"几何投影",更规范的说法通常不是这个词本身,而是下面几类术语之一。不同语境会用不同词。
最常见的是 projective shadow / projection-based shadow ,或者更具体一点叫 geometry-based shadowing 。
意思是:阴影形状由实际几何体的遮挡关系计算出来,而不是由预定义遮罩或函数生成。
shadow is geometry-driven vs shadow is mask-driven。
- hair 增加一个 ShadowCaster pass,这个你说得对
- face 不是必须新开一个单独的 "ReceiveShadow pass"
- 一般是在现有 Forward pass 中加入 shadow coord 和 GetMainLight(shadowCoord)
你要的如果是"标准实时阴影链路",结构应该是:
- hair
- UniversalForward
- DepthOnly
- ShadowCaster
- face
- UniversalForward 里做 shadow receive
- DepthOnly
- 不必专门多开一个 ShadowReceiver pass
为什么 face 不一定单独开 pass:
- 阴影接收不是像投影 那样有独立 shadow map写入阶段
- 它++只是前向着色时,读主光阴影图后把光照压暗++
- 所以多数 URP shader 都是在 Forward pass 内完成
不是。SDF 的生成一般不是"多角度光照融合" 。你说的那个流程更像 light-space occlusion baking / shadow mask baking ,而 SDF(Signed Distance Field)生成的核心是"距离场计算"。
你提到的这个仓库 SDFTool 的功能其实很简单:
它是 把一张二值图(黑白mask)转换成 SDF 图 。GitHub
也就是说输入通常是:
overflow-visible!
binary mask / alpha mask
输出是:
overflow-visible!
signed distance field texture
而不是从多角度光照合成。
SDF一般怎么生成
典型流程是:
overflow-visible!
输入:二值图 / alpha mask
↓
计算每个像素到边界的距离
↓
距离正负号编码
↓
输出 distance field
数学上就是:
overflow-visible!
d(x) = distance(x, nearest boundary)
inside → 正
outside → 负
或者反过来。
最后通常会 归一化到 0-1 存进纹理。
常见 SDF生成算法
实时图形里常见的生成方式:
1 Jump Flooding (GPU)
复杂度
overflow-visible!
O(n log n)
流程:
overflow-visible!
seed → jump propagation → distance compute
优点:
-
GPU可做
-
速度快
-
常见于实时生成
2 Euclidean Distance Transform (EDT)
最标准算法。
复杂度:
overflow-visible!
O(n)
典型论文:
overflow-visible!
Felzenszwalb Distance Transform
很多 SDF 工具用这个。
brute force
最简单:
overflow-visible!
for each pixel:
search nearest boundary
复杂度:
overflow-visible!
O(n²)
只适合小图。
为什么很多SDF是从一张图生成
因为 SDF 本质是:
overflow-visible!
distance to silhouette
而 silhouette 就是:
overflow-visible!
binary mask
例如:
overflow-visible!
hair mask
font glyph
shape mask
shadow mask
SDF 只是把边界变成距离信息。
SDF 可以:
1 resolution independent
一个 256 SDF 可以放大很多倍。
因为在 shader 里会根据 光方向改变采样坐标。
例如:
overflow-visible!
uv = project(facePosition , lightDir)
所以:
overflow-visible!
同一张mask
- 不同 light direction
→ 阴影位置变化
因此只需要一张基础 mask。
SDF 是函数还是图
SDF 本质是函数:
f(p) = distance(p , surface)
但 GPU 不会每帧计算这个函数。
所以一般会 预计算并存储成纹理。
这叫:
distance field texture
也就是:
SDF texture
因此:
SDF function
↓ sampling
SDF texture
就像:
BRDF function
↓
BRDF LUT
是同样思想。
怎么从 mask 转 SDF
过程是 distance transform。
例如:
原 mask
overflow-visible!
██████
██████
██ ██
算法计算:
overflow-visible!
每个像素到最近边界的距离
结果:
overflow-visible!
3 2 1 0 1 2
2 1 0 0 0 1
1 0 -1 -1 0 1
然后归一化到
overflow-visible!
0~1
存进纹理。
工具例如:
-
SDFTool
-
msdfgen
-
distance transform
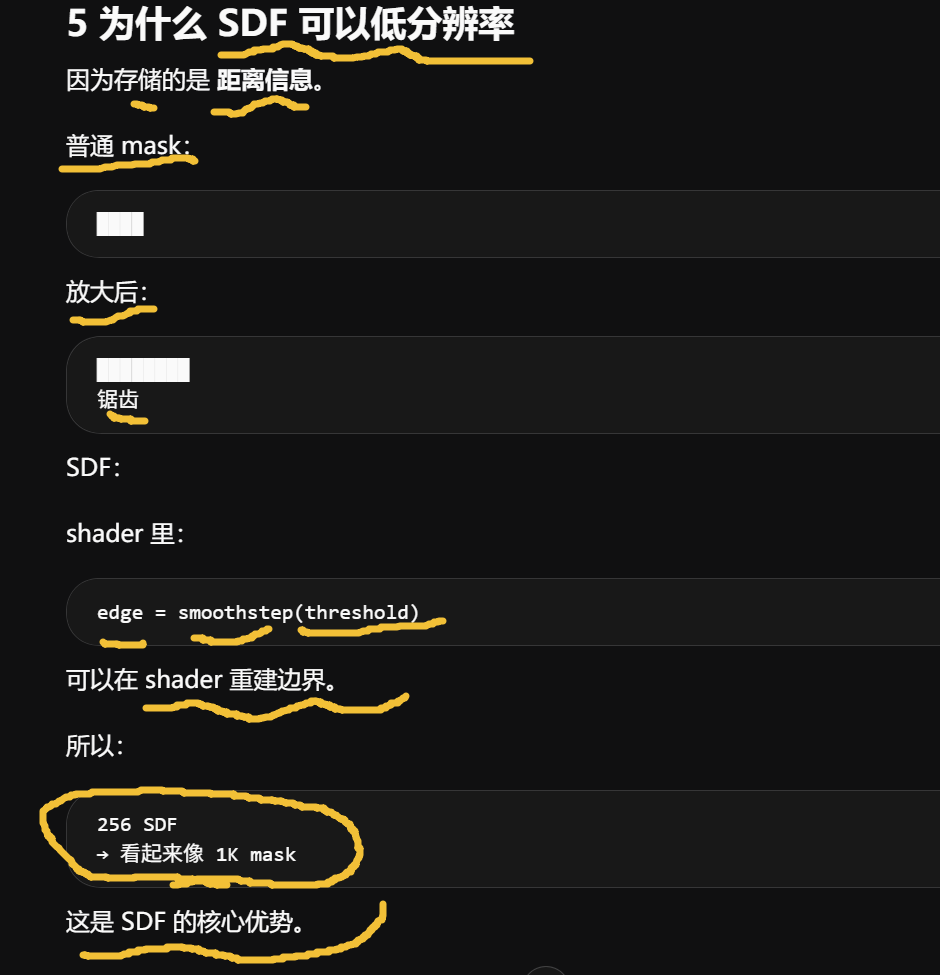
SDF:
shader 里:
edge = smoothstep(threshold)
可以在 shader 重建边界。
所以:
256 SDF
→ 看起来像 1K mask
转换 SDF
使用工具:
overflow-visible!
distance transform
得到:
overflow-visible!
HairShadowSDF.png
step3 shader
overflow-visible!
float d = tex2D(_HairShadowSDF, uv).r;
shadow = smoothstep(t1,t2,d);
控制:
overflow-visible!
阴影宽度
软边
抗锯齿
为什么很多项目用 SDF 而不是直接 mask
原因有三个。
1 边缘稳定
普通 mask:
overflow-visible!
aliasing
SDF:
overflow-visible!
smooth edge
理论上是函数,但实际 存成纹理。
从图变 SDF?
使用 distance transform 算法。
SDF 为什么能放大?
因为存的是 距离信息而不是边界像素。
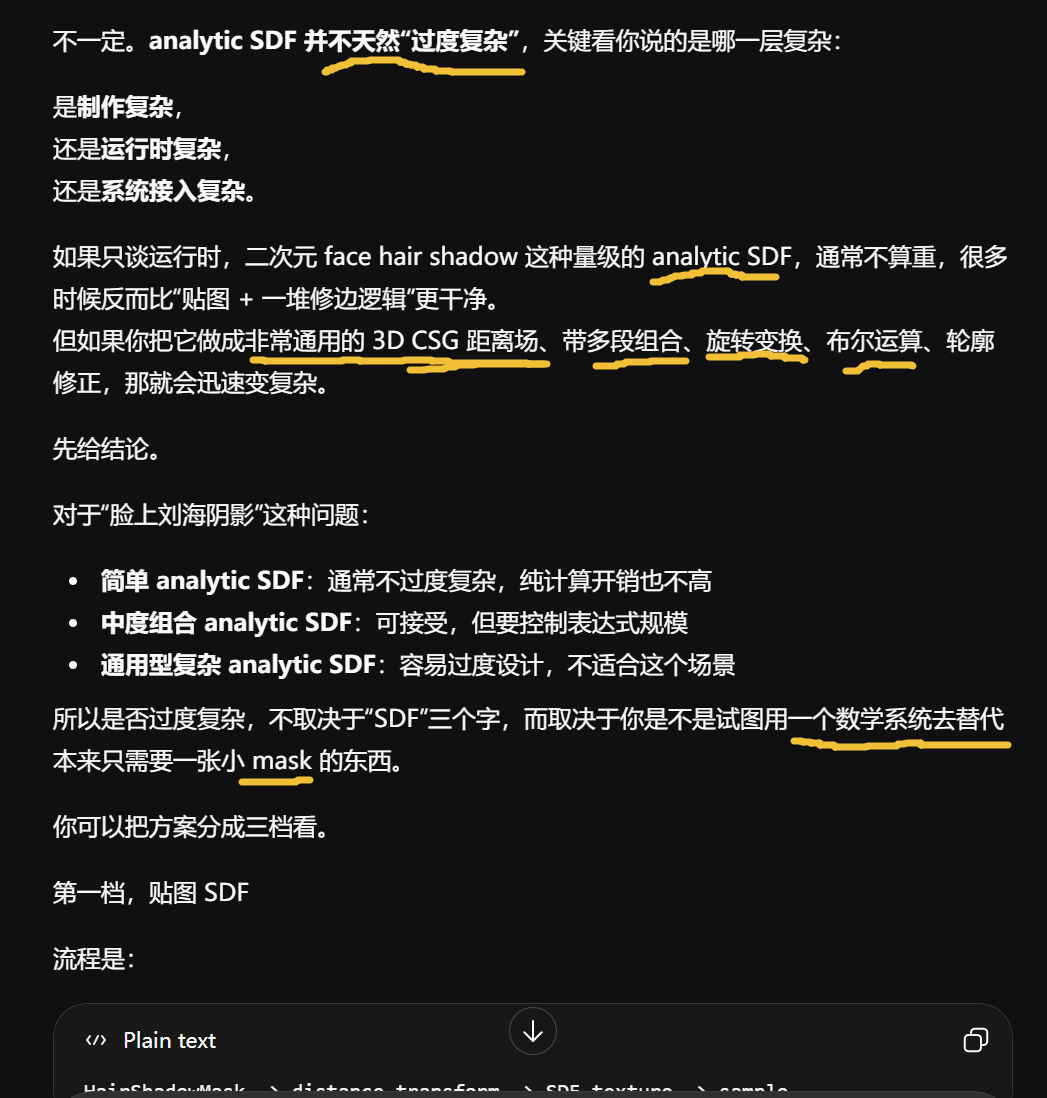
简单、低频、结构明确的阴影边界 ,适合 analytic。
复杂、强角色特征、强美术依赖的轮廓,更适合贴图或 hybrid
对 face hair shadow 这种小逻辑,通常:
-
简单 analytic SDF 不会因为 ALU 过高而成为问题
-
反而常常是更轻的,因为它省掉一次采样和贴图资源管理
尤其在移动端,少一张采样有时比多十几条 ALU 更划算。
当然这不是绝对规律,但在 NPR face shader 这种局部逻辑里很常见。
不过有一个前提:analytic SDF 要保持低频、低图元数、低分支 。
一旦你加很多 if/else、很多旋转矩阵、很多多段 piecewise 修正,它就不再是"简单 analytic"了。
analytic SDF 的"复杂"往往不在运行时,而在 authoring 模型。
也就是:
-
数学上好不好表达
-
参数是不是直觉
-
美术能不能调
-
技术美术能不能维护
例如一个圆、椭圆、box 的 union 很简单。
但"刘海中间缺口 + 左右不对称 + 随头转稍微滑动 + 贴合某角色额头比例"这件事,很快就不再是纯数学优雅问题,而是 authoring ergonomics 问题。

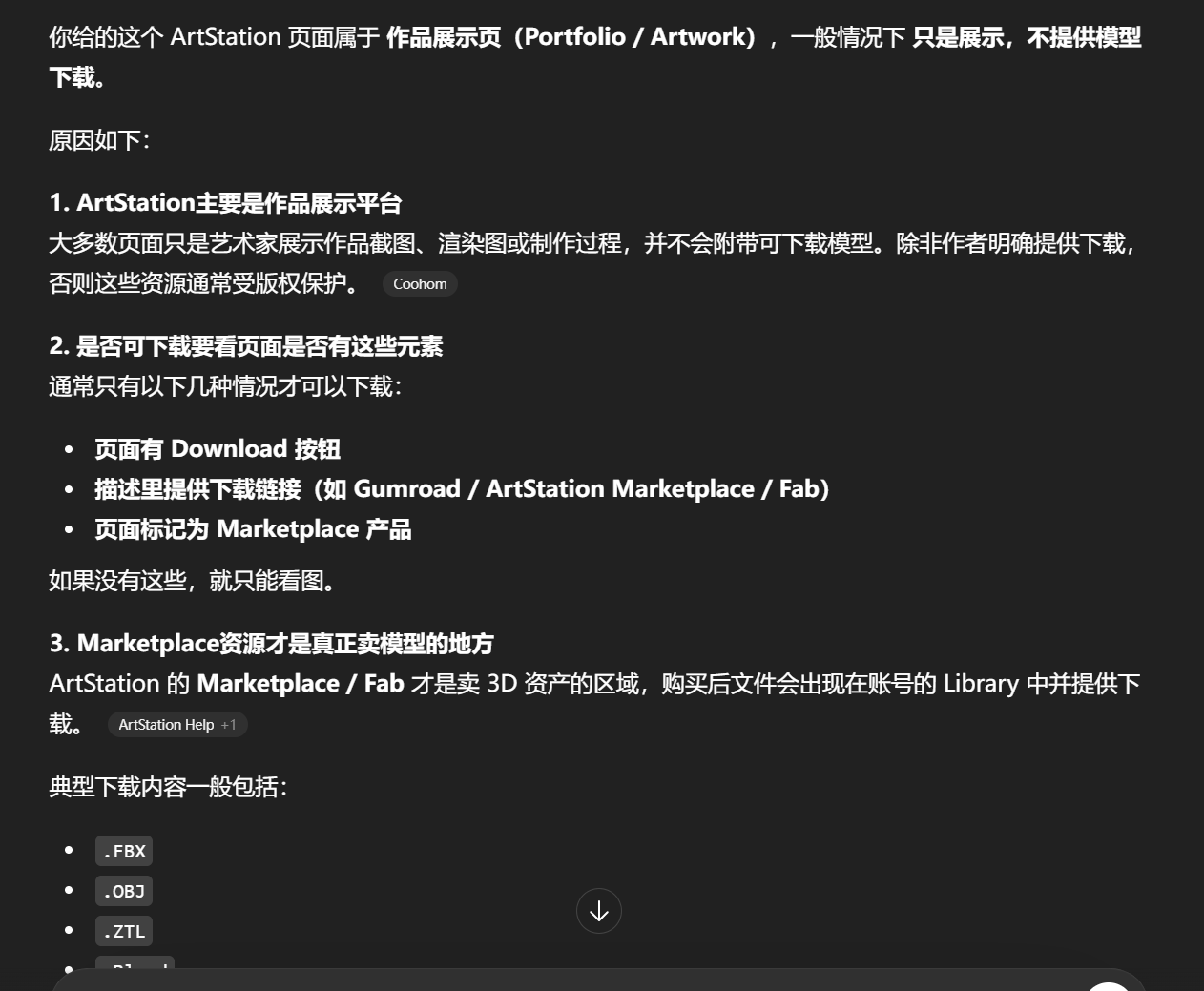
不是"三出一"。你图里的关系其实是 三张独立的 mask → 各自转 SDF → 再做插值混合 → 出现错误结果 。
右边那张并不是某种"3→1 的 SDF 生成",而是作者在说明 SDF 插值的缺陷。
如果你直接做 mask 插值:
shape = lerp(maskA, maskB, t)
得到的是两个形状的像素混合,但仍然保持局部结构。
第二步:把每一张 mask 转成 SDF。
每个 SDF 表示的是:
d(p) = 到该形状边界的距离
所以你得到三张 distance field。
第三步:在 shader 或工具里做 SDF 插值。
例如:
d = lerp(dA, dB, t)
再通过阈值恢复形状:
mask = d < 0
问题就出在这里。
因为:
lerp(distanceA, distanceB)
≠ distance(lerp(shapeA, shapeB))
也就是说:
距离场线性插值不等价于几何形状的线性插值。
于是会出现你右边看到的现象:
-
两个形状的距离场在中间叠加
-
形成一个"能量最低点"
-
产生奇怪的过渡结构
所以右图那种像"沙漏"的形状其实是:
d = lerp(SDF_square, SDF_circle, 0.5)
得到的结果。
不是从三张图生成一张,而是 SDF 插值产生的伪形状。
第四步:为什么会这样。
因为 SDF 表达的是:
distance to nearest boundary
当你插值两个距离场时:
d = (d1 + d2) / 2
某些区域会同时"接近两个形状",于是形成新的零等值面。
零等值面就是新的轮廓。
因此就出现了:
原来不存在的形状
这也是为什么很多文章说:
SDF 不适合直接做 morph / shape interpolation。
在 Built-in 里成立,核心不是因为 Built-in 有什么特殊魔法,而是因为它利用了最朴素的一套固定功能管线顺序:
先把脸提早画出来,写入颜色和深度;
再把"沿光方向偏移后的头发"以更早但仍在正常场景之前的队列画出来,开 ZTest、关 ZWrite,并用 Blend DstColor Zero 直接乘到已经画好的脸颜色上;
最后再画正常头发和其他 Geometry。文章里明确就是这么排的:脸放到 Background-20,偏移头发放到 Background-10,正常头发和其余物体回到 Geometry;偏移头发 pass 开 ZTest、关 ZWrite,并用 Blend DstColor Zero 做类似正片叠底的结果。
【不需要模板测试或额外RT】卡通渲染-刘海投影:一种简单的实现方式---知乎-爬爬修炼中
https://zhuanlan.zhihu.com/p/602180952
拆成三层来看:引擎帧阶段、C# 侧渲染提交、Shader/Pass 侧实际执行。
你关心的其实不是"文件怎么放",而是"谁先把脸写进当前 color/depth,谁再拿这个 dst color 去乘,谁最后再按正常路径覆盖"。
先给一个最接近那篇 Built-in trick 的执行顺序模型,
Camera.Render()
├─ Clear Color/Depth
├─ 渲染队列 Background-20:FacePass
│ └─ 写入 face 的颜色和深度
├─ 渲染队列 Background-10:HairShadowPass
│ └─ 顶点沿光方向偏移后的"假头发"
│ └─ ZTest On, ZWrite Off
│ └─ Blend DstColor Zero
│ └─ 直接乘到已经存在的 face color 上
├─ 渲染队列 Geometry:Normal Opaque
│ ├─ 正常头发
│ ├─ 身体
│ ├─ 场景其他不透明物体
│ └─ 继续用正常深度规则写入
├─ AlphaTest / Transparent / Skybox / PostFX ...
└─ Present
最关键的依赖关系只有两个:
一是 FacePass 必须先把脸写进当前 framebuffer。
二是 HairShadowPass 执行时,dst color 必须已经是脸的颜色,depth 里也必须已经有脸的深度。
所以从工程角度,它不是"一个 shader 很神奇",而是"一个严格依赖 draw order 的小流程"。
下面按文件组织讲。
一、场景对象和材质组织
最朴素的 Built-in 写法一般是:
CharacterRoot
├─ FaceRenderer -> FaceMaterial -> queue = Background-20
├─ HairRenderer -> NormalHairMaterial-> queue = Geometry
└─ HairShadowRenderer-> HairShadowMaterial-> queue = Background-10
其中 HairShadowRenderer 有两种来源:
一种是直接复用同一份头发网格,多挂一个 Renderer 或多材质子通道。
另一种是单独复制一个"投影头发"子对象,只用于阴影乘色 pass。
在这种 trick 里,第二种通常更好管。因为你会明确区分:
正常头发:真实几何、真实着色。
投影头发:只负责偏移和乘色,不参与正常外观。
这里只是表达意图。实际 Unity 里你一般直接在 shader tag 或材质 inspector 里定 queue,而不是运行时写死。
cs
class CharacterSetup : MonoBehaviour
{
MeshRenderer faceRenderer;
MeshRenderer hairRenderer;
MeshRenderer hairShadowRenderer;
void Awake()
{
faceRenderer.sharedMaterial.renderQueue = 1000 - 20; // Background-20
hairShadowRenderer.sharedMaterial.renderQueue = 1000 - 10; // Background-10
hairRenderer.sharedMaterial.renderQueue = 2000; // Geometry
}
}Built-in 相机执行阶段的伪代码
Built-in 没有 URP 那种显式 RendererFeature 调度,所以你可以近似理解成:
Camera 在渲染不透明对象时,会按 queue 从小到大排序提交。
伪代码可以写成这样:
cs
void RenderCamera(Camera cam)
{
SetRenderTarget(CameraColor, CameraDepth);
Clear(CameraColor | CameraDepth);
// 1. 先画 queue 更小的 face
DrawRenderers(queueRange: Background-20);
// 2. 再画 queue 稍后的 hair shadow
DrawRenderers(queueRange: Background-10);
// 3. 最后正常 opaque
DrawRenderers(queueRange: Geometry);
DrawSkybox();
DrawTransparent();
PostProcess();
Present();
}脸的 pass 非常普通。它的任务只有一个:
尽早把脸画进颜色和深度。
不仅是颜色,还有深度,两者不能分开去对待,
Face Shader 的 Pass 组织,这一 pass 的本质不是"脸 shader 多复杂",而是:
ColorBufferx,y = FaceColor
DepthBufferx,y = FaceDepth
HairShadow Shader 的 Pass 组织
这是核心 pass。它不画正常头发外观,只画"偏移投影体"。
它的执行语义是:
-
顶点沿光方向偏移;
-
用深度测试确保只在脸前面、且当前像素通过 ZTest 时才参与;
-
不写深度;
-
用乘法混合去乘当前 framebuffer 里已经存在的脸颜色。
-
"depth buffer"和"backbuffer"在现代 GPU pipeline 里都属于 render target attachment,
先把深度缓冲状态梳理清楚。
Face pass 之后:
DepthBuffer = FaceDepth
ColorBuffer = FaceColor
HairShadow pass:
ZTest LEqual
ZWrite Off
Blend DstColor Zero
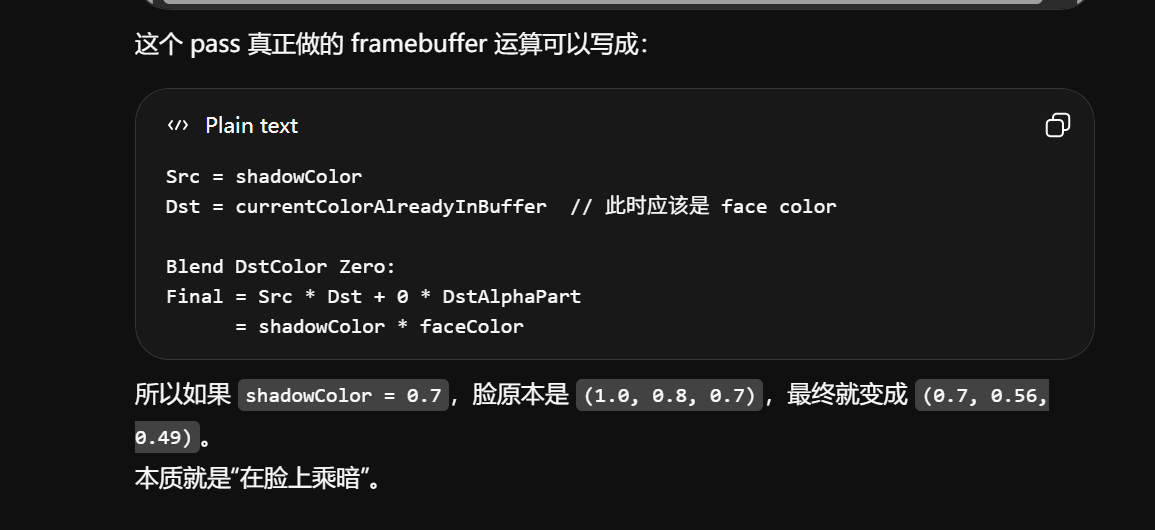
如果 HairShadow 命中:
ColorBuffer = ShadowColor * FaceColor
DepthBuffer 仍然 = FaceDepth
注意:深度没有变化。
接下来如果某个物体 B 在队列上位于:
Face < HairShadow < B < Hair
而 B 的深度满足:
BDepth < FaceDepth
那么 B 会通过 ZTest:
ZTest: BDepth <= FaceDepth → PASS
于是:
ColorBuffer = BColor
DepthBuffer = BDepth
结果就是:
-
B 直接覆盖在脸和阴影之上
-
看起来像"穿透"了
但严格说不是穿透,而是深度规则允许它正确覆盖。因为当前深度仍然是 FaceDepth。
这就是为什么这套 trick 必须保证一个严格的队列区间:只是利用了头发和头发阴影之间实在是非常窄,并且不让玩家突脸看---这是默认的事情,因为如果允许突脸,那整个建模都是可以穿透的,那所有美感都崩溃了,也不在你这一个trick了
Face
HairShadow
Hair
SceneOpaque
而不是:
Face
HairShadow
SceneOpaque
Hair
否则 SceneOpaque 就会插进来。
total control of ,
硬件架构的"语种"不同 (CPU Architecture)
- 手机 :绝大多数使用 ARM 架构(追求低功耗)。
- 电脑 :绝大多数使用 x86 架构(追求高性能)。
- App 是针对 ARM 指令集编写的。电脑的 CPU 根本"听不懂"手机 App 发出的指令。如果要在电脑上运行,电脑必须逐条翻译这些指令(即模拟器的工作),这会消耗大量资源,且效率极低。
- App 运行涉及到频繁的内存交换和总线通信。手机内部的总线速度以 GB/s 计,而普通的 USB 3.0 只有 5Gbps (约 600MB/s)。
- 如果让电脑运行 App,却要把手机里的海量数据实时通过 USB 线传来传去,这种数据延迟会导致程序瞬间卡死。
- 手机 :绝大多数使用 ARM 架构(追求低功耗)。
- 电脑 :绝大多数使用 x86 架构(追求高性能)。
- App 是针对 ARM 指令集编写的。电脑的 CPU 根本"听不懂"手机 App 发出的指令。如果要在电脑上运行,电脑必须逐条翻译这些指令(即模拟器的工作),这会消耗大量资源,且效率极低。
利用电脑的高性能(比如大内存、更强的处理器)来跑手机 App,目前唯一的办法是安卓模拟器 (Emulator) ,如 蓝叠 (BlueStacks) 或 雷电模拟器。
游戏内部可以更新,为什么还需要去Google play分开更新?
bash
这是一个很普遍的现象,主要原因在于"代码"与"资源"是分开存放且更新机制不同的:
* Google Play 负责更新"骨架"(程序代码):
* 底层运行逻辑:涉及到游戏的核心引擎修改、兼容性优化(比如适配新的安卓系统)、安全性补丁或重大功能变更。
* 安全审核:应用商店需要对修改后的底层代码进行安全扫描和合规性检查,确保没有病毒或违规行为。这种更新通常被称为"换包"或"大版本更新"。
* 游戏内部更新负责"皮肉"(美术资源):
* 素材文件:包括新的皮肤、英雄模型、地图贴图、语音包和活动配置等。
* 追求效率:这些资源文件往往非常大(动辄几个GB)。如果通过 Google Play 更新,不仅开发者需要通过漫长的审核流程,用户也可能需要重新下载整个几GB的安装包。
* 热更新:游戏厂商通过自己的服务器推送这些资源,可以绕过商店审核,实现"今天修 Bug,今天就上线"的极速响应。 [1, 2, 3, 4, 5, 6, 7, 8, 9]
为什么要"分开"这么麻烦?
1. 分层下载节省流量:如果你只需要更新一张新地图,没必要让 Google Play 把几十 MB 的核心程序代码也重新下载安装一遍。
2. 规避审核周期:大型节假日活动(如春节、圣诞)的时效性很强。如果等 Google Play 审核几天,活动可能都过半了。通过内部更新,厂商能瞬间开启新内容。
3. 安装包瘦身:很多游戏为了让你在商店下载时更快,只在商店放一个几百 MB 的"空壳"程序,等进入游戏后再按需下载剩下的几个 GB 数据。 [1, 7, 8, 9, 10, 11]
简单来说:Google Play 的更新是给手机系统看的(保证能跑起来),而游戏内的更新是给玩家看的(保证有新内容玩)。 [3, 7]
如果你发现 Google Play 显示有更新但点不开,通常是由于商店缓存问题。你可以尝试在[手机设置中清除 Google Play 商店的缓存](https://support.google.com/googleplay/answer/113412?hl=en-GB)来解决。 [12]
如果你想了解如何减少这些更新带来的流量消耗,或者为什么有些更新总是失败,我可以继续为你解答。
[1] [https://www.reddit.com](https://www.reddit.com/r/AndroidGaming/comments/dgjbx2/why_do_some_games_update_from_within_the_app/)
[2] [https://www.youtube.com](https://www.youtube.com/watch?v=-6o_dJs-nTM)
[3] [https://www.reddit.com](https://www.reddit.com/r/NoStupidQuestions/comments/iotisg/why_do_some_mobile_games_have_both_ingame_updates/)
[4] [https://www.youtube.com](https://www.youtube.com/watch?v=-6o_dJs-nTM)
[5] [https://www.reddit.com](https://www.reddit.com/r/NoStupidQuestions/comments/iotisg/why_do_some_mobile_games_have_both_ingame_updates/)
[6] [https://www.quora.com](https://www.quora.com/What-is-the-difference-between-updating-content-in-apps-and-updating-apps-in-the-App-Store-Why-are-applications-automatically-updated-if-this-feature-was-disabled-in-the-settings)
[7] [https://www.facebook.com](https://www.facebook.com/groups/MobileLegends/posts/2721158634793783/)
[8] [https://www.reddit.com](https://www.reddit.com/r/AndroidGaming/comments/dgjbx2/why_do_some_games_update_from_within_the_app/)
[9] [https://www.reddit.com](https://www.reddit.com/r/gamedev/comments/y9rcuv/curiosity_question_why_some_games_update_outside/)
[10] [https://developer.android.com](https://developer.android.com/google/play/app-updates)
[11] [https://www.quora.com](https://www.quora.com/Mobile-games-seem-to-rely-more-on-updates-instead-of-making-sequels-Why-is-this)
[12] [https://www.reddit.com](https://www.reddit.com/r/DissidiaFFOO/comments/s1df95/game_is_telling_me_to_update_the_version_but/)DXBC(DirectX Bytecode)**是 Direct3D 10/11 时代 HLSL 编译后的中间字节码格式 。
简单说:
HLSL 源码 → 编译 → DXBC → 驱动 → GPU 指令
它是 D3D shader 的一种中间表示(IR / bytecode),而不是最终 GPU ISA。
资产从"静态结果"变成"可调系统"。
如果身体比例改了,只要重新 shrinkwrap 就能自动贴合。
丝袜厚度、平滑程度、偏移量都只是参数。
所以流程保留的核心价值其实是:
把资产从"结果"变成"函数"。
unity项目即使是高版本低版本也可以试着兼容,ue为何完全不可?
-
本层隔离
Unity 游戏逻辑主要在 C#,通过托管 API 与引擎通信。
引擎内部可以改实现,但只要保持 API 表面稳定,项目仍然能编译。
-
序列化格式稳定
Unity 的
.prefab、.scene、.asset等 YAML/文本序列化格式长期保持兼容。即使升级版本,旧字段通常仍然能解析。
-
组件式架构
Unity 的运行时系统比较模块化,大部分功能在 C# 层。
即使引擎内部变化,组件 API 不一定变化。
-
长期维护分支(LTS)策略
Unity 明确保证某些版本 API 稳定。
新版本通常只是增加 API,而不是大规模修改。
因此 Unity 项目跨版本升级时通常只是:
-
重新导入资源
-
重新编译 C#
-
处理少量 API deprecation
即使版本差距较大,也往往能跑起来。
UE 的情况不同。
UE 的项目和引擎耦合程度非常高,因为:
1. UE 是源码级引擎
Unity 项目:
Project
↕
Unity Engine (binary)
UE 项目:
Project C++
↕
Engine C++
项目代码会直接 include:
Engine/Runtime/*
Engine/Renderer/*
Engine/Gameplay*
因此只要引擎内部 API 改动,项目代码就会编译失败。
UE 序列化格式经常变化
UE 的 .uasset / .umap 是二进制序列化。
里面包含:
-
UObject layout
-
property offsets
-
GUID
-
custom version
只要结构改变,就需要升级。
UE 允许 向前升级:
旧版本 → 新版本
但通常不支持:
新版本 → 旧版本
因为新字段旧引擎无法理解。