定义
Middleware(中间件)是一种 钩子(Hook)机制,它允许你在核心调用链路(如向LLM发起请求、调用工具、处理输出)的特定阶段注入自定义逻辑,而无需修改核心 Agent 或工具的代码。
其核心流程:
-
调用发起 :当您执行
chain.invoke()或agent.run()时,触发流程。 -
Middleware介入 :在请求到达核心模型(如OpenAI)之前,相关的Middleware可以对输入(如用户问题、提示模板)进行加工(如改写、添加上下文)。
-
核心执行:模型或工具执行其主要任务。
-
Middleware再次介入 :在核心结果返回给用户之后,Middleware可以对输出进行再处理(如格式化、审计、缓存结果)。
-
结果返回:最终处理后的结果返回给调用方。
感觉和编程里面向切面编程(AOP)的思想是一致的,如果是和我一样之前是做客户端开发的,理解这个就很容易了。
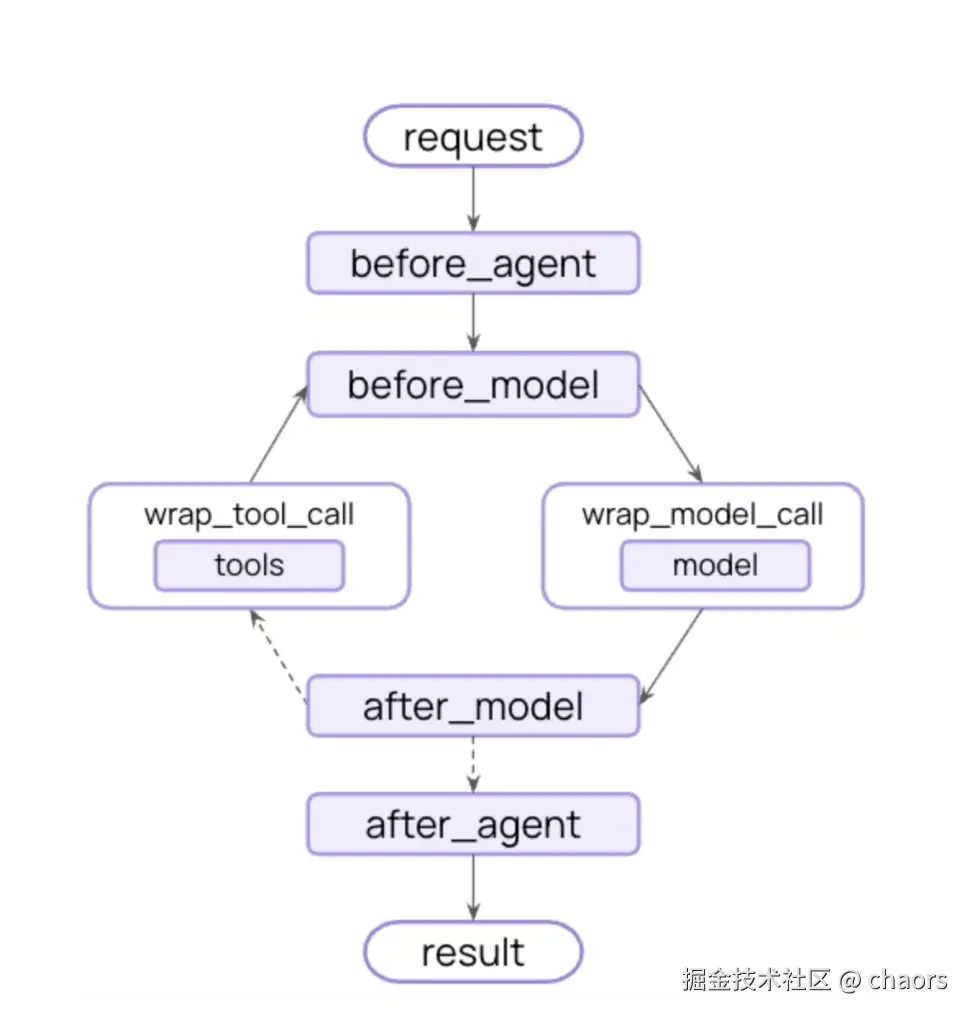
- before_agent - 在Agent启动之前(每次调用一次)
- before_model - 每次模型调用之前。
- after_model - 每次模型响应之后。
- after_agent - Agent完成后(每次调用一次)
- wrap_model_call - 围绕每次模型调用
- wrap_tool_call - 围绕每次工具调用。
内置middleware
LangChain提供了一些常用的内置 middleware。
有哪些?
打开 官方文档,找到其内置的middleware。
🌰SummarizationMiddleware
SummarizationMiddleware: Condenses message history to stay within context limits when conversations grow long- 总结摘要中间件(上下文压缩):当接近会话次数上限时,自动汇总对话历史记录。
我们以 SummarizationMiddleware 为例简单看下 middleware 的使用。
准备工作
ini
llm = get_ali_model_client()
memory = InMemorySaver()middleware
- max_tokens_before_summary:触发的最大Token
- trigger:更高级的触发条件,值是一个数组,数组中任意一个元素满足即可触发
ini
# 创建短期记忆实例
# 中间件列表,可以多个,多个顺序执行
middleware = SummarizationMiddleware(
model=llm,
max_tokens_before_summary=120, # 120个token 会触发 摘要总结
# trigger={"tokens": 4000, "messages": 10}, # 单一条件:当tokens> = 4000且消息> = 10时触发
# trigger=[ # 多重条件-(任意条件满足 - 逻辑"或")。
# {"tokens": 5000, "messages": 3},
# {"tokens": 3000, "messages": 6},
# ],
messages_to_keep=1, # 在总结后保留最后1条消息
# 可选 summary_prompt=" 可以自定义进行摘要的提示词...",
summary_prompt="请将以下对话历史进行简洁的摘要,保留关键信息: {messages}"
)
middlewares = [middleware]run
ini
agent = create_agent(
model=llm,
tools=[],
checkpointer=memory,
middleware=middlewares,
# 打印Agent执行的过程日志
debug= True
)分析
我们模拟一个长对话来分析摘要中间件的处理过程。
python
# 模拟长对话触发摘要
print("\n模拟长对话场景...")
demo_messages = [
"用户询问你是谁",
"用户计算商品价格:数量10,单价25.5",
"用户再次询问你能做什么?",
"用户想要生成一个介绍湖南的文案,要求100字左右,包含三湘四水,人文历史",
"用户继续询问更多GPU产品信息",
"用户要求计算2*20"
]
for i, message in enumerate(demo_messages, 1):
print(f"\n===========💬 第{i}轮对话: {message} ============")
# 循环调用Agent,模拟多轮对话
result = agent.invoke({
"messages": [HumanMessage(content=message)]},
config={"configurable": {"thread_id": "testsummarizationMiddleware"}}
)
print(f"\n===========💬 执行结果: {result} ============")- 条件:
max_tokens_before_summary= 120
我们发现,Log里有个summarizationMiddleware.before_model。这里的before_model就是一个 hook 函数,他负责在 model 之前执行摘要操作。但是这里值为None,表示该中间件并未执行。

我们继续看第二轮对话,before_model 依然未执行。为什么呢?我们可以看出目前total_tokens(77) < 120,所以未触发。
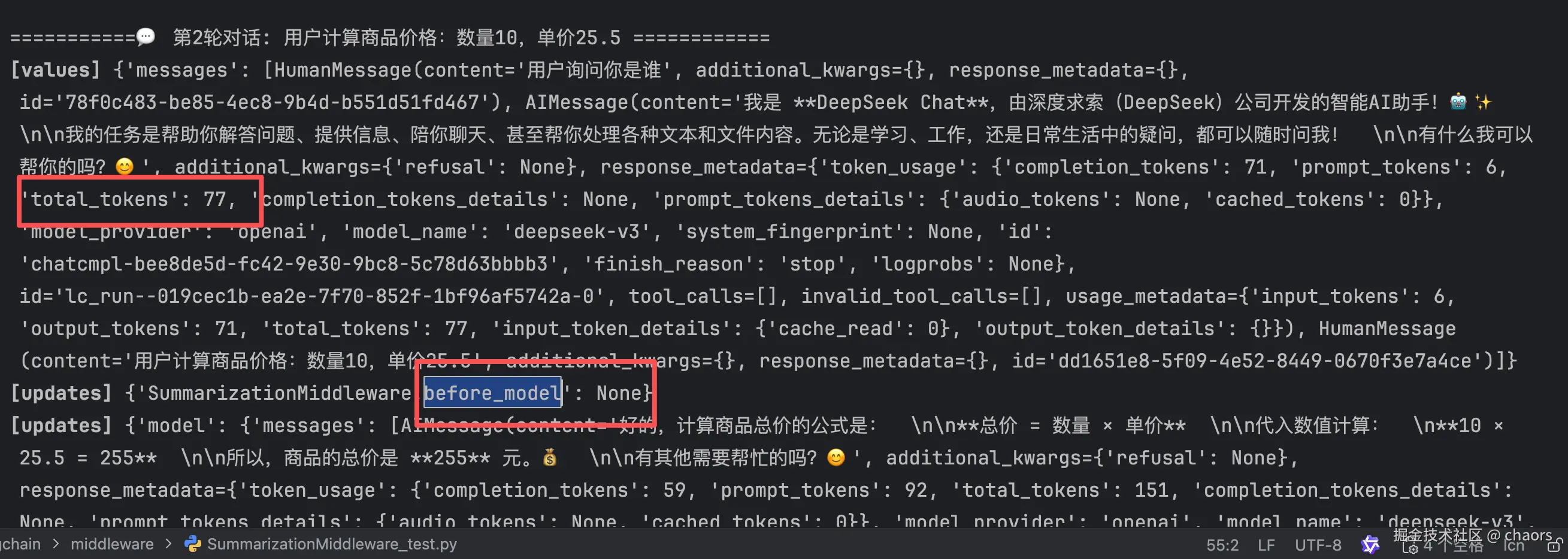
然后我们继续看第三轮对话,我们发现:
- total_tokens(151) > 120,触发 before_model 执行摘要
- LLM 对历史信息进行了摘要,之前大模型回答的信息更精简了
- LLM回答新的问题
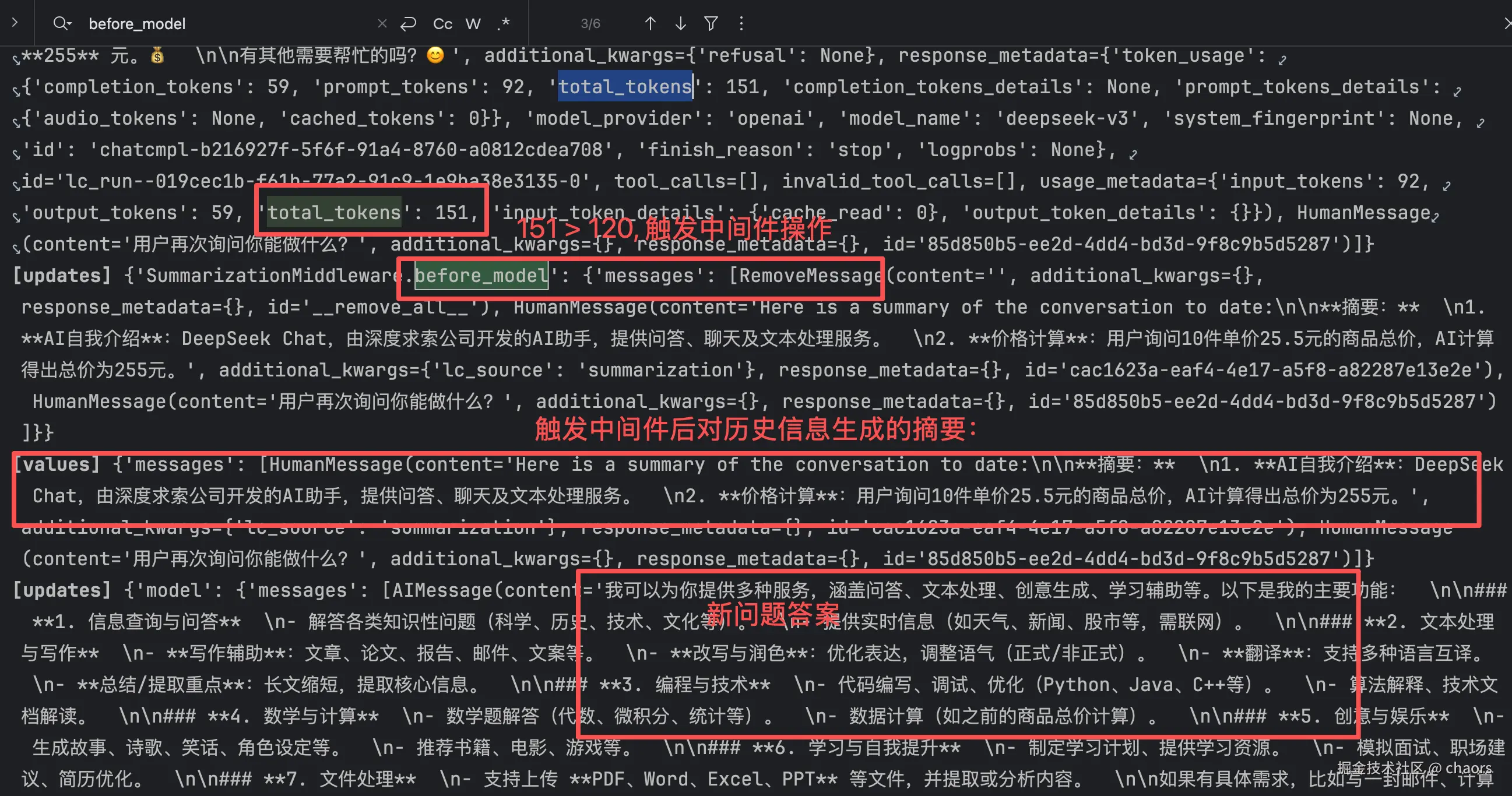
意义
当上下文对话量积累到一定程度时,一个动辄上千token的上下文,经过摘要压缩到几百token,每次调用的费用可能直接下降一个数量级 。而且,更短的输入输出意味着大模型需要处理的序列长度更短,生成速度更快。
自定义middleware
有时候内置 middleware 并不能满足我们的需求。这个时候就需要我们按自己的业务需求来自定义 middleware。那么怎么定义和使用呢?
方式一:装饰器定义
适用于单钩中间件,快速简便。
@before_model:使用 @装饰器即可
middleware
python
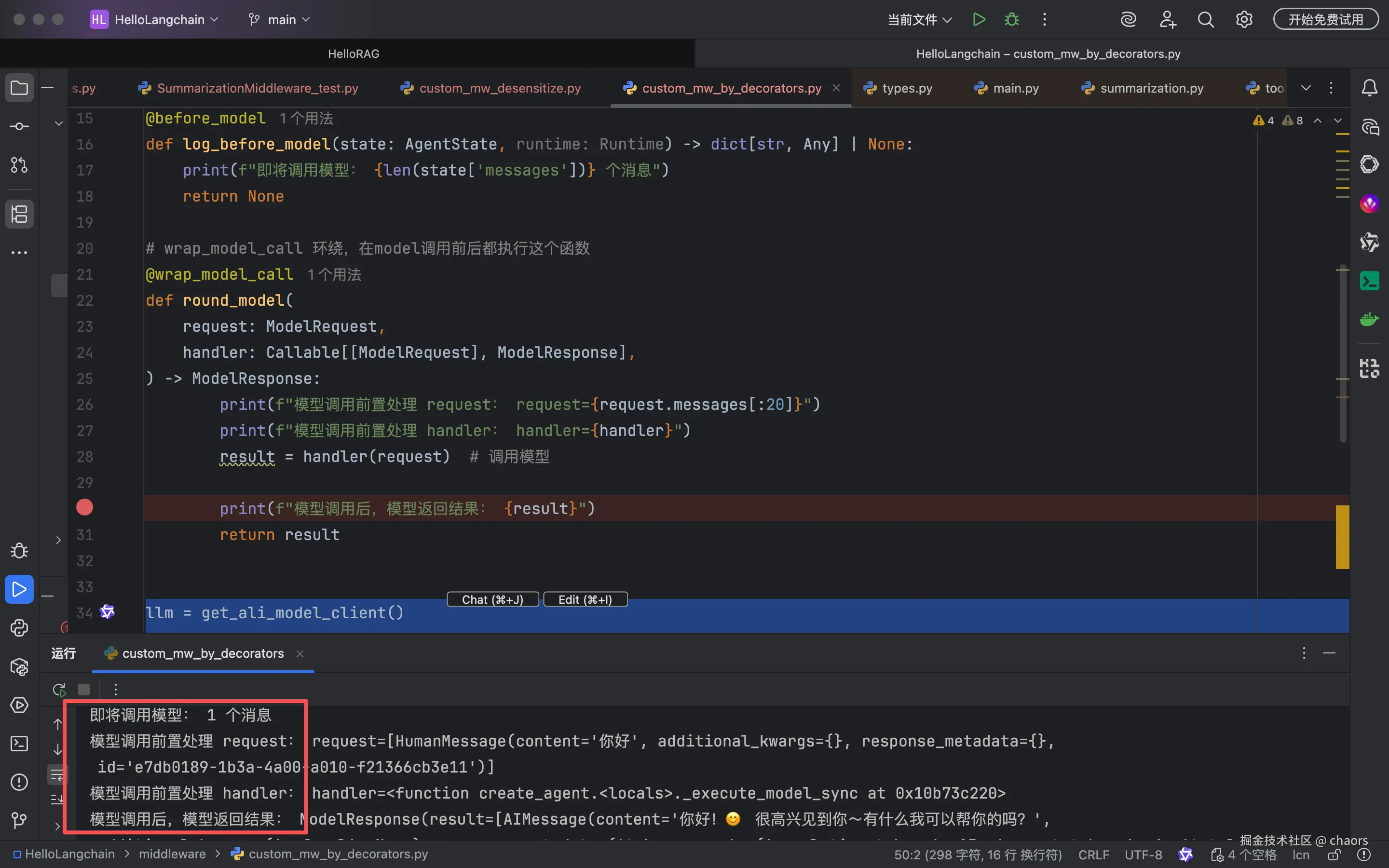
# 前置,在调用模型前,执行这个函数
@before_model
def log_before_model(state: AgentState, runtime: Runtime) -> dict[str, Any] | None:
print(f"即将调用模型: {len(state['messages'])} 个消息")
return None
# wrap_model_call 环绕,在model调用前后都执行这个函数
@wrap_model_call
def round_model(
request: ModelRequest,
handler: Callable[[ModelRequest], ModelResponse],
) -> ModelResponse:
print(f"模型调用前置处理 request: request={request}")
print(f"模型调用前置处理 handler: handler={handler}")
result = handler(request) # 调用模型
print(f"模型调用后,模型返回结果: {result}")
return result调用
ini
llm = get_ali_model_client()
agent = create_agent(
model=llm,
# 按照列表顺序依次执行中间件
middleware=[log_before_model, round_model],
)
result = agent.invoke(
{
"messages": [
{
"role": "user",
"content": "你好",
}
]
}
)
方式二:AgentMiddleware
对于具有多个钩子的复杂中间件来说,基于类的定义是最好的选择。
AgentMiddleware:钩子类必须继承自这个类
python
class LoggingMiddleware(AgentMiddleware):
def before_model(self, state: AgentState, runtime: Runtime) -> dict[str, Any] | None:
print(f"即将调用模型: {len(state['messages'])} 个消息")
return None
def after_model(self, state: AgentState, runtime: Runtime) -> dict[str, Any] | None:
print(f"模型返回消息: {state['messages'][-1].content}")
return None至于调用上就没什么差别。
小实战
现在定义一个 信息脱敏中间件 ,用于在和 LLM 交互过程中隐藏电话号码、邮箱等敏感信息。废话少说上代码。
DesensitizeDataMiddleware
初始化
python
def __init__(self, patterns: list = None):
super().__init__()
self.patterns = patterns or [
(r'[a-zA-Z0-9_.+-]+@[a-zA-Z0-9-]+.[a-zA-Z0-9-.]+', f'{self.placedEmail}'),
(r'(+86)?1[3-9]\d{9}', f'{self.placedPhone}')
]脱敏函数
python
def _desensitize_text(self, text: str) -> str:
# 如果内容为空或已经包含脱敏标记,则跳过处理
if not text or f'{self.placedEmail}' in text or f'{self.placedPhone}' in text:
return text
# 快速预检查:只有当可能包含敏感信息时才继续处理
if '@' not in text and not re.search(r'1[3-9]\d{9}', text):
return text
print(f"脱敏前: {text}")
original_text = text
for pattern, replacement in self.patterns:
text = re.sub(pattern, replacement, text)
# 只有当内容发生变化时才打印
if original_text != text:
print(f"脱敏后: {text}")
return textbefore_model
python
def before_model(self, state: Dict[str, Any]) -> Dict[str, Any]:
"""在模型调用前处理"""
print("中间件DesensitizeDataMiddleware - before_model 被调用")
if 'messages' in state:
messages = state['messages']
processed_any = False
for message in messages:
if hasattr(message, 'content') and isinstance(message.content, str):
# 只处理非空内容且未被脱敏的内容
if message.content and f'{self.placedEmail}' not in message.content and f'{self.placedPhone}' not in message.content:
# 快速预检查:只有当可能包含敏感信息时才继续处理
if '@' in message.content or re.search(r'1[3-9]\d{9}', message.content):
# 只有在真正需要处理时才打印日志
if not processed_any:
print("进行脱敏处理.....")
original_content = message.content
message.content = self._desensitize_text(message.content)
# 只有当内容发生变化时才打印
if original_content != message.content:
print(f"消息内容已从 '{original_content}' 修改为 '{message.content}'")
processed_any = True
if processed_any:
print("脱敏处理完成!")
return state测试代码
ini
# 导入工具,load_tools支持的工具可以在load_tools.py中查看
tools = load_tools(["arxiv"])
# 创建短期记忆实例
memory = InMemorySaver()
# 系统提示词设计
system_prompt = "你是一个专业的论文查询助手,使用arxiv工具为用户查询论文信息,回答需简洁准确,包含论文标题、作者、发表时间和核心摘要。"
# 创建带中间件的Agent
agent_with_middleware = create_agent(
model=llm,
tools=tools,
system_prompt=system_prompt,
checkpointer=memory,
# 加入脱敏的中间件
middleware=[desed_middleware]
)
# 测试---
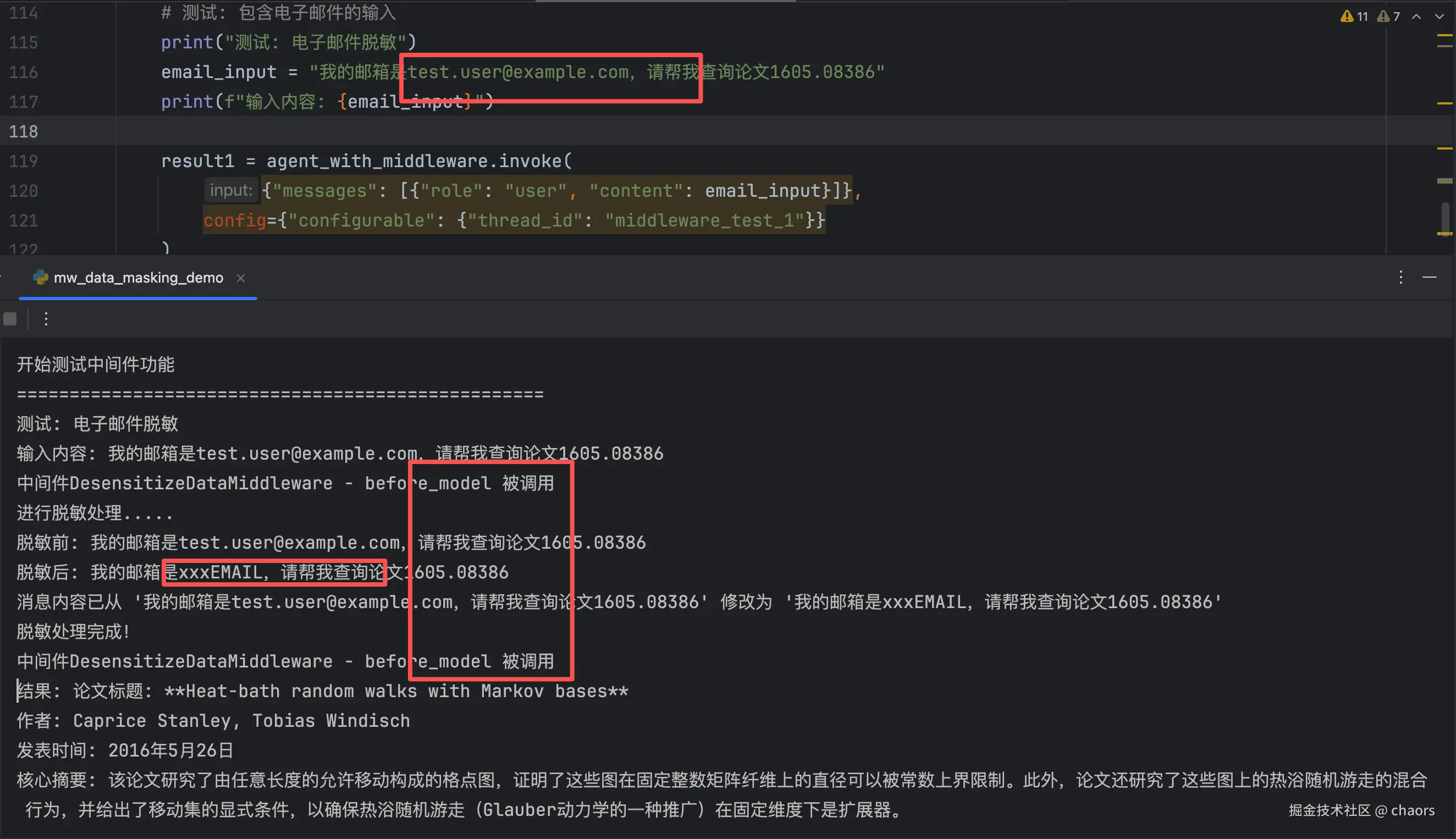
# 测试: 包含电子邮件的输入
print("测试: 电子邮件脱敏")
email_input = "我的邮箱是test.user@example.com,请帮我查询论文1605.08386"
print(f"输入内容: {email_input}")
result1 = agent_with_middleware.invoke(
{"messages": [{"role": "user", "content": email_input}]},
config={"configurable": {"thread_id": "middleware_test_1"}}
)
print("结果:", result1["messages"][-1].content)