该示例为参考算法,仅作为在征程 6 上模型部署的设计参考,非量产算法
1.简介
SparseBevFusionMultitaskOE 模型是一个 bev 多任务感知模型,包含感知三大任务的检测头:sparse 动态检测头,sparse 静态元素检测头和通用障碍物检测头。整体的模型结构如下:

sparse bev 类模型主要思路是通过关键点投影回 camera 空间采样并进行预测。因此对于多任务模型来说,不同 task 之间可以共用的是 img_encoder 的 backbone 和 neck 部分,同时加入辅助分支 densedepthnet 用于辅助训练,部署时不需要。动态检测、静态要素检测和占用格预测任务可以分别抽象为三个 head:detection head(det head)、onlinemapping head(om head)和 occupancy head(occ head)。在模型的选择上,我们选取了参考算法已集成的,也是较主流的模型-sparse4d、maptr、flashocc,在征程 6 上部署的效果更好。
2.性能精度指标
注:flashocc 掉点为分辨率降低导致;sparse 动态目标检测掉点会在后续版本中优化。
地平线部署说明
sparse 多任务模型的每个 head 是基于公版模型做了优化后部署的,以下为模型相较于公版的改动点:
详细可以参考地平线开发者社区官网单任务模型的参考文档的改动说明章节:
地平线 3D 目标检测 bev_sparse 参考算法-V2.0
3.1 训练策略
3.1.1 浮点训练
(一)数据结构说明
参考算法已有的三个单任务模型都是基于 nuscenes 数据集的,它同时包含三个任务的标注数据。其中 dataset 使用 NuscenesSparseMapDataset,包含了地图相关的标注。
NuscenesSparseMapDataset 继承自 NuscenesMapDataset 和 NuscenesBevDataset,同时含有动态、静态和 occ 的标注。因此多任务模型选用 NuscenesSparseMapDataset 作为数据集,可以同时对动态、静态和 occ 任务一起监督训练;动态检测头用到了时序信息,所以 data_loader 采用了 DistStreamBatchSampler,确保数据按时序返回。
训练集和测试集的处理流程见:hat/data/datasets/nuscenes_map_dataset.py
(二)训练架构
HAT 使用的是注册机制,模型结构和参数在 config(configs/bev/bev_sparse_det_maptr_flashocc_henet_tinym_nuscenes.py)中通过 dict 定义,在 config 中构建多个 head 的 dict,然后通过配置 enable_xx_head 参数选择需要合入的任务。
Plain
det_head = dict(
type="SparseBEVOEHead",
enable_dn=True,
level_index=[2],
cls_threshold_to_reg=0.05,
instance_bank=dict(
type="MemoryBankOE",
...
)构建一个 OrderedDict,通过标识选择加入哪些模型,然后在整体 model 中,传入 task_heads。
Plain
task_heads = OrderedDict()
if enable_det_head:
task_heads["det"] = det_head
if enable_om_head:
task_heads["om"] = om_head
if enable_occ_head:
task_heads["occ"] = occ_head
model = dict(
type="SparseBevFusionMultitaskOE",
compiler_model=False,多任务的 forward 流程为遍历 dict(每个 dict 可以理解为一个 task_head),依次执行各自的 head,代码可见:hat/models/structures/sparse_multitask.py
Plain
def forward_single_head(
self, head, feature_maps, data, lidar_feature, compiler_model
):
if isinstance(head, (SparseBEVOEHead, FlashOccHead)):
return head(
feature_maps=feature_maps,
metas=data,
lidar_feature=lidar_feature,
compiler_model=compiler_model,
)注:为了兼容 lidar 融合的模型,head 中保留 lidar_feature,在不使用 lidar net 的情况下 lidar_feature=None
(三)训练策略
SparseBevFusionMultitaskOE 模型在训练上:
- SparseBevFusionMultitaskOE 模型为同源数据集,多个任务一起训练,非单独的训练某个 head。
- 模型训练时需要增加添加 BevRotation,经过在 nescenes 上验证,不添加会导致掉点。
- 训练策略复用了单任务模型 。
- 对模型配置 loss weight,根据模型表现动态的调整权重值。
3.1.2 模型量化
为量化精度保证,我们采取了 HistogramObserver 的校准方式(OE 3.7.0 版本及以后支持),精度上优于 MSEObserver。校准数据为训练数据,校准的 step 为 50,无 qat 训练。
Plain
calibration_data_loader = copy.deepcopy(data_loader)
calibration_data_loader["dataset"]["transforms"] = val_data_loader["dataset"][
"transforms"
]
calibration_batch_processor = copy.deepcopy(val_batch_processor)
calibration_step = 50
calibration_qconfig_setter = QconfigSetter(
reference_qconfig=get_qconfig( # 1. 主要用于获取 observer
# observer=(observer_v2.MSEObserver)
observer=(observer_v2.HistogramObserver)q_template 为量化配置,分为全局的配置和自定义的 ModuleNameTemplate、基于敏感度的 SensitivityTemplate 算子的配置。ModuleNameTemplate 主要作为全局量化配置和个别层的量化配置,被用于配置全局量化类型和对算子配置 int16、固定算子的 scale 操作,以上都是基于经验的。SensitivityTemplate 为敏感度的配置,它是基于 debug 结果,对敏感排行较高的算子通过 topk_or_ratio 配置 int16 算子比例。详细的使用方法可见用户手册*量化感知训练--开发指南--Qconfig 详解*章节。
在多任务时,建议先将已知的在单任务中需要 fix-scale 的层(特别是具有物理意义、范围固定的 op)做固定 scale 处理、对已知需要 int16 精度的算子配置高精度。例如动态单任务的 fix-scale 为:
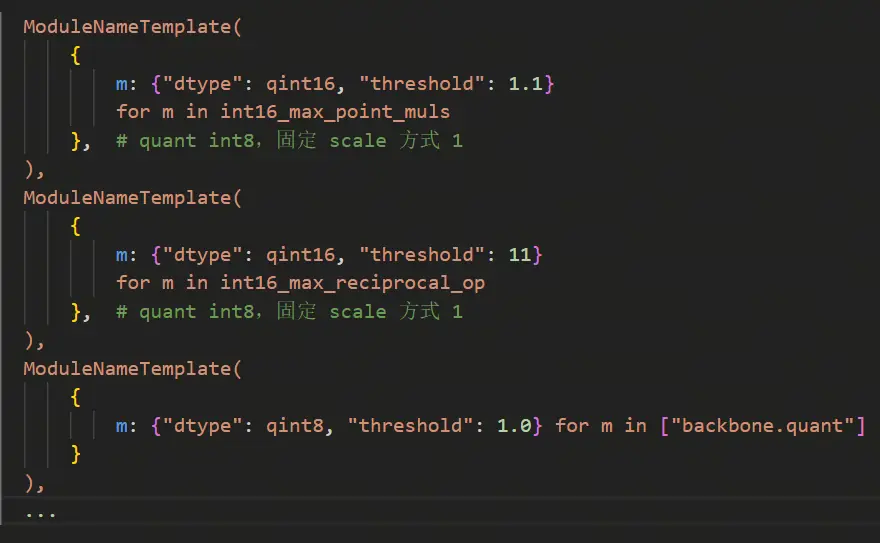
多任务时可以做复用:

模型基于 int8 的量化配置下做 calibration,若出现精度掉点问题参考用户手册中的*量化感知训练--开发指南--精度调优工具使用指南*选取 badcase 做 debug 分析,基于 debug 信息对部分算子配置更高的精度或者尝试手动处理。
多任务量化推荐流程:
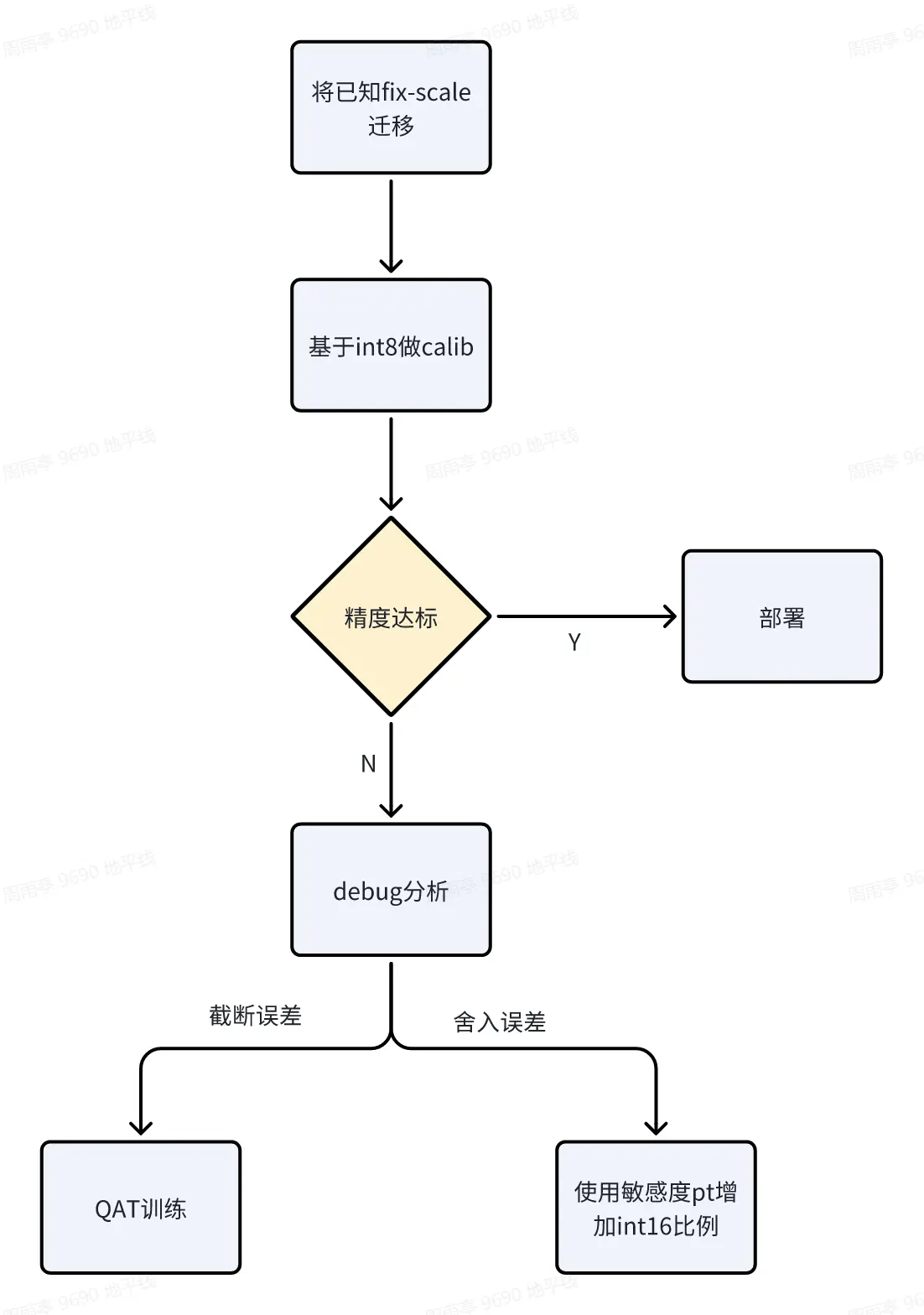
若未部署过单任务则可以按照用户手册推荐流程(*量化感知训练--开发指南--量化精度调优指南)*做部署。
4.总结与建议
4.1 部署建议
- 尝试训练时增加数据增强(BEV Rotate)提高模型的泛化能力
- 对精度较差的任务可以适当的增大 loss weight
- 量化优先尝试 HistogramObserver 校准方式
- 多任务量化时建议基于单任务的经验,对需要固定 scale 的算子做 fixscale,可以有效缩短量化周期。
本文通过对 SparseBevFusionMultitaskOE 在地平线征程 6 上量化部署的优化,使得模型在征程 6M 上得到 latency 为 28 ms 的部署性能,同时,通过 SparseBevFusionMultitaskOE 的部署经验,可以推广到其他多任务模型的部署中。