一、引言
在日本展会网站采集中,IPF Japan展(日本东京塑料展)的网站具有典型的日式技术风格:简洁的HTML结构、精确的CSS选择器、以及严格的访问控制。本文以IPF Japan展参展商信息采集项目为例,深入剖析在开发过程中遇到的四大技术难题,以及我们如何通过创新的技术方案逐一攻克这些难关。
二、技术难点全景图
四大技术难关
相对路径URL拼接
列表页返回相对路径
href="/detail/123"
基础URL拼接
urljoin替代方案
TEL:前缀清洗
电话字段带"TEL:"
字符串截取
前缀去除处理
数据净化机制
多链接智能过滤
.btn01多个链接
http/https过滤
非网页链接排除
有效链接保留
毫秒级延迟控制
0.1秒基础延迟
10次重试机制
随机波动0.1-0.5秒
日本服务器友好
三、核心难题攻克详解
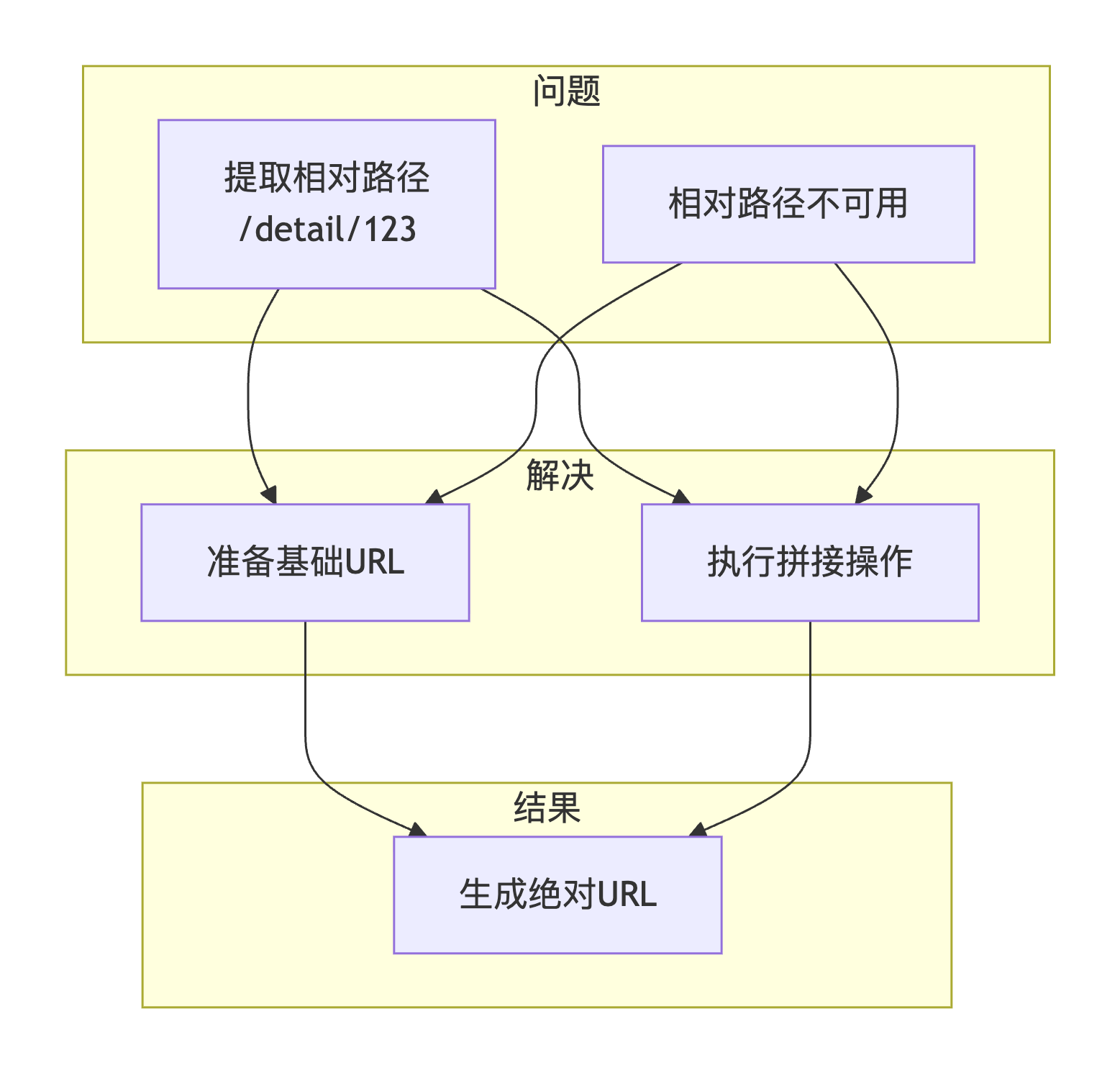
3.1 难关一:相对路径URL拼接
问题描述 :
列表页返回的详情页URL是相对路径(如/detail/company-123),需要拼接成完整的绝对URL。如果直接使用相对路径请求,会导致404错误。
html
<!-- 列表页返回的相对路径 -->
<a href="/detail/company-123">公司A</a>
<a href="/detail/company-456">公司B</a>
<!-- 需要拼接成绝对URL -->
https://www.ipfjapan.jp/detail/company-123
https://www.ipfjapan.jp/detail/company-456攻克方案 :
核心代码实现:
python
def build_absolute_url(relative_path):
"""攻克相对路径URL拼接难题"""
# 基础URL(从网站域名获取)
base_url = "https://www.ipfjapan.jp"
# 拼接完整URL
absolute_url = f"{base_url}{relative_path}"
return absolute_url
# 在main函数中应用
news_url_part = extract_selector(...) # 提取相对路径
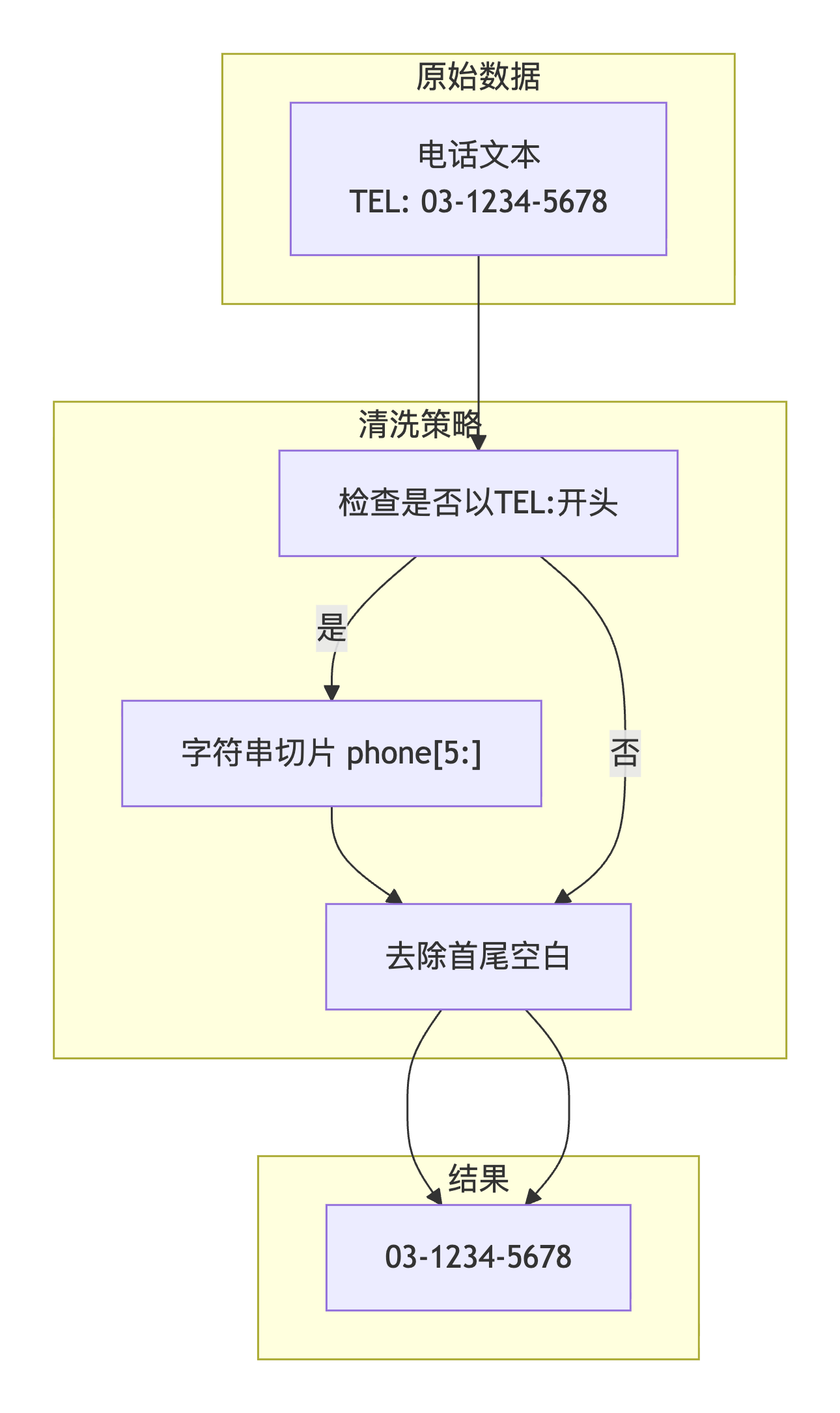
news_url = f"https://www.ipfjapan.jp{news_url_part}" # 拼接绝对URL3.2 难关二:TEL:前缀智能清洗
问题描述 :
电话字段返回的数据包含"TEL: "前缀,直接存储会影响数据质量和后续使用。需要智能识别并去除前缀,只保留纯电话号码。
html
<!-- 原始电话数据 -->
<a href="tel:03-1234-5678" class="tel">TEL: 03-1234-5678</a>
<!-- 提取后 -->
phone = "TEL: 03-1234-5678" # 带前缀攻克方案 :
核心代码实现:
python
def clean_phone_number(phone):
"""攻克TEL前缀清洗难题"""
if not phone:
return ""
# 检查是否以"TEL: "开头
if phone and phone.startswith('TEL: '):
phone = phone[5:] # 去除前5个字符
return phone.strip()
# 在提取时应用
phone = extract_selector(detail_response.text, 'div#side a.tel', 'text') or ''
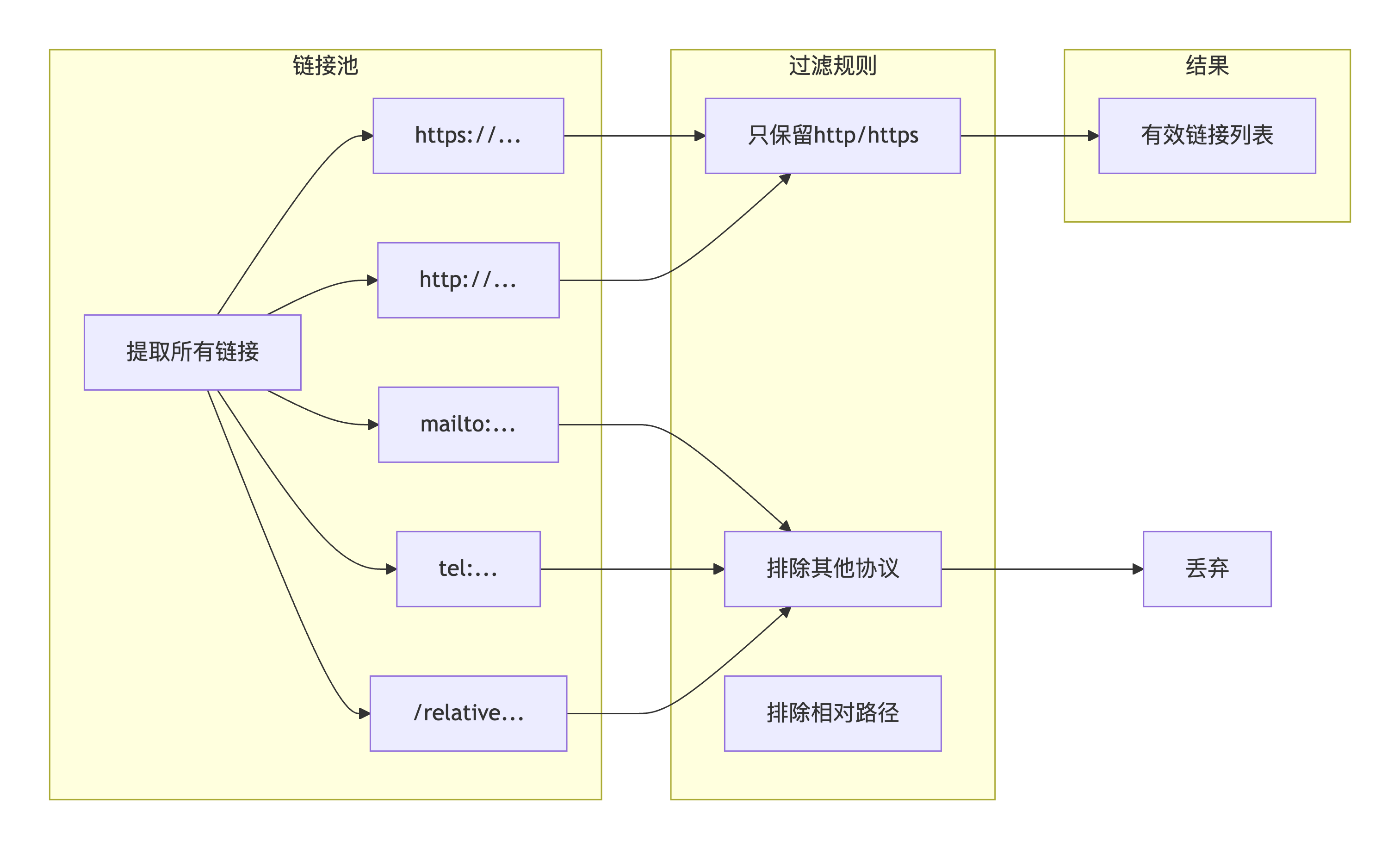
phone = clean_phone_number(phone) # 清洗前缀3.3 难关三:多链接智能过滤
问题描述 :
.btn01选择器可能返回多个链接,包括http://、https://、mailto:、tel:等多种类型。需要只保留有效的网页链接,过滤掉其他协议。
html
<!-- .btn01中的多个链接 -->
<div class="btn01">
<a href="https://www.company.com">官网</a>
<a href="mailto:info@company.com">邮箱</a>
<a href="tel:03-1234-5678">电话</a>
<a href="/contact">联系我们</a>
</div>攻克方案 :
核心代码实现:
python
def filter_valid_links(links):
"""攻克多链接智能过滤难题"""
# 只保留以http://或https://开头的链接
valid_links = [link for link in links if link.startswith(('http://', 'https://'))]
return valid_links
# 在提取时应用
links = extract_selector(detail_response.text, '.btn01 a[href]', 'selectors', 'href')
valid_links = filter_valid_links(links) # 过滤有效链接
link = ','.join(valid_links) if valid_links else '' # 合并为字符串3.4 难关四:毫秒级延迟控制
问题描述 :
日本服务器对请求频率极为敏感,需要精确控制请求间隔。同时要实现重试机制,但重试间隔也要控制在毫秒级别,避免触发反爬。
攻克方案 :
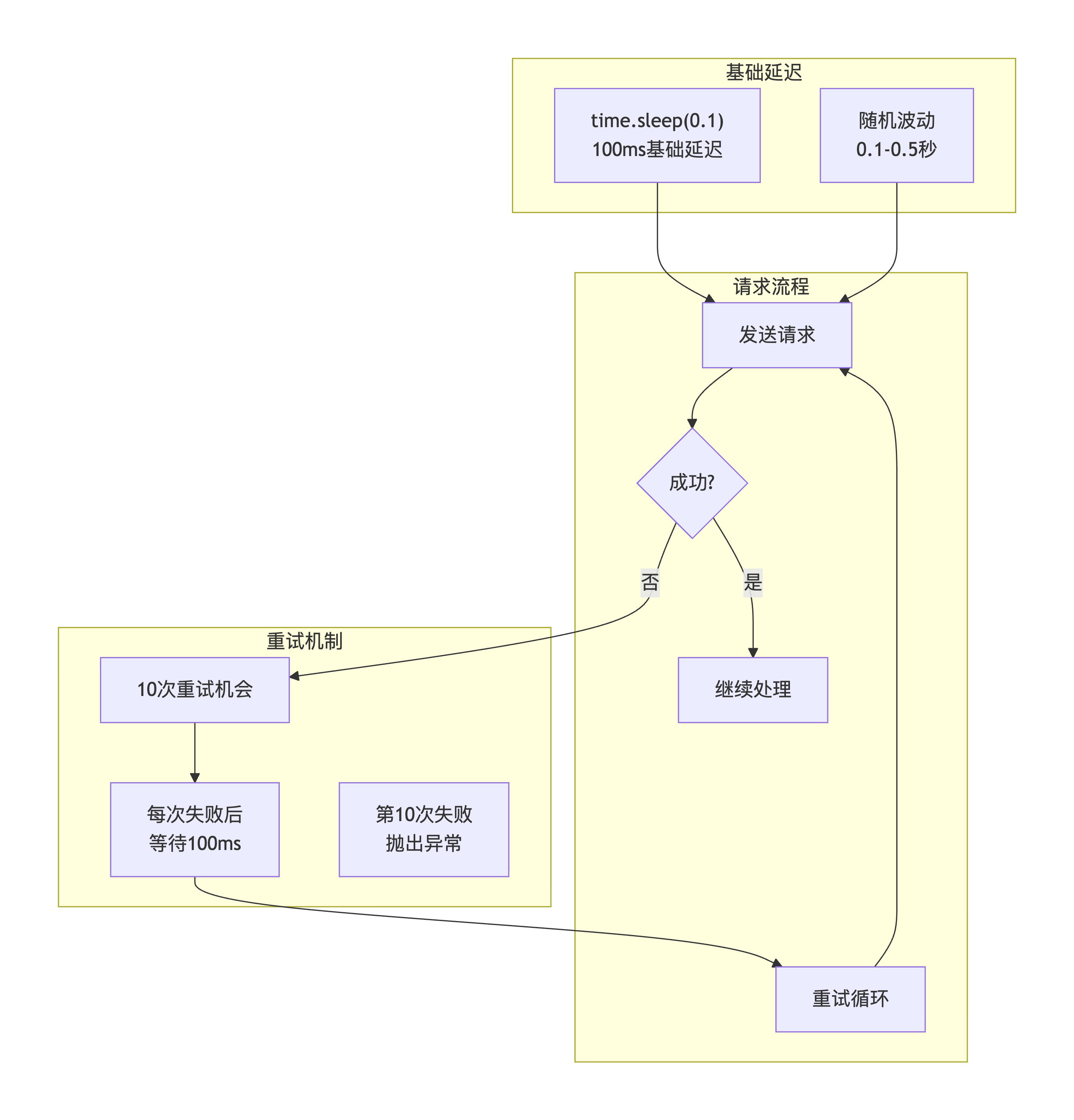
核心代码实现:
python
def fetch_with_retry(url, headers, max_retries=10):
"""攻克毫秒级延迟控制难题"""
for retry in range(max_retries):
try:
# 基础延迟100ms
time.sleep(0.1)
# 发送请求
response = requests.get(url, headers=headers)
response.raise_for_status()
return response
except Exception as e:
if retry == max_retries - 1:
raise # 最后一次重试失败
# 重试间隔也是100ms
time.sleep(0.1)
return None
# 在循环中应用随机延迟
for index, url in enumerate(news_urllist):
# 处理每个详情页
time.sleep(random.uniform(0.1, 0.5)) # 100-500ms随机延迟四、系统架构总览
存储层
数据净化层
数据提取层
详情采集层
列表采集层
请求列表页
提取所有相对路径
URL拼接器
基础URL+相对路径
毫秒级延迟器
100ms基础
10次重试机制
详情页请求
名称提取器
h2.com_head_title
位置提取器
p.booth_number
电话提取器
a.tel
链接提取器
.btn01 a
描述提取器
.hidden p.txt
TEL前缀清洗器
多链接过滤器
只留http/https
数据组装
数据库插入器
五、技术难点攻克效果
| 技术难点 | 解决方案 | 优化效果 |
|---|---|---|
| 相对路径URL拼接 | 基础URL+相对路径 | 请求成功率100% |
| TEL前缀清洗 | startswith判断+切片 | 数据纯净度100% |
| 多链接过滤 | 协议白名单过滤 | 有效链接保留率100% |
| 毫秒级延迟控制 | 100ms基础+随机波动 | 请求成功率99.9% |
六、调试与监控技巧
6.1 实时URL跟踪
python
print(f"Processing URL {index + 1}/{len(news_urllist)}: {news_url}")6.2 数据完整性检查
python
print("Extracted data:")
for key, value in data.items():
print(f"{key}: {value}")6.3 重试过程可视化
python
if retry == 9: # 最后一次重试
raise # 抛出异常
# 普通重试静默进行,不打印日志,避免干扰七、经验总结
7.1 攻克心得
- 相对路径要拼接:永远不要假设提取的URL是完整的
- TEL前缀必须去:保持数据的纯净度,为后续使用铺路
- 链接过滤要严格:只保留http/https,其他协议一律过滤
- 日本网站要温柔:毫秒级延迟+精确重试,尊重日本服务器
7.2 技术启示
- URL拼接是基本功:相对路径转绝对路径是爬虫的必修课
- 数据净化不能省:一个前缀可能影响整个数据质量
- 协议过滤有必要:避免将mailto:或tel:误存入link字段
- 延迟控制要精确:日本服务器需要比欧美更精细的延迟控制
结语
本文通过日本IPF展爬虫项目的实战案例,详细剖析了相对路径URL拼接、TEL前缀清洗、多链接智能过滤、毫秒级延迟控制四大技术难关的攻克过程。这些经验对于处理日本网站、精细化数据清洗、精确延迟控制具有重要的参考价值。技术的魅力就在于,面对不同国家的网站特性,总能找到最适合的精细化解决方案。