一、项目背景
单一的健身 Agent 对于不同需求的问题会出现不同的问题。
比如用户问"我上周跑了多少公里?"------这需要查数据库,返回精确数字。
但用户又问"跑步后腿酸怎么办?"------这需要检索专业文档,返回知识性建议。
如果强行用一个 Agent 处理所有问题,要么数据查询不准,要么知识回答缺乏依据。
这就是 Multi-Agent 系统的价值所在:让不同的 Agent 各司其职,由一个协调层统一调度。
最终实现的效果如下:
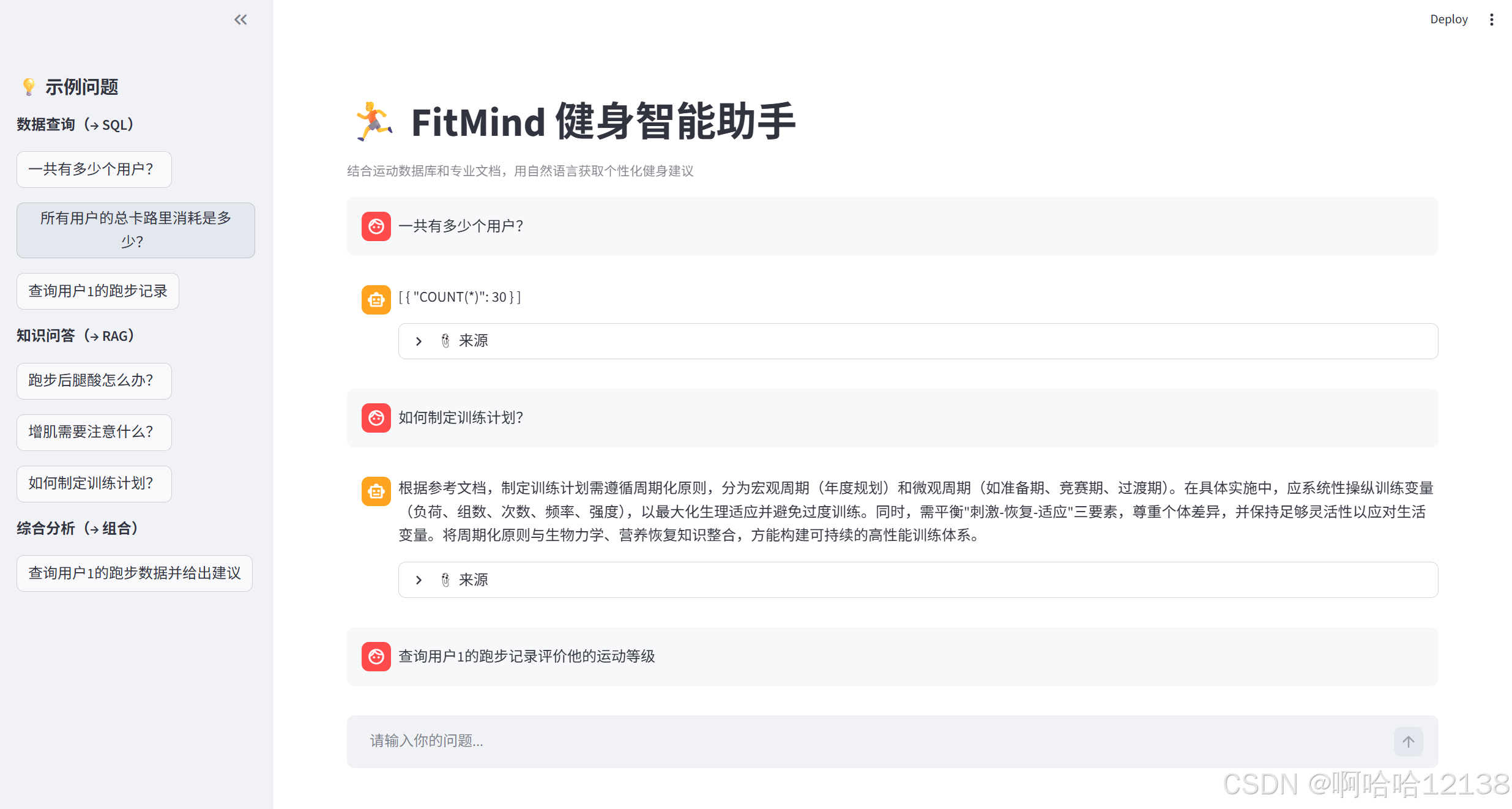
用户用自然语言提问,系统自动判断问题类型并路由:
-
数据类问题 → SQLAgent 查询 SQLite 数据库,返回精确结果
-
知识类问题 → RAGAgent 检索专业文档,返回有依据的建议
-
综合类问题 → 两者协同,数据 + 知识合并成完整回答
技术栈一览
| 组件 | 选型 |
|---|---|
| LLM | 千问 qwen-turbo(OpenAI兼容接口) |
| Embedding | 千问 text-embedding-v3(1024维) |
| 精排模型 | 千问 gte-rerank |
| 向量数据库 | ChromaDB(本地持久化) |
| 结构化数据库 | SQLite |
| 界面框架 | Streamlit |
| 本地调试 | Ollama + qwen3:4b |
二、系统架构设计
整体架构
先看整体架构,再逐层拆解:
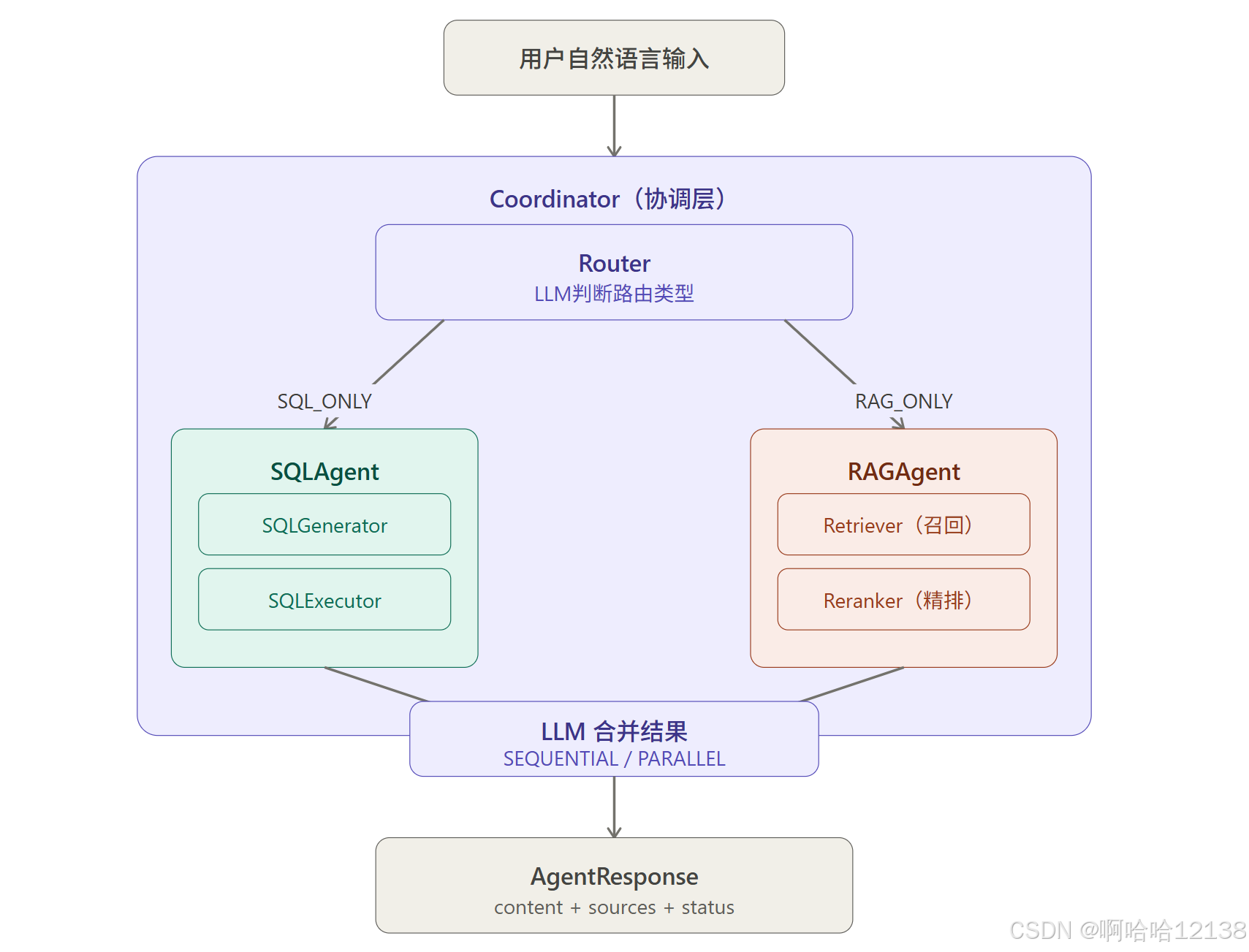
整个系统分三层:Agent 层、协调层、适配层,每层职责清晰,互不耦合。
设计决策一:模板方法模式(BaseAgent)
所有 Agent 都继承自 BaseAgent 抽象基类:
python
class BaseAgent(ABC):
def __init__(self):
self.logger = logging.getLogger(self.__class__.__name__)
self.agent_name = self.__class__.__name__
def run(self, request: AgentRequest) -> AgentResponse:
"""公开入口,所有子类统一走这里"""
self._validate(request) # 验证输入
start = time.time()
try:
response = self._process(request) # 子类实现业务逻辑
except Exception as e:
return self._handle_error(e, request)
finally:
elapsed = int((time.time() - start) * 1000)
self.logger.info(f"{self.agent_name} 耗时 {elapsed}ms")
return response
@abstractmethod
def _process(self, request: AgentRequest) -> AgentResponse:
"""子类必须实现,只写业务逻辑"""
...这样设计的好处是:验证、计时、日志、错误处理由基类统一处理,子类只写业务逻辑。 新增一个 Agent 只需要继承 BaseAgent 并实现 _process(),其他全部复用。
设计决策二:适配器模式(LLM 统一接口)
项目开发阶段用本地 Ollama 调试(零费用),上线切换千问云端 API,业务代码一行不改:
python
class BaseLLM:
def invoke(self, prompt: str) -> str:
"""统一接口,所有子类必须实现"""
response = self.client.chat.completions.create(
model = self.model,
messages = [{"role": "user", "content": prompt}],
temperature = self.temperature,
)
return response.choices[0].message.content
class OllamaLLM(BaseLLM):
def __init__(self, model="qwen3:4b"):
self.client = OpenAI(
base_url = "http://localhost:11434/v1",
api_key = "ollama",
)
class QwenLLM(BaseLLM):
def __init__(self, model="qwen-turbo"):
self.client = OpenAI(
base_url = "https://dashscope.aliyuncs.com/compatible-mode/v1",
api_key = os.getenv("DASHSCOPE_API_KEY"),
)千问和 Ollama 都实现了 OpenAI 兼容接口,切换只需要改一行初始化代码。
设计决策三:依赖注入
所有组件从外部注入依赖,不在内部创建:
python
# ✅ 依赖注入:可测试,可替换
coordinator = Coordinator(
llm = QwenLLM(), # 外部传入
sql_agent = SQLAgent(...),
rag_agent = RAGAgent(...),
)
# ❌ 硬编码:难测试,无法替换
class Coordinator:
def __init__(self):
self.llm = QwenLLM() # 内部创建,测试时无法换成Mock正是因为这个设计,测试时才能方便地注入 Mock 对象,30 个测试用例得以快速运行。
四种路由策略
Coordinator 支持四种调度模式:
| 路由类型 | 触发场景 | 执行方式 |
|---|---|---|
| SQL_ONLY | 纯数据查询 | 只调用 SQLAgent |
| RAG_ONLY | 纯知识问答 | 只调用 RAGAgent |
| SEQUENTIAL | 需要数据支撑知识回答 | 先SQL后RAG,SQL结果传入RAG的context |
| PARALLEL | 数据和知识互相独立 | 两者同时调用,结果合并 |
三、SQLAgent:自然语言查数据库
SQLAgent 负责把用户的自然语言问题转换成 SQL 并执行,返回结构化数据。内部由两个模块组成:SQLGenerator (生成SQL)和 SQLExecutor(执行SQL)。
整体流程
plain
用户问题
│
▼
SQLGenerator
├── 填充 prompt(问题 + 表结构 + 用户ID + 当前日期)
├── 调用 LLM 生成 SQL
├── 安全检查(三层防御)
└── 返回 SQLGenerationResult
│
▼
SQLExecutor
├── 执行 SQL(SQLite)
├── 结果转成 List[Dict] 格式
└── 返回 SQLExecutionResult
│
▼
AgentResponse(content = JSON字符串)Prompt 设计
Prompt 是 SQLAgent 的核心,设计得好坏直接决定生成 SQL 的质量。
最终版 prompt 包含四个关键要素:
python
self._prompt_template = """
你是一个专业的数据库专家,将自然语言转换为准确的 SQL 查询。
# 数据库结构
{table_schema}
# 当前上下文
- {user_id_instruction}
- 当前日期:{current_date}
- 时间定义:
· "今天" = date('now')
· "最近7天" = date('now', '-7 days') 至今
# 查询示例
示例1:查询特定用户的跑步距离
SQL: SELECT COALESCE(SUM(distance), 0) FROM workout_sessions
WHERE user_id=1 AND sport_type=1
示例2:查询所有用户总数(全局统计)
SQL: SELECT COUNT(*) FROM users
# 输出要求
1. 只返回一行 SQL,不要任何解释
2. 不要加分号
3. 只允许 SELECT 查询
4. 只在涉及特定用户时才加 WHERE user_id 条件
SQL:
"""易错点
这里有一个关键踩坑 :最初 prompt 里写的是"必须包含 WHERE user_id 条件",导致查询用户总数这种全局统计也被加上了 WHERE user_id=unknown,SQL 直接报错。
解决方案是根据是否传入有效 user_id,动态生成不同的约束:
python
if user_id and user_id != "unknown":
user_id_instruction = f"当前用户ID:{user_id},查询个人数据时用 WHERE user_id={user_id} 过滤"
else:
user_id_instruction = "这是全局统计查询,不需要 WHERE user_id 条件"三层 SQL 安全防御
即使 LLM 生成了危险 SQL,也无法对数据库造成破坏:
第一层:关键词黑名单
python
DANGEROUS_KEYWORDS = ["UPDATE", "DELETE", "INSERT", "DROP", "ALTER", "TRUNCATE"]
def _safety_check(self, sql: str) -> None:
sql_upper = sql.upper() # 转大写,防止大小写绕过
for keyword in DANGEROUS_KEYWORDS:
if keyword in sql_upper:
raise SQLGenerationError(f"包含禁止关键词: {keyword}")第二层:sqlparse 语句类型检查
python
def _parse_check(self, sql: str) -> None:
parsed = sqlparse.parse(sql)[0]
first_token = parsed.get_type()
if first_token != "SELECT":
raise SQLGenerationError("只允许SELECT查询")第三层:数据库只读权限
即使前两层被绕过(比如通过注释混淆),数据库本身配置为只读,写操作直接被拒绝。
三层防御的逻辑是:拦截意图 → 拦截语法 → 拦截执行,层层兜底。
空结果 vs 执行错误的区分
SQLExecutor 有一个容易忽略但很重要的设计:
python
@dataclass
class SQLExecutionResult:
success: bool
rows_count: int
data: Optional[List[Dict]] # [] 表示空结果,None 表示执行失败
error: Optional[str]data=[] 和 data=None 是两种完全不同的状态:
plain
data = [] → 查询成功,数据库里没有符合条件的记录
→ 告诉用户:"您还没有跑步记录,快去运动吧!"
data = None → SQL 执行失败,系统出现异常
→ 告诉用户:"系统繁忙,请稍后重试"
→ 同时触发告警,通知运维介入两者混淆会把系统故障当成"没有数据"处理,掩盖真实问题。
另一个踩坑:session_id 和 user_id 混用
开发过程中遇到过一个隐蔽的 bug:
plain
LLM 生成的 SQL:
WHERE user_id=20d71de2-509a-44e9-995a-e1802047eb9e
这是 UUID 格式,数据库里 user_id 是整数
→ SQL 语法错误,系统崩溃根本原因是把 AgentRequest.session_id(UUID,用于追踪请求)当成了数据库的 user_id(整数,用于过滤数据)传给了 LLM。
修复方案是在 AgentRequest 里单独加一个 user_id 字段:
python
@dataclass
class AgentRequest:
task: str
session_id: str = field(default_factory=lambda: str(uuid.uuid4()))
user_id: Optional[str] = None # 数据库层面的用户ID,和session_id完全不同这个 bug 的教训 :概念相似的字段一定要明确区分,不能混用。session_id 标识"这次请求",user_id 标识"这个人",两者生命周期和用途完全不同。
四、RAGAgent:两阶段文档检索
RAGAgent 负责从专业文档库里找到最相关的内容,结合 LLM 生成有依据的回答。核心设计是两阶段检索:向量召回 + 精排。
为什么需要两阶段?
很多教程直接用向量检索就结束了,但实际效果并不理想。原因在于:
向量检索只看"语义相似",不理解"问题意图"。
比如用户问"跑步后腿酸怎么办?",向量检索可能返回:
plain
第1名:0.57 "跑步技术与损伤预防"(提到跑步,但没针对腿酸)
第2名:0.61 "常见跑步损伤处理指南"(直接回答腿酸)← 这个更有用
第3名:0.67 "力量训练对耐力的提升"(相关性一般)Reranker 的作用是对候选结果重新精排,从"语义相似"升级为"对回答最有帮助":
plain
精排后:
第1名 0.507 "常见跑步损伤处理指南" ← 被提升到第一
第2名 0.434 "跑步技术与损伤预防"
第3名 0.429 "力量训练对耐力的提升" ← 抗疲劳内容被识别为相关但为什么不直接对全量文档做精排?
plain
文档库有 32 个块,直接精排 = 32 次 API 调用 → 慢且贵
两阶段方案:
第一阶段:向量检索毫秒级找出 Top-5 候选(数学计算,极快)
第二阶段:Reranker 只处理 5 个块 → 快且准确Retriever:向量召回
python
class Retriever:
def __init__(self, docs_dir: str, db_path: str):
# 千问 Embedding 模型,1024维向量
self.embed_client = OpenAI(
api_key = os.getenv("DASHSCOPE_API_KEY"),
base_url = "https://dashscope.aliyuncs.com/compatible-mode/v1"
)
# ChromaDB 持久化存储,重启后不丢失
self.chroma_client = chromadb.PersistentClient(path=db_path)
self.collection = self.chroma_client.get_or_create_collection("fitmind_docs")
def _chunk_text(self, text: str, chunk_size=500, overlap=100) -> List[str]:
"""带重叠的固定大小切块,防止关键信息被切断"""
chunks, start = [], 0
while start < len(text):
chunks.append(text[start:start + chunk_size])
start += chunk_size - overlap # 步长=500-100=400,保留100字重叠
return chunks
def load_documents(self) -> int:
"""离线阶段:文档切块→Embedding→存入ChromaDB"""
if self.collection.count() > 0:
return self.collection.count() # 已加载则跳过,避免重复
# ... 读取文件、切块、embedding、存储为什么用 PersistentClient 而不是内存模式?
内存模式每次重启都要重新 Embedding 全部文档。32 个块还好,生产环境文档库可能有几万个块,每次重启重新 Embedding 要花几小时,还会产生大量 API 费用。持久化到磁盘,只需要第一次加载,后续直接检索。
Reranker:精排
python
class Reranker:
def rerank(self, retrieval_result: RetrievalResult) -> RerankResult:
documents = [chunk.content for chunk in retrieval_result.chunks]
resp = TextReRank.call(
model = "gte-rerank",
query = retrieval_result.query,
documents = documents,
top_n = self.top_n,
)
reranked_chunks, reranked_scores = [], []
for item in resp.output.results:
reranked_chunks.append(retrieval_result.chunks[item.index])
reranked_scores.append(item.relevance_score)
return RerankResult(query=retrieval_result.query,
chunks=reranked_chunks, scores=reranked_scores)注意 Reranker 返回的 relevance_score 越高越相关,和 Retriever 的 distance(越小越相关)方向相反。两者的本质区别:
plain
distance(向量距离):数学计算,看语义相似度
relevance_score(相关性):模型理解,看能否回答问题
relevance_score 更能反映真实相关性,但计算成本更高
两阶段结合,兼顾效率和准确率RAGAgent 组装
python
def _process(self, request: AgentRequest) -> AgentResponse:
# 第一阶段:向量召回
retrieval_result = self.retriever.retrieve(query=request.task, top_k=5)
if not retrieval_result.chunks:
raise RetrievalEmptyError("未检索到相关文档")
# 第二阶段:精排
rerank_result = self.reranker.rerank(retrieval_result)
# 拼接 context,带来源标注
context = "\n\n".join([
f"[来源:{chunk.source}]\n{chunk.content}"
for chunk in rerank_result.chunks
])
# LLM 生成回答
answer = self.llm.invoke(self._answer_prompt.format(
context = context,
query = request.task,
))
# sources 去重
sources = list(set([chunk.source for chunk in rerank_result.chunks]))
return AgentResponse(status=AgentStatus.SUCCESS,
content=answer, sources=sources, ...)五、Coordinator:智能调度层
Router:LLM 驱动的路由决策
python
self._prompt_template = """
你是一个智能路由助手。根据用户问题判断调用哪个Agent。
可用Agent:
- SQLAgent:处理结构化数据查询、数字统计
- RAGAgent:处理文档检索、知识问答
路由规则:
- 只需要数据查询 → sql_only
- 只需要文档检索 → rag_only
- 需要数据+文档(后者依赖前者)→ sequential
- 需要数据+文档(互相独立)→ parallel
只输出JSON:
{{"route_type": "类型", "reasoning": "原因", "order": ["顺序"]}}
"""Router 有两层容错机制:
python
try:
data = json.loads(raw_response)
return RouteDecision(
route_type = RouteType(data.get("route_type", "sequential")),
reasoning = data.get("reasoning", "无原因"), # .get() 防止KeyError
order = data.get("order", ["sql", "rag"]),
)
except json.JSONDecodeError:
# LLM 返回非法 JSON,使用默认策略
return RouteDecision(
route_type = RouteType.SEQUENTIAL,
reasoning = "LLM返回格式异常,使用默认路由策略",
order = ["sql", "rag"],
)为什么用 .get() 而不是直接用 []?
LLM 返回的 JSON 是外部不可控数据,可能缺少某个字段。.get("key", 默认值) 在 key 不存在时返回默认值,[] 索引则直接抛 KeyError。对外部数据始终用防御性编程。
SEQUENTIAL 的核心:上下文传递
SEQUENTIAL 最关键的逻辑是把 SQL 结果传给 RAG:
python
def _run_sequential(self, request: AgentRequest) -> AgentResponse:
# 第一步:SQL 查询数据
sql_response = self.sql_agent.run(request)
# 第二步:把 SQL 结果塞进 RAG 的 context
rag_request = AgentRequest(
task = request.task,
context = [{"role": "assistant", "content": sql_response.content}]
# ↑ RAGAgent 带着这份数据去检索最相关的建议
)
# 第三步:RAG 基于数据给出建议
rag_response = self.rag_agent.run(rag_request)
# 第四步:LLM 合并两份结果
return self._merge(sql_response, rag_response)如果没有这步上下文传递,RAGAgent 不知道用户跑了多少公里,只能给出通用建议。有了数据支撑,回答才能真正个性化。
六、测试体系
测试金字塔
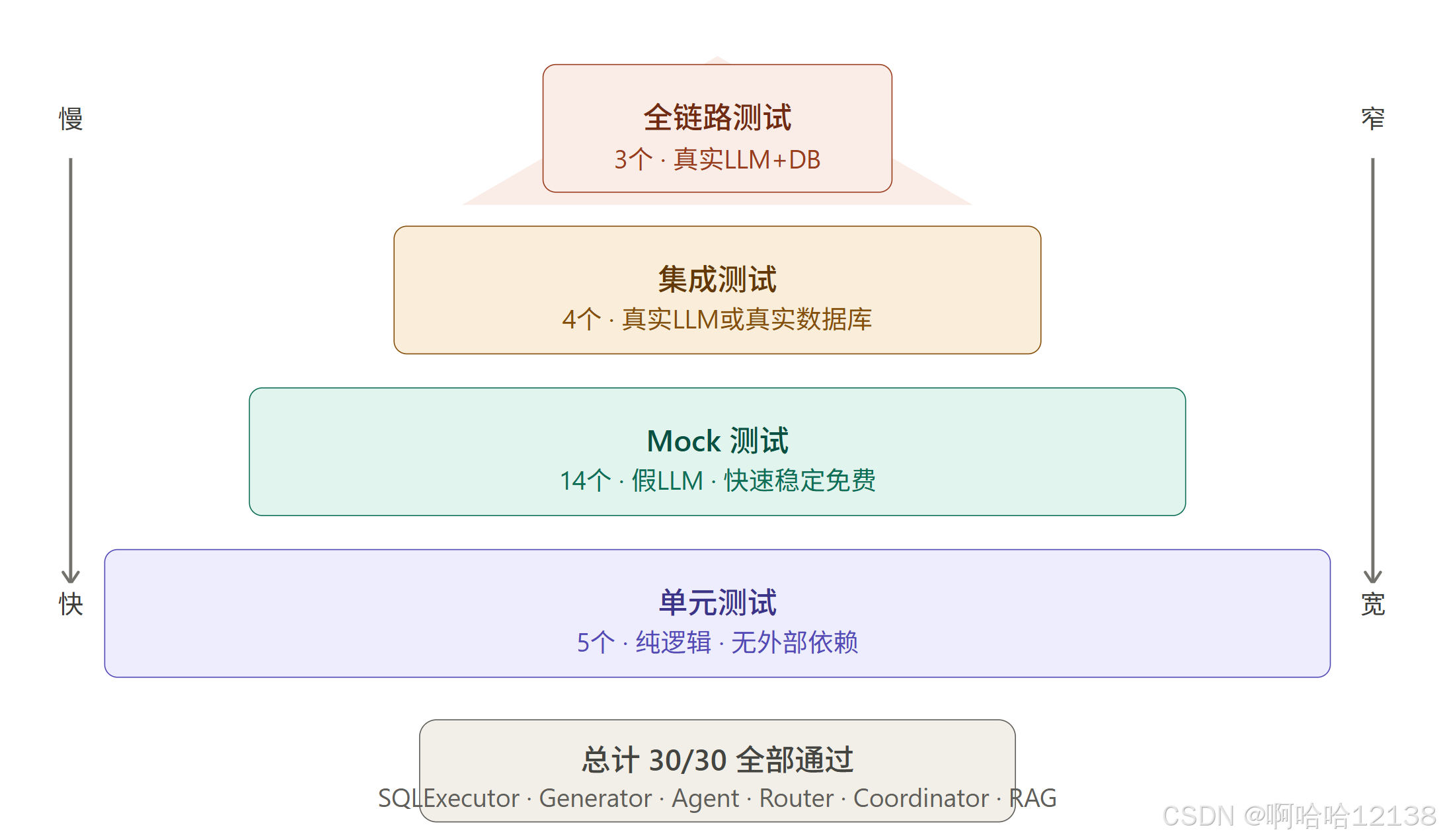
为什么大部分用 Mock?
python
# 不用Mock:每次测试真实调用LLM
# 100个测试 × 3秒 = 5分钟,CI/CD无法接受
# 而且LLM输出不稳定,今天通过明天可能失败
# 用Mock:
mock_llm = MagicMock()
mock_llm.invoke.return_value = "SELECT COUNT(*) FROM users"
# 毫秒级,结果100%可预期,免费Mock 测试的核心思想:测试的是"我的代码逻辑",不是"LLM的能力"。LLM 返回什么是 LLM 厂商的责任,我们只需要测试拿到返回值后,自己的代码处理是否正确。
一个有价值的测试:验证 SEQUENTIAL 的上下文传递
python
def test_sequential_route():
# ... 设置 Mock
result = coordinator.run("分析我的跑步数据并给出训练建议")
# ⭐ 核心断言:SQL结果是否真的传入了RAG的context
rag_call_request = mock_rag_agent.run.call_args[0][0]
assert SQL_CONTENT in rag_call_request.context[0]["content"]
# 如果这个断言失败,说明 SEQUENTIAL 退化成了 PARALLEL
# 两个Agent各自独立运行,没有数据传递,回答缺乏个性化这类行为验证测试在 Agent 开发里特别重要。数据传递错误不会报异常,只会让回答质量下降,很难靠人工发现。

七、踩坑总结
开发过程中遇到的坑,记录下来希望对你有用。
坑1:load_dotenv() 位置不对
python
# ❌ 放在 if __name__ == "__main__" 里
# 其他文件 import 这个模块时,__main__ 块不执行
# os.getenv("DASHSCOPE_API_KEY") 返回 None → 报错
# ✅ 放在模块顶层,import 之后立刻调用
from dotenv import load_dotenv
load_dotenv() # 模块被导入时自动执行坑2:LangChain 和 OpenAI SDK 返回格式不同
python
# LangChain:返回 AIMessage 对象
raw = llm.invoke(prompt)
sql = raw.content.strip() # 需要取 .content
# OpenAI SDK / Ollama:直接返回字符串
raw = llm.invoke(prompt)
sql = raw.strip() # 直接用
# 踩坑:按 LangChain 写法写了代码,换成 OpenAI SDK 后全部报错
# AttributeError: 'str' object has no attribute 'content'
# 解决:用适配器模式统一接口,invoke() 永远返回 str坑3:new 跳过 init 的风险
python
# 测试时用 __new__ 跳过 __init__ 注入 Mock
agent = RAGAgent.__new__(RAGAgent)
# 风险:BaseAgent.__init__ 里初始化的属性全部缺失
# agent.agent_name → AttributeError
# agent.logger → AttributeError
# 修复:手动补上父类初始化的属性
agent.logger = logging.getLogger("RAGAgent")
agent.agent_name = "RAGAgent"坑4:Prompt 约束导致的静默错误
python
# ❌ prompt 里写死"必须包含 WHERE user_id 条件"
# 查询用户总数时生成:SELECT COUNT(*) FROM users WHERE user_id=unknown
# SQL报错,但如果不测试根本发现不了
# ✅ 根据是否有有效 user_id,动态调整约束
# 这类"静默错误"比报错更危险:数据悄悄出错,系统不报警坑5:.gitignore 文件名拼错
plain
.gitinore ← 少了一个 t
# .gitignore 不生效,.env 差点被上传到 GitHub
# API Key 泄露后果很严重,一定要在第一次 git add 前确认八、总结与后续规划
项目地址
GitHub:https://github.com/crgon/fitmind-multi-agent
本地运行:
bash
pip install streamlit openai chromadb dashscope python-dotenv sqlparse
streamlit run app.py这个项目让我理解的几件事
Multi-Agent 的价值不是"多个AI",而是"分工"。 每个 Agent 只做一件事,做好做精,比一个全能 Agent 效果好得多。
Prompt 工程和代码工程同等重要。 Prompt 写得不好,不会报错,只会让结果悄悄变差。需要像测试代码一样测试 Prompt。
分层测试是 Agent 开发的必要投入。 全链路失败时,能在30秒内定位到具体哪一层出了问题,这个能力值得花时间建立。
后续可以加的功能
plain
□ 用户系统:支持注册登录,填写身高/体重/年龄等基本信息,存入数据库
□ 目标制定:用户说明减脂/增肌目标,助手生成每周运动量和每日饮食建议
□ 饮食运动记录:用户用自然语言描述今日饮食和运动,助手自动估算卡路里并记录,支持当日总结
□ 流式输出(Streaming):回答逐字显示,减少等待焦虑
□ 对话记忆:多轮对话时保留上下文
□ 异步并发:PARALLEL 模式升级为真正的 asyncio 并发全文完。如果对你有帮助,欢迎点赞收藏,有问题在评论区交流