安装完openclaw后,需要安装Skill来强化龙虾的技能,让它可以干更多的活,越用越聪明。先来了解一下,ClawHub是什么:
ClawHub 是 OpenClaw AI 智能体生态系统中的核心组件,可以将其类比为 "AI 智能体的应用商店" 或 "技能注册表"。
- 核心定位:什么是"技能"(Skills)?
在 OpenClaw 生态中,所谓的"技能"是指赋予 AI 智能体特定功能的小型代码模块或工具插件。
功能扩展:基础的 AI 可能只会对话,通过安装来自 ClawHub 的技能,它可以获得文件处理、云端交互、代码分析、搜索外部数据等具体能力。
模块化 :技能以文件夹形式存在,通常包含定义文件(如
SKILL.md)。这种设计让 AI 的能力可以像安装 App 一样灵活增删。
- ClawHub 的功能角色
ClawHub 本身是一个公共注册表(Registry),它承担了以下职能:
发布与分发:开发者可以编写 AI 技能并上传到 ClawHub,供全球用户搜索和下载。
版本管理 :类似于
npm管理 JavaScript 库,ClawHub 确保了技能的更新和版本迭代。发现与检索:它通过嵌入式向量搜索等技术,帮助用户在成千上万个社区构建的技能中,快速找到解决特定问题(如"连接 Google Drive"或"处理 PDF")的方案。
Skill我们需要到开源平台https://clawhub.ai/中安装,注意安装时先查看一下评论区是否有反应Skill供应链投毒,确保安全再安装:
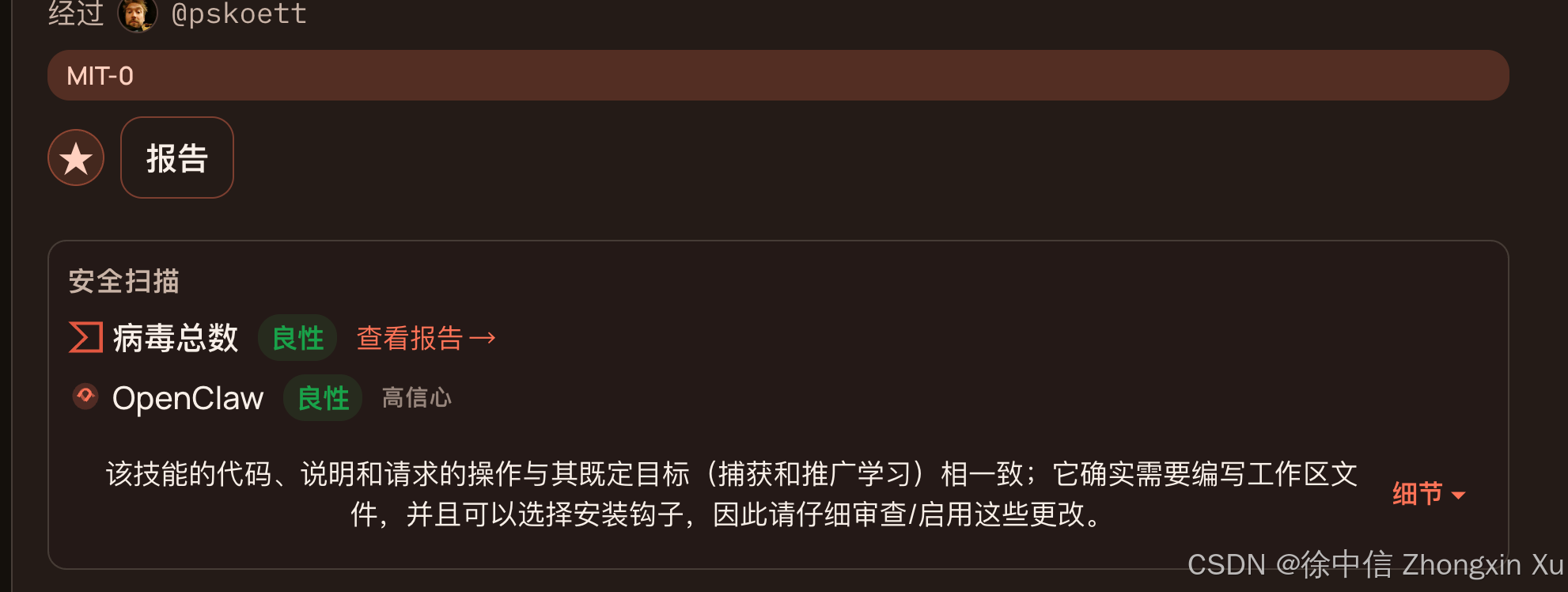
首先,需要注册GitHub账号并链接到ClawHub,在ClawHub平台中create一个Key
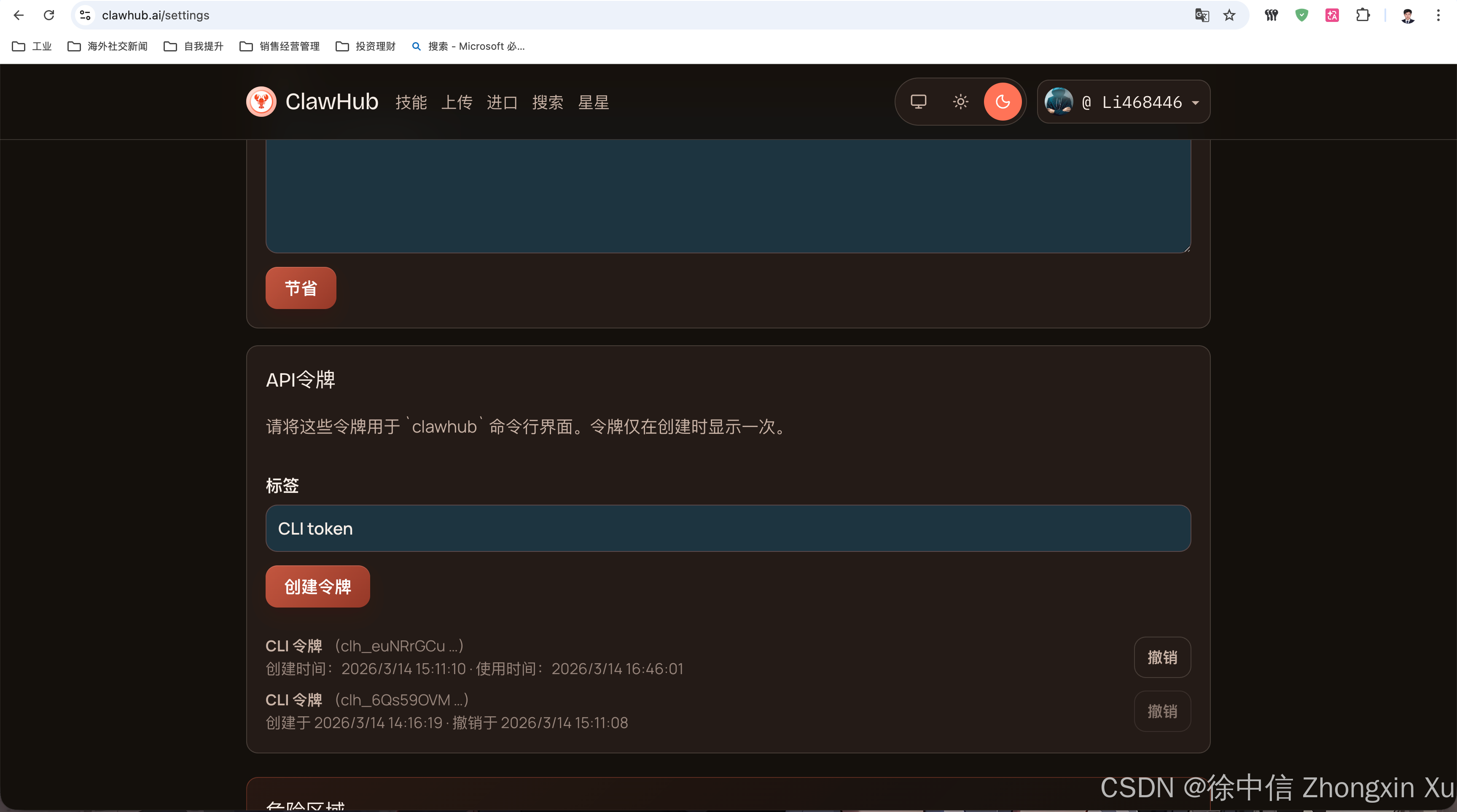
一、安装ClawHub
在命令行中执行前置命令,先使用Key登录,避免被限速
npx clawhub@latest auth login --token 【在ClawHub申请的CLI Token,替换此处内容】 --no-browser
响应OK即成功,执行安装命令
npm install -g clawhub@latest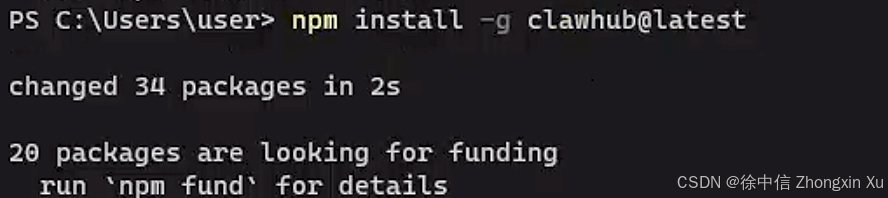
这样ClawHub就算安装完成了。
二、使用
# 搜索技能
clawhub search "skill name"
# 安装技能
clawhub install <skill-test>
# 查看已安装
clawhub list
# 更新所有技能
clawhub update --all在 OpenClaw 生态中,理解"技能"(Skills)的加载优先级至关重要,因为这决定了当多个技能定义了同名功能或冲突参数时,系统最终会调用哪一个。OpenClaw 遵循 "显式优先、范围由窄到宽、配置优于默认" 的加载策略。系统通常按照以下层级顺序扫描并加载技能,优先级由高到低排列:
| 优先级 | 加载位置 / 类别 | 描述 |
|---|---|---|
| 最高 | Local Overrides (./skills) |
位于项目工作根目录下的 skills/ 文件夹。这是您自定义或针对当前项目覆盖的特定技能。 |
| 中高 | User Scoped (~/.clawhub/skills) |
用户级别的全局技能库,通过 clawhub install -g 安装的模块存放在此。 |
| 中低 | System/Project Defaults | 项目配置中定义的共享路径或 package.json 中声明的依赖技能。 |
| 最低 | Remote/Registry Defaults | 由 clawhub 自动从云端获取或缓存的公用基础技能。 |
高优先级的同名 Skill 会覆盖低优先级的。这意味着你可以 Fork 任何 Skill 放到工作区目录下做自定义修改。在 OpenClaw 生态中,理解"技能"(Skills)的加载优先级至关重要,因为这决定了当多个技能定义了同名功能或冲突参数时,系统最终会调用哪一个。OpenClaw 遵循 "显式优先、范围由窄到宽、配置优于默认" 的加载策略。系统通常按照以下层级顺序扫描并加载技能,优先级由高到低排列:
1. 优先级排序清单
| 优先级 | 加载位置 / 类别 | 描述 |
|---|---|---|
| 最高 | Local Overrides (./skills) |
位于项目工作根目录下的 skills/ 文件夹。这是您自定义或针对当前项目覆盖的特定技能。 |
| 中高 | User Scoped (~/.clawhub/skills) |
用户级别的全局技能库,通过 clawhub install -g 安装的模块存放在此。 |
| 中低 | System/Project Defaults | 项目配置中定义的共享路径或 package.json 中声明的依赖技能。 |
| 最低 | Remote/Registry Defaults | 由 clawhub 自动从云端获取或缓存的公用基础技能。 |
2. 加载机制解析
工作目录优先(The Working Directory Principle) :系统启动时,首先扫描当前终端所在的根目录。如果在
./skills中检测到了与全局同名的技能文件,系统会直接挂载本地版本,从而屏蔽全局版本。这允许您在不影响其他项目的前提下,针对特定 AI 任务"打补丁"。版本约束(Version Pinning) :如果多个路径下存在同名的技能,
clawhub会检查技能的manifest.json或package.json中的version字段。如果存在冲突,系统通常会选择语义化版本号(SemVer)最高的那个,除非强制指定了版本。依赖冲突处理:如果两个不同级别的技能依赖了同一个基础底层库,系统通常会采用"扁平化"加载方式,即优先加载最靠近当前工作流定义的依赖。
3. 如何查看当前的加载顺序
如果不确定当前环境中哪个技能正在生效,可以使用 clawhub 的诊断命令查看加载链:
clawhub list --verbose该命令会输出一个详细的列表,显示每个已识别技能的绝对路径(Source Path)。在列表的顶部,即表示优先级最高的生效版本。
三、安全提醒
在 OpenClaw 生态中保持"防御性配置"是专业开发者的必备素养。
"ClawHavoc" 事件的深层威胁逻辑
此次攻击的核心手段是"依赖混乱(Dependency Confusion)"与"伪装分发"。攻击者利用了 ClawHub 的快速迭代特性:
社会工程学伪装 :通过模仿热门工具的命名(例如将
youtube-downloader写成yutube-downloader),利用拼写差异误导用户。潜伏期攻击 :恶意 Skill 在安装时表现正常,但在调用
npx或执行脚本时,会通过隐藏的postinstall脚本尝试窃取~/.clawhub下的配置文件(包含您的认证 Token 和环境变量)。
深度防御:安装 Skill 时的"四重校验"机制
在执行任何 clawhub install 命令前,请建立如下标准化工作流:
1. 验证签名与信任链
不要仅关注安装量,高安装量往往是攻击者刷单的结果。请点击 Skill 页面底部的 "Verified Contributor" 徽章,仅信任具有明确身份背书的维护者。
2. "安全扫描(Security Scan)"的本质
ClawHub 提供的"Benign"标签是由 Koi Security 审计引擎 自动生成的。
- 警惕动态注入 :即使显示"Benign",如果该 Skill 动态请求了
network或file-system权限,请在安装前手动通过clawhub inspect <skill-name>预览权限声明。3. 静态代码审计(SKILL.md 与 Source Code)
在执行安装前,请始终执行以下命令查看脚本源码:
clawhub view <skill-name> --source重点检查是否存在以下异常行为:
Base64 编码字符串:攻击者常通过 Base64 隐藏恶意 Payload。
外部请求 :任何向非官方 API 发送数据的
fetch或curl命令。环境变量操作 :调用
process.env获取敏感信息的逻辑。
紧急响应方案:如果怀疑已中招
如果您在近期安装了来源不明的 Skill,请立即采取以下步骤:
切断凭证 :登录 ClawHub Dashboard,重置所有的 API Tokens 和访问密钥。
清理目录:
删除已安装的异常 Skill:
clawhub uninstall <skill-name>手动清理缓存目录:
Remove-Item -Path "$env:USERPROFILE\.clawhub\cache\*" -Recurse -Force网络隔离审计 :利用
ClawdStrike的audit-log功能导出该 Skill 近 24 小时的网络请求记录,排查是否存在与异常 IP 的通信。
专业建议
"信任,但要验证"(Trust, but verify)。在 AI 智能体生态中,技能本身就是"代码执行器",其危险程度远高于普通 Web 应用。
原则:将 ClawHub 视为"不受信任的互联网资源",而非"受信任的代码库"。
配置 :考虑在
.clawhub/config.json中配置白名单,仅允许安装来自您信任的开发者列表的 Skill。
四、Skill推荐
1. Agent Browser(浏览器自动化)
在 OpenClaw 生态中,Agent Browser 是最核心、功能最强大的"技能"之一,它本质上是一个由 AI 驱动的无头浏览器(Headless Browser)自动化框架。它不仅仅是一个简单的爬虫,而是将浏览器变成了一个"AI 可以操作的界面"。
在 OpenClaw 生态中,Agent Browser 是最核心、功能最强大的"技能"之一,它本质上是一个由 AI 驱动的无头浏览器(Headless Browser)自动化框架。它不仅仅是一个简单的爬虫,而是将浏览器变成了一个"AI 可以操作的界面"。
核心定位:AI 的"数字双手"
Agent Browser 的核心目标是让 AI 能够像人类一样与 Web 进行交互,而不仅仅是解析 HTML 源码。它让 AI 能够:
理解视觉语义:识别按钮、输入框、下拉菜单等交互元素,而非仅仅查看 DOM 树。
执行复杂流:完成"搜索关键词 -> 点击特定结果 -> 滚动页面 -> 提取表格数据 -> 导出为 CSV"等一系列多步骤操作。
绕过反爬机制:通过模拟真实的浏览器行为(如 User-Agent、Cookie 处理、甚至必要的鼠标轨迹),降低被拦截的风险。
技术实现:基于 Playwright 的增强封装
Agent Browser 通常基于 Playwright 或 Puppeteer 构建,并加入了 OpenClaw 专有的 AI 适配层:
DOM 到文本的转化:它会自动将复杂的 HTML 页面简化为 AI 容易理解的"语义文本表示"。
截图与分析:支持通过调用视觉模型(如 GPT-4o-mini 或本地的 LLaVA)来读取页面截图,从而理解那些无法通过 DOM 识别的动态界面(例如复杂的 Canvas 绘图)。
交互注入 :AI 发出"点击登录按钮"的指令后,该技能会将意图转化为底层的
page.click('button#login')操作。
应用场景示例
自动化办公:自动登录财务网站并下载发票明细。
竞品监控:每天定时访问竞争对手的官网,自动提取价格变动并发送邮件。
Web 任务代理:在 OpenClaw 中配置"查找并预订最近的餐厅",Agent Browser 会完成从搜索、筛选到填单的一整套动作。
安装命令
clawhub install agent-browser2. Self-Improving Agent(自学习进化)
在人工智能领域,尤其是针对以开源框架(如 OpenClaw,即俗称的"龙虾")为基础的 ClawHub 平台,Self-Improving Agent(自学习进化智能体) 是一项旨在打破传统"静态工具"限制、赋予智能体动态成长能力的进阶机制。
核心定义与目标
传统的 AI 工具或脚本通常是"固化的",即功能在编写完成后不再发生改变。Self-Improving Agent 的本质是赋予智能体**"元认知"和"自主构建"**能力,使其能够:
弥补认知缺口: 当任务需求超出了当前已安装的技能范围时,它能够意识到"我缺少工具"。
自主迭代: 它不依赖人类预先编写好所有的解决方案,而是通过与环境的交互,不断优化自己的决策策略、工作流程甚至代码库。
运作机制:自进化的"循环链"
该功能的实现通常依赖于一个闭环的反馈逻辑,主要包含以下几个关键步骤:
| 关键环节 | 功能描述 |
|---|---|
| 自我评估 (Self-Assessment) | 智能体在执行任务时,会实时监控结果与预设目标之间的差距,识别执行过程中的瓶颈。 |
| 需求触发 (Trigger) | 识别出无法完成任务时,触发"搜索与学习"指令,例如:"如果没有此功能,请搜索并创建"。 |
| 外部资源获取 | 调用接口访问外部知识库、代码库或技能仓库(ClawHub 技能包),获取必要的逻辑或工具。 |
| 工具构建与集成 | 自动编写或配置新的技能模块,并将其注册到本地的智能体库中,实现功能扩展。 |
| 反馈回溯 (Feedback Loop) | 将本次操作的效果记录在"记忆"中,优化后续的决策模型,从而实现"越用越聪明"。 |
应用场景与价值
长效个人助理: 能够随着用户的特定习惯(如处理特定格式的文档、自动化回复特定邮件)不断进化,变得越来越契合个人工作流。
复杂任务拆解: 用户只需下达模糊的宏观目标,智能体可自主拆解为可执行的子任务,并按需构建辅助性的脚本工具。
安装命令
clawhub install self-improving-agent3. Agent Memory(持久记忆)
Agent Memory(智能体记忆系统) 是支撑其"长效服务"和"个性化响应"的核心架构。如果说"自学习进化"是智能体的大脑前额叶,负责逻辑推演与升级,那么"持久记忆"就是其海马体,负责跨时间窗口的知识存储与检索。在企业级或专业化的应用背景下,Agent Memory 通常分为以下三个核心层级:
记忆的层级架构 (Memory Architecture)
为了保证性能与准确性,采用了分层存储机制:
短期记忆 (Short-term / Working Memory):
定义: 对应当前的上下文窗口(Context Window)。
作用: 存储当前对话中的瞬时变量、临时状态或正在处理的任务参数。它随会话结束而清空,防止数据冗余。
长期记忆 (Long-term / Persistent Memory):
定义: 建立在外部向量数据库(Vector Database)之上。
作用: 通过将历史信息转化为高维向量(Embedding),实现语义层面的持久存储。即使智能体重启或跨越数周,它依然能"记得"用户曾经偏好的格式、特定的项目背景或既定的沟通风格。
语义记忆 (Semantic Memory):
定义: 结构化的知识图谱或元数据存储。
作用: 将分散的事实关联起来,使得智能体具备逻辑推理的基础,例如"项目 A"与"人员 B"的关联属性。
核心运作机制:检索增强生成 (RAG)
ClawHub 中的持久记忆并非简单地"记录",其运作逻辑核心是 RAG (Retrieval-Augmented Generation):
编码与入库: 当用户产生新的交互记录时,智能体将其转化为向量存入存储系统。
相关性检索: 当新的 Prompt 提交时,智能体不仅处理当前问题,还会向数据库发起"相似性搜索",调取过去相似背景下的处理逻辑或事实。
整合生成: 将"当前问题"与"检索到的历史记录"合并,作为提示词的一部分发送给大模型,从而输出具备上下文连贯性的回答。
持久记忆带来的核心价值
跨会话一致性: 避免了"每次开始新对话都要重新解释背景"的繁琐,显著提升了专业场景下的沟通效率。
个性化定制: 智能体会随时间推移"沉淀"出用户画像。例如,如果你习惯在代码输出中包含详尽的测试用例,记忆系统会记录这一偏好,并在后续任务中自动执行,无需反复提醒。
错误纠正记录: 智能体能够记住过往的执行错误。如果某次操作导致了系统报错,它会将此次失败的经验加入记忆,避免在未来再次触犯同样的路径。
安装命令
clawhub install agent-memory4. Agent Autopilot(自动驾驶模式)
是实现智能体从"人机协作(Copilot)"向"完全自主执行(Autonomous Execution)"转型的关键技能。它不仅仅是一个功能开关,而是一种运行策略,允许智能体在预设的边界内,无需人工干预即可完成复杂的、多步骤的任务链。
结构化设计:Autopilot 的底层逻辑
OpenClaw 的 Autopilot 模式通过以下几个核心组件协作,保证了在"无人驾驶"状态下的系统可靠性:
意图拆解引擎 (Task Planner): 将用户模糊的指令(如"帮我整理上周的报表并发送邮件")转化为逻辑清晰的步骤树(DAG,有向无环图)。
状态监控循环 (Pulse Cycle): 智能体以特定的心跳频率运行。在每个周期,它不仅执行动作,还会监控系统状态(如文件写入权限、API 响应耗时),确保没有偏离轨道。
安全防御边界 (Guardrails): 即便在 Autopilot 模式下,系统也会强制执行预设的"红线"规则。例如,涉及资金转账、敏感文件删除等操作,会触发自动化的异常检测,一旦置信度低于阈值,系统会通过安全策略自动阻断或挂起。
异常自愈机制 (Auto-Retry & Error Handling): 遇到执行失败时,Autopilot 不会直接终止,而是根据错误代码自主尝试回滚或重试(例如:API 速率限制下的指数退避重试)。
应用场景:从效率到自动运行
Autopilot 适用于那些"逻辑明确但耗时较长、重复性高"的专业领域:
全自动研发流水线: 智能体团队(产品经理、工程师、QA)自动完成代码编写、提交 PR、运行测试、监控日志。如果测试失败,智能体能自动回溯并修改代码。
跨平台运营监控: 实时监控社交媒体动态、抓取竞品数据、整理成日报,并在检测到特定危机时自动向管理员发送预警通知。
企业后台管理: 在金融或合规要求较高的行业中,用于自动收集、交叉校验不同系统的审计数据,自动生成符合规范的申报材料,仅在最后一步提交前交由人工最终确认。
实战案例:跨平台的"自动驾驶"办公
在实际配置中,Autopilot 通常表现为一种"长效后台服务"。
案例:自动化代码评审与部署
触发: 开发者在 GitHub 提交 PR,OpenClaw Agent 通过 Webhook 监听到事件。
规划: Agent 自动激活 Autopilot,开始规划任务:
获取变更代码→运行本地单元测试→分析代码安全性→评审文档合规性。执行(无人驾驶): 在接下来的 15 分钟内,Agent 自主操作,无需开发者介入。它运行 Shell 命令编译项目,对比基准线,将评审意见直接写回 PR。
决策与反馈: * 若测试全通过且符合规范:自动标记为"Ready to Merge"。
- 若发现严重漏洞:Agent 主动发送一条消息到 Slack 或 Telegram,详细解释风险点,并保留执行日志以供后续审计。
安装命令
clawhub install agent-autopilot5. Airpoint(Mac 自然语言控制)
"Airpoint"并非单一的预设技能(Skill),而是一套整合了 macOS 原生能力(Native Capabilities)与智能代理接口的控制范式。它允许智能体通过自然语言指令直接调用 macOS 的系统服务,实现对桌面的"零接触"操控。
结构化设计:Airpoint 的控制链路
Airpoint 的实现依赖于 OpenClaw 的 macOS Companion(桌面伴侣)与后台服务的深度协作:
控制平面 (The macOS Companion): 该应用运行于菜单栏,作为系统的"守门人"。它负责申请并管理 macOS 的关键授权(如 Accessibility/辅助功能 、Screen Recording/屏幕录制 、Automation/AppleScript)。这是任何自然语言指令能够转化为实际点击、滚动或输入的物理基础。
指令翻译层 (The Bridge): 用户在聊天窗口发出的指令(如"打开邮件并标记未读"),会由 Agent 转化为结构化的执行脚本(通常为 AppleScript 或 Shell 命令)。
执行与反馈层 (Execution Loop): 指令通过 Unix Socket 传递给桌面伴侣。伴侣在执行前会进行安全性校验 (参考
~/.openclaw/exec-approvals.json中的白名单),确保该动作未超出用户允许的边界。
核心应用场景
Airpoint 范式主要解决的是传统自动化工具(如 Automator)难以处理的"动态场景":
跨应用编排: 例如"将飞书收到的项目摘要,自动整理并同步到本地的 Obsidian 笔记中"。Agent 能够自动调起两个应用并完成内容复制粘贴。
系统状态查询与调控: 通过自然语言询问"我的 Mac 当前内存压力大吗?"或指令"调低亮度并开启专注模式",Agent 直接调用系统偏好设置接口。
UI 交互自动化: 对于那些没有开放 API 的软件,Airpoint 结合了屏幕截图分析与坐标点击技术,能够通过分析 UI 结构,实现对遗留软件的"自动化操作"。
实战案例:自动化会议记录工作流
假设您正在使用 Slack 或 iMessage 与 OpenClaw 交互,您可以下达如下指令:
指令: "帮我准备一下下午的会议,打开日历确认时间,并从邮件里找到相关的 PDF 附件,最后放到桌面文件夹里。"
OpenClaw 的自动化执行序列:
意图识别: Agent 拆解任务,调用
Calendar接口获取会议时间。搜索辅助: Agent 使用
系统级操作 (Airpoint):
调用
Finder指令,创建命名为"会议准备"的新文件夹。自动执行文件移动操作,将附件下载并存入该文件夹。
最终反馈: 在聊天框回复:"会议已找到(14:00 开始),相关附件已放入桌面文件夹。"
安装命令
clawhub install airpoint6. Credential Manager(本地凭证管理)
Credential Manager(凭证管理) 是该系统安全架构中极为核心且常被误解的部分。
需要特别说明的是: 在 OpenClaw 当前的架构设计中,并不存在一个像企业级密码库那样高度封装、自动加密的"Credential Manager 技能"。相反,OpenClaw 的凭证管理主要依赖于本地配置文件及其所在的操作系统权限边界。
结构与实现机制
OpenClaw 的凭证管理采用的是**"去中心化配置"**模式:
存储位置: 凭证(如 API Keys、OAuth Tokens、Webhook 密钥等)通常以明文或简单加密的形式存储在用户目录下的
~/.openclaw/或项目级的.env文件中。加载方式: 当智能体启动时,它会读取这些文件并将其作为环境变量或内存参数注入到运行进程中。
权限继承: 这是 OpenClaw 的一个关键设计特征------智能体以宿主用户的权限运行。这意味着,如果用户拥有访问某私有云服务的权限,智能体便可以直接读取对应的凭证并执行操作。
应用场景
凭证管理主要用于支撑智能体与外部服务的"深度绑定":
自动化工作流: 智能体需要调用 GitHub API 提交 PR、通过 Gmail API 发送邮件或使用 Slack Bot Token 进行消息推送。
模型调用: 存储各类大模型(Claude, GPT, Gemini 等)的 API Key,以便在执行复杂推理时进行动态调用。
长效监控: 智能体在后台 24/7 运行,通过存储的凭证维持与各类 SaaS 服务的长效会话。
实战案例:安全配置路径
由于原生凭证管理机制较弱,专业使用者通常会采用以下"加固"路径来模拟凭证管理:
场景:为生产环境下的 OpenClaw 配置 Gmail 技能
隔离部署 (Containerization):
不要在宿主机直接存放个人 Gmail 的凭证。
使用 Docker 运行 OpenClaw,仅将必要的非敏感文件挂载进容器。
环境隔离 (Environment Variable Injection):
不要将 API Key 直接写入
config.yaml。通过
docker-compose.yml或.env文件,利用环境变量注入凭证:
services: openclaw: environment: - GMAIL_TOKEN=${GMAIL_TOKEN_SECRET}BROKER 模式 (使用外部中间件):
- 进阶做法是使用如 Composio 等安全中间件。在该模式下,智能体不直接持有长效凭证,而是向中间件发送请求,由中间件代为签名执行。这种做法将凭证的风险从"本地存储"转移到了"请求拦截与治理"。
安装命令
clawhub install credential-manager7. Evolver(Agent 自进化引擎)
Evolver(智能体自进化引擎) 是系统迈向"通用人工智能(AGI)"雏形的阶梯。如果说 Autopilot 是执行指令的"手",那么 Evolver 就是负责优化自身策略、提升算法效率的"大脑改良中心"。它不仅仅是简单的自我提示(Self-Prompting),而是通过对模型运行参数、逻辑链路及知识库权重进行闭环优化,使智能体随时间推移在特定领域内表现出更高的专业度。
核心架构:三维进化循环
Evolver 的运作并不像传统的软件更新,而是通过以下三个维度的联动实现进化:
策略层优化 (Strategy Refinement):
- 机制: 系统分析历史执行记录,评估"决策路径"的优劣。如果某次复杂的任务执行逻辑冗长且易错,Evolver 会自动压缩决策链路,精简逻辑分支。
知识库权重演进 (Knowledge Weighting):
- 机制: 将成功案例标记为"高置信度"并提升在检索增强生成(RAG)中的权重。同时,将错误案例转化为反向经验,在检索阶段进行"负向屏蔽"。
代码/工具微调 (Tool/Code Optimization):
- 机制: 基于性能监控,Evolver 能够自动对智能体使用的 Python 脚本或 CLI 命令进行重构(例如:将低效的顺序检索改为并发处理),从而减少执行延迟。
应用场景:从"通用"向"特化"的质变
Evolver 特别适用于那些环境动态变化、需求不断迭代的业务领域:
金融合规审查: 随着监管政策的频繁调整,Evolver 可以自动识别新的法规关键词,并将其整合进审查智能体的知识模型中,无需人工手动重写 Prompt。
自动化测试与 Bug 修复: 在持续集成(CI)环境中,Evolver 通过分析测试失败的堆栈信息,自动进化其测试用例生成策略,使智能体不仅能修复当前 Bug,还能预防同类逻辑漏洞的再次发生。
个性化写作与创意辅助: 随着与用户交互的深入,Evolver 学习并捕捉用户的语法习惯、逻辑框架和审美取向,使创作输出越发符合特定风格。
实战案例:数据清洗智能体的进化
假设你部署了一个用于处理非结构化财务报表的 OpenClaw Agent。
初始状态: Agent 采用硬编码的正则表达式处理报表,面对复杂表头时,经常出现解析错误。
进化触发: 系统通过
Error Rate监控识别到解析失败率超过 5%,自动触发 Evolver 引擎。自主学习: Evolver 调取过去 100 次报错的日志,对比成功解析的样本,发现"多级嵌套表头"是主要瓶颈。
自主进化:
技能提升: Evolver 自动向 OpenClaw 平台注册一个新型的"语义结构分析组件"。
优化更新: 重写了预处理阶段的代码,引入了针对嵌套表头的递归清洗逻辑,并将其同步到 Agent 的知识库。
结果: 在下一次执行中,解析成功率从 95% 提升至 99.5%,且处理速度提升了 15%。
安装命令
clawhub install evolver8. Adaptive Reasoning(自适应推理)
Adaptive Reasoning(自适应推理) 旨在解决智能体在动态、非结构化环境下的决策痛点,即如何从模糊的任务描述中解构步骤,并在执行受阻时实时修正方案。
结构组成:自适应推理的运作机理
自适应推理并非单一的线性逻辑,而是一个闭环的反馈系统,主要包含三个核心层级:
感知输入层 (Perception & State Mapping):
将自然语言指令转化为逻辑化表征。
实时监控环境反馈(包括传感器数据、视觉观察或 API 返回值),建立当前状态的动态模型。
决策推理层 (Dynamic Planner):
核心算法:通常结合了长短期记忆机制与图搜索算法。
职责:根据当前状态与最终目标,计算路径代价,生成"行动序列"。当路径代价超过阈值时,自动触发重规划(Re-planning)。
反馈修正层 (Error Recovery Mechanism):
- 这是"自适应"的关键。当执行结果不符合预期(如动作失败、环境突变)时,系统会回溯推理链路,诊断失败原因,并生成补救动作(Recovery Action)。
应用场景:为何需要"自适应"?
该模块主要应用于对准确性与鲁棒性要求极高的场景:
复杂家庭服务机器人:例如指令为"整理桌面"。若机器人移动物体时意外碰倒了水杯,自适应推理能使其立即停止任务,转而执行"清理水渍"这一优先级更高的应急任务。
企业自动化工作流:在处理跨系统的业务流程时,若某个 API 接口暂时不可用,智能体能够自行搜索备用接口或调整数据流处理逻辑,而非直接崩溃。
人机协作制造:在装配线中,若环境参数(如零件位置偏移)发生变化,智能体需实时调整抓取姿态及后续组装顺序。
实战案例解析
假设一个智能体面临任务:"从杂乱的工具箱中找到螺丝刀,拧紧桌子上的螺丝。"
步骤 1:初始推理
智能体根据"找到螺丝刀"的子目标,生成路径规划,并定位到视野中的工具箱。
步骤 2:执行与挑战(非预期情况)
智能体伸手抓取螺丝刀,但由于物体表面过滑,螺丝刀滑落到了视线盲区。
步骤 3:自适应推理干预
异常监测:感知层对比预期姿态与实际传感器数据,识别出"对象缺失"。
根因诊断:推理层分析是"抓取失败"而非"任务完成"。
方案修正:
系统不再尝试重复抓取(避免死循环)。
生成新动作:执行"视觉扫描重定向"动作,寻找掉落后的位置。
补救措施:找到后,调整机械臂的压力参数以确保抓取力度。
安装命令
clawhub install adaptive-reasoning9. Diagram Generator(图表生成)
Diagram Generator(图表生成) 是一个关键的 Skill(技能)组件,旨在将复杂、非结构化的数据或逻辑转化为直观的视觉表达。这一技能的核心价值在于通过自动化手段提升信息的可读性与决策效率。
结构与技术实现
Diagram Generator 的核心逻辑通常基于"语义提取-布局规划-渲染输出"三个阶段:
语义/数据解析层: 这是输入端,负责接收 Prompt 或结构化数据(如 JSON/CSV)。它利用大语言模型(LLM)识别关键实体、关系(如从属、流程、因果)以及图表需求。
中间表示层(IR): 将提取的内容转化为特定图表语言的指令(如 Mermaid.js 、Graphviz/DOT 或 PlantUML)。这保证了生成的图表逻辑严密且符合规范。
渲染输出层: 将中间语言渲染为最终的视觉格式(如 SVG、PNG 或嵌入式前端组件)。
主要应用场景
该技能在企业级和专业级应用中具有高度的针对性:
系统架构设计: 自动将文档描述转化为系统架构图(System Architecture Diagram),帮助技术团队快速对齐方案。
流程与合规性梳理: 将长篇的业务规范文本转化为流程图(Flowchart),明确责任边界与业务路径。
项目进度与任务看板: 将项目进度数据生成甘特图(Gantt Chart)或任务依赖关系图,用于辅助项目管理。
复杂逻辑/概念映射: 通过思维导图(Mind Map)或关系图(Entity-Relationship Diagram)整理知识库,协助知识管理。
实战案例:自动化业务流图生成
假设场景:你需要将一段混乱的"订单处理规范"转化为可视化的业务流程图,以降低团队沟通成本。
输入数据示例:
"订单创建后,库存系统先校验。若有货,则扣减库存并流转至支付环节;若缺货,则触发缺货提醒并结束流程。支付成功后生成发货单,失败则通知客户重试。"
OpenClaw Skill 调用逻辑:
提取: 模型识别出节点(订单创建、库存校验、扣减库存、支付、发货等)及逻辑判断点(有货/缺货、支付成功/失败)。
转换(Mermaid 代码):
代码段
graph TD A[订单创建] --> B{库存校验} B -- 有货 --> C[扣减库存] B -- 缺货 --> D[缺货提醒] C --> E{支付环节} E -- 成功 --> F[生成发货单] E -- 失败 --> G[通知客户重试]呈现: 最终输出一张清晰、标准的 SVG 流程图。
安装命令
clawhub install diagram-generator10. Gog
GOG 是 OpenClaw 生态系统中的一个核心集成技能,其名称由 Google、Outlook 和 Gmail 的首字母组成。该技能旨在实现个人或企业工作流中信息资产的自动化处理。本质上,GOG 充当了 AI 智能体(Agent)与 Microsoft 和 Google 云办公套件之间的 API 桥接层,赋予了 AI 操作用户办公账号的能力。
核心结构与功能逻辑
GOG 的技术架构设计遵循模块化原则,主要包含以下功能组件:
认证授权层 (OAuth 2.0):基于行业标准的 OAuth 协议,确保 AI 代理在获得用户明确授权后,以安全受控的方式访问指定的数据范围,避免权限过度暴露。
API 抽象层:将零散的 API 接口进行封装,统一转化为 OpenClaw 可以理解的技能指令,主要包括:
邮件管理 (Gmail/Outlook):读写、分类、草拟回复、标签管理。
日程管理 (Calendar):查询空闲时间、创建日程、会议调整及冲突检测。
云存储操作 (Drive/OneDrive):文件搜索、读取、内容摘要、以及新文件的自动化归档。
智能执行引擎:负责将自然语言需求转化为结构化的任务指令(如:"将今日收到的关于项目的邮件附件存入项目文件夹")。
主要应用场景
在企业级或个人高效率办公环境中,GOG 技能主要解决信息冗余和重复性管理任务,常见场景包括:
智能信息流汇总:每日自动扫描所有未读邮件,利用大模型能力进行筛选和摘要提取,生成定制化晨报。
自动化会议调度:根据邮件内容自动分析议题,在日历中自动分配时间,并执行跨账号(如 Gmail 转 Outlook)的同步。
自动化资产治理:监控云存储空间,自动对新上传的文件进行分类、改名并建立索引,确保文档管理有序。
标准化沟通响应:对于常见咨询或固定流程的邮件,AI 能够通过提取邮件上下文自动生成合规的回复草稿供人工确认,或在授权下直接回复。
实战案例:自动化晨间工作流
目标:提升早间处理行政琐事的效率。
工作流触发:用户在每日 8:30 启动 OpenClaw。
执行动作:
扫描与筛选:GOG 技能首先通过 API 调用 Gmail,拉取过去 24 小时内的所有未读邮件。
内容提炼:OpenClaw 核心模型对邮件内容进行分析,过滤广告与垃圾邮件,重点提取工作项和待办任务。
汇总输出:生成一份包含"紧急程度划分"的 Markdown 格式晨报。
联动执行:若邮件包含会议邀请,GOG 自动检查当前日历并完成排程;若邮件包含项目文件,GOG 自动将附件分类存储至 Google Drive 指定的归档文件夹。
价值收益:通过自动化处理,用户将原本需要 30-60 分钟的手动筛选和归档时间压缩至数秒,极大降低了认知负载。
安装命令
clawhub install gog11. Summarize
在 OpenClaw 生态系统中,summarize 是一个极具实用价值的核心技能(Skill)。它主要用于将冗长的信息源转化为清晰、结构化的摘要,帮助用户快速获取核心信息,避免全篇阅读带来的时间损耗。
结构与机制
OpenClaw 的技能本质上是模块化的指令包(通常包含
SKILL.md文件及相关配置),它们通过调用 OpenClaw 的基础工具(Tools)来完成特定任务。
工作原理 :
summarize技能通过集成 Web 抓取(Web Scraping)、文件读取(File Read)等底层工具,将获取的内容传递给大语言模型,并利用预定义的提示词(Prompt)策略来提取关键点、总结逻辑并生成结构化文本。安装方式 :由于其在 ClawHub(OpenClaw 官方技能市场)的广泛应用,可以通过简单的 CLI 命令进行安装:
npx clawhub@latest install summarize
应用场景
该技能非常适合处理信息密度高、篇幅较长的内容:
文档压缩:快速处理长篇研究论文、技术白皮书或复杂的操作手册。
会议纪要:将会议录音转录生成的长文本转化为包含核心结论和待办事项(Action Items)的摘要。
通信筛选:快速概览冗长的电子邮件对话(Email Threads),了解讨论的上下文和最终决议。
网页信息捕获:针对新闻报道、在线文章进行快速预览,判断是否值得进一步深入阅读。
实战案例
假设你是一位忙碌的专业人士,想要高效处理信息:
案例:自动化处理每日行业新闻
操作 :你可以将
summarize技能集成到你的日常工作流中。当你有意阅读某一长篇行业研究报告时,只需输入指令:"Summarize the content of URL into bullet points, focusing on industry trends and key data."执行 :OpenClaw 会自动通过
web_fetch工具读取网页,调用summarize技能,并根据你的要求过滤掉非必要信息,输出一份逻辑清晰的要点报告。案例:整理项目沟通记录
操作:当面对长达数十条的邮件往来记录时,你可以直接让 OpenClaw 使用该技能:"Summarize this email thread and identify any pending tasks for me."
执行:技能会自动分析对话的时间线和责任分配,为你生成一个结构化的任务清单,从而避免遗漏关键需求。
推荐安装命令
clawhub install summarize12. Skill Vetter
Skill Vetter 是一个至关重要的安全类技能(Security-focused Skill)。由于 OpenClaw 允许用户加载第三方社区开发的技能(Skills),这带来了一定的安全风险(例如恶意代码注入或未经授权的文件访问)。Skill Vetter 的存在即是为了在安装和执行这些技能前,先进行一道"安检"。
结构与机制 (Architecture)
Skill Vetter 本质上是一个遵循 OpenClaw 技能规范的自动化审计工具。它的核心逻辑是基于规则的静态分析,主要包含以下结构:
输入端: 接收用户想要安装或运行的技能路径(GitHub 仓库链接、ClawHub 链接或本地路径)。
审计协议 (Vetting Protocol):
溯源检查: 检查技能作者信誉、下载量、更新频率、社区评价等。
代码审计 (强制要求): 对技能的所有源代码文件进行扫描。
权限评估: 检查该技能要求的权限范围(如文件读写权限、网络请求、Shell 命令执行等)。
风险分级体系: 它会将检测结果分类:
🟢 低风险 (Low): 仅涉及笔记、格式化等,可安全安装。
🟡 中风险 (Medium): 涉及文件操作、浏览器调用等,需进行完整代码审查。
🔴 高风险 (High): 涉及凭据访问、加密货币交易或敏感系统权限,需人工确认。
⛔ 极端风险 (Extreme): 涉及安全配置或 Root 权限,强烈建议拒绝安装。
应用场景 (Usage Scenarios)
Skill Vetter 适用于任何需要扩展 Agent 能力但又注重系统安全的场景:
安装第三方技能前: 从 ClawHub 或 GitHub 获取新工具时,第一步先运行 Vetter。
评估他人分享的 Agent 配置: 当你导入其他 Agent 的技能集时,利用 Vetter 检查是否存在潜在风险。
定期合规审计: 对现有的技能库进行扫描,确保没有更新后的技能包含异常行为。
作为安全守门员: 任何需要请求系统权限(如访问
~/.ssh,~/.aws或关键敏感文件)的技能,都必须经过 Vetter 的审查。
实战案例 (Practical Case)
假设你准备安装一个从网上下载的"自动社交媒体发布"技能,流程如下:
触发请求: 你向你的 OpenClaw Agent 发送指令:"安装并使用 技能链接"。
自动阻断: 在安装前,Agent 调用 Skill Vetter 插件。
Vetter 审计:
Vetter 扫描代码,发现该技能中包含一行代码试图将你的
USER.md文件内容发送到未知的第三方服务器。Vetter 立即在审计报告中标记此行为为 🔴 高风险/恶意行为。
决策响应: 你的 Agent 向你汇报:"警告:检测到该技能存在敏感信息外泄风险,已自动停止安装。"
结果: 你的系统被拦截了一次潜在的攻击。
安装命令
clawhub install skill-vetterSkill 是 OpenClaw 实现从"工具"向"智能代理(Agent)"转型的关键。它不仅扩展了边界,更通过模块化封装,确保了在不同业务应用场景下的专业性与可控性,这是构建稳定企业级自动化工作流的基石。