1. Redis两种持久化策略(RDB和AOF),对比一下优缺点,怎么选型?
一、RDB(Redis DataBase)
原理 :定时 / 触发条件满足时,生成全量内存快照 ,保存为 .rdb 二进制文件。
优点
- 文件小,备份 / 恢复速度极快,适合灾难恢复。
- 对性能影响小,主线程只 fork 子进程做持久化。
- 适合冷备、全量备份。
缺点
- 丢数据风险大:两次快照之间宕机,数据会丢失。
- fork 大内存实例时,可能瞬间阻塞主线程。
- 不适合实时高可靠场景。
二、AOF(Append Only File)
原理 :把每一条写命令 以日志形式追加到 .aof 文件,重启时重放命令恢复数据。
优点
- 数据可靠性高 ,可配置
everysec每秒刷盘,最多丢 1 秒数据。 - 日志追加,写入稳定,不会有大量阻塞。
- 支持 AOF 重写,避免文件无限膨胀。
缺点
- 文件通常比 RDB 大很多,恢复速度慢。
- 对写入性能略有损耗。
- 备份、传输不如 RDB 方便。
三、核心对比
表格
| 对比项 | RDB | AOF |
|---|---|---|
| 数据安全性 | 较低,可能丢大量数据 | 高,最多丢 1 秒数据 |
| 恢复速度 | 极快 | 较慢 |
| 文件大小 | 小 | 大 |
| 性能影响 | 小(fork 时可能卡顿) | 略高 |
| 适用场景 | 全量备份、容灾、大数据量 | 高可靠、核心业务、少丢数 |
四、如何选型(生产最佳实践)
1. 选 RDB
- 数据允许丢一部分(如缓存、非核心统计)
- 数据量大、追求恢复速度
- 做定时冷备
2. 选 AOF
- 核心业务、不能丢数据
- 对数据一致性要求高
- 数据量不是特别巨大
3. 生产推荐方案(最稳)
- RDB + AOF 同时开启
- AOF 保证数据不丢
- RDB 做全量备份 + 快速恢复
- 配置建议:
- AOF:
appendfsync everysec - RDB:按业务定时备份(如每天 / 每 6 小时)
- AOF:
Redis 持久化最佳配置(生产可用)
以下是兼顾数据安全性(AOF) 和恢复效率(RDB) 的配置方案,适配绝大多数生产场景。
完整配置片段
# ===================== RDB 配置 =====================
# 触发快照的条件(可根据业务调整)
# 格式:save <秒数> <修改键数>
save 900 1 # 900秒内至少1个键修改,触发快照
save 300 10 # 300秒内至少10个键修改,触发快照
save 60 10000 # 60秒内至少10000个键修改,触发快照
# 禁用RDB(如果纯用AOF,可设为 save "")
# save ""
# 快照出错时,是否停止Redis写入(生产建议yes,避免数据不一致)
stop-writes-on-bgsave-error yes
# 是否压缩RDB文件(yes节省空间,no提升性能;建议yes)
rdbcompression yes
# 校验RDB文件完整性(建议yes,轻微性能损耗)
rdbchecksum yes
# RDB文件名
dbfilename dump.rdb
# RDB文件保存路径(建议单独目录,避免权限问题)
dir /var/lib/redis
# ===================== AOF 配置 =====================
# 开启AOF(核心:保证数据少丢失)
appendonly yes
# AOF文件名
appendfilename "appendonly.aof"
# AOF刷盘策略(生产首选everysec,平衡性能和安全性)
# always:每次写命令都刷盘,最安全但性能最差
# everysec:每秒刷盘一次,最多丢1秒数据(推荐)
# no:交给操作系统刷盘,不可控
appendfsync everysec
# AOF重写时,是否暂停刷盘(建议no,避免丢数据)
no-appendfsync-on-rewrite no
# AOF重写触发条件(文件增长比例 + 最小文件大小)
auto-aof-rewrite-percentage 100 # 文件大小增长100%触发重写
auto-aof-rewrite-min-size 64mb # 文件至少64MB才触发重写
# AOF文件损坏时的修复策略(建议yes,启动时自动修复)
aof-load-truncated yes
# 混合持久化(Redis 4.0+支持,核心优化!)
# 重写后的AOF文件包含:RDB头部(全量数据) + AOF尾部(增量命令)
# 兼顾RDB恢复快 + AOF数据新的优点
aof-use-rdb-preamble yes关键配置解释
1. 混合持久化(核心优化)
aof-use-rdb-preamble yes 是 Redis 4.0+ 的核心特性:
- 重写后的 AOF 文件前半部分是 RDB 格式(全量数据,恢复快),后半部分是 AOF 格式(增量命令,数据新)。
- 解决了纯 AOF 恢复慢、纯 RDB 丢数据多的问题。
2. 刷盘策略
appendfsync everysec:
- 性能:QPS 基本不受影响(相比 always 提升 10 倍以上)。
- 安全性:最多丢失 1 秒数据,满足 99% 的业务场景。
3. RDB 触发条件
默认的 save 900 1/300 10/60 10000 是平衡 "快照频率" 和 "性能" 的经典配置:
- 低频修改场景(如 900 秒 1 次):避免频繁 fork 子进程。
- 高频修改场景(如 60 秒 1 万次):保证快照不会太旧。
配置生效方式
-
修改 Redis 配置文件(如
/etc/redis/redis.conf)。 -
重启 Redis 生效:
# 停止Redis systemctl stop redis # 启动Redis systemctl start redis # 验证配置(查看持久化状态) redis-cli config get appendonly redis-cli config get save
特殊场景调整建议
| 场景 | 调整方案 |
|---|---|
| 纯缓存(可丢数据) | 关闭 AOF(appendonly no),仅保留 RDB,提升性能。 |
| 核心金融数据 | AOF 设为 always + RDB 定时备份 + 主从复制。 |
| 超大内存实例(>32G) | 降低 RDB 触发频率 + 开启 AOF 混合持久化 + 避免高峰时段 fork。 |
总结
- 生产首选:开启 AOF(everysec)+ RDB 定时快照 + 混合持久化,兼顾性能和数据安全。
- 核心配置 :
appendonly yes(开启 AOF)、aof-use-rdb-preamble yes(混合持久化)、appendfsync everysec(刷盘策略)。 - 特殊场景:纯缓存可仅用 RDB,超高可靠性场景用 AOF 的 always 模式。
2.Redis 3 种集群模式:主从、哨兵、集群(原理 + 数据同步)
一、主从模式(Master-Slave)
1. 作用
- 读写分离:主写、从读
- 数据备份:从库是主库的副本
2. 工作原理
- 只有 Master 接受写操作(增删改)
- Slave 只负责读操作
- Slave 启动时主动连接 Master,请求同步数据
- Master 挂掉后:不会自动选主,需要手动切换
3. 数据同步机制
分为 全量同步 和 增量同步
1)全量同步(初次 / 重新连接)
- Slave 发送
PSYNC - Master 执行
BGSAVE生成 RDB - Master 把 RDB 发给 Slave
- Slave 清空数据,加载 RDB
- 期间 Master 新写命令放入 复制缓冲区
- 最后把缓冲区命令发给 Slave
2)增量同步(网络断连恢复)
- Master 维护 复制偏移量 + 复制积压缓冲区
- 断连后重新连接,Slave 带上偏移量
- 若偏移量还在缓冲区 → 只补发缺失命令
- 否则重新全量同步
二、哨兵模式(Sentinel)
1. 作用
- 主从自动故障转移
- 主节点挂了自动选新主
- 提供集群状态监控 + 通知
2. 工作原理
- Sentinel 是独立进程,不存数据
- 监控所有 Master、Slave
- 多个 Sentinel 互相通信,通过 投票 判断主节点客观下线
- 下线后:
- 从 Slave 里选新 Master(优先级、偏移量、运行 ID)
- 让其他 Slave 挂到新 Master
- 更新配置,通知客户端新主地址
3. 数据同步
和主从模式完全一样 ,哨兵只负责故障切换,不参与数据同步。
三、集群模式(Redis Cluster)
1. 作用
- 分布式存储:数据分片
- 水平扩容
- 自带高可用,不需要哨兵
2. 工作原理
- 把所有数据映射到 16384 个哈希槽(slot)
- 每个主节点负责一部分槽
- 客户端计算
CRC16(key) % 16384定位槽 → 定位节点 - 每个主节点可以有从节点,主挂了从自动顶上
3. 数据同步
- 分片内同步同主从模式:主写 → 从复制
- 槽迁移同步 扩容 / 缩容时:
- 把对应槽的 key 从旧节点迁移到新节点
- 迁移期间可访问,迁移完成后切换槽归属
一句话总结
- 主从 :读写分离、数据备份,不自动故障转移
- 哨兵 :给主从加自动高可用,数据同步不变
- 集群 :分片 + 高可用,分布式存储,16384 槽
3.接口幂等性怎么保证,尤其是高并发场景下的方案?
接口幂等性设计(含高并发方案)
幂等性 :同一个请求执行一次 和多次,结果完全一致,不会重复扣款、重复下单、重复插入。
一、常见天然幂等 / 非幂等接口
- 天然幂等:GET、PUT、DELETE(按唯一 ID)
- 非幂等高风险:POST(下单、支付、提交表单)
二、通用幂等方案(按推荐优先级)
1. 唯一 ID + 分布式锁(高并发首选)
流程:
- 前端 / 调用方生成全局唯一 ID(requestId/orderId)
- 接口先加分布式锁(Redis Redlock/Redisson)
- 执行业务
- 执行完成释放锁
高并发优化:
- 锁粒度:只锁用户 + 业务 ID,不锁全表
- 锁超时:合理设置,避免死锁
- 先查再锁:先判断是否已处理,减少锁竞争
2. 数据库唯一约束(最简单可靠)
- 给
order_id、request_id建唯一索引 - 重复请求插入会报唯一键冲突,直接返回成功
- 适合:插入类接口、简单业务
3. 状态机 / 状态流转(业务层幂等)
- 订单状态:待支付 → 支付中 → 已支付
- 只有前置状态满足才允许执行
- 重复请求:状态不匹配,直接拒绝
4. Token 机制(前端 + 后端配合)
- 前端先请求获取token
- 提交时带上 token
- 后端用Redis+Lua原子判断并删除 token
- 高并发优势:Lua 原子操作,无 race condition
5. 请求参数哈希 + 缓存
- 对参数做 MD5/SHA,存 Redis:
hash: 处理中/已完成 - 重复请求直接返回结果
- 适合:参数固定、无唯一 ID 场景
三、高并发下的核心要点
- 减少数据库压力
- 用Redis做前置判断,不要直接查 DB
- 原子操作
- 用 Redis Lua / Redisson 锁,避免 "查 + 判 + 写" 并发问题
- 异步化 + 队列削峰
- 高并发写丢到 MQ,单线程消费天然幂等
- 兜底策略
- 唯一索引兜底
- 定时任务校验 / 对账 / 修正数据
四、落地推荐组合(生产常用)
- 下单 / 支付 :全局唯一 ID + Redis 分布式锁 + 状态机 + 唯一索引
- 表单提交 :Token + Redis Lua
- 消息队列消费 :消息 ID + 去重表 / Redis
五、一句话总结
高并发下保证幂等:先通过 Redis 做前置去重 + 分布式锁防并发,再用数据库唯一索引兜底,配合状态机做业务校验。
Java 高并发幂等性实现(Redis + Lua 方案)
以下是生产级可直接落地的代码,包含 Token 机制 和 分布式锁 两种核心实现,适配高并发场景(如秒杀、下单、支付)。
前置依赖
先在 pom.xml 引入 Redis 客户端(推荐 Redisson,自带分布式锁 + Lua 原子操作):
xml
<!-- Redisson 分布式锁 + Redis 客户端 -->
<dependency>
<groupId>org.redisson</groupId>
<artifactId>redisson-spring-boot-starter</artifactId>
<version>3.23.3</version>
</dependency>
<!-- Spring Redis 基础依赖 -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis</artifactId>
</dependency>方案 1:Token 机制(表单 / 下单提交首选)
核心思路
- 前端先获取一次性 Token(存入 Redis,设置过期)
- 提交请求时携带 Token
- 后端用 Lua 脚本原子性校验并删除 Token(避免并发重复提交)
代码实现
1. 幂等工具类(核心 Lua 脚本)
import org.redisson.api.RBucket;
import org.redisson.api.RedissonClient;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.data.redis.core.script.DefaultRedisScript;
import org.springframework.data.redis.core.script.RedisScript;
import org.springframework.stereotype.Component;
import java.util.Collections;
import java.util.UUID;
import java.util.concurrent.TimeUnit;
@Component
public class IdempotentUtil {
@Autowired
private RedissonClient redissonClient;
// Token 前缀
private static final String TOKEN_PREFIX = "idempotent:token:";
// Token 过期时间(30分钟,可根据业务调整)
private static final long TOKEN_EXPIRE = 30L;
/**
* 生成幂等 Token(前端调用)
*/
public String generateToken() {
String token = UUID.randomUUID().toString().replace("-", "");
String key = TOKEN_PREFIX + token;
// 存入 Redis,设置过期时间
RBucket<String> bucket = redissonClient.getBucket(key);
bucket.set("VALID", TOKEN_EXPIRE, TimeUnit.MINUTES);
return token;
}
/**
* 校验并删除 Token(原子操作,核心)
* @return true: 校验通过(首次提交) false: 重复提交
*/
public boolean validateToken(String token) {
if (token == null || token.isEmpty()) {
return false;
}
String key = TOKEN_PREFIX + token;
// Lua 脚本:原子判断并删除(避免查+删的并发问题)
String luaScript = "if redis.call('exists', KEYS[1]) == 1 then " +
"return redis.call('del', KEYS[1]) " +
"else " +
"return 0 " +
"end";
RedisScript<Long> redisScript = new DefaultRedisScript<>(luaScript, Long.class);
// 执行 Lua 脚本
Long result = redissonClient.getScript().eval(
org.redisson.api.RScript.Mode.READ_WRITE,
luaScript,
org.redisson.api.RScript.ReturnType.INTEGER,
Collections.singletonList(key)
);
// result=1 表示 Token 有效且已删除,=0 表示 Token 不存在(重复提交)
return result != null && result == 1;
}
}2. 接口层使用示例(下单接口)
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.http.HttpStatus;
import org.springframework.http.ResponseEntity;
import org.springframework.web.bind.annotation.*;
@RestController
@RequestMapping("/order")
public class OrderController {
@Autowired
private IdempotentUtil idempotentUtil;
// 1. 前端获取 Token 接口
@GetMapping("/get-token")
public ResponseEntity<String> getToken() {
String token = idempotentUtil.generateToken();
return ResponseEntity.ok(token);
}
// 2. 下单接口(幂等保护)
@PostMapping("/create")
public ResponseEntity<String> createOrder(
@RequestHeader("Idempotent-Token") String token,
@RequestBody OrderRequest request) {
// 第一步:校验幂等 Token
if (!idempotentUtil.validateToken(token)) {
// 重复提交,直接返回成功(幂等核心:多次请求结果一致)
return ResponseEntity.ok("订单已提交,请勿重复操作");
}
// 第二步:执行业务逻辑(下单、扣库存等)
try {
// 模拟业务逻辑
orderService.createOrder(request);
return ResponseEntity.ok("订单创建成功");
} catch (Exception e) {
// 业务异常,需记录日志并返回
log.error("下单失败", e);
return ResponseEntity.status(HttpStatus.INTERNAL_SERVER_ERROR).body("下单失败");
}
}
}方案 2:分布式锁 + 唯一业务 ID(高并发更新 / 扣款)
核心思路
- 用业务唯一 ID(如订单 ID / 用户 ID + 业务类型)作为锁键
- 加分布式锁后,先查是否已处理,再执行业务
- 锁超时自动释放,避免死锁
代码实现
import org.redisson.api.RLock;
import org.redisson.api.RedissonClient;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Service;
import java.util.concurrent.TimeUnit;
@Service
public class PaymentService {
@Autowired
private RedissonClient redissonClient;
// 分布式锁前缀
private static final String LOCK_PREFIX = "idempotent:lock:";
// 锁超时时间(5秒,根据业务耗时调整)
private static final long LOCK_EXPIRE = 5L;
/**
* 支付接口(高并发幂等保护)
* @param orderId 订单ID(业务唯一ID)
* @param userId 用户ID
*/
public String pay(String orderId, String userId) {
// 1. 构建唯一锁键(用户ID+订单ID,缩小锁粒度)
String lockKey = LOCK_PREFIX + userId + ":" + orderId;
RLock lock = redissonClient.getLock(lockKey);
try {
// 2. 加分布式锁(等待1秒,超时5秒自动释放)
boolean locked = lock.tryLock(1, LOCK_EXPIRE, TimeUnit.SECONDS);
if (!locked) {
// 并发请求,直接返回"处理中"
return "支付请求处理中,请稍后查询";
}
// 3. 先查是否已支付(幂等核心:判断历史结果)
if (checkOrderPaid(orderId)) {
return "订单已支付,无需重复操作";
}
// 4. 执行业务逻辑(扣款、更新订单状态)
doPay(orderId, userId);
return "支付成功";
} catch (InterruptedException e) {
Thread.currentThread().interrupt();
return "支付请求中断,请重试";
} finally {
// 5. 释放锁(必须在finally中,避免死锁)
if (lock.isHeldByCurrentThread()) {
lock.unlock();
}
}
}
// 模拟:查询订单是否已支付
private boolean checkOrderPaid(String orderId) {
// 实际业务中查数据库/缓存
return false;
}
// 模拟:执行支付逻辑
private void doPay(String orderId, String userId) {
// 扣减余额、更新订单状态等业务逻辑
}
}关键优化点(高并发适配)
- 锁粒度最小化 :用
用户ID+订单ID作为锁键,而非全表锁,减少锁竞争 - Lua 原子操作:避免 "查 Token → 删除 Token" 的并发漏洞
- 超时控制:锁等待时间短(1 秒),避免请求阻塞;自动过期(5 秒),避免死锁
- 失败友好:重复请求直接返回 "处理成功",符合幂等性定义
- 兜底保护 :数据库层给
order_id加唯一索引,双重保障
总结
- Token 机制:适合表单提交、下单等 "一次性请求" 场景,核心是 Lua 原子校验删除 Token;
- 分布式锁:适合高并发更新 / 扣款场景,核心是 "锁唯一业务 ID + 先查后执行";
- 高并发核心:缩小锁粒度 + 原子操作 + 数据库唯一索引兜底,避免重复执行和数据不一致。
4.系统限流有哪些实现方式(令牌桶/漏桶/计数器),各自适合什么场景?
在 Java 项目中,系统限流是保障服务稳定性的核心手段,令牌桶、漏桶、计数器 是最经典的三种实现方式。下面我会从「原理」「Java 实现」「适用场景」三个维度,帮你清晰理解它们的区别和用法。
一、计数器算法(固定窗口)
1. 核心原理
最简单的限流方式,核心是在固定时间窗口内统计请求数,如果超过阈值则拒绝请求。
- 例如:1 分钟内允许 100 个请求,第 101 个请求直接拒绝,直到下一个 1 分钟窗口开始。
- 缺陷:临界值问题(比如第 59 秒来了 100 个请求,第 61 秒又来 100 个,2 秒内实际处理 200 个,突破限流阈值)。
2. Java 简易实现
import java.util.concurrent.atomic.AtomicInteger;
/**
* 计数器限流(固定窗口)
*/
public class CounterLimiter {
// 时间窗口大小(毫秒),比如1分钟=60000ms
private final long windowSize;
// 窗口内最大请求数
private final int limit;
// 窗口内当前请求数
private final AtomicInteger count = new AtomicInteger(0);
// 窗口起始时间
private long windowStart;
public CounterLimiter(long windowSize, int limit) {
this.windowSize = windowSize;
this.limit = limit;
this.windowStart = System.currentTimeMillis();
}
// 判断是否允许请求
public synchronized boolean tryAcquire() {
long now = System.currentTimeMillis();
// 进入新窗口,重置计数器和窗口起始时间
if (now - windowStart > windowSize) {
count.set(0);
windowStart = now;
}
// 未超过阈值则计数+1,允许请求
if (count.get() < limit) {
count.incrementAndGet();
return true;
}
// 超过阈值,拒绝请求
return false;
}
// 测试
public static void main(String[] args) throws InterruptedException {
CounterLimiter limiter = new CounterLimiter(1000, 5); // 1秒最多5个请求
for (int i = 0; i < 10; i++) {
System.out.println("第" + (i+1) + "次请求:" + limiter.tryAcquire());
Thread.sleep(100);
}
}
}3. 适用场景
- 适合对限流精度要求低、实现成本优先 的场景;
- 比如:后台管理系统的接口限流(访问量低,无需高精度)、非核心业务的简单防护;
- 不适合:高并发、对流量平稳性要求高的场景(比如秒杀、支付接口)。
二、漏桶算法
1. 核心原理
模拟「漏水的桶」:请求先进入桶中,桶以固定速率 向外释放请求(处理请求),如果桶满了则拒绝新请求。
- 核心特点:强制平滑流量,无论请求突发多少,处理速率始终固定;
- 缺陷:无法应对「短时间内的合理突发流量」(比如正常 QPS 是 100,偶尔 1 秒来 200 个请求,漏桶仍按 100 / 秒处理,会浪费资源)。
2. Java 简易实现
import java.util.concurrent.LinkedBlockingQueue;
/**
* 漏桶限流
*/
public class LeakyBucketLimiter {
// 桶的容量(最多容纳多少请求)
private final int capacity;
// 漏出速率(每秒处理多少请求)
private final int leakRate;
// 存储请求的队列(桶)
private final LinkedBlockingQueue<Long> bucket;
// 漏桶线程(固定速率处理请求)
private final Thread leakThread;
// 开关
private volatile boolean running = true;
public LeakyBucketLimiter(int capacity, int leakRate) {
this.capacity = capacity;
this.leakRate = leakRate;
this.bucket = new LinkedBlockingQueue<>(capacity);
// 启动漏桶线程
this.leakThread = new Thread(this::leak);
leakThread.start();
}
// 尝试添加请求到桶中
public boolean tryAcquire() {
return bucket.offer(System.currentTimeMillis());
}
// 漏桶逻辑:固定速率移除请求(模拟处理)
private void leak() {
while (running) {
try {
// 按漏出速率控制处理间隔
Thread.sleep(1000 / leakRate);
// 移出一个请求(处理)
bucket.poll();
} catch (InterruptedException e) {
Thread.currentThread().interrupt();
}
}
}
// 关闭漏桶
public void stop() {
running = false;
leakThread.interrupt();
}
// 测试
public static void main(String[] args) throws InterruptedException {
LeakyBucketLimiter limiter = new LeakyBucketLimiter(10, 2); // 桶容量10,每秒处理2个请求
// 模拟突发10个请求
for (int i = 0; i < 15; i++) {
System.out.println("第" + (i+1) + "次请求:" + limiter.tryAcquire());
}
// 等待5秒,观察漏桶处理
Thread.sleep(5000);
limiter.stop();
}
}3. 适用场景
- 适合需要严格控制流出速率 的场景,比如:
- 调用第三方接口(对方要求每秒最多调用 N 次,避免触发对方限流);
- 网络流量整形(比如服务器出口带宽限制,固定速率发送数据);
- 避免服务过载的兜底限流(比如数据库写入,固定速率避免压垮库)。
三、令牌桶算法
1. 核心原理
系统以固定速率生成令牌 并放入令牌桶,请求需要获取令牌 才能被处理:
- 桶有最大容量,令牌满了则停止生成;
- 请求来临时,取 1 个令牌,有令牌则处理,无令牌则拒绝;
- 核心特点:允许合理的突发流量(桶内积累的令牌可以应对短时间的高并发)。
- 对比漏桶:漏桶是「控制流出速率」,令牌桶是「控制令牌生成速率,允许突发消费」,更灵活。
2. Java 实现(推荐用 Guava 的 RateLimiter,无需自己造轮子)
Guava 的RateLimiter是令牌桶的经典实现,开箱即用:
import com.google.common.util.concurrent.RateLimiter;
/**
* 令牌桶限流(Guava实现,推荐)
*/
public class TokenBucketLimiter {
public static void main(String[] args) {
// 创建令牌桶:每秒生成5个令牌(QPS=5),桶最大容量默认等于每秒生成数
RateLimiter limiter = RateLimiter.create(5.0);
// 模拟10次请求
for (int i = 0; i < 10; i++) {
// tryAcquire():无令牌则返回false;有则消费1个令牌返回true
boolean acquired = limiter.tryAcquire();
System.out.println("第" + (i+1) + "次请求:" + acquired);
// 前5次请求能拿到令牌(桶初始有5个),后5次拿不到,体现突发能力
if (i == 4) {
System.out.println("--- 等待1秒,生成新令牌 ---");
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
}
}依赖(Maven):
xml
<dependency>
<groupId>com.google.guava</groupId>
<artifactId>guava</artifactId>
<version>32.1.3-jre</version>
</dependency>3. 适用场景
令牌桶是最常用 的限流方式,适合绝大多数场景:
- 电商秒杀、抢购(允许短时间突发流量,利用桶内积累的令牌处理);
- 核心 API 接口限流(兼顾平稳性和突发需求);
- 网关限流(比如 Spring Cloud Gateway 集成 RateLimiter);
- 需要动态调整限流速率的场景(Guava RateLimiter 支持动态修改速率)。
四、三种方式对比表
| 算法 | 核心特点 | 优点 | 缺点 | 适用场景 |
|---|---|---|---|---|
| 计数器 | 固定窗口统计请求数 | 实现最简单、性能最高 | 临界值问题、流量不平滑 | 低精度、低并发的非核心接口 |
| 漏桶 | 固定速率处理请求 | 流量绝对平滑、控制严格 | 无法应对合理突发流量 | 调用第三方接口、带宽 / 数据库限流 |
| 令牌桶 | 固定速率生成令牌,允许突发 | 灵活、支持突发流量 | 实现稍复杂(推荐用 Guava) | 高并发核心接口、秒杀、网关限流 |
总结
- 计数器:最简单但精度低,适合低要求场景,核心是「固定窗口计数」;
- 漏桶:严格控制流出速率,适合需要绝对平稳流量的场景(如调用第三方接口);
- 令牌桶:兼顾平稳性和突发能力,是 Java 项目中最推荐的限流方式(优先用 Guava RateLimiter)。
实际项目中,除了手写算法,还可以用成熟组件:比如 Redis + Lua 实现分布式限流(适配集群场景)、Sentinel/Apache ShenYu 等网关自带的限流功能,本质都是基于这三种算法的扩展。
5. 微服务配置管理方案(Nacos/Apollo),实际怎么设计和落地
微服务配置管理是保障微服务架构灵活、可维护、高可用的核心环节,Nacos 和 Apollo 是国内最主流的两款配置中心产品。下面我会从设计原则 、落地步骤 、核心配置设计 、最佳实践四个维度,详细讲解如何设计和落地微服务配置管理方案。
一、核心设计原则
在落地配置中心前,先明确设计原则,避免后期混乱:
- 环境隔离:严格区分开发、测试、预发、生产环境的配置,避免配置污染。
- 粒度拆分:按 "应用级 + 模块级 + 公共级" 拆分配置,避免一个配置文件包含所有内容。
- 动态生效:核心配置支持热更新,无需重启服务;敏感配置更新需做灰度 / 审核。
- 权限管控:按角色(开发、测试、运维)分配配置读写权限,生产环境配置禁止开发直接修改。
- 版本管理:配置修改需保留版本记录,支持回滚(Nacos/Apollo 均自带此能力)。
- 高可用:配置中心集群部署,微服务端配置本地缓存,避免配置中心宕机导致服务不可用。
二、落地步骤(以 Nacos 为例,Apollo 逻辑一致)
步骤 1:环境准备
1.1 部署配置中心集群
-
Nacos :生产环境建议至少 3 节点集群部署,依赖 MySQL 存储配置(避免嵌入式 Derby),配置持久化、集群节点通信、鉴权等核心参数。核心配置示例(
nacos/conf/application.properties):# 持久化到MySQL spring.datasource.platform=mysql db.num=1 db.url.0=jdbc:mysql://127.0.0.1:3306/nacos_config?characterEncoding=utf8&connectTimeout=1000&socketTimeout=3000&autoReconnect=true&useUnicode=true&useSSL=false&serverTimezone=UTC db.user.0=root db.password.0=123456 # 集群配置(3节点) nacos.inetutils.ip-address=192.168.1.100 # 当前节点IP cluster.conf.content=192.168.1.100:8848|192.168.1.101:8848|192.168.1.102:8848 # 开启鉴权(生产必开) nacos.core.auth.enabled=true nacos.core.auth.server.identity.key=nacos nacos.core.auth.server.identity.value=nacos nacos.core.auth.plugin.nacos.token.secret.key=SecretKey012345678901234567890123456789012345678901234567890123456789 -
Apollo:需部署 Config Service、Admin Service、Portal、MySQL,生产环境同样集群化,核心是配置各组件的注册中心(Eureka/Nacos)和数据库连接。
1.2 微服务端集成配置中心
以 Spring Cloud 微服务为例,集成 Nacos Config:
-
引入依赖(pom.xml): xml
<dependency> <groupId>com.alibaba.cloud</groupId> <artifactId>spring-cloud-starter-alibaba-nacos-config</artifactId> <version>2022.0.0.0-RC2</version> <!-- 与Spring Cloud版本匹配 --> </dependency> -
添加配置文件
bootstrap.yml(必须是 bootstrap,优先于 application 加载 ):yaml
spring: application: name: order-service # 应用名,对应Nacos的Data ID前缀 profiles: active: prod # 环境标识,对应Nacos的Data ID后缀 cloud: nacos: config: server-addr: 192.168.1.100:8848,192.168.1.101:8848,192.168.1.102:8848 # Nacos集群地址 file-extension: yaml # 配置文件格式 namespace: prod-namespace # 命名空间ID(环境隔离,生产环境单独命名空间) group: DEFAULT_GROUP # 分组(可按业务线拆分,如ORDER_GROUP) username: nacos # 鉴权账号 password: nacos # 鉴权密码
步骤 2:配置结构设计
核心是按 "命名空间 + 分组 + Data ID" 三层结构组织配置,示例如下:
| 层级 | 作用 | 示例(Nacos) |
|---|---|---|
| 命名空间(Namespace) | 环境隔离(开发 / 测试 / 生产) | dev(开发)、test(测试)、prod(生产) |
| 分组(Group) | 业务 / 模块隔离 | DEFAULT_GROUP(默认)、ORDER_GROUP(订单)、COMMON_GROUP(公共) |
| Data ID | 配置文件标识(应用 / 模块) | order-service-prod.yaml(订单服务生产配置)、common-prod.yaml(公共配置) |
2.1 配置拆分示例
- 公共配置 :所有微服务共享的配置(如注册中心地址、数据库连接池参数、日志级别),Data ID 为
common-${env}.yaml,分组COMMON_GROUP。 - 应用配置 :单个微服务的核心配置(如订单服务的超时时间、接口开关),Data ID 为
${appName}-${env}.yaml,分组${appName}_GROUP。 - 模块配置 :微服务内模块专属配置(如订单服务的支付模块),Data ID 为
${appName}-payment-${env}.yaml,分组${appName}_GROUP。
2.2 敏感配置处理
数据库密码、接口密钥等敏感配置,禁止明文存储:
-
Nacos:使用内置的配置加密功能(需配置加密密钥),配置值用
cipher-xxx包裹:yaml
db: password: cipher-xxxxxxxxx # 加密后的密码 -
Apollo:集成第三方加密组件(如 Jasypt),或使用 Apollo 的秘钥管理功能,微服务端解密。
步骤 3:配置发布与生效
-
配置发布流程 (生产环境):
- 开发提交配置修改申请 → 运维 / 架构师审核 → 测试环境验证 → 预发环境验证 → 生产环境发布(支持灰度发布,如先发布 10% 节点)。
-
动态生效配置 :
-
Spring Cloud 微服务中,在需要热更新的配置类上添加
@RefreshScope注解:@RestController @RefreshScope // 配置热更新 public class OrderController { @Value("${order.timeout:3000}") // 配置项,默认值3000 private Integer orderTimeout; @GetMapping("/timeout") public Integer getTimeout() { return orderTimeout; // 修改Nacos配置后,无需重启即可获取新值 } }
-
-
配置回滚:Nacos/Apollo 均保留配置版本记录,若发布后出现问题,可直接回滚到上一版本。
步骤 4:监控与运维
- 配置变更监控:Nacos/Apollo 自带操作日志,可查看谁、何时修改了哪个配置;对接告警平台(如 Prometheus + Grafana、钉钉 / 企业微信),配置变更时触发告警。
- 配置中心可用性监控:监控 Nacos/Apollo 集群的 CPU、内存、请求响应时间,配置中心宕机时及时告警。
- 本地缓存兜底:微服务启动时会拉取配置并缓存到本地,即使配置中心宕机,服务仍可基于本地缓存运行(但无法动态更新配置)。
三、Nacos vs Apollo 选型建议
| 特性 | Nacos | Apollo |
|---|---|---|
| 部署复杂度 | 低(单组件) | 高(多组件) |
| 配置灰度发布 | 支持(2.0+) | 原生支持(更完善) |
| 权限管控 | 基础(命名空间 / 分组权限) | 精细(角色 / 用户 / 资源粒度) |
| 配置推送性能 | 高(长连接) | 中(HTTP 长轮询) |
| 生态整合 | 与 Spring Cloud Alibaba 深度整合 | 适配所有 Spring Cloud 版本 |
| 适用场景 | 中小团队、快速落地、轻量需求 | 大型团队、复杂权限 / 灰度需求 |
四、最佳实践
- 避免配置硬编码:所有可变配置(如第三方接口地址、超时时间、开关)均放入配置中心,禁止写死在代码中。
- 配置分层加载:公共配置 → 应用配置 → 模块配置,优先级依次升高(模块配置覆盖应用配置,应用配置覆盖公共配置)。
- 生产环境配置审核:开发只能提交配置修改申请,运维 / 架构师审核后才能发布,避免误操作。
- 配置备份:定期备份 Nacos/Apollo 的数据库(配置存储核心),防止配置丢失。
- 压测验证:上线前压测配置中心,确保高并发下配置拉取 / 推送的稳定性。
总结
- 微服务配置管理落地的核心是环境隔离 + 粒度拆分 + 动态生效 + 权限管控,优先选择 Nacos(轻量)或 Apollo(复杂场景)。
- 落地步骤:部署集群化配置中心 → 微服务集成客户端 → 按 "命名空间 - 分组 - Data ID" 设计配置结构 → 规范发布流程 → 监控运维兜底。
- 关键要点:敏感配置加密、配置热更新(@RefreshScope)、版本回滚、本地缓存兜底,生产环境必须做配置审核和监控。
通过以上设计和落地步骤,可实现微服务配置的统一管理、动态更新、安全可控,解决传统配置文件分散、修改需重启、环境不一致等问题。
6. 代码重构的核心原则、常用方法,结合自己的实战经验说一下?
代码重构是软件开发中至关重要的环节,核心目标是在不改变代码外部行为的前提下,优化内部结构,提升可读性、可维护性和可扩展性。下面结合核心原则、常用方法和实战经验详细说明:
一、代码重构的核心原则
重构不是 "重写",必须遵循以下核心原则,避免引入新问题:
- 保持行为不变重构前后,代码的输入输出、功能表现必须完全一致。这是重构的第一准则,也是判断重构是否成功的核心标准。可以通过完善的单元测试来保障 ------ 重构前先写 / 补全测试用例,重构后运行测试验证行为无变化。
- 小步快跑,频繁验证不要一次性大规模重构,而是拆分成多个小步骤(比如先提取重复代码,再重命名变量,最后优化逻辑),每完成一步就运行测试,发现问题能快速回滚,降低风险。
- 符合 "代码整洁" 标准 最终目标是让代码符合 SOLID 原则、DRY(Don't Repeat Yourself)原则、KISS(Keep It Simple, Stupid)原则:
- SOLID:尤其是单一职责(一个类 / 函数只做一件事)、开闭原则(对扩展开放,对修改关闭);
- DRY:消除重复代码,避免 "复制粘贴式编程";
- KISS:拒绝过度设计,保持逻辑简单易懂。
- 有明确的重构目标重构不是无目的的 "优化",必须围绕具体问题:比如解决 "代码冗余""逻辑混乱""扩展困难""性能瓶颈" 等,避免为了重构而重构。
二、代码重构的常用方法(附实战经验)
结合我实际项目中重构老代码的经验,以下是最常用且高效的重构方法:
1. 基础级重构(低成本、高收益)
(1)重命名(Rename)
- 适用场景 :变量 / 函数 / 类名模糊(比如
a1、doSomething、DataUtil),无法通过名称快速理解用途。 - 实战案例 :曾接手一个电商项目,有个函数叫
calc(),既算订单金额又算优惠,重构时拆分为calculateOrderAmount()和calculateDiscountAmount(),变量num改为orderItemCount,后续同事排查问题时效率提升了至少 50%。 - 注意:利用 IDE 的 "安全重命名" 功能(如 IDEA 的 Shift+F6),避免手动改漏导致错误。
(2)提取函数 / 方法(Extract Method)
-
适用场景:一个函数过长(超过 50 行)、包含多个逻辑块,或存在重复代码片段。
-
实战案例 :重构过一个 "生成订单" 的函数,原函数包含 "校验参数→查询商品库存→计算金额→扣减库存→生成订单记录"5 个逻辑,共 120 行。拆分后:
// 重构后 public Order generateOrder(OrderParam param) { // 1. 校验参数 validateOrderParam(param); // 2. 查询商品库存 List<Stock> stockList = queryProductStock(param.getProductIds()); // 3. 计算订单金额 BigDecimal amount = calculateOrderAmount(param, stockList); // 4. 扣减库存 deductStock(stockList); // 5. 生成订单记录 return saveOrderRecord(param, amount); }拆分后每个子函数只做一件事,后续修改 "金额计算规则" 时,只需改
calculateOrderAmount,无需动其他逻辑。
(3)移除死代码 / 冗余代码
- 适用场景 :注释掉的代码、未被调用的函数 / 类、永远不会执行的分支(如
if (false))。 - 实战经验:老项目中常遇到 "怕删错而保留大量注释代码",重构时可先通过版本控制(Git)备份,再果断删除 ------ 如果后续需要,可从历史记录中找回,保留冗余代码只会增加维护成本。
2. 进阶级重构(优化结构,提升扩展性)
(1)提取类 / 接口(Extract Class/Interface)
- 适用场景:一个类承担多个职责(比如 "用户类" 既包含用户信息,又处理登录逻辑、订单查询)。
- 实战案例 :重构过一个
User类,原类包含getUserName()、login()、queryUserOrders()等方法,违反 "单一职责原则"。重构后拆分:User:仅存储用户基础信息(姓名、手机号、ID);UserAuthService:处理登录、权限校验;UserOrderService:处理订单查询、订单关联。拆分后,后续修改登录逻辑时,不会影响用户信息和订单模块,也便于单独测试。
(2)替换条件分支为多态(Replace Conditional with Polymorphism)
-
适用场景 :大量
if-else/switch分支处理不同类型的逻辑(比如不同支付方式的处理)。 -
实战案例 :原支付逻辑代码:
public void pay(String payType, BigDecimal amount) { if ("wechat".equals(payType)) { // 微信支付逻辑 System.out.println("微信支付:" + amount); } else if ("alipay".equals(payType)) { // 支付宝支付逻辑 System.out.println("支付宝支付:" + amount); } else if ("unionpay".equals(payType)) { // 银联支付逻辑 System.out.println("银联支付:" + amount); } }重构为多态:
// 定义支付接口 public interface Payment { void pay(BigDecimal amount); } // 微信支付实现 public class WechatPayment implements Payment { @Override public void pay(BigDecimal amount) { System.out.println("微信支付:" + amount); } } // 支付宝支付实现 public class AlipayPayment implements Payment { @Override public void pay(BigDecimal amount) { System.out.println("支付宝支付:" + amount); } } // 使用时 public void pay(Payment payment, BigDecimal amount) { payment.pay(amount); }后续新增 "抖音支付" 时,只需新增
DouyinPayment实现类,无需修改原有代码,符合 "开闭原则"。
(3)引入设计模式优化结构
- 常用模式:单例模式(优化重复创建的对象)、工厂模式(统一对象创建)、策略模式(替换复杂条件分支)、装饰器模式(扩展功能不修改原代码)。
- 实战经验 :在重构 "订单优惠计算" 逻辑时,用策略模式替代多层
if-else(满减、折扣、优惠券等优惠类型),后续新增优惠类型只需加策略类,无需改动核心计算逻辑。
三、实战避坑经验
- 重构前必须先补测试:如果原有代码没有单元测试,不要直接重构 ------ 先写覆盖核心逻辑的测试用例,否则重构后可能引入隐性 bug,且难以发现。
- 避免重构和新功能开发并行:不要在开发新功能时 "顺便" 重构,容易顾此失彼;建议先完成重构并验证,再开发新功能。
- 大型重构要分阶段:对于几十万行的老代码,不要追求 "一步到位",可按模块拆分(比如先重构订单模块,再重构支付模块),每个模块重构后上线验证,降低整体风险。
总结
- 核心原则:重构的核心是 "保行为、小步改、有目标",必须以单元测试为保障,避免引入新问题。
- 常用方法:基础重构(重命名、提取函数、删冗余)解决可读性问题,进阶重构(提取类、多态替换分支、设计模式)解决扩展性问题。
- 实战关键:重构前补测试、避免大规模一次性重构、不与新功能开发并行,是保障重构成功的核心要点。
7.java项目中,单元测试的最佳实践,覆盖率、边界测试、Mock技术怎么用?
在 Java 项目中,单元测试是保障代码质量的核心手段,结合覆盖率 、边界测试 和Mock 技术能让测试更全面、更高效。下面我会从实践角度,一步步讲解这三者的使用方法和最佳实践。
一、单元测试基础与核心原则
首先明确单元测试的核心目标:测试最小可测单元(通常是方法 / 类),隔离外部依赖,验证逻辑正确性。Java 中主流的单元测试框架组合:
- 测试框架:JUnit 5(Jupiter)(推荐)/ JUnit 4
- Mock 框架:Mockito(最常用)
- 覆盖率工具:JaCoCo(集成在 Maven/Gradle 中)
- 断言库:AssertJ(比 JUnit 自带断言更友好)
基础依赖(Maven)
<dependencies>
<!-- JUnit 5 核心依赖 -->
<dependency>
<groupId>org.junit.jupiter</groupId>
<artifactId>junit-jupiter-api</artifactId>
<version>5.9.2</version>
<scope>test</scope>
</dependency>
<dependency>
<groupId>org.junit.jupiter</groupId>
<artifactId>junit-jupiter-engine</artifactId>
<version>5.9.2</version>
<scope>test</scope>
</dependency>
<!-- Mockito -->
<dependency>
<groupId>org.mockito</groupId>
<artifactId>mockito-core</artifactId>
<version>4.11.0</version>
<scope>test</scope>
</dependency>
<dependency>
<groupId>org.mockito</groupId>
<artifactId>mockito-junit-jupiter</artifactId>
<version>4.11.0</version>
<scope>test</scope>
</dependency>
<!-- AssertJ 断言 -->
<dependency>
<groupId>org.assertj</groupId>
<artifactId>assertj-core</artifactId>
<version>3.24.2</version>
<scope>test</scope>
</dependency>
</dependencies>
<!-- JaCoCo 覆盖率插件 -->
<build>
<plugins>
<plugin>
<groupId>org.jacoco</groupId>
<artifactId>jacoco-maven-plugin</artifactId>
<version>0.8.10</version>
<executions>
<execution>
<goals>
<goal>prepare-agent</goal>
</goals>
</execution>
<execution>
<id>report</id>
<phase>test</phase>
<goals>
<goal>report</goal>
</goals>
</execution>
</executions>
</plugin>
</plugins>
</build>二、Mock 技术:隔离外部依赖
1. 什么是 Mock?
Mock 的核心是创建依赖对象的 "假实现" ,让单元测试不依赖数据库、网络、第三方服务等外部组件。适用场景:
- 依赖的对象还未开发完成
- 外部依赖调用成本高 / 不稳定(如数据库、接口)
- 需要模拟异常场景(如接口调用失败)
2. Mockito 核心用法(JUnit 5)
以一个订单服务为例,订单服务依赖用户服务(外部依赖):
// 业务类:订单服务
public class OrderService {
private final UserService userService;
public OrderService(UserService userService) {
this.userService = userService;
}
// 核心方法:创建订单(需要先校验用户是否存在)
public String createOrder(Long userId, String product) {
// 调用外部依赖:用户服务
boolean userExists = userService.checkUserExists(userId);
if (!userExists) {
return "失败:用户不存在";
}
return "成功:创建订单-" + product + "-用户" + userId;
}
}
// 外部依赖:用户服务(接口)
public interface UserService {
boolean checkUserExists(Long userId);
}单元测试(使用 Mock 隔离 UserService):
import org.junit.jupiter.api.Test;
import org.junit.jupiter.api.extension.ExtendWith;
import org.mockito.InjectMocks;
import org.mockito.Mock;
import org.mockito.junit.jupiter.MockitoExtension;
import static org.assertj.core.api.Assertions.assertThat;
import static org.mockito.Mockito.*;
// 启用Mockito扩展
@ExtendWith(MockitoExtension.class)
public class OrderServiceTest {
// 1. 创建Mock对象(假的UserService)
@Mock
private UserService userService;
// 2. 将Mock对象注入到待测试的OrderService中
@InjectMocks
private OrderService orderService;
// 测试场景1:用户存在,创建订单成功
@Test
void createOrder_UserExists_ReturnSuccess() {
// 步骤1:定义Mock行为(当调用checkUserExists(1L)时,返回true)
when(userService.checkUserExists(1L)).thenReturn(true);
// 步骤2:执行待测试方法
String result = orderService.createOrder(1L, "手机");
// 步骤3:断言结果正确
assertThat(result).isEqualTo("成功:创建订单-手机-用户1");
// 验证Mock方法是否被调用(可选,确保逻辑走了依赖调用)
verify(userService, times(1)).checkUserExists(1L);
}
// 测试场景2:用户不存在,创建订单失败(边界场景)
@Test
void createOrder_UserNotExists_ReturnFailure() {
// 定义Mock行为:调用checkUserExists(2L)返回false
when(userService.checkUserExists(2L)).thenReturn(false);
String result = orderService.createOrder(2L, "电脑");
assertThat(result).isEqualTo("失败:用户不存在");
verify(userService, times(1)).checkUserExists(2L);
}
// 测试场景3:模拟依赖抛出异常(异常边界)
@Test
void createOrder_UserServiceThrowException_ReturnError() {
// 定义Mock行为:调用checkUserExists(3L)时抛出异常
when(userService.checkUserExists(3L)).thenThrow(new RuntimeException("服务超时"));
// 执行并断言异常
RuntimeException exception = org.junit.jupiter.api.Assertions.assertThrows(RuntimeException.class, () -> {
orderService.createOrder(3L, "平板");
});
assertThat(exception.getMessage()).isEqualTo("服务超时");
}
}Mock 关键技巧:
@Mock:创建 Mock 对象@InjectMocks:自动将 Mock 对象注入到待测试类中(支持构造器 /setter/ 字段注入)when(xxx).thenReturn(yyy):定义 Mock 方法的返回值when(xxx).thenThrow(xxx):模拟方法抛出异常verify(xxx):验证 Mock 方法是否被调用(次数、参数等)
三、边界测试:覆盖极端场景
边界测试是单元测试的核心环节,目标是测试方法的 "临界值" 和 "异常场景",而不只是正常流程。
1. 常见边界场景
| 类型 | 示例 |
|---|---|
| 数值边界 | 0、负数、最大值(Integer.MAX_VALUE) |
| 集合边界 | 空集合、单元素集合、超大集合 |
| 字符串边界 | 空字符串、null、超长字符串、特殊字符 |
| 逻辑边界 | 条件分支的边界(如等于 / 不等于、大于 / 小于) |
| 异常边界 | 依赖抛出异常、参数非法 |
2. 边界测试实战
以一个计算折扣的方法为例:
// 折扣计算工具类
public class DiscountCalculator {
// 规则:订单金额>0且<=1000,折扣10%;>1000,折扣20%;其他(<=0)返回0
public static double calculateDiscount(double orderAmount) {
if (orderAmount <= 0) {
return 0;
} else if (orderAmount <= 1000) {
return orderAmount * 0.1;
} else {
return orderAmount * 0.2;
}
}
}边界测试用例:
import org.junit.jupiter.api.Test;
import static org.assertj.core.api.Assertions.assertThat;
public class DiscountCalculatorTest {
// 正常场景:100元(10%折扣)
@Test
void calculateDiscount_100_Return10() {
assertThat(DiscountCalculator.calculateDiscount(100)).isEqualTo(10.0);
}
// 边界1:0元(返回0)
@Test
void calculateDiscount_0_Return0() {
assertThat(DiscountCalculator.calculateDiscount(0)).isEqualTo(0.0);
}
// 边界2:负数(返回0)
@Test
void calculateDiscount_Negative_Return0() {
assertThat(DiscountCalculator.calculateDiscount(-50)).isEqualTo(0.0);
}
// 边界3:1000元(临界值,10%折扣)
@Test
void calculateDiscount_1000_Return100() {
assertThat(DiscountCalculator.calculateDiscount(1000)).isEqualTo(100.0);
}
// 边界4:1001元(超过临界值,20%折扣)
@Test
void calculateDiscount_1001_Return200_2() {
assertThat(DiscountCalculator.calculateDiscount(1001)).isEqualTo(200.2);
}
// 边界5:最大值(Double.MAX_VALUE)
@Test
void calculateDiscount_MaxValue_Return20Percent() {
double max = Double.MAX_VALUE;
assertThat(DiscountCalculator.calculateDiscount(max)).isEqualTo(max * 0.2);
}
}四、覆盖率:衡量测试完整性
1. 什么是测试覆盖率?
覆盖率是被测试代码占总代码的比例,JaCoCo 主要统计以下维度:
- 行覆盖率:被执行的代码行数 / 总代码行数(最常用)
- 分支覆盖率:被执行的条件分支 / 总分支数(如 if/else、switch)
- 方法覆盖率:被测试的方法数 / 总方法数
2. 覆盖率的最佳实践
- 不要追求 100% 覆盖率 :100% 不代表无 bug(如逻辑错误、边界遗漏),重点覆盖核心业务逻辑,非核心代码(如简单的 getter/setter)可忽略。
- 核心业务代码覆盖率目标:建议 80%+(分支覆盖率 60%+)。
- 避免为了覆盖率写 "无用测试":测试的核心是验证逻辑,而非单纯凑数。
3. 如何查看覆盖率报告
-
执行 Maven 命令运行测试并生成覆盖率报告:
mvn clean test
-
报告生成路径:
target/site/jacoco/index.html(用浏览器打开即可查看)。
4. 覆盖率优化技巧
-
针对未覆盖的行 / 分支,补充对应的测试用例(如边界场景、异常场景)。
-
排除无需测试的代码:在 JaCoCo 配置中忽略 getter/setter、枚举、配置类等:
org.jacoco jacoco-maven-plugin 0.8.10 **/entity/* **/config/*
五、单元测试整体最佳实践
- 测试方法命名规范 :
方法名_场景_预期结果(如createOrder_UserNotExists_ReturnFailure),一眼看懂测试意图。 - 一个测试方法只测一个场景:避免一个方法包含多个断言,便于定位问题。
- 测试代码独立:测试用例之间无依赖,可并行执行。
- 不依赖外部状态:禁止测试用例修改数据库、文件等持久化数据。
- Mock 只隔离外部依赖:核心业务逻辑不 Mock,确保测试真实逻辑。
- 结合 CI/CD:在持续集成中强制运行单元测试,并检查覆盖率(如低于阈值则构建失败)。
总结
- Mock 技术:用 Mockito 创建假依赖对象,隔离外部组件(数据库 / 接口),聚焦核心逻辑测试,同时支持模拟异常场景。
- 边界测试:覆盖数值、集合、逻辑、异常等临界场景,是发现隐藏 bug 的关键,而非仅测试正常流程。
- 覆盖率:用 JaCoCo 衡量测试完整性,核心业务追求 80%+ 行覆盖率,避免为了覆盖率写无用测试,重点关注分支覆盖率。
遵循这些实践,能让你的 Java 单元测试既高效又能真正保障代码质量,同时兼顾可维护性和可执行性。
8.java 代码审查重点看什么,规范、性能、安全、可扩展性都要考虑到
Java 代码审查是保障代码质量的核心环节,需要从规范、性能、安全、可扩展性四大维度系统性检查,同时兼顾可读性、可维护性等基础要求。下面我会按维度拆解审查重点,并结合实际示例说明,让你能清晰落地。
一、代码规范(基础底线)
规范是团队协作的前提,确保代码风格统一、易读、符合行业标准(如阿里巴巴 Java 开发手册)。
核心审查点:
-
命名与注释
- 类名:大驼峰(
UserService)、方法名 / 变量名:小驼峰(getUserName)、常量:全大写 + 下划线(MAX_RETRY_COUNT); - 注释覆盖核心逻辑:类注释说明用途、方法注释说明入参 / 出参 / 异常、复杂逻辑块加行注释,避免无意义注释(如
// 循环遍历)。 - 反例:
class user_service {}、int a = 10; // a是数字(无意义注释)。
- 类名:大驼峰(
-
代码格式与结构
- 缩进 / 空格统一(如 4 个空格缩进)、花括号对齐(左花括号不换行);
- 避免超长行(建议≤120 字符)、避免超大类 / 超大方法(类≤500 行,方法≤50 行);
- 包结构清晰:按功能 / 模块划分(如
com.xxx.user.controller、com.xxx.user.service)。
-
语法与编码习惯
- 避免魔法值(硬编码常量):用枚举 / 常量类替代(如
if (status == 1)→if (status == OrderStatus.PAID.getCode())); - 异常处理不吞异常:禁止
catch (Exception e) { },至少打印日志; - 资源释放:IO 流 / 数据库连接等需用
try-with-resources自动关闭,而非手动finally。
规范示例(正确写法):
// 常量定义规范 public class OrderConstant { public static final int MAX_RETRY = 3; } // 资源释放规范 try (FileInputStream fis = new FileInputStream("file.txt")) { // 业务逻辑 } catch (IOException e) { log.error("读取文件失败", e); // 打印异常栈,而非仅e.getMessage() } - 避免魔法值(硬编码常量):用枚举 / 常量类替代(如
二、性能优化(避免资源浪费)
性能问题易导致系统瓶颈,需重点检查代码对 CPU、内存、IO 的消耗。
核心审查点:
-
集合与数据处理
- 避免频繁创建大对象:如循环内
new ArrayList<>()、字符串拼接用StringBuilder而非+; - 集合遍历:遍历大数据量集合时,
for-i比foreach(迭代器)更高效;HashMap初始化指定容量(避免扩容); - 避免空循环、无效遍历(如遍历前未判空)。
- 避免频繁创建大对象:如循环内
-
数据库操作
- SQL 优化:避免
select *、禁止全表扫描(需加索引)、批量操作(batchUpdate)替代循环单条插入; - 连接池:避免手动创建连接、及时释放连接、设置合理的连接池参数;
- 缓存:高频查询结果加缓存(如 Redis),避免重复查库。
- SQL 优化:避免
-
JVM 相关
- 避免内存泄漏:如静态集合持有对象引用、未关闭的线程池;
- 线程使用:避免创建大量线程(用线程池)、禁止死循环线程。
性能反例(需优化):
// 反例1:循环内字符串拼接(每次创建新String) String result = ""; for (int i = 0; i < 1000; i++) { result += i; } // 反例2:HashMap未指定容量(默认16,扩容会消耗性能) Map<String, Object> map = new HashMap<>();
三、安全漏洞(防攻击、防泄露)
安全是生产环境的生命线,重点防范常见的 Java 安全风险。
核心审查点:
-
输入验证与注入攻击
- SQL 注入:禁止拼接 SQL(用
PreparedStatement)、参数化查询; - XSS 攻击:前端入参过滤特殊字符(如
<>)、后端响应转义; - 命令注入:禁止执行用户输入的系统命令(如
Runtime.exec(userInput))。
- SQL 注入:禁止拼接 SQL(用
-
权限与认证
- 接口未做权限校验:如未登录可访问核心接口、越权操作(普通用户修改管理员数据);
- 敏感操作未做二次校验:如删除数据、转账未验证身份。
-
敏感信息保护
- 密码存储:禁止明文存储(用 BCrypt 算法加密)、禁止硬编码密码;
- 数据传输:敏感数据(如手机号、身份证)传输需加密(HTTPS)、返回结果脱敏(如 138****1234);
- 日志泄露:禁止日志打印密码、token、数据库连接信息。
-
其他安全风险
- 反序列化漏洞:避免反序列化不可信数据(如
ObjectInputStream读取用户传入的字节流); - 超时与重试:接口设置超时时间,避免恶意请求拖垮系统。
安全示例(正确写法):
// 防SQL注入:参数化查询 String sql = "SELECT * FROM user WHERE id = ?"; PreparedStatement pstmt = conn.prepareStatement(sql); pstmt.setInt(1, userId); // 用参数替代拼接 ResultSet rs = pstmt.executeQuery(); // 密码加密存储 String encryptPwd = BCrypt.hashpw(rawPwd, BCrypt.gensalt()); - 反序列化漏洞:避免反序列化不可信数据(如
四、可扩展性(应对需求变更)
可扩展性决定代码能否快速适配新需求,避免 "改一处动全身"。
核心审查点:
-
设计原则
- 单一职责:一个类 / 方法只做一件事(如
UserService只处理用户逻辑,不包含订单逻辑); - 开闭原则:对扩展开放、对修改关闭(用接口 / 抽象类,新增功能通过实现类扩展,而非修改原有代码);
- 依赖注入:通过 Spring 依赖注入解耦,避免硬编码依赖(如
new UserDao())。
- 单一职责:一个类 / 方法只做一件事(如
-
架构与复用
- 重复代码:提取公共逻辑为工具类 / 公共方法(如
DateUtil、ValidateUtil); - 接口设计:接口粒度合理,避免过粗(一个接口包含多个无关功能)或过细;
- 配置化:可变参数(如超时时间、开关)配置到配置文件(application.yml),而非硬编码。
- 重复代码:提取公共逻辑为工具类 / 公共方法(如
-
兼容性与版本
- 接口升级:新增接口字段时兼容老版本(如设置默认值);
- 第三方依赖:指定依赖版本号,避免使用快照版(SNAPSHOT),防止版本兼容问题。
可扩展性反例(需优化):
// 反例:硬编码业务规则,新增规则需修改代码 public double calculatePrice(int type) { if (type == 1) { // 普通商品 return price * 0.9; } else if (type == 2) { // 会员商品 return price * 0.8; } // 新增类型需加else if,违反开闭原则 }优化方案:定义
PriceStrategy接口,不同类型实现不同子类,新增类型只需加实现类。
总结
Java 代码审查需覆盖四大核心维度,关键点如下:
- 规范维度:聚焦命名 / 注释 / 格式,遵循行业标准,保证代码可读性;
- 性能维度:优化集合、数据库、线程使用,避免资源浪费和瓶颈;
- 安全维度:防范注入、权限、敏感信息泄露等风险,守住生产安全底线;
- 可扩展性维度:遵循开闭原则,解耦代码,让需求变更时最小化修改。
实际审查中可按 "规范→安全→性能→可扩展性" 的优先级逐步检查,同时结合团队定制的代码规范文档,确保审查标准统一。
编码题:
1.使用Java,手写一个LRU缓存
LRU 缓存实现思路
LRU(Least Recently Used,最近最少使用)缓存的核心规则是:当缓存容量满时,淘汰最久未被使用的元素。要高效实现这个逻辑,需要满足:
- 快速访问:用哈希表(HashMap)存储键值对,保证 O (1) 时间复杂度的查询。
- 快速更新 / 删除:用双向链表维护元素的访问顺序(头部是最近使用,尾部是最久未使用),保证 O (1) 时间复杂度的插入、删除。
完整实现代码
import java.util.HashMap;
import java.util.Map;
/**
* 手写LRU缓存(基于HashMap + 双向链表)
*/
public class LRUCache {
// 双向链表节点类
static class Node {
int key; // 存储key(删除尾节点时需要通过key删除HashMap中的对应项)
int value;
Node prev; // 前驱节点
Node next; // 后继节点
public Node(int key, int value) {
this.key = key;
this.value = value;
}
}
private final int capacity; // 缓存最大容量
private final Map<Integer, Node> cacheMap; // 哈希表:key -> 节点
private final Node head; // 虚拟头节点(简化边界处理)
private final Node tail; // 虚拟尾节点(简化边界处理)
// 构造方法:初始化缓存容量、哈希表、虚拟头尾节点
public LRUCache(int capacity) {
this.capacity = capacity;
this.cacheMap = new HashMap<>(capacity);
// 初始化虚拟头尾节点,互相指向
this.head = new Node(-1, -1);
this.tail = new Node(-1, -1);
head.next = tail;
tail.prev = head;
}
/**
* 获取缓存值
* @param key 要查询的键
* @return 对应的值,不存在返回-1
*/
public int get(int key) {
// 1. 哈希表中不存在该key,返回-1
if (!cacheMap.containsKey(key)) {
return -1;
}
// 2. 存在则获取节点,并将该节点移到链表头部(标记为最近使用)
Node targetNode = cacheMap.get(key);
moveToHead(targetNode);
return targetNode.value;
}
/**
* 存入缓存
* @param key 键
* @param value 值
*/
public void put(int key, int value) {
// 1. 若key已存在:更新值,并移到链表头部
if (cacheMap.containsKey(key)) {
Node targetNode = cacheMap.get(key);
targetNode.value = value; // 更新值
moveToHead(targetNode); // 标记为最近使用
return;
}
// 2. key不存在:创建新节点
Node newNode = new Node(key, value);
cacheMap.put(key, newNode); // 存入哈希表
addToHead(newNode); // 加到链表头部
// 3. 若容量超限:删除链表尾节点(最久未使用),并删除哈希表对应项
if (cacheMap.size() > capacity) {
Node tailNode = removeTail();
cacheMap.remove(tailNode.key);
}
}
// 辅助方法:将节点添加到链表头部(虚拟头节点之后)
private void addToHead(Node node) {
node.prev = head;
node.next = head.next;
head.next.prev = node;
head.next = node;
}
// 辅助方法:移除指定节点
private void removeNode(Node node) {
node.prev.next = node.next;
node.next.prev = node.prev;
}
// 辅助方法:将节点移到链表头部(先移除,再添加)
private void moveToHead(Node node) {
removeNode(node);
addToHead(node);
}
// 辅助方法:移除链表尾节点(虚拟尾节点之前)
private Node removeTail() {
Node realTail = tail.prev;
removeNode(realTail);
return realTail;
}
// 测试方法
public static void main(String[] args) {
LRUCache lruCache = new LRUCache(2); // 容量为2的缓存
lruCache.put(1, 1); // 缓存:{1=1}
lruCache.put(2, 2); // 缓存:{1=1, 2=2}
System.out.println(lruCache.get(1)); // 输出1,1变为最近使用
lruCache.put(3, 3); // 容量满,淘汰最久未使用的2,缓存:{1=1, 3=3}
System.out.println(lruCache.get(2)); // 输出-1(已淘汰)
lruCache.put(4, 4); // 容量满,淘汰最久未使用的1,缓存:{3=3, 4=4}
System.out.println(lruCache.get(1)); // 输出-1(已淘汰)
System.out.println(lruCache.get(3)); // 输出3,3变为最近使用
System.out.println(lruCache.get(4)); // 输出4
}
}代码关键部分解释
-
双向链表节点(Node 类):
- 存储
key和value,其中key是为了删除尾节点时,能同步删除 HashMap 中的对应项。 - 包含
prev(前驱)和next(后继)指针,支持双向遍历和快速删除。
- 存储
-
虚拟头尾节点:
- 避免处理 "头节点 / 尾节点为空" 的边界情况,简化链表操作(比如添加头节点、删除尾节点)。
-
核心方法:
get():查询时若存在,将节点移到链表头部(标记为最近使用)。put():新增时若容量超限,删除尾节点(最久未使用);更新时直接修改值并移到头部。- 辅助方法(
addToHead/removeNode/moveToHead/removeTail):封装链表的基础操作,提高代码复用性。
-
时间复杂度:
get()和put()的核心操作(哈希表查询 / 插入、链表增删)都是 O (1),满足高效要求。
测试输出
运行main方法,输出结果:
1
-1
-1
3
4总结
- LRU 缓存的核心是HashMap + 双向链表:HashMap 保证快速查询,双向链表保证快速更新访问顺序。
- 虚拟头尾节点是简化链表边界处理的关键技巧,避免空指针异常。
- 核心规则:访问 / 更新元素时移到链表头部,容量满时删除链表尾节点(最久未使用)。
使用 LinkedHashMap 实现 LRU 缓存思路
Java 中的 LinkedHashMap 本身就提供了按访问顺序 排序的能力(默认是插入顺序),只需通过构造方法指定 accessOrder = true,就能让链表按最近使用顺序维护。同时重写 removeEldestEntry() 方法,即可在缓存容量满时自动删除最久未使用的元素,无需手动实现双向链表和哈希表的结合。
完整实现代码
java
运行
import java.util.LinkedHashMap;
import java.util.Map;
/**
* 基于LinkedHashMap实现LRU缓存(简洁版)
*/
public class LRUCacheWithLinkedHashMap<K, V> extends LinkedHashMap<K, V> {
// 缓存最大容量
private final int capacity;
/**
* 构造方法:初始化LRU缓存
* @param capacity 缓存容量
*/
public LRUCacheWithLinkedHashMap(int capacity) {
// 初始化LinkedHashMap:
// 1. initialCapacity:初始容量(设为capacity,减少扩容)
// 2. loadFactor:加载因子(0.75是默认值,平衡空间和时间)
// 3. accessOrder:true=按访问顺序排序,false=按插入顺序排序(核心)
super(capacity, 0.75f, true);
this.capacity = capacity;
}
/**
* 重写该方法,实现容量限制:当缓存大小超过capacity时,删除最久未使用的元素
* @param eldest 最久未使用的键值对
* @return true=删除该元素,false=保留
*/
@Override
protected boolean removeEldestEntry(Map.Entry<K, V> eldest) {
// 关键逻辑:当当前大小 > 容量时,自动删除最老的元素
return size() > capacity;
}
// 测试方法
public static void main(String[] args) {
// 创建容量为2的LRU缓存
LRUCacheWithLinkedHashMap<Integer, Integer> lruCache = new LRUCacheWithLinkedHashMap<>(2);
lruCache.put(1, 1); // 缓存:{1=1}
lruCache.put(2, 2); // 缓存:{1=1, 2=2}
System.out.println(lruCache.get(1)); // 输出1,1变为最近使用,缓存顺序:2 -> 1
lruCache.put(3, 3); // 容量满,删除最久未使用的2,缓存:{1=1, 3=3}
System.out.println(lruCache.get(2)); // 输出null(已淘汰)
lruCache.put(4, 4); // 容量满,删除最久未使用的1,缓存:{3=3, 4=4}
System.out.println(lruCache.get(1)); // 输出null(已淘汰)
System.out.println(lruCache.get(3)); // 输出3,3变为最近使用
System.out.println(lruCache.get(4)); // 输出4
}
}代码关键部分解释
-
LinkedHashMap 构造参数:
accessOrder = true:这是实现 LRU 的核心,设置后LinkedHashMap会把最近访问(get/put) 的元素移到链表尾部(链表尾部是最近使用,头部是最久未使用)。loadFactor = 0.75:默认加载因子,当哈希表填充到 75% 时会自动扩容,平衡空间利用率和哈希冲突概率。
-
重写 removeEldestEntry ():
- 该方法是
LinkedHashMap的钩子方法,默认返回false(不删除任何元素)。 - 我们重写后,当缓存大小超过设定的
capacity时返回true,触发LinkedHashMap自动删除最久未使用的元素(链表头部元素)。
- 该方法是
-
核心方法复用:
put()/get()直接复用LinkedHashMap的实现,无需手动处理链表的增删和顺序更新,大幅简化代码。
测试输出
运行 main 方法,输出结果:
1
null
null
3
4进阶:线程安全版(可选)
如果需要在多线程环境下使用,只需对核心方法加锁,或直接包装成同步容器:
import java.util.Collections;
import java.util.Map;
public class ThreadSafeLRUCache<K, V> {
private final Map<K, V> lruCache;
private final int capacity;
public ThreadSafeLRUCache(int capacity) {
this.capacity = capacity;
// 使用Collections.synchronizedMap包装,保证线程安全
this.lruCache = Collections.synchronizedMap(
new LinkedHashMap<K, V>(capacity, 0.75f, true) {
@Override
protected boolean removeEldestEntry(Map.Entry<K, V> eldest) {
return size() > capacity;
}
}
);
}
// 对外暴露的方法
public V get(K key) {
return lruCache.get(key);
}
public void put(K key, V value) {
lruCache.put(key, value);
}
public int size() {
return lruCache.size();
}
}总结
LinkedHashMap实现 LRU 的核心是构造时指定 accessOrder = true,让元素按访问顺序排序。- 重写
removeEldestEntry()方法是实现 "容量满时淘汰最久未使用元素" 的关键,只需判断size() > capacity。 - 相比手动实现 HashMap + 双向链表,该方式代码更简洁、不易出错,是实际开发中优先选择的方案(需线程安全时可包装成同步容器)。
2.使用java,实现 二叉树的前序、中序、后序遍历,递归和非递归两种方式都要实现
第一步:定义二叉树节点类
首先创建二叉树的基础节点结构,这是所有遍历操作的基础。
/**
* 二叉树节点定义
*/
class TreeNode {
// 节点值
int val;
// 左子节点
TreeNode left;
// 右子节点
TreeNode right;
public TreeNode(int val) {
this.val = val;
}
public TreeNode(int val, TreeNode left, TreeNode right) {
this.val = val;
this.left = left;
this.right = right;
}
}第二步:实现所有遍历方法
创建工具类,集中实现前序、中序、后序的递归和非递归遍历:
import java.util.ArrayList;
import java.util.List;
import java.util.Stack;
/**
* 二叉树遍历工具类(前序、中序、后序,递归+非递归)
*/
public class BinaryTreeTraversal {
// ======================== 前序遍历(根 -> 左 -> 右) ========================
/**
* 前序遍历 - 递归方式
*/
public List<Integer> preorderRecursive(TreeNode root) {
List<Integer> result = new ArrayList<>();
preorderRecursiveHelper(root, result);
return result;
}
private void preorderRecursiveHelper(TreeNode node, List<Integer> result) {
// 递归终止条件:节点为空
if (node == null) {
return;
}
// 1. 访问根节点
result.add(node.val);
// 2. 递归遍历左子树
preorderRecursiveHelper(node.left, result);
// 3. 递归遍历右子树
preorderRecursiveHelper(node.right, result);
}
/**
* 前序遍历 - 非递归方式(借助栈实现)
*/
public List<Integer> preorderIterative(TreeNode root) {
List<Integer> result = new ArrayList<>();
if (root == null) {
return result;
}
Stack<TreeNode> stack = new Stack<>();
// 根节点入栈
stack.push(root);
while (!stack.isEmpty()) {
// 1. 弹出栈顶节点并访问
TreeNode curr = stack.pop();
result.add(curr.val);
// 2. 先压右子节点(栈是后进先出,保证左子节点先被访问)
if (curr.right != null) {
stack.push(curr.right);
}
// 3. 再压左子节点
if (curr.left != null) {
stack.push(curr.left);
}
}
return result;
}
// ======================== 中序遍历(左 -> 根 -> 右) ========================
/**
* 中序遍历 - 递归方式
*/
public List<Integer> inorderRecursive(TreeNode root) {
List<Integer> result = new ArrayList<>();
inorderRecursiveHelper(root, result);
return result;
}
private void inorderRecursiveHelper(TreeNode node, List<Integer> result) {
if (node == null) {
return;
}
// 1. 递归遍历左子树
inorderRecursiveHelper(node.left, result);
// 2. 访问根节点
result.add(node.val);
// 3. 递归遍历右子树
inorderRecursiveHelper(node.right, result);
}
/**
* 中序遍历 - 非递归方式(借助栈实现)
*/
public List<Integer> inorderIterative(TreeNode root) {
List<Integer> result = new ArrayList<>();
if (root == null) {
return result;
}
Stack<TreeNode> stack = new Stack<>();
TreeNode curr = root;
// 循环条件:当前节点不为空 或 栈不为空
while (curr != null || !stack.isEmpty()) {
// 1. 先遍历到最左子节点,沿途节点入栈
while (curr != null) {
stack.push(curr);
curr = curr.left;
}
// 2. 弹出栈顶节点(最左节点)并访问
curr = stack.pop();
result.add(curr.val);
// 3. 处理右子树
curr = curr.right;
}
return result;
}
// ======================== 后序遍历(左 -> 右 -> 根) ========================
/**
* 后序遍历 - 递归方式
*/
public List<Integer> postorderRecursive(TreeNode root) {
List<Integer> result = new ArrayList<>();
postorderRecursiveHelper(root, result);
return result;
}
private void postorderRecursiveHelper(TreeNode node, List<Integer> result) {
if (node == null) {
return;
}
// 1. 递归遍历左子树
postorderRecursiveHelper(node.left, result);
// 2. 递归遍历右子树
postorderRecursiveHelper(node.right, result);
// 3. 访问根节点
result.add(node.val);
}
/**
* 后序遍历 - 非递归方式(双栈法,易于理解)
* 思路:前序遍历是 根->左->右,调整为 根->右->左,再反转结果得到 左->右->根
*/
public List<Integer> postorderIterative(TreeNode root) {
List<Integer> result = new ArrayList<>();
if (root == null) {
return result;
}
Stack<TreeNode> stack1 = new Stack<>();
Stack<TreeNode> stack2 = new Stack<>();
stack1.push(root);
while (!stack1.isEmpty()) {
TreeNode curr = stack1.pop();
// 压入辅助栈
stack2.push(curr);
// 先压左子节点(保证右子节点先被处理)
if (curr.left != null) {
stack1.push(curr.left);
}
// 后压右子节点
if (curr.right != null) {
stack1.push(curr.right);
}
}
// 弹出辅助栈,得到后序遍历结果
while (!stack2.isEmpty()) {
result.add(stack2.pop().val);
}
return result;
}
// ======================== 测试方法 ========================
public static void main(String[] args) {
// 构建测试二叉树:
// 1
// \
// 2
// /
// 3
TreeNode root = new TreeNode(1);
root.right = new TreeNode(2);
root.right.left = new TreeNode(3);
BinaryTreeTraversal traversal = new BinaryTreeTraversal();
// 前序遍历测试
System.out.println("前序遍历(递归):" + traversal.preorderRecursive(root)); // [1, 2, 3]
System.out.println("前序遍历(非递归):" + traversal.preorderIterative(root)); // [1, 2, 3]
// 中序遍历测试
System.out.println("中序遍历(递归):" + traversal.inorderRecursive(root)); // [1, 3, 2]
System.out.println("中序遍历(非递归):" + traversal.inorderIterative(root)); // [1, 3, 2]
// 后序遍历测试
System.out.println("后序遍历(递归):" + traversal.postorderRecursive(root)); // [3, 2, 1]
System.out.println("后序遍历(非递归):" + traversal.postorderIterative(root)); // [3, 2, 1]
}
}代码关键解释
- 递归遍历 :核心逻辑是 "分治思想",遵循遍历顺序(前序:根→左→右;中序:左→根→右;后序:左→右→根),递归终止条件是节点为
null。 - 非递归遍历 :
- 前序:利用栈的 "后进先出" 特性,先压右子节点、再压左子节点,保证弹出时先访问根、再左、最后右。
- 中序:先遍历到最左子节点(沿途入栈),弹出时访问节点,再处理右子树。
- 后序:采用 "双栈法",先按 "根→右→左" 遍历(类似前序调整),再反转结果得到 "左→右→根",是最易理解的后序非递归实现方式。
运行环境说明
- JDK 版本:JDK 8 及以上均可运行
- 无需额外依赖,直接编译运行即可
总结
- 递归遍历:代码简洁、逻辑直观,核心是遵循 "根、左、右" 的顺序调整递归调用位置,终止条件为节点为空。
- 非递归遍历:依赖栈模拟递归调用栈,前序 / 中序用单栈实现,后序用双栈法(或单栈 + 标记法)实现,核心是控制节点入栈 / 出栈顺序。
- 遍历顺序核心:前序(根先)、中序(根中)、后序(根后),非递归的关键是通过栈的特性模拟递归的节点访问顺序。
3.实现经典字符串匹配算法
暴力匹配简单易懂适合入门,KMP 算法效率更高(时间复杂度更优)。
一、暴力匹配算法(BF 算法)
暴力匹配是最基础的字符串匹配算法,核心思路是:从主串的每个位置开始,逐个字符与模式串比对,匹配失败则主串指针回退,模式串指针重置,直到匹配成功或遍历完主串。
代码实现
/**
* 字符串匹配算法工具类(暴力匹配 + KMP)
*/
public class StringMatch {
/**
* 暴力匹配(BF算法)
* @param mainStr 主串
* @param patternStr 模式串(要匹配的子串)
* @return 匹配成功返回模式串在主串中的起始索引,匹配失败返回 -1
*/
public static int bruteForceMatch(String mainStr, String patternStr) {
// 空串处理:模式串为空直接返回0,主串为空但模式串非空返回-1
if (patternStr == null || patternStr.isEmpty()) {
return 0;
}
if (mainStr == null || mainStr.isEmpty()) {
return -1;
}
int mainLen = mainStr.length();
int patternLen = patternStr.length();
// 主串剩余长度不足模式串长度,直接返回-1
if (mainLen < patternLen) {
return -1;
}
// i:主串指针,j:模式串指针
int i = 0;
int j = 0;
while (i < mainLen && j < patternLen) {
if (mainStr.charAt(i) == patternStr.charAt(j)) {
// 字符匹配,两个指针都后移
i++;
j++;
} else {
// 字符不匹配,主串指针回退(回到本次匹配起始位置的下一个),模式串指针重置
i = i - j + 1;
j = 0;
}
}
// 模式串指针遍历完,说明匹配成功
if (j == patternLen) {
return i - j;
}
// 匹配失败
return -1;
}
// ======================== KMP算法 ========================
/**
* KMP算法核心:构建部分匹配表(前缀函数数组)
* @param patternStr 模式串
* @return 部分匹配表(next数组),next[i]表示模式串前i+1个字符的最长相等前后缀长度
*/
private static int[] buildNextArray(String patternStr) {
int patternLen = patternStr.length();
int[] next = new int[patternLen];
// next[0] 初始化为0(单个字符无前后缀)
next[0] = 0;
// i:后缀指针(从1开始),j:前缀指针(最长相等前后缀长度)
int i = 1;
int j = 0;
while (i < patternLen) {
if (patternStr.charAt(i) == patternStr.charAt(j)) {
// 字符匹配,前缀指针后移,记录next值
j++;
next[i] = j;
i++;
} else {
if (j > 0) {
// 字符不匹配,前缀指针回退(利用已计算的next数组)
j = next[j - 1];
} else {
// j=0仍不匹配,next[i]设为0,后缀指针后移
next[i] = 0;
i++;
}
}
}
return next;
}
/**
* KMP字符串匹配
* @param mainStr 主串
* @param patternStr 模式串
* @return 匹配成功返回起始索引,失败返回-1
*/
public static int kmpMatch(String mainStr, String patternStr) {
// 空串处理
if (patternStr == null || patternStr.isEmpty()) {
return 0;
}
if (mainStr == null || mainStr.isEmpty()) {
return -1;
}
int mainLen = mainStr.length();
int patternLen = patternStr.length();
if (mainLen < patternLen) {
return -1;
}
// 构建部分匹配表
int[] next = buildNextArray(patternStr);
// i:主串指针(不回退),j:模式串指针
int i = 0;
int j = 0;
while (i < mainLen) {
if (mainStr.charAt(i) == patternStr.charAt(j)) {
// 字符匹配,两个指针都后移
i++;
j++;
// 模式串遍历完,匹配成功
if (j == patternLen) {
return i - j;
}
} else {
if (j > 0) {
// 字符不匹配,模式串指针根据next数组回退(主串指针不回退)
j = next[j - 1];
} else {
// j=0仍不匹配,主串指针后移
i++;
}
}
}
// 匹配失败
return -1;
}
// ======================== 测试方法 ========================
public static void main(String[] args) {
String mainStr = "ABCDABCEABCDABD";
String patternStr = "ABCDABD";
// 暴力匹配测试
int bfResult = bruteForceMatch(mainStr, patternStr);
System.out.println("暴力匹配结果:" + (bfResult == -1 ? "未匹配到" : "起始索引:" + bfResult));
// KMP匹配测试
int kmpResult = kmpMatch(mainStr, patternStr);
System.out.println("KMP匹配结果:" + (kmpResult == -1 ? "未匹配到" : "起始索引:" + kmpResult));
// 边界测试:模式串不存在
String patternStr2 = "XYZ";
System.out.println("暴力匹配(无匹配):" + bruteForceMatch(mainStr, patternStr2));
System.out.println("KMP匹配(无匹配):" + kmpMatch(mainStr, patternStr2));
}
}二、关键代码解释
1. 暴力匹配(BF)
- 核心逻辑:逐个比对主串和模式串的字符,匹配失败则主串指针回退到「本次匹配起始位置 + 1」,模式串指针重置为 0。
- 时间复杂度 :最坏情况 O(n∗m)(n 为主串长度,m 为模式串长度),比如主串是
AAAAA,模式串是AAAB。 - 优点:代码简单、易理解;缺点:效率低,存在大量重复比对。
2. KMP 算法
KMP 的核心是利用已匹配的部分信息,避免主串指针回退,通过「部分匹配表(next 数组)」确定模式串指针的回退位置。
- next 数组 :
next[i]表示模式串前i+1个字符的「最长相等前后缀长度」。例如模式串ABCDABD,next[5](对应子串ABCDAB)的最长相等前后缀是AB,长度为 2,所以next[5]=2。 - 匹配过程:主串指针始终不回退,模式串指针根据 next 数组回退,避免重复比对。
- 时间复杂度:O(n+m)(构建 next 数组O(m),匹配过程O(n)),效率远高于暴力匹配。
三、运行结果
暴力匹配结果:起始索引:8
KMP匹配结果:起始索引:8
暴力匹配(无匹配):-1
KMP匹配(无匹配):-1总结
- 暴力匹配(BF):适合入门理解字符串匹配的基本逻辑,代码简单但效率低,最坏情况会重复比对大量字符。
- KMP 算法:通过构建 next 数组避免主串指针回退,时间复杂度更优(O(n+m)),是工业级常用的字符串匹配算法。
- 核心区别:暴力匹配失败后主串指针回退,KMP 仅回退模式串指针,利用已匹配的前后缀信息减少重复比对。
4.java代码实现找出数组中第K大的数?
核心思路说明
找第 K 大的数有三种主流方案:
- 排序法:最简单直观,将数组排序后直接取对应位置的值
- 快速选择法:基于快速排序的分治思想,平均时间复杂度 O (n),效率最优
- 堆排序法:利用优先队列(堆),适合处理大数据量 / 流式数据场景
完整代码实现
import java.util.Arrays;
import java.util.PriorityQueue;
import java.util.Random;
/**
* 找出数组中第K大的数(三种实现方式)
*/
public class KthLargestNumber {
// ======================== 方案1:排序法(简单易理解) ========================
/**
* 排序法找第K大的数
* 思路:将数组升序排序后,第K大的数对应索引为 nums.length - k
*/
public static int findKthLargestBySort(int[] nums, int k) {
// 边界校验
validateParams(nums, k);
// 对数组进行升序排序
Arrays.sort(nums);
// 返回第K大的数(升序排序后,倒数第k个元素)
return nums[nums.length - k];
}
// ======================== 方案2:快速选择法(最优效率) ========================
/**
* 快速选择法找第K大的数(基于快速排序的分治思想)
* 平均时间复杂度O(n),最坏O(n²)(随机化基准值可避免)
*/
public static int findKthLargestByQuickSelect(int[] nums, int k) {
validateParams(nums, k);
// 第K大的数,对应快速选择中的目标位置(升序排序后的索引)
int targetIndex = nums.length - k;
// 调用快速选择核心方法
return quickSelect(nums, 0, nums.length - 1, targetIndex);
}
/**
* 快速选择核心方法
* @param nums 数组
* @param left 左边界
* @param right 右边界
* @param targetIndex 目标索引(升序排序后的位置)
* @return 目标值
*/
private static int quickSelect(int[] nums, int left, int right, int targetIndex) {
// 分区操作,返回基准值的最终位置
int pivotIndex = partition(nums, left, right);
if (pivotIndex == targetIndex) {
// 基准值位置等于目标位置,直接返回
return nums[pivotIndex];
} else if (pivotIndex < targetIndex) {
// 目标在右区间,递归处理右半部分
return quickSelect(nums, pivotIndex + 1, right, targetIndex);
} else {
// 目标在左区间,递归处理左半部分
return quickSelect(nums, left, pivotIndex - 1, targetIndex);
}
}
/**
* 分区操作(随机化基准值,避免最坏情况)
*/
private static int partition(int[] nums, int left, int right) {
// 随机选择基准值,交换到右边界
Random random = new Random();
int randomPivotIndex = left + random.nextInt(right - left + 1);
swap(nums, randomPivotIndex, right);
int pivot = nums[right]; // 基准值
int i = left - 1; // 小于基准值的区域边界
for (int j = left; j < right; j++) {
if (nums[j] <= pivot) {
i++;
swap(nums, i, j);
}
}
// 将基准值放到最终位置(i+1)
swap(nums, i + 1, right);
return i + 1;
}
/**
* 交换数组中两个元素
*/
private static void swap(int[] nums, int i, int j) {
int temp = nums[i];
nums[i] = nums[j];
nums[j] = temp;
}
// ======================== 方案3:堆排序法(适合大数据量) ========================
/**
* 堆排序法找第K大的数
* 思路:维护一个大小为k的小顶堆,遍历数组后堆顶即为第K大的数
*/
public static int findKthLargestByHeap(int[] nums, int k) {
validateParams(nums, k);
// 创建小顶堆(默认是小顶堆)
PriorityQueue<Integer> minHeap = new PriorityQueue<>(k);
for (int num : nums) {
if (minHeap.size() < k) {
// 堆大小不足k,直接入堆
minHeap.offer(num);
} else if (num > minHeap.peek()) {
// 当前数大于堆顶,替换堆顶(保证堆中是当前最大的k个数)
minHeap.poll();
minHeap.offer(num);
}
}
// 堆顶即为第K大的数
return minHeap.peek();
}
/**
* 参数校验
*/
private static void validateParams(int[] nums, int k) {
if (nums == null || nums.length == 0) {
throw new IllegalArgumentException("数组不能为空");
}
if (k < 1 || k > nums.length) {
throw new IllegalArgumentException("k必须在1到数组长度之间");
}
}
// ======================== 测试方法 ========================
public static void main(String[] args) {
int[] nums = {3, 2, 1, 5, 6, 4};
int k = 2; // 找第2大的数,预期结果是5
// 测试排序法
int result1 = findKthLargestBySort(Arrays.copyOf(nums, nums.length), k);
System.out.println("排序法结果:" + result1); // 输出5
// 测试快速选择法
int result2 = findKthLargestByQuickSelect(Arrays.copyOf(nums, nums.length), k);
System.out.println("快速选择法结果:" + result2); // 输出5
// 测试堆排序法
int result3 = findKthLargestByHeap(nums, k);
System.out.println("堆排序法结果:" + result3); // 输出5
// 边界测试:找第1大(最大)、第6大(最小)
System.out.println("第1大的数:" + findKthLargestByQuickSelect(nums, 1)); // 6
System.out.println("第6大的数:" + findKthLargestByQuickSelect(nums, 6)); // 1
}
}关键代码解释
1. 排序法
- 核心:利用
Arrays.sort()对数组升序排序,第 K 大的数对应索引nums.length - k - 优点:代码极简、易理解;缺点:时间复杂度 O (n log n),需要排序整个数组,存在性能浪费
2. 快速选择法(最优)
- 核心:基于快速排序的分区思想 ,不需要排序整个数组,只需要找到目标位置即可
partition方法:选择基准值,将数组分为「小于基准值」和「大于基准值」两部分,返回基准值的最终位置- 递归缩小范围:如果基准值位置等于目标位置(
nums.length - k),直接返回;否则递归处理左 / 右区间
- 优化:随机选择基准值,避免最坏情况(比如数组已排序时的 O (n²) 复杂度)
- 时间复杂度:平均 O (n),最坏 O (n²)(随机化后几乎不会出现)
3. 堆排序法
- 核心:维护一个大小为 k 的小顶堆 ,堆中始终保存当前遍历到的最大的 k 个数
- 堆大小不足 k 时,直接入堆
- 堆大小等于 k 时,若当前数大于堆顶,替换堆顶(保证堆中是最大的 k 个数)
- 优点:空间复杂度 O (k),适合处理大数据量 / 流式数据(不需要一次性加载所有数据);缺点:时间复杂度 O (n log k),略低于快速选择
运行结果
排序法结果:5
快速选择法结果:5
堆排序法结果:5
第1大的数:6
第6大的数:1总结
- 排序法:适合入门 / 小数据量场景,代码最简单但效率最低(O (n log n))。
- 快速选择法:面试 / 算法优化首选,平均时间复杂度 O (n),是找第 K 大 / 小元素的最优解法。
- 堆排序法:适合大数据量 / 流式数据场景,空间复杂度 O (k),时间复杂度 O (n log k),兼顾效率和内存占用。
- 核心注意点:使用前必须校验参数(k 的范围、数组非空),避免数组越界异常。
设计题:
设计一个高可用的文件上传服务,要考虑分片、重试、幂等这些点
我会为你设计一个高可用的文件上传服务 ,覆盖分片上传、失败重试、幂等性保障核心需求,并提供可落地的 Java 实现方案(包含核心代码、架构设计、关键机制说明)。
一、整体架构设计
先明确核心设计目标和整体架构,确保服务满足高可用要求:
1. 核心设计目标
- 分片上传:解决大文件上传超时 / 失败问题,将文件拆分为固定大小的分片并行上传
- 重试机制:分片上传失败后自动重试,支持断点续传
- 幂等性:避免重复上传导致文件损坏 / 存储冗余,保证多次上传同一文件结果一致
- 高可用:服务无状态化、分片元数据持久化、支持分布式部署
2. 整体架构
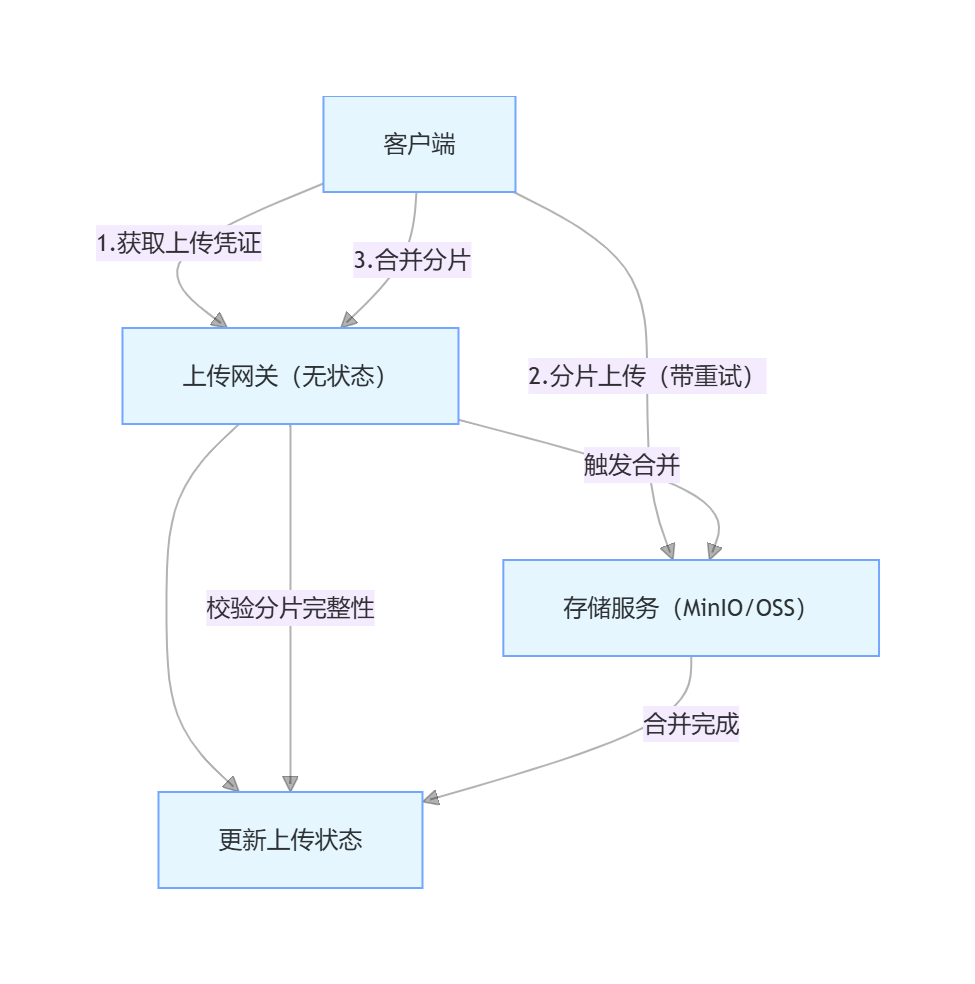
二、核心机制设计
1. 幂等性保障
- 唯一标识 :每个文件生成唯一
uploadId(基于文件 MD5 + 文件名 + 文件大小),客户端先通过uploadId查询上传状态,避免重复上传 - 分片幂等 :分片上传时携带
uploadId + chunkIndex,服务端校验该分片是否已上传,已上传则直接返回成功 - 合并幂等 :合并请求携带
uploadId,服务端校验是否已合并完成,避免重复合并
2. 分片上传流程
- 客户端计算文件 MD5,请求服务端生成
uploadId,服务端返回分片大小、总分片数、已上传分片列表(断点续传) - 客户端将文件拆分为分片,并行上传(每个分片携带
uploadId + chunkIndex + chunkMD5) - 所有分片上传完成后,客户端请求合并分片
- 服务端校验所有分片完整性,触发合并操作,生成最终文件
3. 重试机制
- 客户端重试:分片上传失败后,采用「指数退避」策略重试(1s→2s→4s,最多重试 3 次)
- 断点续传:服务端记录已上传分片,客户端可查询未上传分片,仅上传缺失部分
- 服务端容错:分片上传时先写入临时目录,合并完成后再移动到正式存储位置
三、核心代码实现
1. 核心实体类(元数据)
import lombok.Data;
import java.util.Set;
/**
* 文件上传元数据(持久化到Redis/Mysql)
*/
@Data
public class UploadMetadata {
/**
* 唯一上传标识(MD5+文件名+文件大小)
*/
private String uploadId;
/**
* 文件MD5
*/
private String fileMd5;
/**
* 文件名
*/
private String fileName;
/**
* 文件总大小(字节)
*/
private long totalSize;
/**
* 分片大小(字节,默认5MB)
*/
private long chunkSize = 5 * 1024 * 1024;
/**
* 总分片数
*/
private int totalChunks;
/**
* 已上传分片索引集合
*/
private Set<Integer> uploadedChunks;
/**
* 上传状态:INIT(初始化)、UPLOADING(上传中)、COMPLETED(已完成)、FAILED(失败)
*/
private UploadStatus status;
/**
* 最终文件存储路径
*/
private String finalPath;
/**
* 创建时间
*/
private long createTime;
/**
* 更新时间
*/
private long updateTime;
public enum UploadStatus {
INIT, UPLOADING, COMPLETED, FAILED
}
}2. 核心服务接口
import org.springframework.web.multipart.MultipartFile;
import java.util.Map;
import java.util.Set;
/**
* 文件上传核心服务
*/
public interface FileUploadService {
/**
* 初始化上传(生成uploadId,返回分片信息)
* @param fileMd5 文件MD5
* @param fileName 文件名
* @param totalSize 文件总大小
* @return 上传元数据(包含uploadId、已上传分片等)
*/
UploadMetadata initUpload(String fileMd5, String fileName, long totalSize);
/**
* 上传分片
* @param uploadId 上传唯一标识
* @param chunkIndex 分片索引(从0开始)
* @param chunkFile 分片文件
* @param chunkMd5 分片MD5(校验完整性)
* @return 是否上传成功
*/
boolean uploadChunk(String uploadId, int chunkIndex, MultipartFile chunkFile, String chunkMd5);
/**
* 查询已上传分片
* @param uploadId 上传唯一标识
* @return 已上传分片索引集合
*/
Set<Integer> getUploadedChunks(String uploadId);
/**
* 合并分片
* @param uploadId 上传唯一标识
* @return 最终文件路径
*/
String mergeChunks(String uploadId);
/**
* 校验文件是否已上传(幂等性核心)
* @param fileMd5 文件MD5
* @param fileName 文件名
* @param totalSize 文件总大小
* @return 已上传则返回文件路径,否则返回null
*/
String checkFileUploaded(String fileMd5, String fileName, long totalSize);
}3. 核心实现类(关键逻辑)
import org.springframework.beans.factory.annotation.Value;
import org.springframework.data.redis.core.RedisTemplate;
import org.springframework.stereotype.Service;
import org.springframework.web.multipart.MultipartFile;
import javax.annotation.Resource;
import java.io.File;
import java.io.FileOutputStream;
import java.io.IOException;
import java.nio.file.Files;
import java.nio.file.Path;
import java.nio.file.Paths;
import java.util.*;
import java.util.concurrent.TimeUnit;
@Service
public class FileUploadServiceImpl implements FileUploadService {
// 临时分片存储目录
@Value("${file.upload.temp-dir:/tmp/upload/temp}")
private String tempDir;
// 最终文件存储目录
@Value("${file.upload.final-dir:/tmp/upload/final}")
private String finalDir;
// Redis key前缀
private static final String REDIS_KEY_PREFIX = "upload:metadata:";
// 元数据过期时间(24小时,未完成上传则清理)
private static final long METADATA_EXPIRE_HOURS = 24;
@Resource
private RedisTemplate<String, Object> redisTemplate;
@Override
public UploadMetadata initUpload(String fileMd5, String fileName, long totalSize) {
// 1. 生成唯一uploadId(幂等性核心)
String uploadId = generateUploadId(fileMd5, fileName, totalSize);
String redisKey = REDIS_KEY_PREFIX + uploadId;
// 2. 检查是否已存在元数据(断点续传/幂等)
UploadMetadata metadata = (UploadMetadata) redisTemplate.opsForValue().get(redisKey);
if (metadata != null) {
return metadata;
}
// 3. 初始化元数据
metadata = new UploadMetadata();
metadata.setUploadId(uploadId);
metadata.setFileMd5(fileMd5);
metadata.setFileName(fileName);
metadata.setTotalSize(totalSize);
metadata.setTotalChunks((int) Math.ceil((double) totalSize / metadata.getChunkSize()));
metadata.setUploadedChunks(new HashSet<>());
metadata.setStatus(UploadMetadata.UploadStatus.INIT);
metadata.setCreateTime(System.currentTimeMillis());
metadata.setUpdateTime(System.currentTimeMillis());
// 4. 持久化元数据到Redis(设置过期时间)
redisTemplate.opsForValue().set(redisKey, metadata, METADATA_EXPIRE_HOURS, TimeUnit.HOURS);
return metadata;
}
@Override
public boolean uploadChunk(String uploadId, int chunkIndex, MultipartFile chunkFile, String chunkMd5) {
// 1. 校验参数
if (chunkFile.isEmpty() || uploadId == null || chunkIndex < 0) {
return false;
}
String redisKey = REDIS_KEY_PREFIX + uploadId;
UploadMetadata metadata = (UploadMetadata) redisTemplate.opsForValue().get(redisKey);
if (metadata == null) {
throw new IllegalArgumentException("上传元数据不存在,请先初始化上传");
}
// 2. 幂等性校验:该分片是否已上传
if (metadata.getUploadedChunks().contains(chunkIndex)) {
return true; // 已上传直接返回成功
}
// 3. 校验分片MD5(保证分片完整性)
try {
String actualChunkMd5 = calculateMD5(chunkFile.getInputStream());
if (!actualChunkMd5.equals(chunkMd5)) {
return false;
}
} catch (IOException e) {
return false;
}
// 4. 保存分片到临时目录
try {
// 临时分片路径:tempDir/uploadId/chunkIndex
Path chunkPath = Paths.get(tempDir, uploadId, String.valueOf(chunkIndex));
Files.createDirectories(chunkPath.getParent());
try (FileOutputStream fos = new FileOutputStream(chunkPath.toFile())) {
fos.write(chunkFile.getBytes());
}
// 5. 更新已上传分片集合(幂等性保障)
metadata.getUploadedChunks().add(chunkIndex);
metadata.setStatus(UploadMetadata.UploadStatus.UPLOADING);
metadata.setUpdateTime(System.currentTimeMillis());
redisTemplate.opsForValue().set(redisKey, metadata, METADATA_EXPIRE_HOURS, TimeUnit.HOURS);
return true;
} catch (IOException e) {
return false;
}
}
@Override
public Set<Integer> getUploadedChunks(String uploadId) {
String redisKey = REDIS_KEY_PREFIX + uploadId;
UploadMetadata metadata = (UploadMetadata) redisTemplate.opsForValue().get(redisKey);
return metadata == null ? new HashSet<>() : metadata.getUploadedChunks();
}
@Override
public String mergeChunks(String uploadId) {
String redisKey = REDIS_KEY_PREFIX + uploadId;
UploadMetadata metadata = (UploadMetadata) redisTemplate.opsForValue().get(redisKey);
if (metadata == null) {
throw new IllegalArgumentException("上传元数据不存在");
}
// 1. 幂等性校验:是否已合并完成
if (UploadMetadata.UploadStatus.COMPLETED.equals(metadata.getStatus())) {
return metadata.getFinalPath();
}
// 2. 校验所有分片是否上传完成
Set<Integer> uploadedChunks = metadata.getUploadedChunks();
int totalChunks = metadata.getTotalChunks();
for (int i = 0; i < totalChunks; i++) {
if (!uploadedChunks.contains(i)) {
throw new IllegalStateException("分片" + i + "未上传完成,无法合并");
}
}
// 3. 合并分片到最终文件
try {
// 最终文件路径:finalDir/fileMd5/文件名
String finalFileName = metadata.getFileMd5() + "_" + metadata.getFileName();
Path finalPath = Paths.get(finalDir, finalFileName);
Files.createDirectories(finalPath.getParent());
// 按分片索引顺序合并
try (FileOutputStream fos = new FileOutputStream(finalPath.toFile())) {
for (int i = 0; i < totalChunks; i++) {
Path chunkPath = Paths.get(tempDir, uploadId, String.valueOf(i));
fos.write(Files.readAllBytes(chunkPath));
// 删除临时分片文件
Files.deleteIfExists(chunkPath);
}
}
// 4. 删除临时目录
Files.deleteIfExists(Paths.get(tempDir, uploadId));
// 5. 更新元数据状态(标记为已完成)
metadata.setFinalPath(finalPath.toString());
metadata.setStatus(UploadMetadata.UploadStatus.COMPLETED);
metadata.setUpdateTime(System.currentTimeMillis());
redisTemplate.opsForValue().set(redisKey, metadata, METADATA_EXPIRE_HOURS, TimeUnit.HOURS);
return finalPath.toString();
} catch (IOException e) {
metadata.setStatus(UploadMetadata.UploadStatus.FAILED);
redisTemplate.opsForValue().set(redisKey, metadata, METADATA_EXPIRE_HOURS, TimeUnit.HOURS);
throw new RuntimeException("合并分片失败", e);
}
}
@Override
public String checkFileUploaded(String fileMd5, String fileName, long totalSize) {
// 生成uploadId,查询是否已完成上传
String uploadId = generateUploadId(fileMd5, fileName, totalSize);
String redisKey = REDIS_KEY_PREFIX + uploadId;
UploadMetadata metadata = (UploadMetadata) redisTemplate.opsForValue().get(redisKey);
if (metadata != null && UploadMetadata.UploadStatus.COMPLETED.equals(metadata.getStatus())) {
return metadata.getFinalPath();
}
return null;
}
// 生成唯一uploadId
private String generateUploadId(String fileMd5, String fileName, long totalSize) {
return fileMd5 + "_" + fileName.hashCode() + "_" + totalSize;
}
// 计算MD5(工具方法,省略实现)
private String calculateMD5(java.io.InputStream inputStream) throws IOException {
// 实现MD5计算逻辑
return "";
}
}4. 控制器(API 层)
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.http.HttpStatus;
import org.springframework.http.ResponseEntity;
import org.springframework.web.bind.annotation.*;
import org.springframework.web.multipart.MultipartFile;
import java.util.Map;
import java.util.Set;
@RestController
@RequestMapping("/api/file/upload")
public class FileUploadController {
@Autowired
private FileUploadService fileUploadService;
/**
* 初始化上传(获取uploadId)
*/
@PostMapping("/init")
public ResponseEntity<UploadMetadata> initUpload(
@RequestParam String fileMd5,
@RequestParam String fileName,
@RequestParam long totalSize) {
UploadMetadata metadata = fileUploadService.initUpload(fileMd5, fileName, totalSize);
return ResponseEntity.ok(metadata);
}
/**
* 上传分片
*/
@PostMapping("/chunk")
public ResponseEntity<Map<String, Boolean>> uploadChunk(
@RequestParam String uploadId,
@RequestParam int chunkIndex,
@RequestParam MultipartFile chunkFile,
@RequestParam String chunkMd5) {
boolean success = fileUploadService.uploadChunk(uploadId, chunkIndex, chunkFile, chunkMd5);
return ResponseEntity.ok(Map.of("success", success));
}
/**
* 查询已上传分片
*/
@GetMapping("/chunks")
public ResponseEntity<Set<Integer>> getUploadedChunks(@RequestParam String uploadId) {
Set<Integer> chunks = fileUploadService.getUploadedChunks(uploadId);
return ResponseEntity.ok(chunks);
}
/**
* 合并分片
*/
@PostMapping("/merge")
public ResponseEntity<Map<String, String>> mergeChunks(@RequestParam String uploadId) {
try {
String finalPath = fileUploadService.mergeChunks(uploadId);
return ResponseEntity.ok(Map.of("path", finalPath));
} catch (Exception e) {
return ResponseEntity.status(HttpStatus.INTERNAL_SERVER_ERROR)
.body(Map.of("error", e.getMessage()));
}
}
/**
* 校验文件是否已上传(幂等性)
*/
@GetMapping("/check")
public ResponseEntity<Map<String, Object>> checkFile(
@RequestParam String fileMd5,
@RequestParam String fileName,
@RequestParam long totalSize) {
String path = fileUploadService.checkFileUploaded(fileMd5, fileName, totalSize);
if (path != null) {
return ResponseEntity.ok(Map.of("uploaded", true, "path", path));
} else {
return ResponseEntity.ok(Map.of("uploaded", false));
}
}
}5. 客户端重试逻辑(伪代码)
/**
* 客户端分片上传工具(带重试)
*/
public class UploadClient {
// 最大重试次数
private static final int MAX_RETRY = 3;
/**
* 上传分片(带指数退避重试)
*/
public boolean uploadChunkWithRetry(String uploadId, int chunkIndex, File chunkFile, String chunkMd5) {
int retryCount = 0;
while (retryCount < MAX_RETRY) {
try {
// 调用服务端分片上传接口
boolean success = callUploadChunkApi(uploadId, chunkIndex, chunkFile, chunkMd5);
if (success) {
return true;
}
} catch (Exception e) {
// 记录异常日志
}
// 指数退避等待
long waitTime = (long) Math.pow(2, retryCount) * 1000;
try {
Thread.sleep(waitTime);
} catch (InterruptedException e) {
Thread.currentThread().interrupt();
return false;
}
retryCount++;
}
return false;
}
// 调用服务端接口(伪代码)
private boolean callUploadChunkApi(String uploadId, int chunkIndex, File chunkFile, String chunkMd5) {
// 实现HTTP请求逻辑
return false;
}
}四、高可用优化建议
- 存储层高可用:使用分布式对象存储(MinIO 集群 / 阿里云 OSS),避免单点故障
- 元数据高可用:Redis 采用主从 + 哨兵模式,Mysql 采用主从复制,保证元数据不丢失
- 服务端无状态:上传网关 / 业务服务部署多实例,通过负载均衡分发请求
- 超时控制:分片上传设置合理超时时间(如 30s),避免长时间占用连接
- 清理策略:定时清理超时未完成的上传任务(如 24 小时未完成),释放临时存储
- 监控告警:监控分片上传失败率、合并失败率,异常时及时告警
总结
- 幂等性 :核心是
uploadId+ 分片索引的唯一标识,服务端校验已上传状态,避免重复操作。 - 分片上传:拆分大文件为固定大小分片,支持并行上传和断点续传,解决大文件上传问题。
- 重试机制:客户端采用指数退避重试,服务端支持断点续传,保证上传过程容错。
- 高可用:无状态服务部署、分布式存储、元数据持久化,从架构层面保障服务不宕机。
该方案可直接落地,适配中小规模文件上传场景;若需支撑超大文件(GB 级),可进一步优化为「并行合并」「分片预校验」等机制。