
🔥承渊政道: 个人主页
❄️个人专栏: 《C语言基础语法知识》 《数据结构与算法》
✨逆境不吐心中苦,顺境不忘来时路! 🎬 博主简介:

引言:前篇文章,小编已经介绍了关于深入回溯C++11的发展历程!相信大家应该有所收获!接下来我将带领大家继续深入学习C++的相关内容!本篇文章着重介绍关于C++异常相关内容以及类型转换介绍!在传统C++开发中,简陋的错误码判断、粗放的C风格强制转换,是引发内存越界、逻辑异常、程序崩溃的高频诱因;而随着C++11及后续现代标准的完善,异常机制拥有了noexcept精准约束、标准化的栈展开规则,类型转换则形成了四类安全显式转换的规范体系,彻底告别了无约束转换的风险.那么这里面到底有哪些知识需要我们去学习的呢?废话不多说,带着这些疑问,下面跟着小编的节奏🎵一起去疯狂的学习吧!
目录
1.异常的概念及使⽤
1.1异常的概念
异常(Exception)是程序运行时发生的、打断正常指令执行流程的意外错误或异常事件,是程序与开发者之间用于传递运行故障的标准化机制.
1️⃣核心界定:什么是异常?
异常特指程序运行阶段 出现的错误,并非代码语法错误 :
❌ 编译错误 :语法写错、少分号、类型不匹配(编译器直接报错,无法运行);
✅ 异常 :程序已成功编译运行,执行中触发的不可预知问题.
C++中常见的异常场景
整数除零运算;
访问空指针、数组越界;
动态内存分配失败(new申请内存不足);
打开不存在的文件、网络连接断开;
自定义业务逻辑错误(如参数非法、数据格式错误).
2️⃣本质:错误处理的现代化方案
在没有异常机制时,C/C++ 传统的错误处理依赖返回值/错误码 (如函数返回-1、0表示失败),这种方式存在致命缺陷:
错误处理代码与正常逻辑耦合,代码臃肿混乱;
开发者极易忽略错误检查,导致故障扩散;
多层函数调用时,错误码需要层层传递,维护成本极高.
C++ 异常机制的核心思想 :
将错误的检测 与错误的处理 彻底分离:
函数内部检测到错误时,抛出(throw) 异常信息,终止当前代码执行;
程序跳转到指定的**捕获(catch)**模块处理错误,不干扰正常业务逻辑.
3️⃣异常机制的三大核心关键字
C++用三个关键字实现完整的异常流程,是异常概念的核心载体:
throw:抛出异常,主动上报运行时错误;
try:包裹可能触发异常的代码块,标记需要监控错误的区域;
catch:捕获并处理对应类型的异常,是错误的兜底方案.
一句话总结:
异常是C++用于处理运行时错误的专用机制,通过抛出-捕获模型分离错误检测与处理逻辑,让程序在遭遇意外时不崩溃、可恢复,是编写健壮、安全的工业级代码的基础能力.
1.2异常的抛出和捕获
①程序出现问题时,我们通过抛出(
throw)⼀个对象来引发⼀个异常,该对象的类型以及当前的调⽤链决定了应该由哪个catch的处理代码来处理该异常.
②被选中的处理代码是调⽤链中与该对象类型匹配且离抛出异常位置最近的那⼀个.根据抛出对象的类型和内容,程序的抛出异常部分告知异常处理部分到底发⽣了什么错误.
③当throw执⾏时,throw后⾯的语句将不再被执⾏.程序的执⾏从throw位置跳到与之匹配的catch模块,catch可能是同⼀函数中的⼀个局部的catch,也可能是调⽤链中另⼀个函数中的catch,控制权从throw位置转移到了catch位置.这⾥还有两个重要的含义:⑴沿着调⽤链的函数可能提早退出.⑵⼀旦程序开始执⾏异常处理程序,沿着调⽤链创建的对象都将销毁.
④抛出异常对象后,会⽣成⼀个异常对象的拷⻉,因为抛出的异常对象可能是⼀个局部对象,所以会⽣成⼀个拷⻉对象,这个拷⻉的对象会在catch⼦句后销毁.(这⾥的处理类似于函数的传值返回).
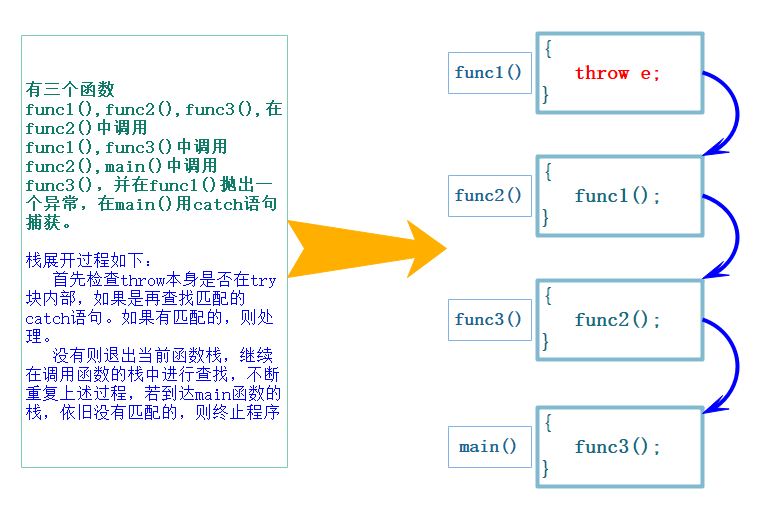
1.3栈展开
①抛出异常后,程序暂停当前函数的执⾏,开始寻找与之匹配的catch⼦句,⾸先检查throw本⾝是否在try块内部,如果在则查找匹配的catch语句,如果有匹配的,则跳到catch的地⽅进⾏处理.
②如果当前函数中没有try/catch⼦句,或者有try/catch⼦句但是类型不匹配,则退出当前函数,继续在外层调⽤函数链中查找,上述查找的catch过程被称为栈展开.
③如果到达main函数,依旧没有找到匹配的catch⼦句,程序会调⽤标准库的terminate函数终⽌程序.
④如果找到匹配的catch⼦句处理后,catch⼦句代码会继续执⾏.
cpp
#include<iostream>
using namespace std;
double Divide(int a, int b)
{
try
{
// 当b == 0时抛出异常
if (b == 0)
{
string s("Divide by zero condition!");
throw s;
}
else
{
return ((double)a / (double)b);
}
}
catch (int errid)
{
cout << errid << endl;
}
return 0;
}
void Func()
{
int len, time;
cin >> len >> time;
try
{
cout << Divide(len, time) << endl;
}
catch (const char* errmsg)
{
cout << errmsg << endl;
}
cout <<__FUNCTION__<<":" << __LINE__ << "⾏执⾏" << endl;
}
int main()
{
while (1)
{
try
{
Func();
}
catch (const string& errmsg)
{
cout << errmsg << endl;
}
}
return 0;
}1.4查找匹配的处理代码
①⼀般情况下抛出对象和catch是类型完全匹配的,如果有多个类型匹配的,就选择离它位置更近的那个.
②但是也有⼀些例外,允许从⾮常量向常量的类型转换,也就是权限缩⼩;允许数组转换成指向数组元素类型的指针,函数被转换成指向函数的指针;允许从派⽣类向基类类型的转换,这个点⾮常实⽤,实际中继承体系基本都是⽤这个⽅式设计的.
③如果到main函数,异常仍旧没有被匹配就会终⽌程序,不是发⽣严重错误的情况下,我们是不期望程序终⽌的,所以⼀般main函数中最后都会使⽤catch(...),它可以捕获任意类型的异常,但是不知道异常错误是什么.
cpp
#define _CRT_SECURE_NO_WARNINGS 1
#include<thread>//用于this_thread::sleep_for 线程休眠
#include<iostream>
#include<string>
using namespace std;
//⼀般⼤型项⽬程序才会使⽤异常,下⾯我们模拟设计⼀个服务的⼏个模块
//每个模块的继承都是Exception的派⽣类,每个模块可以添加⾃⼰的数据
//最后捕获时,我们捕获基类就可以
class Exception
{
public:
//构造函数:错误信息 + 错误编号
Exception(const string& errmsg, int id)
:_errmsg(errmsg)
, _id(id)
{}
//虚函数:多态的核心!返回错误描述
virtual string what() const
{
return _errmsg;
}
int getid() const
{
return _id;
}
protected:
string _errmsg;//错误信息
int _id;//错误码
};
//数据库异常:额外存储执行失败的SQL语句
class SqlException : public Exception
{
public:
SqlException(const string& errmsg, int id, const string& sql)
:Exception(errmsg, id)
, _sql(sql)
{}
//重写虚函数
virtual string what() const
{
string str = "SqlException:";
str += _errmsg;
str += "->";
str += _sql;
return str;
}
private:
const string _sql;
};
//缓存异常
class CacheException : public Exception
{
public:
CacheException(const string& errmsg, int id)
:Exception(errmsg, id)
{}
virtual string what() const
{
string str = "CacheException:";
str += _errmsg;
return str;
}
};
//HTTP请求异常:额外存储请求类型(get/post)
class HttpException : public Exception
{
public:
HttpException(const string& errmsg, int id, const string& type)
:Exception(errmsg, id)
, _type(type)
{}
virtual string what() const
{
string str = "HttpException:";
str += _type;
str += ":";
str += _errmsg;
return str;
}
private:
const string _type;
};
//最底层:数据库模块
void SQLMgr()
{
if (rand() % 7 == 0)
{
//抛派生类异常
throw SqlException("权限不⾜", 100, "select * from name = '张三'");
}
else
{
cout << "SQLMgr 调⽤成功" << endl;
}
}
//中间层:缓存模块 → 调用数据库
void CacheMgr()
{
if (rand() % 5 == 0)
{
throw CacheException("权限不⾜", 100);
}
else if (rand() % 6 == 0)
{
throw CacheException("数据不存在", 101);
}
else
{
cout << "CacheMgr 调⽤成功" << endl;
}
SQLMgr();
}
//最上层:HTTP服务 → 调用缓存
void HttpServer()
{
if (rand() % 3 == 0)
{
throw HttpException("请求资源不存在", 100, "get");
}
else if (rand() % 4 == 0)
{
throw HttpException("权限不⾜", 101, "post");
}
else
{
cout << "HttpServer调⽤成功" << endl;
}
CacheMgr();
}
int main()
{
srand(time(0));//初始化随机数种子
while (1)//死循环,模拟服务持续运行
{
this_thread::sleep_for(chrono::seconds(1));//每秒执行一次
try
{
HttpServer();//执行顶层业务
}
catch (const Exception& e) // 这⾥捕获基类,基类对象和派⽣类对象都可以被捕获
{
cout << e.what() << endl;//多态调用:执行派生类重写的what()
}
//兜底捕获:捕获所有未知类型异常
catch (...)
{
cout << "Unkown Exception" << endl;
}
}
return 0;
}代码整体功能概述
模拟后端服务三层架构:HttpServer(网络层) → CacheMgr(缓存层) → SQLMgr(数据库层);
自定义异常继承体系:基类 Exception,派生数据库、缓存、HTTP 三种专用异常;
随机触发异常:模拟业务运行时的随机错误;
多态捕获异常:在主函数仅捕获基类异常引用,即可统一处理所有派生类异常;
死循环 + 每秒执行:持续模拟服务运行.
核心:自定义异常继承体系
1️⃣这是大型项目异常设计的标准规范:基类抽象异常 + 派生类细分业务异常.
(1)异常基类Exception
✅设计要点:
what() 定义为 virtual 虚函数:为了多态调用(捕获基类时,能执行派生类重写的逻辑);
成员用 protected:允许派生类直接访问,无需写get/set;
作为所有业务异常的基类,统一捕获入口.
(2)派生类:细分业务异常
三个派生类分别对应数据库、缓存、HTTP模块,重写 what() 定制专属错误信息,并扩展独有成员.
2️⃣业务模块函数:分层调用+抛异常
代码模拟了三层服务调用链:
main() → HttpServer() → CacheMgr() → SQLMgr()
函数内部用 rand() 随机触发异常,throw 抛出派生类异常对象.
✅异常机制关键行为:
一旦执行 throw,当前函数立即终止,程序会栈展开,直接跳转到最近的catch块,中间所有未执行完的代码都不会运行.
1.5异常重新抛出
有时catch到⼀个异常对象后,需要对错误进⾏分类,其中的某种异常错误需要进⾏特殊的处理,其他错误则重新抛出异常给外层调⽤链处理.捕获异常后需要重新抛出,直接throw;就可以把捕获的对象直接抛出.
cpp
#define _CRT_SECURE_NO_WARNINGS 1
#include<iostream>
#include<string>
using namespace std;
//下⾯程序模拟展⽰了聊天时发送消息,发送失败补货异常,但是可能在
//电梯地下室等场景⼿机信号不好,则需要多次尝试,如果多次尝试都发
//送不出去,则就需要捕获异常再重新抛出,其次如果不是⽹络差导致的
//错误,捕获后也要重新抛出。
class Exception
{
public:
Exception(const string& errmsg, int id)
:_errmsg(errmsg)
, _id(id)
{}
//虚函数:多态获取错误信息
virtual string what() const
{
return _errmsg;
}
//获取错误码
int getid() const
{
return _id;
}
protected:
string _errmsg; //错误描述
int _id; //错误码
};
//HTTP异常类(继承自Exception)
class HttpException : public Exception
{
public:
HttpException(const string& errmsg, int id, const string& type)
:Exception(errmsg, id)
, _type(type)
{}
//重写虚函数,定制HTTP错误信息格式
virtual string what() const override
{
string str = "HttpException:";
str += _type;
str += ":";
str += _errmsg;
return str;
}
private:
const string _type;
};
void _SeedMsg(const string& s)
{
if (rand() % 2 == 0)
{
throw HttpException("⽹络不稳定,发送失败", 102, "put");
}
else if (rand() % 7 == 0)
{
throw HttpException("你已经不是对象的好友,发送失败", 103, "put");
}
else
{
cout << "发送成功" << endl;
}
}
void SendMsg(const string& s)
{
//发送消息失败,则再重试3次
for (size_t i = 0; i < 4; i++)
{
try
{
_SeedMsg(s);
break;
}
catch (const Exception& e)
{
// 捕获异常,if中是102号错误,⽹络不稳定,则重新发送
// 捕获异常,else中不是102号错误,则将异常重新抛出
if (e.getid() == 102)
{
// 重试三次以后否失败了,则说明⽹络太差了,重新抛出异常
if (i == 3)
throw;
cout << "开始第" << i + 1 << "重试" << endl;
}
else
{
throw;
}
}
}
}
int main()
{
srand(time(0));
string str;
while (cin >> str)
{
try
{
SendMsg(str);
}
catch (const Exception& e)
{
cout << e.what() << endl << endl;
}
catch (...)
{
cout << "Unkown Exception" << endl;
}
}
return 0;
}1.6异常安全问题
①异常抛出后,后⾯的代码就不再执⾏,前⾯申请了资源(内存、锁等),后⾯进⾏释放,但是中间可能会抛异常就会导致资源没有释放,这⾥由于异常就引发了资源泄漏,产⽣安全性的问题.中间我们需要捕获异常,释放资源后⾯再重新抛出,当然小编后续智能指针会介绍的RAII⽅式解决这种问题是更好的.
②其次析构函数中,如果抛出异常也要谨慎处理,⽐如析构函数要释放10个资源,释放到第5个时抛出异常,则也需要捕获处理,否则后⾯的5个资源就没释放,也资源泄漏了.《EffctiveC++》第8个条款也专⻔讲了这个问题,别让异常逃离析构函数.
cpp
#include<iostream>
using namespace std;
double Divide(int a, int b)
{
// 当b == 0时抛出异常
if (b == 0)
{
throw "Division by zero condition!";
}
return (double)a / (double)b;
}
void Func()
{
// 这⾥可以看到如果发⽣除0错误抛出异常,另外下⾯的array没有得到释放。
// 所以这⾥捕获异常后并不处理异常,异常还是交给外层处理,这⾥捕获了再
// 重新抛出去。
int* array = new int[10];
try
{
int len, time;
cin >> len >> time;
cout << Divide(len, time) << endl;
}
catch (...)
{
// 捕获异常释放内存
cout << "delete []" << array << endl;
delete[] array;
throw; // 异常重新抛出,捕获到什么抛出什么
}
cout << "delete []" << array << endl;
delete[] array;
}
int main()
{
try
{
Func();
}
catch (const char* errmsg)
{
cout << errmsg << endl;
}
catch (const exception& e)
{
cout << e.what() << endl;
}
catch (...)
{
cout << "Unkown Exception" << endl;
}
return 0;
}1.7异常规范
①对于⽤⼾和编译器⽽⾔,预先知道某个程序会不会抛出异常⼤有裨益,知道某个函数是否会抛出异常有助于简化调⽤函数的代码.
②C++98中函数参数列表的后⾯接throw(),表示函数不抛异常,函数参数列表的后⾯接throw(类型1,类型2...)表示可能会抛出多种类型的异常,可能会抛出的类型⽤逗号分割.
③C++98的⽅式这种⽅式过于复杂,实践中并不好⽤,C++11中进⾏了简化,函数参数列表后⾯加noexcept表示不会抛出异常,啥都不加表示可能会抛出异常.
④编译器并不会在编译时检查noexcept,也就是说如果⼀个函数⽤noexcept修饰了,但是同时⼜包含了throw语句或者调⽤的函数可能会抛出异常,编译器还是会顺利编译通过的(有些编译器可能会报个警告).但是⼀个声明了noexcept的函数抛出了异常,程序会调⽤terminate 终⽌程序.
⑤noexcept(expression)还可以作为⼀个运算符去检测⼀个表达式是否会抛出异常,可能会则返回false,不会就返回true.
cpp
#include<iostream>
using namespace std;
// C++98
//这⾥表示这个函数只会抛出bad_alloc的异常
//void* operator new (std::size_t size) throw (std::bad_alloc);
//这⾥表示这个函数不会抛出异常
//void* operator delete (std::size_t size, void* ptr) throw();
//C++11
//size_type size() const noexcept;
//iterator begin() noexcept;
//const_iterator begin() const noexcept;
class MyContainer
{
private:
int* _data;
size_t _size;
public:
// 构造函数
MyContainer(size_t size) : _size(size)
{
_data = new int[size](); // 初始化内存
}
// 析构函数
~MyContainer()
{
delete[] _data;
}
size_t size() const noexcept
{
return _size;
}
int* begin() noexcept
{
return _data;
}
const int* begin() const noexcept
{
return _data;
}
};
double Divide(int a, int b)
{
// 当b == 0时抛出异常
if (b == 0)
{
throw "Division by zero condition!";
}
return (double)a / (double)b;
}
int main()
{
try
{
int len, time;
cin >> len >> time;
cout << Divide(len, time) << endl;
}
catch (const char* errmsg)
{
cout << "捕获异常:" << errmsg << endl;
}
catch (...)
{
cout << "Unkown Exception" << endl;
}
int i = 0;
cout <<"noexcept(Divide(1,2))= "<< noexcept(Divide(1, 2)) <<"(1=不抛, 0=抛)"<< endl;
cout <<"noexcept(Divide(1,0))="<< noexcept(Divide(1, 0)) <<"(1=不抛, 0=抛)"<< endl;
cout <<"noexcept(++i)="<< noexcept(++i) <<"(1=不抛, 0=抛)"<< endl;
MyContainer container(5);
cout << "容器大小 size = " << container.size() << endl;
return 0;
}2.标准库的异常
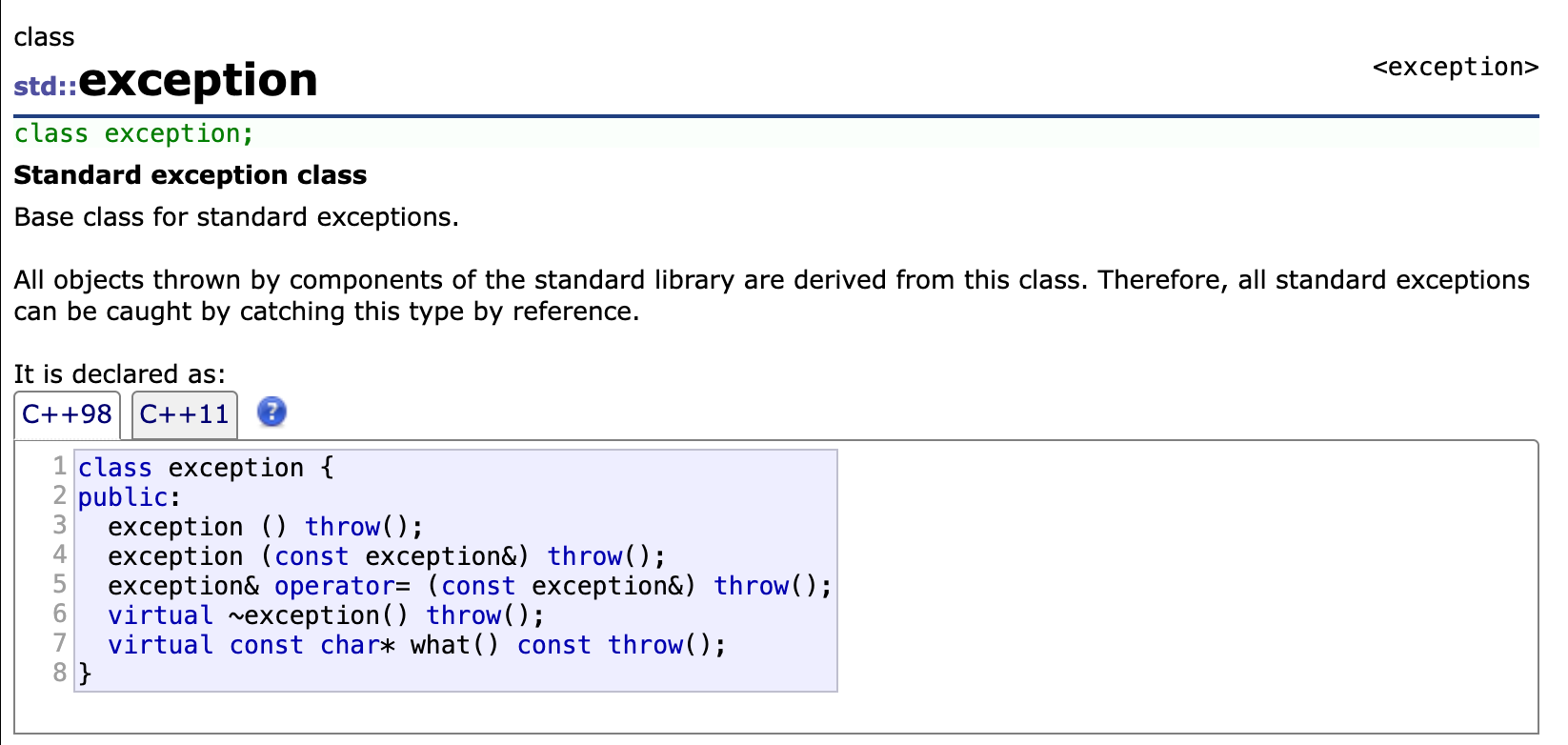
C++标准库的异常官方文档
这张图是C++标准库中std::exception类的官方文档,它是整个C++异常体系的根基类.我这里只说明一下基本的情况,想了解详细的内容可以自己点击链接进去看看.
1️⃣整体定位
头文件:
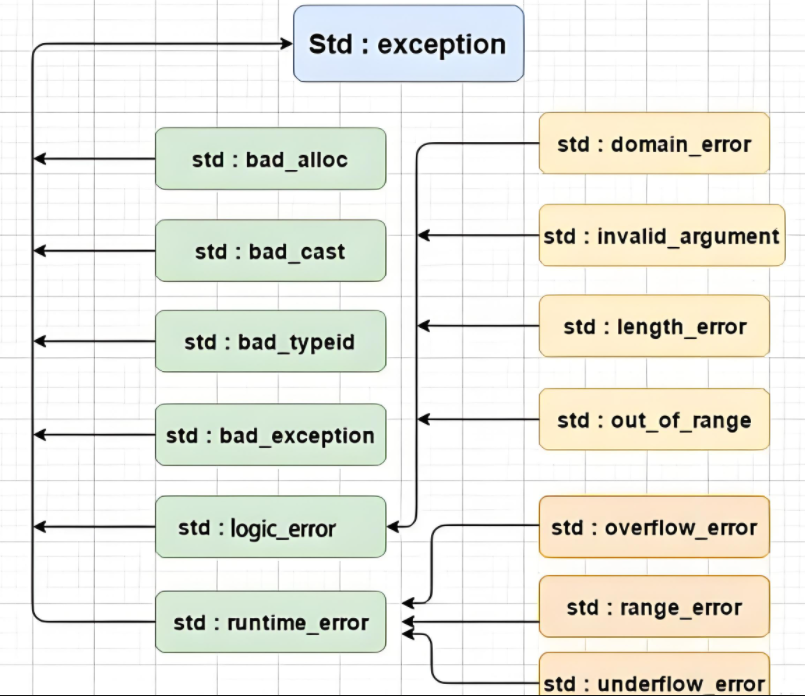
身份:std::exception是所有C++标准库异常的公共基类.
核心价值:标准库中所有组件抛出的异常(如内存分配失败 std::bad_alloc、越界访问 std::out_of_range 等)都继承自它.因此,只要捕获 const std::exception&,就能统一捕获所有标准库异常,实现错误的集中处理.
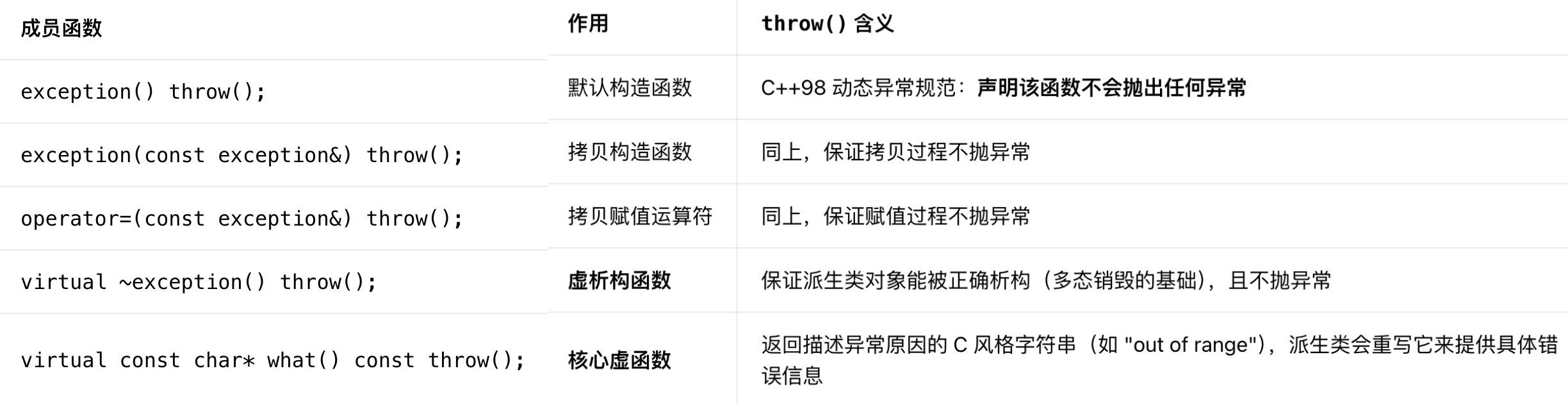
2️⃣C++98版本的类声明解析
⚠️注意:throw() 是C++98的动态异常规范,用来声明函数可能抛出的异常类型;throw() 空括号表示不会抛出任何异常.C++11 之后,这种写法被noexcept关键字替代,但功能完全等价.
3️⃣设计思想与使用场景
多态捕获:因为 what() 是虚函数,当你捕获基类std::exception引用时,调用 e.what() 会自动绑定到实际派生类的实现,从而拿到具体的错误描述.
自定义异常的基类:实际项目中,我们也会继承std::exception来实现自定义异常类,这样就能和标准库异常体系兼容,被统一捕获.
4️⃣C++11之后的演进
C++11引入noexcept后,std::exception的声明被更新为:
把throw()替换为noexcept,语义完全一致,但语法更简洁,是现代C++的推荐写法.
核心接口 what() 保持不变,保证了向后兼容.
C++标准库也定义了⼀套⾃⼰的⼀套异常继承体系库,基类是exception,所以我们⽇常写程序,需要在主函数捕获exception即可,要获取异常信息,调⽤what函数,what是⼀个虚函数,派⽣类可以重写.



3.C语言中的类型转换
①在C语⾔中,如果赋值运算符左右两侧类型不同,或者形参与实参类型不匹配,或者返回值类型与接收返回值类型不⼀致时等场景,就需要发⽣类型转化,C语⾔中总共有两种形式的类型转换:隐式类型转换和显式强制类型转换.
②隐式类型转化:编译器在编译阶段⾃动进⾏,能转就转,不能转就编译失败.
③显式强制类型转化:需要⽤⼾⾃去显示在变量前⽤括号指定要转换的类型.
④并不是任意类型之前都⽀持转换,两个类型⽀持转换需要有⼀定关联性,也就是说转换后要有⼀定的意义,两个毫⽆关联的类型是不⽀持转换的.
cpp
#include<iostream>
using namespace std;
int main()
{
int i = 1;
//隐式类型转换
//隐式类型转换主要发⽣在整形和整形之间,整形和浮点数之间,浮点数和浮点数之间
double d = i;
printf("%d, %.2f\n", i, d);
int* p = &i;
//显示的强制类型转换
//强制类型转换主要发⽣在指针和整形之间,指针和指针之间
int address = (int)p;
printf("%p, %d\n", p, address);
// malloc返回值是void*,被强转成int*
int* ptr = (int*)malloc(8);
//编译报错:类型强制转换: ⽆法从"int *"转换为"double"
//指针是地址的编号,也是⼀种整数,所以可以和整形互相转换
//但是指针和浮点数毫⽆关联,强转也是不⽀持的
//d = (double)p;
return 0;
}4.C++中的类型转换
①C++兼容C,所以C⽀持的隐式类型转换和显式强制类型转换C++都⽀持.
②C++还⽀持内置类型到⾃定义类型之间的转换,内置类型转成⾃定义类型需要构造函数的⽀持,⾃定义类型转成内置类型,需要⼀个operator类型()的函数去⽀持.
③C++还⽀持⾃定义类型到⾃定义类型之间的转换,需要对应类型的构造函数⽀持即可,⽐如A类型对
象想转成B类型,则⽀持⼀个形参为A类型的B构造函数即可⽀持.
cpp
#include <iostream>
using namespace std;
//内置类型和⾃定义类型之间
//1、⾃定义类型 = 内置类型 ->构造函数⽀持
//2、内置类型 = ⾃定义类型 ->operator 内置类型 ⽀持
class A
{
public:
//构造函数加上explicit就不⽀持隐式类型转换了
//explicit A(int a)
A(int a)
:_a1(a)
,_a2(a)
{}
A(int a1, int a2)
:_a1(a1)
,_a2(a2)
{}
//加上explicit就不⽀持隐式类型转换了
//explicit operator int()
operator int() const
{
return _a1 + _a2;
}
private:
int _a1 = 1;
int _a2 = 1;
};
class B
{
public:
B(int b)
:_b1(b)
{}
//⽀持A类型对象转换为B类型对象
B(const A& aa)
:_b1(aa)
{}
private:
int _b1 = 1;
};
int main()
{
//单参数的转换
string s1 = "1111111";
A aa1 = 1;
A aa2 = (A)1;
//多参数的转换
A aa3 = { 2,2 };
const A& aa4 = { 2,2 };
int z = aa1.operator int();
int x = aa1;
int y = (int)aa2;
cout << x << endl;
cout << y << endl;
cout << z << endl;
std::shared_ptr<int> foo;
std::shared_ptr<int> bar(new int(34));
//if(foo.operator bool())
if (foo)
std::cout << "foo points to " << *foo << '\n';
else
std::cout << "foo is null\n";
if (bar)
std::cout << "bar points to " << *bar << '\n';
else
std::cout << "bar is null\n";
//A类型对象隐式转换为B类型
B bb1 = aa1;
B bb2(2);
bb2 = aa1;
const B& ref1 = aa1;
return 0;
}
cpp
//⾃定义类型之间转换的实践样例
#include <iostream>
#include<assert.h>
using namespace std;
namespace lcz
{
template<class T>
struct ListNode
{
ListNode<T>* _next;
ListNode<T>* _prev;
T _data;
ListNode(const T& data = T())
:_next(nullptr)
, _prev(nullptr)
, _data(data)
{
}
};
template<class T, class Ref, class Ptr>
struct ListIterator
{
typedef ListNode<T> Node;
typedef ListIterator<T, Ref, Ptr> Self;
Node* _node;
ListIterator(Node* node)
:_node(node)
{
}
// typedef ListIterator<T, T&, T*> iterator;
// typedef ListIterator<T, const T&, const T*> const_iterator;
// ListIterator实例化为iterator时,这个函数是拷⻉构造
// ListIterator实例化为const_iterator时,这个函数⽀持iterator转换为const_iterator构造函数
ListIterator(const ListIterator<T, T&, T*>& it)
:_node(it._node)
{
}
// ++it;
Self& operator++()
{
_node = _node->_next;
return *this;
}
Self& operator--()
{
_node = _node->_prev;
return *this;
}
Self operator++(int)
{
Self tmp(*this);
_node = _node->_next;
return tmp;
}
Self& operator--(int)
{
Self tmp(*this);
_node = _node->_prev;
return tmp;
}
Ref operator*()
{
return _node->_data;
}
Ptr operator->()
{
return &_node->_data;
}
bool operator!=(const Self& it)
{
return _node != it._node;
}
bool operator==(const Self& it)
{
return _node == it._node;
}
};
template<class T>
class list
{
typedef ListNode<T> Node;
public:
// 同⼀个类模板给不同参数会实例化出不同的类型
typedef ListIterator<T, T&, T*> iterator;
typedef ListIterator<T, const T&, const T*> const_iterator;
iterator begin()
{
return iterator(_head->_next);
}
const_iterator begin() const
{
return const_iterator(_head->_next);
}
iterator end()
{
return iterator(_head);
}
const_iterator end() const
{
return const_iterator(_head);
}
void empty_init()
{
_head = new Node();
_head->_next = _head;
_head->_prev = _head;
}
list()
{
empty_init();
}
list(initializer_list<T> il)
{
empty_init();
for (const auto& e : il)
{
push_back(e);
}
}
void push_back(const T& x)
{
insert(end(), x);
}
// 没有iterator失效
iterator insert(iterator pos, const T& x)
{
Node* cur = pos._node;
Node* newnode = new Node(x);
Node* prev = cur->_prev;
// prev newnode cur
prev->_next = newnode;
newnode->_prev = prev;
newnode->_next = cur;
cur->_prev = newnode;
return iterator(newnode);
}
private:
Node* _head;
};
}
int main()
{
lcz::list<int> lt = { 1,2,3,4 };
// 权限缩⼩?权限缩⼩和放⼤,仅限于const的指针和引⽤
// 这⾥不是权限缩⼩,这⾥是⾃定义类型=⾃定义类型之间的类型转换
// 具体实现看下⾯ListIterator中对应的构造函数的实现
lcz::list<int>::const_iterator cit = lt.begin();
while (cit != lt.end())
{
cout << *cit << " ";
++cit;
}
cout << endl;
return 0;
}5.C++显示强制类型转换
5.1类型安全
①类型安全是指编程语⾔在编译和运⾏时提供保护机制,避免⾮法的类型转换和操作,导致出现⼀个内存访问错误等,从⽽减少程序运⾏时的错误.
②C语⾔不是类型安全的语⾔,C语⾔允许隐式类型转换,⼀些特殊情况下就会导致越界访问的内存错误,其次不合理的使⽤强制类型转换也会导致问题,⽐如⼀个int* 的指针强转成double*访问就会出现越界.
③C++兼容C语⾔,⽀持隐式类型转换和强制类型转换,C++也不是类型安全的语⾔,C++提出4个显示的命名强制类型转换static_cast/reinterpret_cast/const_cast/dynamic_cast就是为了让类型转换相对⽽⾔更安全.
cpp
#include <iostream>
using namespace std;
void insert(size_t pos, char ch)
{
// 这⾥当pos==0时,就会引发由于隐式类型转换
// end跟pos⽐较时,提升为size_t导致判断结束逻辑出现问题
// 在数组中访问挪动数据就会出现越界,经典的类型安全问题
int end = 10;
while (end >= pos)
{
// ...
cout << end << endl;
--end;
}
}
int main()
{
insert(5, 'x');
//insert(0, 'x');
// 这⾥会本质已经出现了越界访问,只是越界不⼀定能被检查出来
int x = 100;
double* p1 = (double*)&x;
cout << *p1 << endl;
const int y = 0;
//volatile const int y = 0;加上volatile之后,y的输出结果就是1
int* p2 = (int*)&y;
(*p2) = 1;
//这⾥打印的结果是1和0,也是因为我们类型转换去掉了const属性
//但是编译器认为y是const的,不会被改变,所以会优化编译时放到
//寄存器或者直接替换y为0导致的
cout << *p2 << endl;
cout << y << endl;
return 0;
}5.2C++中4个显示强制类型转换运算符
①
static_cast⽤于两个类型意义相近的转换,这个转换是具有明确定义的,只要底层不包含const,都可以使⽤static_cast.
②reinterpret_cast⽤于两个类型意义不相近的转换,reinterpret是重新解释的意思,通常为运算对象的位模式提供较低层次上的重新解释,也就是说转换后对原有内存的访问解释已经完全改变了,⾮常的⼤胆.所以我们要谨慎使⽤,清楚知道这样转换是没有内存访问安全问题的.
③const_cast⽤于const类型到⾮const类型的转换,去掉了const属性,也是⼀样的我们要谨慎使⽤,否则可能会出现意想不到的结果.
④dynamic_cast⽤于将基类的指针或者引⽤安全的转换成派⽣类的指针或者引⽤.如果基类的指针或者引⽤时指向派⽣类对象的,则转换回派⽣类指针或者引⽤时可以成功的,如果基类的指针指向基类对象,则转换失败返回nullptr,如果基类引⽤指向基类对象,则转换失败,抛出bad_cast异常.
⑤其次dynamic_cast要求基类必须是多态类型,也就是基类中必须有虚函数.因为dynamic_cast是运⾏时通过虚表中存储的type_info判断基类指针指向的是基类对象还是派⽣类对象.
cpp
#include <iostream>
using namespace std;
int main()
{
// 对应隐式类型转换 -- 数据的解释意义没有改变
double d = 12.34;
int a = static_cast<int>(d);
cout << a << endl;
int&& ref = static_cast<int&&>(a);
// 对应强制类型转换 -- 数据的解释意义已经发⽣改变
int* p1 = reinterpret_cast<int*>(a);
// 对应强制类型转换中有⻛险的去掉const属性
// 所以要注意加volatile
volatile const int b = 0;
int* p2 = const_cast<int*>(&b);
*p2 = 1;
cout << b << endl;
cout << *p2 << endl;
return 0;
}
cpp
#include <iostream>
using namespace std;
class A
{
public:
virtual void f() {}
int _a = 1;
};
class B : public A
{
public:
int _b = 2;
};
void fun1(A* pa)
{
//指向⽗类转换时有⻛险的,后续访问存在越界访问的⻛险
//指向⼦类转换时安全
B* pb1 = (B*)pa;
cout << "pb1:" << pb1 <<endl;
cout << pb1->_a << endl;
cout << pb1->_b << endl;
pb1->_a++;
pb1->_b++;
cout << pb1->_a << endl;
cout << pb1->_b << endl;
}
void fun2(A* pa)
{
//dynamic_cast会先检查是否能转换成功(指向⼦类对象),能成功则转换,
//(指向⽗类对象)转换失败则返回nullptr
B* pb1 = dynamic_cast<B*>(pa);
if (pb1)
{
cout << "pb1:" << pb1 << endl;
cout << pb1->_a << endl;
cout << pb1->_b << endl;
pb1->_a++;
pb1->_b++;
cout << pb1->_a << endl;
cout << pb1->_b << endl;
}
else
{
cout << "转换失败" << endl;
}
}
void fun3(A& pa)
{
//转换失败,则抛出bad_cast异常
try {
B& pb1 = dynamic_cast<B&>(pa);
cout << "转换成功" << endl;
}
catch (const exception& e)
{
cout << e.what() << endl;
}
}
int main()
{
A a;
B b;
//fun1(&a);
//fun1(&b);
fun2(&a);
fun2(&b);
fun3(a);
fun3(b);
return 0;
}6.RTTI(运行时类型信息)
①RTTI的英⽂全称是"Runtime Type Identification",中⽂称为"
运⾏时类型识别",它指的是程序在运⾏的时候才确定需要⽤到的对象是什么类型的.⽤于在运⾏时(⽽不是编译时)获取有关对象的信息.
②RTTI主要由两个运算符实现,typeid和dynamic_cast;typeid主要⽤于返回表达式的类型,dynamic_cast前⾯已经介绍了,主要⽤于将基类的指针或者引⽤安全的转换成派⽣类的指针或者引⽤.
③typeid(e)中e可以是任意表达式或类型的名字,typeid(e)的返回值是typeinfo或typeinfo派⽣类对象的引⽤,typeinfo可以只⽀持⽐较等于和不等于,name成员函数可以返回C⻛格字符串表示对象类型名字,typeinfo的精确定义随着编译器的不同⽽略有差异,也就以为着同⼀个e表达式,不同编译器下,typeid(e).name()返回的名字可能是不⼀样的.
④typeinfo的⽂档
⑤typeid(e)时,当运算对象不属于类类型或者是⼀个不包含任何虚函数的类时,typeid返回的是运算对象的静态类型,当运算对象是定义了⾄少⼀个虚函数的类的左值时,typeid的返回结果直到运⾏时才会求得.
⑥✅优点
运行时动态识别类型,灵活处理多态对象;
dynamic_cast 安全转型,避免野指针、非法访问.
❌ 缺点
运行时开销:需要存储额外的类型信息,降低效率;
破坏封装性:优先使用虚函数多态,而非 RTTI 判断类型;
现代C++项目中,尽量少用RTTI.
cpp
#include<iostream>
#include<string>
#include<vector>
#include<list>
using namespace std;
int main()
{
int a[10];
int* ptr = nullptr;
cout << typeid(10).name() << endl;
cout << typeid(a).name() << endl;
cout << typeid(ptr).name() << endl;
cout << typeid(string).name() << endl;
cout << typeid(string::iterator).name() << endl;
cout << typeid(vector<int>).name() << endl;
cout << typeid(vector<int>::iterator).name() << endl;
return 0;
}
cpp
#include<iostream>
using namespace std;
class A
{
public:
virtual void func()
{}
protected:
int _a1 = 1;
};
class B : public A
{
protected:
int _b1 = 2;
};
int main()
{
try
{
B* pb = new B;
A* pa = (A*)pb;
if (typeid(*pb) == typeid(B))
{
cout << "typeid(*pb) == typeid(B)" << endl;
}
//如果A和B不是继承关系,则会抛bad_typeid异常
if (typeid(*pa) == typeid(B))
{
cout << "typeid(*pa) == typeid(B)" << endl;
}
//这⾥pa和pb是A*和B*,不是类类型对象,它会被当做编译是求值的静态类型运算
//所以这⾥始终是不相等的
if (typeid(pa) == typeid(pb))
{
cout << "typeid(pa) == typeid(B)" << endl;
}
}
catch (const std::exception& e)
{
cout << e.what() << endl;
}
return 0;
}
敬请期待下一篇文章内容:C++智能指针的使⽤及其原理!
每日心灵鸡汤:见自己,明得失!
知人者智,自知者明.人生中最遗憾的不是没有人懂你,而是终其一生你都没看懂自己.成长,就是不断认清自己的过程.懂得认清自己的优劣势,才能在取得成绩时不骄不躁,在遇到挫折时勇于挑战;认清自己的能力边界,才能知不足而上进;认清自己的过往得失,才能改正错误、不断进步.当你能够认清自己,过去的经历有了解释,未来的行动也有了方向.读懂真实的自己,形成自己的价值体系,顺势而为,掌握人生的方向盘,至此方为"见自己".
