作者 :Feng Xiaokun1,2∗^{1,2*}1,2∗, Hu Shiyu3∗^{3*}3∗, Li Xuchen1,2,4^{1,2,4}1,2,4, Zhang Dailing1,2^{1,2}1,2, Wu Meiqi2^{2}2, Zhang Jing2^{2}2, Chen Xiaotang1,2^{1,2}1,2, Huang Kaiqi1,2†^{1,2\dagger}1,2†
单位:
- 中国科学院自动化研究所复杂系统认知与决策智能重点实验室
- 中国科学院大学
- 南洋理工大学物理与数学科学学院
- 中关村实验室
(*表示同等贡献,†\dagger†表示通讯作者)
https://arxiv.org/pdf/2507.19875
摘要
视觉 - 语言跟踪(Vision-Language Tracking, VLT)旨在利用初始帧提供的模板图像块和语言描述,在视频序列中定位目标对象。为了实现鲁棒的跟踪,特别是在最近 MGIT 基准所强调的反映现实世界条件的复杂长时场景中,不仅需要对目标特征进行表征,还必须利用与目标相关的上下文特征。然而,源自初始提示的视觉和文本目标 - 上下文线索通常仅与初始目标状态对齐。由于目标状态的动态性,它们在不断变化,尤其是在复杂的长时序列中。这些线索难以持续引导视觉 - 语言跟踪器(VLTs)。此外,对于表达方式多样的文本提示,我们的实验表明,现有的 VLT 难以辨别哪些词属于目标或上下文,这增加了利用文本线索的复杂性。
在本工作中,我们提出了一种名为 ATCTrack 的新型跟踪器,它通过全面的目标 - 上下文特征建模,获得与动态目标状态对齐的多模态线索,从而实现鲁棒跟踪。具体而言:(1) 对于视觉模态,我们提出了一种有效的时序视觉目标 - 上下文建模方法,为跟踪器提供及时的视觉线索。(2) 对于文本模态,我们仅基于文本内容实现精确的目标词识别,并设计了一种创新的上下文词校准方法,以自适应地利用辅助上下文词。(3) 我们在主流基准上进行了广泛的实验,ATCTrack 取得了新的最先进(SOTA)性能。代码和模型将发布于:https://github.com/XiaokunFeng/ATCTrack。
1. 引言
给定初始帧中的模板图像块和语言描述,视觉 - 语言跟踪(VLT)任务旨在视频序列中定位用户定义的对象。利用多模态的互补优势,最近的研究(以 MGIT 为代表)试图探索 VLT 在复杂长时序列中的性能。这些场景包含多方面的时空和因果关系,更准确地反映了现实世界的条件,同时也给跟踪器设计带来了新的挑战。
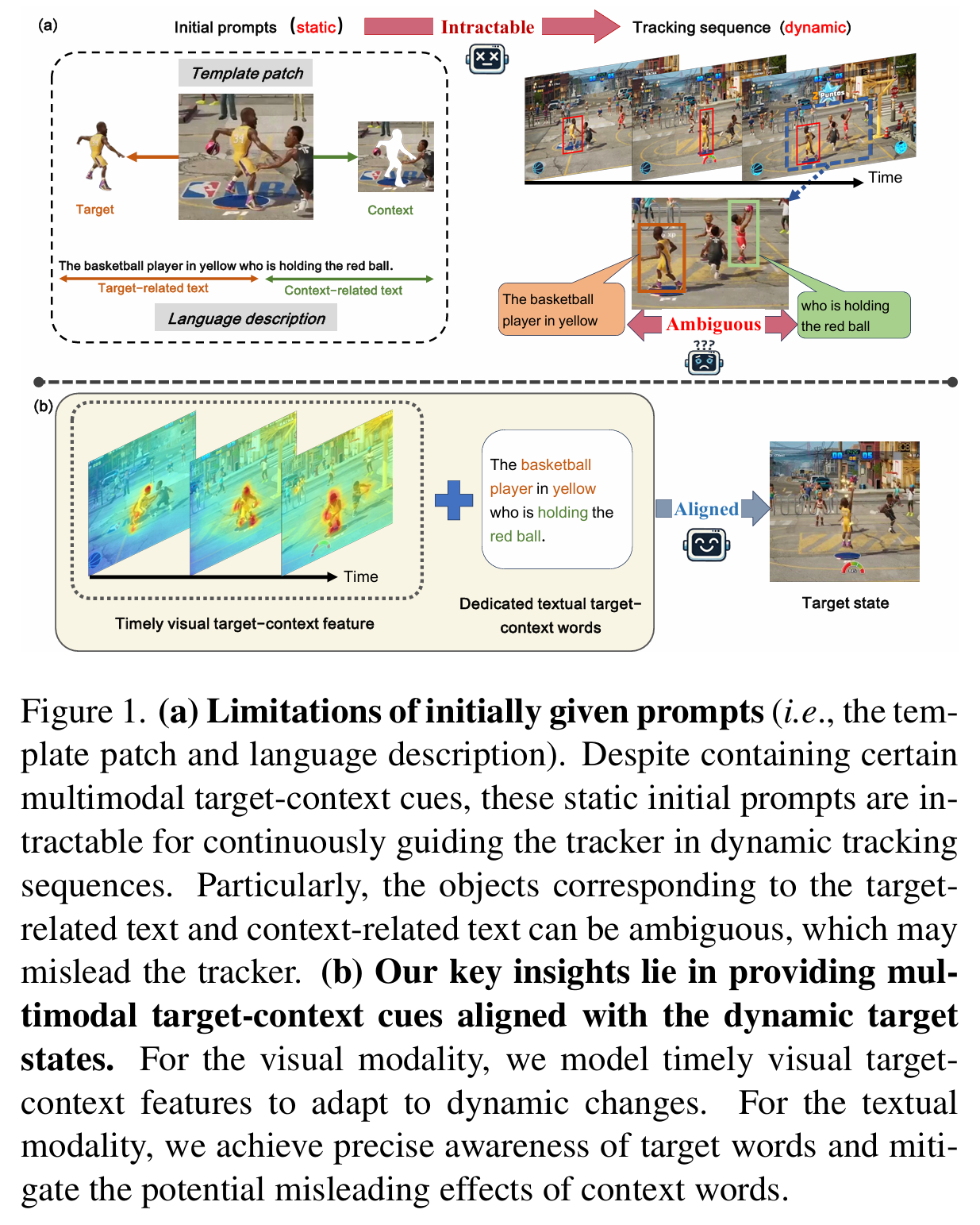
为了在这些环境中实现鲁棒跟踪,我们首先需要利用提供的视觉和文本线索来表征目标特征。如图 1(a) 所示,模板图像中的目标外观和语言描述中与目标相关的文本(例如目标类别、外观属性)为跟踪提供了基本参考信息。然而,复杂的长时场景通常伴随着遮挡和相似物体干扰等挑战,仅依靠这些目标线索是不够的。对目标的上下文特征进行建模也至关重要。具体而言,目标周围的视觉内容和与上下文相关的文本(例如其他参考物体)有助于更鲁棒的跟踪。因此,目标和上下文特征共同描绘了目标状态,有效地表示和利用目标 - 上下文特征对于处理复杂长时场景至关重要。
考虑到初始给定的提示携带了一定的多模态目标 - 上下文信息,大多数现有的 VLT(例如 VLTTT\mathrm{VLT}_{\mathrm{TT}}VLTTT 和 JointNLT)完全依赖它们进行跟踪。对于从第一帧裁剪的视觉模板图像,其裁剪区域是通过扩大目标的边界框确定的,因此包含了一些上下文特征。对于文本描述,整个句子被作为一个整体使用。虽然取得了一定效果,但它们忽略了目标状态固有的动态性质。在复杂的长时场景中,目标状态经常发生显著变化。如图 1(a) 所示,后续的目标状态逐渐偏离初始给定的提示。这种不对齐使得后者难以持续引导跟踪器。此外,对于文本提示,与目标相关的文本和与上下文相关的文本所对应的物体可能是模糊的,这可能会严重误导跟踪器。
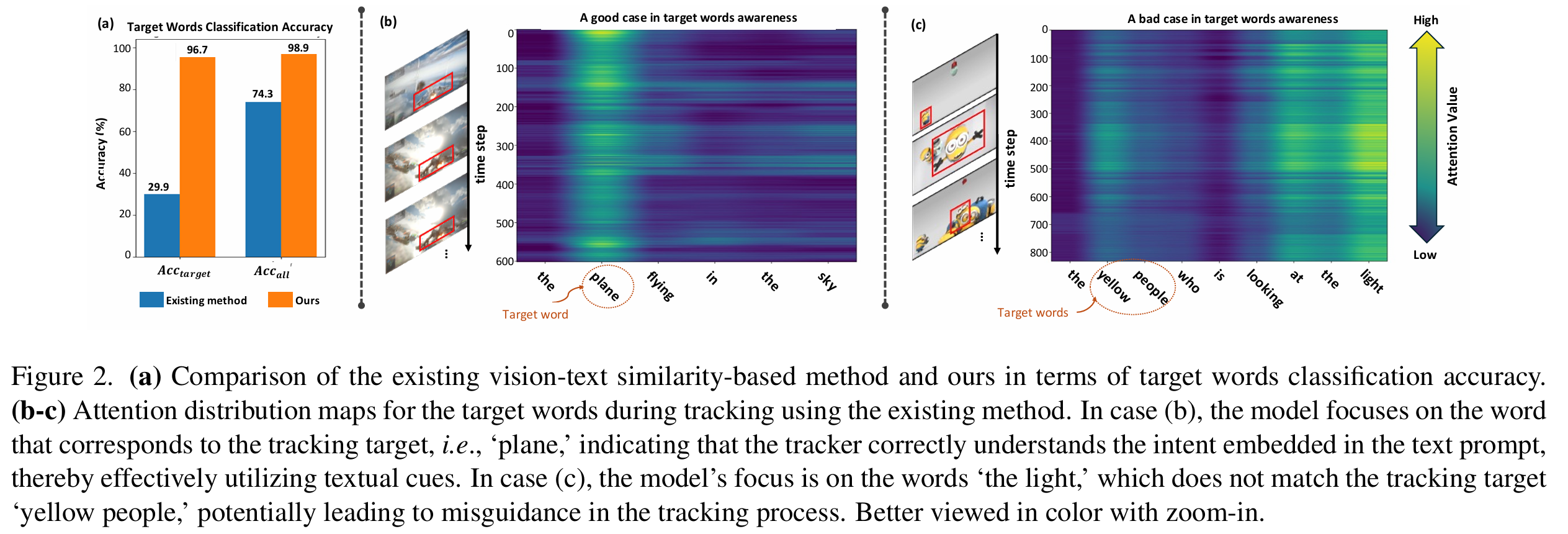
最近,一些 VLT(例如 QueryNLT 和 TTCTrack)尝试专门处理文本提示的不同单词成分,充分关注目标词并减轻上下文词的干扰。虽然动机良好,但这些努力要求跟踪器通过视觉 - 文本特征相似度自动区分目标和上下文词。由于缺乏监督信息和文本表达的多样性,我们发现这种方法并没有产生令人满意的结果。为了直观理解,图 2(b) 和 © 展示了使用该方法正确和错误识别目标词的案例。此外,图 2(a) 展示了定量评估结果,显示该方法实现的目标词分类准确率仅为 29.9%29.9\%29.9%。
为了解决上述问题,我们提出了一种名为 ATCTrack 的新型跟踪器,它通过全面建模目标 - 上下文 特征来获得与动态目标状态对齐 的多模态线索,从而实现鲁棒跟踪。我们的关键见解如图 1(b) 所示。对于视觉模态,我们设计了一种有效的时序视觉目标 - 上下文建模方法,为跟踪器提供及时的视觉线索。具体而言,我们显式构建目标 - 上下文空间分布图,并将其集成到更新的时序记忆中。对于文本模态,我们首先提出了一种仅基于文本内容的精确目标词感知方法。直观地说,即使不依赖视频数据,我们也可以纯粹从文本中识别目标词。例如,我们可以确定图 1(a) 中文本提示的目标词是"basketball player, yellow"。与现有依赖文本单词与视觉目标细粒度对齐的方法相比,我们的方法简化了任务,并实现了令人印象深刻的 96.7%96.7\%96.7% 的目标词分类准确率。鉴于现有基准中缺乏句子成分标签,我们设计了一个自动化的目标词标注流程,利用现成的的大型语言模型(LLMs)为模型训练提供监督标签。此外,利用准确识别的目标词,我们设计了一种创新的上下文词校准机制,以减轻上下文词线索潜在的误导影响。
得益于这些与动态目标状态对齐的多模态目标 - 上下文线索,ATCTrack 在主流基准(即 MGIT、TNL2K 和 LaSOText\mathrm{LaSOT}_{ext}LaSOText)上显著优于现有的 SOTA 方法。令人印象深刻的是,ATCTrack-B 在精度(Precision)上分别比现有最佳结果提高了 6.4%6.4\%6.4%、4.3%4.3\%4.3% 和 3.5%3.5\%3.5%。
我们的贡献如下:
- 我们提出了一种名为 ATCTrack 的新型跟踪器,它通过全面的目标 - 上下文特征建模,获得与动态目标状态对齐的多模态线索。与通常仅与初始目标状态对齐的初始提示的局限性相比,这些对齐的线索可以更鲁棒地引导跟踪。
- 对于视觉模态,ATCTrack 有效地建模时序视觉目标 - 上下文特征以捕捉及时的视觉线索。对于文本模态,ATCTrack 实现了对目标词的精确感知,并减轻了上下文词潜在的误导效应。
- 我们在主流基准上进行了广泛的实验,ATCTrack 取得了新的 SOTA 性能。
2. 相关工作
2.1 传统视觉 - 语言跟踪
视觉 - 语言跟踪通过结合文本描述扩展了经典的视觉单目标跟踪任务。许多早期的工作将初始提示视为核心参考信息,利用其中包含的多模态目标 - 上下文线索来引导跟踪。其中,SNLT 采用通用的语言区域提议网络来实现多模态线索与搜索特征的交互,然后使用聚合模块整合多尺度特征信息。为了增强跟踪器对齐视觉和文本模态的能力,All-in-One 和 UVLTrack 都设计了专门的对比损失以提高模型的多模态理解能力。虽然这些 VLT 取得了一定成功,但它们过度依赖静态初始线索,忽略了目标及其上下文的动态性质。当目标状态偏离初始线索时,这对保持鲁棒跟踪构成了挑战。
2.2 跟踪中的对象 - 上下文建模
为了适应目标状态的动态变化,许多跟踪器尝试利用时序特征来获取更新的目标 - 上下文线索。对于视觉模态,GTI 整合了跟踪和定位任务,用更新的定位结果替换模板。为了支持更长更密集的时序建模,一些跟踪器存储多步视觉时序特征作为额外记忆。一种代表性的方法是使用基于预测边界框的 RoI 特征作为记忆单元,例如 JointNLT 和 TrDiMP。鉴于这种局部裁剪方法只能捕获有限的视觉上下文信息,我们表示全局目标分布图并用它来构建时序视觉目标 - 上下文线索。
除了视觉模态外,最近的跟踪器专注于 VLT 特有的静态文本线索与动态目标状态之间不对齐的挑战。MemVLT 受提示学习启发,将动态目标特征压缩为一小组 token,并用它们隐式调制静态多模态线索。为了更明确地利用多模态线索,QueryNLT 从目标 - 上下文的角度处理问题,旨在通过动态视觉特征与文本线索之间的相互调制来获得准确的线索。虽然 QueryNLT 与我们的工作有相似的动机,但其关键的调制过程需要 VLT 中视觉目标与文本单词之间的细粒度对齐。如图 2(a) 所示,我们进行了定量评估,发现该方法无法有效识别目标和上下文词。相比之下,我们设计了一种直接基于文本内容的准确目标词感知方法,并引入了一种有效的校准机制以减轻上下文词的误导效应。
3. 方法
ATCTrack 的框架如图 3 所示。给定多模态线索和搜索图像,文本编码器和视觉编码器首先将它们编码到特定的特征空间。然后,文本目标 - 上下文引导模块和视觉目标 - 上下文引导模块依次建模与动态搜索目标对齐的全面文本和视觉目标 - 上下文特征,并将它们嵌入到搜索特征中。在此过程中,记忆存储模块(MSM)提供存储的视觉记忆特征并保存更新的记忆信息。最后,预测头用于基于嵌入的搜索特征获得跟踪结果。在以下章节中,我们将详细介绍每个模块。
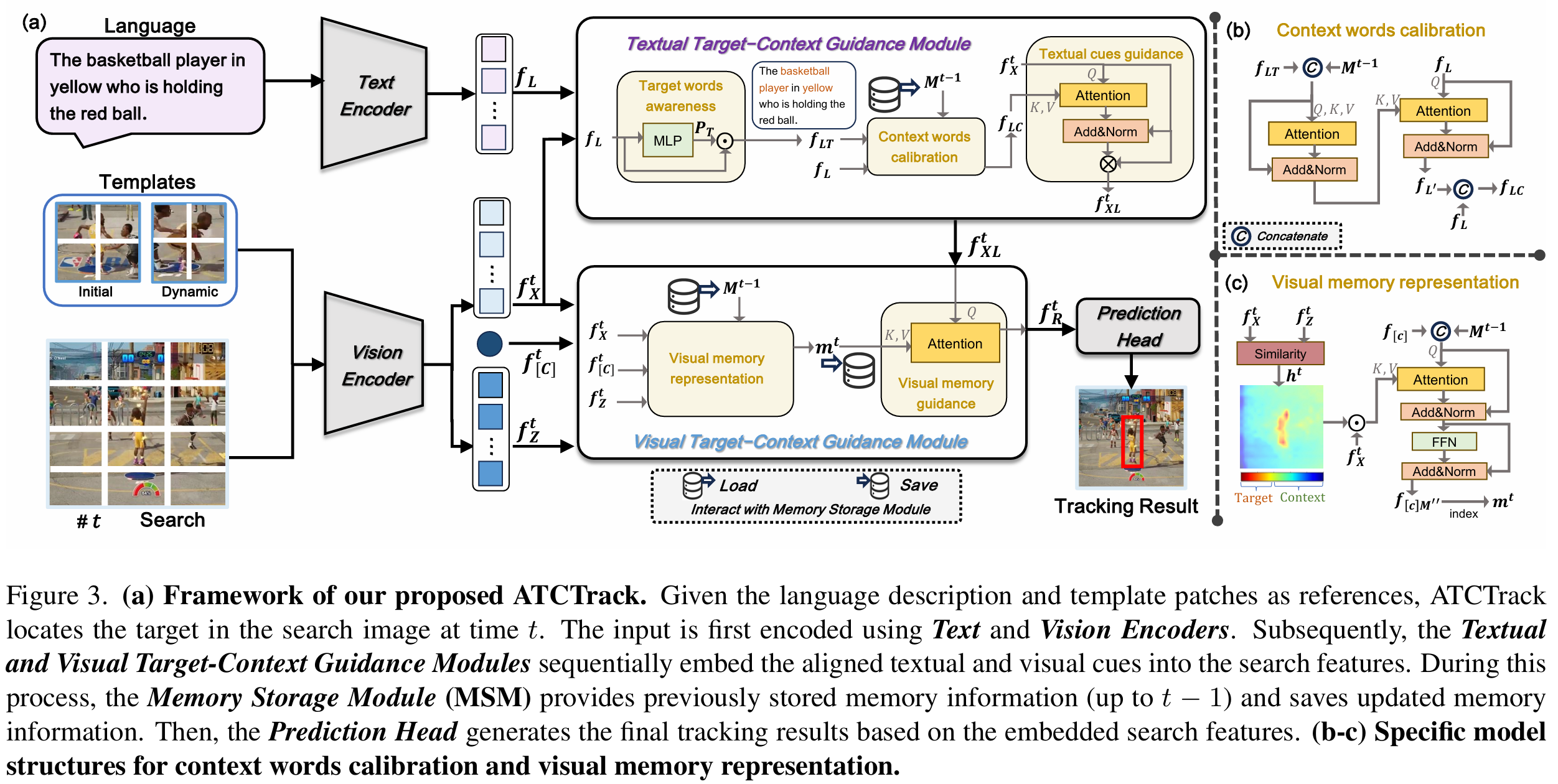
3.1 输入编码器
视觉编码器 。在时间步 ttt,我们的视觉输入包括搜索图像 xt∈R3×Hx×Wxx_{t}\in\mathbb{R}^{3\times H_{x}\times W_{x}}xt∈R3×Hx×Wx,初始模板图像块 z0∈R3×Hz×Wzz_{0}\in\mathbb{R}^{3\times H_{z}\times W_{z}}z0∈R3×Hz×Wz,以及基于跟踪结果更新的动态模板图像块 zt∈R3×Hz×Wzz_{t}\in\mathbb{R}^{3\times H_{z}\times W_{z}}zt∈R3×Hz×Wz。我们采用已被近期主流跟踪器广泛使用的单流网络编码范式。具体而言,xt,z0x_{t}, z_{0}xt,z0 和 ztz_{t}zt 首先被投影为 token 嵌入。此外,受 MemVLT 启发,我们引入一个可学习的 CLS token 来捕获全局视觉语义特征。该 token 与模板 - 搜索 token 连接并输入到 Transformer 层进行特征提取和关系建模。最后,我们获得编码后的搜索特征 fXt∈RNx×Df_{X}^{t}\in\mathbb{R}^{N_{x}\times D}fXt∈RNx×D,对应于两个模板图像的模板特征 fZt∈RNz×Df_{Z}^{t}\in\mathbb{R}^{N_{z}\times D}fZt∈RNz×D,以及聚合的 CLS token fCt∈R1×Df_{C}^{t}\in\mathbb{R}^{1\times D}fCt∈R1×D。
文本编码器 。我们利用经典的预训练模型 RoBERTa 作为文本编码器。具体而言,对于给定的句子,我们将其分词为文本 token 序列。然后将 token 序列输入到 Transformer 层以提取文本嵌入特征 fL∈RNl×Df_{L}\in\mathbb{R}^{N_{l}\times D}fL∈RNl×D。
3.2 文本目标 - 上下文引导模块
为了充分利用文本线索,该模块的关键见解是仔细调制初始文本提示,以充分关注目标词并减轻上下文词潜在的误导效应。如图 3 所示,我们首先从文本内容中显式识别目标词。然后,我们设计了一种上下文词校准机制,利用识别出的目标词和记忆存储模块(MSM)提供的视觉记忆特征来有效利用上下文词。最后,我们将调制后的文本特征与搜索特征集成,以实现文本线索的引导。
目标词感知。与上下文词相比,目标词中的信息通常是恒定的,可以作为跟踪的一致线索。然而,文本表达的多样性使得准确识别目标词具有挑战性。现有的 VLT(如 QueryNLT 和 TTCTrack)尝试基于视觉 - 文本相似度来区分它们。这种对细粒度多模态对齐的要求增加了学习难度。直观地说,我们可以仅基于文本内容识别目标词。因此,我们将目标词的识别简化为一个多标签二分类任务,确定句子中的每个词是否属于目标词。
考虑到现有基准中缺乏相关标签,我们设计了特定的提示并利用 LLM 强大的文本理解能力构建了一个自动化且可靠的目标词标注流程。利用这种定制的目标词标签信息,我们发现可以使用建立在初始文本特征 fLf_{L}fL 之上的轻量级多层感知机(MLP)实现准确的目标词感知:
pT=MLP(fL),p_{T}=MLP(f_{L}),pT=MLP(fL),
其中 pT∈0,1Nl×1p_{T}\in0,1^{N_{l}\times1}pT∈0,1Nl×1 表示每个文本 token 是目标词的概率。通过用 pTp_{T}pT 加权 fLf_{L}fL,我们获得目标词特征 fLT∈RNl×Df_{LT}\in\mathbb{R}^{N_{l}\times D}fLT∈RNl×D。
上下文词校准。上下文词与目标状态之间的对齐决定了它们是引导还是误导跟踪器。确定利用上下文词时机的一个直观方法是根据目标状态的动态演变进行评估。因此,这个建模过程需要 MSM 存储的时序记忆特征,它代表了最新的视觉目标 - 上下文信息。此外,由于上下文信息依赖于目标的位置,准确感知目标特征有助于捕获精确的上下文信息。
基于这些见解,我们上下文词校准机制的核心是首先通过整合识别出的目标词和视觉时序特征来增强目标特征的表示。然后,这些增强的特征被用来调制初始文本特征,以自适应地利用上下文词。
在当前时间 ttt,MSM 存储了直到时间步 t−1t-1t−1 的 LmL_{m}Lm 个记忆单元,记为 Mt−1={mi}i=1LmM^{t-1}=\{m_{i}\}{i=1}^{L{m}}Mt−1={mi}i=1Lm。如图 3(b) 所示,我们首先利用视觉记忆特征 Mt−1M^{t-1}Mt−1 和文本目标词 fLTf_{LT}fLT 之间的互补性来增强目标特征表示。具体而言,我们将这两个特征连接:
fLM=fLT;M∗t−1.f_{LM}=f_{LT};M_{\*}\^{t-1}.fLM=fLT;M∗t−1.
其中 ;;; 表示沿第一维度的连接,M∗t−1∈RLm×DM_{*}^{t-1}\in\mathbb{R}^{L_{m}\times D}M∗t−1∈RLm×D 是 Mt−1M^{t-1}Mt−1 中元素的连接。考虑到 Transformer 层在建模特征交互方面的卓越能力,我们对 fLMf_{LM}fLM 应用 vanilla Transformer 注意力操作:
fLM′=Norm(fLM+ΦCA(fLM,fLM)).f_{LM'}=Norm(f_{LM}+\Phi_{CA}(f_{LM},f_{LM})).fLM′=Norm(fLM+ΦCA(fLM,fLM)).
这里,ΦCA(⋅,⋅)\Phi_{CA}(\cdot,\cdot)ΦCA(⋅,⋅) 表示交叉注意力操作,其中第一个元素作为查询 Q,第二个元素用于获取键 K 和值 V。NormNormNorm 表示层归一化操作。
随着目标特征的增强,周围的上下文信息也被间接更准确地感知。因此,我们使用 fLM′f_{LM'}fLM′ 来调制初始静态文本 fLf_{L}fL,允许对上下文词进行自适应校准。通过以下注意力操作,我们获得精心校准的文本特征 fL′∈RNl×Df_{L'}\in\mathbb{R}^{N_{l}\times D}fL′∈RNl×D:
fL′=Norm(fL+ΦCA(fL,fLM′)).f_{L'}=Norm(f_{L}+\Phi_{CA}(f_{L},f_{LM'})).fL′=Norm(fL+ΦCA(fL,fLM′)).
文本线索引导 。受最近生成模型连接各种类型文本特征以供利用的启发,我们将初始文本和校准文本视为两种不同类型并连接它们以获得综合文本特征 fLC=fL;fL′f_{LC}=f_{L};f_{L'}fLC=fL;fL′。然后,我们采用基于 Transformer 的交叉注意力操作和残差乘法来获得嵌入了文本线索的视觉搜索特征 fXLt∈RNx×Df_{XL}^{t}\in\mathbb{R}^{N_{x}\times D}fXLt∈RNx×D。
3.3 视觉目标 - 上下文引导模块
如图 3 所示,该模块由两个核心过程组成:视觉记忆表示和引导,旨在建模和利用与目标状态对齐的动态视觉目标 - 上下文记忆。与稀疏动态模板相比,视觉记忆可以提供更密集的时序特征。这两种机制共同为跟踪器提供全面的时序信息。对于视觉记忆表示,我们显式构建目标 - 上下文分布图并建模不同时间步的记忆特征。随后,我们将存储在多个时间步的记忆线索嵌入到搜索特征中,从而引导跟踪过程。
视觉记忆表示 。对于视觉编码器编码的 CLS token fCtf_{C}^{t}fCt,由于它参与了视觉信息的整个特征集成过程,因此它适合作为全局视觉特征表示。因此,一个直观的方法是将 fCtf_{C}^{t}fCt 视为当前时间步的记忆表示。然而,由于视觉编码器是模型早期特征建模阶段的一部分,可能尚未充分感知精确的目标位置,这意味着 fCtf_{C}^{t}fCt 缺乏对目标 - 上下文分布信息的显式感知。因此,我们尝试显式构建目标 - 上下文分布热力图并将其嵌入到 fCtf_{C}^{t}fCt 中以获得我们的视觉记忆。
具体而言,我们通过计算编码后的搜索特征 fXtf_{X}^{t}fXt 和模板特征 fZtf_{Z}^{t}fZt 之间的相似度来构建目标 - 上下文分布热力图:
ht=(fXt⋅(fZt)T).mean(dim=1).h^{t}=(f_{X}^{t}\cdot(f_{Z}^{t})^{T}).mean(dim=1).ht=(fXt⋅(fZt)T).mean(dim=1).
由于 fZtf_{Z}^{t}fZt 以目标为中心,ht∈RNx×1h^{t}\in\mathbb{R}^{N_{x}\times1}ht∈RNx×1 反映了每个搜索 token 属于目标(即不属于上下文)的概率。图 3© 中的热力图是通过将 hth^{t}ht 重塑为二维图像空间获得的,展示了其在指示目标 - 上下文空间分布方面的高可解释性。
接下来,将 hth^{t}ht 嵌入到 fCtf_{C}^{t}fCt 中以构建当前记忆单元 mtm^{t}mt。为了在构建 mtm^{t}mt 时提供更丰富的目标 - 上下文动态信息,我们引入了 MSM 中存储的直到步骤 t−1t-1t−1 的历史记忆 Mt−1M^{t-1}Mt−1。注意,M 中的 LmL_{m}Lm 个记忆单元是通过在不同时间步迭代存储 mtm^{t}mt 获得的。假设 Mt−1M^{t-1}Mt−1 已获得,我们将在下文详细阐述每个记忆单元的生成过程,而 M 的更新机制将在 3.4 节中介绍。
在实现上,我们采用 vanilla 交叉注意力机制。特别是,我们将 fCtf_{C}^{t}fCt 和 M∗t−1M_{*}^{t-1}M∗t−1 的特征连接以获得 fCMf_{CM}fCM 作为查询,同时使用 hth^{t}ht 加权的 fxtf_{x}^{t}fxt 作为键和值:
fCM′=Norm(fCM+ΦCA(fCM,ht⊙fXt)),fCM′′=Norm(fCM′+FFN(fCM′)). \begin{aligned} &f_{CM'}=Norm(f_{CM}+\Phi_{CA}(f_{CM},h^t\odot f^t_X)),\\ &\quad f_{CM''}=Norm(f_{CM'}+FFN(f_{CM'})). \end{aligned} fCM′=Norm(fCM+ΦCA(fCM,ht⊙fXt)),fCM′′=Norm(fCM′+FFN(fCM′)).
其中 ⊙\odot⊙ 表示 Hadamard 积,FFNFFNFFN 表示前馈网络。基于连接索引,我们从 fCM′′f_{CM''}fCM′′ 中提取对应于 fCtf_{C}^{t}fCt 的特征,并将其用作当前时间步的记忆单元 mtm^{t}mt。这建立了我们的记忆单元生成机制。生成的 mtm^{t}mt 随后被存储在 MSM 中用于后续时间步的计算。
视觉记忆引导 。对于结合了当前和历史目标 - 上下文特征信息的 mtm^{t}mt,我们采用无参数注意力操作来促进其与搜索特征 fXLtf_{XL}^{t}fXLt 的交互:
fRt=softmax(fXLt⋅(mt)TD)⋅mt,f_{R}^{t}=softmax(\frac{f_{XL}^{t}\cdot(m^{t})^{T}}{\sqrt{D}})\cdot m^{t},fRt=softmax(D fXLt⋅(mt)T)⋅mt,
这里,fRt∈RNx×Df_{R}^{t}\in\mathbb{R}^{N_{x}\times D}fRt∈RNx×D 表示结合了文本和视觉记忆线索的搜索特征,随后被送入预测头。
3.4 记忆存储模块
如前所述,该模块为跟踪器(在 ttt 时刻)提供存储的记忆特征 Mt−1M^{t-1}Mt−1(直到 t−1t-1t−1)。同时,它存储新生成的记忆单元 mtm^{t}mt 以引导下一时间步 (t+1)(t+1)(t+1) 的跟踪过程。M 中的 LmL_{m}Lm 个记忆单元用第一帧的 fC0f_{C}^{0}fC0 初始化,并使用简单但广泛采用的滑动窗口方法进行更新。
3.5 预测头与损失
基于集成了多模态线索的搜索特征 fRtf_{R}^{t}fRt,我们利用经典的基于 CNN 的预测头来获得最终的边界框。我们采用 focal loss LclsL_{cls}Lcls、L1L_{1}L1 loss 和广义 IoU loss LiouL_{iou}Liou 来监督边界框的预测,这些在跟踪器设计中广泛使用。此外,对于目标词分类任务,我们采用二元交叉熵损失 LbceL_{bce}Lbce 进行监督。总体损失函数公式如下:
Lall=Lcls+2×Liou+5×L1+L2+0.2×Lbce.(9)L_{all}=L_{cls}+2\times L_{iou}+5\times L_{1}+L_{2}+0.2\times L_{bce}. \quad (9)Lall=Lcls+2×Liou+5×L1+L2+0.2×Lbce.(9)
4. 实验
4.1 实现细节
我们采用 RoBERTa-Base 作为文本编码器,并遵循近期先进跟踪器的做法,采用 HiViT 作为视觉编码器。为了平衡性能和计算效率,我们开发了两种模型变体:ATCTrack-B 和 ATCTrack-L,分别初始化为 Fast-iTPN-B 和 Fast-iTPN-L,token 维度 DDD 分别为 512 和 768。模板图像块和搜索图像的大小分别为 128×128128 \times 128128×128 和 256×256256 \times 256256×256。此外,MSM 的默认长度设置为 4,动态模板更新策略遵循 STARK。我们的跟踪器在配备四个 A5000 GPU 的服务器上训练,并在 RTX-3090 GPU 上测试。ATCTrack-B/L 的跟踪速度为 35/30 FPS。
我们使用 LaSOT、TNL2K、RefCOCOg、OTB99-Lang、VastTrack、GOT-10k 和 TrackingNet 的训练分割来训练模型。对于缺乏文本注释的 GOT-10k 和 TrackingNet,我们遵循 All-in-One 的策略,将类别名称视为伪语言标签。每个训练样本包含一个文本描述、两个模板图像块和来自同一视频序列的四个搜索帧。我们的跟踪器通过顺序选择搜索图像进行迭代训练。网络参数使用 AdamW 优化器优化 150 个 epoch,每个 epoch 包含 20,000 个随机采样的实例。
4.2 与最先进方法的比较
MGIT 。MGIT 是最新专为复杂长时场景定制的 VLT 基准。如表 1 所示,ATCTrack 在代表性的动作粒度上表现出优越的性能。特别是,ATCTrack-B 在曲线下面积 (AUC)、归一化精度 (PNorm\mathrm{P}_{\mathrm{Norm}}PNorm) 和精度分数 § 上分别超越 SOTA 跟踪器 MemVLT 4.3%4.3\%4.3%、3.2%3.2\%3.2% 和 6.4%6.4\%6.4%。
TNL2K 。TNL2K 也是为 VLT 任务设计的,引入"对抗样本"和"模态切换"等属性显著增加了挑战。如表 1 所示,ATCTrack-L 在 P 指标上比近期的 ChatTracker-L 高出 4.8%4.8\%4.8%。
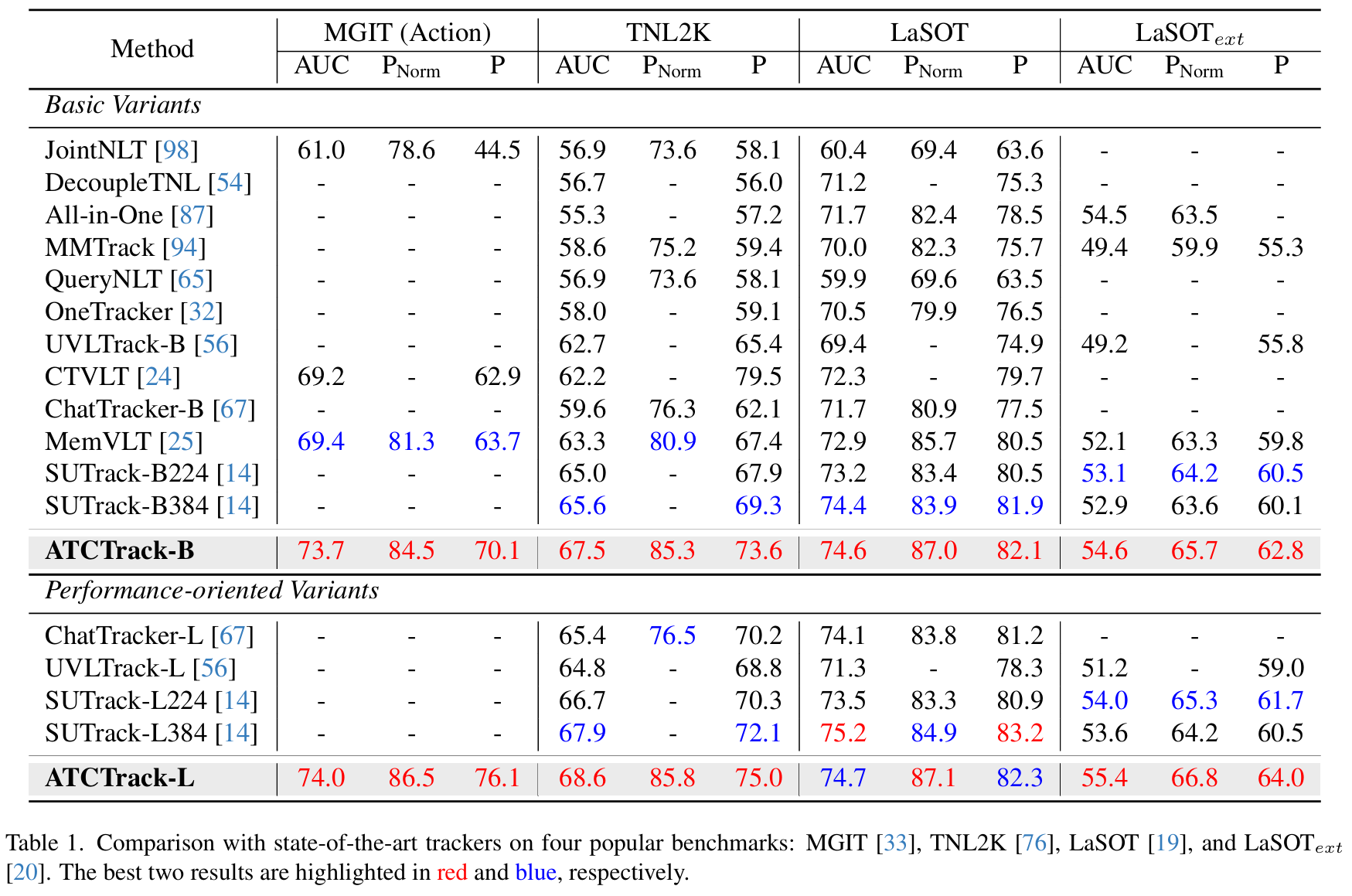
LaSOT & LaSOText\mathrm{LaSOT}_{ext}LaSOText 。它们是传统视觉跟踪基准的扩展,通过添加文本标签,专注于长时跟踪挑战。此外,LaSOText\mathrm{LaSOT}_{ext}LaSOText 还包含许多相似的干扰物,进一步使跟踪任务复杂化。如表 1 所示,除了 AUC 和 P 分数略低于利用更大图像分辨率和更多训练数据集的 SUTrack-L384 外,ATCTrack 在所有其他指标上均表现出极具竞争力的性能。

定性比较。如图 4 所示,我们展示了 ATCTrack-B 和两个现有 SOTA VLT 在四个具有挑战性的序列上的跟踪结果。在这些案例中,目标的外观发生了显著变化,且语言描述包含可能导致歧义的上下文词。显然,我们的 ATCTrack 表现出更强的鲁棒性和有效性。
4.3 消融实验
为了研究 ATCTrack 中各个模块的特性,我们在 TNL2K 和 LaSOT 上使用 ATCTrack-B 进行了全面的消融实验。
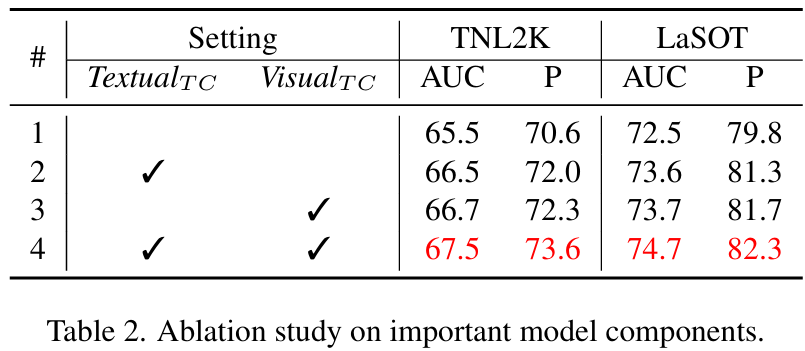
重要模型组件的研究 。我们工作的核心贡献是引入了一种新颖的多模态目标 - 上下文建模机制。表 2 (#1) 展示了仅使用初始提示和动态模板引导跟踪器的结果。表 2 (#2) 和 (#3) 分别展示了使用我们的文本和视觉目标 - 上下文引导模块的结果。相比之下,我们的方法在 TNL2K 上分别获得了 1.0%1.0\%1.0% 和 1.2%1.2\%1.2% 的 AUC 增益,证明了我们方法的有效性。此外,表 2 (#4) 表明结合这两个模块提供了互补的收益,进一步提升了跟踪性能。
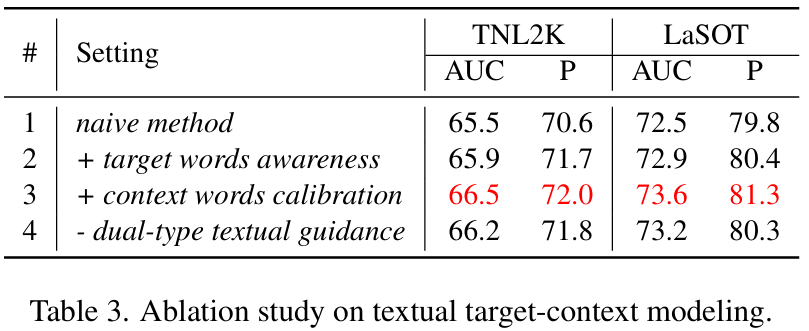
文本目标 - 上下文建模的研究 。表 3 (#1) 将文本特征作为一个整体处理,不加区分地将其与视觉特征融合。表 3 (#2) 和 (#3) 依次结合了目标词感知和上下文词校准机制,以建模和利用与目标状态对齐的文本目标 - 上下文线索。性能的逐步提升证明了我们提出的文本引导方法的有效性。此外,我们利用初始和校准后的文本特征 fLCf_{LC}fLC 进行跟踪引导。表 3 (#4) 展示了仅使用校准后的文本特征 fL′f_{L'}fL′ 的结果。与表 3 (#3) 相比,模型性能的下降表明双类型文本特征有助于跟踪器利用更全面的信息。
此外,我们定量评估了我们方法与现有基于视觉 - 文本相似度的方法在目标词识别准确率上的表现。如图 2(a) 所示,尽管仅使用轻量级多层感知机,我们的方法取得了令人印象深刻的准确率,识别目标词的整体准确率 (Accall\mathrm{Acc}_{\mathrm{all}}Accall) 达到 98.9%98.9\%98.9%。
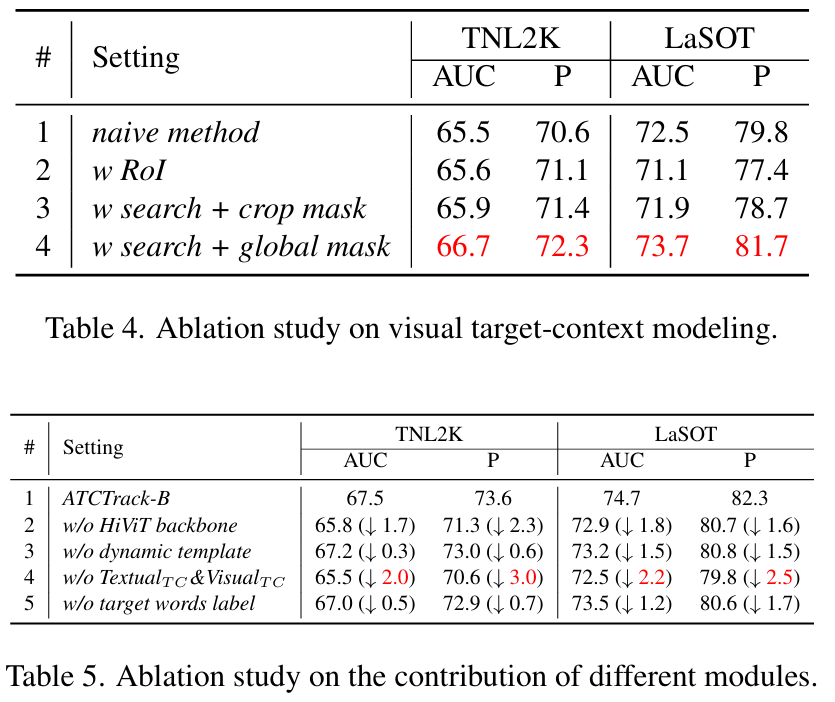
视觉目标 - 上下文建模的研究。表 4 (#1) 展示了仅使用稀疏初始和动态模板图像块时的结果。为了建模和利用更密集的动态目标 - 上下文特征,我们提出了视觉目标 - 上下文引导模块。表 4 (#3, #4, #5) 探索了不同的实现方法。相比之下,我们的方法(即表 4 (#5))取得了更好的结果,证明了从全局角度表示目标 - 上下文信息的必要性。
进一步的消融实验。表 5 显示了移除不同模块(如 HiViT 骨干网、动态模板、多模态目标 - 上下文引导模块和目标词标签)的影响。结果表明,ATCTrack 的优越性能主要源于我们提出的多模态目标 - 上下文引导方法。
5. 结论
为了追求鲁棒的视觉 - 语言跟踪,特别是在反映现实世界条件的复杂长时场景中,我们提出了一种名为 ATCTrack 的新型跟踪器。通过全面的目标 - 上下文建模,我们获得了与动态目标状态对齐的多模态线索,为初始静态线索无法提供持续引导的障碍提供了创新的解决方案。对于文本模态,我们引入了一种精确的目标词感知方法以确保充分关注目标词,并设计了一种创新的上下文词校准机制以减轻潜在的误导效应。对于视觉模态,我们有效地表征了时序目标 - 上下文特征,为跟踪提供及时的视觉线索。通过这些共同努力,我们的模型取得了出色的性能,在四个主流基准上显著超越了现有方法。
致谢
本工作部分得到了中国国家自然科学基金(批准号:62176255)的支持。
ATCTrack:将目标 - 上下文线索与动态目标状态对齐以实现鲁棒的视觉 - 语言跟踪
A. 目标词标注流程
鉴于文本描述本质上具有灵活性和多样性,跟踪器很难准确识别目标词和上下文词。在我们的工作中,我们将目标词的识别视为一个多标签二分类任务,通过监督学习增强模型识别目标词的能力。然而,现有的基准数据集 20, 33, 61, 76 仅提供文本描述,而没有关于目标词类型(即目标词或上下文词)的标注信息。对于这样一个自然语言处理任务,我们利用大语言模型 37, 70 强大的文本理解能力,构建了一个自动化的目标词标注流程。具体而言,我们采用了广泛使用的多模态大语言模型 GPT-4o 37,并设计了一个特定的核心提示词(prompt)来引导 GPT-4o 识别目标词(如图 A1 所示)。

利用我们的自动化标注流程,我们完成了 MGIT 33、TNL2K 76、LaSOT 19、RefCOCOg 57、OTB99-Lang 49 和 Vasttrack 61 数据集中文本数据的目标词标注。我们对标注结果进行了随机抽样,检查了 50 个句子,发现标注完全准确。这确保了我们用于分类目标词的监督模型的可靠性。未来,我们将开源目标词标签信息和我们的代码。
B. 目标词识别的评估
在本节中,我们讨论了图 2(a) 所示的目标词分类准确率结果的具体实现方法。最近的研究,如 QueryNLT 65、TTCTrack 58 和 OSDT 89,利用视觉 - 文本相似度指标来识别目标词。虽然这是它们的主要贡献之一,但它们并未提供定量的评估结果。为此,我们基于从 A 节获得的目标词标签信息进行了定量分析。
B.1. 基于相似度的目标词识别
考虑到 QueryNLT 65、TTCTrack 58 和 OSDT 89 尚未开源其代码,我们采用 JointNLT 98(一种具有代表性的视觉 - 语言跟踪器)作为代理模型进行评估。JointNLT 的核心思想是使用单流网络联合建模文本、模板图像和搜索图像的特征提取与交互。这些元素之间广泛的特征交互在一定程度上可以代表上述工作中为测量视觉 - 文本相似度所进行的特征交互操作。
具体而言,在时间步 ttt (t≥0t \ge 0t≥0),经过 JointNLT 骨干网络的特征编码后,我们获得视觉特征 ftV∈R400×512f^V_t \in \mathbb{R}^{400 \times 512}ftV∈R400×512 和文本特征 ftL∈RL×512f^L_t \in \mathbb{R}^{L \times 512}ftL∈RL×512。这里,视觉 token 的长度固定为 400,而文本 token 的长度 LLL 由句子中的单词数量决定。它们之间的相似度通过以下操作获得:
attlv=(ftL)T⋅ftV,(A1) att^v_l = (f^L_t)^T \cdot f^V_t, \quad \text{(A1)} attlv=(ftL)T⋅ftV,(A1)
其中 attlv∈RL×400att^v_l \in \mathbb{R}^{L \times 400}attlv∈RL×400 表示每个视觉 token 和文本 token 之间的相似度。通过对搜索 token 维度取平均,我们可以确定每个文本 token 在当前时间步 ttt 获得的注意力,记为 atttl∈RLatt^l_t \in \mathbb{R}^Latttl∈RL。
通过将视频序列中每个时间步的 atttlatt^l_tatttl 沿时间维度拼接,我们可以获得该序列的文本特征信息热力图,记为 Attl∈RL×TAtt^l \in \mathbb{R}^{L \times T}Attl∈RL×T,其中 TTT 代表视频序列中的帧数。
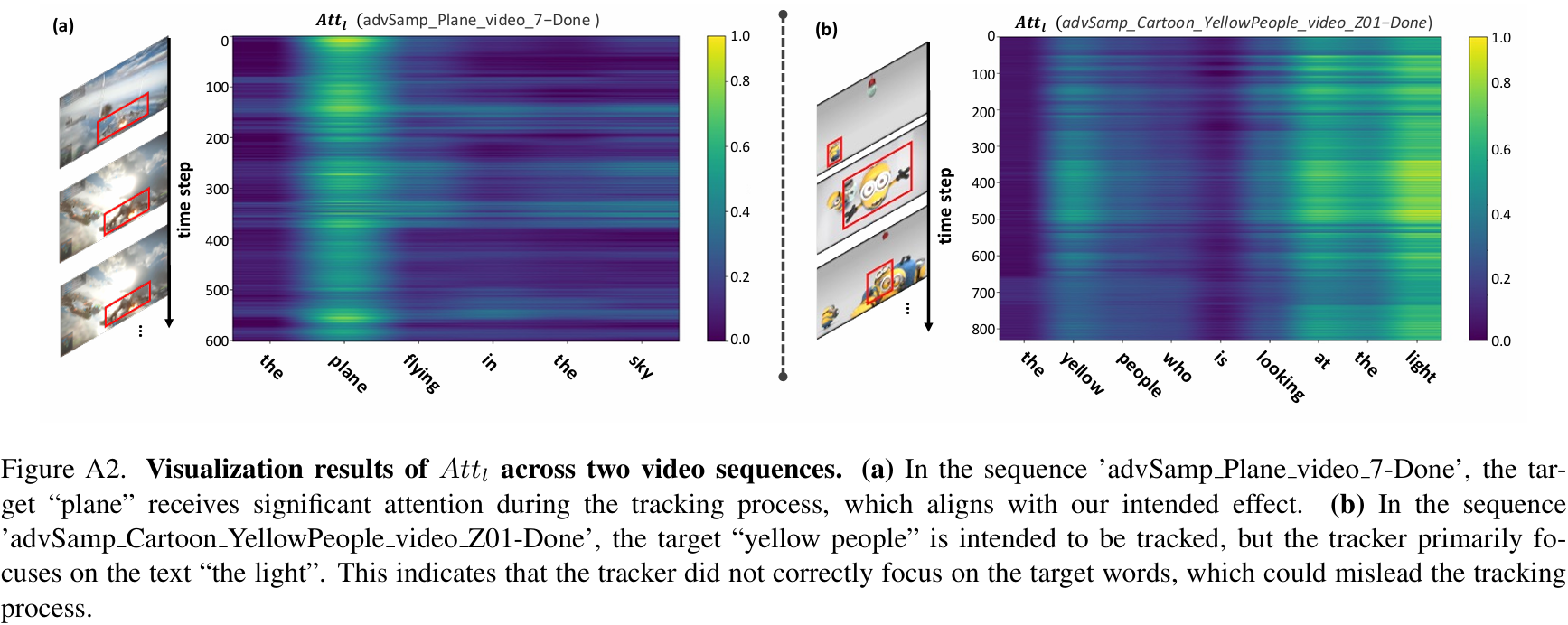
为了更直观地理解,我们以两个视频序列为例进行可视化分析。相关结果如图 A2 所示,这是对正文图 2(b) 和 © 的补充。如图 A2(a) 所示,该序列中跟踪的目标是"plane"(飞机)。在相应的 AttlAtt^lAttl 热力图中,目标词"plane"获得了显著的注意力,表明跟踪器正确理解了文本提示中嵌入的意图,且该文本线索有助于跟踪过程。对于图 A2(b) 中的示例,预期的跟踪目标是"yellow people"(穿黄衣服的人),但跟踪器主要关注的是单词"the light"(灯光)。这表明跟踪器没有正确聚焦于目标词,这可能会误导跟踪过程。
B.2. 目标词识别准确率评估
除了如上所述定性展示跟踪器区分文本中每个单词的能力外,我们还需要进行定量评估。首先,为了分析跟踪器在整个视频序列中对每个单词的注意力,我们沿时间维度对 AttlAtt^lAttl 取平均,得到 Resl∈RLRes^l \in \mathbb{R}^LResl∈RL。ReslRes^lResl 中的每个元素反映了跟踪器给予对应位置单词的注意力大小。
基于此信息,我们可以映射到从 A 节获得的标签信息,确定句子中目标词的数量 kkk。然后,我们计算 ReslRes^lResl 中前 kkk 个元素及其索引。随后,我们将 ppp 中这些索引处的元素设置为 1,而所有其他元素设置为 0,从而获得跟踪器对目标词分类的最终预测结果 p∈{0,1}Lp \in \{0, 1\}^Lp∈{0,1}L。
此外,利用 A 节提供的目标词标签信息,我们可以获得真实标签 g∈{0,1}Lg \in \{0, 1\}^Lg∈{0,1}L。在该标签中,0 表示该位置的单词 token 是上下文词,1 表示它是目标词。然后,通过对 ppp 和 ggg 进行不同的计算,我们建立了两个准确率评估指标,即 AccallAcc_{all}Accall 和 AcctargetAcc_{target}Acctarget,以评估跟踪器分类目标词的准确性。这里,AccallAcc_{all}Accall 代表模型对目标词和上下文词的整体分类准确率;而 AcctargetAcc_{target}Acctarget 则专门关注目标词的分类准确率。
Accall=∑i=1L1(pi=gi)L,(A2) Acc_{all} = \frac{\sum_{i=1}^{L} \mathbb{1}(p_i = g_i)}{L}, \quad \text{(A2)} Accall=L∑i=1L1(pi=gi),(A2)
Acctarget=∑i=1N1(pi=1∧gi=1)∑i=1N1(gi=1).(A3) Acc_{target} = \frac{\sum_{i=1}^{N} \mathbb{1}(p_i = 1 \land g_i = 1)}{\sum_{i=1}^{N} \mathbb{1}(g_i = 1)}. \quad \text{(A3)} Acctarget=∑i=1N1(gi=1)∑i=1N1(pi=1∧gi=1).(A3)
这里,1(⋅)\mathbb{1}(\cdot)1(⋅) 是一个指示函数,如果括号内的条件满足则返回 1。
同样地,对于我们提出的 ATCTrack 及其关于目标词的预测 ptlp^l_tptl(见公式 (1)),我们可以使用相同的方法将其映射到 ppp,然后使用上述公式进行准确率测量。相应的准确率结果显示在图 2(a) 中。显然,在这两个指标上,我们的方法都显著优于基于视觉 - 文本相似度的方法。
B.3. 评估结果分析
图 2(a) 展示了我们的方法与现有基于视觉 - 文本相似度的方法 58, 65, 89 在目标词识别准确率上的对比。可以看出,我们的方法在 AcctargetAcc_{target}Acctarget 指标上达到了令人印象深刻的 96.7%,显著超过了后者的 29.9%。这种精确的目标词感知为后续的文本线索调整和利用奠定了坚实的基础。这表明我们轻量级的多层感知机(公式 (1))有效地将大语言模型(LLMs)的目标词区分能力迁移到了跟踪器中。虽然现有的 LLMs 具有良好的目标词感知能力,但直接将 LLMs 集成到跟踪器中会产生巨大的计算成本,不利于实际应用。此外,自然语言处理领域还有一些轻量级的文本成分分析工具,如广泛使用的 Scene Graph Parser 64。我们评估了 Scene Graph Parser 在识别句子中目标词的准确率,发现其仅为 21.0%。这表明这些工具尚不能以即插即用的方式满足我们的目标词识别需求。
C. 关于 ATCTrack 的更多细节
由于篇幅限制,我们在第 3 节主要关注论文的主要贡献,具体是文本目标 - 上下文引导模块(见 3.2 节)和视觉目标 - 上下文引导模块(见 3.3 节)。对于跟踪器的其他组件,如预测头和记忆存储模块,我们使用当前主流方法进行了简要介绍,并补充了相关参考文献。在本节中,我们对这些组件提供额外的解释。
C.1. 预测头
预测头用于预测最终的边界框 btb_tbt。我们采用基于 CNN 的跟踪头 80, 86,这在跟踪器设计中已被广泛采用。首先,对于集成了文本和视觉线索的搜索特征 ftR∈RNx×Df^R_t \in \mathbb{R}^{N_x \times D}ftR∈RNx×D,我们将其转换为 2D 空间特征图。随后,经过 LhL_hLh 层堆叠的 Conv-BN-ReLU 层后,我们获得分类得分图 P∈0,11×Hs×WsP \in 0, 1^{1 \times H_s \times W_s}P∈0,11×Hs×Ws,边界框大小 B∈0,12×Hs×WsB \in 0, 1^{2 \times H_s \times W_s}B∈0,12×Hs×Ws 和偏移量大小 O∈[0,1)2×Hs×WsO \in [0, 1)^{2 \times H_s \times W_s}O∈[0,1)2×Hs×Ws。然后,具有最高分类得分的位置被认为是目标位置,即 (xd,yd)=argmax(x,y)Pxy(x_d, y_d) = \arg\max_{(x,y)} P_{xy}(xd,yd)=argmax(x,y)Pxy。最终的目标边界框获取如下:
x=xd+O(0,xd,yd),(A4) x = x_d + O_{(0, x_d, y_d)}, \quad \text{(A4)} x=xd+O(0,xd,yd),(A4)
y=yd+O(1,xd,yd),(A5) y = y_d + O_{(1, x_d, y_d)}, \quad \text{(A5)} y=yd+O(1,xd,yd),(A5)
w=S(0,xd,yd),(A6) w = S_{(0, x_d, y_d)}, \quad \text{(A6)} w=S(0,xd,yd),(A6)
h=S(1,xd,yd).(A7) h = S_{(1, x_d, y_d)}. \quad \text{(A7)} h=S(1,xd,yd).(A7)
C.2. 记忆存储模块
正如 3.4 节所介绍的,我们采用滑动窗口方法 7, 80 来更新记忆单元,这是一种在最近专注于时序建模的视觉跟踪器中广泛使用的方法。MSM 中的视觉记忆特征 MMM 由 LmL_mLm 个记忆单元 mmm 组成的列表构成,记为 M={mi}i=1LmM = \{m_i\}_{i=1}^{L_m}M={mi}i=1Lm。下面,我们将说明滑动窗口记忆存储方法是如何实现的。
对于具有 TTT 帧的视频序列 (0≤t≤T−10 \le t \le T-10≤t≤T−1),在处理第一帧(即 t=0t=0t=0)时需要初始化 MMM 中的记忆单元。具体而言,通过视觉编码器编码视觉输入信息后,我们获得从 CLS token 编码的特征 fC0f^0_{C}fC0。考虑到 CLS token 可以代表全局视觉特征 17,我们使用 fC0f^0_{C}fC0 来初始化 LmL_mLm 个记忆单元。在时间间隔 t∈1,T−1t \in 1, T-1t∈1,T−1 期间,在跟踪每个搜索帧后,我们获得更新的记忆单元 mtm_tmt。我们从 MMM 中弹出索引为 0 的记忆单元,并将 mtm_tmt 追加到 MMM 的末尾。
D. 模型实现的更多细节
由于篇幅限制,第 4.1 节仅提供了核心模型实现细节。在这里,我们补充一些额外的细节。首先,关于模型结构,在执行上下文词校准时,我们使用了由公式 (3) 和公式 (4) 组成的两个堆叠模块。在执行视觉记忆表示时,我们使用了由公式 (6) 和公式 (7) 组成的两个堆叠模块。值得注意的是,我们仅在视觉记忆表示部分使用了 FFN(前馈网络)。考虑到 Transformer 模块中 FFN 的计算成本高于 Attention 71,我们的模块设计有助于减少模型的整体参数和计算量。
此外,对于模型训练,我们使用 AdamW 优化器 53 来优化我们的模型。文本编码器保持冻结状态,视觉编码器的学习率设为 10−510^{-5}10−5,其余未冻结模块的学习率设为 10−410^{-4}10−4,权重衰减设为 10−410^{-4}10−4。我们总共训练 150 个 epoch,并在 120 个 epoch 后将学习率降低 10 倍。最后,在模型推理阶段,动态模板更新遵循 STARK 82 的实现。我们将更新间隔设为 25,更新置信度阈值设为 0.8。
E. 消融实验的实验细节
在 4.3 节中,我们进行了详细的消融分析,以调查 ATCTrack 中各个模块的特性。由于空间限制,我们没有充分阐述消融实验的具体实施。在本节中,我们提供额外的细节。
E.1. 重要模型组件的消融研究
表 2 展示了我们方法中两个核心组件的消融研究结果:文本和视觉目标 - 上下文引导模块。具体实现如下:表 2(#1) 展示了不使用我们的文本和视觉对象 - 上下文引导模块的基线结果。在此设置中,文本特征作为一个整体实体进行处理,这是最近跟踪器如 SNLT 74 和 MMTrack 94 广泛采用的方法。具体而言,我们采用基于 Transformer 的解码器来促进文本特征 fLf^LfL 和搜索特征 ftXf^X_tftX 之间的交互:
ftR=TransDec(ftX,fL),(A8) f^R_t = TransDec(f^X_t, f^L), \quad \text{(A8)} ftR=TransDec(ftX,fL),(A8)
其中 TransDecTransDecTransDec 代表标准的 Transformer 解码器层 71,主要由注意力操作和前馈网络组成。ftRf^R_tftR 表示嵌入了文本线索的搜索特征,随后被送入预测头以获得最终的跟踪结果。为了确保公平比较,我们将 Transformer 解码器配置为四层,使其参数量与视觉和文本对象 - 上下文引导模块相匹配。
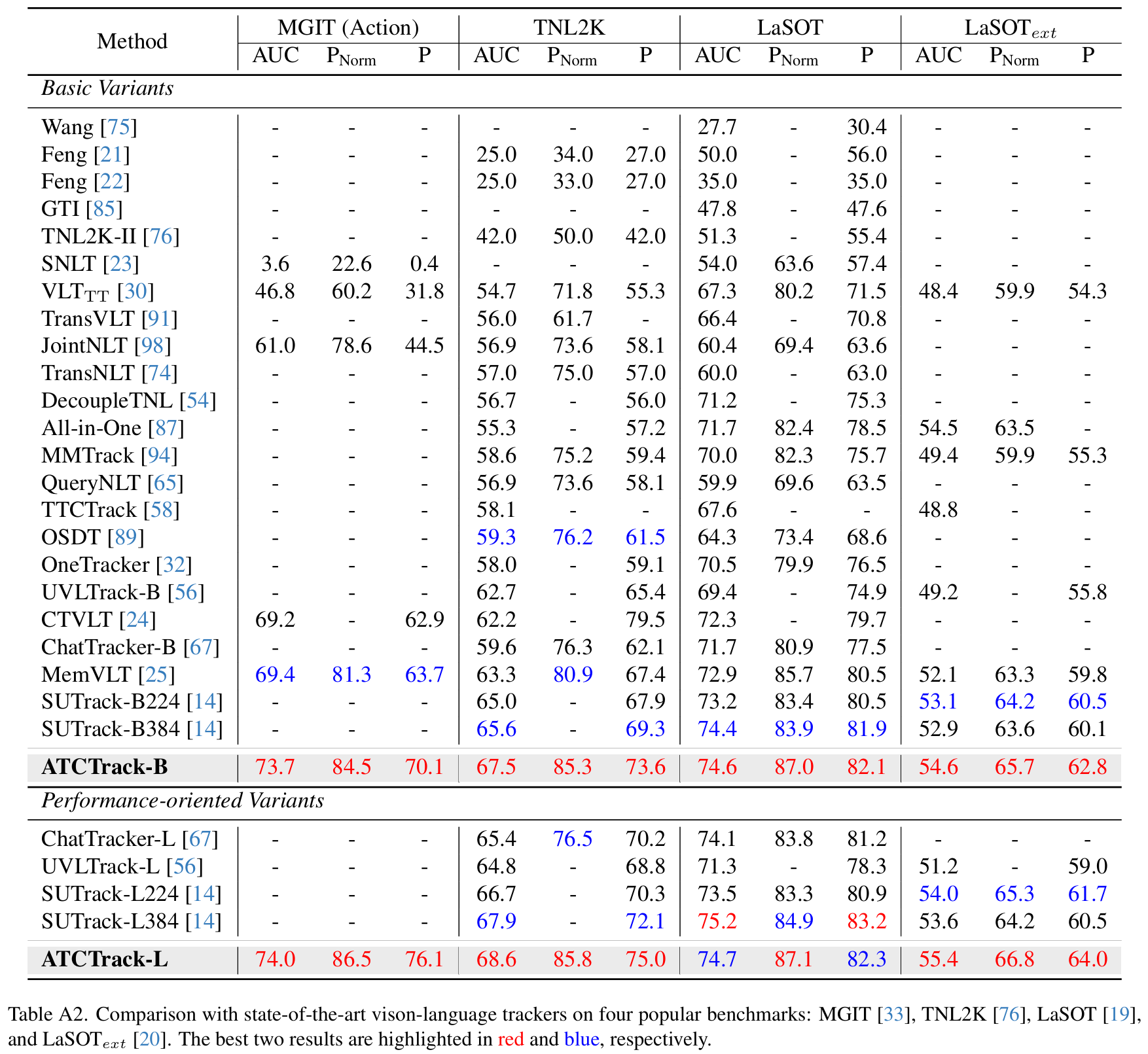
表 2(#2) 展示了仅使用文本对象 - 上下文引导模块的结果。在此实现中,我们省略了视觉记忆引导过程,并直接将来自文本目标 - 上下文引导模块的输出特征 ftXLf^{XL}_tftXL 送入预测头以获得最终结果。表 2(#3) 展示了仅使用我们的视觉对象 - 上下文引导模块的结果。在此实现中,我们采用基于 Transformer 的解码器用文本信息引导搜索特征,公式化为:
ftXL=TransDec(ftX,fL),(A9) f^{XL}_t = TransDec(f^X_t, f^L), \quad \text{(A9)} ftXL=TransDec(ftX,fL),(A9)
为了公平比较,我们实现了一个两层解码器架构。
表 2(#4) 展示了我们完整的 ATCTrack 模型的结果。
E.2. 文本目标 - 上下文建模的消融研究
表 3 展示了利用文本线索的不同方式,每种设置的具体实现如下:
- 朴素方法 (Naive method):此设置与表 2(#1) 一致。
- + 目标词感知 (+ Target words awareness) :指在"朴素方法"设置的基础上 Incorporate 目标词感知方法。具体而言,我们将 fLTf^{LT}fLT 与 fLf^LfL 拼接以获得上下文特征 fLCf^{LC}fLC,用于后续的文本引导。
- + 上下文词校准 (+ Context words calibration):指在"+ 目标词感知"设置的基础上 Incorporate 上下文词校准操作。这是我们 ATCTrack 采用的方法。
- - 双类型文本引导 (- Dual-type textual guidance) :这种方法仅利用校准后的单类型文本特征 fL′f^{L'}fL′ 进行文本引导,其中 fLC=fL′f^{LC} = f^{L'}fLC=fL′。
E.3. 视觉目标 - 上下文建模的消融研究
表 4 展示了利用视觉线索的不同方式,每种设置的具体实现如下:
- 朴素方法 (Naive method):此设置与表 2(#1) 一致。
- + ROI :代表通过在"朴素方法"中 Incorporate 显式的视觉记忆特征来辅助跟踪。具体而言,我们采用感兴趣区域 (RoI) 方法 62,这在最近的视觉 - 语言跟踪器 (VLTs) 如 JointNLT 98 和 TrDiMP 73 中被广泛采用。我们使用预测的边界框(缩放 1.5 倍)对搜索特征 ftXf^X_tftX 应用 RoI 处理,以获得局部搜索特征 ftX′∈R36×Df^{X'}t \in \mathbb{R}^{36 \times D}ftX′∈R36×D。随后,视觉记忆表示过程通过以下计算实现:
fCM′=Norm(fCM+ΦCA(fCM,ftX′)),(A10) f^{CM'} = Norm(f^{CM} + \Phi{CA}(f^{CM}, f^{X'}_t)), \quad \text{(A10)} fCM′=Norm(fCM+ΦCA(fCM,ftX′)),(A10)
fCM′′=Norm(fCM′+FFN(fCM′)).(A11) f^{CM''} = Norm(f^{CM'} + FFN(f^{CM'})). \quad \text{(A11)} fCM′′=Norm(fCM′+FFN(fCM′)).(A11) - + Search + crop mask :此设置涉及使用局部掩码构建对象 - 上下文指示图。具体而言,对于全局对象 - 上下文指示图 hth_tht,我们仅保留对应于预测边界框 1.5 倍区域内的值,而将所有其他区域的值设为零,得到 htlh^l_thtl。然后,视觉记忆表示过程通过以下计算实现:
fCM′=Norm(fCM+ΦCA(fCM,htl⊙ftX)),(A12) f^{CM'} = Norm(f^{CM} + \Phi_{CA}(f^{CM}, h^l_t \odot f^X_t)), \quad \text{(A12)} fCM′=Norm(fCM+ΦCA(fCM,htl⊙ftX)),(A12)
fCM′′=Norm(fCM′+FFN(fCM′)).(A13) f^{CM''} = Norm(f^{CM'} + FFN(f^{CM'})). \quad \text{(A13)} fCM′′=Norm(fCM′+FFN(fCM′)).(A13) - + Search + global mask :此设置涉及使用全局掩码构建对象 - 上下文指示图,用于获得显式的视觉记忆特征。这是我们 ATCTrack 采用的方法。
E.4. 不同模块贡献的消融研究
- w/o HiViT backbone:此设置指将 HiViT 骨干网络 69, 90 替换为传统跟踪器通常使用的 ViT 骨干网络 16, 86。
- w/o dynamic template:此设置指仅使用原始的静态模板作为视觉输入,而不使用稀疏动态模板 82。
- w/o TextualT C & VisualT C:此设置与表 2(#1) 中的设置相同,意味着未利用我们要设计的视觉和文本目标 - 上下文引导机制。
- w/o target words label :此设置在模型结构不变的情况下,指不使用目标词监督信号,从而排除 LbceL_{bce}Lbce 损失。
F. 额外的实验结果
F.1. 效率分析
在表 A1 中,我们在效率(参数量和速度)和性能(TNL2K 上的 AUC 和 P)方面将 ATCTrack 与最新的 VLTs(即 JointNLT 98、MMTrack 94 和 MemVLT 25)进行了比较。对于 ATCTrack-B,其参数量和跟踪速度与最近的跟踪器相当,但显示出显著的性能优势,例如与 MemVLT 相比,AUC 提高了 4.2%。对于 ATCTrack-L,其参数规模远大于 ATCTrack-B,这带来了进一步的性能提升。
F.2. 与更多跟踪器的比较
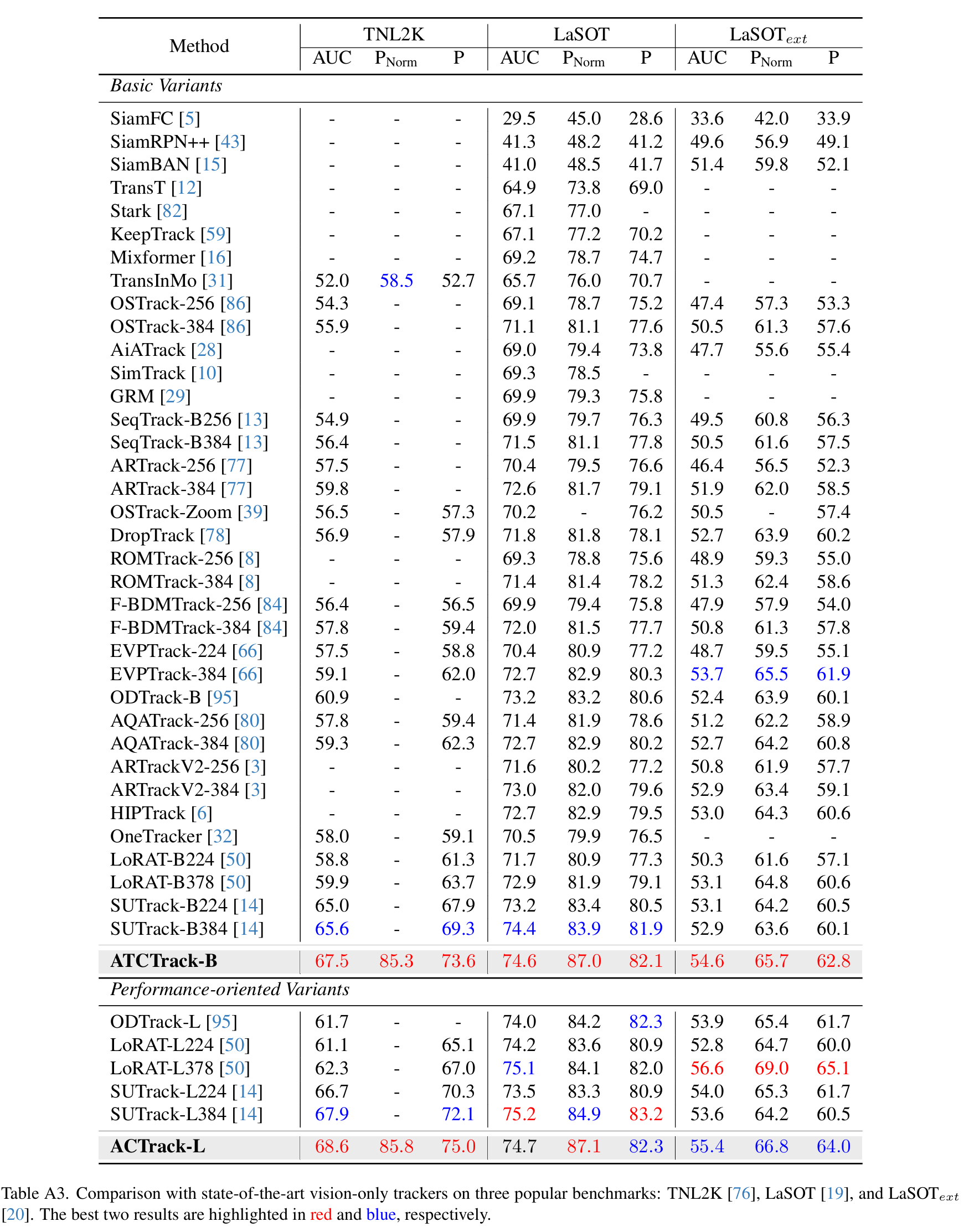
在 4.2 节的表 1 中,由于篇幅限制,我们将 ATCTrack 与几种近期高性能的视觉 - 语言跟踪器进行了比较。作为补充,表 A2 展示了更广泛范围的视觉 - 语言跟踪器的性能。此外,遵循视觉 - 语言跟踪模型的主流范式 25, 94, 98,表 A3 提供了与仅视觉跟踪器的额外比较。我们的模型在这些跟踪器中的强劲表现进一步证明了我们方法的有效性。
G. 更多定性结果
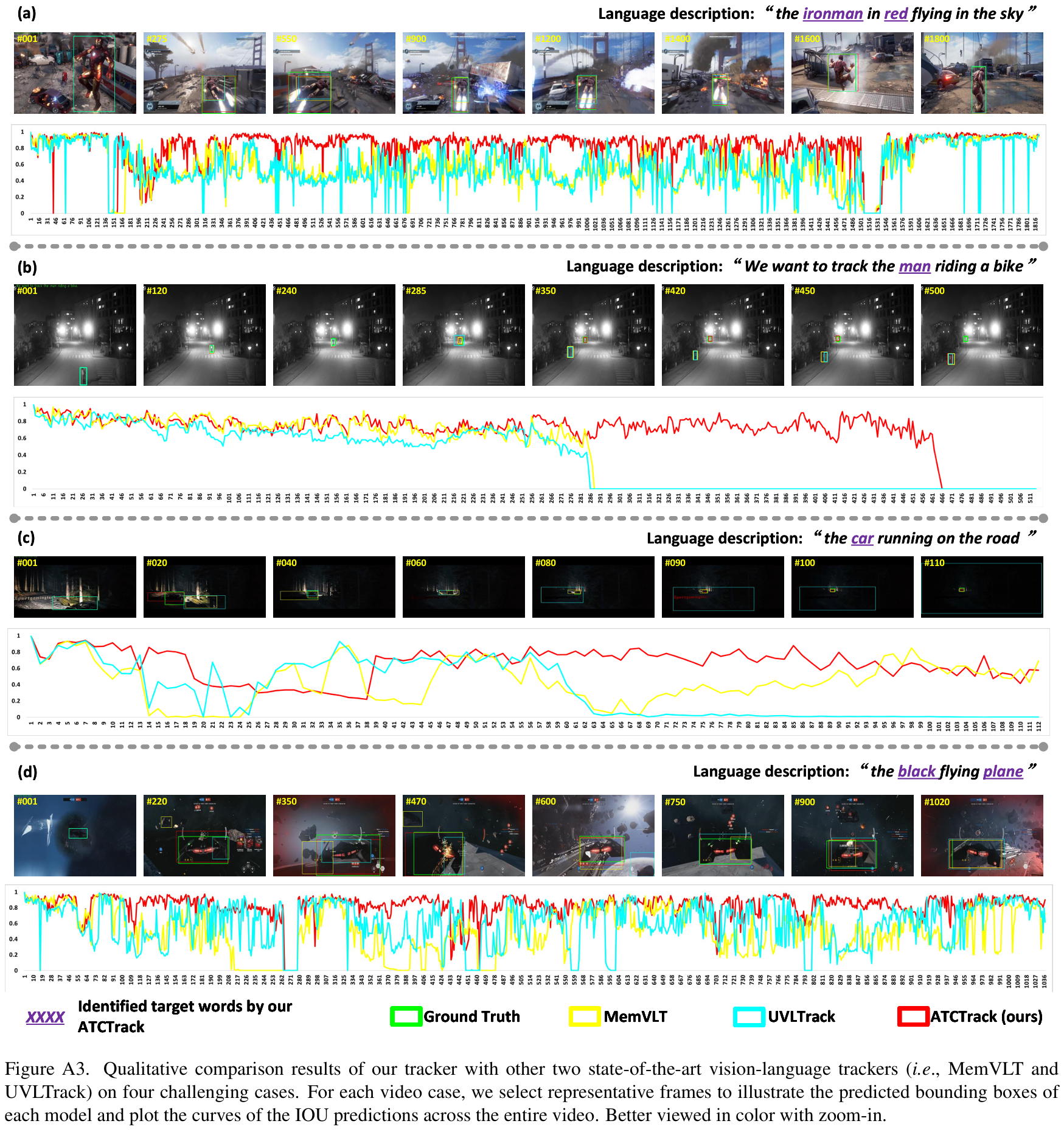
由于篇幅限制,图 4 仅展示了我们的模型与最新 SOTA 模型之间定性比较的四个案例。在本节中,我们提供额外的定性比较结果,如图 A3 所示。