在机器学习的世界里,有一种极具挑战性的任务:你只有极少量的正样本(比如5个或10个),而且只有正样本可用,没有负样本 。这就是**小样本单类分类(Few-Shot One-Class Classification, FS-OCC)**问题。
这个场景在实际应用中非常普遍:
-
生物特征认证:每个人只有自己的少量注册样本(正样本),需要拒绝所有其他人(负样本)
-
工业异常检测:只有正常产品的少量样本,需要检测各种未知缺陷
-
网络安全:只有正常流量的少量样本,需要识别各种攻击
然而,现有方法大多基于几何假设(如用超球面包围正样本),没有显式建模数据的分布规律,导致学到的特征表示泛化能力有限。当面对全新的类别时,性能往往不尽如人意。
针对这一挑战,来自北京理工大学的研究团队提出了一种新颖的方法------BayesAHDD(基于贝叶斯规则的自适应超球面数据描述) ,将贝叶斯决策规则 与高斯分布建模 相结合,为小样本单类分类提供了全新的概率视角。该成果发表于Expert Systems with Applications(2026)。
现有方法的困境
目前主流的FS-OCC方法大致分为两类:
-
超平面法(如Ow- ProtoNet):假设负类集中在原点,用超平面分离正负类。但超平面边界往往导致类间重叠,区分能力有限。
-
超球面法(如Meta- SVDD、AHDD):用一个最小体积的超球面包围正样本。虽然AHDD引入了可学习的半径,但这些方法仍然依赖几何假设,只优化样本"在边界内/外",而没有显式建模数据的分布规律。
这些方法的共同局限:学到的特征表示缺乏概率解释,难以真正捕捉数据的底层分布,导致泛化能力受限。
BayesAHDD:从几何到概率的范式转变
BayesAHDD的核心思想是:用高斯分布显式建模正类和负类的概率密度,然后根据贝叶斯决策规则进行分类。
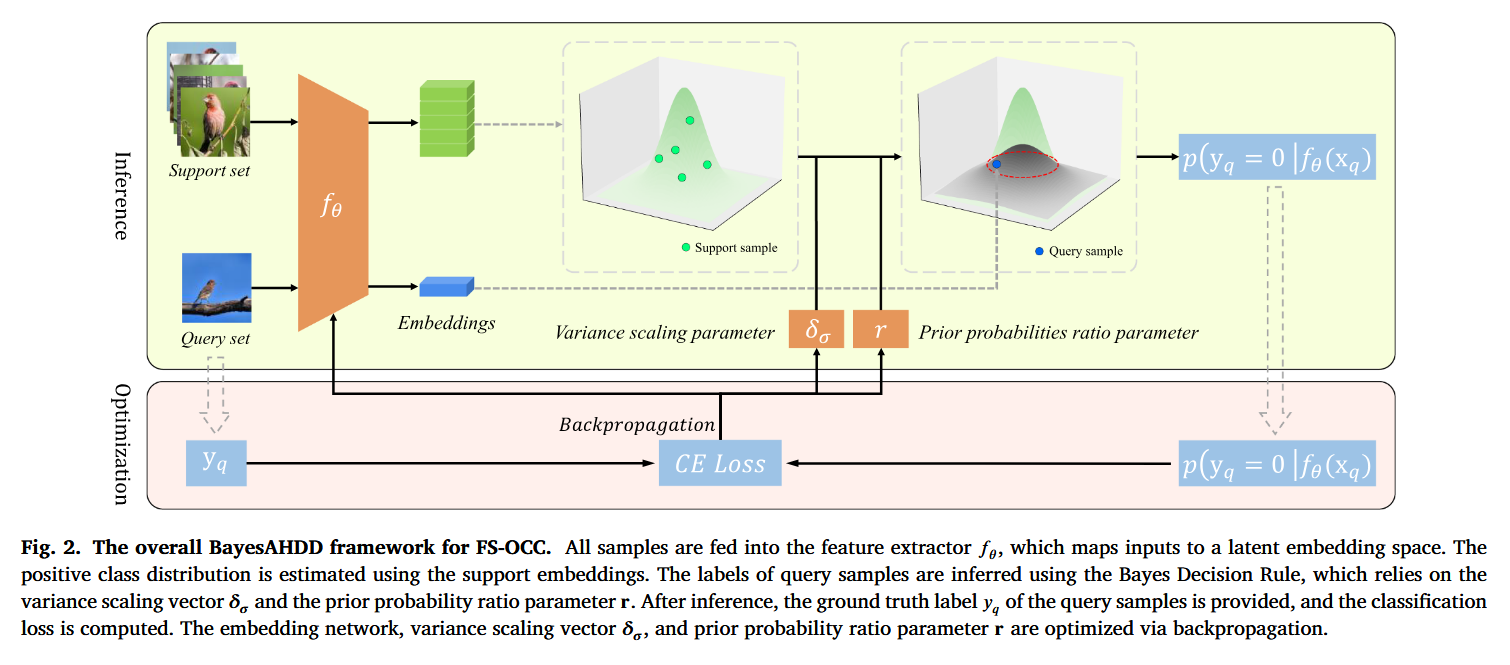
1. 高斯分布建模
-
正类分布:从支持集(少量正样本)中估计均值和方差。假设特征维度不相关,使用对角协方差矩阵(简化计算,避免矩阵奇异)。
-
负类分布 :与正类共享相同的均值,但方差更大------通过一个可学习的缩放向量 δσδσ 逐元素放大正类方差。这体现了"负类样本在特征空间中更分散"的合理假设。
2. 贝叶斯决策
对于查询样本,计算其后验概率 p(y=0∣fθ(x))p(y=0∣fθ(x))(属于正类的概率)。当后验概率≥0.5时判为正类,否则为负类。
后验概率的计算巧妙简化了:引入可学习参数 rr,将先验概率比与高斯分布的归一化常数整合在一起,避免直接计算行列式(防止数值溢出)。
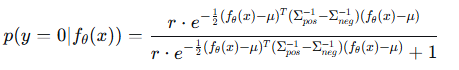
3. 方差下界约束:防止梯度爆炸
在元学习训练中,不同任务的正类随机变化,导致估计的方差可能极小,引发梯度爆炸。BayesAHDD引入方差下界约束,将小于阈值 ll 的方差元素裁剪到 ll,显著提升了训练稳定性。
实验验证:全面超越现有方法
研究团队在多个基准数据集上进行了严格评估,包括Omniglot、miniImageNet、CIFAR-FS,以及领域特定的CUB-200-2011鸟类数据集和真实的CNC铣床异常检测数据集。
分类准确率:显著领先
-
Omniglot (5-shot):BayesAHDD达到97.74%,优于AHDD(97.61%)
-
miniImageNet (5-shot):76.00% vs AHDD(74.87%)
-
CIFAR-FS (5-shot):79.39% vs AHDD(79.04%)
-
CUB-200-2011 (5-shot):71.45% vs AHDD(68.75%)
在使用更强骨干网络ResNet-12时,优势进一步扩大(CIFAR-FS 5-shot达到81.68%)。
F1分数与AUC:全面评估
在不平衡场景下,F1分数和AUC更能反映模型真实性能:
-
在miniImageNet(5-shot)上,BayesAHDD的F1分数76.00%,高于AHDD的74.82%
-
AUC在miniImageNet(5-shot)上达到83.60%,远超OC-ProtoNet(72.58%)和AHDD(82.47%)
真实工业场景:CNC铣床异常检测
在高度不平衡(816:35)的CNC铣床数据集中,BayesAHDD在三个操作类型上的平均准确率达到84.70%,显著优于AHDD的81.76%。
特征表示质量:更紧致、更可分
-
类间/类内距离比:在Omniglot的20个字母表上,BayesAHDD的比值均低于AHDD,尤其在Malayalam(0.67 vs 0.94)和Manipuri(0.64 vs 0.94)上优势明显,说明特征更紧致、更易区分。
-
t-SNE可视化:BayesAHDD学到的特征空间中,不同类别界限清晰,重叠极少;而AHDD存在明显混叠。
高斯性检验:验证分布假设
使用Henze-Zirkler多元正态性检验:
-
在嵌入维度7时,BayesAHDD在18/20个类别上通过正态性检验(p>0.05),而AHDD仅通过13/20个
-
这说明BayesAHDD学到的特征确实更符合高斯分布,验证了模型假设的合理性
讨论与展望
参数r的物理意义
当查询样本恰好位于类中心时,rr 等于正负类联合概率密度的峰值比。实验中学到的 rr 值很大(miniImageNet上约520),说明中心区域正类的概率密度远高于负类------这正是一个好的单类分类器应有的特性。
共享均值的合理性
虽然负类与正类共享均值看似反直觉,但这确保了负样本总能获得远离正类中心的梯度信号,使优化方向明确、收敛稳定。
局限与未来方向
-
高斯分布假设:对非高斯分布的数据可能不适用,未来可探索更灵活的非超球面数据描述模型
-
固定特征表示:作为基于度量的元学习方法,特征表示在元训练后固定,难以适应环境变化。未来可引入在线学习或进化计算,实现持续适应
总结
BayesAHDD通过将贝叶斯决策规则与高斯分布建模引入小样本单类分类,实现了从几何假设到概率建模的范式突破。其核心创新------方差共享与缩放、可学习先验参数、方差下界约束------共同构建了一个理论上优雅、实践上强大的框架。
实验结果表明,BayesAHDD不仅在标准基准上全面超越现有方法,在真实的工业异常检测场景中也表现出色。这项工作为小样本单类分类开辟了新方向,也为其他小样本学习任务提供了有益启示。