【LangGraph】LangGraph 实战(五):持久化、流式输出与部署
- 前言
-
- 一、持久化机制
-
- [1.1 两层持久化](#1.1 两层持久化)
- [1.2 Checkpoint:自动状态快照](#1.2 Checkpoint:自动状态快照)
- [1.3 Store:用户数据存储](#1.3 Store:用户数据存储)
- [1.4 Runtime 上下文](#1.4 Runtime 上下文)
- 二、流式输出
-
- [2.1 SSE 协议](#2.1 SSE 协议)
- [2.2 House_Agent 的流式输出流程](#2.2 House_Agent 的流式输出流程)
- [2.3 前端 SSE 解析](#2.3 前端 SSE 解析)
- [2.4 interrupt 的前端处理](#2.4 interrupt 的前端处理)
- [三、FastAPI 代理服务器](#三、FastAPI 代理服务器)
- 四、部署方案
-
- [4.1 Docker 部署](#4.1 Docker 部署)
- [4.2 开发 vs 生产](#4.2 开发 vs 生产)
- 五、代码中的知识点
-
- [5.1 State 与 MessagesState](#5.1 State 与 MessagesState)
- [5.2 条件路由](#5.2 条件路由)
- [5.3 工具调用](#5.3 工具调用)
- [5.4 interrupt 与循环验证](#5.4 interrupt 与循环验证)
- [5.5 持久化存储](#5.5 持久化存储)
- [5.6 结构化输出](#5.6 结构化输出)
- [5.7 条件边控制循环](#5.7 条件边控制循环)
- 六、系列回顾
-
- [6.1 整体架构回顾](#6.1 整体架构回顾)
- [6.2 核心知识点回顾](#6.2 核心知识点回顾)
- [6.3 架构图总览](#6.3 架构图总览)
- [6.4 面试高频问题](#6.4 面试高频问题)
上一章------>【LangGraph】House_Agent 实战(四):预定流程 ------ 中断与人工干预

前言
上一篇我们完成了预定流程的实现,学习了 interrupt 机制和循环验证,
本篇是系列最后一篇,将把 House_Agent 项目跑起来------讲解持久化、流式输出、前端对接和部署方案,最后对整个系列做一个回顾,也是对前面知识点的一个回顾
一、持久化机制
1.1 两层持久化
LangGraph 提供了两层持久化机制,House_Agent 项目中都有用到:
| 机制 | 用途 | House_Agent 中的使用 |
|---|---|---|
| Checkpoint | 保存图的执行状态 | interrupt 暂停时自动保存,支持恢复执行 |
| Store | 存储用户数据 | 用户偏好(预算)、预定工单记录 |
1.2 Checkpoint:自动状态快照
Checkpoint 是 LangGraph 自动保存的状态快照,每当一个节点执行完毕,当前状态就会被保存。
在 House_Agent 中的作用:
预定流程中,get_title、get_phone、get_id 三个节点都使用了 interrupt()每次 interrupt 暂停时,图的状态自动保存到 Checkpoint
用户输入后,LangGraph 从 Checkpoint 恢复状态,继续执行
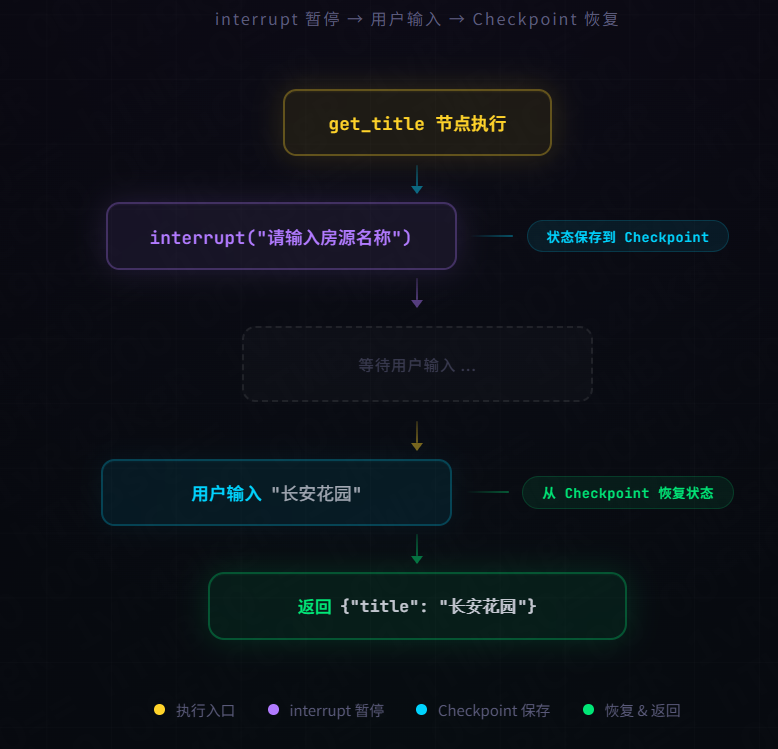
默认配置 :builder.compile() 不传参数时,使用 InMemorySaver,数据保存在内存中
开发测试足够用,服务重启后丢失
生产环境:需要持久化存储,比如 PostgreSQL:
python
from langgraph.checkpoint.postgres import PostgresSaver
checkpointer = PostgresSaver.from_conn_string(
"postgresql://user:password@localhost:5432/langgraph"
)
graph = builder.compile(checkpointer=checkpointer)1.3 Store:用户数据存储
Store 用于存储跨会话 的用户数据
与 Checkpoint 不同,Store 需要手动读写
在 House_Agent 中的使用:
场景一:用户偏好读取 (get_store_info 节点):
python
def get_store_info(state: State, runtime: Runtime[ContextSchema], *, store: BaseStore):
user_id = runtime.context.get("user_id")
namespace = (user_id, "preferences")
prefs_result = store.search(namespace)
if prefs_result and prefs_result[0]:
return {"user_preferences": prefs_result[0].value}
return {"user_preferences": {}}场景二:推荐时更新偏好 (collect_user_info 节点):
python
# 提取到预算信息后,持久化保存
if prefs_result:
prefs = prefs_result[0].value
if user_info.budget_min:
prefs['budget_min'] = user_info.budget_min
if user_info.budget_max:
prefs['budget_max'] = user_info.budget_max
store.put(namespace, prefs_result[0].key, prefs)场景三:预定工单持久化 (generate_orders 工具):
python
@tool
def generate_orders(phone_number, id_card, title,
runtime: ToolRuntime, store: Annotated[Any, InjectedStore()]):
order_id = str(uuid.uuid4())
reserved_info = ReservedInfo(order_id=order_id, phone_number=phone_number, title=title)
user_id = runtime.context.get("user_id")
namespace = (user_id, "preferences")
prefs_result = store.search(namespace)
if len(prefs_result) == 0:
# 首次预定,新建记录
prefs = UserPreferences(reserved_info=[reserved_info])
store.put(namespace, str(uuid.uuid4()), prefs.model_dump(exclude_none=True))
else:
# 已有记录,追加预定信息
prefs = prefs_result[0].value or {}
prefs.setdefault("reserved_info", []).append(reserved_info.model_dump())
store.put(namespace, prefs_result[0].key, prefs)
return f"已预定房源为:{title},预定工单号为:{order_id}"Store 的 namespace 设计:
namespace: (user_id, "preferences")
│
├── key: uuid-1
└── value: {
"budget_min": 3000,
"budget_max": 5000,
"reserved_info": [
{"order_id": "xxx", "title": "长安花园", "phone_number": "138..."},
{"order_id": "yyy", "title": "翠苑小区", "phone_number": "138..."}
]
}使用 user_id 作为 namespace 的第一层,实现用户级数据隔离
1.4 Runtime 上下文
user_id 从哪里来?通过 Runtime 上下文传入:
python
# context.py
class ContextSchema(TypedDict):
user_id: str
# 编译图时指定 context_schema
builder = StateGraph(State, context_schema=ContextSchema)
# 客户端请求时传入 config
config = {"configurable": {"user_id": "web_user"}}节点中通过 runtime.context["user_id"] 访问,
工具中通过 runtime.context.get("user_id") 访问
二、流式输出
2.1 SSE 协议
LangGraph 使用 SSE(Server-Sent Events) 协议实现流式输出
客户端发起 HTTP 请求后,服务端通过长连接持续推送事件
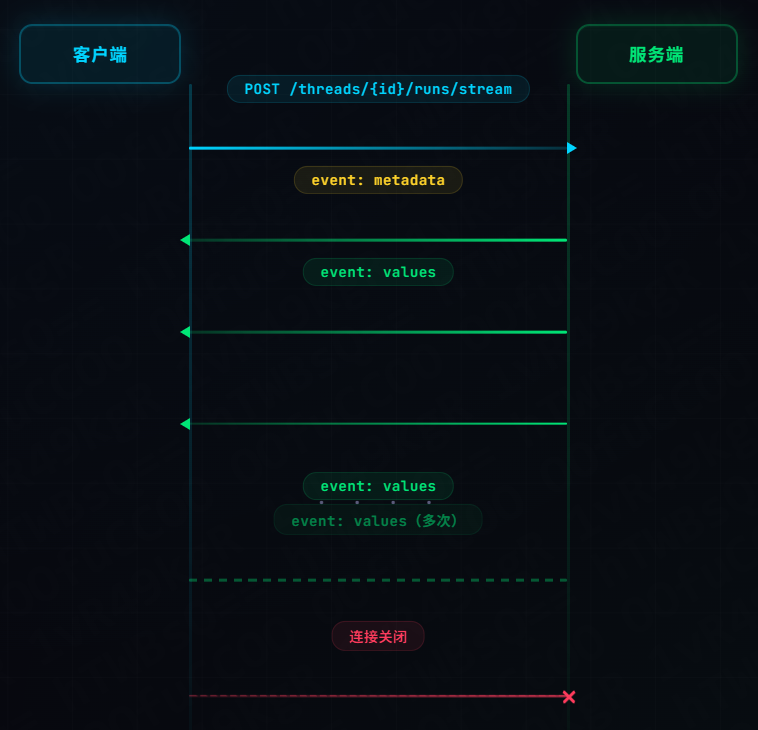
每个 SSE 事件包含两部分:
event: values
data: {"messages": [...], "user_intent": "recommend_house", ...}2.2 House_Agent 的流式输出流程
以"帮我推荐北京 3000-5000 的两室一厅"为例,SSE 事件流如下:
event: metadata ← 运行 ID
event: values ← get_store_info 完成(加载用户偏好)
event: values ← identify_question 完成(识别为 recommend_house)
event: values ← collect_user_info 完成(提取城市、预算)
event: values ← list_tables 完成
event: values ← call_get_schema 完成
event: values ← generate_query 完成(生成 SQL)
event: values ← check_query 完成
event: values ← run_query 完成(执行 SQL)
event: values ← generate_query 完成(生成最终回复 + interrupt)每个 values 事件包含完整的当前状态,前端需要从中提取消息和 interrupt 信息
2.3 前端 SSE 解析
前端通过 fetch + ReadableStream 消费 SSE:
javascript
const resp = await fetch(`/api/threads/${threadId}/runs/stream`, {
method: 'POST',
headers: { 'Content-Type': 'application/json' },
body: JSON.stringify({
assistant_id: 'house_agent',
config: { configurable: { user_id: 'web_user' } },
input: { messages: [{ role: 'user', content: text }] }
})
});
const reader = resp.body.getReader();
const decoder = new TextDecoder();
while (true) {
const { done, value } = await reader.read();
if (done) break;
buffer += decoder.decode(value, { stream: true });
// 解析 event: 和 data: 行
// 提取 AI 消息和 interrupt 信息
}关键点:
- 多次 values 事件 :图经过多个节点,每个节点完成都会触发一次
values事件 - 最后一条 AI 消息:需要从所有事件中找到最后一条有效的 AI 回复
- interrupt 处理 :当
data.__interrupt__存在时,需要显示提示并等待用户输入
2.4 interrupt 的前端处理
当推荐流程完成后,need_reserve 节点触发 interrupt,前端收到:
json
{
"messages": [...],
"__interrupt__": [{
"value": "已经为您推荐合适的房源,是否需要帮您预定房源?\n如果不需要,请输入'**不需要**'\n如果需要,请输入'**需要**'"
}]
}前端处理逻辑:
- 从
messages中提取 AI 的推荐结果,显示为聊天气泡 - 从
__interrupt__中提取提示信息,显示为交互卡片 - 用户点击"需要"或"不需要"后,发送
resume请求
javascript
// 恢复执行
await fetch(`/api/threads/${threadId}/runs/stream`, {
method: 'POST',
body: JSON.stringify({
assistant_id: 'house_agent',
command: { resume: "需要" }, // 或 "不需要"
config: { configurable: { user_id: 'web_user' } }
})
});三、FastAPI 代理服务器
3.1 为什么需要代理?
LangGraph Server 运行在 2024 端口,前端页面需要一个统一的入口FastAPI 代理负责:
- 页面服务 :
GET /返回前端 HTML - 静态资源 :
/static/*提供图片等静态文件 - API 代理 :
/api/*转发到 LangGraph Server
3.2 server.py 核心代码
python
# server.py
import httpx
from fastapi import FastAPI, Request, Response
from fastapi.responses import HTMLResponse, StreamingResponse
from fastapi.staticfiles import StaticFiles
app = FastAPI()
app.mount("/static", StaticFiles(directory="static"), name="static")
LANGGRAPH_URL = "http://localhost:2024"
@app.get("/", response_class=HTMLResponse)
async def index():
with open("frontend/index.html", encoding="utf-8") as f:
return f.read()
@app.api_route("/api/{path:path}", methods=["GET", "POST", "PUT", "DELETE", "PATCH"])
async def proxy(path: str, request: Request):
url = f"{LANGGRAPH_URL}/{path}"
body = await request.body()
headers = dict(request.headers)
headers.pop("host", None)
# SSE 流式转发
if "stream" in path:
client = httpx.AsyncClient(timeout=None)
req = client.build_request(request.method, url, content=body, headers=headers)
resp = await client.send(req, stream=True)
async def stream():
async for chunk in resp.aiter_bytes():
yield chunk
await resp.aclose()
await client.aclose()
return StreamingResponse(stream(), status_code=resp.status_code,
media_type="text/event-stream")
# 普通请求转发
async with httpx.AsyncClient(timeout=60.0) as client:
resp = await client.request(request.method, url, content=body, headers=headers)
return Response(content=resp.content, status_code=resp.status_code,
headers=dict(resp.headers))SSE 转发的关键:
timeout=None:SSE 连接可能持续很长时间stream=True:启用流式传输,逐块转发字节media_type="text/event-stream":告诉浏览器这是 SSE 流
3.3 启动方式
需要两个终端分别启动:
bash
# 终端 1:启动 LangGraph Server
langgraph dev --port 2024
# 终端 2:启动 FastAPI 代理
python server.py访问 http://localhost:8000 即可使用前端页面
四、部署方案
4.1 Docker 部署
Dockerfile:
dockerfile
FROM python:3.11-slim
WORKDIR /app
COPY requirements.txt .
RUN pip install --no-cache-dir -r requirements.txt
COPY . .
EXPOSE 8000 2024
CMD ["sh", "-c", "langgraph dev --port 2024 & uvicorn server:app --host 0.0.0.0 --port 8000"]docker-compose.yml:
yaml
version: '3.8'
services:
app:
build: .
ports:
- "8000:8000"
- "2024:2024"
environment:
- DASHSCOPE_API_KEY=${DASHSCOPE_API_KEY}
- DB_HOST=mysql
- DB_PORT=3306
- DB_NAME=houser_agent
- DB_USER=root
- DB_PASSWORD=${DB_PASSWORD}
depends_on:
- mysql
mysql:
image: mysql:8.0
environment:
MYSQL_ROOT_PASSWORD: ${DB_PASSWORD}
MYSQL_DATABASE: houser_agent
volumes:
- mysql_data:/var/lib/mysql
volumes:
mysql_data:4.2 开发 vs 生产
| 维度 | 开发环境 | 生产环境 |
|---|---|---|
| Checkpoint | InMemorySaver | PostgresSaver |
| Store | InMemoryStore | PostgresStore |
| LLM | qwen-turbo | 按需选择 |
| 前端 | FastAPI 直接返回 | Nginx + CDN |
| 监控 | 无 | LangSmith |
五、代码中的知识点
House_Agent 项目的每一段代码都在体现 LangGraph 的核心概念。下面按知识点分类,看看它们在代码中是怎么用的。
5.1 State 与 MessagesState
体现位置 :state/main.py、state/recommend.py、state/reserve.py
python
# 主图状态 ------ 继承 MessagesState,自动拥有 messages 字段
class State(MessagesState):
user_intent: str # 意图识别结果
reserve: str # 是否需要预定
user_preferences: dict # 用户偏好
# 推荐子图状态 ------ 子图私有字段不影响主图
class RecommendState(TypedDict):
messages: Annotated[list[BaseMessage], add_messages] # 共享字段
city: Optional[str] # 私有字段
budget_min: Optional[float]
# 预定流程状态
class ReserveState(MessagesState):
title: Optional[str] = None
phone_number: Optional[str] = None
id_card: Optional[str] = None知识点:
MessagesState提供messages字段和add_messagesreducerAnnotated[list, add_messages]让新消息自动追加而非覆盖- 子图状态的私有字段与主图隔离
5.2 条件路由
体现位置 :graph.py
python
# 路由函数:根据状态决定下一步去哪
def router_message(state: State) -> Literal["recommend_graph", "get_title", "extend_graph", "get_user_preferences"]:
user_intent = state["user_intent"]
if user_intent == "recommend_house":
return "recommend_graph"
elif user_intent == "reserve_house":
return "get_title"
...
# 注册条件边
builder.add_conditional_edges(
"identify_question", # 源节点
router_message, # 路由函数
["recommend_graph", "get_title", "extend_graph", "get_user_preferences"]
)知识点:
add_conditional_edges实现动态路由- 路由函数读取
state中的字段做决策 Literal类型约束返回值,确保路由目标合法
5.3 工具调用
体现位置 :node/recommend.py、node/reserve.py
python
# 推荐子图:SQLDatabaseToolkit 提供的内置工具
toolkit = SQLDatabaseToolkit(db=db, llm=model)
tools = toolkit.get_tools()
get_schema_tool = next(tool for tool in tools if tool.name == "sql_db_schema")
# 预定流程:自定义工具
@tool
def generate_orders(phone_number: str, id_card: str, title: str,
runtime: ToolRuntime, store: Annotated[Any, InjectedStore()]) -> str:
...
# LLM 绑定工具
llm_with_tools = model.bind_tools([run_query_tool]) # 非强制
llm_with_tools = model.bind_tools([get_schema_tool], tool_choice=...) # 强制调用
# 工具节点
run_query_node = ToolNode([run_query_tool], name="run_query")
tool_node = ToolNode([generate_orders])知识点:
@tool装饰器定义自定义工具bind_tools将工具绑定到 LLM,tool_choice控制是否强制调用ToolNode自动解析 LLM 的工具调用并执行ToolRuntime和InjectedStore注入运行时参数,不暴露给 LLM
5.4 interrupt 与循环验证
体现位置 :node/reserve.py
python
def get_title(state: ReserveState):
prompt = '请输入要预定的房源名称(输入"取消"可退出)'
while True: # 循环验证
title = interrupt(prompt) # 暂停等待用户输入
if _is_cancel(title): # 取消检测
return {"cancel": True}
if not title or not title.strip(): # 空值检测
prompt = "房源名称不能为空,请重新输入。"
else:
return {"title": title.strip()} # 有效输入,退出循环知识点:
interrupt()暂停图执行,等待用户输入while True实现节点内的验证-重试循环- 状态保存依赖 Checkpoint,恢复时从
interrupt()处继续
5.5 持久化存储
体现位置 :node/main.py、node/recommend.py、node/reserve.py
python
# 读取:节点中通过 store 参数访问
def get_store_info(state, runtime, *, store: BaseStore):
namespace = (runtime.context["user_id"], "preferences")
prefs = store.search(namespace)
# 写入:推荐时更新预算
store.put(namespace, prefs_result[0].key, prefs)
# 写入:工具中持久化工单
@tool
def generate_orders(..., store: Annotated[Any, InjectedStore()]):
store.put(namespace, str(uuid.uuid4()), prefs.model_dump())知识点:
store作为关键字参数注入节点InjectedStore注入到工具中- namespace 用
(user_id, "preferences")实现用户级隔离 store.search()查询,store.put()写入
5.6 结构化输出
体现位置 :node/main.py、node/recommend.py
python
# 意图识别:LLM 返回固定的枚举类型
class UserIntendMessage(BaseModel):
type: Literal["recommend_house", "reserve_house", "get_info", "others"]
user_intent = model.with_structured_output(UserIntendMessage).invoke(...)
# 信息提取:LLM 返回结构化的用户信息
class UserInfo(BaseModel):
city: Optional[str]
budget_min: Optional[float]
...
user_info = model.with_structured_output(UserInfo).invoke(...)知识点:
with_structured_output()让 LLM 返回 Pydantic 模型Literal限制字段取值范围Optional允许字段为空,渐进式填充
5.7 条件边控制循环
体现位置 :recommend.py、graph.py
python
# 推荐子图:SQL 生成→检查→执行的循环
def should_continue(state: RecommendState) -> Literal[END, "check_query"]:
last_message = state["messages"][-1]
if not last_message.tool_calls:
return END # LLM 不再调用工具,结束循环
else:
return "check_query" # 继续检查并执行
builder.add_conditional_edges("generate_query", should_continue, [END, "check_query"])
# 预定流程:每步检查取消
def _should_continue(state: ReserveState):
return "cancel" if state.get("cancel") else "continue"
builder.add_conditional_edges("get_title", _should_continue, {"continue": "get_phone", "cancel": "cancel_node"})知识点:
should_continue读取最后一条消息的tool_calls判断是否继续- 预定流程中每个节点后都用条件边检查
cancel标志 tools_condition是内置的工具调用判断函数
六、系列回顾
6.1 整体架构回顾
回顾整个 House_Agent 项目,我们走过了这样一条路:

最后完成了整个项目
6.2 核心知识点回顾
- State(状态):
- 主图
State继承MessagesState,添加user_intent、reserve等字段 - 推荐子图
RecommendState有自己的私有字段:city、budget_min等 - 预定流程的
ReserveState添加title、phone_number、id_card
- Node(节点):
- 普通节点:处理逻辑,返回状态更新
- ToolNode:执行工具,由
tools_condition路由 - 子图节点:独立编译的图,嵌入主图
Edge(边):
- 普通边:
builder.add_edge(A, B) - 条件边:
builder.add_conditional_edges(A, router, [B, C]) - 预定流程中每个节点后都用条件边检查取消
interrupt(中断):
interrupt()暂停执行,等待用户输入- 依赖 Checkpoint 保存状态
- 预定流程中
get_title、get_phone、get_id都使用 interrupt
- 工具调用:
@tool装饰器定义工具model.bind_tools()绑定工具到 LLMToolRuntime和InjectedStore注入运行时参数tools_condition判断是否需要执行工具
- 持久化:
- Checkpoint 自动保存,支持 interrupt 恢复
- Store 手动读写,支持跨会话数据共享
- namespace 设计实现用户级数据隔离
6.3 架构图总览
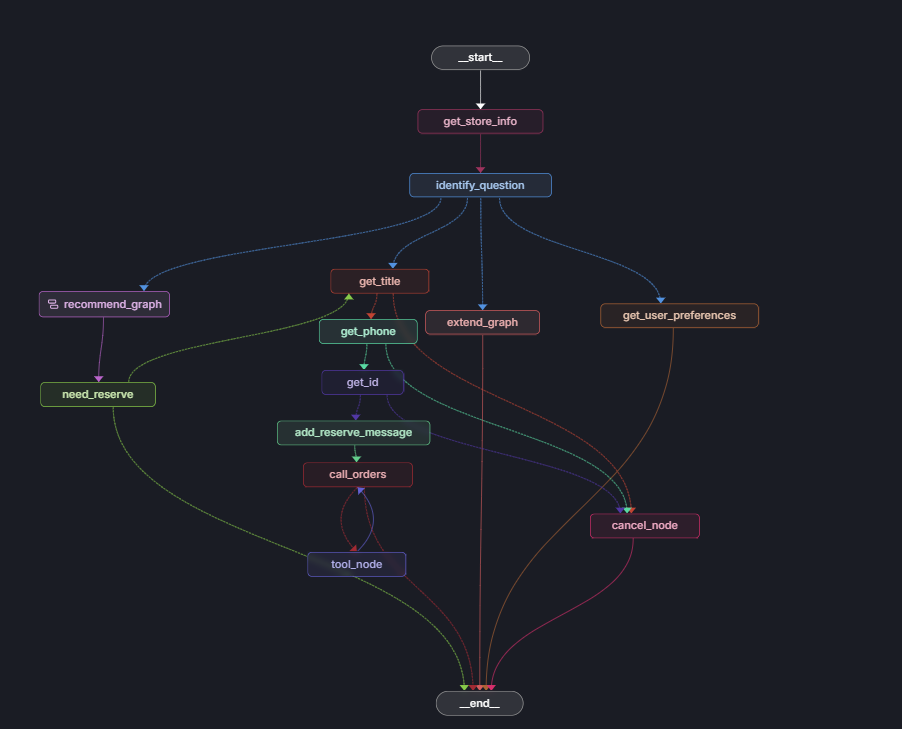
这里用LangSmith 展示一下最终图:
6.4 面试高频问题
Q1:LangGraph 的 interrupt 和普通 input() 有什么区别?
interrupt 将状态保存到 Checkpoint,支持跨会话恢复;
input() 只是阻塞当前线程
Q2:主图和子图如何共享状态?
通过 messages 字段共享,子图的私有字段不影响主图
Q3:Checkpoint 和 Store 的区别?
Checkpoint 自动保存图的执行状态,用于恢复;
Store 手动存储用户数据,用于跨会话共享
Q4:tools_condition 的作用?
检查 LLM 最后一条消息是否包含工具调用,决定执行工具还是结束流程
Q5:为什么预定流程不做成子图?
interrupt 事件需要从子图传递到主图再到客户端,链路长、调试难
直接放在主图中,事件转发更可靠
Q6:SSE 流式输出中如何处理 interrupt?
从 values 事件的 __interrupt__ 字段提取提示信息,同时从 messages 中提取最后一条 AI 回复
用户输入后发送 command.resume 恢复执行
本文是 House_Agent 实战系列的第五篇,也是最后一篇
感谢阅读,希望这个系列能帮助你掌握 LangGraph 的核心概念和实战技巧!,再见再见~~
