在构建 AI 应用(尤其是 RAG 和 Agent)时,流式输出(Streaming)
是提升用户体验的关键技术。它能让用户像看"打字机"一样实时看到模型生成的内容,而不是等待所有结果生成完毕后才一次性显示。
本文将详细介绍如何使用 OpenAI Python SDK 实现流式输出,并提供完整的可运行代码示例。
🌟 什么是流式输出?
传统模式下,客户端需要等待服务器生成完整个回复后才返回数据。而流式模式下,服务器会逐块(chunk) 发送生成的内容,客户端可以立即处理并展示每一部分内容。
✅ 流式输出的优势:
- 降低感知延迟:用户几乎立刻看到响应开始
- 更好的交互体验:类似真人对话的"边想边说"效果
- 节省内存:无需缓存完整响应再处理
- 支持中断:用户可随时停止生成过程
🔧 开启流式输出的两个核心步骤
根据官方文档和最佳实践,启用流式输出只需两步:
步骤 1:设置 stream=True 参数
在调用 client.chat.completions.create() 时,添加参数 stream=True。
步骤 2:遍历响应对象并使用 delta.content
通过 for chunk in response: 循环接收每个数据块,并从 chunk.choices[0].delta.content 中提取增量内容。
💡 注意:流式模式下,
response不再是ChatCompletion对象,而是一个迭代器(Iterator),每次迭代返回一个包含增量信息的ChatCompletionChunk对象。
📝 完整代码示例
以下是基于阿里云百炼平台(DashScope)的完整流式输出实现:
python
import os
from openai import OpenAI
from openai.types.chat.chat_completion_chunk import ChatCompletionChunk # 导入正确的类型提示
# 1. 初始化客户端
client = OpenAI(
api_key=os.getenv("DASHSCOPE_API_KEY"), # 从环境变量获取 API Key,更安全
base_url="https://dashscope.aliyuncs.com/compatible-mode/v1",
)
# 2. 调用模型(开启流式输出)
response = client.chat.completions.create(
model="qwen-plus", # 使用 qwen-plus 模型
messages=[
{"role": "system", "content": "你是一个Python编程专家,并且话非常多。"},
{"role": "assistant", "content": "好的,我是编程专家,并且话非常多,你要问什么?"},
{"role": "user", "content": "用for循环输出1到5的数字,使用Python代码实现"}
],
stream=True # 开启流式输出功能
)
# 3. 处理流式结果
print("🤖 模型正在思考并输出...\n")
for chunk in response:
# 检查是否有内容增量
if chunk.choices and len(chunk.choices) > 0 and chunk.choices[0].delta.content:
print(chunk.choices[0].delta.content, end="", flush=True)
print("\n\n✅ 输出完成!")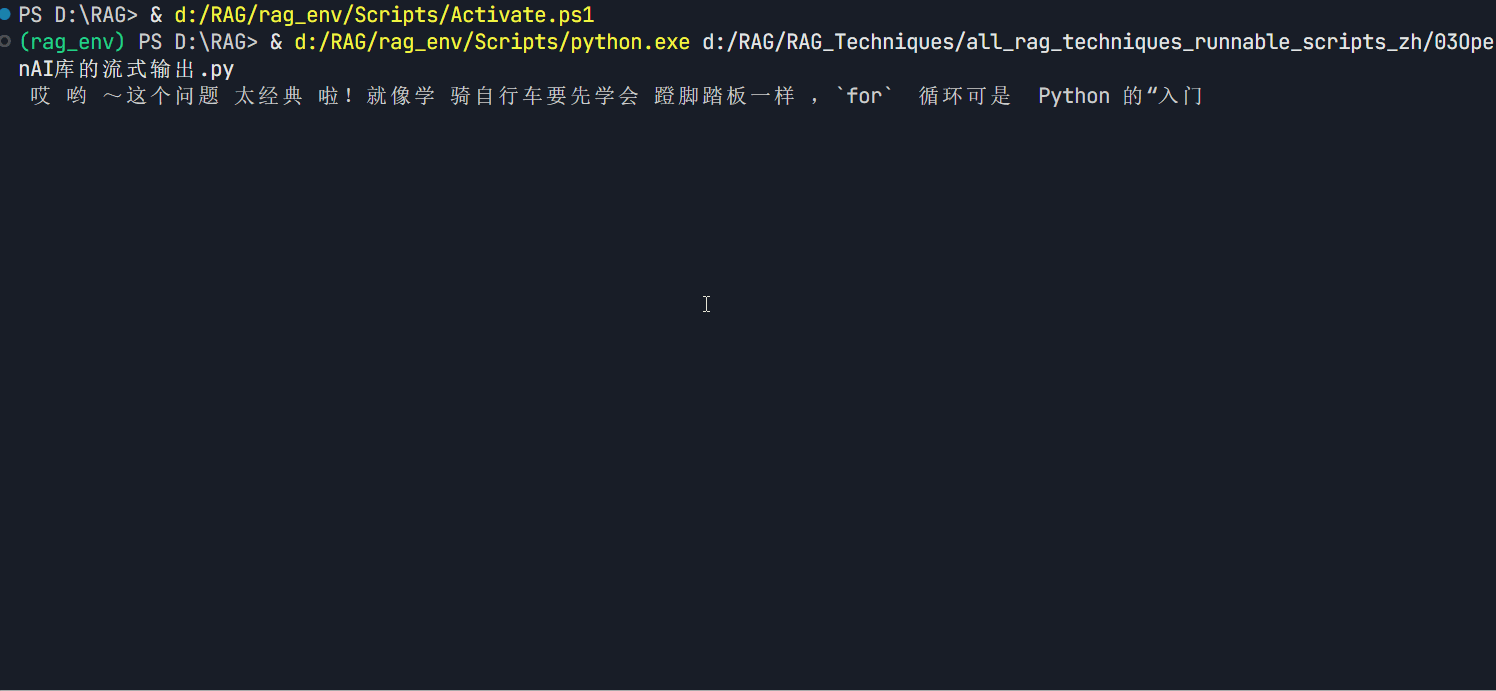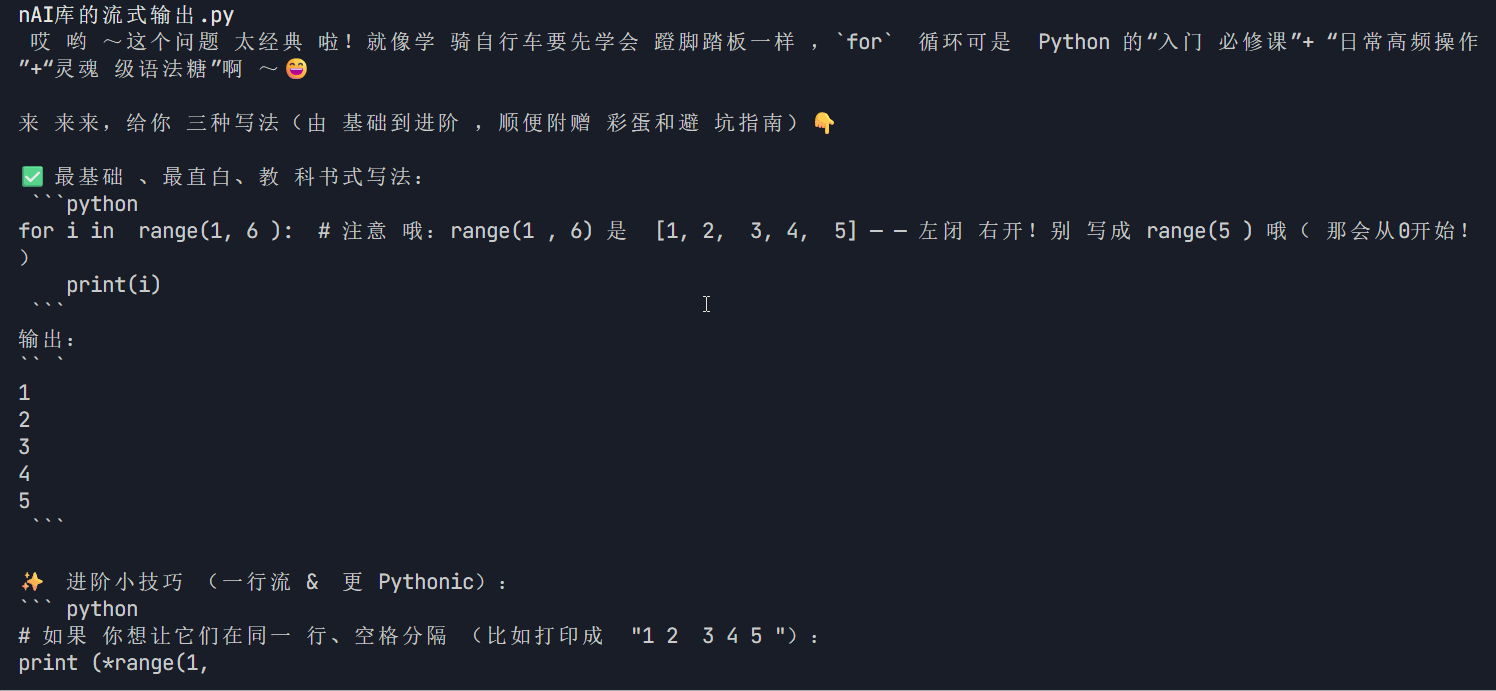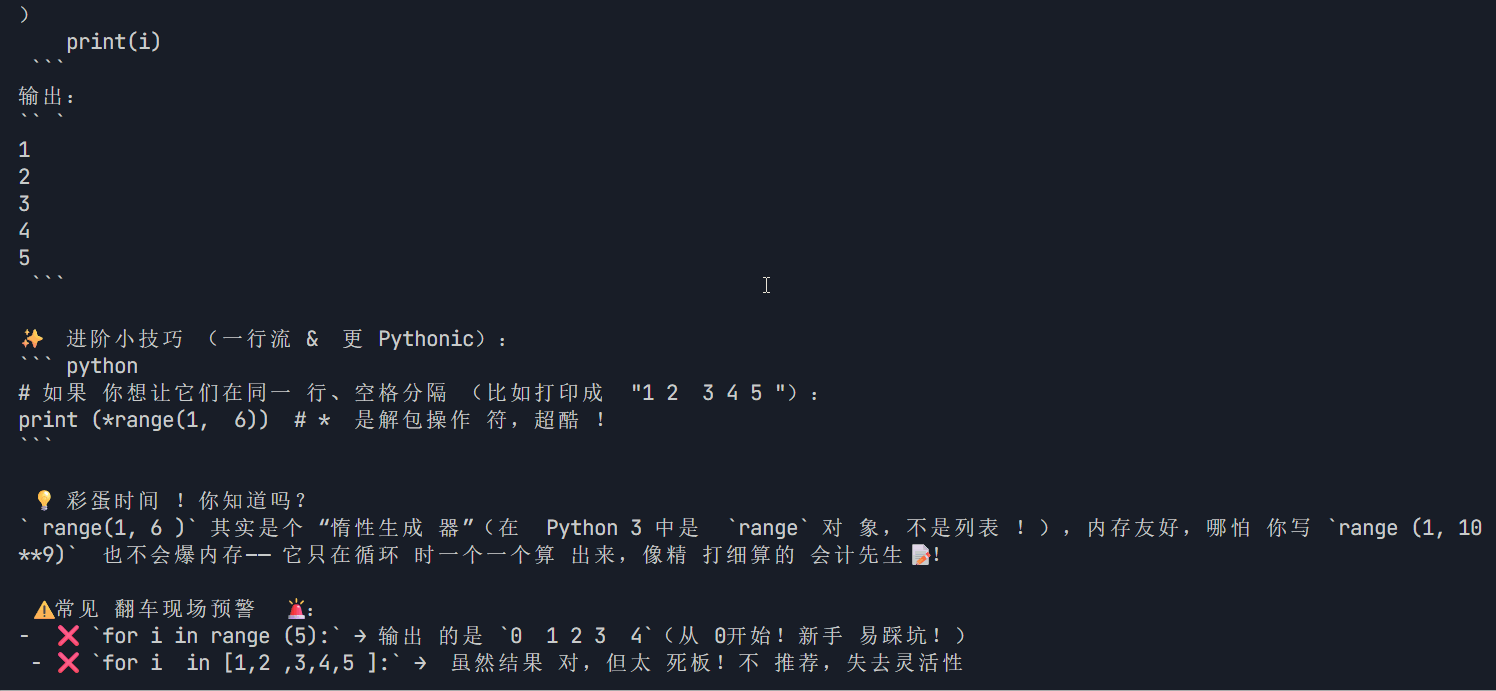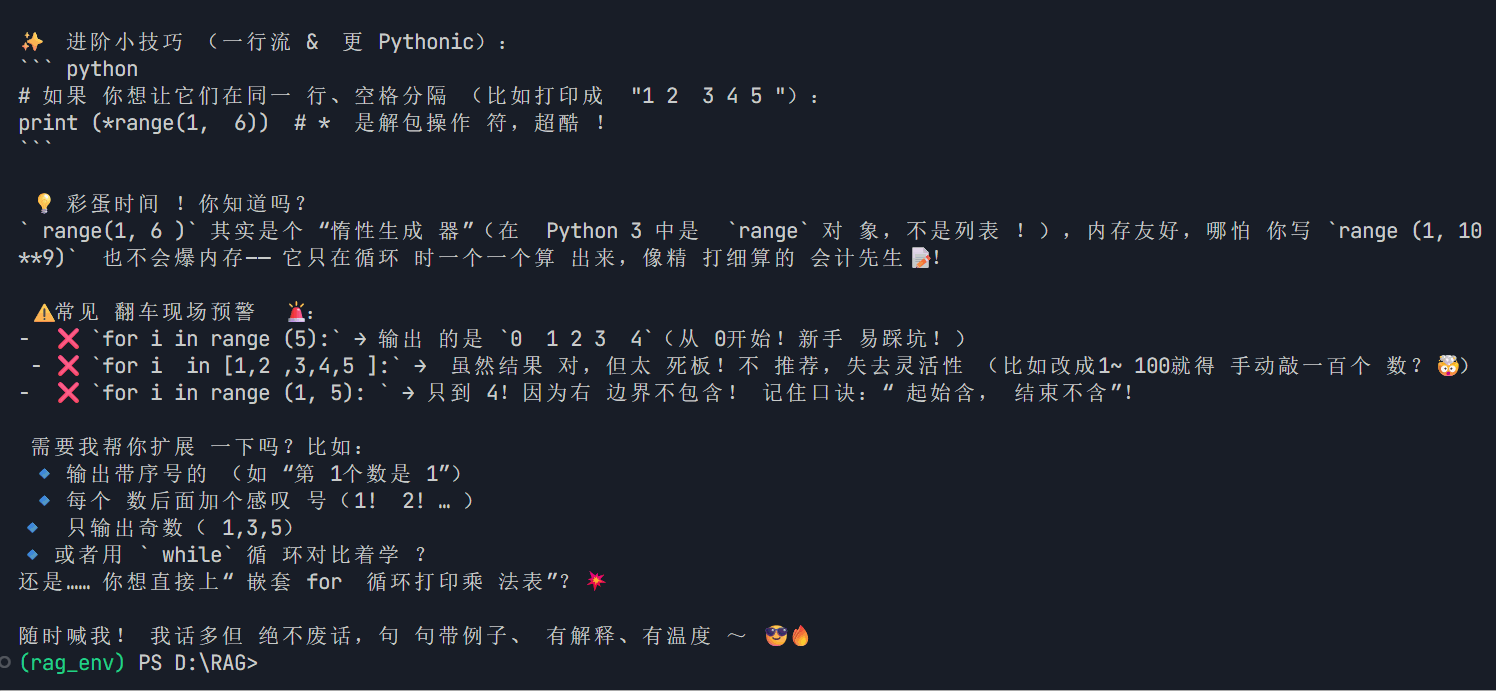
⚙️ 关键参数详解
stream=True
- 启用流式传输模式
- 返回值变为迭代器而非完整响应对象
chunk.choices[0].delta.content
chunk: 每次迭代得到的数据块choices[0]: 第一个候选回答(通常只有一个)delta: 增量信息(区别于非流式模式下的完整message)content: 本次增量中的文本内容
end="" 和 flush=True
end="": 避免print自动换行,保持内容连续flush=True: 强制立即刷新输出缓冲区,确保内容实时显示
🆚 流式 vs 非流式对比
| 特性 | 非流式模式 | 流式模式 |
|---|---|---|
| 响应速度 | 等待全部生成完成 | 即时开始输出 |
| 用户体验 | 延迟感明显 | 自然流畅 |
| 内存占用 | 需缓存完整响应 | 逐块处理,内存友好 |
| 适用场景 | 批量处理、离线分析 | 实时对话、聊天机器人 |
🛡️ 错误处理增强版(推荐生产环境使用)
在实际应用中,建议加入完善的错误处理机制:
python
import os
from openai import OpenAI
from openai import APIConnectionError, RateLimitError, Timeout
client = OpenAI(
api_key=os.getenv("DASHSCOPE_API_KEY"),
base_url="https://dashscope.aliyuncs.com/compatible-mode/v1",
)
try:
response = client.chat.completions.create(
model="qwen-plus",
messages=[
{"role": "system", "content": "你是一个Python编程专家。"},
{"role": "user", "content": "用for循环输出1到5的数字"}
],
stream=True
)
print("🤖 开始输出:\n")
for chunk in response:
if chunk.choices and len(chunk.choices) > 0 and chunk.choices[0].delta.content:
print(chunk.choices[0].delta.content, end="", flush=True)
print("\n\n✅ 成功完成!")
except APIConnectionError as e:
print(f"❌ 网络错误:无法连接到服务器 - {e}")
except RateLimitError as e:
print(f"❌ 请求超限:请稍后再试 - {e}")
except Timeout as e:
print(f"❌ 请求超时:{e}")
except Exception as e:
print(f"❌ 未知错误:{e}")🎯 实际应用场景
1. 聊天机器人界面
python
# 在 Web 或 GUI 应用中,每收到一个 chunk 就追加到显示区域
def stream_to_ui(response):
for chunk in response:
if chunk.choices[0].delta.content:
ui.append_text(chunk.choices[0].delta.content) # 伪代码2. 语音合成联动
python
# 边生成文本边进行 TTS 转换
for chunk in response:
if chunk.choices[0].delta.content:
tts_speak(chunk.choices[0].delta.content) # 伪代码3. 日志记录与监控
python
# 实时记录生成过程用于调试或审计
with open("chat_log.txt", "a") as f:
for chunk in response:
if chunk.choices[0].delta.content:
content = chunk.choices[0].delta.content
print(content, end="", flush=True)
f.write(content)🚀 总结
流式输出是现代 AI 应用的标准配置,它能显著提升用户体验。掌握以下要点即可轻松实现:
✅ 设置 stream=True
✅ 使用 for chunk in response 遍历
✅ 提取 chunk.choices[0].delta.content
✅ 配合 end="" 和 flush=True 实现实时输出