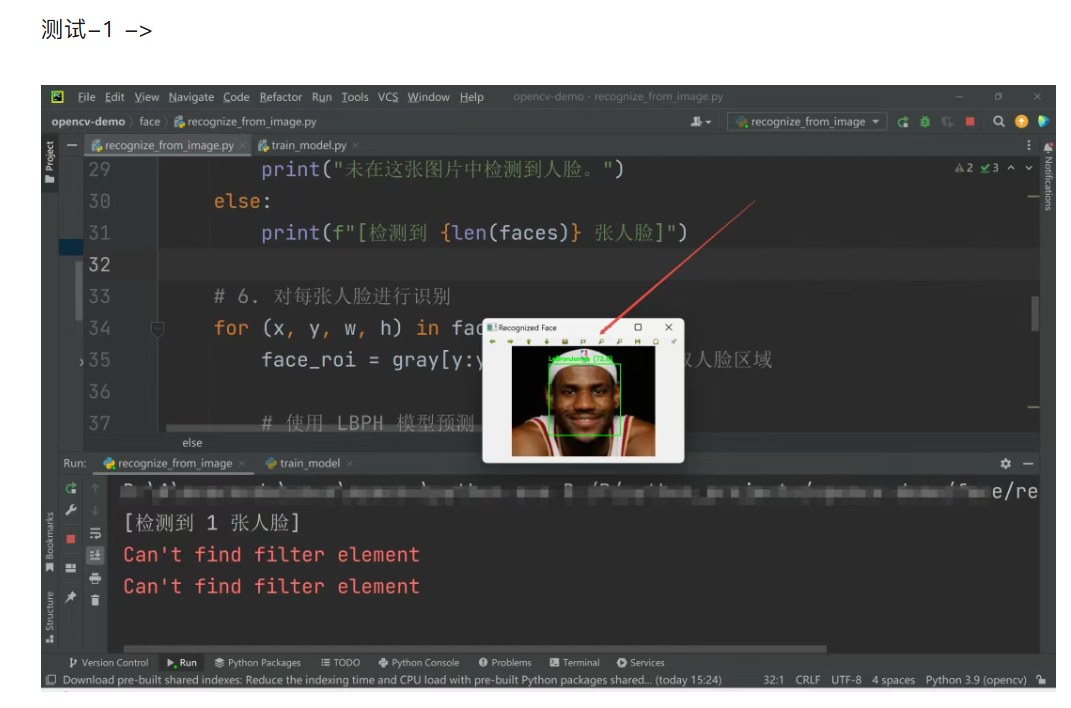
print(f"[检测到 {len(faces)} 张人脸]")
# 6. 对每张人脸进行识别
for (x, y, w, h) in faces:
face_roi = gray[y:y+h, x:x+w] # 提取人脸区域
# 使用 LBPH 模型预测 # 预测:得到ID和置信度(分数越小越准确)
label, confidence = recognizer.predict(face_roi)
# 获取人名
name = "Unknown"
if str(label) in id_map:
name = id_map[str(label)]
# 在图片上画框 + 标签
cv2.rectangle(image, (x, y), (x+w, y+h), (0, 255, 0), 2)
text = f"{name} ({confidence:.1f})"
cv2.putText(image, text, (x, y - 10), cv2.FONT_HERSHEY_SIMPLEX, 0.6, (0, 255, 0), 2)
# 7. 显示结果图片
cv2.imshow('Recognized Face', image)
while True:
key = cv2.waitKey(1) & 0xFF
if key == ord('q'):
break
cv2.destroyAllWindqows()重点事项:
前面的id_map.json这个里面把人名和id对应了,就和这里的代码呼应,被运用到。
python
# 使用 LBPH 模型预测 # 预测:得到ID和置信度(分数越小越准确)
label, confidence = recognizer.predict(face_roi)
# 获取人名
name = "Unknown"
if str(label) in id_map:
name = id_map[str(label)]这里的label就是id,然后去id_map.json文件里面去查,能查到就代表比对成功了。
三、运行结果