在构建对话式 AI 应用时,会话管理是一个核心功能。用户期望 AI 能够记住之前的对话内容,并且在应用重启后能够继续之前的对话。本文将详细介绍如何使用 DynamoDB 实现一个支持多会话的 LangChain Agent 系统。
我们的核心需求需要实现以下功能:
- 会话持久化:对话历史保存到数据库,应用重启后可恢复
- 多会话支持:一个用户可以创建多个独立的对话会话
- 自动加载:启动时自动加载用户最近的会话
- 会话切换:用户可以在不同会话之间切换
- 性能优化:随着对话增多,保持良好的响应速度
技术选型如下
- LLM 框架LangChain - 提供统一的 LLM 接口
- 数据库DynamoDB - AWS 托管的 NoSQL 数据库,支持自动扩展
表结构设计
对于多会话系统,我们需要支持"一个用户多个会话"的数据模型。DynamoDB 的表设计如下
-
为什么使用 user_id 作为 Partition Key?这样可以将同一用户的所有会话存储在同一个分区中,查询效率高。通过 Sort Key (session_id) 可以唯一标识每个会话。
-
为什么需要 GSI?GSI 允许我们按创建时间倒序查询用户的会话列表,这样可以快速找到最近的会话。此外GSI 投影类型为 ALL,在查询时可以获取完整的 item 数据
-
TTL 的作用?DynamoDB 的 TTL 功能可以自动删除过期的会话,避免数据无限增长。我们设置为 30 天后自动删除。
表名: ChatSessions
主键:
- Partition Key: user_id (String) - 用户ID
- Sort Key: session_id (String) - 会话ID属性:
- messages (List) - 对话消息列表
- session_name (String) - 会话名称
- created_at (Number) - 创建时间戳
- updated_at (Number) - 更新时间戳
- ttl (Number) - 过期时间(用于自动清理)全局二级索引 (GSI):
- user-time-index
- Partition Key: user_id
- Sort Key: created_at
- 用途: 按时间查询用户的所有会话
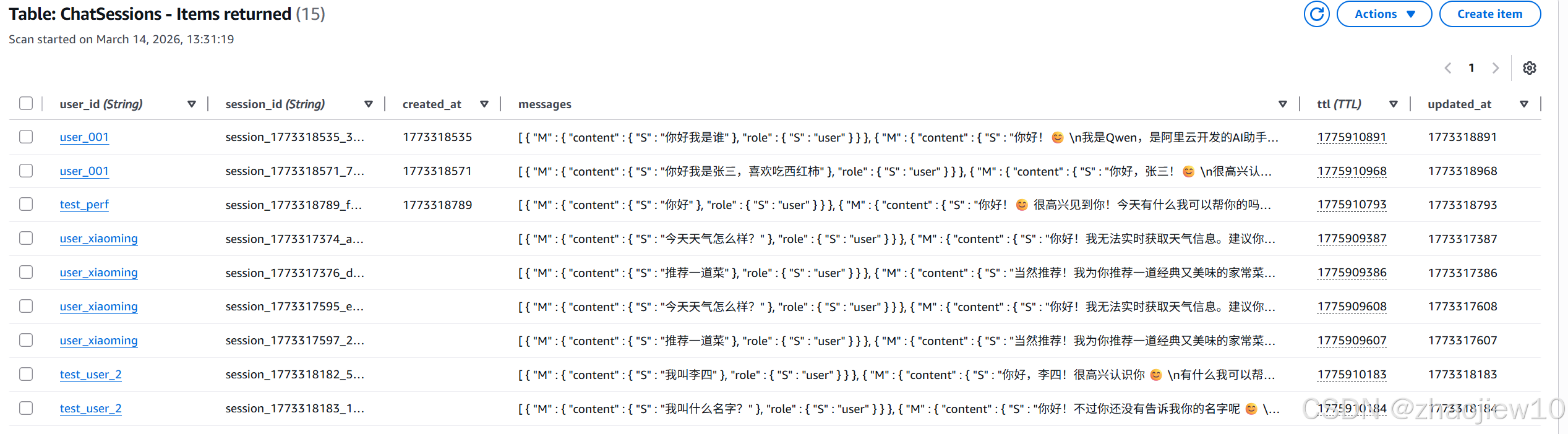
存储效果如下
会话管理器实现
会话管理器负责与 DynamoDB 交互,设计要点:
- session_id 生成策略:使用时间戳 + UUID 确保全局唯一
- 默认会话名称:如果用户不指定,自动生成带时间的名称
- TTL 设置:30 天后自动过期
python
import boto3
import time
import uuid
from datetime import datetime, timedelta
from typing import Optional, List, Dict
class MultiSessionManager:
"""支持一个用户多个会话的管理器"""
def __init__(self, table_name: str = "ChatSessions", region: str = "cn-north-1"):
self.dynamodb = boto3.resource('dynamodb', region_name=region)
self.table = self.dynamodb.Table(table_name)
def create_session(self, user_id: str, session_name: str = None) -> str:
"""创建新会话,返回 session_id"""
# 生成唯一的 session_id
session_id = f"session_{int(time.time())}_{uuid.uuid4().hex[:8]}"
created_at = int(time.time())
# 初始化会话数据
self.table.put_item(Item={
'user_id': user_id,
'session_id': session_id,
'session_name': session_name or f"对话 {datetime.now().strftime('%Y-%m-%d %H:%M')}",
'messages': [],
'created_at': created_at,
'updated_at': created_at,
'ttl': int((datetime.now() + timedelta(days=30)).timestamp())
})
return session_id保存和加载会话,关键实现细节:
- save_session 使用 put_item:直接覆盖整个 item,简单高效
- created_at 参数:是为了实现自动加载最近会话功能
- list_user_sessions 使用 GSI:通过 user-time-index 按时间倒序查询
- ProjectionExpression:只返回必要的字段,减少数据传输
python
def save_session(
self,
user_id: str,
session_id: str,
messages: List[Dict],
created_at: int = None,
session_name: str = None
):
"""保存会话数据"""
item = {
'user_id': user_id,
'session_id': session_id,
'messages': messages,
'created_at': created_at or int(time.time()),
'updated_at': int(time.time()),
'ttl': int((datetime.now() + timedelta(days=30)).timestamp())
}
if session_name:
item['session_name'] = session_name
# 使用 put_item 直接覆盖整个 item
self.table.put_item(Item=item)
def load_session(self, user_id: str, session_id: str) -> Optional[Dict]:
"""加载指定会话"""
response = self.table.get_item(
Key={
'user_id': user_id,
'session_id': session_id
}
)
return response.get('Item')
def list_user_sessions(self, user_id: str, limit: int = 20) -> List[Dict]:
"""列出用户的所有会话(按创建时间倒序)"""
response = self.table.query(
IndexName='user-time-index',
KeyConditionExpression='user_id = :uid',
ExpressionAttributeValues={':uid': user_id},
ScanIndexForward=False, # 降序排列
Limit=limit,
ProjectionExpression='session_id, session_name, created_at, updated_at'
)
return response.get('Items', [])Agent 集成
Agent 需要整合以下组件:
- LLM:使用 LangChain 的 ChatOpenAI
- Memory:对话历史存储在内存中(self.messages)
- Session Manager:负责持久化到 DynamoDB,初始化agent时从 DynamoDB 加载历史
初始化逻辑解析:
- 不指定 session_id:自动加载用户最近的会话,如果没有则创建新会话
- 指定 session_id:加载指定的会话
- created_at 缓存:在内存中保存创建时间,避免每次保存时读取数据库
这种设计让用户体验更流畅:启动应用后自动继续上次的对话。
python
from langchain_core.messages import SystemMessage, HumanMessage, AIMessage
from langchain_openai import ChatOpenAI
class MultiSessionAgent:
"""支持多会话的对话 Agent"""
def __init__(
self,
user_id: str,
session_id: Optional[str] = None,
system_prompt: str = "你是一个友好的助手",
model_name: str = "gpt-4o-mini",
api_key: Optional[str] = None,
base_url: Optional[str] = None,
dynamodb_table: str = "ChatSessions",
region: str = "cn-north-1"
):
self.user_id = user_id
self.system_prompt = system_prompt
# 初始化 LLM
llm_kwargs = {"model": model_name, "temperature": 0}
if api_key:
llm_kwargs["api_key"] = api_key
if base_url:
llm_kwargs["base_url"] = base_url
self.llm = ChatOpenAI(llm_kwargs)
# 初始化会话管理器
self.session_manager = MultiSessionManager(dynamodb_table, region)
# 加载或创建会话
if session_id:
# 指定了 session_id,加载该会话
self.session_id = session_id
self._load_session()
else:
# 未指定 session_id,尝试加载最近的会话
recent_sessions = self.session_manager.list_user_sessions(user_id, limit=1)
if recent_sessions:
self.session_id = recent_sessions[0]['session_id']
self._load_session()
print(f"[自动加载最近会话] {self.session_id}")
else:
# 没有历史会话,创建新会话
self.session_id = self.session_manager.create_session(user_id)
self.messages = []
self.created_at = int(time.time())
print(f"[新会话] {self.session_id}")对话流程详解:
- 内存操作:先将消息添加到内存中的
self.messages - 格式转换:将简单的字典格式转换为 LangChain 的消息对象
- LLM 调用:将完整的对话历史发送给 LLM
- 持久化:每次对话后自动保存到 DynamoDB
为什么每次都保存?这样可以确保数据不丢失。即使应用崩溃,用户也能恢复到最后一次对话的状态。
python
def chat(self, user_input: str) -> str:
"""对话"""
print(f"User: {user_input}")
# 1. 添加用户消息到内存
self.messages.append({"role": "user", "content": user_input})
# 2. 构建 LangChain 消息格式
lc_messages = [SystemMessage(content=self.system_prompt)]
for msg in self.messages:
if msg["role"] == "user":
lc_messages.append(HumanMessage(content=msg["content"]))
elif msg["role"] == "assistant":
lc_messages.append(AIMessage(content=msg["content"]))
# 3. 调用 LLM
response = self.llm.invoke(lc_messages)
output = response.content
# 4. 添加 AI 回复到内存
self.messages.append({"role": "assistant", "content": output})
# 5. 保存到 DynamoDB
self._save_session()
return output
def _save_session(self):
"""保存会话到 DynamoDB"""
self.session_manager.save_session(
self.user_id,
self.session_id,
self.messages,
created_at=self.created_at # 传递创建时间,避免读取数据库
)会话切换功能
python
def new_session(self, session_name: str = None) -> str:
"""创建新会话并切换到该会话"""
self.session_id = self.session_manager.create_session(self.user_id, session_name)
self.messages = []
self.created_at = int(time.time())
print(f"[创建新会话] {self.session_id}")
return self.session_id
def switch_session(self, session_id: str):
"""切换到另一个会话"""
self.session_id = session_id
self._load_session()
def list_sessions(self) -> list:
"""列出用户的所有会话"""
return self.session_manager.list_user_sessions(self.user_id)这些方法让用户可以:
- 创建新的对话主题
- 在不同会话之间切换
- 查看所有历史会话
性能优化
随着对话增多,会话数据会越来越大。每次保存都需要覆盖整个 item,这会带来性能问题。并且DynamoDB 存在限制单个 item 最大 400KB,约等于 2000 条消息。
当消息数量超过一定阈值时,可以只保留最近的 N 条消息
python
def chat(self, user_input: str) -> str:
# ... 对话逻辑 ...
# 只保留最近 100 条消息
if len(self.messages) > 100:
self.messages = self.messages[-100:]
self._save_session()
return output这样可以:
- 控制 item 大小在合理范围内,减少 LLM 的 token 消耗
- 保持响应速度稳定
当然如果对数据一致性要求不高,可以每 N 条消息保存一次,降低数据库压力,但增加了数据丢失的风险。
python
def chat(self, user_input: str) -> str:
# ... 对话逻辑 ...
# 每 5 条消息保存一次
if len(self.messages) % 5 == 0:
self._save_session()
return output通过实现了一个交互式命令行工具,支持以下命令:
bash
python chat.py
=== 多会话对话系统 ===
请输入用户ID (默认: user_001):
当前会话: session_1773318789_fe87edf3
命令:
/new - 创建新会话
/list - 列出所有会话
/switch [session_id] - 切换会话(不输入ID则显示列表)
/quit - 退出
开始对话:
You: 你好
Agent: 你好!有什么我可以帮你的吗?
You: /new
会话名称 (可选): 技术讨论
[创建新会话] session_1773318800_abc123
You: /switch
可用的会话:
→ 1. session_1773318800_abc123: 技术讨论
2. session_1773318789_fe87edf3: 对话 2026-03-12 10:30
输入序号或 session_id: 1
已切换到: session_1773318800_abc123后续可以考虑使用 Redis 缓存,将活跃会话缓存到 Redis,减少 DynamoDB 读取
python
class CachedSessionManager(MultiSessionManager):
def __init__(self, redis_client, args, kwargs):
super().__init__(args, kwargs)
self.redis = redis_client
def load_session(self, user_id, session_id):
# 先查 Redis
cached = self.redis.get(f"{user_id}:{session_id}")
if cached:
return json.loads(cached)
# Redis 没有,查 DynamoDB
session = super().load_session(user_id, session_id)
if session:
self.redis.setex(f"{user_id}:{session_id}", 3600, json.dumps(session))
return session此外,当历史消息过多,可以考虑对历史消息进行压缩存储
python
import gzip
import base64
def compress_messages(messages: List[Dict]) -> str:
"""压缩消息列表"""
json_str = json.dumps(messages)
compressed = gzip.compress(json_str.encode())
return base64.b64encode(compressed).decode()
def decompress_messages(compressed: str) -> List[Dict]:
"""解压消息列表"""
compressed_bytes = base64.b64decode(compressed)
json_str = gzip.decompress(compressed_bytes).decode()
return json.loads(json_str)