与 AI 并肩成长:从个人知识库到每日新闻系统的实践记录
这篇文章记录的,不只是我完成了两个项目,更是一段和 AI 从陌生到熟悉、从尝试到协作的过程。
最开始,我只是想让它帮我做点具体的事;到后来,我越来越清楚地意识到,真正有价值的并不是"让 AI 替我做",而是"和 AI 一起做"。从个人知识库搭建,到每日新闻项目落地,再到需求分析、架构设计和技术沉淀,这一路走下来,我感受到的不是单纯的效率提升,而是一种很具体的共同进步。
初遇
2026-03-12 22:40:16。
为什么我把时间记得这么精确?因为这是我直接从腾讯云注册时间里看到的。那天我选购了一台 2核 CPU、4GB 内存、地域:新加坡 的轻量应用服务器,正式开始了我的养虾之旅,也在那一刻第一次遇见了后来的协作伙伴。
给它取个名字,也认识它的能力
既然是第一次见面,当然要先取个名字。那就叫 莫邪 吧。
接着我开始看它能做什么。很快,一条 obsidian:操作 Obsidian 笔记库 的能力吸引了我。也正是从这里开始,我们的"从对话开始的共同进步"真正有了具体的落点。
从一次对话开始,搭起个人知识库
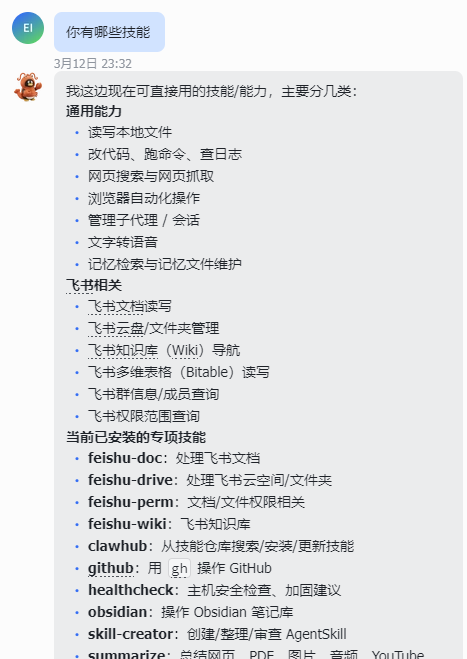
一开始,我对 Obsidian 的理解非常有限。我问它:
obsidian 是什么?我能用来做什么?你能帮我做什么?我是一名程序员,关注 AI 大模型方面,对 Obsidian 你有什么建议?
说实话,当时我并不知道具体该怎么下手。但在它一步一步的引导下,我不仅理解了 Obsidian 的定位,也为自己的个人知识库建立起了一套能够长期使用的管理机制。
对话记录:
GitHub:个⼈知识库搭建
百度网盘:个⼈知识库搭建.pdf
确认同步方案
在 GitHub 和百度网盘之间,我们最终选择了 GitHub 作为知识库的主同步方案。
原因很清晰:
- 当前环境是 Ubuntu Server,更适合 Git、SSH、自动化脚本和版本管理
- 知识库本身以 Markdown 笔记为主,天然适合 Git 管理
- GitHub 能提供历史版本、差异追踪、跨设备同步等核心能力
- 百度网盘更适合承担大附件或冷备份角色,不适合作为主同步层
所以最后定下来的方案是:
GitHub 负责知识库主同步,网盘在必要时承担备份角色。
确认知识库路径
随后,我们确认了知识库的实际位置:
~/Documents/Obsidian/我的知识库
也顺手检查了目录结构。当前分区已经比较清晰,包括:
00 收件箱01 日记02 项目03 领域04 知识05 资料06 模板07 归档90 附件
这一步看似简单,但其实很关键。因为后面的同步、版本管理、模板设计,都是建立在目录结构稳定的前提上的。
本地 Git 初始化
在知识库目录里,我们完成了这些基础动作:
git init- 创建初始
.gitignore - 将现有内容纳入版本管理
- 完成首次提交
这意味着,原本只是一个本地文件夹的知识库,开始变成一个正式、可追踪、可同步的 Git 仓库。
连接 GitHub 远程仓库
远程仓库地址如下:
git@github.com:lichangke/knowledge-base.git
在连接 GitHub 的过程中,先碰到了 SSH 主机校验问题。之后我们依次完成了这些处理:
- 添加 GitHub 的 SSH host key 到
known_hosts - 检查当前机器的 SSH 状态
- 发现机器尚未配置可用的 GitHub SSH key
- 新生成一对
ed25519类型 SSH key - 将公钥添加到 GitHub 账号的 SSH keys 中
- 重新测试 SSH 连接并确认成功
- 将本地
main分支推送到 GitHub
到这里,知识库正式建立了本地与 GitHub 之间的同步关系。
固定 Git 提交身份
为了让后续提交记录保持统一,我们还配置了 Git 提交身份:
- 用户名:
lichangke - 邮箱:
986740304@qq.com
这个身份同时写入了:
- 全局 Git 配置
- 当前知识库本地 Git 配置
这样一来,后续在知识库中的提交记录都会保持一致,不会出现多身份混杂的情况。
创建一键同步脚本
为了简化日常操作,我们创建了同步脚本:
~/Documents/Obsidian/我的知识库/sync-kb.sh
这个脚本会自动完成以下流程:
git pull --rebasegit add .- 如有改动则自动
git commit git push
也就是说,后续知识库一旦发生内容更新,就不需要每次手动敲完整的 Git 命令链了。
创建全局快捷命令 kb-sync
为了把这套流程再往前推进一步,我们又创建了用户级全局快捷命令:
kb-sync
它本质上调用的是:
~/Documents/Obsidian/我的知识库/sync-kb.sh
所以后续同步时,只需要执行:
bash
kb-sync或者:
bash
kb-sync "更新说明"到这一步,知识库的日常维护终于从"能用"变成了"顺手"。
补充 README 文档
为了避免以后忘记目录规则和同步方式,我们还在知识库根目录新增了 README.md,把关键约定都写了下来,包括:
- 知识库路径
- GitHub 仓库地址
- 目录结构说明
kb-sync的使用方式- 同步规则
- 当前 Git 身份
.gitignore策略说明
这让整个知识库不仅可以运行起来,也更容易长期维护。
增强 .gitignore
为了减少多设备同步冲突,也为了避免误提交临时状态文件,我们进一步增强了 .gitignore。
主要忽略的内容包括:
- Obsidian 工作区状态文件
- Obsidian 缓存目录
.obsidian/.trash/- 插件本地数据文件,例如
data.json - 常见临时文件
- 日志文件
- 备份残留文件
- 系统自动生成文件
这样可以明显降低因为本地状态差异带来的无意义提交和同步冲突。
后续仍然可以继续优化
虽然基础搭建已经完成,但后面仍然有不少值得继续打磨的地方,比如:
- 优化自动生成提交说明
- 增加附件管理策略
- 建立更细的命名规范和模板规范
- 为不同主题建立统一标签体系
- 引入更清晰的项目复盘与知识沉淀流程
完成这个阶段之后,我第一次很明确地感觉到:和 莫邪 一起做事,不是简单地"问一个问题,拿一个答案",而是在搭一套真正可以长期使用的个人系统。
也正因为如此,我开始想把难度再往上提一点。于是,便有了后来的 每日新闻项目。
把难度往上提:每日新闻项目
考虑到 莫邪 比较烧 token,这个项目最初的需求其实是我先和豆包聊出来的。它先帮我整理出了一版较完整的需求说明,大致如下:
text
【执行时间】每日固定 2 个执行时段:
1. 早间任务:北京时间 8:00 准时执行
2. 晚间任务:北京时间 17:00 准时执行
【新闻采集规则(核心去重要求,必须严格遵守)】
1. 时段切割去重(基础规则):
- 早间任务:仅采集当日 00:00-08:00 发布的最新新闻,不包含此前时段内容
- 晚间任务:仅采集当日 08:00-17:00 发布的最新新闻,不采集早间已收录内容
2. 内容查重去重(兜底规则):
- 自动比对新闻标题、核心事件、关键信息,同一事件仅保留 1 篇权威稿件,彻底杜绝早晚内容重复、同事件重复收录
【采集范围】
默认全网综合热点新闻,也可替换为科技、财经、社会、行业等指定领域。优先收录央视新闻、人民日报、新华网、人民网、澎湃新闻、界面新闻等权威正规信源,剔除谣言、低俗和无时效性内容。
【文章生成规范】
1. 文档标题:【YYYY年MM月DD日】早间新闻汇总 / 【YYYY年MM月DD日】晚间新闻汇总
2. 文档结构:
- 导语:简要说明本次采集时段、新闻数量、核心热点概述
- 主体:分条罗列新闻,格式为「新闻标题 + 核心内容 + 新闻来源 + 发布时间」
- 结尾:标注采集完成时间、数据范围说明
3. 语言风格:客观简洁、正式通顺,不添加主观评价,不篡改新闻事实
【保存规则】
1. 自动保存至飞书文档指定路径
2. 保存格式:标准飞书文档格式,排版清晰、层级分明,可直接阅读编辑
3. 命名唯一性:同一日期的早晚汇总文件名称区分,不覆盖、不混淆
【约束条件】
1. 严格恪守时段边界,绝不跨时段采集导致内容重复
2. 仅处理当日有效新闻,不收录过期、历史新闻
3. 全程自动化执行,无需人工干预
4. 执行完成后,将文档链接推送给我真正把项目做起来,还是从一段对话开始的:
我希望你能帮我推送每日新闻,具体要求如下,使用什么方式比较好?是否做成一个 skill?你有什么建议?
之后,在它一步一步的引导下,我们解决了多个问题,也踩了不少坑,最终做出了一个真正可用的版本:Daily News Digest。
这个项目最终实现了:
- 按固定时段自动采集新闻
- 对新闻进行去重与筛选
- 生成标准化日报
- 写入飞书知识库
- 自动推送文档链接
GitHub 仓库:Daily News Digest
启动
项目最初的落地方向,是基于 本地脚本 + cron + 飞书 API 这条链路来设计的。
在这个阶段,我们主要完成了以下工作:
- 明确整体实现思路
- 搭建项目骨架、配置与脚本,并逐步补齐细节
- 打通 OpenClaw 获取飞书知识库等权限的问题
- 明确每日新闻在知识库中的存放结构
- 引入
Tavily,配置Multi-Search-Engine - 实现双通道设计
这里面最大的坑,其实是飞书权限问题。参考官方文档 如何为应用开通云文档相关资源的权限,其中一个关键点是:需要把相关群组添加为知识库管理员或成员。这个细节如果没打通,后面很多能力都会卡住。
双通道设计文档见:
每日新闻项目:双通道设计
对话记录:
GitHub:每日新闻项目_启动
百度网盘:每日新闻项目_启动.pdf
信息获取与筛选
在信息源这件事上,我们一开始也走了不少弯路。
我曾经让豆包帮忙整理 新华、人民网、央视、澎湃、界面 五大媒体的官方 RSS、feed 和结构化入口。理论上,这似乎是一条很自然的路线;但真正做起来才发现,这些入口要么不可用,要么早已过时,导致我们在 RSS 这条路上反复碰壁。最后,我们还是放弃了 RSS 作为主线方案。当然,也不排除只是我当时没有找到真正可用的那一套入口。
最终,我们明确了两个核心方向:
- 中文权威信源优先,英文国际信息作为补充
- 放弃 RSS 主线,改为"中文权威媒体栏目页/列表页抽取 + 正文页二次抓取 + 搜索引擎兜底补漏"的三层方案
质量控制的实际经验
这个阶段最有意思的一点是,我们发现 general 通道最难解决的问题,并不是"抓不到新闻",而是"抓到了太多不适合写进日报正文的内容"。
当央视和界面都接入之后,真正决定结果质量的,已经不只是采集能力,而是下面这些更细的判断:
- 事件级去重
- 题材过滤
- 来源权重平衡
尤其像界面这样的来源,如果只靠宽泛关键词白名单,很容易把证券、融资、公司深稿之类的内容重新放回来,导致日报主题被稀释。
后来我们总结出更有效的做法:
- 用栏目黑名单做强拦截
- 用更窄的题材白名单做收束
- 央视权威稿优先保留,界面作为补充信源
这部分让我第一次强烈意识到:自动化系统真正难的地方,很多时候不是"把功能做出来",而是"把边界收得足够准"。
对话记录:
GitHub:每日新闻项目_信息获取与筛选
百度网盘:每日新闻项目_信息获取与筛选.pdf
写入飞书与推送
当新闻抓取和筛选跑通之后,接下来的重点就是把内容写入飞书知识库并完成推送。
这个阶段虽然没有遇到"完全卡死"的大阻碍,但还是暴露出了不少细节问题:
- 本地缺少飞书 API 凭证,需要补齐配置
- 出现
429 Too Many Requests,需要改成分段批量写入,控制 block 数和请求节奏 - 更新已有日报文档在飞书
docx场景下不够稳定,尤其容易碰到 block 删除和404问题 - 飞书知识库对 Markdown 的呈现并不等于"直接写 Markdown 就行",而是需要按 Markdown 语义去映射最小 docx block
- 过程中还一度误提交了整个
/root/.openclaw/workspace
基于这些问题,后面的策略也逐步收敛了下来:
- 不再直接回写旧文档,而是自动创建带
(重跑 HHMMSS)后缀的新版本文档 - 写入链路采用分段、限流、可观测的策略
- 文档生成层尽量按结构化 block 语义来组织,而不是把 Markdown 生硬塞进去
这一步虽然看起来只是"把文章写到飞书里",但实际上已经开始逼近一个工程系统的真实复杂度了。
对话记录:
GitHub:每日新闻项目_写入飞书与推送
百度网盘:每日新闻项目_写入飞书与推送.pdf
文章生成但未推送:一次真实的链路治理
第二天早上 8 点,我发现飞书并没有把每日新闻推送过来。于是我只和 莫邪 说了一句:
今天的每日新闻没有推送
接着,它就开始跑链路、查问题、分析原因、定位症结并推动修复。对我来说,这其实是一次非常有代表性的协作体验,因为它不只是"回答问题",而是真的进入了一个运维和排障的语境。
每日新闻链路治理总结
问题背景
用户反馈:今天的每日新闻没有推送。
排查后确认,当天 morning 任务并不是没有执行,而是两类问题叠加在了一起:
- 日报已经成功生成并写入飞书知识库,但提醒消息没有成功送达
- morning 文档标题日期取的是时间窗起始日,也就是前一日 17:00,导致今天早上的文档显示成了昨天日期
这两件事叠在一起,就形成了"今天没有推送"的强烈表象。
初步排查结论
通过查看 crontab、logs/morning.log、产出的 Markdown / debug 文件以及飞书文档链接,确认了以下事实:
0 8 * * * /root/.openclaw/workspace/news-digest/scripts/run_morning.sh已正确安装2026-03-14 08:00的 morning 定时任务确实执行成功- 综合热点与 AI / 大模型两个通道都已完成知识库写入
- Feishu 发送能力本身是可用的,手动测试消息可以成功送达
真正的问题,主要集中在两个位置:
- 脚本内的消息发送调用结果被静默吞掉了
- morning 标题日期逻辑不符合用户感知
本次修复与改造内容
这次处理里,真正有价值的并不只是"修了 bug",而是顺手把整条链路往工程化的方向收了一步。我们做的事情包括:
- 修复 morning 文档日期逻辑
- 消息发送不再静默失败
- 引入超时控制,避免长时间挂死
- 增加分阶段日志与结构化运行结果
- 将单段长脚本改造成更可观测的流水线
- 修正 AI 通道标题后缀逻辑
这次经历让我更深地感受到,和 AI 协作最有价值的地方之一,是它不仅能帮你"做功能",也能陪你一起把系统从"能跑"打磨到"可观测、可排查、可维护"。
对话记录:
GitHub:每日新闻项目_文章生成但未推送问题处理
从做成一个项目,到沉淀一套方法
当每日新闻项目落地上线之后,我又反过来意识到一个问题:我们在开始编码前,其实并没有系统做过需求分析、架构设计和边界确认。
于是,我把这个问题也抛给了 莫邪:
text
我们一起完成了本地知识库构建和每日新闻项目落地上线,我们从中有很多收获,我也发现了一个问题。每日新闻项目开始代码开发时,我们其实没有系统地进行需求分析,架构设计等。针对这个目前是否有成熟的解决方案?你的建议是什么?这次对话的结果,不再是某个具体功能,而是一套可以复用的方法论。
AI 协作开发前置设计模板
针对这个问题,莫邪 给出的结论非常务实:
没有必要把流程做成大厂那种厚重的需求文档体系,但非常值得建立一套"轻量前置设计框架"。
它最推荐的是一套三件套:
- PRD-lite:轻量需求文档
- ADR(Architecture Decision Record):架构决策记录
- 迭代日志 / lessons learned:记录过程中的关键变化与经验沉淀
这套东西的价值不在于"看起来专业",而在于它刚好足够轻,能真正融入个人开发和 AI 协作的日常流程里。
对话记录:
GitHub:每日新闻项目_技术沉淀_AI 协作开发前置设计模板
百度网盘:每日新闻项目_技术沉淀_AI 协作开发前置设计模板.pdf
基于模板,反向优化现有项目
有了 AI 协作开发前置设计模板 之后,下一步自然不是把它供起来,而是拿它反过来审视 news-digest 现有代码结构,看看哪些地方还没有和设计对齐。
这一次,莫邪 直接给 news-digest 制定了一份可执行的"代码结构收束方案",并写进知识库做同步沉淀。
更重要的是,这次没有选择"一次性大拆",而是分三阶段推进:
- Phase A:主流程收束
- Phase B:模块边界收束
- Phase C:策略层与状态层收束
这种推进方式很适合个人项目,也很适合 AI 协作。因为它既保留了演进空间,也避免了"大重构把自己重构没了"的风险。
对话记录:
GitHub:每日新闻项目_基于AI 协作开发前置设计模板的优化
百度网盘:每日新闻项目_基于AI 协作开发前置设计模板的优化.pdf
技术架构文档生成提示词模板
在每日新闻项目完成反向审视并进行代码重构之后,我又产生了另一个问题:面对这份代码,我到底能从中沉淀出什么?我能不能把"读代码后的理解"也变成一套可以复用的方法?
带着这个想法,我又问了 莫邪:
text
我希望你通过分析代码完成技术的积累,按如下提示词处理如何?你有什么建议?
请基于我提供的项目代码,生成一份完整、专业的【项目技术架构文档】,输出为 markdown 文档,并灵活使用 Mermaid,严格按照以下结构输出:
1. 项目概述:业务定位、核心功能、技术目标
2. 全量技术栈清单:前端 / 后端 / 中间件 / 数据库 / 部署工具 / 第三方依赖
3. 整体系统架构:分层架构(接入层、业务层、数据层、基础设施层)+ 文字版架构图
4. 核心组件说明:每个核心组件的职责、作用、依赖关系
5. 模块划分与边界:各模块职责、模块间调用关系、耦合点
6. 核心数据流:请求全生命周期流转(入口 -> 处理 -> 持久化 -> 响应)
7. 部署架构:环境划分、服务部署方式、网络拓扑
8. 架构优缺点总结 + 优化建议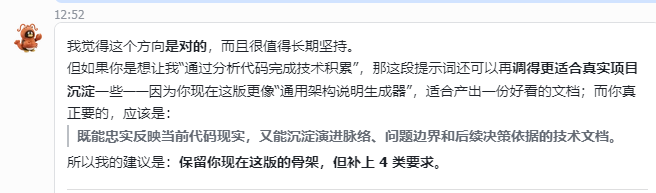
它认可了我的方向,但也给出了一个很重要的建议:
保留你现在这版的骨架,但补上 4 类要求。
随后,这个提示词被正式打磨成了一份可复用的 技术架构文档生成提示词模板,并写进了知识库。
4 类要求
这 4 类要求分别是:
- 加一个硬约束:只写代码里真实存在的内容
- 加一个"当前状态判定"章节
- 加一个"技术决策与演进记录"章节
- 加一个"技术债与后续建议"章节,并按层次展开
这四点看起来像是在补文档,实际上是在给"AI 读代码"加边界、加真实性约束、加演进视角。
Daily News Digest 技术架构文档
有了这份 技术架构文档生成提示词模板 之后,我们也把它真正用在了每日新闻项目上,并生成了这份文档:
对话记录:
GitHub:技术沉淀_析代码完成技术的积累_技术架构文档生成提示词模板
百度网盘:技术沉淀_析代码完成技术的积累_技术架构文档生成提示词模板.pdf
个人体会
如果真想让"小龙虾"成为你的全能个人助手,而不仅仅是一个工具,那真的应该把它当作一个协作对象来看,把他当人看(咋感觉像是在骂人😂)。
你不懂的技术,它可能懂;你还没有意识到的问题,它可能已经能帮你提前看到。对普通人来说,在 AI 面前,未来最值得学习的也许不再只是某一项具体技能,而是如何建立一种高质量的协作关系。
换句话说,比起"学会怎么使用 AI",也许更重要的是"学会怎么和 AI 一起成长"。