文章目录
- 进程间通信(IPC))
-
- 什么是进程间通信(IPC)
- 为什么需要进程间通信
-
- [数据传输(Data Transfer)](#数据传输(Data Transfer))
- [资源共享(Resource Sharing)](#资源共享(Resource Sharing))
- [事件通知(Event Notification)](#事件通知(Event Notification))
- [进程控制(Process Control)](#进程控制(Process Control))
- 多进程协同的典型示例
- 操作系统提供的IPC标准
-
- [POSIX 标准](#POSIX 标准)
- [System V 标准](#System V 标准)
- 另一类通信方式:基于文件系统
- 进程间通信的本质
- 通信的基本过程
- 不同IPC机制的本质区别
- 管道通信
进程间通信(IPC)
什么是进程间通信(IPC)
在操作系统中,进程(Process)具有独立性 。
每个进程拥有:
- 独立的 PCB(Process Control Block)
- 独立的 虚拟地址空间
- 独立的 页表映射
- 独立的 资源管理结构
因此,一个进程的运行、崩溃或退出通常不会直接影响其他进程。
然而,在实际系统中,很多任务需要多个进程协同完成 。由于进程之间相互隔离,如果需要共享数据或协同工作,就必须通过某种机制进行信息交换,这种机制称为:
进程间通信(Inter-Process Communication, IPC)。
为什么需要进程间通信
虽然进程之间是相互独立的,但在许多应用场景中仍然需要进行信息交互。进程间通信通常具有以下几类目的:
数据传输(Data Transfer)
一个进程将其产生的数据发送给另一个进程。
例如:
- 生产者进程生成数据
- 消费者进程处理数据
资源共享(Resource Sharing)
多个进程共享同一份资源,例如:
- 共享内存
- 文件
- 数据缓冲区
事件通知(Event Notification)
一个进程通知另一个进程某个事件已经发生。
例如:
- 数据准备完成
- 任务完成
- 状态变化
进程控制(Process Control)
一个进程控制另一个进程的执行。
例如:
调试工具 GNU Debugger
可以控制被调试程序的运行、暂停、单步执行等。
多进程协同的典型示例
在类 Unix 系统中,经常使用 管道(pipe) 实现进程协作,例如:
c
cat file | grep hello该命令实际上启动了两个进程:
进程1:
c
cat file负责读取文件内容。
进程2:
c
grep hello负责根据关键字过滤数据。
两者之间通过 管道(pipe) 建立连接:
c
cat → pipe → grep因此:
cat将数据写入管道grep从管道读取数据
这实际上就是一个典型的 进程间通信场景。
操作系统提供的IPC标准
为了支持进程间通信,操作系统设计者提出了多种通信机制,并形成了两类主流标准:
POSIX 标准
POSIX(Portable Operating System Interface)
特点:
- 支持 跨主机通信
- 与文件描述符模型高度统一
- 在现代系统中使用最广泛
例如: - Socket
- 管道
- 共享内存
System V 标准
System V IPC 是早期 Unix 系统提供的一组进程通信机制,主要用于:
同一主机上的进程通信
包含三种机制:
- 共享内存(Shared Memory)
- 消息队列(Message Queue)
- 信号量(Semaphore)
在现代系统中,System V IPC 仍然存在,但使用频率较低。
原因主要包括:
- 接口设计较为复杂
- 与文件描述符体系不统一
- 不适合网络通信场景
另一类通信方式:基于文件系统
除了 POSIX 和 System V 之外,还有一种通信机制:
管道(Pipe)
它本质上依赖于 文件系统机制 实现。
管道分为两种:
- 匿名管道(Anonymous Pipe)
- 命名管道(Named Pipe / FIFO)
进程间通信的本质
进程间通信的核心问题是:
如何在多个独立进程之间传递数据。
由于进程具有独立地址空间,一个进程无法直接访问另一个进程的内存。因此必须引入一个共享的数据交换区域 。
该区域具有以下特征:
- 两个进程都可以访问
- 用于临时保存通信数据
- 由操作系统负责管理
因此可以得到一个重要结论:
进程间通信的本质是:
- 操作系统直接或间接地为通信双方提供一块公共资源(通常是"内存空间"),用于进行数据交换。
- 要通信的进程必须要看到一份公共资源
换句话说:
IPC = 共享资源 + 数据交换
不同的通信种类本质就是:上面所说的资源是os哪一个模块提供的
通信的基本过程
一个完整的进程通信过程通常包括两个阶段:
第一阶段:建立共享资源
由于进程之间相互隔离,操作系统必须先创建一块双方可访问的公共资源,例如:
- 管道缓冲区
- 共享内存
- 消息队列
第二阶段:进行数据交换
通信双方通过该资源进行数据传递:
进程A → 写入数据 → 公共缓冲区 → 读取数据 → 进程B不同IPC机制的本质区别
不同的进程通信方式,本质上只是:
公共资源由操作系统的哪个模块提供
例如
| IPC方式 | 公共资源来源 |
|---|---|
| 管道 | 文件系统 |
| 共享内存 | System V / POSIX 内存管理 |
| 消息队列 | System V IPC |
| 信号量 | System V IPC |
| Socket | 网络协议栈 |
| 因此可以总结为: |
进程间通信的核心是让多个进程能够访问同一份公共资源。
管道通信
管道(Pipe)的基本概念
管道(Pipe) 是一种由操作系统提供的 进程间通信(IPC, Inter-Process Communication)机制 ,用于在 具有亲缘关系的进程(通常是父子进程)之间传递数据 。
从实现角度来看,管道本质上是一种 内核维护的内存级文件对象,其主要特点包括:
- 数据仅存在于内核缓冲区中,不会刷新到磁盘
- 通过文件描述符进行读写操作
- 通常用于父子进程之间的通信
- 默认是单向通信机制
管道的本质:内存级文件
在传统文件系统中:
-
进程调用
open()打开磁盘文件 -
操作系统创建对应的 file 结构体对象
-
内核维护文件缓冲区
-
写入数据最终可能被 刷新到磁盘
数据流如下:进程内存
↓
文件缓冲区
↓
磁盘
然而在 进程通信场景中,如果仍然采用磁盘文件作为通信媒介,则会出现以下问题:
-
数据需要写入磁盘
-
另一个进程再从磁盘读取
-
存在大量 磁盘 I/O 开销
这种方式虽然技术上可行 ,但效率极低。
因此,操作系统提供了 管道机制: -
不再依赖磁盘文件
-
仅在 内核空间创建一个文件对象
-
数据只在 内存缓冲区中传递
数据流变为:进程A
↓
内核管道缓冲区
↓
进程B
因此,管道可以理解为:
由操作系统在内核中创建的一种"内存级文件",其数据存储在内核缓冲区中,而不会持久化到磁盘。
管道文件对象的实现原理
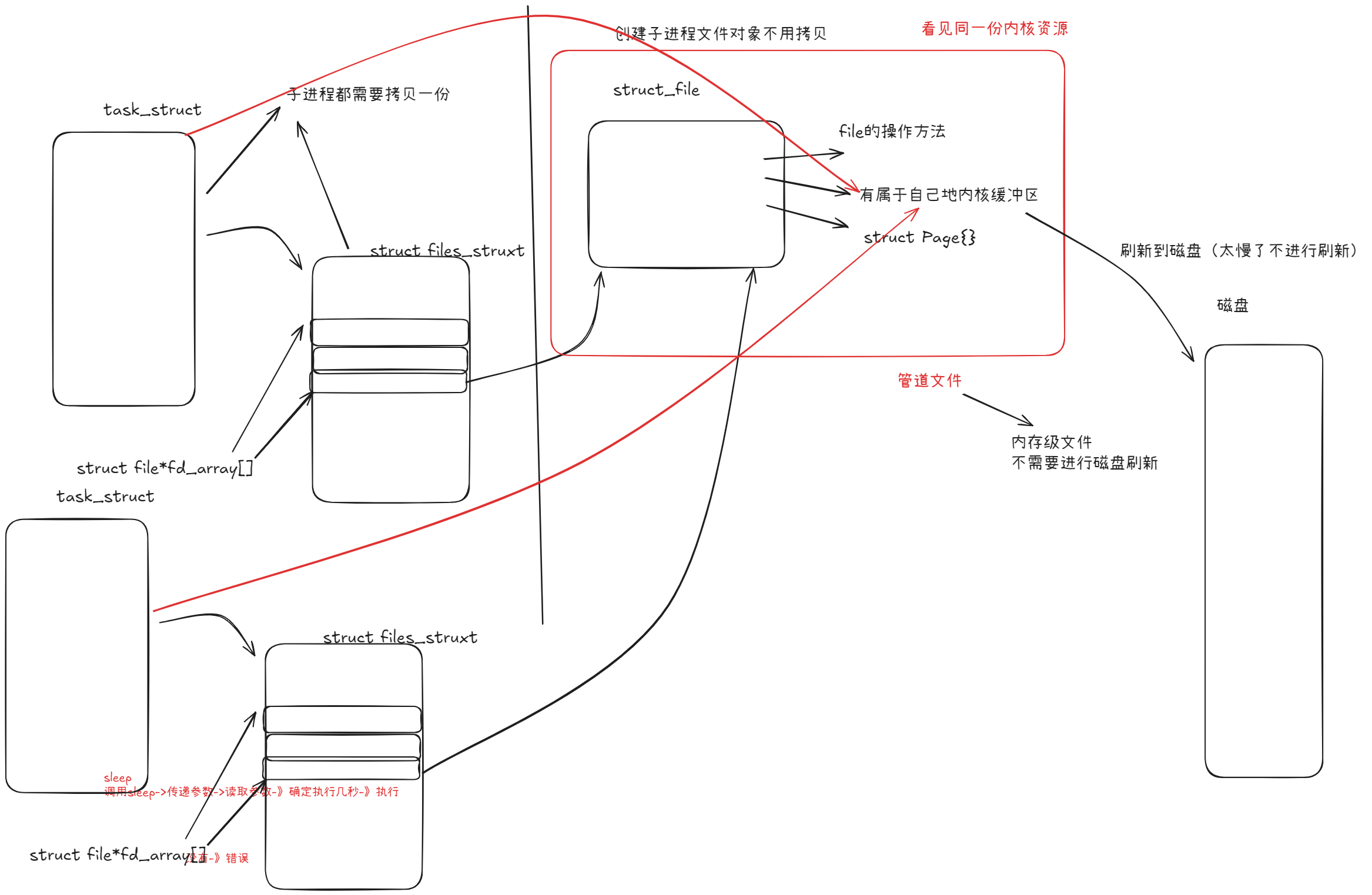
在 Linux 内核中,文件通常由 struct file 表示。
该结构体内部会包含:
- 文件操作函数指针
- 文件类型标识
- 缓冲区信息
- 文件偏移量等
对于管道文件而言: struct file中的 文件类型字段 会标识该文件为 pipe 类型- 文件数据缓冲区位于 内核空间
因此,虽然管道表现为文件描述符,但其 底层并不是磁盘文件,而是内核对象。
父子进程共享文件对象
当一个进程调用 fork() 创建子进程时:
-
子进程会复制父进程的 文件描述符表
-
文件描述符表中的指针仍然指向 同一个 file 对象
结构关系如下:父进程 fd table
↓
file *
↑
子进程 fd table
因此:
- 父子进程共享同一个文件对象
- 共享同一个内核缓冲区
这使得管道成为一种天然的 父子进程通信机制。
管道通信的基本原理
在管道通信中,操作系统创建一个特殊的管道文件(pipe file) 。
该文件内部维护一个 内核缓冲区(kernel buffer) 。
其结构可以理解为:
Process A → write() → Kernel Buffer → read() → Process B通信流程如下:
- 进程A向管道写入数据
- 数据进入内核缓冲区
- 进程B从管道读取数据
由于两个进程访问的是同一块 内核缓冲区,因此完成了数据传递。
管道文件的本质
管道(Pipe)是一种用于实现进程间通信(IPC)的机制。那么管道文件是如何产生的,以及其本质特征是什么。
首先需要区分两类文件:
- 普通文件(Regular File)
- 管道文件(Pipe File)
普通文件的工作机制
对于普通文件而言,其典型的数据流转过程如下:
-
文件存储在**磁盘(Disk)**上。
-
当进程调用
open()打开文件时:- 操作系统会在内核中创建对应的 file 对象(struct file)。
-
操作系统在内核中为该文件维护:
- 文件操作方法(file operations)
- 内核缓冲区(Kernel Buffer)
当进程对文件进行写操作时,数据流程通常为:
进程用户空间
↓
内核缓冲区
↓
磁盘文件
即:
内存 → 内核缓冲区 → 磁盘
同样,当读取文件时:
磁盘
↓
内核缓冲区
↓
进程用户空间普通文件用于通信的问题
理论上,两个进程可以通过普通文件进行通信。例如:
进程 A:
不断向文件写入数据进程 B:
不断从文件读取数据从技术角度来看,这种方式是完全可行的 。
但是,这种方式存在严重问题:
通信效率极低。
原因在于:
-
写入操作需要将数据刷新到磁盘
-
读取操作又需要从磁盘加载到内存
其完整数据路径为:进程A → 内存 → 磁盘 → 内存 → 进程B
磁盘 I/O 的开销远高于内存访问,因此这种通信方式效率非常低。
而进程间通信的核心目标是:
实现进程之间的快速数据传递(内存到内存)。
因此,操作系统在设计 IPC 机制时,通常会避免磁盘 I/O。
管道文件的实现方式
为了解决上述问题,操作系统提供了管道(Pipe)机制 。
管道文件具有以下重要特征:
管道文件并不对应磁盘上的实际文件。
换言之:
管道是一种仅存在于内核中的"内存级文件"。
具体实现方式如下:
当创建管道时,操作系统会:
-
在内核中创建一个 struct file 对象
-
为该对象分配 内核缓冲区(Kernel Buffer)
-
将该对象的地址填入进程的 文件描述符表(File Descriptor Table)
整个过程不涉及磁盘文件的创建或访问 。
因此:
管道通信的数据流为:进程A → 内核缓冲区 → 进程B
完全在内存中完成。
这也是管道通信效率较高的重要原因。
管道文件类型
在 Linux 内核中,struct file 结构体内部包含用于标识文件类型的字段。
该字段通常通过类似 联合体(union)或类型标识字段 来表示文件类型,例如:
- 普通文件
- 目录
- 设备文件
- 管道文件
当创建管道时,操作系统会:
- 创建
struct file - 将其 类型字段设置为 PIPE 类型
- 初始化对应的管道缓冲区
因此,从内核角度来看:
管道仍然是一种特殊类型的文件对象。
父子进程访问管道文件
接下来需要回答另一个问题:
两个进程是如何访问同一个管道文件的?
在匿名管道中,这一过程依赖于:
fork() 系统调用
具体流程如下:
创建管道
父进程首先创建管道文件。
此时:
-
内核中存在一个
struct file -
父进程文件描述符表中记录该文件
结构如下:父进程 fd table
↓
struct file
创建子进程
父进程调用:
fork()创建子进程。
fork 的一个重要特性是:
子进程会继承父进程的文件描述符表。
因此:
父进程 fd table
↓
struct file
↑
子进程 fd table此时:
- 父进程和子进程的文件描述符表不同
- 但其中的指针 指向同一个 struct file
因此两个进程访问的是:
同一个内核缓冲区
从而实现数据共享。