前言
这一片博客开始,我们进入STL标准模板库的学习
什么是STL
STL(Standard Template Library)是C++标准库的核心组成部分,提供了一系列通用模板类和函数 ,实现了常见的数据结构和算法。它基于泛型编程思想,强调代码复用和高效性。
STL的版本

STL的六大组件
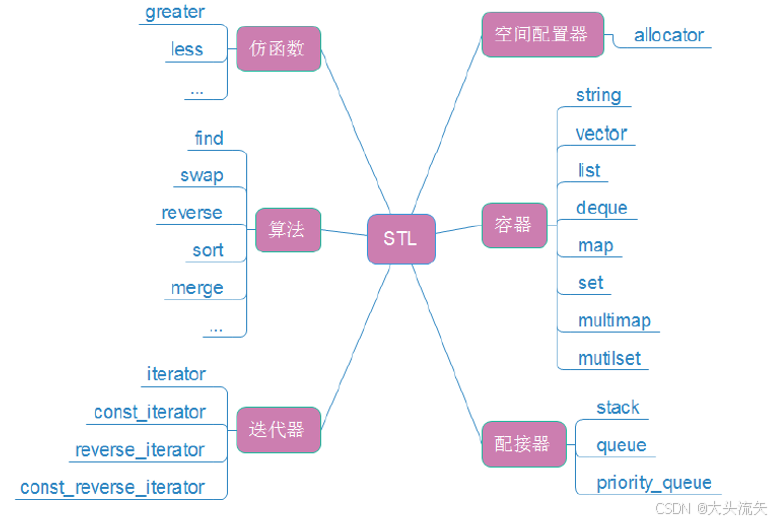
就像上图所示的一样,STL中一共有六大组件分别是仿函数、算法、迭代器、空间配置器、容器、配接器
今天我们主要来讲一下容器中的string和迭代器中的iterator、const_iterator
STL中的容器string
string - C++ Reference (cplusplus.com)
上面这个链接是C++的一个文档网站,里面有C++中相关的所有内容
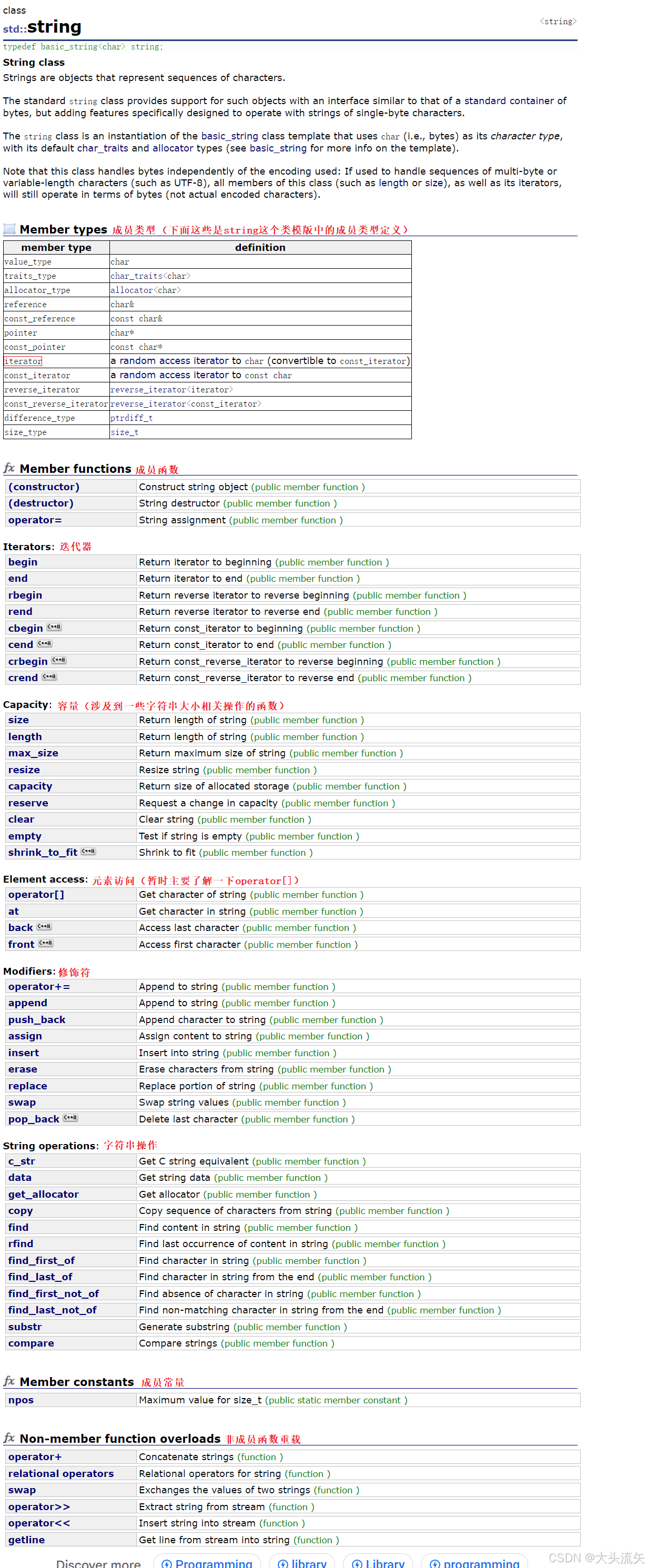
这里我们可以看到string其实就是一个类,而且是一个字符串类型的类
string的构造函数
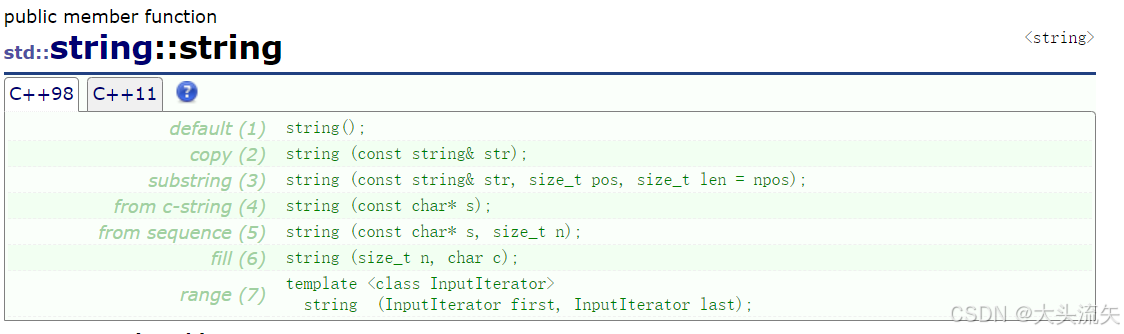
这就是string的构造函数,这里主要的是要去掌握1、2、4具体的3、5可以做一个了解,因为没有前面三个常用
cpp
// string 是 basic_string<char> 的重命名
typedef basic_string<char> string;
basic_string<char> s;
int main()
{
//string();
string s1;
s1 = "hello world";
//string(const string& str)
string s2(s1);
string s3 = s2;//调用拷贝函数
//string(const char* s)
string s4("hello world");
//字符串类型可以直接用<<>>来打印和输入
//string类中有对<<>>的重载
cout << s1 << endl;
cout << s2 << endl;
cout << s3 << endl;
cout << s4 << endl;
return 0;
}
cpp
int main()
{
//string(const string& str, size_t pos, size_t len = npos)
//第三个是缺省值,要是你不输入他会默认给一个-1,size_t的-1就是一个很大的数字了大约是42亿bit~4G左右
string s1("hello world");
string s2(s1, 1, 9);
cout << s2 << endl;
//string(const char* s, size_t n)
//这个构造函数的使用方式是:从第一个参数的第一个字符开始拷贝,拷贝n个字符,结束
//第一个参数必须得是字符串,不能是字符串对象
//否则就会调用string(const string& str, size_t pos, size_t len = npos)这个构造函数
string s3("hello world", 5);
cout << s3 << endl;
return 0;
}以上是这几个常用的构造函数创建对象的方式
这里在对npos说明一下,这是string类模版中的静态常量

size_tnpos = -1 ,这会使的npos是一个非常大的值,这个值足以应付我们正常的字符串拷贝
stirng中size()、lenght()的使用
cpp
int main()
{
string s1("hello world");
size_t _size = s1.size();//size()和lenght()的返回值都是size_t类型的数据
cout << _size << endl;
cout << s1.size()<<endl;
cout << s1.length() << endl;
return 0;
}size()、length()俩者没有任何区别,你想使用哪一个都可以,作用就是计算该字符串对象中字符串的长度
string中 的使用
cpp
int main()
{
string s1("hello world");
for (int i = 0; i < s1.size(); i++)
{
cout << s1[i] << " ";
}
return 0;
}可以支持直接访问操作
cpp
int main()
{
string s1("hello world");
s1[0] = 'x';
for (int i = 0; i < s1.size(); i++)
{
cout << s1[i] << " ";
}
return 0;
}也可以支持赋值操作
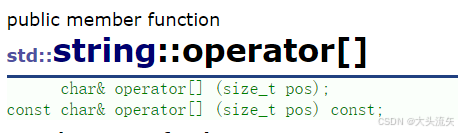
\[\]重载也是支持const修饰的,保证了\[\]在针对const修饰的string对象的时候,不会被修改数据
string中at的使用

at的作用和\[\]是一样的,但是at是更安全的\[\],它支持越界的检查,我知道\[\]对越界的检查只在为尾元素的后几个,一旦超过一定距离,编译器就不会报错,at就很好的解决了这个问题
cpp
#define _CRT_SECURE_NO_WARNINGS 1
#include<iostream>
using namespace std;
void print(const string& str)
{
for(size_t i = 0;i < str.size(); i++)
{
cout << str.at(i) << " ";
}
cout << endl;
}
int main()
{
string s("1234567890");
print(s);
return 0;
}代码结果:
1 2 3 4 5 6 7 8 9 0
string中back/front的使用


front是返回string对象中的第一个元素
back是返回string对象中的最后一个元素
俩个const版本也是对应const修饰的string类型对象
cpp
#define _CRT_SECURE_NO_WARNINGS 1
#include<iostream>
using namespace std;
int main()
{
string s("1234567890");
cout << s.back() << endl;
cout << s.front() << endl;
return 0;
}代码结果:
0
1
sting中max_size
max_size返回的是该容器对象在理想情况下理论上可以容纳的最大元素个数
这个方法的作用并没有什么真正的运用场景,因为内存的大小,系统的不同都会影响,所以这个方法可以不看
string中capacity

作用是返回string对象的最大存储容量,之前我们就说了其实string就是一个字符串,那么是字符串就会存在最大存储容量 和当前存储个数 和起始位置这三个成员属性
string中resize

该方法的作用是根据你给的n来调整string对象的大小
1.n > 对象的最大存储容量时(capacity)
- capacity会扩大到至少n(可能略大于n,取决于内存分配策略)
- size会变成n
- 新元素会初始化为指定值(c存在)或默认值(c不存在)
- ⚠️ 注意 :capacity可能大于n,不一定精确等于n
2.size < n < capacity 时
- capacity不变
- size = n
- 新元素会初始化为指定值(c存在)或默认值(c不存在)
3.n < size时
- capacity不变
- size = n
- size - n这段数据丢失
cpp
#define _CRT_SECURE_NO_WARNINGS 1
#include<iostream>
using namespace std;
int main()
{
string s("1234567890");
cout << s << endl;
cout << "s的初始capacity和size" << endl;
cout << "capacity:"<<s.capacity() << endl;
cout << "size:" << s.size() << endl;
cout<< endl << endl;
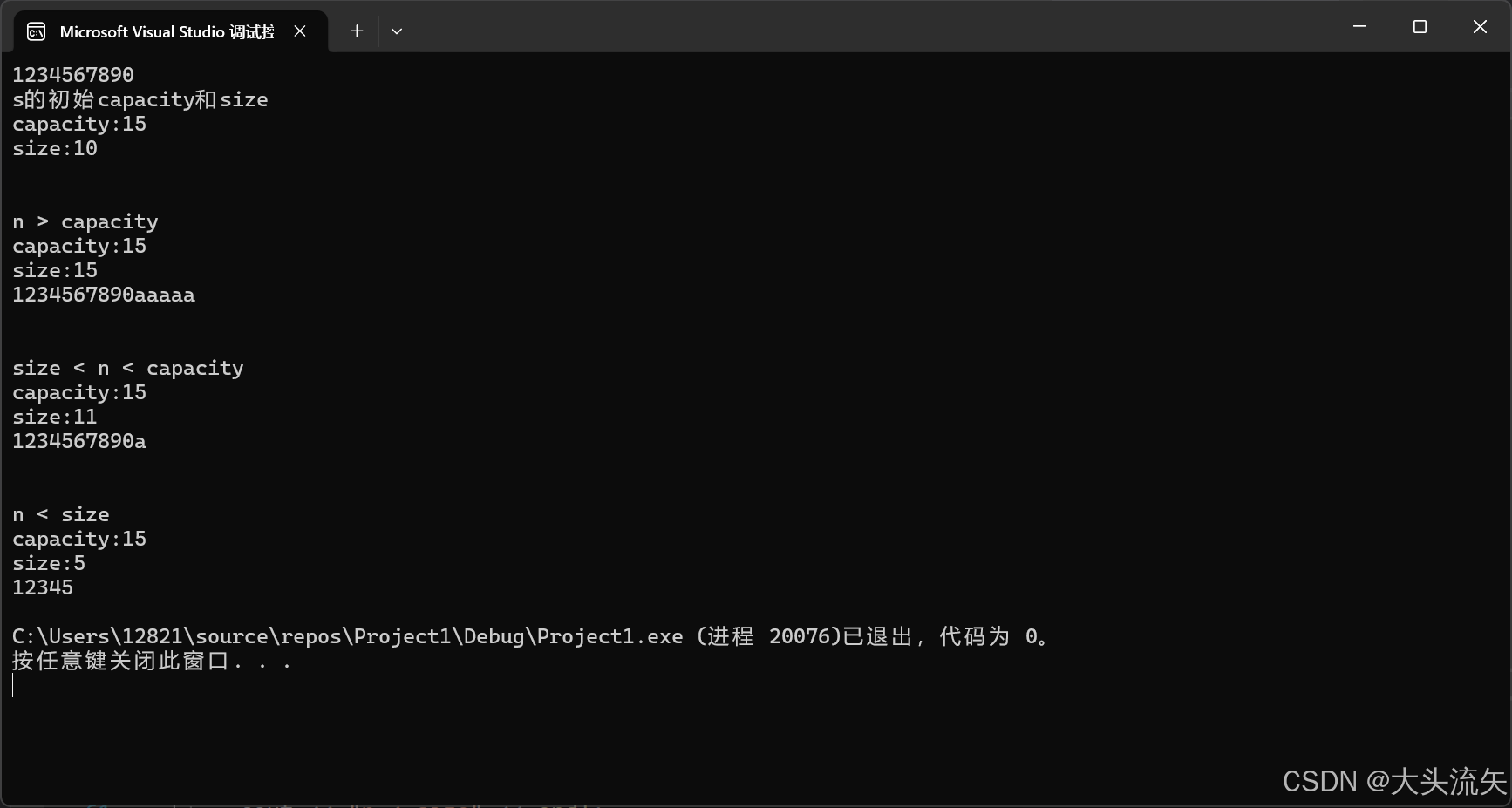
cout << "n > capacity" << endl;
s.resize(15,'a');
cout << "capacity:" << s.capacity() << endl;
cout << "size:" << s.size() << endl;
cout << s << endl;
cout << endl << endl;
cout << "size < n < capacity" << endl;
s.resize(11);
cout << "capacity:" << s.capacity() << endl;
cout << "size:" << s.size() << endl;
cout << s << endl;
cout << endl << endl;
cout << "n < size" << endl;
s.resize(5);
cout << "capacity:" << s.capacity() << endl;
cout << "size:" << s.size() << endl;
cout << s << endl;
return 0;
}代码结果:
string中reserve

reserve的作用就是将string对象的capacity扩容到 大于等于n
cpp
#define _CRT_SECURE_NO_WARNINGS 1
#include<iostream>
using namespace std;
int main()
{
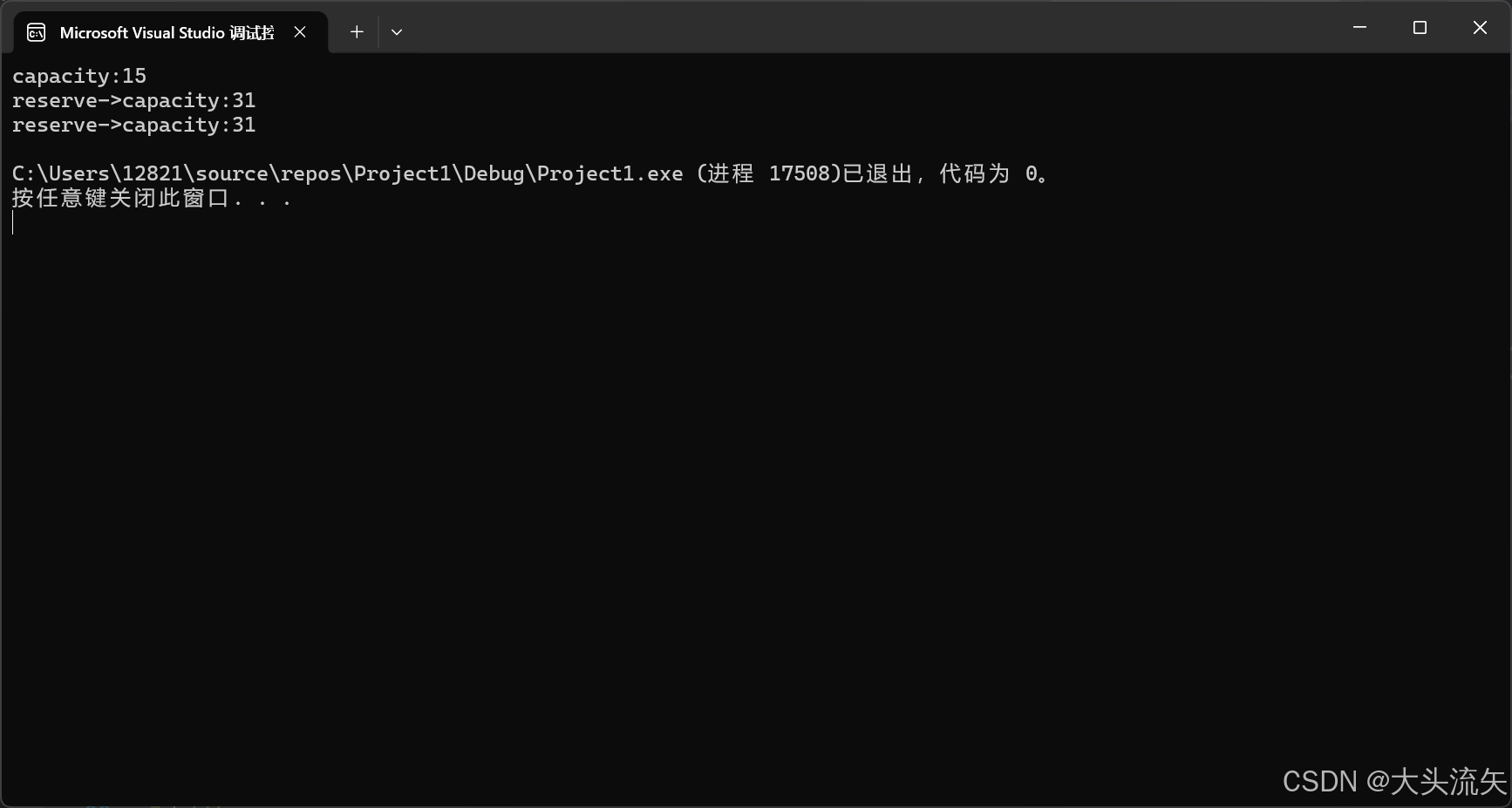
string s("12345");
cout << "capacity:" << s.capacity() << endl;
s.reserve(20);
cout << "reserve->capacity:" << s.capacity() << endl;
s.reserve(20);
cout << "reserve->capacity:" << s.capacity() << endl;
return 0;
}代码结果:
 特点:
特点:
当 n 小于capacity的时候,string对象的capacity不会改变
当 n 大于capacity的时候,string对象的capacity会增容到大于等于n
不同的编译器下的reserve的实现机制不同,在vs2019下的reserve的增容不是以n
这个数值为基准的,他会在n的基础上进行对齐操作,所以最后增容的大小其实并不是n
但是在Linux下,reserve就是按照n的大小来进行扩容,并且最后的增容大小也是以n为基准
重点:不同的编译器下的reserve的实现不同
clear

clear的作用是清空string对象的数据,将size置为0,capacity不变
cpp
#define _CRT_SECURE_NO_WARNINGS 1
#include<iostream>
using namespace std;
int main()
{
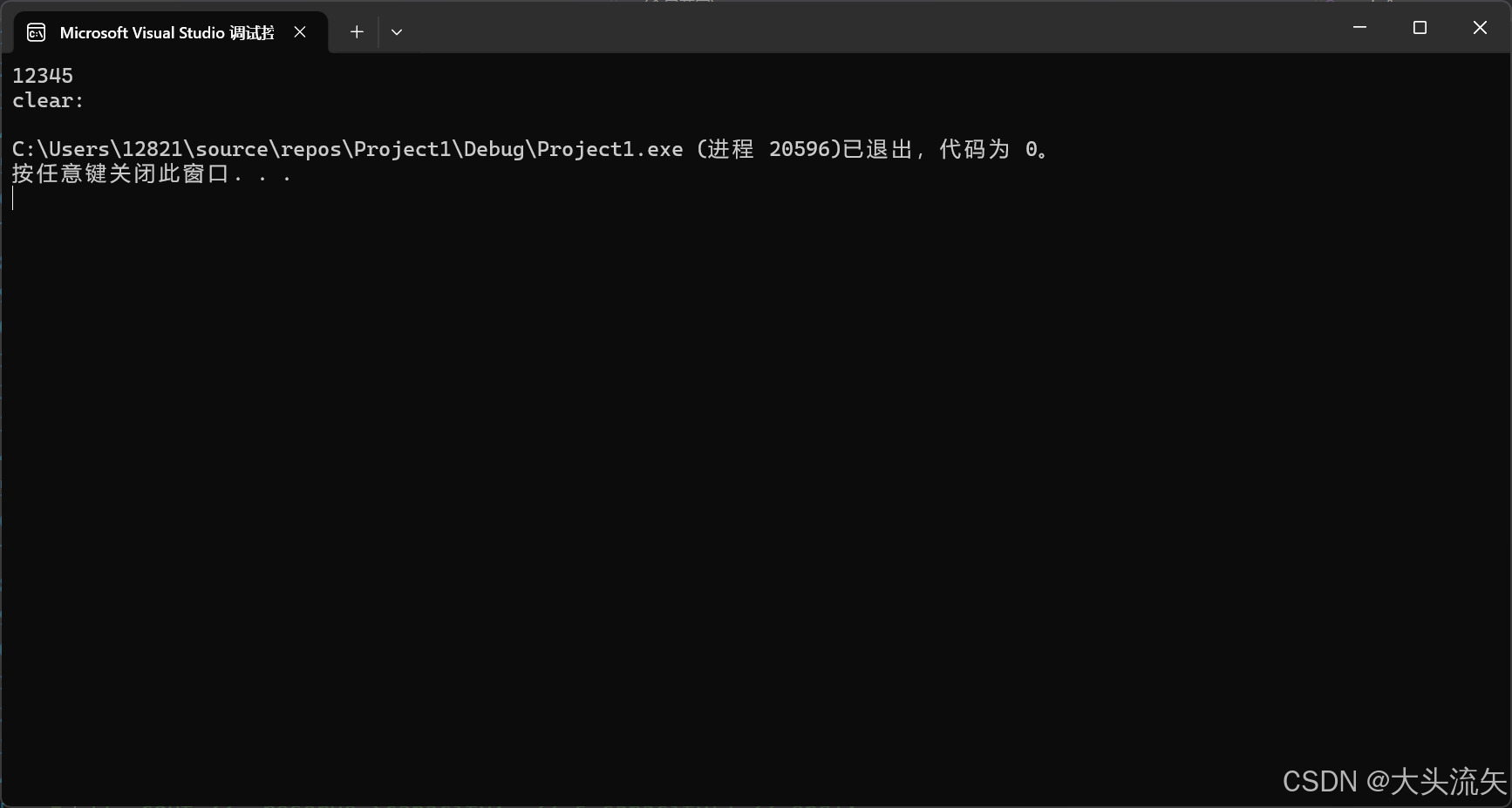
string s("12345");
cout << s << endl;
s.clear();
cout << "clear:" << s << endl;
return 0;
}代码结果:
empty

作用是判断string是否为空,为空就返回true,不为空就返回false
cpp
#define _CRT_SECURE_NO_WARNINGS 1
#include<iostream>
using namespace std;
int main()
{
string s("12345");
cout << s.empty() << endl;
s.clear();
cout << "clear:" << s.empty() << endl;
return 0;
}代码结果:
+=

我们看到+=有三个版本,其实版本1可以不用设计,因为c++中有隐式转化
+=就是对string对象进行尾差
cpp
#define _CRT_SECURE_NO_WARNINGS 1
#include<iostream>
using namespace std;
int main()
{
string s("12345");
string ss = "one two three";
cout << s<< endl;
s += " 6789 ";
s += " qwe";
s += ' c ';
s += ss;
cout <<s<< endl;
return 0;
}代码结果:
append
常用的几个版本就是我框选出来的几个,这几个已经可以满足我们的大部分的使用场景了,属于一定要掌握的,其他的可以按需来学习
append的作用就是对string对象进行尾差,不过尾差的类型可以是string、char*、char类型
也可以是目标数据str的一部分(subpos->sublen)进行尾插
这个版本的append在使用的过程你可能觉得他是左闭右开的,其实不是。如果你传的是0-size这个区间,那么其实最后是有把\0也插入进去的,因为\0对于string来说就是一个普通的字符而已,只是在打印的时候会以\0作为结束标志
如果区间超过了源数据,这种行为是C++未定义的行为,编译器不回去自动检查你的append有没有发生越界
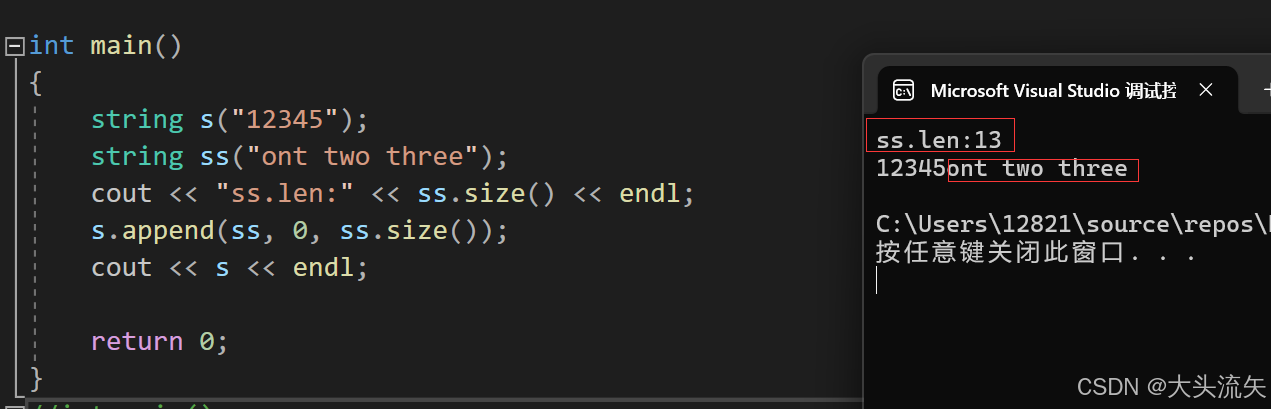
cpp#define _CRT_SECURE_NO_WARNINGS 1 #include<iostream> using namespace std; int main() { string s("12345"); string ss("ont two three"); cout << "ss.len:" << ss.size() << endl; s.append(ss, 0, ss.size()); cout << s << endl; return 0; }代码结果:
这个版本和一般的append不一样
- 正常append在插入是遇到源数据的'\0',就会停止插入
- 这个版本n的优先度大于'\0',只要没有插入到n个数据,哪怕遇到'\0'也不会停下
- 如果源数据的元素个数小于n,这种行为是C++未定义的行为,编译器不回去自动检查你的append有没有发生越界
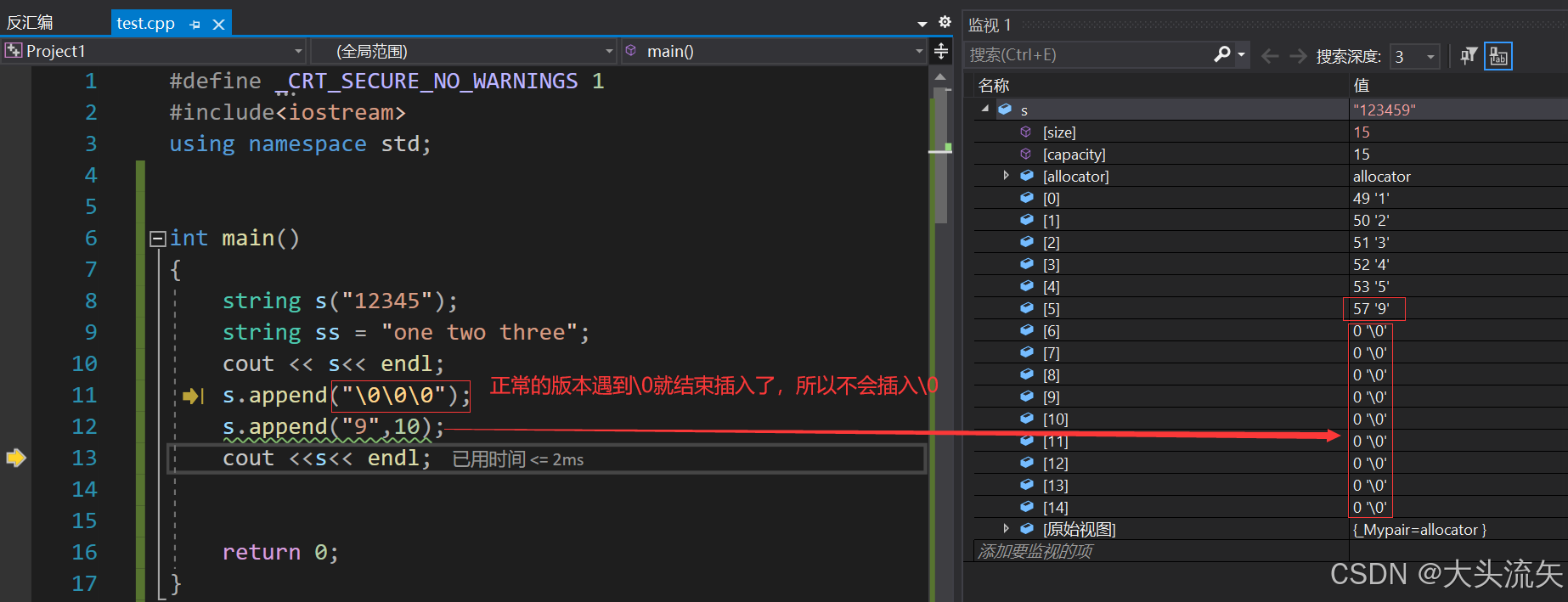
注意看我这段代码,我用append("9",10),明显我的源数据是不够的10位,但是在vs2019下,在插入完9以后,还插入了9个\0,但是这种行为C++是没有做出定义的,所以在不同的编译器下的结果可能不一样
这一图片就很好的证明了,该版本对于\0的优先级并没有n的高
这个版本是用迭代器来完成插入操作
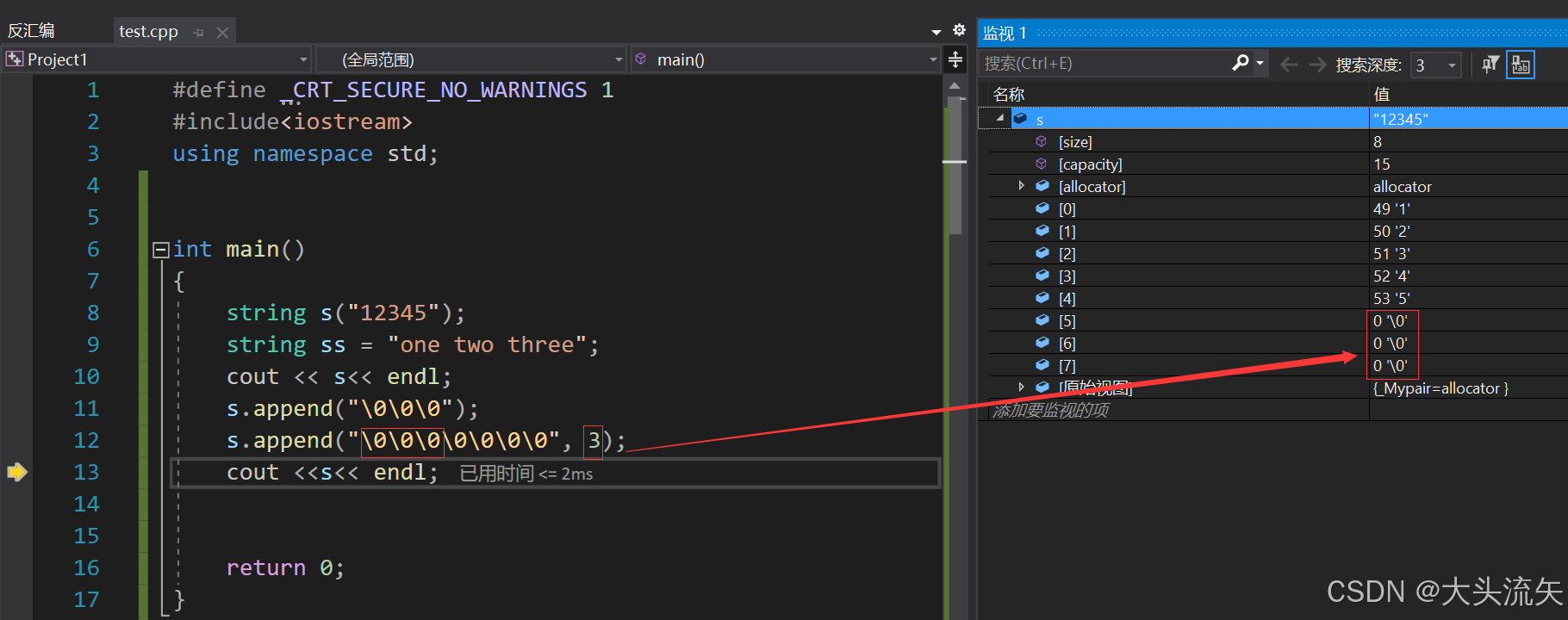
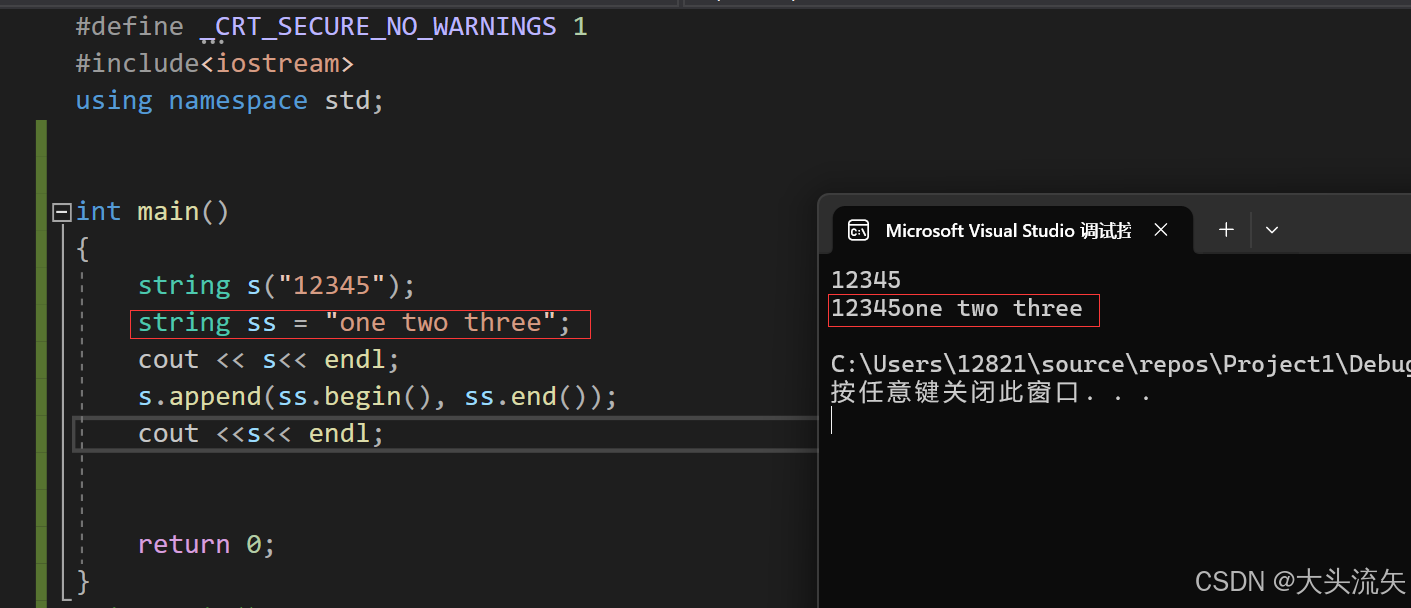
cpp#define _CRT_SECURE_NO_WARNINGS 1 #include<iostream> using namespace std; int main() { string s("12345"); string ss = "one two three"; cout << s<< endl; s.append(ss.begin(), ss.end()); cout <<s<< endl; return 0; }代码结果:



push_back
对string对象进行尾差一个字符
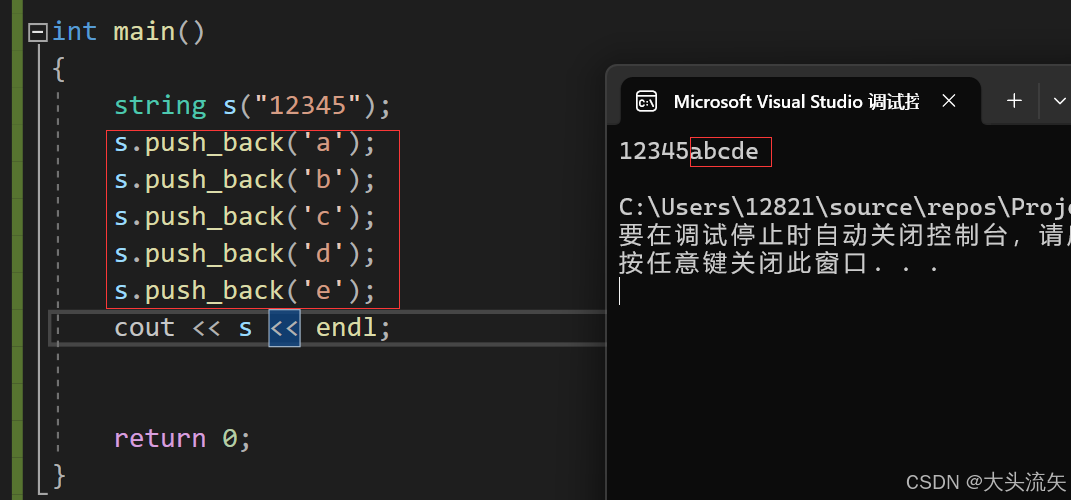
cpp#define _CRT_SECURE_NO_WARNINGS 1 #include<iostream> using namespace std; int main() { string s("12345"); s.push_back('a'); s.push_back('b'); s.push_back('c'); s.push_back('d'); s.push_back('e'); cout << s << endl; return 0; }代码结果:

assign
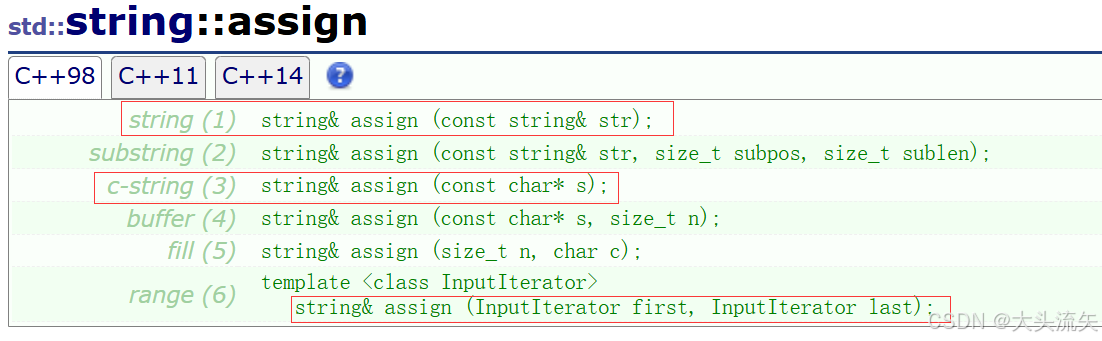
assign的作用:
是将原string对象中的数据,用参数列表中的第一个参数或者他的一部分覆盖掉原有数据
这个assign的版本参数设置和刚刚我们讲的append一模一样,其实确实一个意思
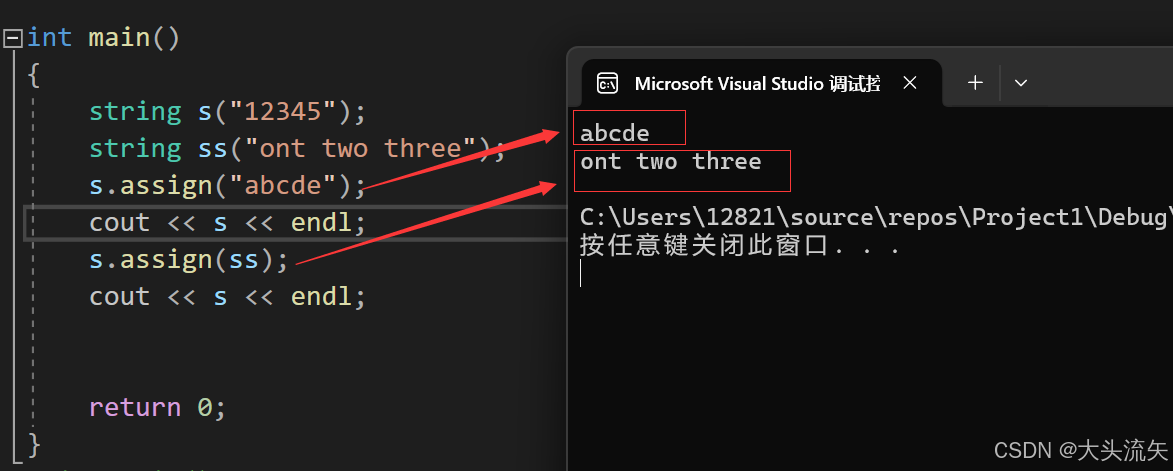
这个就是用str字符串和s的数据去覆盖原string的数据
cpp#define _CRT_SECURE_NO_WARNINGS 1 #include<iostream> using namespace std; int main() { string s("12345"); string ss("ont two three"); s.assign("abcde"); cout << s << endl; s.assign(ss); cout << s << endl; return 0; }代码结果:
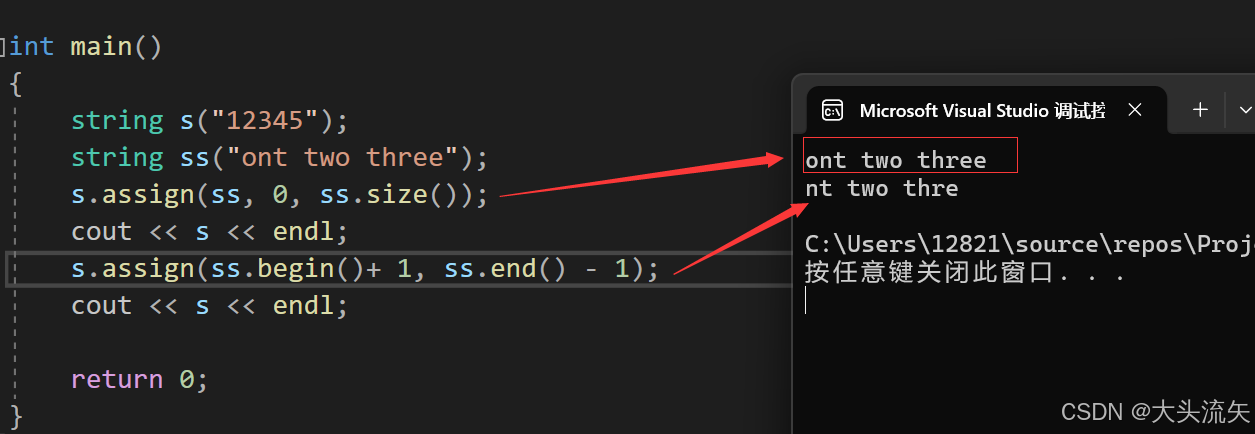
这两个的功能比较类似我就放一起说了,一个是用string对象的subpos->sublen的数据来覆盖源数据
一个是用迭代器来实现用新数据来覆盖源数据
这里的一些使用性质用参考和append相同的参数列表
cpp#define _CRT_SECURE_NO_WARNINGS 1 #include<iostream> using namespace std; int main() { string s("12345"); string ss("ont two three"); s.assign(ss, 0, ss.size()); cout << s << endl; s.assign(ss.begin()+ 1, ss.end() - 1); cout << s << endl; return 0; }
然后这个版本我就不在多说了,参数的使用规则和append那个是一致的,只是这个是覆盖原数据而已




insert

intsert的作用:
在pos位置之前插入数据
还是一样我们不需要全部掌握所有的版本,只要掌握我框上的版本就可以,其他的用的时候在查也是可以的
在pos位置插入一个string对象
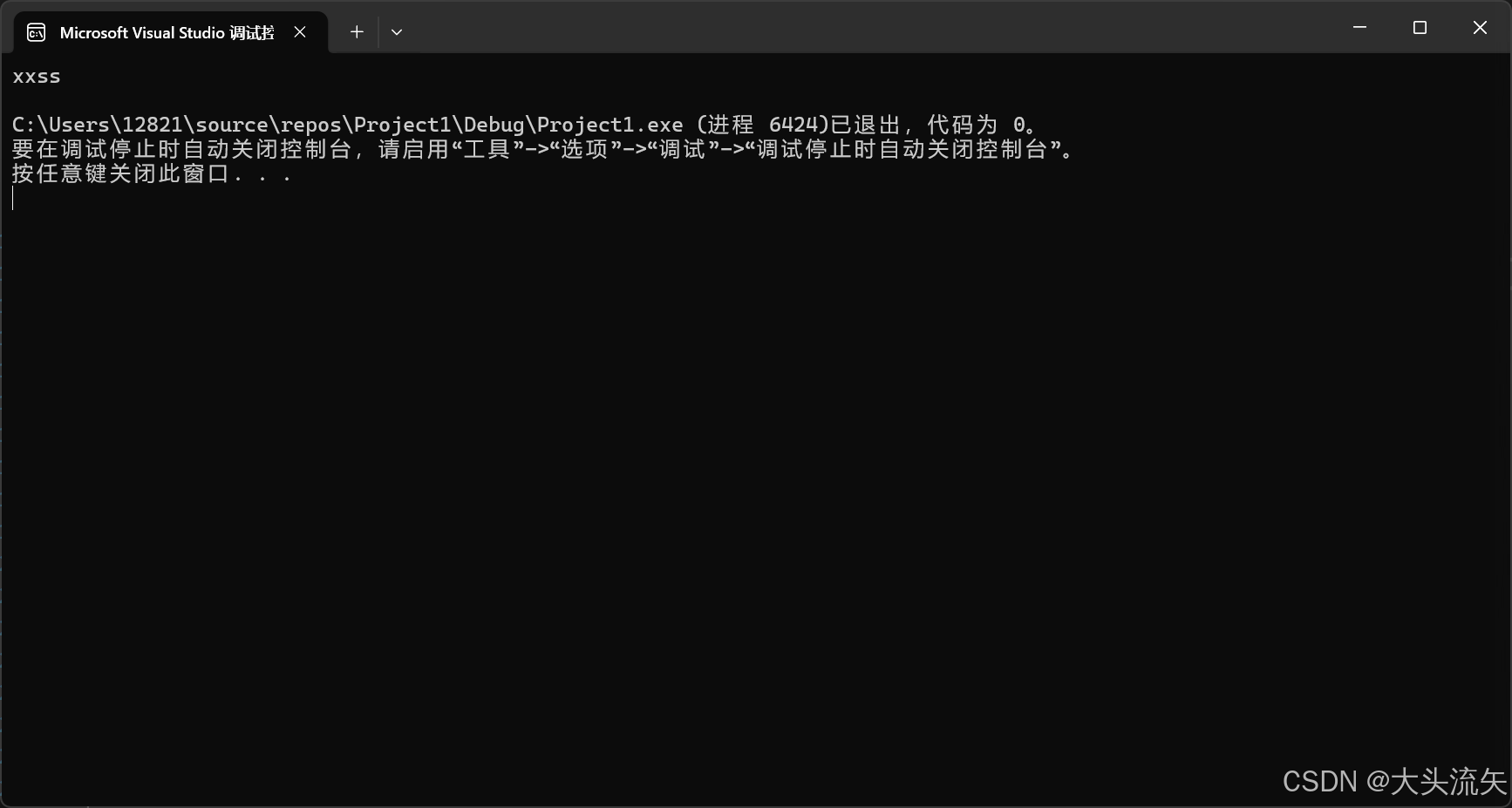
cpp#define _CRT_SECURE_NO_WARNINGS 1 #include<iostream> using namespace std; int main() { string str("ss"); string s = "xx"; str.insert(0, s); cout << str << endl; return 0; }代码结果:
在pos位置之前插入一个字符串,其实这个版本和string版本是一样的(因为C++支持隐式类型转换),没必要再去设计一个char*的版本
cpp#define _CRT_SECURE_NO_WARNINGS 1 #include<iostream> using namespace std; int main() { string str("ss"); str.insert(0, "1234"); cout << str << endl; return 0; }代码结果:
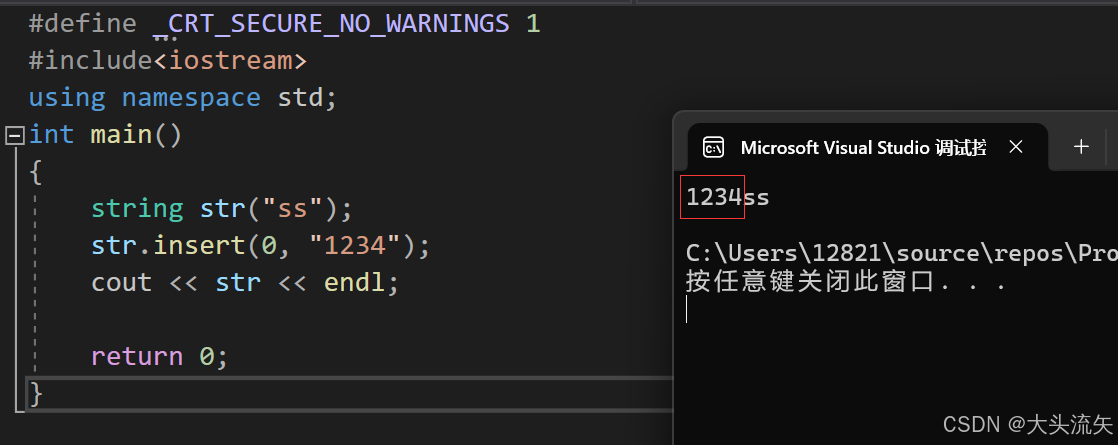
在pos位置之前插入n个字符c这也是insert唯一种不使用迭代器可以插入字符的方式
cpp#define _CRT_SECURE_NO_WARNINGS 1 #include<iostream> using namespace std; int main() { string str("ss"); str.insert(0, 3,'1'); cout << str << endl; return 0; }代码结果:
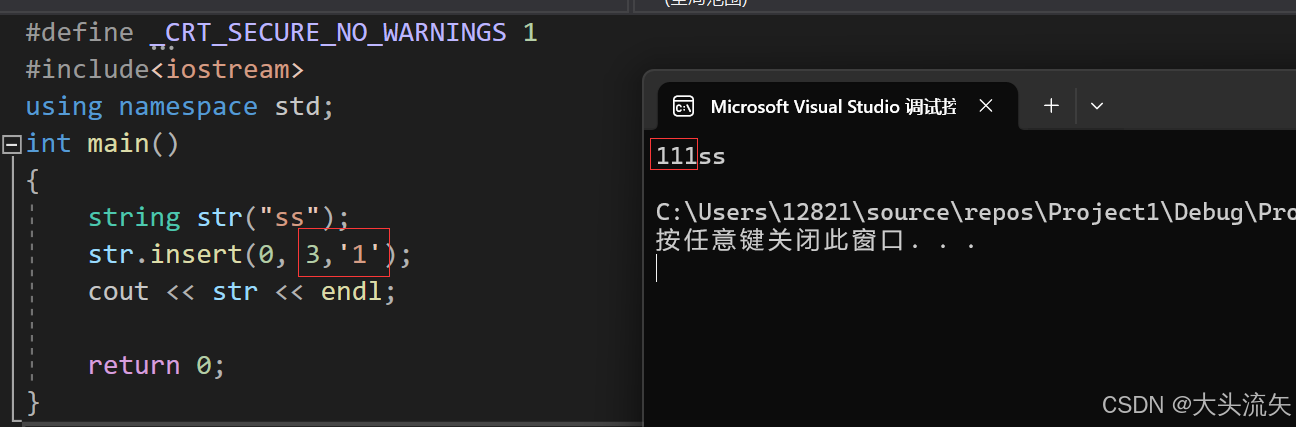
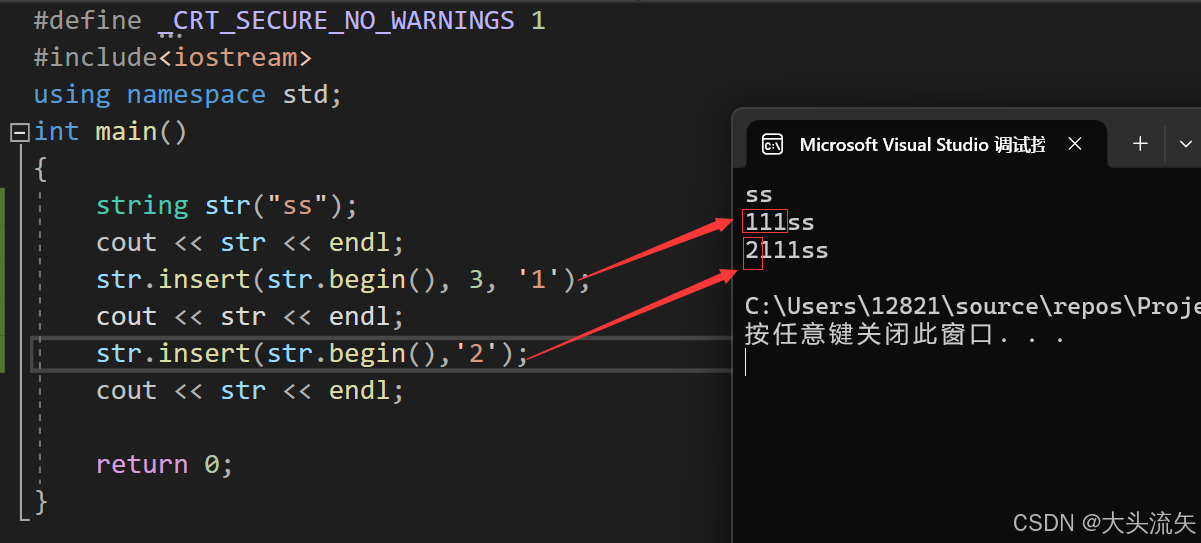
一个是在迭代器p位置之前插入n个字符c
另一个是在迭代器p位置之前插入一个字符c
cpp#define _CRT_SECURE_NO_WARNINGS 1 #include<iostream> using namespace std; int main() { string str("ss"); cout << str << endl; str.insert(str.begin(), 3, '1'); cout << str << endl; str.insert(str.begin(),'2'); cout << str << endl; return 0; }代码结果:




erase

erase的作用:
删除指定位置的数据,或是指定位置的后len个长度单位的数据区间
len是一个缺省值,如果你没传len的值,那么len就会默认赋nops值
我们可以看到nops其实就是一个静态属性,size_t == unsigned int,所以当nops == -1时,npos就是最大的正整数
- 共享性
- 类直接访问
- 再类加载是初始化
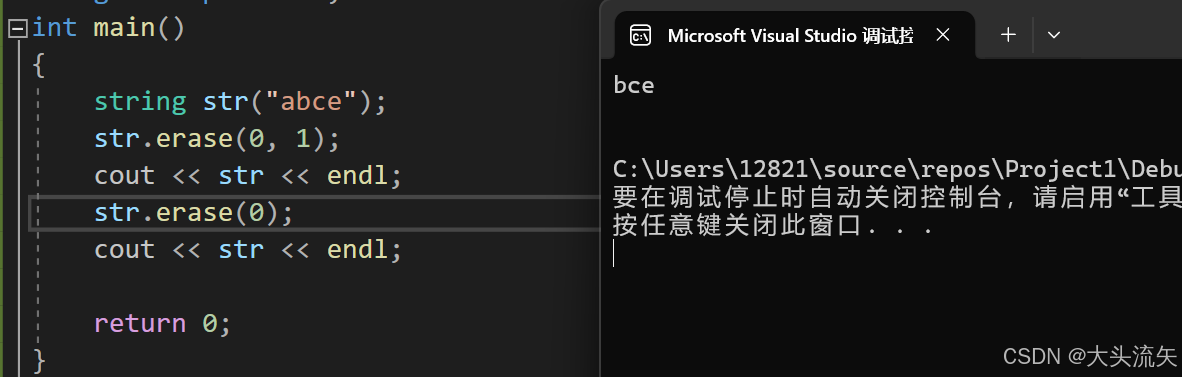
cpp#define _CRT_SECURE_NO_WARNINGS 1 #include<iostream> using namespace std; int main() { string str("abce"); str.erase(0, 1); cout << str << endl; str.erase(0); cout << str << endl; return 0; }代码结果:
这俩版本分别是
- 删除迭代器指向的未知的数据、
- 删除俩个迭代器之间的数据(左闭右开)
左闭右开:包括左迭代器指向的数据,但不包括右迭代器指向的数据(删除到他的前一个位置为止)
cpp#define _CRT_SECURE_NO_WARNINGS 1 #include<iostream> using namespace std; int main() { string str("abce"); str.erase(str.begin() + 1); cout << str << endl; str.erase(str.begin() + 1, str.end() - 1); cout << str << endl; return 0; }代码结果:
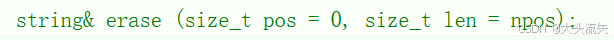


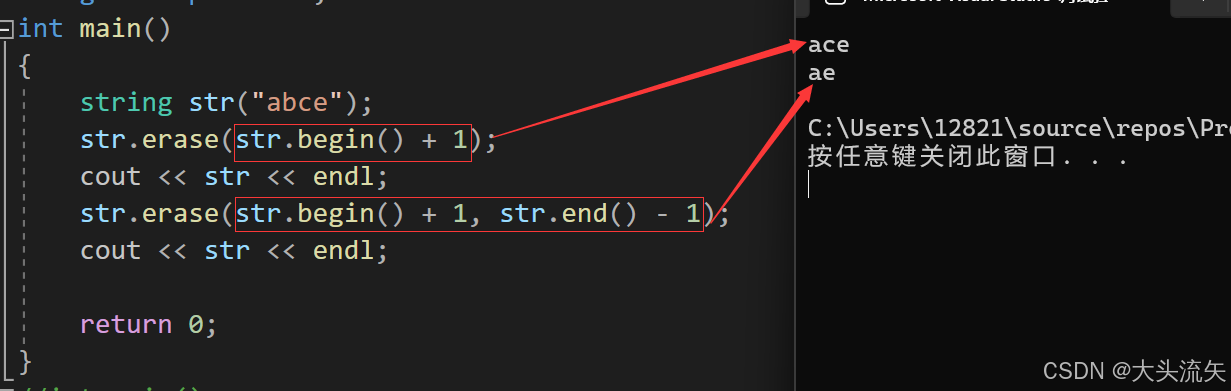
replace

主要关注我框选的几个版本掌握即可,其他的使用场景不多,可以用到在来看
replace的作用:
用于替换字符串中部分内容的成员函数,就是将string对象中的数据或者一部分数据替换掉
(替换不一定就是等值个数的数据替换,也可能是1个元素被替换成2个元素,2个元素被替换成1个元素)
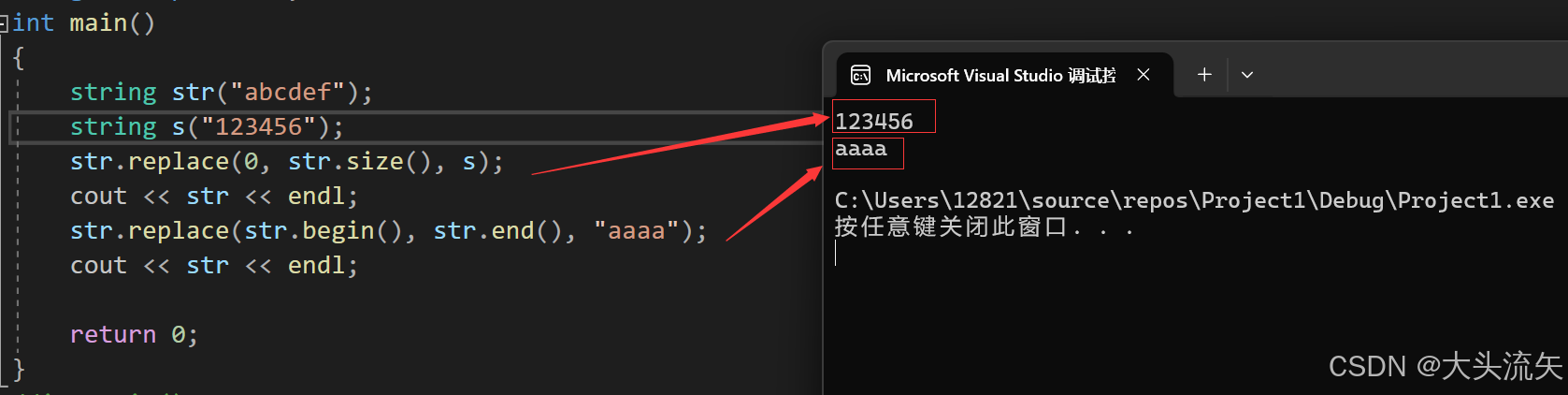
在pos位置到pos+len的区间,替换为str(左闭右开)
在迭代器i1到迭代器i2区间,替换为str
cpp#define _CRT_SECURE_NO_WARNINGS 1 #include<iostream> using namespace std; int main() { string str("abcdef"); string s("123456"); str.replace(0, str.size(), s); cout << str << endl; str.replace(str.begin(), str.end(), "aaaa"); cout << str << endl; return 0; }代码结果:
这个两版本其实和上面的string版本是一样的,就是替换的源数据不一样,一个是string一个是char*类型的,这里我就不再去演示了
把指定的区间的数据替换成n个字符c
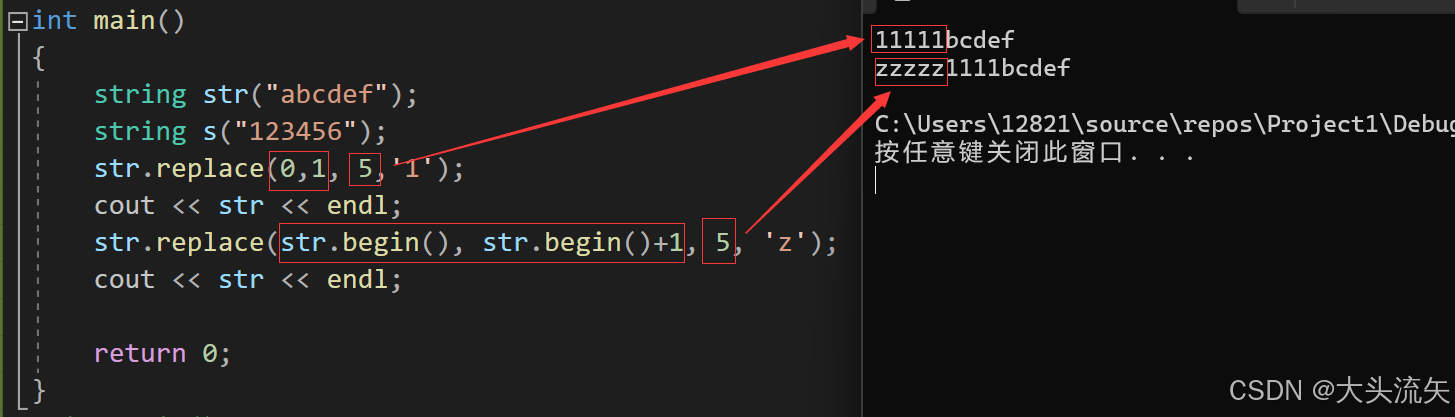
cpp#define _CRT_SECURE_NO_WARNINGS 1 #include<iostream> using namespace std; int main() { string str("abcdef"); string s("123456"); str.replace(0,1, 5,'1'); cout << str << endl; str.replace(str.begin(), str.begin()+1, 5, 'z'); cout << str << endl; return 0; }代码结果:
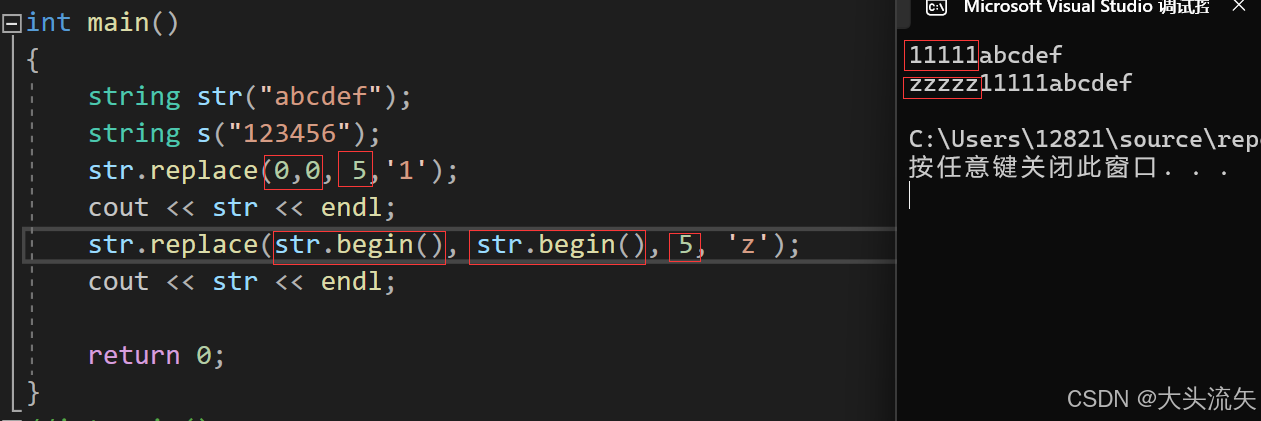
这里在讲一下,当len的长度为0的的时候、当i1和i2相等的时候
cpp#define _CRT_SECURE_NO_WARNINGS 1 #include<iostream> using namespace std; int main() { string str("abcdef"); string s("123456"); str.replace(0,0, 5,'1'); cout << str << endl; str.replace(str.begin(), str.begin(), 5, 'z'); cout << str << endl; return 0; }代码结果:
我们可以看到,当len的长度为0,i1和i2相等的时候,其实此时的替换操作,就变成了插入操作,而且是pos(i1)位置之前插入的操作,虽然replace可以进行这一的操作,但是如果我们要进行插入操作,还是建议直接使用insert



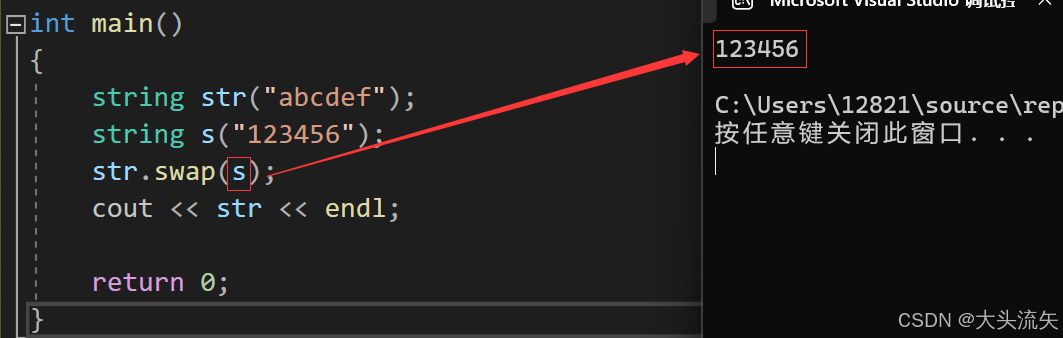
swap

swap作用:
交换俩个string对象的数据
这个第一的个swap是string类的成员函数,第二个是std域名中的swap函数
区别:
- string类中的swap成员函数内部是直接交换两个string对象的地址,来达到数据交换的效果
- std域名中的swap函数内部是创建一个相同的数据类型作为媒介,来交换两个对象的数据,但是这种交换会涉及到对象的拷贝构造,所以并没有类中的swap来的高效
cpp
#define _CRT_SECURE_NO_WARNINGS 1
#include<iostream>
using namespace std;
int main()
{
string str("abcdef");
string s("123456");
str.swap(s);
cout << str << endl;
return 0;
}代码结果:
pop_back
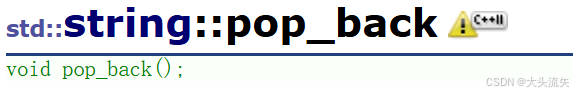
pop_back的作用:
删除字符串的最后一个元素
cpp
#define _CRT_SECURE_NO_WARNINGS 1
#include<iostream>
using namespace std;
int main()
{
string str("abcdef");
str.pop_back();
cout << str <<endl;
return 0;
}代码结果:
c_str和data
c_str和data的作用:
返回一个char*地址
我们一开始就说了,string其实就是一个字符串,是字符串就会有char*的地址,只是string对char*字符串进行了一系列的封装,最后以string 的形式供我们使用
那有没有什么使用场景呢?
有的
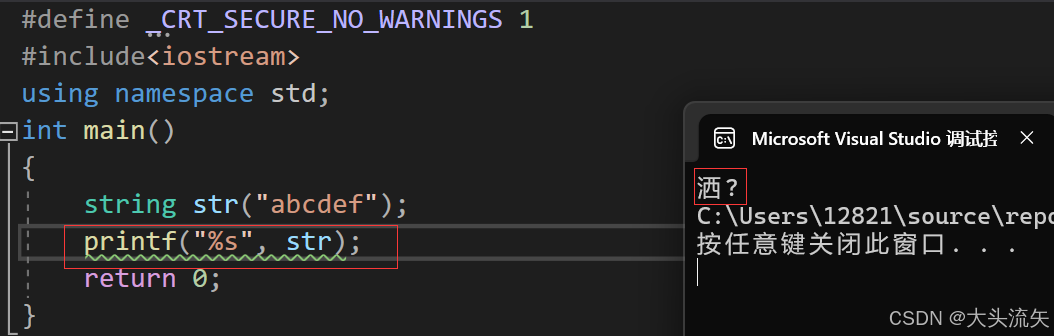
当我们想用printf来打印string对象的时候,你会发现报错,为什么会这样呢?因为printf会根据%s来判断接受的地址是一个字符串地址,但是string对象他的地址里面不光是存储了字符串,还有字符串的元素个数、最大存储容量等等信息,所以你直接当字符串打印打出来的就很可能是乱码
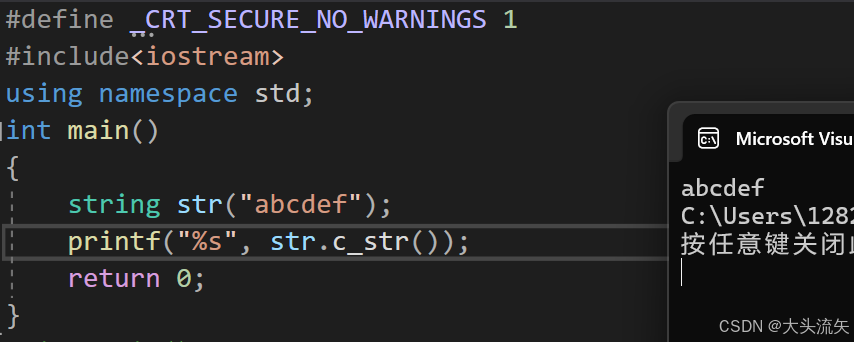
当你使用c_str和data的时候就可以正常打印,这相当于你直接把string对象中的字符串地址提取出来了
copy

copy作用:
用数组s来接收string对象距离pos位置的len个距离单位的数据区间
cpp
#define _CRT_SECURE_NO_WARNINGS 1
#include<iostream>
using namespace std;
int main()
{
string str("abcdef");
char data[20];
str.copy(data, 2, 0);
cout << data <<endl;
return 0;
}代码结果:
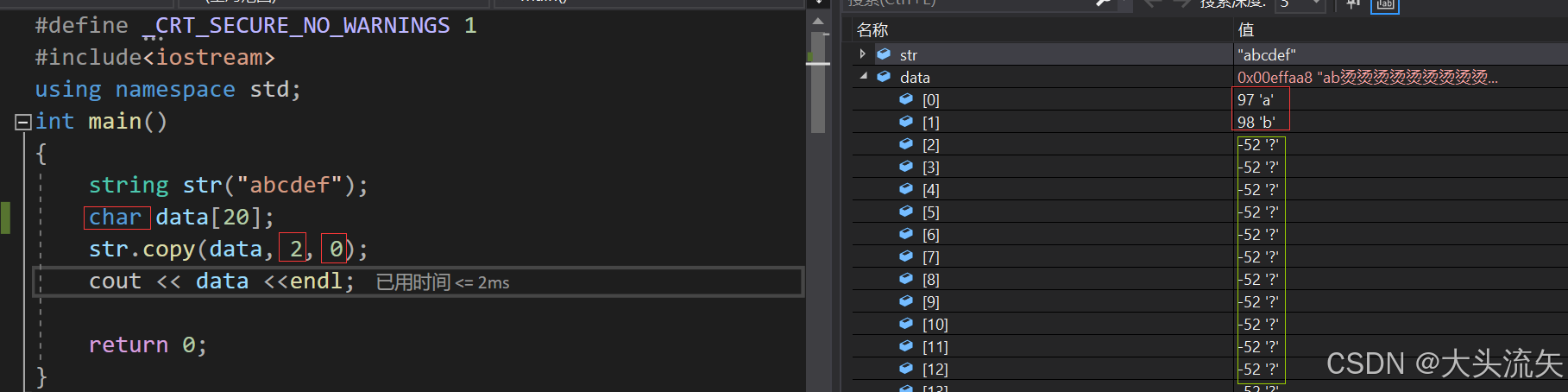
直接截取拷贝到目标数组里,肯定会丢失\0但是没关系,因为data是以字符的形式存储的,不需要\0来作为结束标记
find

find的作用:
根据给的第一个参数,在string对象中从pos位置开始查找第一次匹配的数据,返回该数据的的下标,找不到返回nops
cpp
#define _CRT_SECURE_NO_WARNINGS 1
#include<iostream>
using namespace std;
int main()
{
string str("abcdef");
string s("b");
//size_t find (const string& str, size_t pos = 0) const;
size_t judge = str.find(s);
if (judge != string::npos)
{
cout << str[judge] << endl;
}
//size_t find (const char* s, size_t pos = 0) const;
judge = str.find("b");
if (judge != string::npos)
{
cout << str[judge] << endl;
}
//size_t find (const char* s, size_t pos, size_t n) const;
judge = str.find("b", 0, 1);
if (judge != string::npos)
{
cout << str[judge] << endl;
}
//size_t find (char c, size_t pos = 0) const;
judge = str.find('b');
if (judge != string::npos)
{
cout << str[judge] << endl;
}
return 0;
}代码结果:
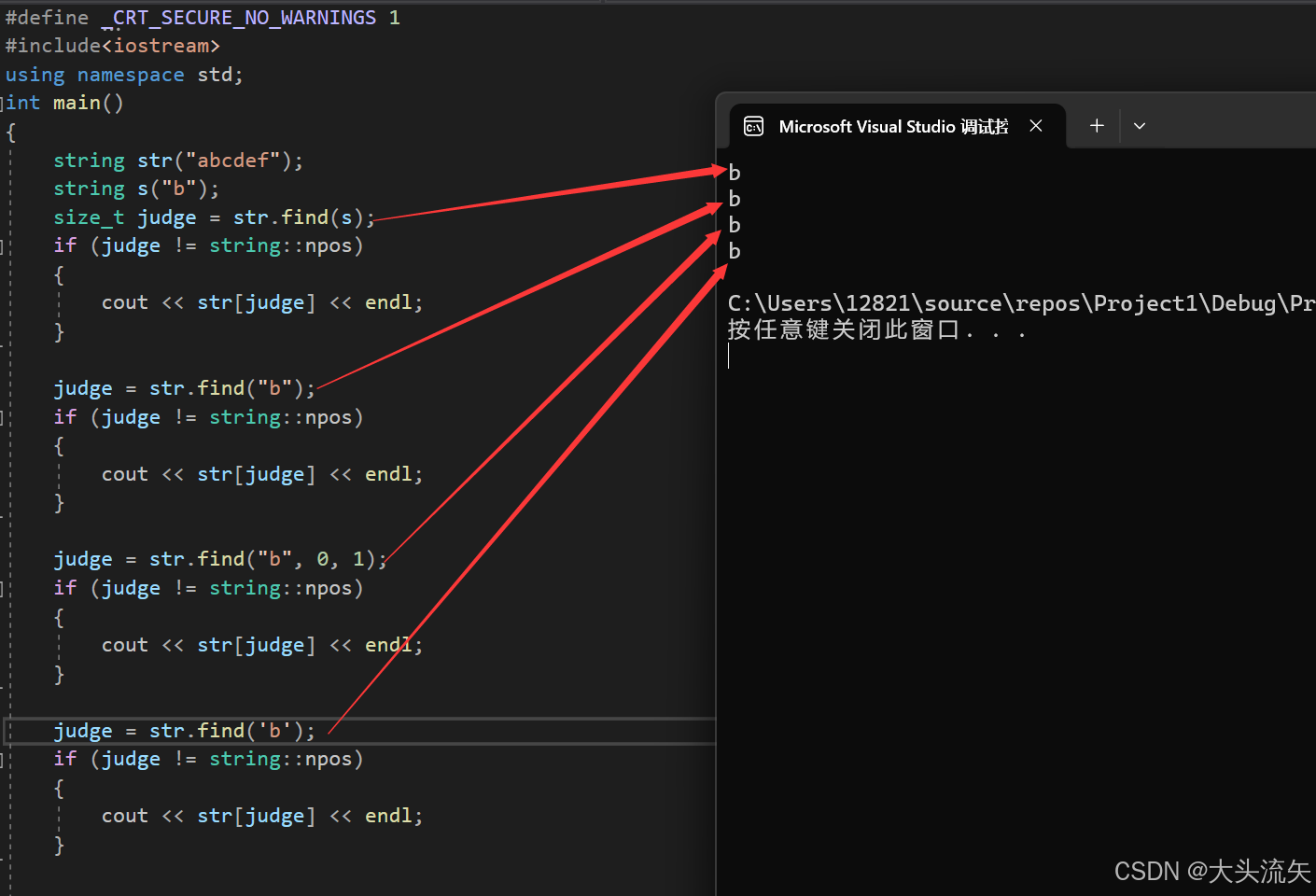
我相信其他几个版本大家都可以看得懂,就是
size_t find (const char\* s, size_t pos, size_t n) const;这个版本可能有点看不明白,我这里再解释一下
从string对象的pos位置开始查找,查找的对象是s字符串数组的前n位
rfind和find_first_of、find_last_of、find_first_not_of、find_last_not_of
rfind的作用:
从后往前查找
find_first_of的作用:
从前往后查找,只要查找到数据中的任意一个元素,就返回下标
find_last_of的作用:
从后往前查找,只要查找到数据中的任意一个元素,就返回下标
find_first_not_of的作用:
从前往后查找,除了数据中的元素,查找到其他的任意元素就返回下标
find_last_not_of
从后往前查找,除了数据中的元素,查找到其他的任意元素就返回下标
因为他们的参数列表都是一致的,所以我就不一一演示了
substr

substr的作用:
将string对象的pos位置到pos+len位置的数据区间,拷贝出来构成一个子串
cpp
#define _CRT_SECURE_NO_WARNINGS 1
#include<iostream>
using namespace std;
int main()
{
string str("abcdef");
string s = str.substr(0,3);
cout << s << endl;
return 0;
}代码结果:
string中iterator迭代器
迭代器 iterator一般是做一个类型来创建对象,或者是作为其他迭代器的返回值或者参数类型
(你可以理解iterator是一个被重命名的char*)
迭代器就是string中专门用来访问string对象数据的,为什么明明有了\[\]还需要iterator迭代器呢?
这个也是为了和其他容器保持一致,因为在内存空间连续存储的string和vector容器中确实感觉作用并不突出,但是在内存空间不连续的链表结构和树结构上那就效果十分显著了,我们只需要创建一个迭代器,然后去根据自己的需求是修改还是迭代打印就可以,不需要去关注他们之间的访问细节
begin和end

这里为了更好的理解,我们先把上面这些迭代器分为两大类
begin() end()
cbegin() cend()
rbegin() rend()
crbegin() crend()
我们先来了解一下begin和end

begin的作用是返回字符串的第一个元素的位置,end的作用是返回字符串的最后一个元素的位置
然后it指向该元素,你可以暂时理解为是一个指针
cpp
int main()
{
string s1("hello world");
//要指定类域才可以直接访问,这个it可以自己去设置名字
string::iterator it = s1.begin();
while (it != s1.end())
{
cout << *it << " ";
++it;
}
return 0;
}注意begin()和end()的也有const版本,但是他们的返回值是const_iterator (这一点和iterator的普通版本和const版本是相对应的)
之所以会引用iterator迭代器来遍历,就是因为下标+\[\]只适用于部分容器,底层物理有一定连续的,链式结构、树形结构、哈希结构只能用迭代器,迭代器才是容器访问的主流形态
每一个容器里面都有一个iterator迭代器,但是iterator也分俩个版本
一个是无const修饰的版本,一个是有const修饰的版本(const修饰的是this地址)
注意const_iterator不是const iterator
|-----------------------|------------|
| iterator() | 无const修饰 |
| const_iterator()const | 修饰*it不能修改 |
| const iterator() | 修饰it不能修改 |
这里在讲一下const_iterator的使用场景
cpp
#define _CRT_SECURE_NO_WARNINGS 1
#include<iostream>
using namespace std;
void print(const string& str)
{
//如果这里不使用const_iterator的话,str.begin就会报错
string::const_iterator it = str.begin();
while (it != str.end())
{
cout << *it++ << "";
}
cout << endl;
}
int main()
{
string s("1234567890");
print(s);
return 0;
}代码结果:
1 2 3 4 5 6 7 8 9 0
这里在解释一下为什么会报错,因为C++的编译器在检测到str为const修饰的对象以后,在str去调用begin迭代器就会去调用那个const_iterator begin()const版本的迭代器,这个时候的返回值就是const_iterator类型的,你用iterator类型的it去接收const_iterator的类型,类型就会不匹配
范围for
其实范围for的原理也是迭代器的调用,编译器会去调用迭代器去实现所需要的功能,但是如果想验证这一观点的话,现阶段最好的办法就是,自己去模拟实现一个string类,然后在迭代器的实现部分,begin和end就先不实现,然后去使用范围for看看他是否可以正常运行
cbegin/rbegin/crbegin和cend/rend/crend
除了begin/rbegin和end/rend,其他这几个迭代器是C++11中引入的,其实在功能上他们之间没有什么区别
begin == cbegin end == cend rbegin == crbegin rend == crend
加c的前缀就是const版本,但是begin、end、rbegin、rend都是自带const版本的,所以特意分出来一个const版本意义不是特别大,当然如果你使用了C++11新引入的迭代器,那么在代码的可读性上绝对是有提升的