文章目录
- 前言
- [什么是 Text-to-SQL?](#什么是 Text-to-SQL?)
- 实现流程概览
- 步骤讲解
-
- [1. 依赖安装](#1. 依赖安装)
- [2. SQLDatabase ------ 数据库连接封装](#2. SQLDatabase —— 数据库连接封装)
-
- [2.1 基础连接](#2.1 基础连接)
- [2.2 常用参数](#2.2 常用参数)
- [2.3 完整示例](#2.3 完整示例)
- [3. SQLDatabaseToolkit ------ 工具包](#3. SQLDatabaseToolkit —— 工具包)
-
- [3.1 初始化](#3.1 初始化)
- [3.2 生成的工具](#3.2 生成的工具)
- [3.3 按名称获取具体工具](#3.3 按名称获取具体工具)
- [4. SQLDatabase 核心方法详解](#4. SQLDatabase 核心方法详解)
-
- [4.1 `get_usable_table_names()` ------ 获取可用表名](#4.1
get_usable_table_names()—— 获取可用表名) - [4.2 `get_table_info()` ------ 获取表结构(供 LLM 阅读)](#4.2
get_table_info()—— 获取表结构(供 LLM 阅读))
- [4.1 `get_usable_table_names()` ------ 获取可用表名](#4.1
- [5. `create_sql_agent` ------ 创建 SQL Agent](#5.
create_sql_agent—— 创建 SQL Agent) -
- [5.1 核心参数](#5.1 核心参数)
- [5.2 `agent_type` 可选值](#5.2
agent_type可选值) - [5.3 提示词控制](#5.3 提示词控制)
- [5.4 DML 权限控制(重要!)](#5.4 DML 权限控制(重要!))
- [5.5 运行控制参数](#5.5 运行控制参数)
- [5.6 高级参数](#5.6 高级参数)
- [5.7 返回值与调用方式](#5.7 返回值与调用方式)
- [5.8 完整调用示例](#5.8 完整调用示例)
- [6. 代码示例(三层递进)](#6. 代码示例(三层递进))
-
- [6.1 基础版:无 RAG、无向量库](#6.1 基础版:无 RAG、无向量库)
- [6.2 进阶版:RAG + 向量检索](#6.2 进阶版:RAG + 向量检索)
- [6.3 生产环境版:混合检索 + 去重 + 精排](#6.3 生产环境版:混合检索 + 去重 + 精排)
- 三个版本的对比总结
- [7. 查询速度优化实践](#7. 查询速度优化实践)
-
- [策略一:切换 agent_type 为 `tool-calling`](#策略一:切换 agent_type 为
tool-calling) - [策略二:在 ReAct 模式下屏蔽 `sql_db_query_checker`](#策略二:在 ReAct 模式下屏蔽
sql_db_query_checker) - 策略三:表结构存储时去掉示例数据
- [策略一:切换 agent_type 为 `tool-calling`](#策略一:切换 agent_type 为
- 总结
前言
本文基于 LangChain v1.2 生态,系统讲解如何构建一个生产可用的 Text-to-SQL 智能代理,涵盖基础用法、RAG 增强检索、混合检索 + 重排序等完整演进路径,并汇总了实际开发中容易踩到的坑。
什么是 Text-to-SQL?
简单来说,Text-to-SQL(文本到SQL) 就是让 AI 把日常的自然语言问题,自动转换成可以查询数据库的 SQL 语句。比如,你问:"上个月销售额最高的5款产品是什么?",AI 模型会将其转化为类似:
sql
SELECT product_name, SUM(sales) AS total
FROM orders
WHERE order_date BETWEEN '2026-04-01' AND '2026-04-30'
GROUP BY product_name
ORDER BY total DESC
LIMIT 5;在 AI 项目中,它的核心价值是降低数据库查询的门槛------让完全不懂 SQL 的业务人员,也能用说话的方式从数据库中获取答案,常用于智能问答、数据分析助手、低代码平台等场景。
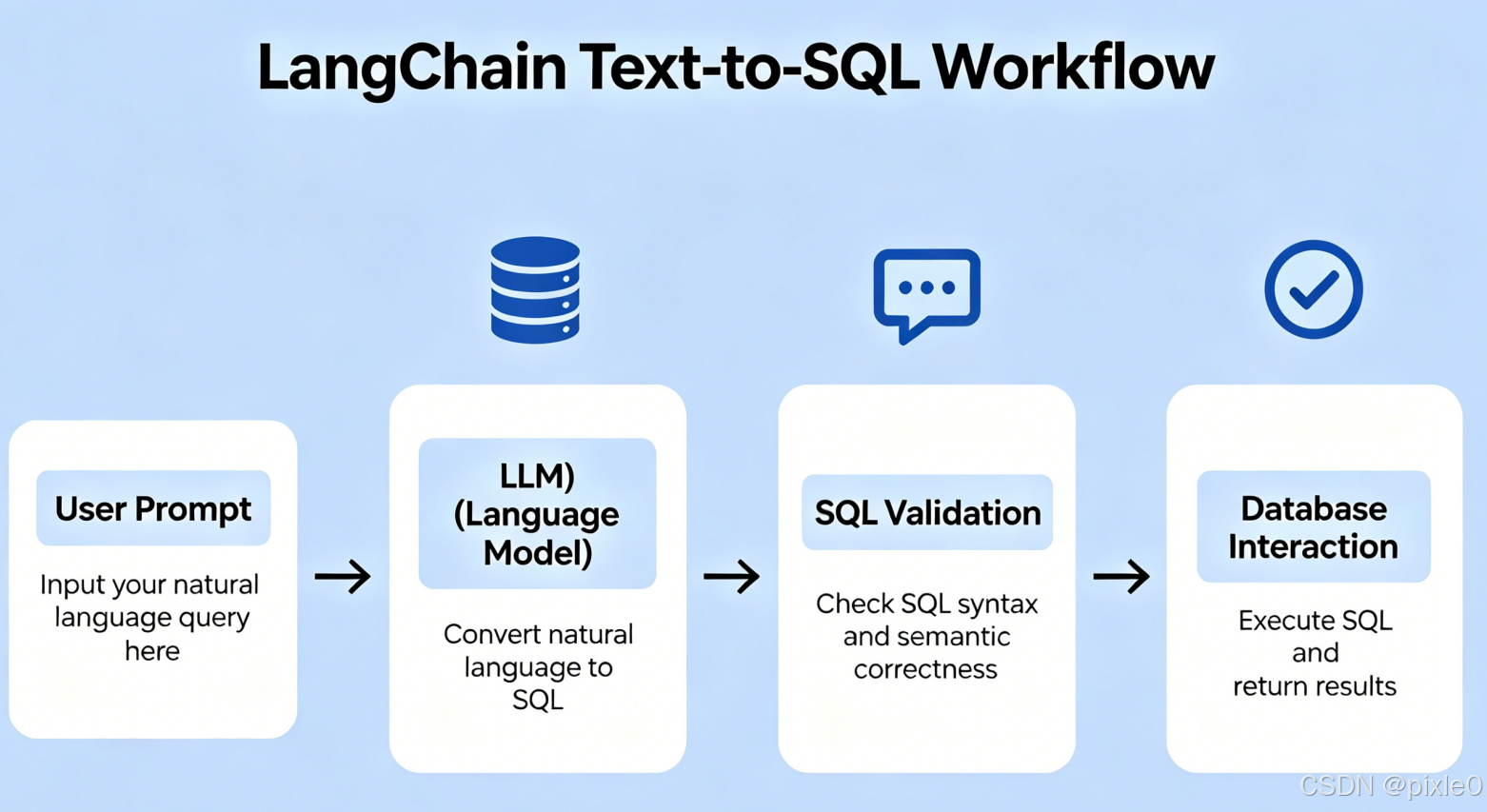
实现流程概览
在本文的 AI Agent 方案中,Text-to-SQL 被封装成一个可供大模型调用的工具链,整体实现遵循一条清晰的流水线。结合我们选用的 LangChain 组件,一条用户问题从入口到最终回答,会经历以下核心步骤:
html
MySQL / SQLite 数据库
↓
SQLDatabase 连接 & 抽取 Schema(含示例数据、业务注释)
↓
将每张表的 DDL + 样本数据向量化,存入 Chroma 向量库(进阶/生产级)
↓
用户输入自然语言问题 → Agent 自动识别需查库
↓
检索阶段:
- 基础版:直接塞入全部表结构
- 进阶版:基于向量的语义检索(Chroma)
- 生产版:混合检索(向量 + BM25)→ RRF 融合 → Reranker 精排
↓
将召回的相关表结构作为上下文注入 Prompt → LLM 生成 SQL
↓
SQL 安全校验(可选,如 sql_db_query_checker)
↓
执行 SQL,获取结构化数据
↓
查询结果 + 原始问题再次交给 LLM 总结 → 输出自然语言回答步骤讲解
1. 依赖安装
bash
uv add pymysql根据你实际使用的数据库驱动,也可以替换为 psycopg2(PostgreSQL)、aiosqlite(异步 SQLite)等。
2. SQLDatabase ------ 数据库连接封装
SQLDatabase 是 LangChain 中对数据库连接的抽象层,负责三件事:建立连接 、获取表结构 、执行 SQL 查询。它是整个 Text-to-SQL 管道的底座。
2.1 基础连接
python
db = SQLDatabase.from_uri("sqlite:///Demo.db") # SQLite
# 或 MySQL/PostgreSQL:
# db = SQLDatabase.from_uri("mysql+pymysql://user:pass@host/db")2.2 常用参数
| 参数 | 类型 | 说明 |
|---|---|---|
include_tables |
List[str] |
白名单,限定 Agent 可见的表名列表,如 ["Album", "Artist"] |
ignore_tables |
List[str] |
黑名单,Agent 可看到除列表外的所有表。注意:include_tables 的优先级高于 ignore_tables |
sample_rows_in_table_info |
int |
获取表结构信息时包含的示例数据行数,默认 3,设为 0 则不采样 |
custom_table_info |
dict |
手动补充表级描述,辅助 LLM 理解业务语义 |
max_string_length |
int |
字符串列的截断长度,避免单列值过长撑爆 token 上限 |
2.3 完整示例
python
db = SQLDatabase.from_uri(
"mysql+pymysql://root:abc123abc@localhost/demo",
include_tables=["products", "sales"], # 只能操作"products", "sales"
sample_rows_in_table_info=5, # 表信息示例显示5行数据
custom_table_info={
"sales": "销售订单表,记录每笔交易。字段:order_id, customer_id, amount, order_date" # 自定义表信息
},
)踩坑提示 :
include_tables和ignore_tables同时设置时,include_tables优先生效,被include_tables明确列出的表即使在ignore_tables中也会被保留。这个行为与直觉相反,容易造成调试困惑。
3. SQLDatabaseToolkit ------ 工具包
SQLDatabaseToolkit 将数据库能力封装成 LLM 可调用的工具列表(Tools),是连接 LLM 与数据库的桥梁。
3.1 初始化
python
toolkit = SQLDatabaseToolkit(db=db, llm=llm)| 参数 | 类型 | 说明 |
|---|---|---|
db |
SQLDatabase |
数据库连接对象,必填 |
llm |
BaseLanguageModel |
语言模型,用于生成查询、修复 SQL 等,必填 |
3.2 生成的工具
调用 toolkit.get_tools() 可获得工具列表,通常包含以下四把"瑞士军刀":
sql_db_query:执行 SQL 查询并返回结果。sql_db_schema:获取表结构信息(DDL + 示例数据),这是 LLM 写 SQL 的核心上下文来源。sql_db_list_tables:列出所有表名。sql_db_query_checker:用 LLM 检查并修正 SQL 语法------相当于给 SQL 加了一道"校对"工序。
3.3 按名称获取具体工具
工具列表也可以转成字典,按名称精确取出:
python
# 工具
tools = toolkit.get_tools()
# 工具转字典
tool_dict = { tool.name: tool for tool in tools }
sql_db_list_tables = tool_dict['sql_db_list_tables'] # 获取表名工具
sql_db_schema = tool_dict['sql_db_schema'] # 获取表结构信息工具
tabls = sql_db_list_tables.invoke({}) # 列出所有表名
schema = sql_db_schema.invoke({"table_names": "products"}) # 获取 products 表结构踩坑提示 :
sql_db_list_tables.invoke({})必须传入空字典{},不能传None或不传参数。这是 LangChain Tool 的运行约定------Tool 的invoke方法要求接收一个 dict,即使没有实际参数也要给空 dict。
4. SQLDatabase 核心方法详解
除了通过 Toolkit 间接使用,SQLDatabase 本身也提供了两个非常实用的方法,在自定义工具链时经常需要绕过 Toolkit 直接调用。
4.1 get_usable_table_names() ------ 获取可用表名
python
def get_usable_table_names(self) -> List[str]:返回当前数据库连接中允许被 Agent 访问 的表名列表。注意它不是 简单地列出数据库中所有表,而是结合了 include_tables / ignore_tables 过滤参数后的结果。
python
db = SQLDatabase.from_uri("mysql+pymysql://root:abc123abc@localhost/demo")
table_names = db.get_usable_table_names() # ['users', 'products', ...]4.2 get_table_info() ------ 获取表结构(供 LLM 阅读)
python
def get_table_info(self, table_names: Optional[List[str]] = None) -> str:生成一个文本格式的字符串,包含指定表(或全部可用表)的 DDL(CREATE TABLE 语句)和示例数据行。这个文本会直接塞入 LLM 的上下文,帮助模型写出准确的 SQL。
python
all_table_info = db.get_table_info() # 获取所有表结构信息
table_info = db.get_table_info(['users']) # 仅获取 users 表结构返回的字符串类似下面这样(一段同时包含 DDL 和 3 行示例数据的文本):
sql
CREATE TABLE users (
id INTEGER NOT NULL AUTO_INCREMENT,
username VARCHAR(50) NOT NULL,
email VARCHAR(100) NOT NULL,
phone VARCHAR(20),
password_hash VARCHAR(255),
real_name VARCHAR(50),
gender ENUM('male','female','other') DEFAULT 'other',
birthday DATE,
address VARCHAR(255),
avatar VARCHAR(255),
status ENUM('active','inactive','banned') DEFAULT 'active',
balance DECIMAL(10, 2) DEFAULT '0.00',
points INTEGER DEFAULT '0',
last_login_at TIMESTAMP NULL,
created_at TIMESTAMP NULL DEFAULT CURRENT_TIMESTAMP,
updated_at TIMESTAMP NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP,
PRIMARY KEY (id)
)COLLATE utf8mb4_0900_ai_ci ENGINE=InnoDB DEFAULT CHARSET=utf8mb4
/*
3 rows from users table:
id username email phone password_hash real_name gender birthday address avatar status balance points last_login_at created_at updated_at
1 张三 zhangsan@example.com 110110 None 张三 male 1990-05-15 北京市朝阳区建国路88号 None active 15000.00 2500 None 2026-04-18 14:26:08 2026-04-18 19:55:27
2 李四 lisi@example.com 13800138002 None 李四 male 1985-08-20 上海市浦东新区陆家嘴路100号 None active 28000.00 4200 None 2026-04-18 14:26:08 2026-04-18 14:32:14
3 王五 wangwu@example.com 13800138003 None 王五 female 1992-03-10 广州市天河区体育西路103号 None active 8500.00 1200 None 2026-04-18 14:26:08 2026-04-18 14:32:14
*/踩坑提示 :
get_table_info()的示例行数据是通过SELECT * FROM table LIMIT N实时查出来的,在生产大表上调用时注意耗时。可通过构造SQLDatabase时减小sample_rows_in_table_info来控制。
5. create_sql_agent ------ 创建 SQL Agent
这是 LangChain Text-to-SQL 的核心工厂函数,返回一个 AgentExecutor 实例------它把 LLM、Toolkit、提示词和运行参数缝合在一起,形成一个可交互的 SQL 智能代理。
5.1 核心参数
| 参数 | 说明 |
|---|---|
llm |
大模型实例,必须支持 Function Calling 。推荐 ChatOpenAI(model="gpt-4") 或同等能力的模型 |
toolkit |
SQLDatabaseToolkit 实例,提供数据库工具 |
agent_type |
Agent 类型(详见下方),不指定则 LangChain 自动根据 LLM 能力选择 |
5.2 agent_type 可选值
| 值 | 说明 |
|---|---|
"tool-calling"(推荐) |
依赖模型原生 Tool Calling 能力,推理步骤少,效率最高 |
"openai-tools" |
旧版命名,行为与 tool-calling 类似 |
"zero-shot-react-description" |
基于 ReAct 范式的通用型,兼容不支持 Tool Calling 的模型。准确率高但速度慢 |
重要提示 :如果不指定
agent_type,LangChain 会自动根据 LLM 能力选择。默认优先使用 ReAct。自动选择虽然省心,但在生产环境建议显式指定,避免因模型更替导致行为变化。
5.3 提示词控制
提示词的组装顺序如下(仅对 ReAct 模式严格排列,tool-calling 模式更灵活):
{prefix}
{tools}
{format_instructions}
{suffix} ← 你自定义的内容
{agent_scratchpad} ← 必须保留,记录思考过程三个控制点:
prefix:在系统提示词最前面插入的自定义内容。可强调任务目标、数据库背景、业务规则等。修改提示词时优先使用这个参数。suffix:追加在提示词末尾的内容,常用于注入查询约束、输出格式要求。注意:如果是 ReAct 模式,必须保留{agent_scratchpad}占位符。format_instructions:覆盖默认的输出格式说明(仅对 ReAct 等特定类型生效,一般不需要动)。
5.4 DML 权限控制(重要!)
这是一个生产环境必须理解的关键行为差异:
| 模式 | prefix 设置 |
能否执行 INSERT/UPDATE/DELETE | 原因 |
|---|---|---|---|
| ReAct(默认) | ❌ 不设置(默认) | ❌ 不能 | 内置提示词硬编码 DO NOT make any DML statements |
| ReAct(默认) | ✅ 设置自定义 | ✅ 能 | 自定义 prefix 替换了默认提示词,DML 禁令被覆盖 |
| tool-calling | ❌ 不设置 | ✅ 能 | 默认提示词极简,没有硬编码 DML 禁令 |
| tool-calling | ✅ 设置自定义 | 取决于你写没写限制 | 你的 prefix 写什么规则,模型就遵循什么 |
| 直接调用工具 | 无关 | ✅ 能 | sql_db_query 底层直接执行 SQL,不受任何 Agent 提示词限制 |
踩坑重点 :如果你在 ReAct 模式下自定义了
prefix,原来的 DML 禁令会静默消失 !此时必须在新的prefix中重新声明 DML 禁止规则。推荐在prefix中显式加入:
4. 你只能执行 SELECT 查询操作,严禁执行 INSERT、UPDATE、DELETE、DROP、ALTER、TRUNCATE 等任何数据修改或结构变更操作。
5.5 运行控制参数
| 参数 | 默认值 | 说明 |
|---|---|---|
top_k |
10 |
sql_db_query 返回结果的最大行数,防止海量数据撑爆 token |
max_iterations |
15 |
Agent 思考+行动的最大轮数,防止死循环 |
max_execution_time |
无 | 最大执行时间(秒),超时后停止 |
early_stopping_method |
--- | 达到最大迭代次数时的行为:"force" 强制返回最后结果,"generate" 让 LLM 生成最终答案 |
verbose |
False |
是否打印详细日志,调试时强烈建议开启 |
5.6 高级参数
agent_executor_kwargs:直接传递给AgentExecutor的额外参数。强烈推荐设置handle_parsing_errors=True------当 LLM 输出格式错误时自动重试,大幅提升系统容错率。callback_manager:回调管理器,用于监控、日志、LangSmith 追踪。
5.7 返回值与调用方式
返回一个 AgentExecutor 对象,支持以下调用方式:
| 方法 | 说明 |
|---|---|
invoke({"input": "问题"}) |
同步执行,返回 {"output": "回答", ...} |
ainvoke(...) |
异步版本 |
stream(...) |
流式输出(需 LLM 支持 streaming) |
5.8 完整调用示例
python
agent = create_sql_agent(
llm=llm,
toolkit=toolkit,
max_iterations=10, # 思考+行动的最大轮数,默认 15,防止死循环
max_execution_time=100, # 最大执行时间(秒),超时后停止
verbose=True, # 开启调试
top_k=10, # 查询到数据最多返回10行
# agent_type="tool-calling",
prefix="""
你是一个设计用于与 SQL 数据库交互的 Agent。
给定一个输入问题,首先创建一个语法正确的 {dialect} 查询语句并执行,然后查看查询结果并返回答案。
除非用户指定了希望获得的具体示例数量,否则始终使用 LIMIT 子句将查询限制为最多 {top_k} 个结果。
你可以根据相关列对结果进行排序,以返回数据库中最有趣的示例。
永远不要查询特定表的所有列,只根据问题询问相关的列。
你有权限访问用于与数据库交互的工具。
只能使用给定的工具。只能使用工具返回的信息来构建你的最终答案。
如果执行查询时出错,重写查询并重试。
【补充规则】
1. 如果查询结果为空,或数据库中没有相关信息,你的最终回答必须是:查无信息。
2. 请用简洁的语言回答,不要胡编乱造。
3. 不要编造或猜测任何工具返回信息中不存在的数据。
4. 你只能执行 SELECT 查询操作,严禁执行 INSERT、UPDATE、DELETE、DROP、ALTER、TRUNCATE 等任何数据修改或结构变更操作。
""", # 系统提示词
agent_executor_kwargs={"handle_parsing_errors": True},
)
res = agent.invoke({"input": "张三的手机号是多少"})
print(res["output"])6. 代码示例(三层递进)
下面提供三个版本的完整可运行代码,从简单到复杂,展示了从"能用"到"好用"再到"生产级"的演进过程。
6.1 基础版:无 RAG、无向量库
适合场景:数据库表数量少(5 张以内),LLM 上下文窗口足以容纳全部表结构。
python
"""
text-to-sql
基础版(无rag、无向量库)
"""
import os
from dotenv import load_dotenv
from langchain_community.agent_toolkits import SQLDatabaseToolkit, create_sql_agent
from langchain_community.tools import tool
from langchain_community.utilities import SQLDatabase
from langchain_openai import ChatOpenAI
# 加载环境变量配置
load_dotenv()
# 创建数据库连接
# 连接MySQL数据库,地址为localhost,用户名root,密码abc123abc,数据库名demo
db = SQLDatabase.from_uri(
"mysql+pymysql://root:abc123abc@localhost/demo",
)
# 创建大语言模型实例
llm = ChatOpenAI(
model=os.getenv("AL_MODEL_NAME"), # 从环境变量获取模型名称
base_url=os.getenv("AL_BASE_URL"), # 从环境变量获取API基础URL
api_key=os.getenv("AL_API_KEY"), # 从环境变量获取API密钥
temperature=0, # 设置温度参数为0,使输出更确定性
)
# 创建SQL数据库工具包
# 将数据库连接和语言模型传入,构建SQL操作工具集
toolkit = SQLDatabaseToolkit(db=db, llm=llm)
# 创建SQL智能代理
# 该代理结合LLM和SQL工具包,能够理解和执行自然语言到SQL的转换
agent = create_sql_agent(
llm=llm,
toolkit=toolkit,
max_iterations=10, # 思考+行动的最大轮数,默认 15,防止死循环
max_execution_time=100, # 最大执行时间(秒),超时后停止
verbose=True, # 输出详细日志信息
agent_executor_kwargs={"handle_parsing_errors": True}, # 遇到解析错误时自动处理
)
# 交互式问答循环
# 允许用户持续输入问题并获得SQL查询结果
while True:
answer = input("请输入问题:") # 获取用户输入
if answer == "exit": # 如果输入exit则退出程序
break
# 调用智能代理处理用户问题并执行相应的SQL查询
res = agent.invoke({"input": answer})
# 输出查询结果
print(res["output"], flush=True, end="\n")基础版的局限:当数据库有数十张甚至上百张表时,将所有表的 DDL 和示例数据全部塞入 LLM 上下文会导致 token 开销爆炸,同时无关表的噪音也会降低 SQL 准确率。下一节引入 RAG 来解决这个问题。
6.2 进阶版:RAG + 向量检索
核心思路:将每张表的 DDL + 示例数据向量化存入 Chroma,用户提问时只召回最相关的几张表结构作为 LLM 上下文,从而大幅缩减 token 消耗并减少噪音干扰。
文件结构:
├── main.py # 主程序
├── rag_sql_database_toolkit.py # 自定义 RAG Toolkit
└── chroma_db/ # 向量库持久化目录main.py
python
"""
text-to-sql
进阶版(有rag+有向量库+向量检索)
"""
import os
from dotenv import load_dotenv
from langchain_community.agent_toolkits import create_sql_agent
from langchain_community.tools import tool
from langchain_community.utilities import SQLDatabase
from langchain_community.vectorstores import Chroma
from langchain_openai import ChatOpenAI
from langchain_openai import OpenAIEmbeddings
from rag_sql_database_toolkit import RAGSQLDatabaseToolkit
# 加载环境变量配置
load_dotenv()
# 创建数据库连接
# 连接MySQL数据库,地址为localhost,用户名root,密码abc123abc,数据库名demo
db = SQLDatabase.from_uri(
"mysql+pymysql://root:abc123abc@localhost/demo",
)
# 向量嵌入模型(阿里百炼 text-embedding-v4)
# 用于将文本转换为向量表示,便于相似性搜索
embedding = OpenAIEmbeddings(
model=os.getenv("AL_EMMODEL_NAME"), # 从环境变量读取嵌入模型名称
base_url=os.getenv("AL_BASE_URL"), # API 基础地址
api_key=os.getenv("AL_API_KEY"), # API 密钥
check_embedding_ctx_length=False, # 禁用 token 长度检查,避免某些兼容性问题
chunk_size=10, # 每批处理 10 个文档,用于控制并发
)
# 获取所有表名
table_names = db.get_usable_table_names()
# 表结构文本列表
table_texts = []
# 获取所有表结构信息
for name in table_names:
table_info = db.get_table_info([name])
table_texts.append(table_info)
# 为每个文本添加元数据(表名)
metadatas = [{"table_name": name} for name in table_names]
# 向量数据库
vectorstore = Chroma.from_texts(
texts=table_texts,
embedding=embedding,
persist_directory="./chroma_db",
metadatas=metadatas,
collection_name="table_schemas",
)
# 创建大语言模型实例
# 配置用于理解和生成SQL查询的语言模型
llm = ChatOpenAI(
model=os.getenv("AL_MODEL_NAME"), # 从环境变量获取模型名称
base_url=os.getenv("AL_BASE_URL"), # 从环境变量获取API基础URL
api_key=os.getenv("AL_API_KEY"), # 从环境变量获取API密钥
temperature=0, # 设置温度参数为0,使输出更确定性
)
# 创建自定义的RAG SQL数据库工具包
# 结合数据库连接、语言模型和向量数据库,提供增强的SQL查询能力
rag_toolkit = RAGSQLDatabaseToolkit(db=db, llm=llm, vectorstore=vectorstore)
# 创建SQL智能代理
# 该代理结合LLM和SQL工具包,能够理解和执行自然语言到SQL的转换
agent = create_sql_agent(
llm=llm, # 使用上面配置的语言模型
toolkit=rag_toolkit, # 使用自定义的RAG工具包
max_iterations=10, # 思考+行动的最大轮数,默认 15,防止死循环
max_execution_time=100, # 最大执行时间(秒),超时后停止
verbose=True, # 输出详细日志信息
agent_executor_kwargs={"handle_parsing_errors": True}, # 遇到解析错误时自动处理
)
# 交互式问答循环
# 允许用户持续输入问题并获得SQL查询结果
while True:
answer = input("请输入问题:") # 获取用户输入
if answer == "exit": # 如果输入exit则退出程序
break
# 调用智能代理处理用户问题并执行相应的SQL查询
res = agent.invoke({"input": answer})
# 输出查询结果
print(res["output"], flush=True, end="\n")rag_sql_database_toolkit.py
这是整个 RAG 方案的核心------继承 SQLDatabaseToolkit 并替换其中的 sql_db_schema 工具,将原来的"返回全部表结构"替换为"基于向量相似度召回最相关的 N 张表结构"。
python
from typing import Any
from langchain_community.agent_toolkits import SQLDatabaseToolkit
from langchain_community.tools import BaseTool, InfoSQLDatabaseTool, tool
from pydantic import Field
# 自定义 SQLDatabaseToolkit ,替换sql_db_schema方法
class RAGSQLDatabaseToolkit(SQLDatabaseToolkit):
# 定义类属性
vectorstore: Any = Field(default=None, describe="向量数据库对象") # 存储向量数据库实例
k: int = Field(default=5, describe="rag召回相关表数量") # 控制检索返回的表数量
def __init__(self, db, llm, vectorstore=None, k=5, **kwargs):
# 调用父类构造函数初始化基础功能
super().__init__(db=db, llm=llm, **kwargs)
# 初始化自定义属性
self.vectorstore = vectorstore # 向量数据库实例
self.k = k # 检索返回的表数量
def get_tools(self) -> list[BaseTool]:
# 获取默认工具
tools = super().get_tools() # 从父类获取默认的工具集
# 找到并替换 sql_db_schema 方法
new_tools = [] # 新的工具列表
for tool in tools:
# 如果是InfoSQLDatabaseTool类型(用于获取数据库表结构信息)
if isinstance(tool, InfoSQLDatabaseTool):
# 使用自定义的RAG工具替换原有的表结构查询工具
new_tools.append(self.create_rag_tool())
else:
# 其他工具保持不变
new_tools.append(tool)
return new_tools
# 生成rag工具
def create_rag_tool(self):
# 使用tool装饰器创建一个可调用的工具函数
@tool
def search_tables_info(query: str) -> str:
"""
根据用户问题检索最相关的数据库表结构信息。
输入应为用户的自然语言问题。
返回拼装好的表结构字符串,供SQL生成参考
"""
# 在向量数据库中进行相似性搜索
# 根据用户查询找到最相关的表结构信息
docs = self.vectorstore.similarity_search(query, k=self.k)
if not docs:
return "找不到相关数据表" # 如果没有找到相关文档,返回提示信息
# 将找到的文档内容拼接起来,用双换行符分隔
return "\n\n".join([doc.page_content for doc in docs])
return search_tables_info # 返回创建的工具函数这个版本的核心价值:100 张表的场景下,传统方式需要把全部 100 张表结构塞进 prompt(可能消耗 20K+ token),而 RAG 版本只召回最相关的 5 张表(约 1K token),token 节省 20 倍,且减少了无关表结构对 LLM 的干扰。
6.3 生产环境版:混合检索 + 去重 + 精排
在进阶版的基础上,引入三项关键升级:
- BM25 关键词检索 :解决纯向量检索在精确关键词匹配(如列名
order_status)上的短板。 - RRF 混合检索融合 :通过
EnsembleRetriever将向量检索和 BM25 的结果融合,取长补短。 - 重排序(Reranker) :用
DashScopeRerank(阿里百炼 qwen3-rerank)对融合后的候选结果进行精排,把真正相关的表结构排到最前面。
文件结构:
├── main.py # 主程序
├── rag_sql_database_toolkit.py # 自定义 RAG Toolkit(混合检索 + 重排序版)
└── chroma_db/ # 向量库持久化目录main.py
python
"""
text-to-sql
生产环境版(有rag+有向量库+混合检索+去重+精排)
"""
import os
from dotenv import load_dotenv
from langchain_community.agent_toolkits import SQLDatabaseToolkit, create_sql_agent
from langchain_community.document_compressors import DashScopeRerank
from langchain_community.retrievers import BM25Retriever
from langchain_community.tools import tool
from langchain_community.utilities import SQLDatabase
from langchain_community.vectorstores import Chroma, PGVector
from langchain_core.callbacks import StdOutCallbackHandler
from langchain_openai import ChatOpenAI
from langchain_openai import OpenAIEmbeddings
from rag_sql_database_toolkit import RAGSQLDatabaseToolkit
load_dotenv()
# 创建数据库连接
# 连接MySQL数据库,地址为localhost,用户名root,密码abc123abc,数据库名demo
# sample_rows_in_table_info=1 表示在表结构信息中包含1行示例数据,有助于理解表结构
db = SQLDatabase.from_uri(
"mysql+pymysql://root:abc123abc@localhost/demo",
sample_rows_in_table_info=1, # 采样1行数据,避免耗时过长
)
# 获取所有可用的表名
table_names = db.get_usable_table_names()
# 存储表结构信息的文本列表
table_texts = []
# 遍历所有表名,获取每张表的结构信息并存储到文本列表中
for name in table_names:
table_info = db.get_table_info([name]) # 获取指定表的结构信息
table_texts.append(table_info) # 添加到文本列表
# 向量嵌入模型
# 用于将表结构信息转换为向量表示,便于语义相似性搜索
embedding = OpenAIEmbeddings(
model=os.getenv("AL_EMMODEL_NAME"), # 从环境变量读取嵌入模型名称
base_url=os.getenv("AL_BASE_URL"), # API 基础地址
api_key=os.getenv("AL_API_KEY"), # API 密钥
check_embedding_ctx_length=False, # 禁用 token 长度检查,避免某些兼容性问题
chunk_size=10, # 每批处理 10 个文档,用于控制并发
)
# 为每个文本添加元数据(表名)
# 用于在检索时知道对应的表名信息
metadatas = [{"table_name": name} for name in table_names]
# 创建向量数据库
# 将表结构信息存储到Chroma向量数据库中,支持语义检索
vectorstore = Chroma.from_texts(
texts=table_texts, # 表结构文本内容
embedding=embedding, # 使用上面定义的嵌入模型
persist_directory="./chroma_db", # 持久化存储路径
metadatas=metadatas, # 对应的元数据(表名)
collection_name="table_schemas", # 集合名称
)
# BM25 关键词检索器
# 基于关键词匹配的检索器,用于处理精确的关键词查询
bm25_retriever = BM25Retriever.from_texts(texts=table_texts, metadatas=metadatas, k=1)
# 阿里云百炼的 qwen3‑rerank 重排序模型
# 用于对混合检索结果进行重排序,提升最相关结果的排序位置
reranker = DashScopeRerank(
model="qwen3-rerank", # 阿里百炼提供的重排序模型
top_n=5, # 最终返回 5 个最相关的文档
dashscope_api_key=os.getenv("AL_API_KEY"), # 从环境变量读取 API 密钥
)
# 创建LLM实例
llm = ChatOpenAI(
model=os.getenv("AL_MODEL_NAME"), # 从环境变量获取模型名称
base_url=os.getenv("AL_BASE_URL"), # 从环境变量获取API基础URL
api_key=os.getenv("AL_API_KEY"), # 从环境变量获取API密钥
temperature=0, # 设置温度参数为0,使输出更确定性
)
# 创建RAG SQL数据库工具包
# 结合了数据库连接、语言模型、向量数据库、BM25检索器和重排序器
rag_toolkit = RAGSQLDatabaseToolkit(
db=db, # 数据库连接实例
llm=llm, # 语言模型实例
vectorstore=vectorstore, # 向量数据库实例
bm25_retriever=bm25_retriever, # BM25关键词检索器
k=5, # 检索返回的文档数量
reranker=reranker, # 重排序模型
)
top_k = 10 # 返回结果的最大数量
sql_dialect = "mysql" # 数据库方言,这里设置为mysql
# 创建SQL智能代理
# 结合语言模型和RAG工具包,能够理解和执行自然语言到SQL的转换
agent = create_sql_agent(
llm=llm, # 使用上面配置的语言模型
toolkit=rag_toolkit, # 使用自定义的RAG工具包
max_iterations=10, # 思考+行动的最大轮数,默认 15,防止死循环
max_execution_time=100, # 最大执行时间(秒),超时后停止
verbose=True, # 输出详细日志信息
top_k=top_k, # 返回结果的最大数量
agent_type="tool-calling", # 使用工具调用模式,回答速度更快
prefix=f"""
你是一个设计用于与 SQL 数据库交互的 Agent。
给定一个输入问题,首先创建一个语法正确的{sql_dialect}查询语句并执行,然后查看查询结果并返回答案。
除非用户指定了希望获得的具体示例数量,否则始终使用 LIMIT 子句将查询限制为最多 {top_k} 个结果。
你可以根据相关列对结果进行排序,以返回数据库中最有趣的示例。
永远不要查询特定表的所有列,只根据问题询问相关的列。
你有权限访问用于与数据库交互的工具。
只能使用给定的工具。只能使用工具返回的信息来构建你的最终答案。
如果执行查询时出错,重写查询并重试。
【补充规则】
1. 如果查询结果为空,或数据库中没有相关信息,你的最终回答必须是:查无信息。
2. 请用简洁的语言回答,不要胡编乱造。
3. 不要编造或猜测任何工具返回信息中不存在的数据。
4. 你只能执行 SELECT 查询操作,严禁执行 INSERT、UPDATE、DELETE、DROP、ALTER、TRUNCATE 等任何数据修改或结构变更操作。
""", # 系统提示词,定义了智能代理的行为规则
agent_executor_kwargs={"handle_parsing_errors": True}, # 遇到解析错误时自动处理
)
# 交互式问答循环
# 允许用户持续输入问题并获得SQL查询结果
while True:
answer = input("请输入问题:") # 获取用户输入的自然语言问题
if answer == "exit": # 如果输入exit则退出程序
break
# 调用智能代理处理用户问题并执行相应的SQL查询
res = agent.invoke({"input": answer})
# 输出查询结果
print(res["output"], flush=True, end="\n")rag_sql_database_toolkit.py
生产级的核心 Toolkit,完整实现了向量检索 + BM25 关键词检索 → RRF 混合融合 → Reranker 精排的检索管线。
python
from typing import Any
from langchain_community.agent_toolkits import SQLDatabaseToolkit
from langchain_community.retrievers import BM25Retriever
from langchain_community.tools import BaseTool, InfoSQLDatabaseTool, tool
from langchain_core.tools import create_retriever_tool
from pydantic import Field
from langchain_classic.retrievers import (
ContextualCompressionRetriever,
EnsembleRetriever,
)
# 自定义 SQLDatabaseToolkit ,替换sql_db_schema方法
class RAGSQLDatabaseToolkit(SQLDatabaseToolkit):
vectorstore: Any = Field(default=None, describe="向量数据库对象")
k: int = Field(default=5, describe="rag召回片段数量")
vector_retriever: Any = Field(default=None, describe="向量检索器")
bm25_retriever: Any = Field(default=None, describe="BM25 关键词检索器")
reranker: Any = Field(default=None, describe="重排模型")
def __init__(
self,
db,
llm,
vectorstore=None,
k=5,
vector_retriever=None,
bm25_retriever=None,
reranker=None,
**kwargs
):
super().__init__(db=db, llm=llm, **kwargs)
self.vectorstore = vectorstore
self.k = k
self.vector_retriever = vector_retriever
self.bm25_retriever = bm25_retriever
self.reranker = reranker
def get_tools(self) -> list[BaseTool]:
# 获取默认工具
tools = super().get_tools() # 从父类获取默认的工具集
# 找到并替换 sql_db_schema 方法
new_tools = [] # 新的工具列表
for tool in tools:
# 如果是InfoSQLDatabaseTool类型(用于获取数据库表结构信息)
if isinstance(tool, InfoSQLDatabaseTool):
# 使用自定义的RAG工具替换原有的表结构查询工具
new_tools.append(self.create_multiple_rag_tool())
# elif tool.name == "sql_db_query_checker" : # 过滤掉slq检查器(耗时长可优化)
# continue
else:
new_tools.append(tool)
return new_tools
# 生成向量检索rag工具
def create_rag_tool(self):
@tool
def search_tables_info(query: str) -> str:
"""
根据用户问题检索最相关的数据库表结构信息。
输入应为用户的自然语言问题。
返回拼装好的表结构字符串,供SQL生成参考
"""
docs = self.vectorstore.similarity_search(query, k=self.k)
if not docs:
return "找不到相关数据表"
return "\n\n".join([doc.page_content for doc in docs])
return search_tables_info
# 生成混合检索rag工具
def create_multiple_rag_tool(self):
# 确定向量检索器
vec_retriever = self.vector_retriever
if not vec_retriever and self.vectorstore:
vec_retriever = self.vectorstore.as_retriever(
search_kwargs={"k": self.k * 2}
)
# 收集所有可用的检索器
# 构建混合检索器列表,包括向量检索器和BM25关键词检索器
active_retrievers = []
if vec_retriever:
# 添加向量检索器(基于语义相似性的检索)
active_retrievers.append(vec_retriever)
if self.bm25_retriever:
# 添加BM25检索器(基于关键词匹配的检索)
active_retrievers.append(self.bm25_retriever)
if not active_retrievers:
# 确保至少有一个检索器可用
raise ValueError("至少需要提供一个检索器")
# 使用 RRF(Reciprocal Rank Fusion)算法进行混合检索
# RRF是一种有效的多检索器融合方法,能综合不同检索器的结果
ensemble = EnsembleRetriever(
retrievers=active_retrievers, # 所有激活的检索器
k=self.k, # 最终返回 top_k 个结果
)
# 可选的压缩(重排序)
# 如果提供了重排序模型,则对混合检索结果进行重排序优化
if self.reranker:
# 使用上下文压缩检索器,通过重排序模型优化结果
compression_retriever = ContextualCompressionRetriever(
base_compressor=self.reranker, # 重排序模型
base_retriever=ensemble, # 基础检索器(混合检索结果)
)
else:
# 如果没有重排序模型,直接使用混合检索结果
compression_retriever = ensemble
# 包装为工具
retriever_tool = create_retriever_tool(
retriever=compression_retriever,
name="search_tables_info",
description="""根据用户问题检索最相关的数据库表结构信息。
输入应为用户的自然语言问题。
返回拼装好的表结构字符串,供SQL生成参考""",
)
return retriever_tool三个版本的对比总结
| 特性 | 基础版 | 进阶版 | 生产环境版 |
|---|---|---|---|
| 检索方式 | 全量表结构 | 向量检索 | 向量 + BM25 混合 + Reranker |
| Token 消耗 | 高(全量) | 低(Top-K 召回) | 低(Top-K 召回 + 精排) |
| 关键词匹配 | --- | 弱 | 强(BM25 补充) |
| 检索精度 | --- | 中 | 高(Reranker 精排) |
| 适用表数量 | < 5 张 | 5-50 张 | 50+ 张 |
| 推荐场景 | 原型验证 | 中等规模库 | 生产环境 |
7. 查询速度优化实践
在实际项目中,从"能用"到"好用"通常意味着需要把单次回答从 30 秒压到 5 秒以内。以下是三条经过验证的有效优化策略。
策略一:切换 agent_type 为 tool-calling
默认的 zero-shot-react-description(ReAct)模式每步都要经历"思考 → 行动 → 观察"循环,在简单查询上可能浪费 3-5 步推理。直接指定 agent_type="tool-calling" 利用模型原生 Function Calling 能力,可将推理步骤压缩至 1-2 步,响应速度提升 3-5 倍。
策略二:在 ReAct 模式下屏蔽 sql_db_query_checker
如果你仍需要使用 ReAct 模式(例如模型不支持 Tool Calling),可以通过自定义 Toolkit 过滤掉 sql_db_query_checker 工具。它能减少一次完整的 LLM 推理调用。ReAct 模式下的最大耗时往往源于多步推理,每减少一个不必要的步骤都能带来可感知的速度提升。
python
# 自定义 SQLDatabaseToolkit ,替换sql_db_schema方法、过滤sql_db_query_checker方法
class RAGSQLDatabaseToolkit(SQLDatabaseToolkit):
...
...
...
def get_tools(self) -> list[BaseTool]:
# 获取默认工具
tools = super().get_tools()
# 找到并替换 InfoSQLDatabaseTool
new_tools = []
for tool in tools:
if isinstance(tool, InfoSQLDatabaseTool):
new_tools.append(self.create_multiple_rag_tool())
############### 关键步骤 ############
elif tool.name == "sql_db_query_checker": # 过滤掉sql检查器(耗时久)
continue
else:
new_tools.append(tool)
return new_tools策略三:表结构存储时去掉示例数据
get_table_info() 返回的示例数据行在大型表中可能非常宽(几十列),实际对 SQL 生成有帮助的只有列名和类型。将 sample_rows_in_table_info 设为 0,只保留 DDL,可大幅缩短 LLM 上下文长度,从而降低首 Token 延迟和整体推理时间。
python
db = SQLDatabase.from_uri(
"mysql+pymysql://root:abc123abc@localhost/demo",
sample_rows_in_table_info=0, # 不采样,避免耗时过长
)权衡 :去掉示例数据会损失一部分语义信息------LLM 无法通过样本值推断列的取值分布和业务含义。如果你的领域术语非常冷门(例如列名用的是缩写或内部代号),建议至少保留 1 行示例数据,或者通过
custom_table_info参数手动补充列级别的业务说明。
总结
本文从 SQLDatabase 连接封装出发,逐步构建了三个版本的 Text-to-SQL Agent:
- 基础版适合快速验证,几行代码即可跑通自然语言查数据库。
- 进阶版引入 RAG 向量检索,在表数量中等时显著降低 token 消耗。
- 生产环境版通过 BM25 + RRF 混合检索 + Reranker 精排,补齐了纯向量检索在关键词匹配和排序精度上的短板。
三个版本共享同一套核心 API(SQLDatabase → SQLDatabaseToolkit → create_sql_agent),上层检索策略的变化通过自定义 Toolkit 的 get_tools() 方法优雅地实现插拔,架构本身不耦合。
最后,三个容易被忽略但影响深远的点值得再强调一遍:
- DML 禁令在自定义 ReAct prefix 后会静默消失,务必在新 prompt 中显式声明。
agent_type="tool-calling"是提升响应速度最直接的手段,前提是模型支持 Function Calling。- 检索管线的每个环节都可以独立开关:向量检索、BM25、Reranker 都是可选的。根据你的数据库规模、查询模式和成本预算按需组合,不必一上来就上全套。