目录
- 前言
- 一、贪心算法
-
- [1.1 推公式](#1.1 推公式)
-
- [1.1.1 拼数](#1.1.1 拼数)
- [1.1.2 保卫家园](#1.1.2 保卫家园)
- [1.1.3 奶牛玩杂技](#1.1.3 奶牛玩杂技)
- 结语


🎬 云泽Q :个人主页
🔥 专栏传送入口 : 《C语言》《数据结构》《C++》《Linux》《蓝桥杯系列》
⛺️遇见安然遇见你,不负代码不负卿~
前言
大家好啊,我是云泽Q,欢迎阅读我的文章,一名热爱计算机技术的在校大学生,喜欢在课余时间做一些计算机技术的总结性文章,希望我的文章能为你解答困惑~
一、贪心算法
1.1 推公式
如果细说的话,这个专题应该叫推公式+排序 。其中推公式就是寻找排序规则 ,排序就是在该排序规则下对整个对象排序。
在解决某些问题的时,当我们发现最终结果需要调整每个对象的先后顺序,也就是对整个对象排序时,那么我们就可以用推公式的方式,得出我们的排序规则,进而对整个对象排序。
正确性证明:
利用排序解决问题,最重要的就是需要证明"在新的排序规则下,整个集合可以排序"。这需要用到离散数学中"全序关系"的知识。我会在第一道题中证明该题的排序规则下,整个集合是可以排序的。
但是证明过程很麻烦,后续题目中我们只要发现该题最终结果需要排序,并且交换相邻两个元素的时候,对其余元素不会产生影响,那么我们就可以推导出排序的规则,然后直接去排序,就不去证明了。
1.1.1 拼数
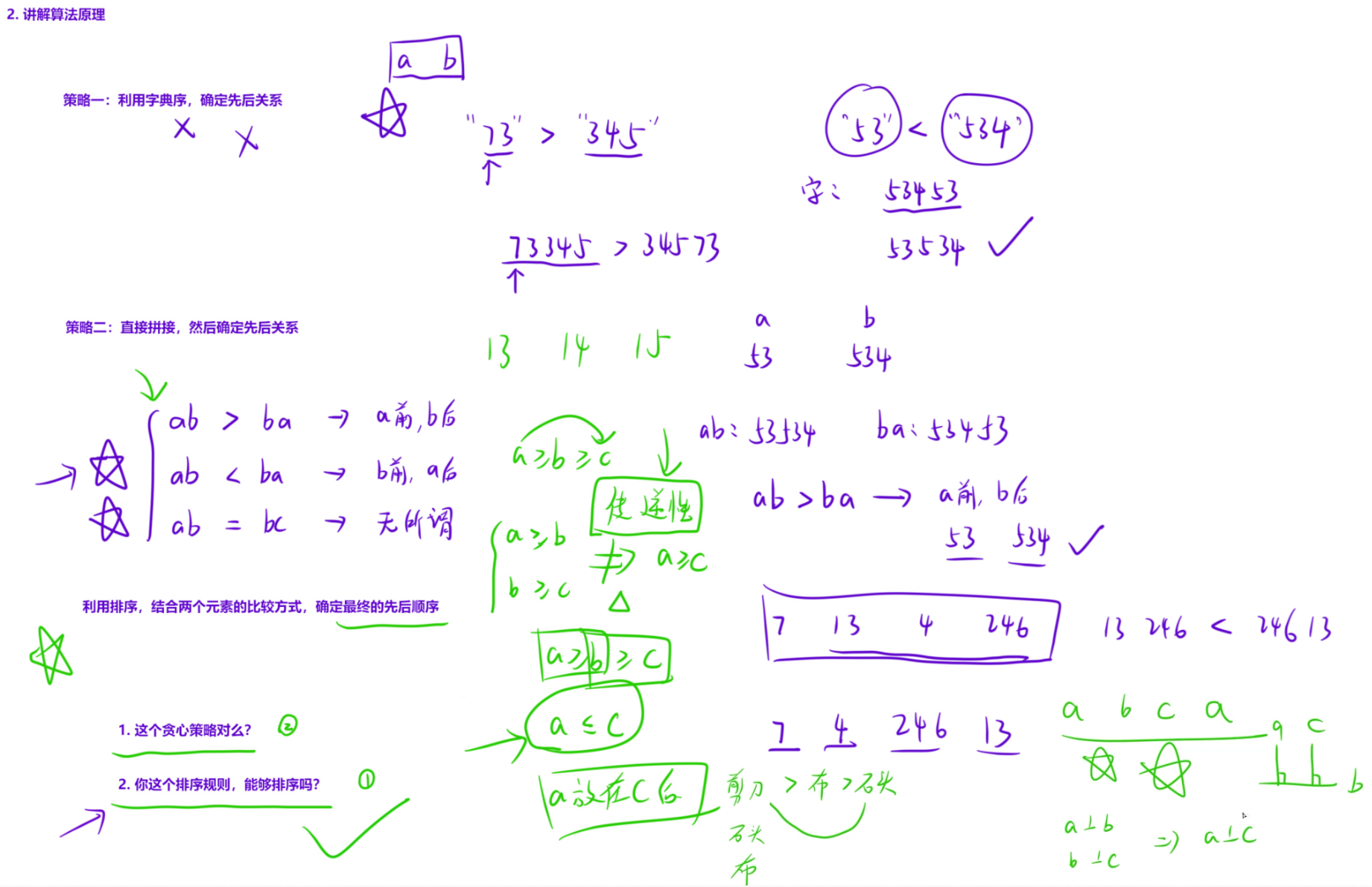

在该题目中,数据范围已经达到了109,并且拼接完之后数是逐渐变长的,用int是存不下最终的结果,因此这里用字符串把所有的数读进来,最终把这个字符串拼起来输出即可,这样也不用写高精度的计算了
cpp
#include <iostream>
#include <algorithm>
using namespace std;
const int N = 25;
int n;
string a[N];
bool cmp(string& x, string& y)
{
return x + y > y + x;
}
int main()
{
cin >> n;
for(int i = 1; i <= n; i++) cin >> a[i];
// 排序
sort(a + 1, a + 1 + n, cmp);
for(int i = 1; i <= n; i++) cout << a[i];
return 0;
}补充要点:
一、字符串字典序的基础比较规则
字符串的字典序比较,本质是逐位对比字符的 ASCII 码值,步骤如下:
- 从左到右依次比较两个字符串的每一位字符。
- 若某一位字符不同,字符更大的字符串整体字典序更大。
- 若一个字符串是另一个的前缀(如 "53" 和 "534"),则较短的字符串字典序更小(如 "53" < "534")。
二、为什么字符串 + 能直接拼接?
C++ 的标准库为 std::string 类重载了 + 运算符,它的行为和普通数值(int/float)的 + 完全不同:
- 对数值类型 (如 int a=123, b=456):a + b 是数值相加,结果是 579;
- 对字符串类型 (如 string a="123", b="456"):a + b 是字符串拼接,结果是 "123456"。
这个重载是 C++ 为字符串专门设计的语法糖,目的就是让字符串拼接操作更直观、更简洁。
字符串拼接后直接比较大小等价于数值大小比较
三、C++ sort 函数和自定义比较器的核心工作原理
C++ 的 sort 函数是一个通用排序工具,它本身不知道你想按 "从小到大""从大到小" 还是 "拼接更大" 排序 ------ 它完全依赖你传入的 cmp 函数来判断:
- cmp (a, b) 返回 true → 表示 a 应该排在 b 的前面;
- cmp (a, b) 返回 false → 表示 a 不应该排在 b 前面(即 b 应该排在 a 前面)。
这个规则是所有自定义排序的核心,cmp 函数的唯一作用就是给 sort 提供 "顺序判断依据",而实际的元素交换、排序逻辑都由 sort 内部完成(比如快排 / 归并算法),cmp 只负责 "投票"。
结合实际情况来说:
情况 1:x + y > y + x → 返回 true
比如 x="343",y="312":x+y="343312" > y+x="312343" → cmp(x,y)=true;
sort 收到 "true" 的结果,就知道 "x 应该在 y 前面",于是会把 x 放在 y 的前面(如果原本顺序不对,sort 会自动交换)。
情况 2:x + y < y + x → 返回 false
比如 x="13",y="312":x+y="13312" < y+x="31213" → cmp(x,y)=false;
sort 收到 "false" 的结果,就知道 "x 不应该在 y 前面",于是会把 y 放在 x 的前面。
情况 3:x + y = y + x → 返回 false
比如 x="12",y="12",此时 cmp 返回 false,sort 认为两者顺序无关紧要(谁前谁后拼接结果都一样)。
1.1.2 保卫家园
保卫家园
一、题目本质与核心思路
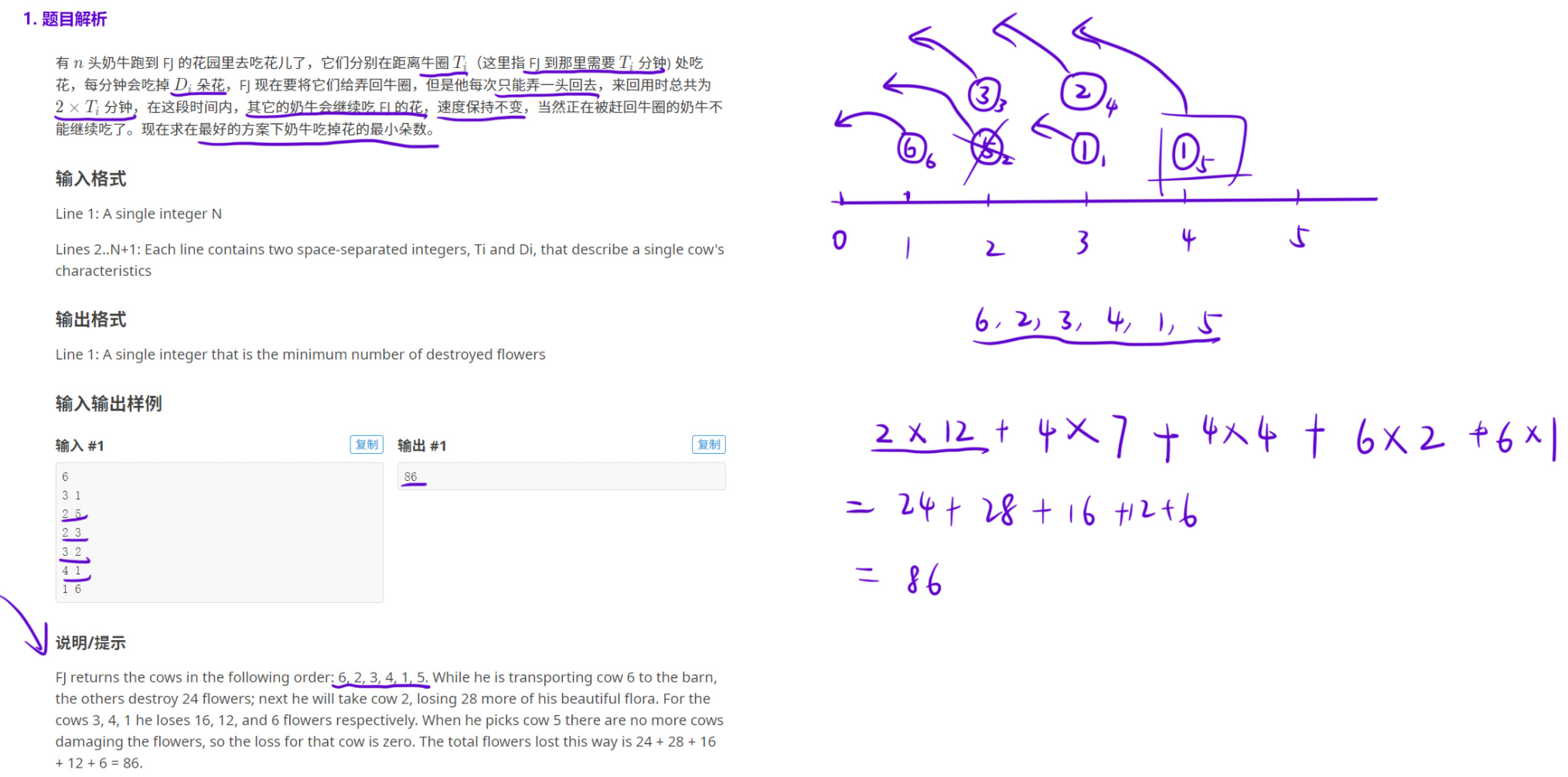
这是一道贪心排序类算法题 ,核心目标是通过最优赶牛顺序,让奶牛吃掉的总花数最少。
- 每赶一头牛,来回需要 2×Ti 分钟,这段时间里其他奶牛会继续吃花。
- 问题本质:确定赶牛顺序,使得「每头牛在被赶回前的存活时间 × 它的吃花速度 Di」的总和最小。
二、算法原理:相邻交换法推导排序规则
用相邻交换法 找到最优排序规则:
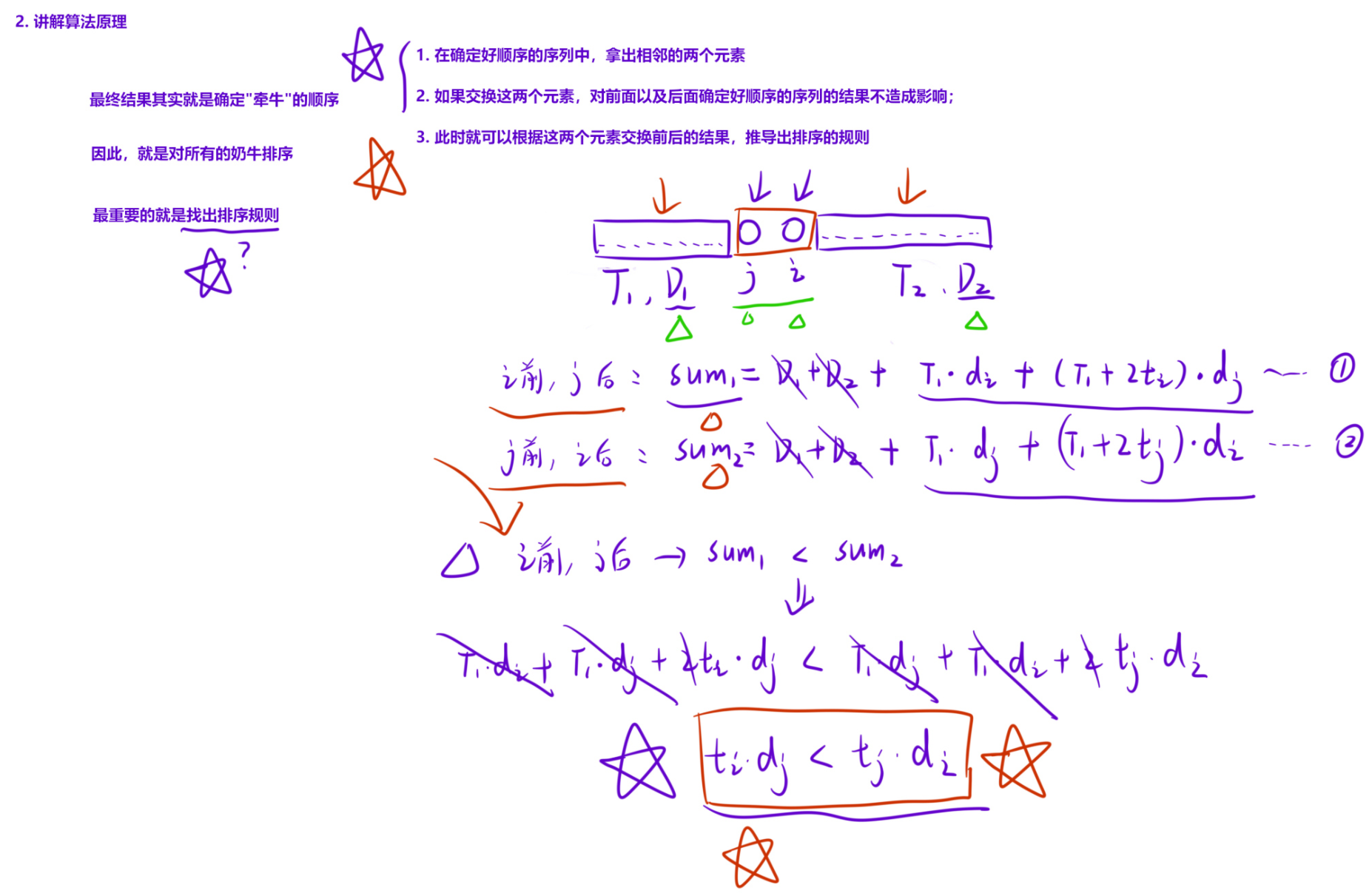
1. 问题简化
假设我们有两个相邻的奶牛 i(Ti,Di)和 j(Tj,Dj),交换它们的顺序不会影响:
- 前面已处理奶牛的时间(已经固定)
- 后面奶牛的总时间(2Ti+2Tj 交换后总和不变)因此只需比较交换 i 和 j 前后,这两头牛对总花数的贡献差异。
2. 贡献计算
-
情况 1:i 在前,j 在后
总贡献 = T×Di+(T+2Ti)×Dj(T 是处理 i,j 前已用的时间)
-
情况 2:j 在前,i 在后
总贡献 = T×Dj+(T+2Tj)×Di
3. 推导排序规则
如果 i 在 j 前比较好,对应的 sum1 应该小于 sum2:
T×Di+(T+2Ti)×Dj < T×Dj+(T+2Tj)×Di消去相同项 T(Di+Dj) 后化简:2TiDj < 2TjDi⟹Ti×Dj<Tj×Di这就是最优排序规则 :
当 Ti×Dj<Tj×Di 时,i 应该排在 j 前面。
cpp
#include<iostream>
#include<algorithm>
using namespace std;
const int N = 1e5 + 10;
typedef long long LL;
LL n;
struct node{
LL t;
LL d;
}a[N];
bool cmp(node& x, node& y)
{
return x.t * y.d < y.t * x.d;
}
int main()
{
cin >> n;
for(int i = 1; i <= n; i++)
{
cin >> a[i].t >> a[i].d;
}
sort(a + 1, a + 1 + n, cmp);
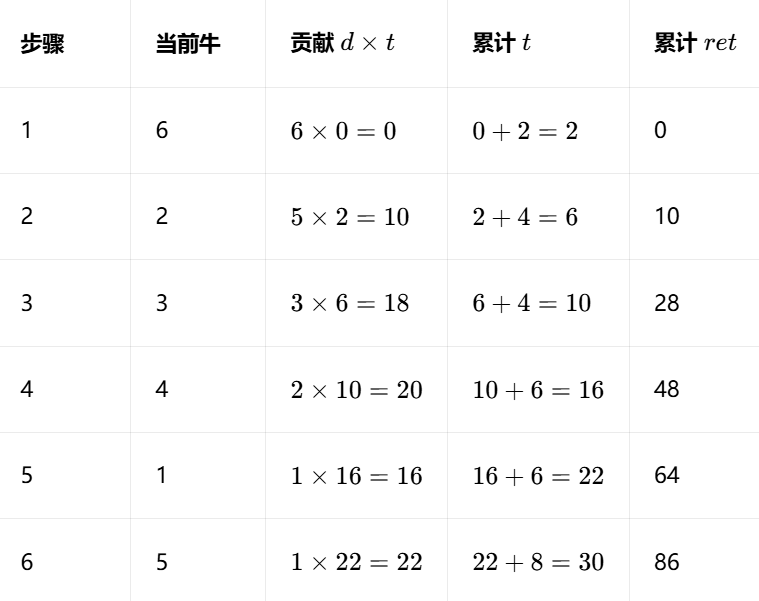
// ret:总花数,t:当前已用时间
LL ret = 0, t = 0;
for(int i = 1; i <= n; i++)
{
// 当前牛在被赶前,吃了t分钟花
ret += a[i].d * t;
// 赶这头牛的来回时间,累加到总时间
t += 2 * a[i].t;
}
cout << ret << endl;
return 0;
}三、样例验证
样例输入最优顺序:6→2→3→4→1→5
对应数据:
6: t=1,d=6
2: t=2,d=5
3: t=2,d=3
4: t=3,d=2
1: t=3,d=1
5: t=4,d=1
1.1.3 奶牛玩杂技

一、题目要求 :
我们需要将所有牛竖直堆叠 成一列,每头牛的 "压扁指数" 定义为:它上方所有牛的总重量(不包含自身重量)减去它的力量 si。
我们的目标是:找到一种堆叠顺序,使得所有牛的压扁指数的最大值尽可能小,最终输出这个最小的最大值。
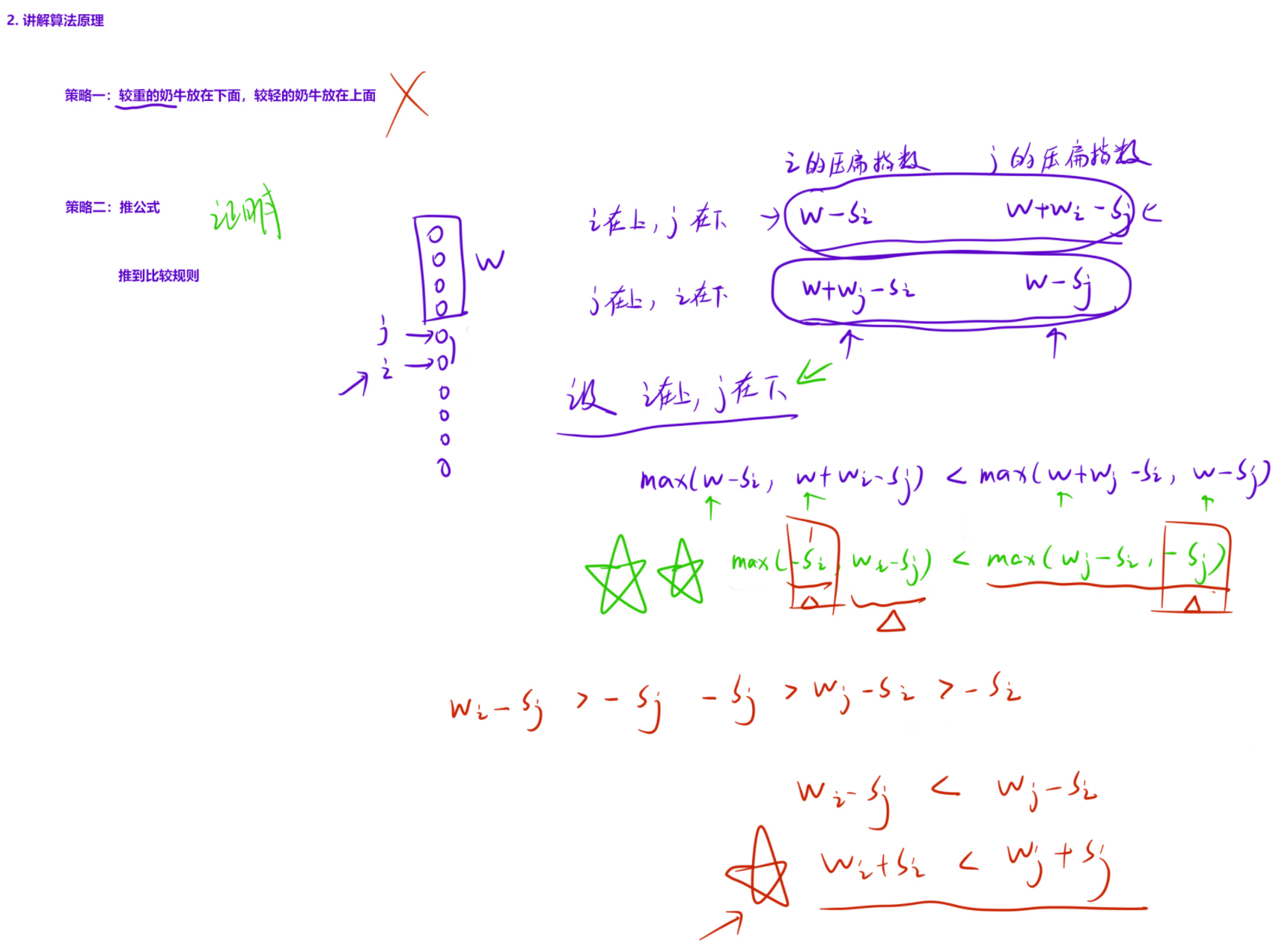
二、贪心策略推导
1. 局部最优分析
考虑任意两头牛 i 和 j,比较两种堆叠顺序:
- 情况 1:i 在上,j 在下
- 情况 2:j 在上,i 在下
设它们上方已有总重量为 W 的牛(这部分不影响两者相对顺序的比较)。
情况 1(i 在上,j 在下):
- i 的压扁指数:W−Si
- j 的压扁指数:W+Wi−Sj
- 两者最大值:max(W−Si, W+Wi−Sj)
情况 2(j 在上,i 在下):
- j 的压扁指数:W−Sj
- i 的压扁指数:W+Wj−Si
- 两者最大值:max(W−Sj, W+Wj−Si)
当i 应该放在 j 上方时:我们要让情况 1 的最大值 ≤ 情况 2 的最大值,即:max(W−Si, W+Wi−Sj)≤max(W−Sj, W+Wj−Si)
2. 不等式化简
两边同时减去 W,不等式方向不变:max(−Si, Wi−Sj)≤max(−Sj, Wj−Si)
进一步推导可得:当 Wi+Si<Wj+Sj 时,上述不等式成立 → i 应该放在 j 上方。
3. 全局策略
将所有牛按 w+s 升序排列(w+s 小的在上,大的在下),即可得到全局最优解。
cpp
#include<iostream>
#include<algorithm>
using namespace std;
const int N = 5e4 + 10;
typedef long long LL;
LL n;
struct node{
LL w;
LL s;
}a[N];
bool cmp(node& x, node& y)
{
//个人感觉不化简最好,少些操作不容易犯错
return max(-x.s, x.w - y.s) < max(y.w - x.s, -y.s);
}
int main()
{
cin >> n;
for(int i = 1; i <= n; i++) cin >> a[i].w >> a[i].s;
sort(a + 1, a + 1 + n, cmp);
LL ret = -1e9 - 10;
//记录当前牛上方所有牛的总重量(初始为 0,因为最上面的牛上方没有牛)
LL wight = 0;
for(int i = 1; i <= n; i++)
{
//计算当前牛的压扁指数,更新最大值
ret = max(ret, wight - a[i].s);
//将当前牛的重量加入总重量
wight += a[i].w;
}
cout << ret << endl;
return 0;
}补充要点:
ret 初始值为什么是 - 1e9-10?
压扁指数可能为负数(比如力量很大的牛),初始值需要足够小,确保第一个牛的压扁指数能覆盖它;
如果初始值为 0,会导致负数的压扁指数无法更新 ret,最终答案错误。
结语
