(学习自黑马程序员)黑马程序员Python+AI零基础入门到大神全套视频课程
爬虫
网络爬虫(网络机器人),自动浏览并抓取网络数据的程序或脚本。
robots协议(爬虫协议) 哪些页面可以抓取,哪些页面不能抓取

对豌豆荚全禁止
通过在连接后面加/robots.txt来访问,比如:https://www.baidu.com/robots.txt
User-agent: *# 所有网络机器人
Disallow: /wp-admin/
Allow: /wp-admin/admin-ajax.php
Sitemap: https://www.tiobe.com/sitemap_index.xml
python
import requests
from lxml import html
# 定义url
target_url = "https://www.tiobe.com/tiobe-index/"
# 发送请求, 获取数据
response = requests.get(target_url)
# 输出数据到控制台
#print(response.text)
document = html.fromstring(response.text)
# 解析数据
# 解析表头
# th_list = document.xpath("//table[@id='top20']/thead/tr/th/text()")
# th_list = document.xpath("/html/body/section/div/article/table[1]/thead/tr/th/text()")
th_list = document.xpath("//*[@id='top20']/thead/tr/th/text()")
print(th_list)
# 解析表格中的数据
tr_list = document.xpath("//table[@id='top20']/tbody/tr")
for tr in tr_list:
td_list = tr.xpath("./td/text()")
print(td_list)# 输出数据到控制台 print(response.text)此代码将服务器端响应的前端HTML代码
Xpath
lxml是一个HTML/XML (标签构成的语言)文档的解析库,支持基于Xpath语法来解析和获取网页数据
Xpath:是用于在文档中导航或定位元素的查询语言
document.xpath()

为了获取其文本都需要text()
获取对应的属性用@*如:@src获取src属性值,比如:'//img/@src' -----------获取的是<img src='xx',alt='aa'>的标签中的src属性值
/开头就必须从根目录一步步屡到目标位置。
//就直接找到符合目标的标签
p1第一个 <p>标签,这是从1开始的,而不是从0开始。
python
document.xpath("//table[@id='top20']/thread/tr/th/text()")
# 定位属性中id为top20的Table,然后向下找到text定位属性中id为top20的Table,然后向下找到text
python
from lxml import html
# 读取 html 文件
with open("resources/仙逆人物志.html", "r", encoding="utf-8") as f:
html_text = f.read()
# 解析html的文本, 将其转换为一个html文档对象
document = html.fromstring(html_text)
# 解析表头 - xpath语法
# /table/thead/tr/th/text() : 表示从根节点开始匹配
# //table/thead/tr/th/text(): 从任意位置开始匹配
# th_list = document.xpath("/html/body/div/div/table/thead/tr/th/text()")
# th_list = document.xpath("//table/thead/tr/th/text()")
th_list = document.xpath("//thead/tr/th/text()")
print(th_list)
# tr[2] : 表示匹配第2个tr标签
td_list = document.xpath("//tbody/tr[2]/td/text()")
print(td_list)
# last() : 表示匹配最后一个
td_list = document.xpath("//tbody/tr[last()-1]/td/text()")
print(td_list)
# p[@class]: 表示匹配class属性为p的标签
p_list = document.xpath("//p[@class]/text()")
print(p_list)
# p[@class='xn']: 表示匹配class属性为xn的p标签
p_list = document.xpath("//p[@class='xn']/text()")
print(p_list)
# * : 表示匹配任意标签
th_list = document.xpath("//thead/tr/*/text()")
print(th_list)
# @src: 表示匹配src属性
# @* : 表示匹配任意属性
# a_list = document.xpath("//td/img/@src")
a_list = document.xpath("//td/img/@*")
print(a_list)快速定位
F12通过选取页面原素,定位到Elements中的页面源码,定位的元素右键copy-copyfullXpath
Copy-xpath
案例1------电影榜单Top100
爬取信息:标题、年份、评分、简洁
CSV文件
comma-separated values 逗号分隔值,一种文本文件格式,用于存储表格数据,可用Excel打开。
中文windows默认编码为GBK编码,如果使用功能UTF-8编码,再打开就会乱码。
所以保存时需要注意更改编码方式,如果找不到GBK可以用ANSI即和系统编码一致
(写和读的格式不一样就会乱码)
而PyCharm或者VSCode默认使用UTF-8编码,所以使用他们打开要注意编码方式

python
import csv
with open('test.csv','w',encoding='utf-8',newline='') as f:
writer = csv.DictWriter(f,filenames=['',''])
writer.writeheafer()# 写入表头
writer.writerow({"name": "张三", "age": 18})
writer.writerow({"name": "李四", "age": 20})
with open('test.csv','r',encoding='utf-8') as f:
reader = csv.DictReader(f)
for row in reader:
print(row)开始案例
- 1.明确网站的robots.txt中的抓取规则
- 2.查看页面结构,拆解页面元素,编码实现
python
import requests
import csv
from lxml import html
# 常量
MOVIE_LIST_FILE = "csv_data/movie_list.csv"
TMDB_BASE_URL = "https://www.themoviedb.org"
TMDB_TOP_URL = "https://www.themoviedb.org/movie/top-rated"
# 保存电影数据, 保存为 csv 文件
def save_all_movies(all_movies):
with open(MOVIE_LIST_FILE, "w", encoding="utf-8", newline="") as csvfile:
writer = csv.DictWriter(csvfile, fieldnames=["电影名", "年份", "上映时间", "类型", "时长", "评分", "语言", "导演", "作者", "宣传语", "简介"])
writer.writeheader() # 写入表头
writer.writerows(all_movies) # 写入数据
# 获取电影详情
def get_movie_info(movie_info_url):
# 1. 发送请求, 获取电影详情数据
movie_response = requests.get(movie_info_url, timeout=60)
print(f"发送请求{movie_info_url}, 获取电影详情数据 ...")
# 2. 解析数据, 获取电影详情
movie_doc = html.fromstring(movie_response.text)
movie_names = movie_doc.xpath("//*[@id='original_header']/div[2]/section/div[1]/h2/a/text()") # 电影名称
movie_years = movie_doc.xpath("//*[@id='original_header']/div[2]/section/div[1]/h2/span/text()") # 上映年份
movie_dates = movie_doc.xpath("//*[@id='original_header']/div[2]/section/div[1]/div/span[2]/text()") # 上映时间
movie_tags = movie_doc.xpath("//*[@id='original_header']/div[2]/section/div[1]/div/span[3]/a/text()") # 类型
movie_cost_times = movie_doc.xpath("//*[@id='original_header']/div[2]/section/div[1]/div/span[4]/text()") # 时长
movie_scores = movie_doc.xpath("//*[@id='consensus_pill']/div/div[1]/div/div/@data-percent") # 评分
movie_languages = movie_doc.xpath("//*[@id='media_v4']/div/div/div[2]/div/section/div[1]/div/section[1]/p[3]/text()") # 语言
movie_directors = movie_doc.xpath("//*[@id='original_header']/div[2]/section/div[3]/ol/li[1]/p[1]/a/text()") # 导演
movie_authors = movie_doc.xpath("//*[@id='original_header']/div[2]/section/div[3]/ol/li[2]/p[1]/a/text()") # 作者
movie_slogans = movie_doc.xpath("//*[@id='original_header']/div[2]/section/div[3]/h3[1]/text()") # 宣传语
movie_descriptions = movie_doc.xpath("//*[@id='original_header']/div[2]/section/div[3]/div/p/text()") # 简介
# 3. 返回电影详情 - 字典
movie_info = {
"电影名": movie_names[0].strip() if movie_names else '',
"年份": movie_years[0].strip() if movie_years else '',
"上映时间": movie_dates[0].strip() if movie_dates else '',
"类型": ",".join(movie_tags) if movie_tags else '',
"时长": movie_cost_times[0].strip() if movie_cost_times else '',
"评分": movie_scores[0].strip() if movie_scores else '',
"语言": movie_languages[0].strip() if movie_languages else '',
"导演": ",".join(movie_directors) if movie_directors else '',
"作者": ",".join(movie_authors) if movie_authors else '',
"宣传语": movie_slogans[0].strip() if movie_slogans else '',
"简介": movie_descriptions[0].strip() if movie_descriptions else ''
}
return movie_info
# 主函数, 定义核心逻辑
def main():
response = requests.get(TMDB_TOP_URL, timeout=60)
print(f"发送请求, 获取TMDB电影榜单数据 ...")
# 2.解析数据, 获取电影列表
document = html.fromstring(response.text)
movie_list = document.xpath("//*[@id='page_1']/div[@class='card style_1']")
# 3.遍历电影列表, 获取电影详情
all_movies = [] # 保存所有的电影数据
for movie in movie_list:
movie_urls = movie.xpath("./div/div/a/@href")
if movie_urls:
# 电影详情的url
movie_info_url = TMDB_BASE_URL + movie_urls[0]
# 发送请求, 获取电影详情数据
movie_info = get_movie_info(movie_info_url)
all_movies.append(movie_info)
# 4.保存数据, 保存为 csv 文件
print("获取到所有的电影详情, 保存电影数据到CSV文件 ...")
save_all_movies(all_movies)
if __name__ == '__main__':
main()分页加载
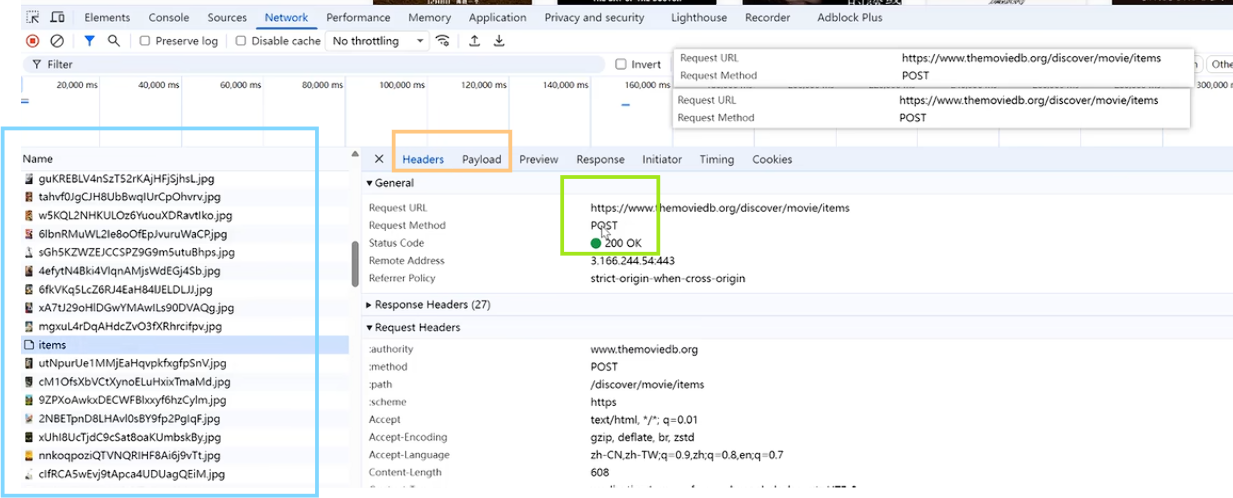
点击加载,进入下一页面的加载过程中。按F12,查看Network在Name当中可以看到第一个items。是加载网页前端代码,下面的都是一些jpg的图片。每次向下滑动鼠标,可以看到它新加载的下一页的数据。在Network当中可以看到在一条条jpg图片中夹杂着items,然后又是一大堆图片,再是一个items.每个items都是一个post请求。
Headers中是一个post请求。每个post请求是有请求体的,该请求的请求体在Payload中。
Payload当中有很多参数。可以通过点击不同的页面加载items,看到这些参数之间的区别就是page属性对应的不同的数字。
在Payload-View parsed中产看完整请求体代码,可见其中是由&链接一个个属性的。
python
补充:GET 与 POST 的区别
【HTTP】方法(method)以及 GET 和 POST 的区别
在 HTTP 协议中,GET 和 POST 是最常用的两种请求方法,它们在数据传输方式、安全性、缓存机制等方面存在显著差异。
数据传输方式
GET:将参数以 key=value 形式附加在 URL 之后,通过 ? 连接,多个参数用 & 分隔,例如:http://example.com/test?name=Tom&age=20
POST:将参数放在 HTTP 请求的消息体中,不会显示在 URL 上,适合传输大量或敏感数据。
适用场景
GET:适合数据查询、无副作用的请求。
POST:适合提交表单、上传文件、涉及数据修改的操作。由于页面结构不规范或者说是由于页面结构特殊导致抓取不到数据,需要对特殊情况做兼容性处理,将按照第一个的/span3这种改为/span@class=''按照属性来抓取
python
import requests
import csv
from lxml import html
# 常量
MOVIE_LIST_FILE = "csv_data/movie_list.csv"
TMDB_BASE_URL = "https://www.themoviedb.org"
TMDB_TOP_URL_1 = "https://www.themoviedb.org/movie/top-rated" # 高分电影榜单的url(第1页)
TMDB_TOP_URL_2 = "https://www.themoviedb.org/discover/movie/items" # 高分电影榜单的url(第2页之后)
# 保存电影数据, 保存为 csv 文件
def save_all_movies(all_movies):
with open(MOVIE_LIST_FILE, "w", encoding="utf-8", newline="") as csvfile:
writer = csv.DictWriter(csvfile, fieldnames=["电影名", "年份", "上映时间", "类型", "时长", "评分", "语言", "导演", "作者", "宣传语", "简介"])
writer.writeheader() # 写入表头
writer.writerows(all_movies) # 写入数据
# 获取电影详情
def get_movie_info(movie_info_url):
# 1. 发送请求, 获取电影详情数据
movie_response = requests.get(movie_info_url, timeout=60)
print(f"发送请求{movie_info_url}, 获取电影详情数据 ...")
# 2. 解析数据, 获取电影详情
movie_doc = html.fromstring(movie_response.text)
movie_names = movie_doc.xpath("//*[@id='original_header']/div[2]/section/div[1]/h2/a/text()") # 电影名称
movie_years = movie_doc.xpath("//*[@id='original_header']/div[2]/section/div[1]/h2/span/text()") # 上映年份
movie_dates = movie_doc.xpath("//*[@id='original_header']/div[2]/section/div[1]/div/span[@class='release']/text()") # 上映时间
movie_tags = movie_doc.xpath("//*[@id='original_header']/div[2]/section/div[1]/div/span[@class='genres']/a/text()") # 类型
movie_cost_times = movie_doc.xpath("//*[@id='original_header']/div[2]/section/div[1]/div/span[@class='runtime']/text()") # 时长
movie_scores = movie_doc.xpath("//*[@id='consensus_pill']/div/div[1]/div/div/@data-percent") # 评分
movie_languages = movie_doc.xpath("//*[@id='media_v4']/div/div/div[2]/div/section/div[1]/div/section[1]/p[3]/text()") # 语言
movie_directors = movie_doc.xpath("//*[@id='original_header']/div[2]/section/div[3]/ol/li[1]/p[1]/a/text()") # 导演
movie_authors = movie_doc.xpath("//*[@id='original_header']/div[2]/section/div[3]/ol/li[2]/p[1]/a/text()") # 作者
movie_slogans = movie_doc.xpath("//*[@id='original_header']/div[2]/section/div[3]/h3[1]/text()") # 宣传语
movie_descriptions = movie_doc.xpath("//*[@id='original_header']/div[2]/section/div[3]/div/p/text()") # 简介
# 3. 返回电影详情 - 字典
movie_info = {
"电影名": movie_names[0].strip() if movie_names else '',
"年份": movie_years[0].strip() if movie_years else '',
"上映时间": movie_dates[0].strip() if movie_dates else '',
"类型": ",".join(movie_tags) if movie_tags else '',
"时长": movie_cost_times[0].strip() if movie_cost_times else '',
"评分": movie_scores[0].strip() if movie_scores else '',
"语言": movie_languages[0].strip() if movie_languages else '',
"导演": ",".join(movie_directors) if movie_directors else '',
"作者": ",".join(movie_authors) if movie_authors else '',
"宣传语": movie_slogans[0].strip() if movie_slogans else '',
"简介": movie_descriptions[0].strip() if movie_descriptions else ''
}
return movie_info
# 主函数, 定义核心逻辑
def main():
all_movies = [] # 保存所有的电影数据
# 循环获取电影列表(第1页到第5页)
for page_num in range(1, 6):#(获取100个电影而每页只展示20个电影,所以需要获取5页的数据)
# 1.发送请求, 获取高分电影榜单数据
if page_num == 1:
response = requests.get(TMDB_TOP_URL_1, timeout=60)# 访问第一页的时候是get请求
else:# 访问第二页及之后的页面的时候是post请求,并在请求体中指定请求参数
response = requests.post(TMDB_TOP_URL_2,
f"air_date.gte=&air_date.lte=&certification=&certification_country=CN&debug=&first_air_date.gte=&first_air_date.lte=&include_adult=false&latest_ceremony.gte=&latest_ceremony.lte=&page={page_num}&primary_release_date.gte=&primary_release_date.lte=®ion=&release_date.gte=&release_date.lte=2026-07-31&show_me=everything&sort_by=vote_average.desc&vote_average.gte=0&vote_average.lte=10&vote_count.gte=300&watch_region=CN&with_genres=&with_keywords=&with_networks=&with_origin_country=&with_original_language=&with_watch_monetization_types=&with_watch_providers=&with_release_type=&with_runtime.gte=0&with_runtime.lte=400",
timeout=60)
print(f"发送请求, 访问第{page_num}页的数据, 获取TMDB电影榜单数据 ...")
# 2.解析数据, 获取电影列表
document = html.fromstring(response.text)
movie_list = document.xpath(f"//*[@id='page_{page_num}']/div[@class='card style_1']")
# 3.遍历电影列表, 获取电影详情
for movie in movie_list:
movie_urls = movie.xpath("./div/div/a/@href")
if movie_urls:
# 电影详情的url
movie_info_url = TMDB_BASE_URL + movie_urls[0]
# 发送请求, 获取电影详情数据
movie_info = get_movie_info(movie_info_url)
all_movies.append(movie_info)
# 4.保存数据, 保存为 csv 文件
print("获取到所有的电影详情, 保存电影数据到CSV文件 ...")
save_all_movies(all_movies)
if __name__ == '__main__':
main()